
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
!rant
This was over a year ago now, but my first PR at my current job was +6,249/-1,545,334 loc. Here is how that happened... When I joined the company and saw the code I was supposed to work on I kind of freaked out. The project was set up in the most ass-backward way with some sort of bootstrap boilerplate sample app thing with its own build process inside a subfolder of the main angular project. The angular app used all the CSS, fonts, icons, etc. from the boilerplate app and referenced the assets directly. If you needed to make changes to the CSS, fonts, icons, etc you would need to cd into the boilerplate app directory, make the changes, run a Gulp build that compiled things there, then cd back to the main directory and run Grunt build (thats right, both grunt and gulp) that then built the angular app and referenced the compiled assets inside the boilerplate directory. One simple CSS change would take 2 minutes to test at minimum.
I told them I needed at least a week to overhaul the app before I felt like I could do any real work. Here were the horrors I found along the way.
- All compiled (unminified) assets (both CSS and JS) were committed to git, including vendor code such as jQuery and Bootstrap.
- All bower components were committed to git (ALL their source code, documentation, etc, not just the one dist/minified JS file we referenced).
- The Grunt build was set up by someone who had no idea what they were doing. Every SINGLE file or dependency that needed to be copied to the build folder was listed one by one in a HUGE config.json file instead of using pattern matching like `assets/images/*`.
- All the example code from the boilerplate and multiple jQuery spaghetti sample apps from the boilerplate were committed to git, as well as ALL the documentation too. There was literally a `git clone` of the boilerplate repo inside a folder in the app.
- There were two separate copies of Bootstrap 3 being compiled from source. One inside the boilerplate folder and one at the angular app level. They were both included on the page, so literally every single CSS rule was overridden by the second copy of bootstrap. Oh, and because bootstrap source was included and commited and built from source, the actual bootstrap source files had been edited by developers to change styles (instead of overriding them) so there was no replacing it with an OOTB minified version.
- It is an angular app but there were multiple jQuery libraries included and relied upon and used for actual in-app functionality behavior. And, beyond that, even though angular includes many native ways to do XHR requests (using $resource or $http), there were numerous places in the app where there were `XMLHttpRequest`s intermixed with angular code.
- There was no live reloading for local development, meaning if I wanted to make one CSS change I had to stop my server, run a build, start again (about 2 minutes total). They seemed to think this was fine.
- All this monstrosity was handled by a single massive Gruntfile that was over 2000loc. When all my hacking and slashing was done, I reduced this to ~140loc.
- There were developer's (I use that term loosely) *PERSONAL AWS ACCESS KEYS* hardcoded into the source code (remember, this is a web end app, so this was in every user's browser) in order to do file uploads. Of course when I checked in AWS, those keys had full admin access to absolutely everything in AWS.
- The entire unminified AWS Javascript SDK was included on the page and not used or referenced (~1.5mb)
- There was no error handling or reporting. An API error would just result in nothing happening on the front end, so the user would usually just click and click again, re-triggering the same error. There was also no error reporting software installed (NewRelic, Rollbar, etc) so we had no idea when our users encountered errors on the front end. The previous developers would literally guide users who were experiencing issues through opening their console in dev tools and have them screenshot the error and send it to them.
- I could go on and on...
This is why you hire a real front-end engineer to build your web app instead of the cheapest contractors you can find from Ukraine. 19
19 -
An intern I was supposed to lead (as an intern) and work with. Which sounded kinda crazy to me, but also fun so I rolled with it. But when I met her I quickly found out she didn't even have a coding editor installed and when I advised one she was "scared of virusses". She had Microsoft Edge in her toolbar, and some picture of a cat as a background. We were given some project by our boss, and a freelance programmer helped us set it up on Trello. Great, lets start! Oke maybe first some R&D, she had to reaeach how to use the Twilio API. After catching her on WhatsApp a few times I realised this wasnt gonna go anywere. After a few weeks of coding and posting a initial project to git I asked her if she could show me the code of the API she made so far..
She told me she was using the quickstart guide (the last 3 FUCKING weeks) which contained some test project with specific use cases.
The one that I did 3 weeks ago that same fucking morning.
AND SHE WAS STILL NOT DONE...
A few days later I asked her about the progress (strangly, I wasn't allowed ti give her another task bcs the freelanc already did) and guess what... She got fking pissed at me
Her: "I will come to you when im done, ok?"
Me: "I just want to see how it is going so far and if you are running into any problems!"
Her: "I dont want to show you right now"
She then goes to my fucking boss to tell him I am bothering her.
And omg... Please dear god please kill me now...
Instead of him saying the she probably didn't do shit. He says to me that the girl thinks im looking down on her and she needs a stress free environment to work in. She will show me when its done. ITS A FUCKING QUICKSTART GUIDE YOU DUMB BITCH.
