
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
A fanfic based on devRant-chan. The character was created by @caramelCase and a drawing by @ichijou.
This is freestyle. I'll think of an image of a scene and go with the flow. I won't remove my fingers from the keyboard and I won't edit or change anything. That's how I come up with my best ideas.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Notes:
B/N = Boss' name (I was too lazy to think of one.)
Anything in between astericks is in italics.
Ex.) *this is in italics.*
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
It was an early January morning when devRant-chan was situated in her desk, typing away on her laptop. She was working on a Python script for her barbaric client when she could've been out with friends. Oddly enough, her Sunday was surged with tranquility.
Normally, Sunday is when her irksome boss barks orders at her on the phone.
"This is wrong!"
"What is this?"
"Change it!"
devRant-chan resented her boss but loved her job. After all, "you can't force yourself to like everyone," was something her elder brother would tell her.
She released a slight chuckle, the one she would only display at the thought of her brother.
Her musings were interrupted when a concerning thought crawled into her mind like an undesirable intruder.
Why hasn't her boss called to complain yet? It's not that she enjoyed his complaining, which she didn't. She simply found it odd, since he's done this every Sunday morning, since she was a junior developer.
Unless he found someone else to complain to? In that case, good riddance!
But still, it wasn't a euphoric feeling to be replaced. She was already accustomed to his Sunday morning calls that it feels almost lonely not to receive them.
She should call him... Just in case some situation—or—problem—has emerged.
She dialed his number, waiting patiently for a reply.
"Hello," said her boss.
"Ah, hello," said devRant-chan. "I called, wondering—"
"You've reached the voicemail of B/N, please leave a message after the beep."
"Damn..." mumbled devRant-chan with a sharp exhale. "I always fall for that."
Why didn't her boss answer the phone? It was odd of him, considering he's always answered her calls.
She was about to dial her coworker when she received an email, which stimulated her attention. The subject of the email read:
*Important. Please read.*
She opened the email. It was her boss. The email read:
*Hello.*
*In case you aren't aware, I had quit my job, due to the stress. I've left the manager in charge. Starting tomorrow, he will be your new boss.*
*-B/N*
Before she could rejoice in excitement, she detected a strange change of voice, emitting from the email. Did her boss really write this?
That's when she spotted something. The word "tomorrow."
Her boss didn't write this.
He would never use words such as "tomorrow," or "today." He would use time instead. If this was her boss, he would say "in 24 hours."
She checked the IP of the email. Oddly enough, it was her boss' IP.
Still, the pieces didn't fit the puzzle. Her boss didn't complain, answer her call, or use his style of speaking in the email.
Something happened to him and she knows it. Whatever it is, has something to do with the manager, and she was determined to figure it out.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
This was just a quick random fanfic, and I'm not sure if I'll continue it. As I said, I didn't plan anything, since it's freestyle. I might or might not continue it, so I'll think it over.8 -
The riskiest dev choice...
How about "The riskiest thing you've done as a dev"? I have a great entry for that. and I suppose it was my choice to build the feature afterall.
I was working on an instance of a small MMO at a game company I worked for. The MMO boasted multiple servers, each of them a vastly different take on the base game. We could use, extend, or outright replace anything we wanted to, leading to everything from Zelda to pokemon to an RP haven to a top-down futuristic counterstrike. The server in this particular instance was a fantasy RPG, and I was building it a new leveling and experience system with most of the trimmings. (Talents, feats/perks, etc. were in a future update.)
A bit of background, first: the game's dev setup did not have the now-standard dev/staging/prod servers; everything ran on prod, devs worked on prod, players connected and played on prod, etc. Worse yet, there was no backup system implemented -- or not really. The CTO was really the only person with sufficient access. The techy CEO did as well, but he rarely dealt with anything technical except server hardware, occasionally. And usually just to troll/punish us devs (as in "Oops ! I pulled the cat5 ! ;)"). Neither of them were the most reliable of people, either. The CTO would occasionally remote in and make backups of each server -- we assumed whenever he happened to think of it -- and would also occasionally do it when asked, but it could take him a week, sometimes even up to a month to get around to it. So the backups were only really useful for retreiving lost code and assets, not so much for player data.
