
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
FUCK PEOPLE ON STACKOVERFLOW ANSWERING JAVASCRIPT QUESTIONS WITH FUCKIN JQUERY SOLUTIONS! IF I EVER WANT JQUERY I WILL TELL YA!
NOW GTFO AND SHOVE IT UP YOUR ASS!!!15 -
Stack Overflow users in a nutshell:
*8 months ago*
Noob: "How can I do this with Javascript?"
SO User: "You should use jQuery. Here's how to do this in jQuery."
*Now*
Noob: "How can I do this with jQuery?"
SO User: "jQuery is redundant now. Here's how you can do it with Javascript."18 -
Found this code back in jQuery 1.9.1. Checked again, and t is still here in jQuery 3.1.0. Suppose it is just in case the values of true and false ever change 😃
 11
11 -
Hey, wanna hear a disappointing stack?
- WordPress
- jQuery
- vanilla inline CSS
- shitty random legacy PHP
Disclaimer:
The author is NOT responsible nor liable for any injuries, mental health issues, sanitary problems, asexuality, crippling depression, triggered by this rant nor liable for any damaged walls, hurt animals or deaths.12 -
After interviewing tens of candidates, finally found that one guy who doesn't start the conversation by mentioning jQuery 😂
Too many people started off with jQuery and didn't even bother to learn more about Javascript itself. 11
11 -
WHY THE ACTUALL FUCK DO PEOPLE PUT JQUERY IN EVERY FUCKING PROJECT EVEN IF IT IS A FUCKING ELECTRON APP AND EVEN WORSE WHY FOR THE LOVE OF GOD DO THEY MIX VUE AND JQUERY JUST WHYYY 😢13
-
worst advice:
"Use only jQuery, js is shit"
"Use only js, jQuery is shit"
Dude, use whatever dafuq you want, both have their pros and cons..9 -
SO: How to ... in JavaScript?
Answer: use jQuery!
SO: How to ... in JavaScript without jQuery?
Answer: use jQuery!
Me: ffffffffffffffffuuuuuuuuuuuuuuuuu I hate j-f*cking-query, I don't want to learn it!!15 -
Saying you know Javascript when you only know jQuery fells like inviting friends over for dinner and serve frozen food.7
-
Why THE FUCK does the StackOverflow Community answer any JS related question with a solution containing jQuery - sometimes even without mentioning it?
Gosh - it's 2017 use Vanilla or at least a modern libary!10 -
There will always be that one person who ruins all the fun
PS: Speaking of JQuery, I really found it to be somewhat slow. Is it slow or am I doing something wrong? 6
6 -
My son has started learning javascript at school, but he is complaining that all the $ signs are ugly! Yep, they're teaching the kids with jquery.
I don't know whether to laugh or cry 😱😱😱6 -
I always get a little angry when I'm looking for the solution to a problem I have with JavaScript and the answerer has the solution in JQuery. Like, not everyone uses that people!5
-
WTF!! I want a JavaScript solution.. not jQuery!! When JavaScript mentioned in the question, why the hell people answer with jQuery solution and also same solution multiple times.15
-
- Let's use jquery to fix this
- No
- But it will work just fine
- I'd rather re-write the code and not use jquery in an angular project
- ...
- NO!10 -
Fuck all these CSS frameworks using Jquery as their dependency. Cross-browser my ass.
I am going full flexbox.2 -
Watched Kung fury and decided to make a Windows 98 CSS / JQuery app. Check it out
http://codepen.io/penry/pen/xEPKpj7 -
There was a time when a fellow dev asked me if it was possible to use JavaScript in jQuery code... Yeah, true story6
-
“Written in pure React”
What’s impure react then? React with angular? Or with jquery?
For fuck's sake11 -
I should not have looked at this really interesting Chrome extension.
https://chrome.google.com/webstore/...
It tries to prevent phishing links from working by adding attributes to change the behaviour of the browser.
HOW DOES THIS WORK?
Just one simple line:
$('[target="_blank"]').attr("rel", "noopener noreferrer");
But why is this extension so bloated?
It loads the full jQuery library. For an attribute change!
I'd like to refer to this site for further investigations: http://youmightnotneedjquery.com//...
http://youmightnotneedjquery.com//...3 -
Me: I want to try Angular2 as a frontend framework.
Boss: Just use jQuery.
Me: That's not a framework but syntactic sugar for JavaScript. I rather not use it at all and rely more on ES6 shims. Let's maybe try vuejs.org?
