
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
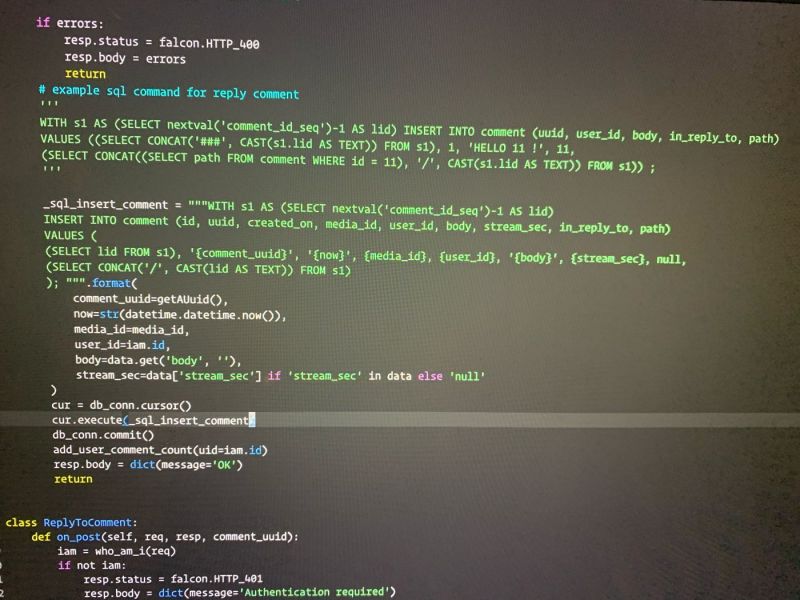
This fucking stupid asshole developer, wrote every single SQL execution with string formatting. Made me a full sleepless night fixing this shit. Isn’t this a classical SQL injection sample?
 15
15 -
Ahhh yes Prof, because I really want to be doing more work than I need to be...
// Tedious string concatenation.
System.out.println("a: " + a + " b: " + b);
// Output using string formatting.
System.out.printf("a: %d b: %d\n", a, b);
But, hey that's just my opinion. 3
3 -
Fuck this I need to ventilate.
Thinking about job change because maintaining and extending 3 years old codebase (flask project) is FUCKIN exhausting. It was badly written since start by someone who obviously didn't know much about python. (Going by commit history.)
Examples:
- if var != None / if var == None
- if var is not None / if var is None (well..)
- Returning self-parsed obscure JSONs from dict variable
- Serializing dictionaries into database by str() (both sqlalchemy and mysql support JSON format) - THEY ARE ALMOST UNUSABLE OTHER WAY AROUND (luckily, python can deal even with that)
- celery tasks, the way they are called they BLOCK the whole flask (not bad in itself, but if connection breaks there are no errors, nothing it just hangs)
- obscure generator/yielding that contains return of flask's response in itself
- creating fifteen thousands of variables one by one where they would look so nicely as dict keys, and hey they are then both MANUALLY SERIALIZED into returning dict by "%s" (string formatting) [okey, some of them are objecst like datetime but MATE WTF]
- many, many more, PEP lint shall not pass
I would rather deal with fresh startup owners wanting me to program unicorns in one week then trying to extend and manage zombie-like projects.
Nothing personal against the firm I actually like the place.3 -
I once made an oopsie in an API for a logistics provider (one of the biggest in Germany...).
To understand the oopsie...
Based on input data a string must be created containing several hex / string / formatted values.
Think of ...
$return .= sprintf("%02X", ...)
I think there were around 15 to 20 lines, although more complicated.
The bug happened because I had a brainfart.
What was previously one line with... Many many many many variables, I had to split into multiple lines since internal stuff changed and it was impossible to change this oneliner of hell with >50 formatting codes.
Of course we didn't test everything.
XD
What we didn't test was - funnily enough - wether the casting was correct in all cases.
I misplaced a formatting code.
And we had a major brainfart because we tested integer, but not double / float values....
We sent for a long time packages much cheaper than allowed (took thw logistics provider nearly 3-4 months to realize this :) ).
Spot the difference:
@highlight
print sprintf("%01.2s", $money).PHP_EOL;
print sprintf("%01.2f", $money).PHP_EOL;1 -
Recently installed SonarQube and its been amazing to see the level of code quality (or lack thereof)
Some projects have 30 to 60 days of technical debt and I found a few files with a cyclomatic complexity over 100. I’m still learning what the “good” numbers should be.
Yesterday, couple of devs were very proud they were going to start reducing the numbers, they started with one of my solutions that had 5 minutes of technical debt. Yes, 5 minutes.
