
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I setup stable diffusion today. Still figuring it out but I'm like an artist now right? Right?
Next step is figuring out how to train models.
Then I have to make some samples of various words in spectrogram form for training.
After that we'll see if stable diffusion can reconstruct phonemes.
I'll train using both my voice and a couple others, and apply them as styles.
And then finally, I can accomplish my lifes goal.
To have the voice of morgan freeman with me at all times, everywhere I go.5 -
When Everybody Is Digging for Gold, It’s Good To Be in the Pick and Shovel Business
- ai is just another squeeze of money to cloud from our pockets, no matter what you do as long as you’re not selling/renting hardware or have high profit customers your product will die
I don’t believe in any ai product right now that can’t be self hosted and opensource and many of them are not.
I use mac, like 64GB m1 mac book pro so I can host load of things like llama, wizzard-lm, mistral, any yolo, whisper, gpt, fucking midjourney or other stable diffusion for me is no drama.
I’d say there is no consumer product for ai right now. OpenAI is scam given what we got from mistral.
We are very early in this new but old technology and my worries are that we are not there yet. We will need to wait for another iteration that is approximately 10 years to achieve what we have in mind because current hardware is 10 years behind software.
We don’t have an affordable computing power to go for our dreams.
Sad but true.4 -
New models of LLM have realized they can cut bit rates and still gain relative efficiency by increasing size. They figured out its actually worth it.
However, and theres a caveat, under 4bit quantization and it loses a *lot* of quality (high perplexity). Essentially, without new quantization techniques, they're out of runway. The only direction they can go from here is better Lora implementations/architecture, better base models, and larger models themselves.
I do see one improvement though.
By taking the same underlying model, and reducing it to 3, 2, or even 1 bit, assuming the distribution is bit-agnotic (even if the output isn't), the smaller network acts as an inverted-supervisor.
In otherwords the larger model is likely to be *more precise and accurate* than a bitsize-handicapped one of equivalent parameter count. Sufficient sampling would, in otherwords, allow the 4-bit quantization model to train against a lower bit quantization of itself, on the theory that its hard to generate a correct (low perpelixyt, low loss) answer or sample, but *easy* to generate one thats wrong.
And if you have a model of higher accuracy, and a version that has a much lower accuracy relative to the baseline, you should be able to effectively bootstrap the better model.
This is similar to the approach of alphago playing against itself, or how certain drones autohover, where they calculate the wrong flight path first (looking for high loss) because its simpler, and then calculating relative to that to get the "wrong" answer.
If crashing is flying with style, failing at crashing is *flying* with style.15 -
I would have never considered it but several people thought: why not train our diffusion models on mappings between latent spaces themselves instead of on say, raw data like pixels?
It's a palm-to-face moment because of how obvious it is in hindsight.
Details in the following link (or just google 'latent diffusion models')
https://huggingface.co/docs/... -
Piratesoftware's "2D Raytracing" code is just shitty radial light diffusion with collision checks. The worst part is he's individually checking each pixel and manually adjusting the lighting pixel by pixel😭 🙏
Does anyone else feel like Piratesoftware's content is just dedicated to people starting out with coding and game dev? Should this piece of shit be the person these newbie devs look up to? What a fucktard. This is the dude who has "DECADES OF INDUSTRY EXPERIENCE" hacking windmills and sending emails like "please let me hack you" in blizzard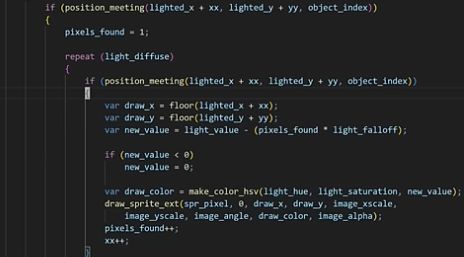 7
7 -
The next step for improving large language models (if not diffusion) is hot-encoding.
The idea is pretty straightforward:
Generate many prompts, or take many prompts as a training and validation set. Do partial inference, and find the intersection of best overall performance with least computation.
Then save the state of the network during partial inference, and use that for all subsequent inferences. Sort of like LoRa, but for inference, instead of fine-tuning.
