
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I wrote a node + vue web app that consumes bing api and lets you block specific hosts with a click, and I have some thoughts I need to post somewhere.
My main motivation for this it is that the search results I've been getting with the big search engines are lacking a lot of quality. The SEO situation right now is very complex but the bottom line is that there is a lot of white hat SEO abuse.
Commercial companies are fucking up the internet very hard. Search results have become way too profit oriented thus unneutral. Personal blogs are becoming very rare. Information is losing quality and sites are losing identity. The internet is consollidating.
So, I decided to write something to help me give this situation the middle finger.
I wrote this because I consider the ability to block specific sites a basic universal right. If you were ripped off by a website or you just don't like it, then you should be able to block said site from your search results. It's not rocket science.
Google used to have this feature integrated but they removed it in 2013. They also had an extension that did this client side, but they removed it in 2018 too. We're years past the time where Google forgot their "Don't be evil" motto.
AFAIK, the only search engine on earth that lets you block sites is millionshort.com, but if you block too many sites, the performance degrades. And the company that runs it is a for profit too.
There is a third party extension that blocks sites called uBlacklist. The problem is that it only works on google. I wrote my app so as to escape google's tracking clutches, ads and their annoying products showing up in between my results.
But aside uBlacklist does the same thing as my app, including the limitation that this isn't an actual search engine, it's just filtering search results after they are generated.
This is far from ideal because filter results before the results are generated would be much more preferred.
But developing a search engine is prohibitively expensive to both index and rank pages for a single person. Which is sad, but can't do much about it.
I'm also thinking of implementing the ability promote certain sites, the opposite to blocking, so these promoted sites would get more priority within the results.
I guess I would have to move the promoted sites between all pages I fetched to the first page/s, but client side.
But this is suboptimal compared to having actual access to the rank algorithm, where you could promote sites in a smarter way, but again, I can't build a search engine by myself.
I'm using mongo to cache the results, so with a click of a button I can retrieve the results of a previous query without hitting bing. So far a couple of queries don't seem to bring much performance or space issues.
On using bing: bing is basically the only realiable API option I could find that was hobby cost worthy. Most microsoft products are usually my last choice.
Bing is giving me a 7 day free trial of their search API until I register a CC. They offer a free tier, but I'm not sure if that's only for these 7 days. Otherwise, I'm gonna need to pay like 5$.
Paying or not, having to use a CC to use this software I wrote sucks balls.
So far the usage of this app has resulted in me becoming more critical of sites and finding sites of better quality. I think overall it helps me to become a better programmer, all the while having better protection of my privacy.
One not upside is that I'm the only one curating myself, whereas I could benefit from other people that I trust own block/promote lists.
I will git push it somewhere at some point, but it does require some more work:
I would want to add a docker-compose script to make it easy to start, and I didn't write any tests unfortunately (I did use eslint for both apps, though).
The performance is not excellent (the app has not experienced blocks so far, but it does make the coolers spin after a bit) because the algorithms I wrote were very POC.
But it took me some time to write it, and I need to catch some breath.
There are other more open efforts that seem to be more ethical, but they are usually hard to use or just incomplete.
commoncrawl.org is a free index of the web. one problem I found is that it doesn't seem to index everything (for example, it doesn't seem to index the blog of a friend I know that has been writing for years and is indexed by google).
it also requires knowledge on reading warc files, which will surely require some time investment to learn.
it also seems kinda slow for responses,
it is also generated only once a month, and I would still have little idea on how to implement a pagerank algorithm, let alone code it.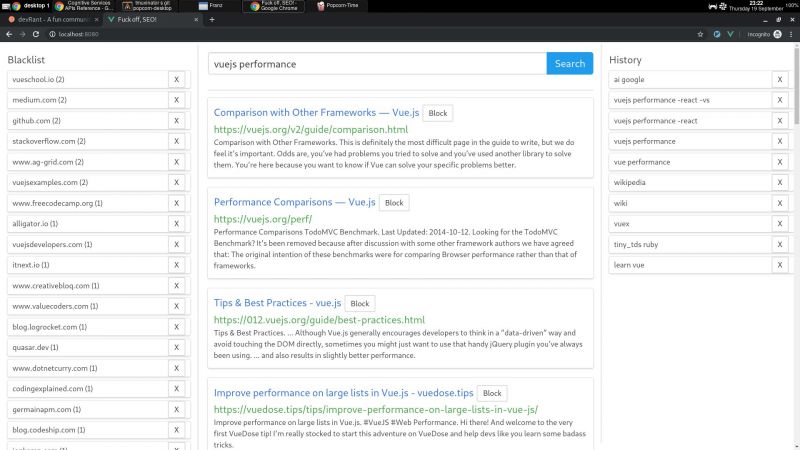 4
4 -
I haven't touched algorithms for many months but needed to create a matching algorithm today.
