

Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More

 Machine Learning messed up!
Machine Learning messed up!
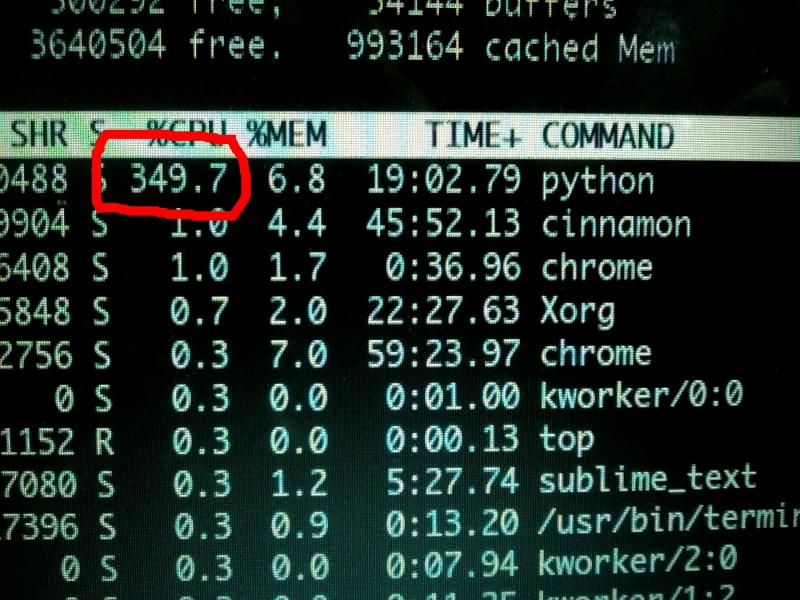 When your CPU is motivated and gives more than his 100%
When your CPU is motivated and gives more than his 100%
 What is machine learning?
What is machine learning?
Next personal fail ...
previous rant
https://devrant.com/rants/2060249/...
Turned out that wavenet is sequential so it needs previous step to predict next.
Quite obvious when you look at how people speak sentences, they hardly stop in the middle of the word.
🤔
need to think how to proceed next, how to cut sentences.
Watched deepvoice3 and some accent models from baidu.
I can generate 8 sentences at a time, each takes 8 minutes so if I cut between words and got last mels between words right I can get 1 minute but I need to store model somewhere.
I forgot my machine learning and speech synthesis skills from previous life, time to load more skills ...
rant
matrix
text to speech
machine learning
developers life