The lack of reliable backups and the lack of proper testing grounds (among the plethora of other issues at the company) made for an absolutely terrible dev setup, but that's just how it was, and that's what we dealt with. We were game devs, afterall. Terrible or not, we got to make games! What more could you ask for!? It was amazing and terrible and wonderful and the worst thing ever, all at the same time. (and no, I'm not sharing the company name, but it isn't EA or Nexon, surprisingly 😅)
Anyway, back to the story! My new leveling system also needed to migrate players' existing data, so... you can see where this is going.
I did as much testing and inspection of my code as I could, copied it from a personal dev script to the server's xp system, ... and debated if I really wanted to click [Apply]. Every time I considered it, I went back to check another part or do yet more testing. I ended up taking like 40 minutes to finally click it.
And when I did... that was the scariest button press of my life. And the scariest three seconds' wait afterwards. That one click could have ruined every single player's account, permanently lost us players ...
After applying it, I immediately checked my character to see if she was broken, checked the account data for corruption or botched flags, checked for broken interactions with the other systems....
Everything ended up working out perfectly, and the players loved all of the new features. They had no idea what went into building them, and certainly had no idea of what went into applying them, or what could have gone wrong -- which is probably a good thing.
Looking back, that entire environment was so fragile, it's a wonder things didn't go horribly wrong all the time. Really, they almost never did. Apocalypses did happen, but were exceedingly rare, and were ususally fixed quickly. I guess we were all super careful simply because everything was so fragile? or the decent devs were, at least. We never trusted the lessers with access 😅 at least on the main servers where it mattered. Some of the smaller servers... well, we never really cared about those.
But I'm honestly more surprised to realize I've never had nightmares of that button click. It was certainly terrifying enough.
But yay! Complete system overhaul and migration of stored and realtime player data! on prod! With no issues! And lots of happy players! Woooooo!
Thinking back on it makes me happy 😊1 -
I worked for over 13 hours yesterday on super-urgent projects. I got so much done it's insane.
Projects:
1) the printer auto-configuration script.
2) changing Stripe from test mode to live mode in production
3) website responsiveness
I finished two within five minutes and pushed to both QA and Production. actually urgent, actually necessary. Easy change.
The printer auto-configure script was honestly fun to write, if very involved. However, the APIs I needed to call to fetch data, create a printer client, etc... none of them were tested, and they were _all_ broken in at least two ways. The CTO (api guy in my previous rant) was slow at fixing them, so getting the APIs working took literally four hours. One of them (test print) still doesn't work.
Responsiveness... this was my first time making a website responsive. Ever. Also, one of the pages I needed to style was very complicated (nested fixed-aspect-ratio + flexbox); I ended up duplicating the markup and hacking the styling together just to make it work. The code is horrible. But! "Friday's the day! it's going live and we're pushing traffic to it!" So, I invested a lot of time and energy into making it ready and as pretty as I could, and finally got it working. That page alone took me two hours.
The site and the printer script (and obv the Stripe change as well) absolutely needed to be done by this morning. Super important.
well.
1) Auto-configure script. Ostensibly we would have an intern come in and configure the printers. However, we have no printers that need configuring, so she did marketing instead. :/ Also, the docs Epson sent us only work for the T88V printer (we have exactly one, which we happened to set up and connect to). They do not work for the T88VI printers, which is what we ordered. and all we'll ever be ordering. So. :/ I'll need to rewrite a large chunk of my code to make this work. Joy :/
2) Stripe Live mode. Nobody even seemed to notice that we were collecting info in Test mode, or that I fixed it. so. um. :/
3) Responsiveness.
Well. That deadline is actually next Wednesday. The marketing won't even start until then, and I haven't even been given the final changes yet (like come on). Also! I asked for a QA review last night before I'd push it to production. One person glanced at it. Nobody else cared. Nobody else cared enough to look in the morning, either, so it's still on QA. Super-important deadline indeed. :/
Honestly?
I feel like Alice (from Dilbert) after she worked frantically on urgent projects that ended up just being cancelled. (That one where Wally smells that lovely buttery-popcorn scent of unnecessary work.)