Boss: Other devs know jQuery, just write it in jQuery. We'll need to build it fast and you have used jQuery before, haven't you?
Me: Yes, but ...
Boss: And you haven't used these recommendations.
Me: Yes, but ...
Boss: I won't take the risk. I want something that is known to work.
Me <dying on the inside>: If you insist.
Image source: https://hakanforss.wordpress.com/20...
PS: I don't work there anymore ;) 11
11 -
So I watched this video that tries to convince people, that the jQuery library isn't really best practice anymore and showed how you can achieve basic tasks with vanilla JS, aswell as some frameworks (Vue, React, Angualar) and how they handle interactions with the DOM.
It also talked about how nearly every JS question on SO has top answers using jQuery, and how that's a bad thing.
But what I found in the comment section of this video was pure horror: So-called "Developers" defending jQuery to the death. Of course there were some people who made some viable arguments (legacy code, quick & dirty projects), but the overwhelming majority were people making absurd claims and they seemed quit self-confident.
GOSH!
Want an example?
Look: 22
22 -
When GitHub marks your iOS project as JavaScript because there is that much JQuery floating around3
-
When job requirements say:
Programming Languages:
CSS
Scrum
Git
jQuery
JSON
...who tf writes these requirements!?9 -
Stackoverflow, the place in which those who search for Javascript will almost certainly leave with jQuery.9
-
WTF is with the entire Angular2 eco system and "half instructions". Started learning it and every inch is a struggle, out dated docs and code samples and then this style of shit:
Google: "Angular2 and bootstrap"
Result: "Install ng-bootstrap to get native bootstrap components written in Angular by the Angular UI team"
Me: Install != work
Google: "ng-bootstrap not working"
Result: "You also need to install bootstrap css, heres how"
Me: Install, plus try component
Error: "Bootstrap requires jQuery"
Google: "Installing jQuery in Angular 2"
Result: <Instructions>
Me: Install, still not working
Google "Angular2 ng-bootstrap bootstrap jQuery"
Result: "Don't forget to also include Tether"
WHY DID THE FUCKING "ANGULAR-UI" TEAM NOT MENTION ANY OF THIS6 -
>Me: *wants to do something in plain JS*
>Idiots on SO: "Here, have a jQuery solution"
How about fuck off with your jQuery?13 -
Many years ago when I changed to my second job, I had to do a lot more JavaScript work and upon Googling for a solution, that's when I came across jQuery. The idea of only having to write a few lines instead of multiple lines just to do a simple task was pretty exciting.
Plus looking through the docs and reading up about animations, I thought that was pretty cool and started playing around with it. Eventually I came to a project where I needed an interactive form and so I used jQuery to handle a lot of the UI work. My managers and the client were pretty excited about seeing how stuff can appear/disappear.6 -
During interview...
Interviewer: Do you know what is JQuery?
Applicants: Yes?
Interviewer: what is JQuery?
Applicants: am.... (in a couple of minutes thinking, the right answer that could be)
Applicants: JQuery is Java Query?
a pretty honest mistakes where the applicant do not know the answer and looks confident during interview5 -
Am I a machochistic fuck?
This sunday I had the glorious idea to fix a not-so-recent Wordpress website for a friend.
Imagine an upgrade from 3.3.2 to 4.9.8! (and PHP 5.5.old to 7.2.new
Oh boy. I thought it was impossible, because the site uses a free theme from 2012 and had some other plugins installed.
But what kind of developer am I, if I give up so easily?
I forced XAMPP to run PHP 5.6.stoneage in order to let me debug this thing. After some fixing in different files, I was able to get the admin panel back, disabled some plugins and then overwrote the installation with WP 4.9.8. After firing up the admin panel I had to fix 20 differend PHP files in the plugins.
Finally! After the plugins were updated, all worked again.
Except for the backend part of this free crappy theme. It uses an old version of JQuery UI widgets with custom mods.
I've done enough for today so I let it be like this. I'm not in the mood to load a second JQuery version.4 -
People that call themselves JavaScript developers but can't figure out how to update the DOM without using jQuery5
-
I'm not really keen in relying too much on JavaScript to render a properly functioning web page. HTML and CSS is now than good enough for it nowadays.
But if due to technical limitations, i have to use JavaScript, I make sure to not use jquery.
I don't like jquery.9 -
Local IT company proposes to give talks about the basics of web development in our school for one and a half week.
