
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
At a previous job, I worked with a graphic designer who knew it all.
The first design he gave me, all font sizes were in points, and way too big.
I asked for them in pixels.
He said points and pixels are exactly the same.
I explained that they were not, when you're using a browser. He got visibly angry, and stormed out of the office to cool down.
When he came back, I sent him a link explaining the difference between points and pixels for digital media.
He sent me pixel sizes.
Next project, same exact thing happens, complete with him angrily storming out of the room.
By the third project, I just started picking my own font sizes, and ignored his point specs.14 -
Our CEO had a virtual town hall using Zoom and now have a sign language interpreter box as a regular feature... To go along with all the Inclusion stuff...
The most immediate problem though is they didn't turn on auto-captions...
I don't know sign but am deaf so needed the captions which it turns out you can get using the Google Recorder app on Pixels. (This is literally like a fuck you to non-Pixel users and Zoom which disables Live Captions in conferences and recording full transcripts).
Anyway I left it own and near the end, a speaker was like "we're getting a lot of likes and positive feedback about the interpreter box! See how small changes make such a big difference?!"
And well of course in my mind I'm going "uh.... No."
I'll just go back to not caring about anything that isn't related to how much I make.2 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!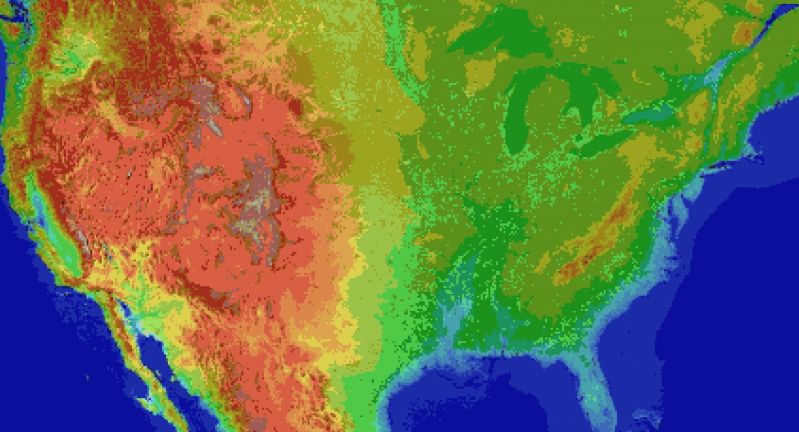 5
5 -
When you do work on a front end ticket. You implement the things as UX tells you to, make a few mistakes, fix those as well when QA catches them.
But then UX realizes other improvements they can make , so you toss some of those in and move some of the other shit to tech debt to avoid possibly failing the sprint due to rabbit hole of front end awfulness because you suck at your job.
Then later somebody else a couple degrees above you in job hierarchy, notes a couple tips and things you could fix unrelated to your ticket. But when will it ever end or do. I suck and hate front end work, AY LMAO LEMME SUBMIT THE SAME SHIT WHICH RENDERS DIFFERENTLY BETWEEN CHROME vs CHROMIUM AND EVERYTHING THAT USES CHROMIUM.1 -
My work product: Or why I learned to get twitchy around Java...
I maintain a Java based test system, that tests a raster image processor. The client is a Java swing project that contains CORBA bindings to the internal API of the raster image processor. It also has custom written UI elements and duplicated functionality that became available in later versions of Java, but because some of the third party tools we use don't work with later versions of Java for some reason, it's not possible to upgrade Java to gain things as simple as recursive directory deletion, yes the version of Java we have to use does not support something as simple as that and custom code had to be written to support it.
Because of the requirement to build the API bindings along with the client the whole application must be built with the raster image processor build chain, which is a heavily customised jam build system. So an ant task calls out to execute a jam task and jam does about 90% of the heavy lifting.
In addition to the Java code there's code for interpreting PostScript files, as these can be used to alter the behaviour of the raster image processor during testing.
As if that weren't enough, there's a beanshell interface to allow users to script the test system, but none of the users know Java well enough to feel confident writing interpreted Java scripts (and that's too close to JavaScript for my comfort). I once tried swapping this out for the Rhino JavaScript interpreter and got all the verbal support in the world but no developer time to design an API that'd work for all the departments.
The server isn't much better though. It's a tomcat based application that was written by someone who had never built a tomcat application before, or any web application for that matter and uses raw SQL strings instead of an orm, it doesn't use MVC in any way, and insane amount of functionality is dumped into the jsp files.
It too interacts with a raster image processor to create difference masks of the output, running PostScript as needed. It spawns off multiple threads and can spend days processing hundreds of gigabytes of image output (depending on the size of the tests).
We're stuck on Tomcat seven because we can't upgrade beyond Java 6, which brings a whole manner of security issues, but that eager little Java updated will break the tool chain if it gets its way.
Between these two components we have the Java RMI server (sometimes) working to help generate image data on the client side before all images are pulled across a UNC network path onto the server that processes test jobs (in PDF format), by reading into the xref table of said PDF, finding the embedded image data (for our server consumed test files are just flate encoded TIFF files wrapped around just enough PDF to make them valid) and uses a tool to create a difference mask of two images.
This tool is very error prone, it can't difference images of different sizes, colour spaces, orientations or pixel depths, but it's the best we have.
The tool is installed in both the client and server if the client can generate images it'll query from the server which ones it needs to and if it can't the server will use the tool itself.
Our shells have custom profiles for linking to a whole manner of third party tools and libraries, including a link to visual studio 2005 (more indirectly related build dependencies), the whole profile has to ensure that absolutely no operating system pollution gets into the shell, most of our apps are installed in our home directories and we have to ensure our paths are correct for every single application we add.
And... Fucking and!
Most of the tools are stored as source bundles in a version control system... Not got or mercurial, not perforce or svn, not even CVS... They use a custom built version control system that is built on top of RCS, it keeps a central database of locked files (using soft and hard locks along with write protecting the files in the file system) to ensure users can't get merge conflicts by preventing other users from writing to the files at all.
Branching is heavy weight and can take the best part of a day to create a new branch and populate the history.
Gathering the tools alone to build the Dev environment to build my project takes the best part of a week.
What should be a joy come hardware refresh year becomes a curse ("Well fuck, now I loose a week spending it setting up the Dev environment on ANOTHER machine").
Needless to say, I enjoy NOT working with Java. A lot of this isn't Javas fault, but there's a lot of things that Java (specifically the Java 6 version we're stuck on) does not make easy.
This is why I prefer to build my web apps in python or node, hell, I'd even take Lua... Just... Compiling web pages into executable Java classes, why? I mean I understand the implementation of how this happens, but why did my predecessor have to choose this? Why?2





Top Tags
Weekly Rant
View