I worked 13 hours yesterday.
for nothing.
fucking. hell.7 -
Alright, so my previous rant got a way better response than I expected! (https://devrant.io/rants/832897)
Hereby the first project that I cannot seem to get started on too badly :/.
DISCLAIMER: I AM NOT PROMOTING PIRACY, I JUST CAN'T FIND A SUITABLE SERVICE WHICH HAS ALL THE MUSIC I WANT. I REGULARLY BUY ALBUMS. before everyone starts to go batshit crazy regarding piracy, this is legal in The Netherlands for personal use. I think that supporting the artists you love is very good and I actually regularly pay for albums and so on but:
- I want all the music from about every artist in my scene. Either on Deezer or on Spotify this is not available and I'm not gonna get them both (they both have about half of the music I want). Their services are awesome but I'm not going to pay for something if I can't listen to all the music I like, hell even some artists (on deezer mostly) only have half their music on there and it's mostly not better on Spotify.
- I'd happily buy all albums because I love supporting the artists I love but buying everything is just way too fucking much."Get a premium music streaming subscription!" - see the first point.
You can either agree or disagree with me but that's not what this rant is about so here we go:
The idea is to create a commandline program (basically only needs to be called by a cron job every day or so) which will check your favourite youtube (sorry, haven't found a suitable non-google youtube replacement yet) channels every day through a cronjob and look for new uploads. If there are, it will download them, convert them to MP3 or whatever music format you'd like and place them in the right folder. Example with a favourite artist of mine:
1. Script checks if there are any new uploads from Gearbox Digital (underground raw hardstyle label).
2. Script detects two new uploads.
3. Script downloads the files (I managed to get that done through the (linux only or also mac?) youtube-dl software) and converts them to mp3 in my case (through FFMPEG maybe?).
4. Script copies them to the music library folder but then the specific sub-folder for Gearbox Digital in this case.
You should be able to put as many channels in there as you want, I've tried this with the official YouTube Data API which worked pretty fine tbh (the data gathering through that API). The ideal case would be to work without API as youtube-dl and youtube-dlg do. This is just too complicated for me :).
So, thoughts?43 -
I'm a DevOps engineer. It's my job to understand why this type of shit is broken, and when I finally figure it out, I get so mad at bullish players like AWS.
It's simple. Install Python3 from apt.
`apt-get update && apt-get install -y python3-dev`
I've done this thousands of times, and it just works.
Docker? Yup.
AWS AMI? Yup.
Automation? Nope.
WTF? Let's waste 2.5 hours and figure out why this morning.
In docker: `apt-cache policy python3-dev` shows us:
python3-dev:
http://archive.ubuntu.com/ubuntu focal/main amd64 Packages
But in AWS instance, we see we're reading from "http://us-east-1.ec2.archive.ubuntu.com/... focal/main" instead!
Ah, but why does it fail? AWS is just using a mirror, right? Not quite.
When the automation script is running, it's beating AWS to the apt mirror update! My instance, running on AWS is trying to access the same archive.ubuntu.com that the Docker container tried to use. "python3-dev" was not a candidate for installation! WTF Amazon? Shouldn't that just work, even if I'm not using your mirror?
So I try again, and again, and again. It works, on average, 1 out of every 5 times. I'm assuming this means we're seeing some strange shit configuration between EC2 racks where some are configured to redirect archive.ubuntu.com to the ec2 mirror, and others are configured to block. I haven't dug this far into the issue yet, because by the time I can SSH into the machine after automation, the apt list has already received it's blessed update from EC2.
Now I have to build a graceful delay into my automation while I wait for AWS to mangle, I mean "fix up" my apt sources list to their whim.
After completely blowing my allotted time on this task, I just shipped a "sleep" statement in my code. I feel so dirty. I'm going to go brew some more coffee to be okay with my life. Then figure out a proper wait statement.7 -
So I setup a nice csv file for the customer to fill in the shop items for their webshop, you know? with a nice layout like
name - language - description etc.