It has to match using variations of the original key and output the keys that can't be matched.
The feeling in my head felt like I was turning rusty gears n sort of just stumbling through...
I used an N^2 approach but afterwards it just felt wrong... And it took me like an hour of hacking to do it....
Actually I just realized it's an N approach! because all possible matches would be hit by iterating from one of the lists of possible names!
I suddenly feel so proud of my subsconcious...
But still something doesn't feel right...1 -
Boss: “Our ecommerce conversions in Google Analytics are less than the actual pace of orders.”
Me: “Nothing has changed in the tracking code or setup. It must be our goals setup which you have to have a Ph.D. to understand, plus whatever mood Google’s algorithms are in today.”
He’s not mad at me. We’re both just confused why Google AdWords, Analytics, and Tag Manager have to be so damn hard to get right. I’ve never been able to do it right. And most data is thrown out because people browse websites while logged into their Google Account, which makes their clickstream disappear and become unattributable because of understandable privacy policies. I don’t want my data tracked when I’m logged in either!
So now we have had to hire specialists at several thousand dollars per month to figure this out. -
Hi ppl of devRant! I’m not really a dev but I love reading your rants :) I decided to post my first rant because I think I could use some advice from you.
Background: I’m a student just finished my first year at uni. Earlier I applied for a developer intern just for fun and somehow magically got in. However, I'm a statistics major (not even CS!) and only know basic java stuff. I guess they hired me because I speak ok english and a little french? I live in a non-English speaking country but the company has a lot of foreign customers.
The problem is, the longer I stay, the more I feel that they only hired me out of charity *sobs* There isn’t much for me to do, and most of the time I couldn’t understand what my co-workers are doing so I can’t really help them either. Plus, they don’t seem to need my language skill as much, so I kinda feel useless here.
It’s my 5th (maybe already 6th?) week here and the only thing I did was fixing an itty bitty bug that literally needed only one additional line of code. Yes it took me a while to set up the environment, learn js from scratch since they use js for this project, and locate the issue but I’m pretty sure it’d probably take someone who’s familiar with the project, like, 3 mins? And now that I’ve fixed it and the merge request was passed, I’m out of work to do again. I talked to the lead and he pretty much just said “read more of the code”. Guess I can do that. I’ve spent like 4 days going through the code but is this really promising?
I want to spend time on learning actual stuff rather than yet another resume ornament. So what should I do? Should I ask for more help/more work to do, or keep learning on my own (I’m quite interested in algorithms, maybe I could make use of my time to study that?), or even leave?
Sorry for the long rant. I know ass-kicking devs probably hate useless, underqualified ppl at work in real life but believe me it really hurts to be one and I hate myself enough already so I’d appreciate any thoughts/advice :/10 -
In an algorithm class, professor introduced us to some simple search algorithms (bubble sort, selection sort, insertion sort, shell sort). He did a quite decent job and most of the students were able to grasp the code and understand the differences in those algorithms. But then he spoiled his whole lecture with one additional slide. There he proposed an optimization: Instead of using a temporary swap variable, we just could use the first array element (or the zeroth element, respectively: the one ad index 0) for doing all the swapping. We just had to document that, so that the caller would "leave the first position of the array empty", resulting in "cleaner code". And he did that in the same class where he used Big-O notation to argue about runtime complexity. But having the caller to resize the array and to shift all the elements by one position did not matter to him at all, because it was "not part of the actual algorithm".1
-
The hype of Artificial Intelligence and Neutral Net gets me sick by the day.
