

Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More









 The week before project deadline...
The week before project deadline...
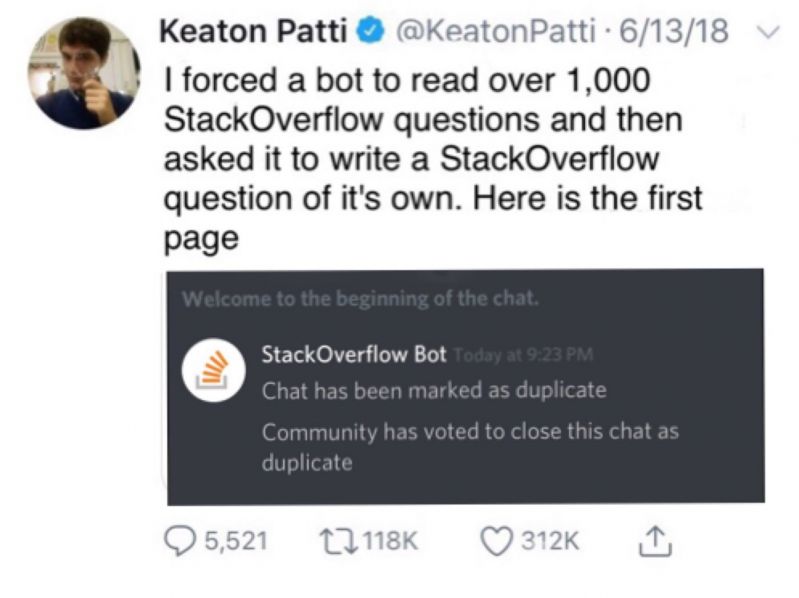 Machine Learning messed up!
Machine Learning messed up!
Currently getting into Machine Learning and working on a joke-project to identify the main programming language of GitHub repositories based on commit messages. For half of the commits, the language is predicted correctly out of 53 possible languages. Which is not too bad given the fact that I have no clue what I'm doing...
random
project
machine learning
ml
supervised learning