(just temporary, because the legacy website is going under a ((sadly frontend only)) rework, so it now also has to display different 'kind' of products... and because the new cms isn't done yet they
have to provide the data with other means)
my thoughts were to create a little import script to write the file into the database.... keep in mind of the relations... etc...
guess what? TWO MONTHS later, I get a file with a custom layout, empty cells, sometimes with actual data, sometimes (in red / green text color) notes for me
I mean WHY.... WHY DO YOU MAKE MY LIVE HARDER???
So now I have to put data in 6 columns and 411 rows in the database BY HAND...
oh and did I mention they also have relations? yeah... I also have to do that by hand now...3 -
I'm going on vacation next week, and all I need to do before then is finish up my three tickets. Two of them are done save a code review comment that amounts to combining two migrations -- 30 seconds of work. The other amounts to some research, then including some new images and passing it off to QA.
I finish the migrations, and run the fast migration script -- should take 10 minutes. I come back half an hour later, and it's sitting there, frozen. Whatever; I'll kill it and start it again. Failure: database doesn't exist. whatever, `mysql` `create database misery;` rerun. Frozen. FINE. I'll do the proper, longer script. Recreate the db, run the script.... STILL GODDAMN FREEZING.
WHATEVER.
Research time.
I switch branches, follow the code, and look for any reference to the images, asset directory, anything. There are none. I analyze the data we're sending to the third party (Apple); no references there either, yet they appear on-device. I scour the code for references for hours; none except for one ref in google-specific code. I grep every file in the entire codebase for any reference (another half hour) and find only that one ref. I give up. It works, somehow, and the how doesn't matter. I can just replace the images and all should be well. If it isn't, it will be super obvious during QA.
So... I'll just bug product for the new images, add them, and push. No need to run specs if all that's changed is some assets. I ask the lead product goon, and .... Slack shits the bed. The outage lasts for two hours and change.
Meanwhile, I'm still trying to run db migrations. shit keeps hanging.
Slack eventually comes back, and ... Mr. Product is long gone. fine, it's late, and I can't blame him for leaving for the night. I'll just do it tomorrow.
I make a drink. and another.
hard horchata is amazing. Sheelin white chocolate is amazing. Rum and Kahlua and milk is kind of amazing too. I'm on an alcoholic milk kick; sue me.
I randomly decide to switch branches and start the migration script again, because why not? I'm not doing anything else anyway. and while I'm at it, I randomly Slack again.
Hey, Product dude messaged me. He's totally confused as to what i want, and says "All I created was {exact thing i fucking asked for}". sfjaskfj. He asks for the current images so he can "noodle" on it and ofc realize that they're the same fucking things, and that all he needs to provide is the new "hero" banner. Just like I asked him for. whatever. I comply and send him the archive. he's offline for the night, and won't have the images "compiled" until tomorrow anyway. Back to drinking.
But before then, what about that migration I started? I check on it. it's fucking frozen. Because of course it fucking is.
I HAD FIFTEEN MINUTES OF FUCKING WORK TODAY, AND I WOULD BE DONE FOR NEARLY THREE FUCKING WEEKS.
UGH!6 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!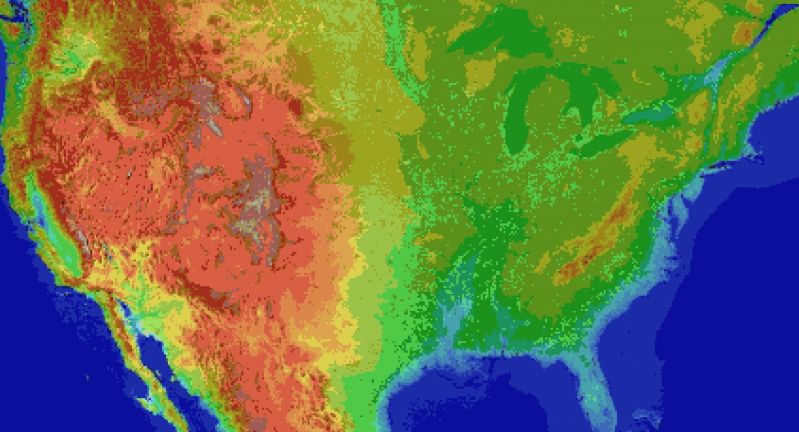 5
5 -
!dev #SocialIsolationIsBad #I'm_waiting_for_this_script_to_finish
I'm the one who intentionally creeps out everyone who like her, and then sits on the toilet shedding internal tears of self-pity that "nobody likes me" and then does the comfort talk of "I'm a strong independent moldy potato and need nobody".