We all know that the potential power of AI’s give stock prices a bump and bolster investor confidence. But too many companies are reluctant to address its very real limits. It has evidently become a taboo to discuss AI’s shortcomings and the limitations of machine learning, neural nets, and deep learning. However, if we want to strategically deploy these technologies in enterprises, we really need to talk about its weaknesses.
AI lacks common sense. AI may be able to recognize that within a photo, there’s a man on a horse. But it probably won’t appreciate that the figures are actually a bronze sculpture of a man on a horse, not an actual man on an actual horse.
Let's consider the lesson offered by Margaret Mitchell, a research scientist at Google. Mitchell helps develop computers that can communicate about what they see and understand. As she feeds images and data to AIs, she asks them questions about what they “see.” In one case, Mitchell fed an AI lots of input about fun things and activities. When Mitchell showed the AI an image of a koala bear, it said, “Cute creature!” But when she showed the AI a picture of a house violently burning down, the AI exclaimed, “That’s awesome!”
The AI selected this response due to the orange and red colors it scanned in the photo; these fiery tones were frequently associated with positive responses in the AI’s input data set. It’s stories like these that demonstrate AI’s inevitable gaps, blind spots, and complete lack of common sense.
AI is data-hungry and brittle. Neural nets require far too much data to match human intellects. In most cases, they require thousands or millions of examples to learn from. Worse still, each time you need to recognize a new type of item, you have to start from scratch.
Algorithmic problem-solving is also severely hampered by the quality of data it’s fed. If an AI hasn’t been explicitly told how to answer a question, it can’t reason it out. It cannot respond to an unexpected change if it hasn’t been programmed to anticipate it.
Today’s business world is filled with disruptions and events—from physical to economic to political—and these disruptions require interpretation and flexibility. Algorithms alone cannot handle that.
"AI lacks intuition". Humans use intuition to navigate the physical world. When you pivot and swing to hit a tennis ball or step off a sidewalk to cross the street, you do so without a thought—things that would require a robot so much processing power that it’s almost inconceivable that we would engineer them.
Algorithms get trapped in local optima. When assigned a task, a computer program may find solutions that are close by in the search process—known as the local optimum—but fail to find the best of all possible solutions. Finding the best global solution would require understanding context and changing context, or thinking creatively about the problem and potential solutions. Humans can do that. They can connect seemingly disparate concepts and come up with out-of-the-box thinking that solves problems in novel ways. AI cannot.
"AI can’t explain itself". AI may come up with the right answers, but even researchers who train AI systems often do not understand how an algorithm reached a specific conclusion. This is very problematic when AI is used in the context of medical diagnoses, for example, or in any environment where decisions have non-trivial consequences. What the algorithm has “learned” remains a mystery to everyone. Even if the AI is right, people will not trust its analytical output.
Artificial Intelligence offers tremendous opportunities and capabilities but it can’t see the world as we humans do. All we need do is work on its weaknesses and have them sorted out rather than have it overly hyped with make-believes and ignore its limitations in plain sight.
Ref: https://thriveglobal.com/stories/...6 -
(I'm not completely sure of what I'm saying here, so don't take this too seriously)
Settling on a language to write the api for ranterix is hard.
I'm finding a lot of things about elixir to be insanely good for a stable api.
But I'm having a lot of gripes with the most important elixir web framework, phoenix.
Take a look at this piece of code from the phoenix docs:
defmodule Hello.Repo.Migrations.CreateUsers do
use Ecto.Migration
def change do
create table(:users) do
add :name, :string
add :email, :string add :bio, :string
add :number_of_pets, :integer
timestamps()
end
end
end
Jesus christ, I hate this shit.
Wtf are create, add and timestamps. Add is somehow valid inside the create, how the fuck is that considered good code? What happens if you call timestamps twice? It's all obscure "trust me, it works" code.
It appears to be written by a child.
js may have a million problems. But one thing I like about CJS (require) or ESM (import) is that there's nothing unexplained. You know where the fuck most things come from.
You default export an eatShit() function on one file and import it from another, and what do you get?
The goddamn actual eatShit function.
require is a function the same way toString is a function and it returns whatever the fuck you had exported in the target file.
