
Ranter
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
Comments
-
 donuts232474y@sariel yes guess I sorta did though now watching the program run, the logs freeze occasionally so probably it's the queries that are shit too...
donuts232474y@sariel yes guess I sorta did though now watching the program run, the logs freeze occasionally so probably it's the queries that are shit too...
Just emailed JPROFILER to see if they'd be nice enough to extend my trial license because I don't know who to contact within my org to buy it... -
 JsonBoa31334y@donuts, we got to 6000 writes per second on a single database with 5 indices (all primitive types on the outer layer of the documents). Single-instance deployment with 32 GB ram and eight cores.
JsonBoa31334y@donuts, we got to 6000 writes per second on a single database with 5 indices (all primitive types on the outer layer of the documents). Single-instance deployment with 32 GB ram and eight cores.
We had between 16 and 128 connected clients and at least 64 concurrent writes. Each document was between 100kb and 2000kb, semi-formatted. all documents had the index attributes.
Mongo could probably still handle way more writes. -
donuts232474y@JsonBoa thanks, then could be our document structure too?
Our docs are probably not near 2000kb, and have a lot of nested fields.
We're averaging about 400/s on writes...
20-30 indexes on this collection but even our fastest I think is around there too...
Our instance has 4TB using Wired tiger compression, would that be why it's slower, the compression? -
JsonBoa31334y@donuts, document databases can be either optimized for write (just use very few indexes, 8 top, and those must all fit in main memory of a single instance and use primitive types. NEVER ALLOW FOR SWAP) or read (indexes on every field in your queries), but not both.
"and what about read replicas and replica sets?" those do solve your problems if you do not need the most recently inserted data. Mongo can delay the sync to replica sets without compromising performance (using binary heap indexes), but if you need stuff as soon as inserted, you are gonna have a bad time with countless sync jobs locking the same index bins that you want to write to. -
JsonBoa31334yso, if you use mongo as a part of a pipeline, I recommend an y-shaped architecture in which you have an proxy that writes a document to mongo while forwarding it to your pipeline (I suggest using RabbitMQ or RedisPubSub as a point of entry, replicating every document to two queues each with it's own consumers. One queue will just write to mongo and the other will actually process the near-real-time data)
-
JsonBoa31334y@donuts, nested attributes are OK if not used on indexes. Indexes should be light and prioritize primitive types. It is often faster to let mongo retrieve up to 5 times as much data as you need (using light indexes) and letting your application filter the complex attributes of the received data on its end
-
donuts232474y@JsonBoa we have loader apps that load feed files from upstream at the end of the day.
Then other jobs query them, so can't really do real-time.
The main memory thing could be the issue... We have a single DB, 4TB but everything uses it... So a lot of page faults
Would it be better to have multiple smaller DBs and just have the app connect to all of them/just the ones it needs? -
donuts232474yThanks by the way, really helpful though probably not going to convince my boss ...
Why need docker/containers when you can have a giant VM with everything.... ¯\_(ツ)_/¯ -
JsonBoa31334y@donuts, Yep! NoSQL and Kubernetes/fleet architectures are BFFs
You can set mongo to partition data between collections and have several instances, each with its own relevant collections and indexes.
Also, mongo is really nice for "hot" databases, where data can be still updated or you have no idea how you will use it yet.
However, as your app matures, you might want to invest in an ETL job that extracts data from mongo and turns it into long-term storage, like Apache ORC or parquet files.
Avoid extracting huge amounts of data from mongo as a query, though. Mongodump files are basically huge Json arrays, so Hadoop or spark can read them easily. put your backups to good use! -
donuts232474y@JsonBoa App matures... already there but just designed and built by a team that has no idea what they're doing or based on "how they've always done it"
Tell them ... Is a dumb idea but they do it anyway...
Then go hey can you optimize it? -
JsonBoa31334y@donut, ugh, been there.
Just try to use only indexed fields in queries, and use the replica-set distributed architecture.
and prepare for some huge tech debt interest paid in sleepless working nights.


Related Rants
-
 StanTheMan4Hired a new backend Dev. He writes a script and sends it for testing... Tester: "It's not working..." Backend ...
StanTheMan4Hired a new backend Dev. He writes a script and sends it for testing... Tester: "It's not working..." Backend ... -
 goodBoiBadDev44She - So. Do you read ? Me - Yes. Infact a lot. Daily. My life is filled with it. She - Wow. Nice. So what d...
goodBoiBadDev44She - So. Do you read ? Me - Yes. Infact a lot. Daily. My life is filled with it. She - Wow. Nice. So what d... -
 shauryachats2
shauryachats2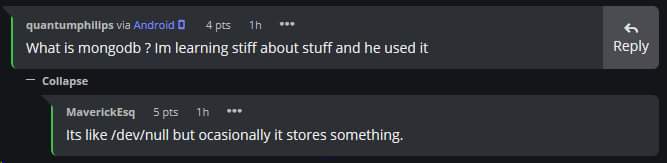 "Occasionally stores something" 😂
"Occasionally stores something" 😂
What is a normal write speed (docs/second) for mongo db?
Can't find a benchmark online and well I'm trying to prove my point to my boss that our speeds are insanely slow due to index bloat,..
question
mongodb