>"And now we're going to learn more about JavaScript."
>"The first thing we need to do is to import jQuery in our webpage."
>Literally no mention of plain JS.
this is why jquery is still not dead...........5 -
People who says jQuery is a programming language should go back to
alert("hello world")
exercises.
Man, I hate those guys9 -
Please tell me I'm not the only one who gets really annoyed when someone uses jQuery to do stuff that would take the same amount of pure JS. I think these days many people only use jQuery out of laziness, not because it's necessary. Why load an entire library to set CSS attributes and innerHTML? Yes, there was a time when it was very useful to have jQuery, but today we have querySelectorAll and all that. You can save plenty of kBs, load time and improve performance.
Next time you're about to load jQuery ask yourself: do I really need it? Chances are the answer will be no.22 -
No matter what JS framework/library holds the #1 spot at any given time, jQuery will always have a special place in my heart.11
-
WHY DOES TYPESCRIPT EXIST OH MY FUCKING GOD WASN'T JAVASCRIPT ENOUGH
(just starting out on angular2 and i already hate it compared to jQuery)26 -
Those jQuery fuckers spam their shit into every damn article or video. Why do you retards even use it in 2018? JavaScript has evolved and can do all the useless shit jQuery does in an equal style.
I hate to see modern front-end tutorials using this useless ugly tool.27 -
While Google is developing breakthrough AI systems that might quite possibly pass the Turing tests in the near future, my university suggests I learn JQUERY and calls the course Advanced Web Programming4
-
I'm learning web development, and this is another small project that I made - a basic code player.
Used jQuery for the first time and realized how easy it makes things.
PS - I know it is pretty insignificant given that people here create much bigger things, but I'm proud of it!
PPS - Will post the previous small project I'd done. It was a browser based basic game.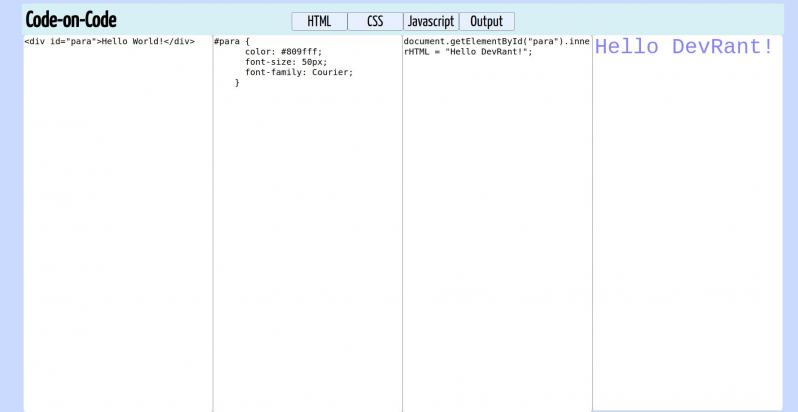 17
17 -
Successfully wasted 4 hours then realised jQuery was not inserted..
jQuery inserted..
Bug Fixed.. o_O8 -
Fuck you Ajax
Fuck you js
Fuck you jQuery
Fuck you {{insert js frameworks}}
I've been learning ajax now and this shit happend 15
15 -
Designers!!
What do ya think
A dashboard for a website
The cpu temp progress bar has jquery/AJAX wich outputs the cpu temperature at every each 3 second of the server wich is on a raspberry pi at the moment.
Does it look good for these days?
PS: used php for the backend 10
10 -
An iOS app which was basically a wrapper for a giant jQuery eForm.
~5000 lines of custom JS and it broke ALL THE DAMN TIME. A team of us worked on it for about a year and all we ever did was fix bugs. But the bug count never went down. The bugs just got replaced with more bugs.
Thankfully its not live anymore.
After the global thermonuclear war, all that will remain is cockroaches and jQuery. -
interviewing a guy earlier on... apparently jQuery is better because it can do things javascript can't

-
It's pretty common the hear developers moan about JQuery being imported to select an element. That's fair enough and I've sighed inside about that myself before.
However, I've come across an odd one. I'm looking a JavaScript file here that's close to 600KB in size.
528KB of that file is the Loadash library (which is excellent btw). The actual site uses the "join" function (https://lodash.com/docs/4.17.4#join).
I mean seriously wtf, face palms all around.
JQuery, for all it's faults is always cited in such circumstances i.e. being used unnecessarily. However, such things are not limited to Jquery alone unfortunately.