DevA: “OMG…look at this…it has a cyclomatic complexity of 11…that’s terrible. I thought we were supposed to be professional developers.”
DevB: “And take a look at this, he used the double-slash instead of a triple slash for comments. How does any of code even compile?!”
Me: “Maybe we should tweak some of those SonarQube rules so they make more sense to our code base. We’re never going to use unicode, so all those string culture warnings should go away and code comment formatting? Who cares? Be happy we have comments. I think we should also focus on the bigger fish in that pond. The CRM project is one of the biggest and has a lot of improvement opportunities.”
DevB: “There you go again, don’t bring me problems, bring me solutions..ha ha”
DevA: “Yea, no kidding …hey…did you see the logger? OMG…the whole class is over 25 lines…we gotta split that up into smaller projects so it’s more manageable.”
It’s a good thing our revenue stream isn’t dependent on people getting work done.3 -
Do you think my credit card company has a big bounty? String formatting really isn't that difficult.
 1
1 -
Saw this in the Python project codebase today:
arg = '\"foo\"'
Which is funny, because '\"foo\"' == '"foo"' -
we don't really need data types. By default, everything should be string. When you do addition, when the string has nothing but digits, commas and periods, they should be parsed added as numbers. Else, they should be concatenated. If that string-number formatting doesn't match any conventional formatting of any locale, it's a string. Same number-inferring behavior should be implemented when comparing things. There should be no type casting because there is just one type, so every comparison is type-exact. "true" and "false" are special strings that won't throw an error during comparison. Comparing two strings using less, more, less than or equal and more than or equal always throw an error.
Dates are ISO strings. Every other thing is not a date.
We basically sieve the data starting with the strictest conditions down to more forgiving conditions, then down to no conditions at all where it will be interpreted as just string. ISO date requires a very specific formatting, so we should check that first. Then, let's check for a formatted number. Then, a boolean. If nothing clicked, it's a string.
Oh, and every string is automatically trimmed, so it can't start or end with any kind of space.
No classes, no procedures, no constants, no switch operator. Also, no methods, just a lot of helper functions.
Performance will be lacking compared to languages with static types, but performance is not a priority here — this is the language for code monkeys and their AI counterparts. It should only be used for making trivial client-server prototype apps that could've been replaced by Excel if only people knew how to use it, at passable quality, that work reasonably fast on modern hardware.
Those apps will be deprecated because the company went out of business/because the project was proven to not be financially viable in several months anyway.
UI should be rendered not using a webview, but using a lightweight cross-platform UI engine written in a proper language like C++. There should be no semantic tags — every UI element acts like a div would. Everything is measured in pixels and milliseconds. All colors are #rrggbbaa. All vector graphics are SVG, all raster graphics are AVIF. All sounds are Opus. All videos are AV1. All UIs are reactive, Vue style, e.g. you change a variable and the UI updates itself in the right way every time.
Add some junior devs paired with GPT-4.5 or any super-expensive LLM, sprinkle with some Extreme Go-Horse management style (https://hackernoon.com/you-might-be...), and boom, we recreated Zergs but in the tech space. Let's solve software by brute force.10 -
I use the ICU format often for translation because it's simple enough and supported on many platforms. It's something of a standard so I can use the same translation string format and similar library functions everywhere.
ICU is like a really simple templating language, somewhere between printf and something like smarty or twig simplified and specifically intended for internationalisation.
I updated a library providing ICU compatible parsing and formatting for one of the platforms I'm using and find tests break. I assume that only thing to change is the API. ICU very rarely changes and if it did it would be unexpected for it to break the syntax in a major way without big news of a new syntax.
The main contributor of the library has changed since some time last year. Someone else picked up the project from previous contributors.
Though the library is heavily advertised as using ICU it has now switched to using a custom extended format that's not fully compatible and that is being driven by use case demand rather than standardisation.
Seems like a nice chap but has also decided for a major paradigm shift for the library.
The ICU format only parses ICU templates for string substitution and formatting. The new format tries to parse anything that looks XML like as well but with much more strict rules only supporting a tiny subset of XML and failing to preserve what would otherwise be string literals.
Has anyone else seen this happen after the handover of an opensource library where the paradigm shifts?3 -
Spending a whole morning on a problem with Selectize, on jQuery, on a problem where my values weren't displayed while they were stocked.
Tried a lot of things, even StackOverflowed it, no success. While I was desperating, I thought that should be the formatting of the String.
Bingo.
Gosh so much time lost












Top Tags
Weekly Rant
View