

Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More





 No questions asked
No questions asked As a Python user and the fucking unicode mess, this is sooooo mean!
As a Python user and the fucking unicode mess, this is sooooo mean!
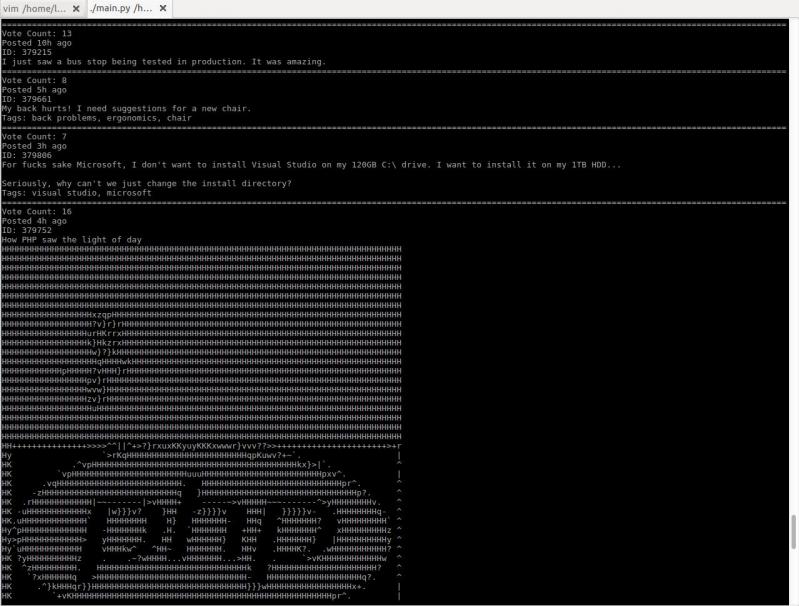 I just started working on a little project to browse devrant from terminal. It converts images to ascii art!
I just started working on a little project to browse devrant from terminal. It converts images to ascii art!
Hi, I am using a Wikipedia scrapper in one of my Open Source project. The data extracted from it is the stored in Elasticsearch... Now I have decided to create library out of it so that other people can use it too... My question is should also include the Elasticsearch storing module in library or just add the scrapper... Please let me know your thoughts.
rant
wikipedia
python
scraper