I'm now going to do some serious optimization and cut a 600KB file to ~80KB.
*** facepalm *** 4
4 -
Why do people mix JS vanilla with framework syntax? That's horrible.
Why do people use jQuery anyways? There's no need at all anymore. It is just dumb JS for dumb devs.
Did that trigger you? - well....7 -
Are there any developers here who still use jQuery rather than these new big ass JS frameworks. Recently I started with Angular 2 for an internship but I really miss jQuery.🤔10
-
I just saw the equalizer 2 at the cinema and about half way through there is a phone with "military grade encryption" on it. We see the phone screen showing the encryption and what is it? Freaking JQuery!3
-
You think jQuery would finally have died after the IE era? Or that it would only be used to still pander to IE users?
Well... nope: https://w3techs.com/technologies/... says jQuery 3 has overtaken jQuery 1, which was the only version to even polyfill IE.
WTF is wrong with web devs, just WHY?! jQuery's use cases are shit that would be simpler and with less code without jQuery, shit that should be done in CSS instead, or shit that doesn't belong on websites to begin with.39 -
I must learn jQuery and NodeJS. It's amazing the potential of JS. My lastest 10 programs were written in pure JS and I made them in a few hours. As an electronic engineer I hate the high level languages but JS (and maybe Python) it's definitely excluded from the list.17
-
So i had the second talk with this company today. The backend developer somehow expected me to know all four benefits of jQuery. What the hell dude?
Nobody knows everything.
I’m not a big fan of jQuery period.8 -
Fuck jQuery. The only reason I see anyone using it legitemately is because of backwards compatibility. Almost every jq method is either native js or native css. The problem is, some devs become practically dependent on a library. By then, they are no longer js devs. They are jQuery devs. When you find yourself going to the docs of a lib before native methods 9 times out of 10 you've gone past the turning point. When you find yourself including jQuery instinctively, you're gone. StackOverflow is a great example of this:
Question - 1 up
Pure JS answer - 0 ups
jQuery answer (same length) - 2 ups and accepted
Come on man. It's 2018! We shouldn't be writing jQuery anymore. Native methods ftw!15 -
just spent 2-3 hours trying to make a slideshow responsive for mobiles.
position().left returned an incorrect value breaking the whole thing. then jquery animations slowly produced a one pixel discrepancy when everything is animating based on the container width. breaking the whole thing.
Only solution has been to pretend all is fine.
things that make you want to smash something.3 -
Lead-Dev: "These links don't work as they should, I'm having you fix them, 'kay?"
Me: "I'll have a look."
> The link doesn't do anything when you click on it.
My internal monologue: (The href is probably just wrong)
> It's not wrong.
Me: "What the fuck?"
Lead-Dev: "Can you fix it?"
Me: "I don't think I can."
Lead-Dev: "Why don't you try looking in thisScript.js?"
Me: "Oh, you think the click event got prevented or something?"
Lead-Dev: "No, I think something went wrong with what that script is doing with the jQuery library this site uses."
Me: "..."
Lead-Dev: "..."
Me: "jQuery... library...?"3 -
Don't you just love it when someone adds jquery, jquery UI and the CSS for jquery UI, to run one function on one page in order to do something that's already built in to materialize?
Because I don't :v
https://github.com/inabahare/... 7
7 -
jQuery. jQuery everywhere.
People's dependency on this library would be like everybody carrying a tool chest with them, even for basic jobs like re-arranging a stack of books or collecting leaves in the yard. Cmon y'all, JS does a lot of this out of the box without the bloated library.
But then again, I'm addicted to MOMENTJS, so I should probably shut up now. 😆😄😬5 -
jQuery < 3.4.0 is a known moderate severity vulnerability now and Github just send me about 20 alert mails for repos which are using jQuery that I had used for side projects.
Like thanks but damn.2 -
This guy looks very promising and has experience, let's let him make a test site...
WHAT DO YOU MEAN 4 JQUERY SCRIPTS IN THE SAME PAGE?
btw the versions are, in order of appearance:
3.5.1
2.1.3
1.11.2 (!!!)
And the last one within the body: 3.6.0
Such a professional.8 -
PSA: If you use jQuery and BlueImp's jQuery File Upload there is a big potential vulnerability you need to be aware of. If you use NPM to pull the repo into your public folder, the "server" folder will be available for people to take advantage of. "Hackers" may be able to upload malicious code and replace parts of your site.
