
Ranter

Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
Comments
-
 hjk10156163yOkay I find that last line a bit extreme. It's quite a handy tool. It's used way too often as a hammer but it has it's uses, also in code.
hjk10156163yOkay I find that last line a bit extreme. It's quite a handy tool. It's used way too often as a hammer but it has it's uses, also in code. -
@hjk101 Well, Math is simple :
If I can't run code in my mind, I can't accept the code.
And regex is almost the only thing I can't imagine in my head just by reading the line.
I know, it's a "me" issue, not regex. -
Regexes can be ridiculous, sure. But if you can't read something like:
\d*
...and understand what it means, then you need to skill up, badly. -
 j0n4s50883yThe problem I have is that there exist multiple regex variants.
j0n4s50883yThe problem I have is that there exist multiple regex variants.
Regex isn't a problem, but realizing that your regex does not work because you can't use feature xy in program(ming language) abc. -
hjk10156163y@jonas-w yeah that is really annoying though I've found that SQL is worse in that regard. In practice there are two main regex formats where the Perl one is the most dominant. There are also some minor implementation differences here and there but generally if you know Perl regex you are good to go in any programming language or GUI tool/editor and POSIX regex is used in the UNIX cli tools like grep.
-
hjk10156163y@NoToJavaScript it's fine if you want to let some one else look at the request but outright rejecting it because of a "you" problem would get my hackles up if you where my team mate.
Sure if the regex is so complicated that it would be objectively clearer in code or perhaps multiple regular expressions that would warrant some comments/improvements.
But in a lot of cases a regex is just better. For example I would rather read '/N[A-Z]?[0-9]{3,10}/' than deciphering 20 odd lines of code matching this. -
j0n4s50883y@hjk101 also the slashes are used for example in sed and in many other languages but not in grep for example. And IIRC {3,10} would not work in grep without 'grep-E'. (Don't have my laptop open, can't verify it)
-
j0n4s50883yI love regex and how it makes my life in the shell so much easier. But I hate that it is not 100% consistent implementation wise across different tools.
-
hjk10156163y@jonas-w yeah that is the PCRE vs POSIX you are taking about. The -e extended has to do with escaping. \{3,10\} works without -e. That shit gets me every time.
Another annoying thing are the replacement placeholders. Most of the times it's $1 $2 etc. but sometimes \1 or &1. -
It's easy to write RegEx.
It's harder to write an efficient RegEx.
It's very hard to write an readable, efficient and secure RegEx.
Imho, RegEx are overvalued for most devs... String operations are almost always faster for simple things (e.g. detecting if a string consists only of blanks).
Security and RegEx is an antipattern...
Dependent on length of string and operations necessary for the regular expression, it's easy to have a slow choke point of death.
I see this daily.
Lovely NGINX configurations where someone sprinkled RegEx like candy...
Very fucked up validation RegEx who run against user input of unknown length...
RegEx for text parsing of unknown length input with zero text sanitization beforehand.
Etc.
Explaining what ReDos is and why RegEx needs to be handled carefully is a thing I do at least once a month.
Or the reminder that an RegEx can be commented and optimized by e.g. deduplicating RegEx groups / patterns etc.
It's not that I hate RegEx...
But thx to stack overflow, google, medium and the casual I found this somewhere and someone said it works, my experience with RegEx is:
Give the dev a 10 kilovolt shock first, then ask if they wrote it by themselves and if they carefully thought about how the RegEx is executed and what side effects can occur....
Dependent on answer, rinse and repeat...
I've pulled RegExes out of a lot of things cause they really did serious harm.
E.g. when you enter a 120 length email and suddenly the browser freezes harm.
:( -
Good. A simple regex would translate to simple code. \d* means
string.chars()
.skip_while(|c| !c.is_digit(10))
.take_while(|c| c.is_digit(10))
.collect()
A long regex translates to disproportionately more code, but a long regex is also hard to read and does a lot of things that should be explicitly stated.
I don't get why languages that are expected to scale well have syntax support for regex but don't have a parser combinator in the STL. -
Every example I'd seen so far of a regex that was substantially simpler than the same thing expressed with iterator transformation managed to look simpler by obscuring a lot of important characteristics. And this is also exactly why I think it's a dangerous thing to allow some regex in a codebase. If you think it's simple enough to be allowed, is it because it's really that simple or is it because you didn't notice what it actually means? And even if the reviewer did understand the regex correctly, is the next reader gonna find it as simple, waste a lot of time double checking what it means, or skip over some details the reviewer assumed to be obvious?
-
I found this note in the docs for Blade, Laravel's templating language. The scary thing here isn't that Blade's parser isn't perfect. The scary thing is that the maintainers clearly have no idea what it does and doesn't support, because RegEx is very hard to reason about.

