
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
A CMS raping WordPress so hard up the ass till there is no tomorrow. I hate that bastardized piece of fuck. “Hey I want you to fix my page and its wordpress. I pay 20 bucks.“ Well fuck you too sir. Wordpress is no cms you wanna be coders. Get back to your fucking photoshop and design something original! Every fucking wp page looks the same. Every “nice feature“ is some kind of monkeypatched workarround. No problem i set preview pictures for every post just to enable some weird slider to function.
I also love those buttfucked files with just a “require foo“ which also just requires “bar“. Drop that fuck. Implement autoloading. Nobody uses php4 anymore step into the future. “easy to learn“ fuck me and fuck you untill you vomit jizz! Clusterfucked spaghetticode thats easy, easy to put another rotten load of clusterfuck on top. Also those security features. I put an empty index.php to prevent directory traversal. N I C E! Stop using wordpress as CMS, its a blog engine. Nothing great has every been written on top of wordpress and never will. I dare you to deny everything related to it and if you are one of those designer guyd, you can gargle my jizz you fucknut!
Starting 2017 i will start a counter and rape every 10th Wordpress which gets abused as cms i encounter into oblivion on their 0,99$ webhosting shit.
Fuck this I'm so mad about that crap17 -
Just added an RSS feed to my blog (https://nixmagic.com/rssfeed.xml/ if you're interested), and as I was testing it out in an RSS reader, I noticed that the reader basically just renders the webpage as if it were a web browser.
Heh.. I have only the Webkit engine on my computer, so I suppose it's just using that in the backend or something like that? How much RAM does that consume?
*looks at Task Manager*
67MB. I shit you not.. 67 megabytes. And that is rendering an entire website with no noticeable differences from a regular web browser.
Chrome: *gobble*8 -
oauth (Yahoo) just opened sourced their data-processing & search engine!
It looks fricken cool, can't wait to play with it... and even more I can't wait to see what people make with it!
Yahoo!
[announcement](https://oath.com/press/...)
[docs](http://docs.vespa.ai/documentation/...)4 -
I wrote a node + vue web app that consumes bing api and lets you block specific hosts with a click, and I have some thoughts I need to post somewhere.
My main motivation for this it is that the search results I've been getting with the big search engines are lacking a lot of quality. The SEO situation right now is very complex but the bottom line is that there is a lot of white hat SEO abuse.
Commercial companies are fucking up the internet very hard. Search results have become way too profit oriented thus unneutral. Personal blogs are becoming very rare. Information is losing quality and sites are losing identity. The internet is consollidating.
So, I decided to write something to help me give this situation the middle finger.
I wrote this because I consider the ability to block specific sites a basic universal right. If you were ripped off by a website or you just don't like it, then you should be able to block said site from your search results. It's not rocket science.
Google used to have this feature integrated but they removed it in 2013. They also had an extension that did this client side, but they removed it in 2018 too. We're years past the time where Google forgot their "Don't be evil" motto.
AFAIK, the only search engine on earth that lets you block sites is millionshort.com, but if you block too many sites, the performance degrades. And the company that runs it is a for profit too.
There is a third party extension that blocks sites called uBlacklist. The problem is that it only works on google. I wrote my app so as to escape google's tracking clutches, ads and their annoying products showing up in between my results.
But aside uBlacklist does the same thing as my app, including the limitation that this isn't an actual search engine, it's just filtering search results after they are generated.
This is far from ideal because filter results before the results are generated would be much more preferred.
But developing a search engine is prohibitively expensive to both index and rank pages for a single person. Which is sad, but can't do much about it.
I'm also thinking of implementing the ability promote certain sites, the opposite to blocking, so these promoted sites would get more priority within the results.
I guess I would have to move the promoted sites between all pages I fetched to the first page/s, but client side.
But this is suboptimal compared to having actual access to the rank algorithm, where you could promote sites in a smarter way, but again, I can't build a search engine by myself.
I'm using mongo to cache the results, so with a click of a button I can retrieve the results of a previous query without hitting bing. So far a couple of queries don't seem to bring much performance or space issues.
On using bing: bing is basically the only realiable API option I could find that was hobby cost worthy. Most microsoft products are usually my last choice.
Bing is giving me a 7 day free trial of their search API until I register a CC. They offer a free tier, but I'm not sure if that's only for these 7 days. Otherwise, I'm gonna need to pay like 5$.
Paying or not, having to use a CC to use this software I wrote sucks balls.
So far the usage of this app has resulted in me becoming more critical of sites and finding sites of better quality. I think overall it helps me to become a better programmer, all the while having better protection of my privacy.
One not upside is that I'm the only one curating myself, whereas I could benefit from other people that I trust own block/promote lists.
I will git push it somewhere at some point, but it does require some more work:
I would want to add a docker-compose script to make it easy to start, and I didn't write any tests unfortunately (I did use eslint for both apps, though).
The performance is not excellent (the app has not experienced blocks so far, but it does make the coolers spin after a bit) because the algorithms I wrote were very POC.
But it took me some time to write it, and I need to catch some breath.