I had a site hacked and later saw on Google Analytics that people were posting to random URLs in that folder. The fix is to simply delete that folder, but if you use NPM, you need to be extra careful it doesn't come back.
Also, I didn't investigate further. So I'm not sure what (if anything) is vulnerable in there, or if it was just the specific version I had. To be safe, if you use this plugin (as MANY people do), just delete the folder.
Link to the repo for your reference: https://github.com/blueimp/... 4
4 -
A few years ago, i was kinda bored on my internship, so i changed the name of all variables of some jquery functions i had on my code with lyrics from a song that was stuck on my head.
Never understood that code again.3 -
!rant
Been working on a custom html partial injector (js/jquery only) as both a personal challenge and utility to use for my website scaffold. Being a challenge, i decided not to look at any implementation from another JS framework. I won't lie, i had it 'working' at least 5 times now, but this time, after about 3-4 days, i think i got it for real. And the cool thing? It's a bit less code than my original implementation even with my generous whitespace and verbosity. And it even unwraps nicely so it looks like a regular html page in the dev tools.
I love when things finally work as they should--God knows i question my motives before then.2 -
"This is your last chance. After this, there is no turning back. You take the blue pill - the story ends, you wake up in your bed and believe whatever you want to believe. You take the red pill - you stay in Wonderland and I show you how deep the rabbit-hole goes."
Said to a new team member before they embarked on a journey of pain as I took them through a huge web app made with jQuery (think: 10K lines of DOM manipulation horror), WCF, and sadness. -
I'm raging all over the place at the moment. I've just inherited possibly the worst PHP project (Codeigniter) in 10 years.
Apart from the fact that the previous developer has created 87 different header and footer files (same content, but each screen has different footer file for some reason, i.e. footer-login.php, header-login.php, footer-profile.php, header-profile.php etc.), he seems to like adding the following comment all over the place: "Released under MIT license: http://opensource.org/licenses/..." to some how protect is shitty code. I mean take a look at the below of some high quality,propriety Jquery he's written, under MIT. 4
4 -
My most intense day was in the company at the day we had to publish a website containing lots of jQuery & CSS animated stuff.
We planned to go live at 3pm but due to the fact that before lunch time there began to appear more and more styling and animation problems, we went live at around 9pm. I was sweating and nervous as hell the whole time.
At least my boss and I went to drink a few beers right after that. ;) -
In cour company we need an online dashboard that monitors logfiles from various interface processes.
My collage and me, the newest company members (for almost 2 years) get the task to build this and get it presented as some intern project where we can try out some more recent technologies/frameworks.
Now in the first meeting our senior team leader told us we shoeldn't use the noew hot buzzword js frameworks.
Reason? They are not proven and wil probably lose popularity next year and we don't want to migrate everything every half year. Plus he had negeative experiences with Angular in some project he had to work on, probably just because his limited JS skils.
So he wants us to use jQuery to build a modern web application.
I get it you don't want to migrate to TheNewHotThing(tm) every year. Guess what? You fucking don't have to. If I build sonting in Vue.js now, it won't stop working when a new framework comes along.
Look at our own fucking ASP.NET Web Forms prooject, that stil works. Just don't deny the usability of modern frameworks. 4
4 -
That feel when an intern is tasked with implementing a web frontend for a project you're working on.
That feel when you open up one of the views and it's filled with JQuery spaghetti and your eyes glaze over.
That feel when you actually step through the code, and it actually makes sense and is remarkably light and clever for what it does.
That feel when you learned a bit more JQuery (a library that you never had any experience with before) and it made doing some more things an absolute breeze.
Thanks intern!
-
Trying to learn es6 JavaScript and Vue js, whilst also maintaining sites using jquery.
My head is about to explode... -
All the jQuery... in one single repository / website.
There is a good reason why we should use fucking CDNs.
Edit: Yes, these are different files in different folders.
Edit2: I've already deleted 2 other jQuery files (the library itself). 4
4 -
Well I wish I could abandon jQuery and bootstrap all together and just use some vuejs admin template with my Laravel app. But things are not that easy and I am a lvl 1.0 vuejs user.
