

Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More


Related Rants

 HAHAHA.
HAHAHA.
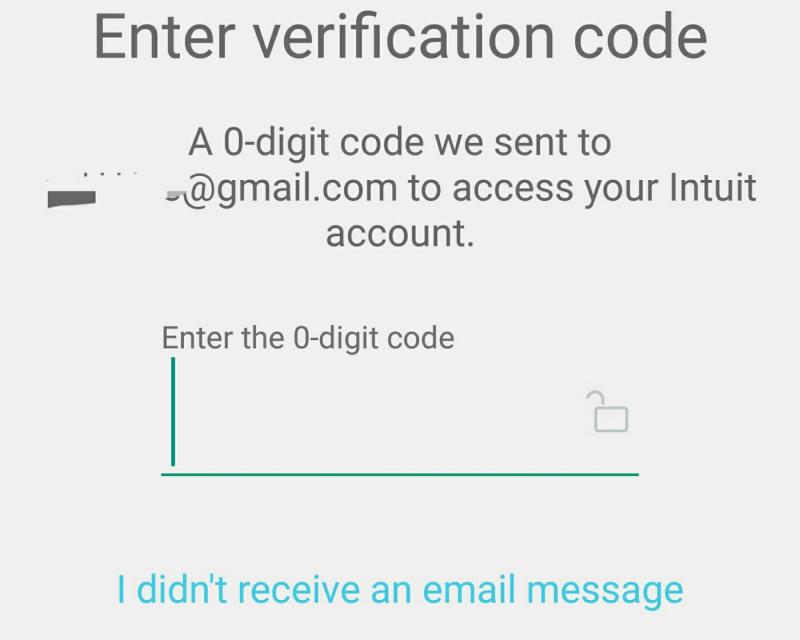 I'm not sure how I'm supposed to proceed from here.
I'm not sure how I'm supposed to proceed from here.
Auto-healing deployments are great until your deployment fails because it can't handle sending a large number of push notifications (triggered by a message on a pub/sub topic that starts being read from on startup)...so restarts, tries to send them again, fails, restarts, etc...and meanwhile a few tens of thousands of users are getting spammed by notifications 😱
rant
push notifications
woops
kubernetes
auto-healing