Anyways, came full circle now can somebody hand me more toilet papers, please? 🚽10 -
I am so fucking lost.
I literally have zero expectations from life for now and future.
There was a time when I had so much clarity in my life. Rather, I was known for it.
Folks used to reach me out for guidance and my approaches even worked for others.
I was goal oriented and biased towards action. Failing and learning from it, I used to make things happen and with constant feedback kept progressing.
While none of that has changed, I still feel lost and numb. No, I am not depressed or suffering through any mental illness. I am physical active and able to feel the happiness.
But the recent incident with a narcissistic, left me emotionally handicap. I can no longer feel any kind of love or affection. I overcame the damage done and healed myself.
But now, I am done. Even if I engage with anyone for a relationship it would be mostly for sex. I can care for people around me and be affectionate towards them but when it comes to an intimate relationship, I feel it's not something I can do in this lifetime. I tried multiple times but failed.
These days, all I am doing is putting my heads down and working like crazy. Never in my life I worked more than 10 hours in an entire week. Now, I work 10+ hours everyday. During that time, I am highly productive.
And in my free time, I am busy housekeeping different life problems. Either paying bills, figuring out an insurance, planning some investment, or making some kind of life decision.
It's draining me. I feel as if I am losing sanity. But that's the only thing I am able to do.
Maybe it's the lockdown effect. Maybe some damage is yet to be healed.
But I got nothing better to do. I have some good ideas. Not those hipster-ish disruptive Million dollar ideas, but decent enough to solve a problem for a strong use case.
However, all of this is becoming overwhelming these days. Because decision making is complex and difficult task. It can make or break the future.
As of now I am confused how should I go about pursuing two of the important projects that I want to accomplish.
1. Migrating out of Google ecosystem. Is it even practically possible for my use case? What are the alternatives? Planning to opt in for a paid cloud storage so have to factor in that aspect as well.
I want to keep this new setup only for official use like bank and government stuff. Maybe family and close friends. Then have current ids for public logins and sharing it with retards whom I can block or ignore if they harass me. The research is overwhelming but having a structured setup gives insane amount of efficiency when life is spam free.
2. Migrating my Pihole and OpenVPN setup out of Digital Ocean to GCP. Primarily because $5 is a lot of amount for my computational requirements and Google has used my data enough, for me to use the free tier.
However, there isn't a simple script for a tech noob like me, to go ahead and setup something. I did find a Github repository but the documentation is kind of outdated so RTFM failed for me.
I don't know whether to pursue my start-up or let it go and focus on moving to Europe.
It's just so fucking stupid to even exist. And let's not forget taxes. Bloody taxes.21 -
Last Week Friday:
PM: We'll be taking you off the one project on to another, we'll send the details later.
Me: Cool
*Hours Later*
PM: Ok cool, so you'll be looking at a script that one of our Pillar heads has scripted. You need to make sure it works and that it can run on the server.
Me: *I always thought this guy was useless now i get to see what he can do* Cool, just send the documentation and i'll take a look at it over the weekend. Just tell me when you've sent it.
PM: Cool.
Project Head: I'll inform you when i send the files and how to run them.
Me: *I know how to set up a database locally, i'm not an idiot* Cool.
Whole Weekend I don't get a single message.
Monday Morning:
Project Head(PH): Have you taken a look at it yet?
Me: Taken a look at what?
PH: The Database and the Script
Me: i didn't get any message over the weekend.
PH: I sent it yesterday, it should be in your inbox.
Me: There's Nothing. Sending anything on a Sunday is expecting me not to see it, especially at 10pm. Besides i can't retrieve any of the files in the attachment(Outlook tripping), rather send it in a zip file or upload it to onedrive.
PH sends the link. I get the files, set up the DB, glance at the script.