So sorry V girl, you gotta learn how to live with Mr.J for a few more months.4 -
That moment when you're working on a website and all of the sudden the site (on localhost) stops working, you don't understand why, and then you realize you're offline :/, your site uses Jquery for everything (And because you're lazy, you didn't downloaded it... and you never will).1
-
I used jQuery to solve an issue today because I was too lazy to restructure the way my site was rendered by my framework :(3
-
This is 1:05AM and this is the 3rd time I start over my question to Stack Overflow because I don't know what the fuck is going on with jQuery UI, and when I finally get it, Google finds me both the question and the answer of the same and only dude that had the same problem than me FIVE FUCKING YEARS AGO and he couldn't solve it.
Fuck this, tomorrow I'll start over with VueJS.3 -
What a coincidence. JQuery gets an update to 3.4.0 - and I removed the JQuery dependency that a mid-sized widget (15 kB minified) needed.
Rewriting the selector, css and trim stuff was easy. Each, children, append, empty, remove and extend were not too hard. Animations gave me more headache, but in the end, JS triggered CSS transitions worked nicely.
I was able to shave off the usual 30 kB over the wire for JQuery, and the whole thing seems snappier. Finally, I'm at vanilla everything!
Of course, it's largely due to JQuery's merits that vanilla JS is where it is today. So, thank you JQuery, and farewell.3 -
When you want to move your site off of jQuery, but all the dependencies still use jQuery.
Also screw those services that write their client code with jQuery. Screw you all!2 -
looks up JavaScript question, gets jQuery answer
Are you kidding me? Does anyone even do plain JS anymore?? D:1 -
Javascript in general (jquery, Ajax, nodejs and so on) is my greatest weakness. I've been working on a project which a great part is js and it's slapping in my face that I don't really know js. It's frustrating as fuck but it's a great experience, because I can now work on my weakness and turn it into my greatest strength. So let's see how it goes. If I don't smash my head into a wall in absolute rage that is...5
-
I love the simplicity of jQuery and Angular 1.0 - you just include the JS files and off you go. No additional dependencies or messing around.4
-
Wanting to animate an arrow turning.
Has jQuery and thinks of. animate().
Spends 2 hours wondering why it won't rotate.
Reads in smallprint "jQuery doesn't support CSS3 animations."
There goes the time I didn't have -_-7 -
The webdevs from another team upgraded jquery from 1 to 3 and wondered why the interactions aren't working anymore.
Why tf do you call yourself a developer when you can't fix deprecated stuff. Simply by using plugins and copy paste shit.
And fuck me, i'm fixing their shit now17 -
Just found this great JQuery selector in a bit of code a freelancer wrote:
var showErrorFor = $('[name="newPass"]').attr('name')6 -
Overhears colleague say 'Ohh there's a plugin for that'. Few weeks later i find the dumb fuck added it to the codebase and not use the dependency manager. I'd happily shoot the senior Dev who peer reviewed it but looks like this pleb merged straight in!
With a codebase overflowing with duplicate frameworks and unused jquery plugins I'll be burning the god damn place down come next week!2 -
some days are very frustrating , i had a task today in which client want a page where he can add bulk of car details on the same page.
now jquery fucked me.
I want to do something to release stress. Why do I get stuck at shitty problems sometimes ?
Damn I'm a noob programmer4 -
Okay but
A js library with the exact same api as jquery, only using native js functions so developers can simply swap out the jquery file8 -
It literally haunts me that I've used jQuery in a reactjs project, I'm not saying that jQuery is bad but using it does not seems right, I can't sleep, always thinking about a solution, fml5
-
Why do people hate jQuery so much? 30KB is basically nothing in times of modern bandwidth and for me CSS selectors are mich more readable than the Vanilla JS functions.
Im not judging and would be happy if someone explains it to me or shows better alternatives.4 -
I wanted to add a simple gallery for our website.
I started browsing open source alternatives.
Result: "Depens on jquery, depends on node, depends on bla bla bla... Fuck it... I'l just make one myself."2 -
Anyone that tells you "jquery is stupid" is either a pro or obviously hasn't tried to do drag and drop with the html5 api.
What a pain in the fucking ass bunch of boilerplate bullshit.14 -
Question: Why did the jQuery developer never have financial problems?
Answer: Because he was in $.noConflict() mode2 -
The state of web dev is we have to be explicit that a lib DOES NOT depend on jQuery.
Even when it is blindingly obvious that will be a terribly bad idea to do so.
https://github.com/STRML/... 11
11 -
So, my favourite language is Python, and for web developing I use Pyramid, and to stay in my "comfort zone" I use brython for client scripting, don't take me wrong, I love javascript, but for just a bit of performance lost I like being able to use all my pre-existing python code if I need to...
