
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I love Linux, but its community can be so full of incompetent assholes..
Just now I asked in Freenode ##linux how to get the process ID of my current running process in bash. I got my answer - it's a shell built-in called "$$".
Then people start to nitpick some more - why do you need it? How is that different from an exit? - to which my response was.. well I know the whole idea behind exit codes, and I'd use it whenever possible, in all defined behavior that allows my program to terminate itself whenever it can. This pidfile however would be used to exit itself and provide diagnostic information whenever the program enters undefined behavior - a segfault in C language. Scenarios in which I don't have full control over the script's behavior anymore, such as the system entering an unworkable state where the system stalled, still got some binaries in RAM but the rootfs got unwritable, such as now - very helpfully, thanks HP! - when my laptop likely overheated and shat itself. I issued sudo reboot into it, but even that wouldn't issue properly anymore due to the /sbin/poweroff binary becoming inaccessible too. I had to issue a hard power cycle.. one of the few times in which I'm thankful to HP for actually causing shit like this, lol.
Point is, that undefined behavior is what I'm trying to mitigate against. I certainly can't let any files other than diagnostics remain in nonvolatile storage like that, especially when their state should be predictable in order to ensure good operation (like files expressing whether the script is already running or not, i.e. lock files).
Back to that IRC chat. Aside from the answer, I got ridicule from people who probably don't even know how to properly compile a kernel. Ubuntu users, overconfident scum. Sometimes I feel like I should ask questions in channels like #archlinux only, where such incompetency is ridiculed on its own.13 -
I've optimised so many things in my time I can't remember most of them.
Most recently, something had to be the equivalent off `"literal" LIKE column` with a million rows to compare. It would take around a second average each literal to lookup for a service that needs to be high load and low latency. This isn't an easy case to optimise, many people would consider it impossible.
It took my a couple of hours to reverse engineer the data and implement a few hundred line implementation that would look it up in 1ms average with the worst possible case being very rare and not too distant from this.
In another case there was a lookup of arbitrary time spans that most people would not bother to cache because the input parameters are too short lived and variable to make a difference. I replaced the 50000+ line application acting as a middle man between the application and database with 500 lines of code that did the look up faster and was able to implement a reasonable caching strategy. This dropped resource consumption by a minimum of factor of ten at least. Misses were cheaper and it was able to cache most cases. It also involved modifying the client library in C to stop it unnecessarily wrapping primitives in objects to the high level language which was causing it to consume excessive amounts of memory when processing huge data streams.
Another system would download a huge data set for every point of sale constantly, then parse and apply it. It had to reflect changes quickly but would download the whole dataset each time containing hundreds of thousands of rows. I whipped up a system so that a single server (barring redundancy) would download it in a loop, parse it using C which was much faster than the traditional interpreted language, then use a custom data differential format, TCP data streaming protocol, binary serialisation and LZMA compression to pipe it down to points of sale. This protocol also used versioning for catchup and differential combination for additional reduction in size. It went from being 30 seconds to a few minutes behind to using able to keep up to with in a second of changes. It was also using so much bandwidth that it would reach the limit on ADSL connections then get throttled. I looked at the traffic stats after and it dropped from dozens of terabytes a month to around a gigabyte or so a month for several hundred machines. The drop in the graphs you'd think all the machines had been turned off as that's what it looked like. It could now happily run over GPRS or 56K.
I was working on a project with a lot of data and noticed these huge tables and horrible queries. The tables were all the results of queries. Someone wrote terrible SQL then to optimise it ran it in the background with all possible variable values then store the results of joins and aggregates into new tables. On top of those tables they wrote more SQL. I wrote some new queries and query generation that wiped out thousands of lines of code immediately and operated on the original tables taking things down from 30GB and rapidly climbing to a couple GB.
Another time a piece of mathematics had to generate all possible permutations and the existing solution was factorial. I worked out how to optimise it to run n*n which believe it or not made the world of difference. Went from hardly handling anything to handling anything thrown at it. It was nice trying to get people to "freeze the system now".
I build my own frontend systems (admittedly rushed) that do what angular/react/vue aim for but with higher (maximum) performance including an in memory data base to back the UI that had layered event driven indexes and could handle referential integrity (overlay on the database only revealing items with valid integrity) or reordering and reposition events very rapidly using a custom AVL tree. You could layer indexes over it (data inheritance) that could be partial and dynamic.
So many times have I optimised things on automatic just cleaning up code normally. Hundreds, thousands of optimisations. It's what makes my clock tick.4 -
So, I work in a game development studio, right?
We're trying to launch the title on as many platforms as reasonable, because as a social VR app we're kinda rowing upstream.
So far, Steam and Oculus have been fairly reasonable, if oddly broken and inconsistent.
Enter store 3.
Basically no in-game transaction support (our asking prompted them to *start* developing it. No, it's not very complete). No patch-update system (You want an update? Gotta download the whole fsckin' thing!). No beta-testing functionality for most of their stuff ("Just write the code like the example, it will work, trust us!"). No tools besides the buggy SDK (Wanna upload that new build? Say hello to this page in your web browser!).
So, in other words: Fun.
We've been trying to get actively launched for two months now. Keep in mind that the build has been up on Steam and Oculus for over a year and half a year (respectively), so the actual binary functionality is, presumably fine.
The best feedback we get back tends to be "Well, when we click the Launch button it crashes, so fail."
Meanwhile we're going back and forth, dealing with other-side-of-the-world timezone lag, trying to figure out what is so different from their machines as ours. Eventually we get them to start sending logs (and no, Windows Event logs are not sufficient for GAMES, where did you even get that idea????) except the logs indicate that the program is getting killed so terribly that the engine's built-in crash handler can't even kick in to generate memory dumps or even know it died.
All this boils down to today, where I get a screenshot of their latest attempt.
I just can't even right now.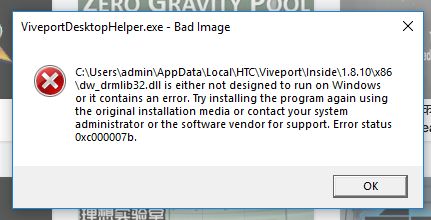 5
5



Top Tags
Weekly Rant
View