Me: This is actually interesting.
PH: You know what it does?
Me: My SQL knowledge is below average but i can read and understand it pretty well. So your dynamically copying the database from the server to the warehouse, cool.
It's not going to work though.
PH: Check first.
I check it
Me: Doesn't work, but it sort of works.
PH: What do you mean?
Me: Some tables are populated but some aren't,, how and there's a shit tone of errors.
PH: So i does copy the data over.
Me: Some of the data.
PH: test it on the Server
Me: Not a good idea.
PH: Just try it.
PM: In the mean time i'll send you some documentation i need you to review and edit.
Me: *Idiots* Cool.
Tuesday:
Me: Have you checked it on the server yet?
PH: Not yet, busy.
Me: Where's the documentation again?
PM: I'll send it it a moment.
Me: In the mean time i'll write some script to fix that script that's definitely not going to work.
Wednesday:
Boss: I heard you done with the script
Me: It's not done, but we'll be testing it on the server later.
Boss: Then why are you running it on the server?
Me: Ask the PH and PM.
Boss: What are you doing now?
Me: Well i'm supposed to do documentation *looks at PM* but i haven't recieved any yet, so I've been writing a script to fix the copy script.
PH: Ok we'll test when the boss leaves, after all the meetings.
PM: here's the documentation.
Me: Thanks
I start on documentation.
PH: It didn't work.
Me: I know.
PH: Fix it.
Thursday:
Meeting.
PM: What you doing?
Me: Fixing the script,
PM: Do the documentation first
Me: Cool.
End of the day:
PH: Why you doing the documentation? The script has highest priority.
Me: Ask the PM.
Friday(Today):
Boss: can we talk.
Me: Sure.
Boss: I though you said the script was done?
Me: i said it sort of works, just doesn't do the job 100%.
Boss: Monday i was told it's done.
Me: i only looked through it Monday to understand it, i done nothing before Tuesday. though i have been trying to create a script to fix it.
Boss: Your working really slow hey.
Me: *It's been a week, and stupid people are in charge* I was doing what i was told.
Boss: Cool.(His Upset)
Stupid FUCKEN people, make stupid FUCKEN decisions. But Hey, the boss only see's the final result. I am a human being, even i make mistakes. But there's a huge gap between stupidity and a mistake. -
its day 4 of updating documentation and consolidating data.
The webclient has broken on average 4 times a day.
The database took 20+ seconds on updating a password entry.
I explained to my boss the real cost of interrupting my attention with these pauses. I figure it's caused my productivity to go from record high last week to being literally losing about 4 hours a day lost, plus extra time in having to go back through and verify things worked.
The technicians and developers who are working on fixing the database system are apparently quitting left right and center; their company acquired it awhile back, so they don't actually have native developers on it. Yet they still are pushing out new integration features rather than fixing anything.
Yesterday, one of the other people on the documentation project lost half a days work due to the angular updating the local cache, but it never reaching the backend. He came back from lunch, reopened his browser, and all his work was gone. (at least thats what we think happened). So we are hard resetting the program every 10 minutes or so just to make sure it is updating the backend.
The good news is that when it is done, we theoretically will be able to use this to cut back onboarding time and update times by about half, and it'll mean our new nano-server deployment project should be able to spin out with standards that can be referenced properly by everyone, not just the guy with the powershell script that he tinkered with for a particular project and never told anyone else what he did.
Theoretically. -
So I'm trying out docker and see how I can make use of it, current setup:
1. Ubuntu on VM and Mac for Asp.Net core development
2. Windiws for MS only stuff like SQL Server
3. Ubuntu Server on VM and is running docker images: MS image for SQL and Ms image for dinner core.
What I did so far one script which will handle updating SQL Server database on windows with the changes done on docker SQL image
Then publish website from Mac or Ubuntu to docker image. I have yet to find a way to execute scripts remotely on a docker image using bash script from a remote
What should I do next? And for home setup go for Ubuntu server or CentOS? Any recommended packages for server administration? Workflow ..etc.? 2
2 -
So, i'm trying to get linkr (a pretty cool short link service) to work in a docker container since 4 hours now to host it on my server. There is no official container because it needs a working database connection and stuff during installation which can only be done via console and (for whatever reason I couldn't find out yet) need to be done while building the container. The problem is, I can't connect it to the database while building the container so there is no database during installation to create tables and stuff and the build will fail. ARGH.