-
I think I've met you before! You're "every manager who was a senior dev 6 years ago and thinks lowly of anything they don't recognize"!
Yes, sure boss, I'll re-write this in visual basic. You're right, C# is just a trend and I'm dumb for choosing it.
In truth, I've only ever used regex to validate input. For anything more complex, I would definitely choose a parser -
 Hazarth91873ySo if I tried to remove all double, tripple and so on spaces from some user or API input using this code:
Hazarth91873ySo if I tried to remove all double, tripple and so on spaces from some user or API input using this code:
before.trim().replaceAll(" +", " ");
you're telling me you would reject it and instead tell me to write it using a for loop that goes over each byte and concatenates the strings in a byte array or using a string builder with an extra boolean flag checking for "wasLastSpace" or content[i-1] == " "?
You would seriously reject the RegEx? I don't believe that, but if so, what the fuck dude -
@Hazarth Many projects like e.g. apache String Utils use explicitly string operations for this - for performance reasons.
If you have a short string, less than 100 chars, it's fine.
If you have an string of unknown length, do text analysis, ...
It will melt your face off. -
Just learn everything about regex once in about an hour with a few exercises, it isn't that hard
For visualizing/testing I primarily use https://regex101.com -
Hazarth91873y@IntrusionCM ye, It's not performant, but that's not always the point. It's more readable imo of It's a simple single line like this and less error prone since the mechanics are known.
Though then again, if there's a library that already does it better in one line, use it. This was just an example. :) -
hjk10156163y@IntrusionCM do performance tests first. You might be surprised. A lot of regex engines that allow for compiled statements are highly optimized.
I've seen the other way around; a nested loop mess that is slow and hard to read.
If the input is 6TiB you have other problems and only parallel assembly optimised block trickery will get you there. -
@hjk101 and now you've an incentive to not even properly document it because the optimizer doesn't work if you break it up into meaningful and sufficiently documented fragments and string-concatenate them, and your language's "first class" regex support doesn't even support composition (the vast majority don't and I've never seen CTFE work on regex)
It's perverse incentives all the way. -
All powerful things are met with both joy, frustration and maybe even hostility. 🤷🏼♂️





Related Rants

 The only expressions devs have
The only expressions devs have
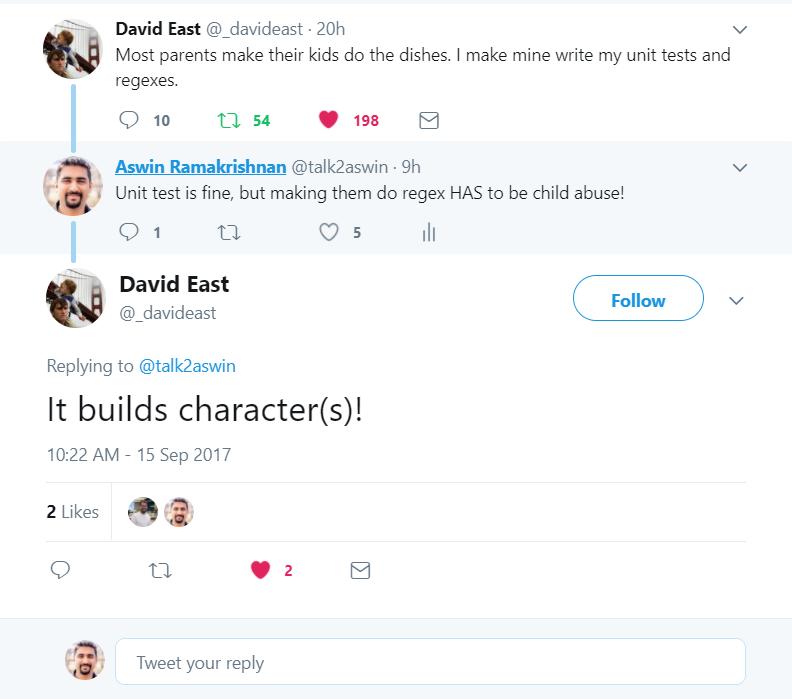 He's got a valid point
He's got a valid point
 How to break a chatbot (well done).
How to break a chatbot (well done).
After more than 24 years in dev, I still don't use RegEx and I have no idea how to write one without using an online builder.
I also refuse any Pull requests contaning regEx..
rant
regex