
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!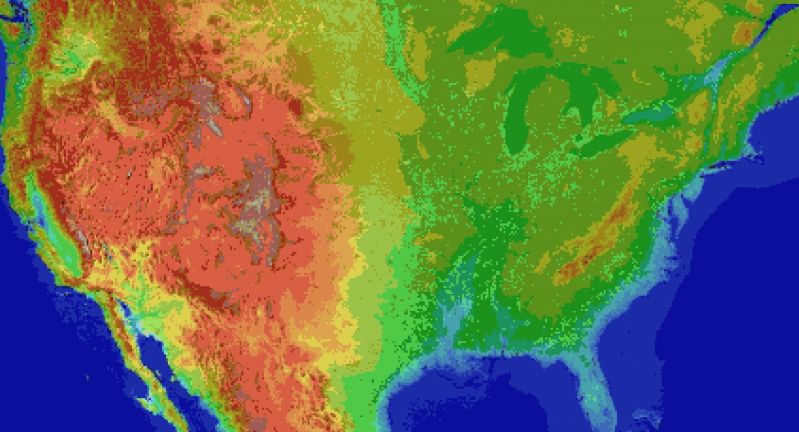 5
5 -
People think Machine Learning is all about using Super Complex Prediction Models...
But turns out to devote most time in data gathering and data cleaning(preprocessing). 2
2 -
I am learning Machine Learning via Matlab ML Onramp.
It seems to me that ML is;
1. (%80) preprocessing the ugly data so you can process data.
2. (%20) Creating models via algorithms you memorize from somewhere else, that has accuracy of %20 aswell.
3. (%100) Flaunting around like ML is second coming of Jesus and you are the harbinger of a new era.8 -
Question Time:
What technologies would u suggest for a web based project that'll do some data scraping, data preprocessing and also incorporate a few ML models.
I've done data scraping in php but now I want to move on and try something new....
Planning to use AWS to host it.
Thanks in advance :)5 -
I’m trying to update a job posting so that it’s not complete BS and deters juniors from applying... but honestly this is so tough... no wonder these posting get so much bs in them...
Maybe devRant community can help be tackle this conundrum.
I am looking for a junior ml engineer. Basically somebody I can offload a bunch of easy menial tasks like “helping data scientists debug their docker containers”, “integrating with 3rd party REST APIs some of our models for governance”, “extend/debug our ci”, “write some preprocessing functions for raw data”. I’m not expecting the person to know any of the tech we are using, but they should at least be competent enough to google what “docker is” or how GitHub actions work. I’ll be reviewing their work anyhow. Also the person should be able to speak to data scientists on topics relating to accuracy metrics and mode inputs/outputs (not so much the deep-end of how the models work).
In my opinion i need either a “mathy person who loves to code” (like me) or a “techy person who’s interested in data science”.
What do you think is a reasonable request for credentials/experience?5 -
I starting developing my skills to a pro level from 1 year and half from now. My skillset is focused on Backend Development + Data Science(Specially Deep Learning), some sort of Machine Learning Engineer. I fill my github with personal projects the last 5 months, and im currently working on a very exciting project that involves all of my skills, its about Developing and deploy a Deep Learning Model for Image Deblurring.
I started to look for work two months to now. I applied to dozens of jobs at startups, no response. I changed my strategy a bit, focusing on early stage startups that dont have infinite money for pay all that senior devs, nothing, not even that startups wish to have me in their teams. I even applied to 2 or 3 and claim to do the job for little payment, arguing im not going for money but experience, nothing. I never got a reply back, not an interview, the few that reach back(like 3, from 3 or 4 dozen of startups), was just for say their are not interested on me.
This is frustrating, what i do on my days is just push forward my personal projects without rest. I will be broke in a few months from now if i dont get a job, im still young, i have 21 years, but i dont have economic support from parents anymore(they are already broke). Truly dont know what to do. Currently my brother is helping me with the money, but he will broke in few months as i say.
The worst of all this case is that i feel capable of get things done, i have skills and i trust in myself. This is not about me having doubts about my skills, but about startups that dont care, they are not interested in me, and the other worst thing is that my profile is in high demand, at least on startups, they always seek for backend devs with Machine Learning knowledge. Im nothing for them, i only want to land that first job, but seems to be impossible.
For add to this situation, im from south america, Venezuela, and im only able to get a remote job, because in my country basically has no Tech Industry, just Agencies everywhere underpaying devs, that as extent, dont care about my profile too!!! this is ridiculous, not even that almost dead Agencies that contract devs for very little payment in my country are interested in me! As extra, my economic situation dont allows me to reallocate, i simple cant afford that. planning to do it, but after land some job for a few months. Anyways coronavirus seems to finally set remote work as the default, maybe this is not a huge factor right now.
I try to find job as freelancer, i check the freelancer sites(Freelancer, Guru and so on) every week more or less, but at least from what i see, there is no Backend-Only gigs for Python Devs, They always ask for Fullstack developers, and Machine Learning gigs i dont even mention them.
Maybe im missing something obvious, but feel incredible that someone that has skills is not capable of land even a freelancer job. Maybe im blind, or maybe im asking too much(I feel the latter is not the case). Or maybe im overestimating my self? i think around that time to time, but is not possible, i have knowledge of Rest/GraphQL APIs Development using frameworks like Flask or DJango(But i like Flask more than DJango, i feel awesome with its microframework approach). Familiarized with containerization and Docker. I can mention knowledge about SQL and DBs(PostgreSQL), ORMs(SQLAlchemy), Open Auth, CI/CD, Unit Testing, Git, Soft DevOps Skills, Design Patterns like MVC or MTV, Serverless Environments, Deep Learning Solutions, end to end: Data Gathering, Preprocessing, Data Analysis, Model Architecture Design, Training and Finetunning. Im familiarized with SotA techniques widely used now days, GANs, Transformers, Residual Networks, U-Nets, Sequence Data, Image Data or high Dimensional Data, Data Augmentation, Regularization, Dropout, All kind of loss functions and Non Linear functions. My toolset is based around Python, with Tensorflow as the main framework, supported by other libraries like pandas, numpy and other Data Science oriented utils.
I know lot of stuff, is not that enough for get a Junior Level underpaid job? truly dont get it, what is required for get a job? not even enough for get an interview?
I have some dev friends and everyone seems to be able to land jobs, why im not landing even an interview?
I will keep pushing my Dev career, is that or starve to death. But i will love to read your suggestions! how i can approach this?
i will leave here my relevant social presence:
https://linkedin.com/in/...
https://github.com/ElPapi42
Thanks in advance!9








Top Tags
Weekly Rant
View