
Ranter

Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
Comments
-
*slap on the butt*
What DBMS?
Explain / Analyze / Query Execution Plan?
Is an index usable for multiple conditions?
Can the conditions be evaluated by the DB? Or is it an large OR chunk which prevents filtering?
JOIN Filter?
Self Joins for filtering?
*sparkling eyes* -
@Jilano
If you're that dumb, you deserve it 😘
We need more information. The only conclusion we can have right is n+1maybe. -
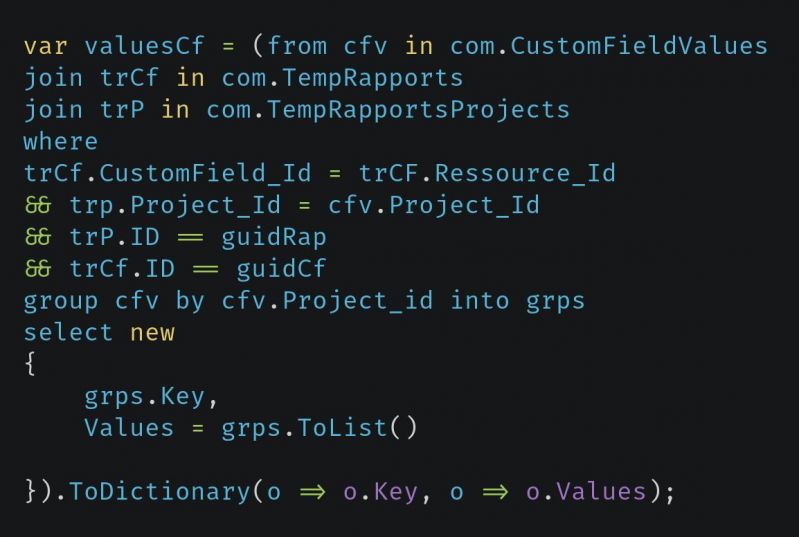
Ok I cannot share all details, but :
We are using Entity framework 6.
We prefetch the needed objects Ids in separates “tmp” tables.
The C# EF query with database group by is (It timeout at 30 seconds) :
https://pastebin.com/HgX2gECu
The C# Ef querry with web server side grouping is (Executes in 3 seconds) :
https://pastebin.com/MeVU7Zkj
The pastebin of real SQL 1 :
https://pastebin.com/m6cyFgpq
The pastebin of real SQL 2 :
https://pastebin.com/9KEnTUb9
I don’t get it. -
@netikras Not an option. “Explain” does not considers parameter sniffing. It will reuse the last execution plan saved, which we now already and is bad.
-
@NoToJavaScript
MSSQL...
Option Recompile
Execution Plan
But the Grouped By Query looks very fucked up...
I'll think about it a bit longer -
Hm. I'm not liking the query.
Depending on selectivity of the IDs the materialization of the nested derived tables can be pretty painful.
What's annoying me most is this gem.... Casting isn't usually a problem, and I'm not sure how well MSSQL handles it.... But when the whole nestdd queries get materialized and need to be casted to fulfill the outer ORDER by... It can be problematic. Since on disk seems like an better solution than memory for most optimizers.
@highlight
CASE WHEN ([Join4].[Id1] IS NULL) THEN CAST(NULL AS INT) ELSE 1 END AS [C1] -
I found mssql server to be very bad at selecting from sub queries.
Solved my problem by using a temp table, and running the where on that. Reduced my huge ass report (7 joins with time range limitation, running stored procedures per row, and more crap) runtime from 40min to 2.5 minutes. I do NOT miss that international corporate.
I was under the impression that The problem was in that the subquery result was not indexed.... -
@NoToJavaScript
pt. 1
It seems like what's probably happening here is that your joins are causing an M*N+1 expression due to the CASE have to run the distinct computation on the inner select to bind the conditionally resolved branch, which then outer joins against a third inner select.
This is why I absolutely never use Linq query syntax, especially with ORMS. It paints you into these corners and leaves you without an intuition as to what will be generated
Try something along the lines of this, or precompute the distinct operations and apply them in the wheres against the joins:
edit:
derp, pasted wrong example -
pt. 2
You also need to look at the plan and see what's being generated in sql:
https://docs.microsoft.com/en-us/... -
Aight, had a nice dinner and took a few minute to spew an example for you.
https://github.com/FailedChecksum/...
The bit you really care about is the test project, and the 1 unit test file. The brightside of updating your EF in the future will be that shit no longer compiles in 3.1, so you'll be prohibited from writing things that bad in the future.
https://github.com/FailedChecksum/...
This includes 3 examples:
- linq nested query
- linq group by, and why it fails outright in the latest version
- just using raw sql -
-
@SortOfTested I use a bit different method to lof generated SQL :
string s = "";
com.Database.Log = x => s += x;
I'll try your example ! -
@SortOfTested
OK ! Solved issue. Was way dumb than it seems. How did I miss it ?!
Let’s step back a little. What EF does when you select a Entity Type object?
Yes, It materializes it.
And then : It adds to tracking via proxy class.
Because you may change it. AND this tracking involves all navigation properties (Not loading, but still tracking).
So when the result is more than 75.000 entities, EF is keeping track of ALL of them, even their parents.
No if we use a projection via POCO (Or anonymous in this case, I’ll move it to Projections extenders later) class, EF will not add these objects to tracking at all.
So execution time went from 4 seconds to 287 ms







I’m fucking lost.
So, situation. I have a SQL table with about 3M rows (not a lot).
I have indexes. Indexes are used. BUT when I add where clause (On indexed column), it’s super slow. Around 10 seconds.
If I do select * (ALL 3M rows) and THEN I filter then on webserver side, it takes 0.5 seconds.
HOW my manual filtering is faster than DB filtering with indexes? I even tried bubble sort. Bubble sort is faster than SQL ‘where’. HOW ?!
I do not understand….
And if I add group by….. WELL, 25 seconds SQL time. 2 Seconds if I do select all and group by in code manually.
Does not make ANY sense to me.
What am I missing ?
rant