
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
POSTMORTEM
"4096 bit ~ 96 hours is what he said.
IDK why, but when he took the challenge, he posted that it'd take 36 hours"
As @cbsa wrote, and nitwhiz wrote "but the statement was that op's i3 did it in 11 hours. So there must be a result already, which can be verified?"
I added time because I was in the middle of a port involving ArbFloat so I could get arbitrary precision. I had a crude desmos graph doing projections on what I'd already factored in order to get an idea of how long it'd take to do larger
bit lengths
@p100sch speculated on the walked back time, and overstating the rig capabilities. Instead I spent a lot of time trying to get it 'just-so'.
Worse, because I had to resort to "Decimal" in python (and am currently experimenting with the same in Julia), both of which are immutable types, the GC was taking > 25% of the cpu time.
Performancewise, the numbers I cited in the actual thread, as of this time:
largest product factored was 32bit, 1855526741 * 2163967087, took 1116.111s in python.
Julia build used a slightly different method, & managed to factor a 27 bit number, 103147223 * 88789957 in 20.9s,
but this wasn't typical.
What surprised me was the variability. One bit length could take 100s or a couple thousand seconds even, and a product that was 1-2 bits longer could return a result in under a minute, sometimes in seconds.
This started cropping up, ironically, right after I posted the thread, whats a man to do?
So I started trying a bunch of things, some of which worked. Shameless as I am, I accepted the challenge. Things weren't perfect but it was going well enough. At that point I hadn't slept in 30~ hours so when I thought I had it I let it run and went to bed. 5 AM comes, I check the program. Still calculating, and way overshot. Fuuuuuuccc...
So here we are now and it's say to safe the worlds not gonna burn if I explain it seeing as it doesn't work, or at least only some of the time.
Others people, much smarter than me, mentioned it may be a means of finding more secure pairs, and maybe so, I'm not familiar enough to know.
For everyone that followed, commented, those who contributed, even the doubters who kept a sanity check on this without whom this would have been an even bigger embarassement, and the people with their pins and tactical dots, thanks.
So here it is.
A few assumptions first.
Assuming p = the product,
a = some prime,
b = another prime,
and r = a/b (where a is smaller than b)
w = 1/sqrt(p)
(also experimented with w = 1/sqrt(p)*2 but I kept overshooting my a very small margin)
x = a/p
y = b/p
1. for every two numbers, there is a ratio (r) that you can search for among the decimals, starting at 1.0, counting down. You can use this to find the original factors e.x. p*r=n, p/n=m (assuming the product has only two factors), instead of having to do a sieve.
2. You don't need the first number you find to be the precise value of a factor (we're doing floating point math), a large subset of decimal values for the value of a or b will naturally 'fall' into the value of a (or b) + some fractional number, which is lost. Some of you will object, "But if thats wrong, your result will be wrong!" but hear me out.
3. You round for the first factor 'found', and from there, you take the result and do p/a to get b. If 'a' is actually a factor of p, then mod(b, 1) == 0, and then naturally, a*b SHOULD equal p.
If not, you throw out both numbers, rinse and repeat.
Now I knew this this could be faster. Realized the finer the representation, the less important the fractional digits further right in the number were, it was just a matter of how much precision I could AFFORD to lose and still get an accurate result for r*p=a.
Fast forward, lot of experimentation, was hitting a lot of worst case time complexities, where the most significant digits had a bunch of zeroes in front of them so starting at 1.0 was a no go in many situations. Started looking and realized
I didn't NEED the ratio of a/b, I just needed the ratio of a to p.
Intuitively it made sense, but starting at 1.0 was blowing up the calculation time, and this made it so much worse.
I realized if I could start at r=1/sqrt(p) instead, and that because of certain properties, the fractional result of this, r, would ALWAYS be 1. close to one of the factors fractional value of n/p, and 2. it looked like it was guaranteed that r=1/sqrt(p) would ALWAYS be less than at least one of the primes, putting a bound on worst case.
The final result in executable pseudo code (python lol) looks something like the above variables plus
while w >= 0.0:
if (p / round(w*p)) % 1 == 0:
x = round(w*p)
y = p / round(w*p)
if x*y == p:
print("factors found!")
print(x)
print(y)
break
w = w + i
Still working but if anyone sees obvious problems I'd LOVE to hear about it.36 -
I happen to be the only girl in my small dev team of 4 males plus me.
I'm freaking tired of hearing 'hey guys','how are you doing guys', 'what's the update guys' in every meeting/call when one of them is addressing the rest of us.
Yeah i know I/they can't do anything about it. I somehow grew numb to hearing it, but sometimes hearing it one thousand time in a single call is driving me crazy.
I once mentioned it to an a senior dev who happens to be the one using the g word the most during meeting.
Me: could you please stop saying guys all the time, I'm not a guy.
Him: what do you want me to say, 'hey guys and a girl?!'
Me: ... -_- (internally: seriously!!)
Uugh.23 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!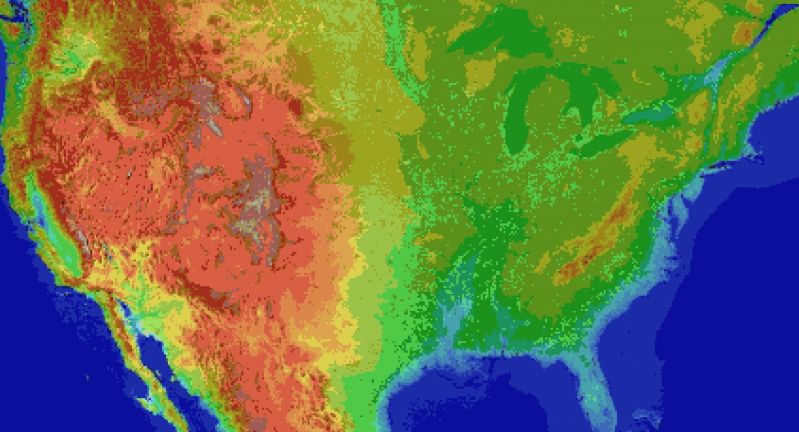 5
5 -
Boss: “Our ecommerce conversions in Google Analytics are less than the actual pace of orders.”