So, this was my first work experience, for a military industry, we had to make a service for uploading big files and sending them via email.
I heard one thing that shot me out of my "comfort zone" (I'll call it cf from now on)... "Use php"...
So, I already had written in php and I've always disliked it, perl-ish and broken as a bethesda game (i like bethesda games, but they are broken)
Another thing: javascript vanilla or jquery, never liked jquery either, so I decided to use vanilla js...
So, after 6 months of work, my partner and I finished it...
Well, more than one year later that mess we had to make to satisfy our boss' most absurd desires is not online yet, I search it on google every month, so yeah, 6 months of my life wasted (also, it was a "stage", so not only I didn't get any recognition, but they didn't give me any money) -
I’m new to coding. I decided to pick JavaScript to learn how to code. For a while I was confused as I couldn’t grasp the fact that jQuery wasn’t a language of its own even though multiple people on devRant told me it wasn’t (or was?)
Anyway thanks for baring with me. I’ve decided to drop jQuery. It seems kind of outdated even though a new version of the library was added quite recently.
I’m now delving into ReactJs. Some people say it’s a framework, others say it isn’t. Again one of those confusing debates which is beyond me. Anyways I’m amazed at how easily I can get a basic web page up and running with React. So far I’ve only managed to launch an application using the create-react-app command in the command box. Oh and I’ve also been able to add a button to the html with a counter increment.
Fun times ahead!15 -
I started building an application for FIDAL (Italian Federation of Athletics) because why not: I was bored and wanted to learn Flutter.
There is no API, but I didn't even expect it. Parsing the HTML is easy enough.
BUT OH MY GOD THE ENTIRE WEBSITE IS SHIT. Take this page: http://www.fidal.it/graduatorie.php, it uses some useless jQuery plugin and uses a buttload of JavaScript that isn't even needed. BUT WAIT. Try entering an invalid "club code" (http://fidal.it/graduatorie.php/...), a FUCKING white page with 200, are you kidding?
I'd also like to mention that all pages that require form input won't load correctly if you don't include "submit=Invia" in the URL.
I am not giving up.3 -
Working with jquery:
When I was there, all was perfect.
Came from vaykay, nothing works!! In my comments it said, DONT NOT CHANGE ANY `${anyNastyWord}` CLASS NAME!!!1 -
Just a quick Tip for our jQuery Users: There is a difference between $(document).ready() and $(document).on("ready")! I learnt it the hard way :)4
-
Anybody else really dislike jQuery coding standards? Like who decided $ was a nice & informative variable name?2
-
I regret becoming a frontend dev ( mostly because I started learning jQuery first and not pure js ) .1
-
"You must have heard of JavaScript, Node.js and jQuery. Could you write them down on the whiteboard?"
Possible answers you'll see:
Javascript, nodejs and Jquery2 -
> be me
> recruiter: *sends a LinkedIn request with a message, I saw your profile, you're quite proficient in javascript and jQuery, do you want to work with us with cutting edge meteorjs stack*
> me : *the fuck ?! I don't even know that library exists, replies anyway for a call*
> me:...okay I'll call before I come in
> me: *quick look on their website which is built on meteorjs, fucking beautiful*
> me: *opens console out of curosity*
> me: holy shit, what the fuck? they're loading jQuery 1.1.2 over HTTP and website is on HTTPS, top of that they are loading jQuery libraries before jQuery.
> me : *reports to the recruiter*
> recruiter: thanks, we'll look into it
> ???
> profit
and I don't plan to work a place like that3 -
I love how all the shorthands for events are deprecated, but JQuery docs still haven't been updated.8
-
That feeling you have when you successfully removed jQuery from a legacy project and everything for some reason still works!

-
JQuery is not badly designed... It's not designed at all.
JQuery is just awful and it's being used by people who know nothing about programming... Hell, some of the JQuery developers were not even programmers or had programmed before.
JQuery is a part of the whole "Wordpress community/world" and that world is full of people who doesn't understand what they are doing, Wordpress isn't designed either (that's why Wordpress stores serialized data in a structured database).
Every single Wordpress theme developer includes JQuery and it's disgusting. Most of the time, they don't even use it.
JQuery is not Javascript on steroids, it's javascript with cancer. Get rid of it. It's bloated and only lazy people use it. (JQuery will give you about 200ms extra response time for your site)5 -
What is everyone's thoughts on dynamically creating html using templating or other methods with javascript or jquery?4
-
Customer complain about errors reported on their content on their website.