He then procceeded to whine to me about the email template (another project I do at the same time) which didn't look perfect in all of his clients.
Dont they understand that I am not a frontend developer? Can you stop please? I know nothing about email templates, I told you this!!!
Really... the whole fucking internship the only thing the girl did was ask people if they want more tea. Then she starts cleaning the windows, talk to people for an hour, or clean everyone's dask.
all this while I already made 50% of the fucking product and she just finished the quickstart tutorial 😭. Truly 2 months wasted, and the worse thing is I didn't get any apprication. They constantly blamed me and whined at me. Sometimes for being 3 minutes late, the other for smoking too much, or because I drink to much coffee, or that I dont eat healthy. They even forced me to play Ping Pong. While im just trying to do my job. One of the worst things they got mad at me for if when my laptop got hacked bcs it was infected with some virus. He had remote access and bought 5 iPhones 6's with my paypal while I was on break. I had to go home and quickly reset all my passwords and make sure the iPhones wouldnt get delivered. strange this was, this laptop I only used at the company. So it must have been software I had to download there. Probably phpstorm (torrent). Bcs nobody would give me a license. And the freelancer said I * have to *.
the monday after I still had to reinstall windows so I called them and said I would be late. when I came they were so disrepectfull and didn't understand anything. It went a little like this:
Boss: why u late?
Me: had to reinstall my laptop, sorry.
Boss: why didnt you do this in your own time?
Me: well, I didn't have any time.
Boss: cant you do this in the weekend or something? Because now we have to pay you several hours bcs you downloaded something at home.
Me: I am only using this laptop for work so thats not possible.
Boss: how can that even be possible? You are not doing anything at home with your laptop? Is that why you never do anything at home?
Me: uhm, I have desktop computer you know. Its much faster. And I also need to rest sometimes. Areeb (freelancer) told me to torrent the software. He gave me the link. 2 days later this happends
Boss: Ahh okeee I see.. Well dont let it happen again.
After that nobody at the compamy trusted me with anything computer related. Yes it was my own fault I downloaded a virus but it can happen to anyone. After that I never used Windows again btw, also no more auto login apps.8 -
I’m surrounded by idiots.
I’m continually reminded of that fact, but today I found something that really drives that point home.
Gather ‘round, everybody, it’s story time!
While working on a slow query ticket, I perused the code, finding several causes, and decided to run git blame on the files to see what dummy authored the mental diarrhea currently befouling my screen. As it turns out, the entire feature was written by mister legendary Apple golden boy “Finder’s Keeper” dev himself.
To give you the full scope of this mess, let me start at the frontend and work my way backward.
He wrote a javascript method that tracks whatever row was/is under the mouse in a table and dynamically removes/adds a “.row_selected” class on it. At least the js uses events (jQuery…) instead of a `setTimeout()` so it could be worse. But still, has he never heard of :hover? The function literally does nothing else, and the `selectedRow` var he stores the element reference in isn’t used elsewhere.
This function allows the user to better see the rows in the API Calls table, for which there is a also search feature — the very thing I’m tasked with fixing.
It’s worth noting that above the search feature are two inputs for a date range, with some helpful links like “last week” and “last month” … and “All”. It’s also worth noting that this table is for displaying search results of all the API requests and their responses for a given merchant… this table is enormous.
This search field for this table queries the backend on every character the user types. There’s no debouncing, no submit event, etc., so it triggers on every keystroke. The actual request runs through a layer of abstraction to parse out and log the user-entered date range, figure out where the request came from, and to map out some column names or add additional ones. It also does some hard to follow (and amazingly not injectable) orm condition building. It’s a mess of functional ugly.
The important columns in the table this query ultimately searches are not indexed, despite it only looking for “create_order” records — the largest of twenty-some types in the table. It also uses partial text matching (again: on. every. single. keystroke.) across two varchar(255)s that only ever hold <16 chars — and of which users only ever care about one at a time. After all of this, it filters the results based on some uncommented regexes, and worst of all: instead of fetching only one page’s worth of results like you’d expect, it fetches all of them at once and then discards what isn’t included by the paginator. So not only is this a guaranteed full table scan with partial text matching for every query (over millions to hundreds of millions of records), it’s that same full table scan for every single keystroke while the user types, and all but 25 records (user-selectable) get discarded — and then requeried when the user looks at the next page of results.
What the bloody fucking hell? I’d swear this idiot is an intern, but his code does (amazingly) actually work.
No wonder this search field nearly crashed one of the servers when someone actually tried using it.
Asdfajsdfk.21 -
I wrote a node + vue web app that consumes bing api and lets you block specific hosts with a click, and I have some thoughts I need to post somewhere.
