

Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More


 No questions asked
No questions asked As a Python user and the fucking unicode mess, this is sooooo mean!
As a Python user and the fucking unicode mess, this is sooooo mean!
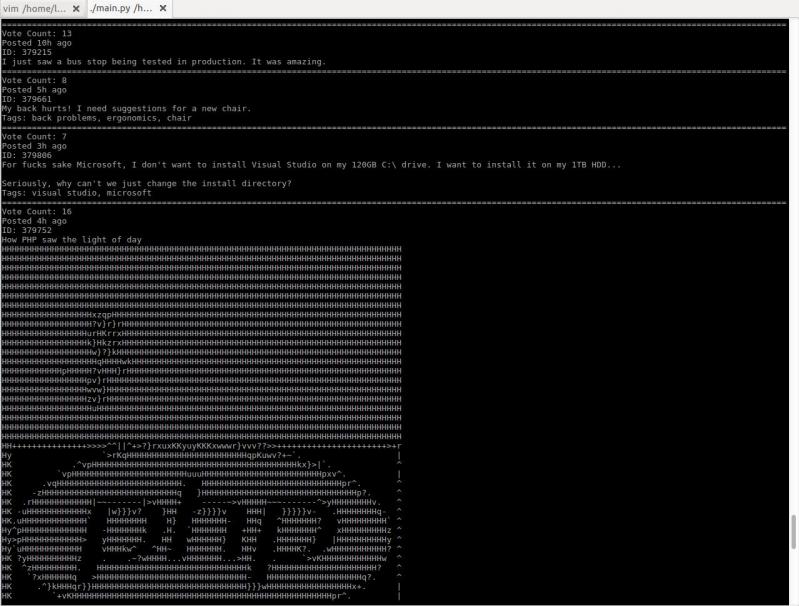 I just started working on a little project to browse devrant from terminal. It converts images to ascii art!
I just started working on a little project to browse devrant from terminal. It converts images to ascii art!
TLDR;
Side project update.
Made simple nlp library in python and published it’s first version to open source.
Now I can feed it with parsed pdf text.
See rant https://devrant.com/rants/2192388/...
Why ?
Cause during reading book about nltk I couldn’t find simple extendible way to provide support for polish language and I wanted to abstract stemming, word normalization, tokenizer etc. so I can provide ex. different conditions for separate text files and don’t write much code what is an asset when you work solo.
It’s about 12GB of pdf public accessible law data I am trying to handle ( at first ) which is about 35000 files from last 90 years.
So far I automated downloading web pages and pdf documents from them. Extracting data from web pages and saving it to database. Extracting text from pdf files. I have about 5-6 projects to do all of it above maybe at the end I will put it to some workflow manager like Luigi or just run it by cronjob.
First thing for website version 1.0 part is find correlation between all documents inside law text using nlp library by building custom conditions. Then just generate directory structure and html files with links between documents.
Website version 2.0 is already in my mind but it will be creepy to make it and will take at least 1-2 months and I want to publish fast.
I have some pdfs with only images instead of text and tesseract worked quite good with them so maybe I will try to process them when everything go live.
Learned a lot about pdf as now I know that font in pdf is not always providing unicode characters ( stupid form of obfuscation) so when you extract text you need to build glyph vector to text map for every font.
Pdf is full vector representation - just like svg - what is logic if you think a bit and know that some printers are running using postscript.
Let’s hope next update will be about flutter mobile app which started all of shit above. It’s almost ready ( except getting data from api I am trying to do and logo for release version ). It’s last piece of puzzle.
random
developer life
python
side project
nlp
pdf parsing