
Ranter

Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
Comments
-
 asgs109316yFor an endpoint that is supposed to return in 9 millis, I can return a 200 OK
asgs109316yFor an endpoint that is supposed to return in 9 millis, I can return a 200 OK
Also, what is the actual API supposed to do? -
 potata14576y@asgs Impossible, given that it suppose to account network ping + connecting and retrieval....
potata14576y@asgs Impossible, given that it suppose to account network ping + connecting and retrieval.... -
So he wants a mobile client to get 9ms response times to a resource over the Internet? You could distribute your api to every cell tower in the world and still not get those response times over cellular. That said, I haven’t seen many 5g tests. They boast sub 1ms max response times one way to the tower in tests (would love to see more data on that though). Spoiler alert, you still won’t get those response times. I’d manage the hell out of that expectation before launch, good luck
-
@asgs I'm not part of the team, so take this with a grain of salt.
My understanding is the API will have to generate a unique serial number within a certain range and have certain restrictions. That needs to be written to a database, validated, and a shipping label with this number needs to be generated, converted to an image and returned to the mobile device
... in 9ms
Humans can't even perceive anything close to that, so I don't know why the phone needs to get it that quickly.
Spoiler: it won't -
asgs109316y@potata API response times don't include external factors like the ones you mentioned. The time difference between the time request is received and response is committed is usually what the API SLAs are defined on
Of course, a laggy network still makes the API look degraded but that's not a direct problem of the API providers -
 Root771946yI would laugh and tell him to upgrade to tachyon networking, invent and automate time travel, or start using magic.
Root771946yI would laugh and tell him to upgrade to tachyon networking, invent and automate time travel, or start using magic. -
 hitko29956y@practiseSafeHex Not sure what infrastructure you're running on, but 9 ms SLA is perfectly reasonable if you're talking about mean request-processing time. Attached is a performance log from one of my services which is relatively similar in that it:
hitko29956y@practiseSafeHex Not sure what infrastructure you're running on, but 9 ms SLA is perfectly reasonable if you're talking about mean request-processing time. Attached is a performance log from one of my services which is relatively similar in that it:
- finds resources in db
- selects the best-fit returned resource
- logs request to db (accounting) and SQS (analytics)
- either streams an image from S3 bucket / cache server, or generates image and streams it directly
But again, it depends on details; in my case it's all within a single data center, clearly it would take way more if it had to perform requests to an external service. SLA can be either based on mean, or a certain percentile - it only passes 9 ms SLA for mean and 87th percentile. On the other hand, it's not utilising anything to boost network communication and reduce latences between db, S3, and application server, and it's running JIT, not precompiled code.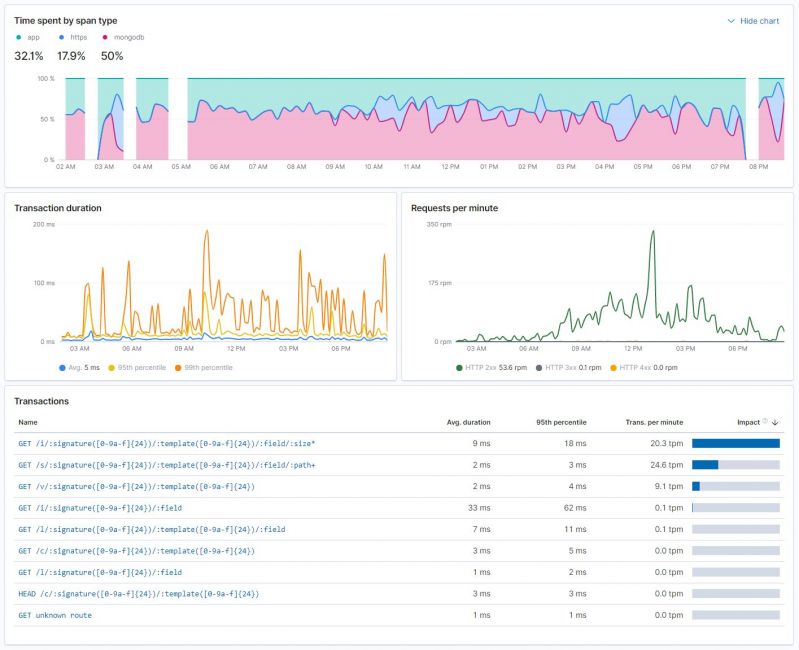
-
@stop Reminds me of LTSpice (electronic circuit simulation).
Resistance: 1M Ohm.
LTSpice: I will calculate 1 milli Ohm! -
> a unique serial number
Random generated with a database "unique".
If the data type is large enough and the database is fast, that should be no problem. In nearly all cases.
> within a certain range
All random functions support that.
> certain restrictions
Can mean everything, but I assume something like "not starting with 0" or "has the postal code at the end". Both constraints are not difficult to achieve.
> Converted to an image
I assume the rest of the label is already generate d so you only need to replace certain areas? Doable.
Spending on the software stack, it may be challenging (of course this entirely skips authentication and whatsoever) but with careful programming, it seems doable.
But it might take some time to get down to the 9ms. -
If my headmath is correct, technically that should be doable if, say, this is only needed for one country within one time zone. But yeah anything more would be too much for c = 3e8 m/s
-
This company is one of the biggest in the world. I would imagine any API such as this one is going to have extremely high traffic, and in the region of one to a couple hundred thousand concurrent users.
This isn’t going to be just an API reading from a database and returning. This is multi region cloud + database, Kafka event queues, I think one other internal company API and then all the layers of services and load balancers between it and the internet that the team don’t own.
All of the engineers on that team say 9ms is a pipe dream -
potata14576y@asgs yeah, I get that, it was more like a sarcastic joke in this situation :) don't take it too seriously
-
hitko29956y@practiseSafeHex At your scale, each data center should have a local database shard, and with proper sharding architecture there should be no need to interact beyond the local shard. I presume at such scale any internal API would be deployed across all data centres as well, so anything running within the same data centres should always interact with those before any outwards-facing load balancing, which should grant sub-millisecond network latencies interacting with other APIs.





Related Rants

 Every software should have this
Every software should have this

 Non-dev buddy: Dude I'm gonna report you to the tech department what are you hacking??
Me:
Non-dev buddy: Dude I'm gonna report you to the tech department what are you hacking??
Me:
Dev lead on another team: Ok we can build that API for the mobile apps, we'll generate everything, generate printable images for the labels, persist it all and do all the relevant lookups and checks. Do you need an SLA?
Director: Yes, 9ms
*silence*
Lead: Sorry .... 9ms?
Director: yeah, its a must have
Lead: ... the speed of light wouldn't even let us transmit it that fast
rant
must have
moron
unfeasible
requirements
director