My main motivation for this it is that the search results I've been getting with the big search engines are lacking a lot of quality. The SEO situation right now is very complex but the bottom line is that there is a lot of white hat SEO abuse.
Commercial companies are fucking up the internet very hard. Search results have become way too profit oriented thus unneutral. Personal blogs are becoming very rare. Information is losing quality and sites are losing identity. The internet is consollidating.
So, I decided to write something to help me give this situation the middle finger.
I wrote this because I consider the ability to block specific sites a basic universal right. If you were ripped off by a website or you just don't like it, then you should be able to block said site from your search results. It's not rocket science.
Google used to have this feature integrated but they removed it in 2013. They also had an extension that did this client side, but they removed it in 2018 too. We're years past the time where Google forgot their "Don't be evil" motto.
AFAIK, the only search engine on earth that lets you block sites is millionshort.com, but if you block too many sites, the performance degrades. And the company that runs it is a for profit too.
There is a third party extension that blocks sites called uBlacklist. The problem is that it only works on google. I wrote my app so as to escape google's tracking clutches, ads and their annoying products showing up in between my results.
But aside uBlacklist does the same thing as my app, including the limitation that this isn't an actual search engine, it's just filtering search results after they are generated.
This is far from ideal because filter results before the results are generated would be much more preferred.
But developing a search engine is prohibitively expensive to both index and rank pages for a single person. Which is sad, but can't do much about it.
I'm also thinking of implementing the ability promote certain sites, the opposite to blocking, so these promoted sites would get more priority within the results.
I guess I would have to move the promoted sites between all pages I fetched to the first page/s, but client side.
But this is suboptimal compared to having actual access to the rank algorithm, where you could promote sites in a smarter way, but again, I can't build a search engine by myself.
I'm using mongo to cache the results, so with a click of a button I can retrieve the results of a previous query without hitting bing. So far a couple of queries don't seem to bring much performance or space issues.
On using bing: bing is basically the only realiable API option I could find that was hobby cost worthy. Most microsoft products are usually my last choice.
Bing is giving me a 7 day free trial of their search API until I register a CC. They offer a free tier, but I'm not sure if that's only for these 7 days. Otherwise, I'm gonna need to pay like 5$.
Paying or not, having to use a CC to use this software I wrote sucks balls.
So far the usage of this app has resulted in me becoming more critical of sites and finding sites of better quality. I think overall it helps me to become a better programmer, all the while having better protection of my privacy.
One not upside is that I'm the only one curating myself, whereas I could benefit from other people that I trust own block/promote lists.
I will git push it somewhere at some point, but it does require some more work:
I would want to add a docker-compose script to make it easy to start, and I didn't write any tests unfortunately (I did use eslint for both apps, though).
The performance is not excellent (the app has not experienced blocks so far, but it does make the coolers spin after a bit) because the algorithms I wrote were very POC.
But it took me some time to write it, and I need to catch some breath.
There are other more open efforts that seem to be more ethical, but they are usually hard to use or just incomplete.
commoncrawl.org is a free index of the web. one problem I found is that it doesn't seem to index everything (for example, it doesn't seem to index the blog of a friend I know that has been writing for years and is indexed by google).
it also requires knowledge on reading warc files, which will surely require some time investment to learn.
it also seems kinda slow for responses,
it is also generated only once a month, and I would still have little idea on how to implement a pagerank algorithm, let alone code it.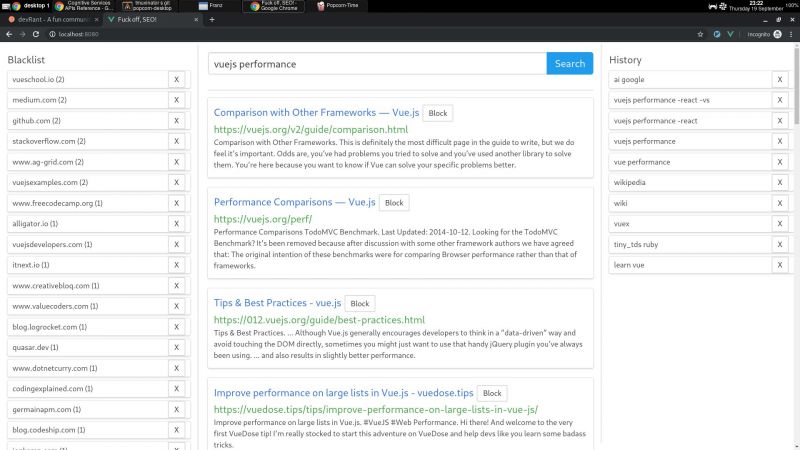 4
4





Top Tags
Weekly Rant
View