
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More



 No questions asked
No questions asked As a Python user and the fucking unicode mess, this is sooooo mean!
As a Python user and the fucking unicode mess, this is sooooo mean!
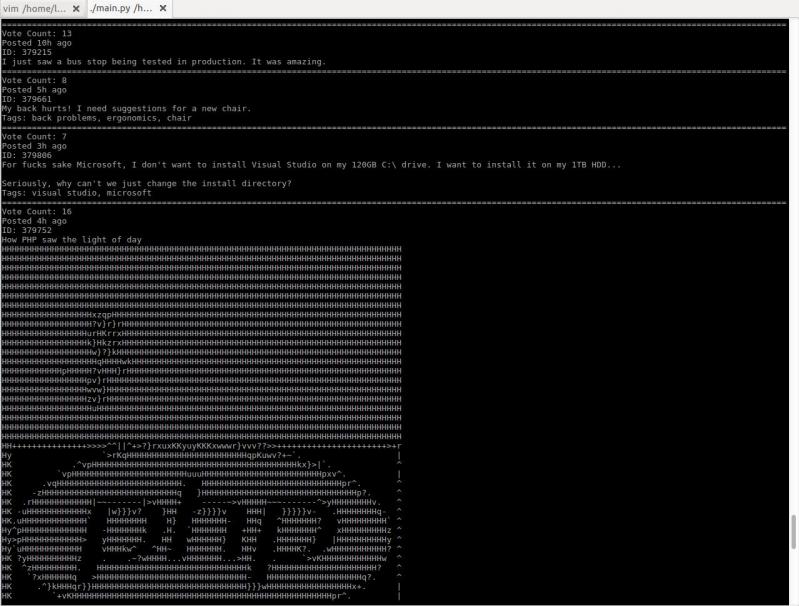 I just started working on a little project to browse devrant from terminal. It converts images to ascii art!
I just started working on a little project to browse devrant from terminal. It converts images to ascii art!
can you please help me with this.
I'm creating dataset of [Leet words][1].
This code is for generating [Leet words][1]. it is working fine with less number of strings but I've nearly 3,800+ strings and my pc is not capable to do so. I've Tried to run this on cloud(30gb RAM) not worked for me. but I think possible solution is to convert this code into numpy but I don't know how. if you know any other efficient way to do this it will be helpful.
Thanks!
from itertools import product
import pandas as pd
REPLACE = {'a': '@', 'i': '*', 'o': '*', 'u': '*', 'v': '*',
'l': '1', 'e': '*', 's': '$', 't': '7'}
def Leet2Combos(word):
possibles = []
for l in word.lower():
ll = REPLACE.get(l, l)
possibles.append( (l,) if ll == l else (l, ll) )
return [ ''.join(t) for t in product(*possibles) ]
s="""india
love
USA"""
words = s.split('\n')
print(words)
lst=[]
# ['india', 'love', 'USA']
for word in words:
lst.append(Leet2Combos(word))
k = pd.DataFrame(lst)
k.head()
rant
help
pandas
python3
python
help me
numpy