Inference, after-all, is what matters. And there has to be some subset of prompt-based initializations of a network, that perform, regardless of the prompt, (generally) as well as a full inference step.
Likewise with diffusion, there likely exists some priors (based on the training data) that speed up reconstruction or lower the network loss, allowing us to substitute a 'snapshot' that has the correct distribution, without necessarily performing a full generation.
Another idea I had was 'semantic centering' instead of regional image labelling. The idea is to find some patch of an object within an image, and ask, for all such patches that belong to an object, what best describes the object? if it were a dog, what patch of the image is "most dog-like" etc. I could see it as being much closer to how the human brain quickly identifies objects by short-cuts. The size of such patches could be adjusted to minimize the cross-entropy of classification relative to the tested size of each patch (pixel-sized patches for example might lead to too high a training loss). Of course it might allow us to do a scattershot 'at a glance' type lookup of potential image contents, even if you get multiple categories for a single pixel, it greatly narrows the total span of categories you need to do subsequent searches for.
In other news I'm starting a new ML blackbook for various ideas. Old one is mostly outdated now, and I think I scanned it (and since buried it somewhere amongst my ten thousand other files like a digital hoarder) and lost it.
I have some other 'low-hanging fruit' type ideas for improving existing and emerging models but I'll save those for another time.2 -
1/2 dev and a fair warning: do not go into the comments.
You're going anyway? Good.
I began trying to figure out how to use stable diffusion out of boredom. Couldn't do shit at first, but after messing around for a few days I'm starting to get the hang of it.
Writing long prompts gets tiresome, though. Think I can build myself a tool to help with this. Nothing fancy. A local database to hold trees of tokens, associate each tree to an ID, like say <class 'path'> or some such. Essentially, you use this to save a description of any size.
The rest is textual substitution, which is trivial in devil-speak. Off the top of my head:
my $RE=qr{\< (?<class> [^\s]+) \s+ ' (?<path>) [^'] '\>}x;
And then? match |> fetch(validate) |> replace, recurse. Say:
while ($in =~ $RE) {
my $tree=db->fetch $+{class},$+{path};
$in=~ s[$RE][$tree];
};
Is that it? As far the substitution goes, then yeah, more or less. We have to check that a tree's definition does not recurse for this to work though, but I would do that __before__ dumping the tree to disk, not after.
There is most likely an upper limit to how much abstraction can be achieved this way, one can only get so specific before the algorithm starts tripping balls I reckon, the point here is just reaching that limit sooner.
So pasting lists of tokens, in a nutshell. Not a novel idea. I'd just be making it easier for myself. I'd rather reference things by name, and I'd rather not define what a name means more than once. So if I've already detailed what a Nazgul is, for instance, then I'd like to reuse it. Copy, paste, good times.
Do promise to slay me in combat should you ever catch me using the term "prompt engineering" unironically, what a stupid fucking joke.
Anyway, the other half, so !dev and I repeat the warning, just out of courtesy. I don't think it needs to be here, as this is all fairly mild imagery, but just in case.
I felt disappointed that a cursed image would scare me when I've seen far worse shit. So I began experimenting, seeing if I could replicate the result. No luck yet, but I think we're getting somewhere.
Our mission is clearly the bronwning of pants, that much is clear. But how do we come to understand fear? I don't know. "Scaring" seems fairly subjective.
But I fear what I know to be real,
And I believe my own two eyes. 11
11 -
This is gonna be a long post, and inevitably DR will mutilate my line breaks, so bear with me.
Also I cut out a bunch because the length was overlimit, so I'll post the second half later.
I'm annoyed because it appears the current stablediffusion trend has thrown the baby out with the bath water. I'll explain that in a moment.
As you all know I like to make extraordinary claims with little proof, sometimes
for shits and giggles, and sometimes because I'm just delusional apparently.
One of my legit 'claims to fame' is, on the theoretical level, I predicted
most of the developments in AI over the last 10+ years, down to key insights.
I've never had the math background for it, but I understood the ideas I
was working with at a conceptual level. Part of this flowed from powering
through literal (god I hate that word) hundreds of research papers a year, because I'm an obsessive like that. And I had to power through them, because
a lot of the technical low-level details were beyond my reach, but architecturally
I started to see a lot of patterns, and begin to grasp the general thrust
of where research and development *needed* to go.