Meanwhile some dynamic langs are like "oh, I'll just export only some lang construct that i expect you to specify and put that shit in fucking global of the importing file".
Js is about the fucking freedom. It won't decide for you what things will files export, you can export whatever the fuck you want, strings, functions, classes, objects or even nothing at all, thanks to module.exports object or export statement.
And in js, you can spy on anything external, for example with (...args) => debugger; fnToSpyOn(...args)
You can spoof console.log this way to see what the fuck is calling it (note: monkey patching for debugging = GOOD, for actual programming = DOGSHIT)
To be fair though, that is possible because of being a dynamic lang and elixir is kind of a hybrid typed lang, fair enough.
But here's where i drop the shit.
Phoenix takes it one step further by following the braindead ruby style of code and pretty DSLs.
I fucking hate DSLs, I fucking hate abstraction addiction.
Get this, we're not writing fucking poetry here. We're writing programs for machines for them to execute.
Machines are not humans with emotions or creativity, nor feel.
We need some level of abstraction to save time understanding source code, sure.
But there has to be a balance. Languages can be ergonomic for humans, but they also need to be ergonomic for algorithms and machines.
Some of the people that write "beautiful" "zen" code are the folks that think that everyone who doesn't push the pretty code agenda is a code elitist that doesn't want "normal" people to get into programming.
Programming is hard, man, there's no fucking way around it.
Sometimes operating system or even hardware details bleed into code.
DSLs are one easy way to make code really really easy to understand, but also make it really fucking hard to debug or to lose "programming meaning".7 -
>start new job, not very professionally experienced dev
>spend couple of months working on a feature that is supposed to be an MVP kind of thing, be rushed to finish and told to cut corners because it's "just an MVP", still lose sleep and have relationship suffer (and ultimately ruined) as I try to not lose deadlines created by the boss with questions like "you can have this done by <very soon>, right?"
>frontend created by fellow developer is a garbled mess of repeated code and questionably implemented subpages, frontend dev apparently copies CSS from Figma and pastes it into new non-reusable React components as envisioned by designer, I am tasked with making sense of the mess and adding in API consumption, when questioning boss what to do with the mess I am often told to discard stuff that the frontend dev has made and just reuse his styling; all of this on top of implementing the backend feature that a previous developer wasn't able to do
>specs change along the way, I had been using a library as a helper in some part of the original feature, now the boss sees that and (without further testing the library) promises CEO that we'll add that as a separate subfeature, but the performance of the library is garbage for larger inputs and causes problems, is basically shit that might not have been shit if we had implemented it ourselves, however at this point CEO has promised new feature to some customers, all the actual sense of responsibility falls upon my hands
>marketing folk see halfway done application and ask for more changes
>everything is rushed to launch, plenty of things aren't implemented or are done halfway
>while I'm waiting for boss to deploy, I'm called up to company office by CEO, and get new task that is pretty cool and will actually involve assessing various algorithms and experiment with them, rather than just stitching API calls and endpoints together, it involves delving into a whole new field of CS that I never had the opportunity to delve into before
>start working on cool task, doing research, making good progress
>boss finally deploys feature I had been originally implementing
>cut corners of original boring insane feature start showing up, now I have to start fixing them instead of working on cool task, however the cool task also has a deadline which is likely expected to be met
I'm not sure if I'm having it bad or not, is this what a whole career in software development will look like?6 -
I started coding as soon as year 5 of school. It was more learning how to write algorithms at first. This gave me the necessary grounds for being able to solve complex problems in my head by splitting them up. Actual programming started out in year 9 when I first met Pascal, younger programmers probably don't even know what it is(I'm 20 and I say that) 😂. Then I moved on to C and C++ in the following year and that made me realise that all languages are really similar.
-
How many of you have formalized knowledge in computer science theory? Do you find yourself using that knowledge in your daily engineering life? For example, knowing random search algorithms, or obscure data structures. I ask this because of the modern "technical interview" trending towards discrete math instead of actual programming ability. Instead of coding projects I care about or reading research papers, I'm just doing discrete math problems to prep for recruiting. While it's not the worst thing to do I just wish there was a more direct way of interviewing a person's engineering abilities.1









Top Tags
Weekly Rant
View