
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I wrote a node + vue web app that consumes bing api and lets you block specific hosts with a click, and I have some thoughts I need to post somewhere.
My main motivation for this it is that the search results I've been getting with the big search engines are lacking a lot of quality. The SEO situation right now is very complex but the bottom line is that there is a lot of white hat SEO abuse.
Commercial companies are fucking up the internet very hard. Search results have become way too profit oriented thus unneutral. Personal blogs are becoming very rare. Information is losing quality and sites are losing identity. The internet is consollidating.
So, I decided to write something to help me give this situation the middle finger.
I wrote this because I consider the ability to block specific sites a basic universal right. If you were ripped off by a website or you just don't like it, then you should be able to block said site from your search results. It's not rocket science.
Google used to have this feature integrated but they removed it in 2013. They also had an extension that did this client side, but they removed it in 2018 too. We're years past the time where Google forgot their "Don't be evil" motto.
AFAIK, the only search engine on earth that lets you block sites is millionshort.com, but if you block too many sites, the performance degrades. And the company that runs it is a for profit too.
There is a third party extension that blocks sites called uBlacklist. The problem is that it only works on google. I wrote my app so as to escape google's tracking clutches, ads and their annoying products showing up in between my results.
But aside uBlacklist does the same thing as my app, including the limitation that this isn't an actual search engine, it's just filtering search results after they are generated.
This is far from ideal because filter results before the results are generated would be much more preferred.
But developing a search engine is prohibitively expensive to both index and rank pages for a single person. Which is sad, but can't do much about it.
I'm also thinking of implementing the ability promote certain sites, the opposite to blocking, so these promoted sites would get more priority within the results.
I guess I would have to move the promoted sites between all pages I fetched to the first page/s, but client side.
But this is suboptimal compared to having actual access to the rank algorithm, where you could promote sites in a smarter way, but again, I can't build a search engine by myself.
I'm using mongo to cache the results, so with a click of a button I can retrieve the results of a previous query without hitting bing. So far a couple of queries don't seem to bring much performance or space issues.
On using bing: bing is basically the only realiable API option I could find that was hobby cost worthy. Most microsoft products are usually my last choice.
Bing is giving me a 7 day free trial of their search API until I register a CC. They offer a free tier, but I'm not sure if that's only for these 7 days. Otherwise, I'm gonna need to pay like 5$.
Paying or not, having to use a CC to use this software I wrote sucks balls.
So far the usage of this app has resulted in me becoming more critical of sites and finding sites of better quality. I think overall it helps me to become a better programmer, all the while having better protection of my privacy.
One not upside is that I'm the only one curating myself, whereas I could benefit from other people that I trust own block/promote lists.
I will git push it somewhere at some point, but it does require some more work:
I would want to add a docker-compose script to make it easy to start, and I didn't write any tests unfortunately (I did use eslint for both apps, though).
The performance is not excellent (the app has not experienced blocks so far, but it does make the coolers spin after a bit) because the algorithms I wrote were very POC.
But it took me some time to write it, and I need to catch some breath.
There are other more open efforts that seem to be more ethical, but they are usually hard to use or just incomplete.
commoncrawl.org is a free index of the web. one problem I found is that it doesn't seem to index everything (for example, it doesn't seem to index the blog of a friend I know that has been writing for years and is indexed by google).
it also requires knowledge on reading warc files, which will surely require some time investment to learn.
it also seems kinda slow for responses,
it is also generated only once a month, and I would still have little idea on how to implement a pagerank algorithm, let alone code it.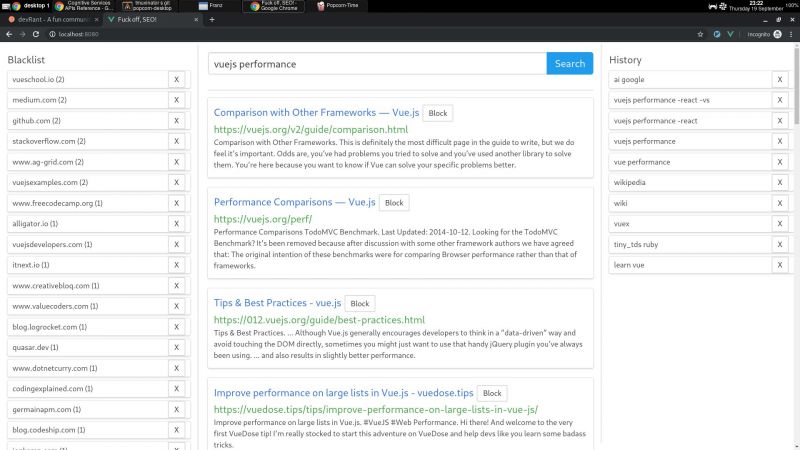 4
4 -
Every time I search for some CSS or Javascript feature the first three or four results are always from w3schools. I want MDN! Any good tricks or sites that does not involve searching directly on MDN? Some Google filter add-on perhaps?14
-
WTF!? Is the internet is fake? What happened to the actual internet?
If you take any search phrase and search on Google or Bing you will get millions or billions or results. But if you go to the last page enough times it will drop down to a total of like 200 results. I am unsure on other search engines as they make it difficult to jump ahead in the search (only provide "next page"). I was going to the next page of results in Brave search engine and it came up with a "are you human" test. Like nobody is going to search more than a few pages. This definitely makes me feel like in am in the Truman Show.
What is the point of limiting to only a few hundred pages? Why show millions or billions for initial search? Are there any real search engines that don't filter so much? Did the technocrats burn the second great library already?8



Top Tags
Weekly Rant
View