Me: “Nothing has changed in the tracking code or setup. It must be our goals setup which you have to have a Ph.D. to understand, plus whatever mood Google’s algorithms are in today.”
He’s not mad at me. We’re both just confused why Google AdWords, Analytics, and Tag Manager have to be so damn hard to get right. I’ve never been able to do it right. And most data is thrown out because people browse websites while logged into their Google Account, which makes their clickstream disappear and become unattributable because of understandable privacy policies. I don’t want my data tracked when I’m logged in either!
So now we have had to hire specialists at several thousand dollars per month to figure this out. -
Woo time for a Chromebook rant against Samsung!
So they just 'revised' the Chromebook plus (Currently using v1 to write this) and I was intrigued because they ditched the Samsung made ARM chips for an intel CPU.... Buuuuuuuuuut... It's a fucking celeron... Of all fucking things to put in a half thousand dollar laptop, at least an m3 would be useful. Then I find out they are ditching the full metal body, it's heavier, thicker, same 3GB of RAM, ditching the 3:2 aspect ratio (Fucking why?!) and the 'upgraded' keyboard doesn't even have back lighting...
Ugh, makes me want a pixel book more, double the price and a million times the performance and quality -.-3 -
A couple fucking brutal, merciless dungeon moments.
So first, we were having a chill kind of session. Throwing lots of jokes and shit, and I rolled with it. The baddie for the day, I felt inspired, and named him Fawq El-Fuqer, which yes, is very unfortunate.
Anyway, we avoid his goons and reach his impenetrable fortress of chronic masturbation, and it goes as well as you think. The rogue says hey, we gotta get him with his pants down (pause) literally. The cleric is skeptical at first, but she comes around to it.
And so we do it. I spin this tale of a man who's got a schedule tighter than his fucking asshole. El-Fuqer meticulously plans his shits, he makes it a whole ritual, even gives it a special name: Mud O'Clock.
We wait for his alarm to ring, and spring into action while he's taking a fat stinking fucking dump. The warrior kicks down the bathroom door and corners El-Fuqer while he's on the shitter, demanding satisfaction for their past romantic involment that's been strongly been hinted at, you see, she said Fuck the Fucker and I, that's history. And that's enough for a subplot if you ask me.
So where was I? Ah, yes, the rogue bursts in through the window shouting out "Mud O'Clock MOTHER FUCKER!!" and we immortalize the moment in the finest silks. The wizard then does a little Bane impression for some reason and a multitude of loud 'plops' are heard as El-Fuqer evacuates the entire content of his putrid guts.
He gets roughed up a little, you know nothing like interrogating someone after they nearly shit themselves to death. We reveal some oooh so unexpected plot twist about a portal to goddamn hell and it's like well, crap, we gotta do something about that. So the wizard and the rogue leave to give the warrior and El-Fuqer some, ehem, space to settle their score.
What followed was the most unexpected, most brilliant part of the whole session. She didn't just execute him in a brutal, gruesome manner, no, she went full fucking throttle. Forced El-Fuqer to eat his own cock and balls while sewing his ass shut, then had a bowl of bull testicle salad to drop a montanious fecal cake of biblical proportions upon his face.
Believe it or not, we made it into an emotional moment. Because everyone was shocked by how brutal the affair was. Warrior had a mental breakdown like, uuuh, I'm becoming the monsters I swore to fight ooh no. She starting shaking and crap, ran away and hid in an alley to weep, it begins raining and it's getting very dramatic, so I cook up some spirit of sorrow that goes in and helps her face her fears and shit through the power of friendship or whatever.
Moving on to second moment, this is shorter but I like it best. The cleric and another two extras went to an old shrine to try and prove the wizard wrong about his denial of prophecy. Thing is, they did the ritual wrong. And I'm usually very forgiving but I was feeling nasty after the whole sowing of the asshole thing. So I'm like, uh, I gave you fools VERY PRECISE instructions on how to perform this ritual, and you just did some wacky prayers to the moon nonsense, that's idolatry in-universe and out-of-universe too (depending on who you ask).
So I said fuck it, you guys had it coming. I whip out immortal ten-thousand year old elder sorceress bitch guardian of the holy sphincter, and it gets real pretty fucking quick. She's got sanctified heavy plate armor, blue fire torches coming out they fucking pauldrons, argent greatsword of anal judgement plus infinity, all the juiciest shit.
Anyway, the sorc descends from the sky in a pillar of azure flames and is like yo, drop that idolatrous shit right now or I'm gonna kill you all. They mistake her for angel or some shit, and are like hey chill, we're the good guys. But the sorc doesn't give a shit, and she says shut the fuck up or I'll send you to the Night Eternal, bitch.
I dunno why but the cleric and the other two extras don't get it, so they insist with the whole heyyyy we are not idolaters, we're your friends, we are questing for the mandinga mandango mcguffango. So she bisects one, breaks the neck of another, and decapitates the fucking cleric. It was awesome.
So what did we learn? idk, don't plan your dumps and don't pray to the fucking moon if you're standing on hallowed ground. *****7







Top Tags
Weekly Rant
View