
Ranter
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
Comments
-
 Heemers4939y@Eariel I have this corpus of wikipedia comments... I need to find the highest word frequency.
Heemers4939y@Eariel I have this corpus of wikipedia comments... I need to find the highest word frequency. -
 Bagul11449ySince RegEx took away all your emotions, does that mean you can't use regular expressions in everyday conversations anymore?
Bagul11449ySince RegEx took away all your emotions, does that mean you can't use regular expressions in everyday conversations anymore? -
 Voxera108839yRegex is good for finding patterns in text OR for parsing well formated text.
Voxera108839yRegex is good for finding patterns in text OR for parsing well formated text.
For anything else I either build something custom or use a mix of technics.
Or possibly use several regex after each other.
They are not good for doing more than one thing since every layer usually requires repetition of the same regex part and it quickly grows beyond comprehension.
Also, many times you eventually have to come back to it to tweek it and thats when you start hating your former self for not separating out the different operations. -
 ZaLiTHkA8369y@Heemers, if it's just word frequency you're after, why not simply split the string on word boundaries (\b), obviously catering for words that would be inside links, then iterate over the array of results and discard all invalid strings?
ZaLiTHkA8369y@Heemers, if it's just word frequency you're after, why not simply split the string on word boundaries (\b), obviously catering for words that would be inside links, then iterate over the array of results and discard all invalid strings?
I love RegEx, but as powerful as it is, it's by no means the solution to every string manipulation problem. O.o -
login1049yEach time you use regex to parse HTML a fairy dies: http://stackoverflow.com/questions/...
-
Regular expressions can only match regular languages.
HTML is a context-free language.
The pain you are experiencing is using a frozen fish for a hammer.
I advise you to read this: http://stackoverflow.com/q/6751105/... -
why don't you use BeautifulSoup or something? also any decent scrapper would do it, say Scrapy...
thats way too much hassle with raw regex! -
 anekix3679yI was wondering it could be done with half -a-word code maybe? try XPath?? As simple as:
anekix3679yI was wondering it could be done with half -a-word code maybe? try XPath?? As simple as:
//text()[normalize-space()]
FYI XPath is not a library or framework




Related Rants

 The only expressions devs have
The only expressions devs have
 No questions asked
No questions asked
 He's got a valid point
He's got a valid point
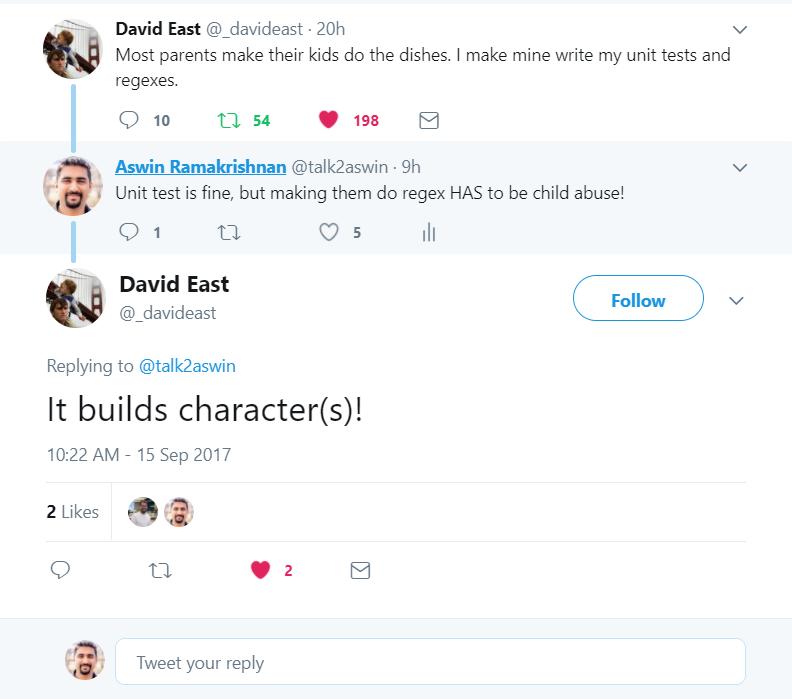
I spent almost 10 hours coming up with this RegEx. Trial and erroring my way to hell. First I had get rid of the HTML tags (which was easy-ish) then I spent most of my time trying to figure out how to remove the god damn dash but keep hyphenated words ....... Then I found \B and look behinds...
I am making it a point to get good at this shit... Because right now I am petrified of it... Fuck you Regular expression you have taken away all my emotions...
undefined
regex
regular expressions
python