In any case, I'm looking at stablediffusion and what occurs to me is that we've almost entirely thrown out GANs. As some or most of you may know, a GAN is
where networks compete, one to generate outputs that look real, another
to discern which is real, and by the process of competition, improve the ability
to generate a convincing fake, and to discern one. Imagine a self-sharpening knife and you get the idea.
Well, when we went to the diffusion method, upscaling noise (essentially a form of controlled pareidolia using autoencoders over seq2seq models) we threw out
GANs.
We also threw out online learning. The models only grow on the backend.
This doesn't help anyone but those corporations that have massive funding
to create and train models. They get to decide how the models 'think', what their
biases are, and what topics or subjects they cover. This is no good long run,
but thats more of an ideological argument. Thats not the real problem.
The problem is they've once again gimped the research, chosen a suboptimal
trap for the direction of development.
What interested me early on in the lottery ticket theory was the implications.
The lottery ticket theory says that, part of the reason *some* RANDOM initializations of a network train/predict better than others, is essentially
down to a small pool of subgraphs that happened, by pure luck, to chance on
initialization that just so happened to be the right 'lottery numbers' as it were, for training quickly.
The first implication of this, is that the bigger a network therefore, the greater the chance of these lucky subgraphs occurring. Whether the density grows
faster than the density of the 'unlucky' or average subgraphs, is another matter.
From this though, they realized what they could do was search out these subgraphs, and prune many of the worst or average performing neighbor graphs, without meaningful loss in model performance. Essentially they could *shrink down* things like chatGPT and BERT.
The second implication was more sublte and overlooked, and still is.
The existence of lucky subnetworks might suggest nothing additional--In which case the implication is that *any* subnet could *technically*, by transfer learning, be 'lucky' and train fast or be particularly good for some unknown task.
INSTEAD however, what has happened is we haven't really seen that. What this means is actually pretty startling. It has two possible implications, either of which will have significant outcomes on the research sooner or later:
1. there is an 'island' of network size, beyond what we've currently achieved,
where networks that are currently state of the3 art at some things, rapidly converge to state-of-the-art *generalists* in nearly *all* task, regardless of input. What this would look like at first, is a gradual drop off in gains of the current approach, characterized as a potential new "ai winter", or a "limit to the current approach", which wouldn't actually be the limit, but a saddle point in its utility across domains and its intelligence (for some measure and definition of 'intelligence').4 -
Theres a method for speeding up diffusion generation (things like stablediffusion) by several orders of magnitude. It's related to particle physics simulations.
I'm just waiting for the researchers to figure it out for themselves.
it's like watching kids break toys.6 -
Anyone tried converting speech waveforms to some type of image and then using those as training data for a stable diffusion model?
Hypothetically it should generate "ultrarealistic" waveforms for phonemes, for any given style of voice. The training labels are naturally the words or phonemes themselves, in text format (well, embedding vectors fwiw)
After that it's a matter of testing text-to-image, which should generate the relevant phonemes as images of waveforms (or your given visual representation, however you choose to pack it)
I would have tried this myself but I only have 3gb vram.
Even rudimentary voice generation that produces recognizable words from text input, would be interesting to see implemented and maybe a first for SD.
In other news:
Implementing SQL for an identity explorer. Basically the system generates sets of values for given known identities, and stores the formulas as strings, along with the values.
For any given value test set we can then cross reference to look up equivalent identities. And then we can test if these same identities hold for other test sets of actual variable values. If not, the identity string cam be removed, or gophered elsewhere in the database for further exploration and experimentation.
I'm hoping by doing this, I can somewhat automate the process of finding identities, instead of relying on logs and using the OS built-in text search for test value (which I can then look up in the files that show up, and cross reference the logged equations that produced those values), which I use to find new identities.
I was even considering processing the logs of equations and identities as some form of training data perhaps for a ML system that generates plausible new identities but that's a little outside my reach I think.
Finally, now that I know the new modular function converts semiprimes into numbers with larger factor trees, I'm thinking of writing a visual browser that maps the connections from factor tree to factor tree, making them expandable and collapsible, andallowong adjusting the formula and regenerating trees on the fly.6




Top Tags
Weekly Rant
View