There are other more open efforts that seem to be more ethical, but they are usually hard to use or just incomplete.
commoncrawl.org is a free index of the web. one problem I found is that it doesn't seem to index everything (for example, it doesn't seem to index the blog of a friend I know that has been writing for years and is indexed by google).
it also requires knowledge on reading warc files, which will surely require some time investment to learn.
it also seems kinda slow for responses,
it is also generated only once a month, and I would still have little idea on how to implement a pagerank algorithm, let alone code it.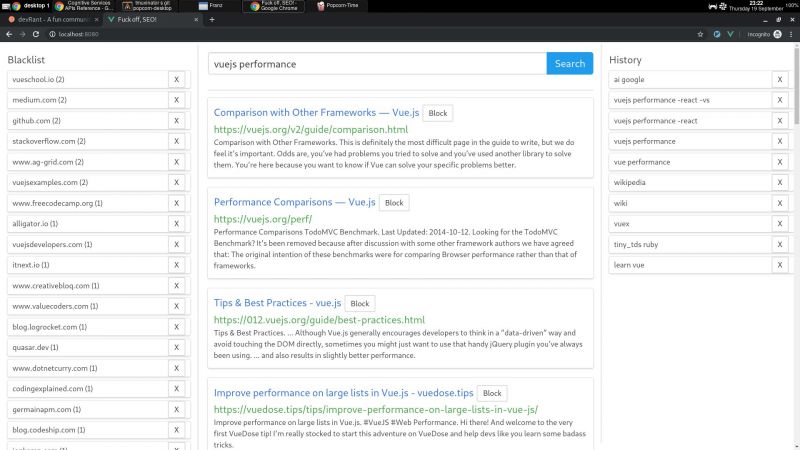 4
4 -
So for anyone else who uses Gamemaker studio 2... For the love of all that is holy get excited for the updates coming to GML!
Finally it looks like it's becoming more and more off a legitimate language with the addition of lightweight objects and inline methods...
Maybe people will start taking GML seriously and Gamemaker won't be considered a 'basic' engine anymore :-D
All can be found here: https://yoyogames.com/blog/514/...5 -
I am pulling my hair out on ducking low level stuff. This is why people (more importantly me!) should have the chance to learn, rather than assume how things work.
Has anyone of you detailed resources on how linking objects into shared libraries really works ? Especially Name Resolution. All those ducking tutorials and bloody blog post just have simple examples and explain shit not in detail!
Even ducking man pages on gcc/ld don’t help me out! Maybe I’m too dumb to type the right words into me search engine. I’d even love to read a bloody paper book.16 -
Well I was laid off at my last company with 6 weeks paid holiday at the end of my employment - since one of my hobbies is volunteering at the red cross as paramedic / ambulance driver, I was on duty quite often in those 6 weeks but since this job does not pay well, I had to look for something different and so I did - after those 6 weeks.
I found one quite nice job posting online at 1 am in the morning, sent my application out at 2 am and went to bed as I had a 12 hours shift at that day. I didn't really think that I'd get a reply but at 6 pm I got a call, talked to the guy and he asked me if I could come in the next day and talk to him in person and show him some stuff I did lately. I didn't really have projects to show as most of my previous work was under a NDA and so I just developed a small blog engine to show off (the main thing he wanted to see was my coding style). So I went there at 7:15pm , talked to them and at 10pm I got the contract - I signed the contract about 48 hours after I applied to the job :)2 -
I write a blogpost twice a year and then spend 4 hours fixing my handcrafted blog engine. It's healthy to stay in the loop regarding the latest Vite, Typescript and React bugs and inconsistencies I guess.
Anyway, I explained a cool pattern with Rust traits:
https://lbfalvy.com/blog/...20 -
I've been out of the loop with websites and frontends for a while. Now, is it me or is it just overengineered to make a static website that's not a blog these days?
I mean, I need to make a landing page. 6 sections + footer. And I don't want to end up with a 600+ lines html file. With tailwind possibly.
JEKYLL
I've used it a few times, and after 3 years I still get some weird error when installing everything. Maybe it's trivial, but I know shit about ruby. Plus, I don't need ruby for anything else, and the official Docker image just doesn't work, exactly like the quickstart tutorial. 3 years later, same issues.
HUGO
I like this guy but god, the docs are just unreadable, it's not compatible with tailwind 3.x (or smth) and it's been a pain to build a user-configurable homepage. Plus, it does more than half of the work by itself, Fair enough, it's supposed to be used for blogs.
ANY OTHER "JAMSTACK" BULLSHIT
Anything is either a blogging engine or delivers some crappy javascript blob from hell. I just need an html document, that weird thingie the whole World Wide Web was built upon, broken into pieces so I can keep my sanity.
Looking forward to get the fucking AWS Solutions Architect. Looking even more forward to build my farm.8 -
Stuff I need to finish:
PHP framework
Music player for android
Nginx module for crypting mp4 fragments
Personal blog engine
Unit and data converter service
Personal transactions application
Too much, just too much...











Top Tags
Weekly Rant
View