Why the hell would you do this????? Theyre actually saying in their readme there is no dockerfile because the config options are specific to your configuration...?!?!
The thing is entirely written in python, so reading and parsing configfiles on the fly should not really be a problem.
Of course I could ssh into the container and run the installation script but that's not the point.
Docker is not about being lazy.
It's about portability.
Maybe I don't want to bloat my server with your 39579372639 npm dependencies? Or I don't want to install a freakin apache, because I have every other site on nginx and therefore wouldn't work with apache.
AAAAAAAARRRRRRGGHHGGGGG
in the end, I'm probably going to modify the thing to install tables when running the container and giving the first user admin rights instead of prompting to enter credentials for a new admin user.
And yet I didn't even speak python. -
I know a lot of people aren't fans of Microsoft here, but does anyone have some extended experience with using powershell?
I've been using it for creating a script that handles quite a large set of tasks for setting up and configuring some application servers and so far I have been really digging the language. Being able to invoke the script against remote hosts in parallel like ansible has been a really cool learning experience.
Admittedly it's verbose as fuck, so getting the same thing done in something like python/perl might be like half the lines of code. And I know that some of the commands illicit a "WTF?" every now and again. But I think one of the powershell tutorials I watched early on in attempting this helped make using powershell not suck ass.
Every command is basically 'verb-noun'. You don't know what the command or switches are:
> get-help "command" -showwindow
It will give you a list of options if you didn't select the exact command with get-help.
It feels* amazingly buttoned up as a scripting language and it's really cool to be able to take advantage of lower level stuff, like you can run alternative shells (we have cygwin installed on some of our servers), you can run C# code, you have access to interfacing with .NET api's. I haven't messed with anything azure yet, but being able to interface with products and services like SQL/Exchange/O365/azure/servers/desktops from the same language seems pretty cool.
Admittedly, the learning curve feels terrible though. I felt like a dunce for the first couple weeks, couldn't navigate the language at all, and was always in the docs trying to figure stuff out. I think I just needed to understand how the people developing powershell intended for it to be used. Once I was able to put two-and-two together about the verb-noun structure and how to find information/examples about the cmdlets it's been quite easy to work with it.
If anyone else has any extended experience with it, please share your thoughts/opinions. Curious to see if your experiences are/were similar to mine.
If you don't have Powershell experience, please feel free to share your opinions of Micro$haft and me for using Micro$haft products too! It's all good 😎9 -
I'm creating a bitmap font right now and wanted to automatically generate a image with some text so I can track my progress how it looks. gnome-font-viewer displays it fine, but it'd nothing compared to some real text. Well, how hard can it be?
First attempt: Use ImageMagick to create an image and draw some text. I found a forum post in the ImageMagick forums from 2017 claiming incorrect rendering of BDF fonts, which was promised to be fixed. Yet convert does exactly nothing besides saying “couldn't read font”.
Looking around, there is exactly one tool for the job I'm looking to get done: pbmtext. It works, but doesn't support Unicode. Egh.
Maybe I could write a short script to do it, then? Python's Pillow can import Bitmap fonts (cairo can't). Halfway done I notice it can't deal with anything outside of the character range 0..256.
Using FreeFont directly is out of the question as that seems to be equally much work as creating the font in the first place. I briefly tried SDL, but the font formats it understands are limited.
So how about converting the font then, you ask? Everyone seems to be only concerned about the other way (like OTF to BDF). I tried loading the font into FontForge and exporting an OTF or TTF but couldn't get anything out of it that ImageMagick recognizes as a font.
It seems fucking impossible to render text to an image with an Unicode BDF font in some automated way.
To add insult to injury, my searches containing “bdf” are always interpreted as with “pdf”. I'm not even a Franconian, I can distinguish B and P!4














Top Tags
Weekly Rant
View