
Ranter

Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
Comments
-
@irene it was a more specific debate where qneko claimed that std::copy was faster than memcpy and he said that it was because memcpy was implemented in assembler
-
@irene since copy is templated, it can take pointers - which are pointers to buffers
-
@ganjaman Some people think that its as fast as it gets ;-)
*not going to mention any names* -
@irene yes, thats why it works with std::copy. I dont see the difference to buffers, though
-
@irene i don't see how you would copy a chunk of memory in bulk without iterating
-
This is not idiomatic C++, the malloc alone tells this. I wouldn't be astonished if this leads to a bytewise copy, which would then take 4 times as long as needed, which would be 21 seconds.
Remember that with all that overloaded shit, you can never be quite sure what is actually behind. -
@Fast-Nop idiomatic C++ won't make stuff that much better
since I use the variable type int, it should do a dword by dword copy.
malloc and new do virtually the same thing (in some implementations, new will even call malloc, so that just adds overhead) so shrug. Making me create a std::array <a, size> won't really make stuff better, since I still have the same buffer to copy -
@BinaryByter but you aren't using variable type int, you are handing over raw pointers and on low optimisation level. Just give it a try with array and new whether that changes things.
Btw, performance benchmarks on O1 don't really mean anything, and the compiler is still faster on O2 because it's able to optimise the whole loop away. -
@Fast-Nop the type int should change the size of the r/w since by definition, pointer arithmetic is different on int* than on void*
-
@BinaryByter yeah it should, but not necessarily with optimisations more or less disabled.
I mean, 84s / 4 = 21s, which is very close to 19s. That's hardly by accident. -
@Fast-Nop btw: i got it to compile with -03 without overoptimization. I also noticed, that my asm code did copy by DWORD, so I changed that too.
Now we are looking at a result of
19s vs 1.9s -
@BinaryByter so now std::copy seems to work at 32 bit, same as the previous assembly version?
What is the width that you are now copying with in assembly? -
@BinaryByter For type int, the address is not guaranteed to be 64 bit aligned, so that's not a 1:1 comparison.
What if you change the type in the C++ code to int64_t? -
@Fast-Nop i'm too lazy to go back to the code - but int is compiled to 64bit on clang on my machine on my os
-
@BinaryByter sizeof(int)==8? Now that's exotic, which OS is that?
AFAIK, Windows (LLP64), Linux and macOS (both LP64) use 32 bit for int even on 64 bit machines. -
c++ and asm devs: *fight over speed and usability*
everybody else here: *sips coffee in confusion*





Related Rants

 No doubt 😂
No doubt 😂
 OMG, security breach on devRant!!!
My password is shown in clear text near my avatar.
OMG, security breach on devRant!!!
My password is shown in clear text near my avatar.
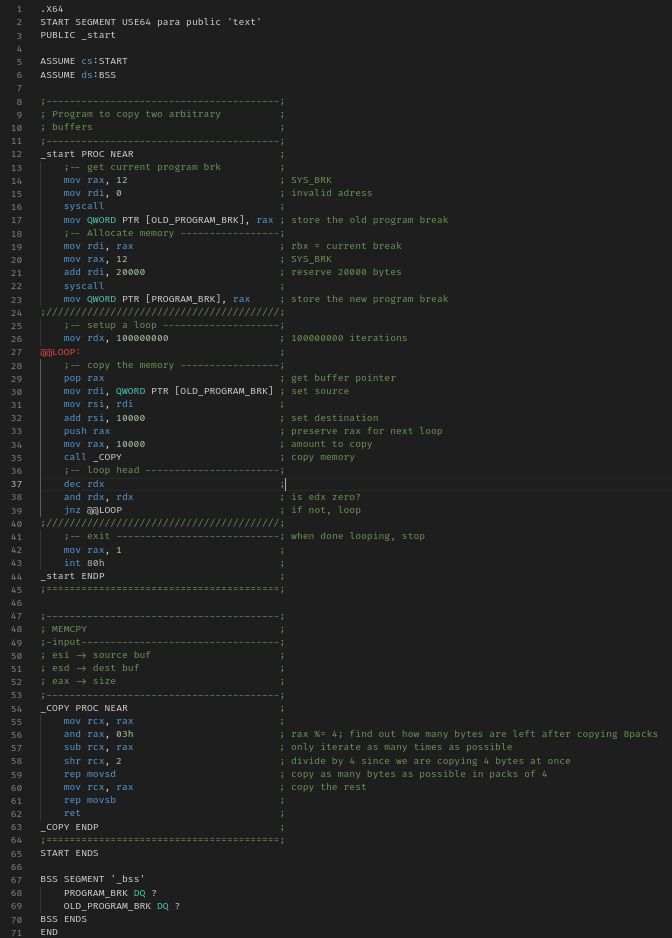
Here is another rather big example of how C++ is WAY slower than assembler (picture)
Sure - std::copy is convenient
but asm is just way faster.
This code should be compatible with EVERY x86_64 CPU.
I even do duffs device without having the loop:
the loop happens in the rep opcode which allows for prefetching (meaning that it doesnt destroy the prefetch queue and can even allow for preprocessing).
BTW: for those who commented on my comment porn last time: I made sure to satisfy your cravings ;-)
To those who can't make sense of my command line:
C++ 1m24s
ASM 19s
To those who tell me to call clang with -o<something>:
1) clang removes the call to copy on o3 or o2
2) the result isnt better in o1 (well... one second but that might be due to so many other things, and even if... one second isn't that much)
rant
c++ vs asm
comment porn
1337