Checking their content in WordPress and they was adding a script to include jQuery and another js with html tags.
So trying to understand why jQuery is required and on a 100 lines js vanilla, was used on line 3 to get an attribute of an element.
And they was breaking a site for this.1 -
Ugh I hate jQuery. It's so bloated, and I can do everything I need without it. But I can't get rid of it cause WordPress absolutely needs it.
At least I can pretend it doesn't exist on my personal projects.8 -
manually writing multiselector widget with jquery and javascript, because you need to be able hackily pass in metadata for some stupid fucking edge case that the previous generation didn't want to deal with
please euthanize me, i fucking hate frontend and im sure it hates me back3 -
It always irritates me whenever I try to find solutions for my coding problems in angular typescript alot of resources available in jQuery and JavaScript. In the end I have to invent my own solutions. It would have been done with jQuery and JavaScript easily!1
-
Spent the last 3 days on a jQuery scrolling bug that has been in the product for 3 years. It was a 5 line fix.
-
So todays issue. Working with slideshow functionality with jQuery and setInterval() and things seem to be working as expected.
That is.. until you leave the page for awhile and come back and see a constant fading of images because the intervals appear to be "catching up" with themselves xD
Luckily, setTimeout() takes care of this issue nicely.1 -
A customer sent me code today along with their request for a feature.
They want a thing happen when they click a button so they sent me some jQuery on click function ;)
I really don't mind it. They're trying, it's a well meaning tip .... but fuck no am I adding a customer specific function for their request, we have a another system for that kinda thing ;)6 -
I was building a super simple Laravel app for a client (forms APIs stuff)
For the frontend I used jQuery cuz why overkill it with react.
Now the sad part:
The app makes ajax calls to fetch the data from the database and update the view according. The code is very well written and the call is so quick that in a blink of an eye the data is processed from the controller and sent to the view -_-
Because the user doesn't gets to see what the fuck just happened when they clicked the action button, I had to add a setTimeout function before the Ajax call to slow down the process by 2000ms and added a freakin spinner.
I feel very sad when I can't show how awesome apps I can build but,
I killed my ego for the UX.
This was my sacrifice.
Anyone faced similar shits?3 -
I really love JavaScript but the most fustrating thing is solving IE bugs and finding only solution by using jQuery... Yes even in 2016.2
-
It took me a month to self taught web dev with jQuery
- made 3 sites for school projects
Took me more than a month to learn the MEAN stack.
- taught it to students as a TA in software engineering class for 3rd year while I was at 4th year.
Took me 3 months approx to learn RoR and Clojurescript at my current work.
- year later I am one of the main devs, and pushed the company towards big Data while implementing scrum and pushing for devtasks priority.
Learned React but I am still struggling to figure out how to start a new project.
And I am still fighting Eleverytime I need to center in CSS.
Am I a bad dev mommy?5 -
Created a new MIT licensed plugin for anyone who's interested and already uses jQuery:
https://htmlguyllc.github.io/jConfi...13 -
I'm currently doing a small personal project on JavaScript and HTML5. I ran into a problem and tried asking my teacher about it. It wasn't the JavaScript teacher but the HTML one. Anyway, his response is, "the department won't let me solve your doubts about JavaScript, only about JQuery". Because some of my classmates ranted to the department about a project that teacher told us to do in JavaScript (which is not strictly his subject) So here I am, my problem is still unsolved and I'm pissed off. I wonder if its ok to tell a teacher to NOT solve the students doubts.2
-
Not a js expert. I'm trying to learn a new js framework so I'm stuck between angular and react. I'm a Django dev, so I'll be mostly using this framework in my Django apps. Which one should I learn? I'm migrating from jquery so please don't be harsh at me 😅7
-
oh my, this guy was a serious joke. This was 3 years ago at a company I just joined and this guy should have had more than 10 years of experience.
He was a frontend developer and I had to explain to him how to create a hamburger slide-out menu with jQuery.
He got laid off a couple of months later and now his title holds "senior" developer... I feel sorry for his colleagues that have to deal with his stupidity every day now6 -
The fun times, watching the little weenie down voting the guy who thinks vanilla js is better than jQuery. Here I thought devs were meant to be more intelligent, yet somehow a 30kb wrapper for js is better than js itself...
-
Hey guys.
So, got tired of trying to learn on top of the knee (Portuguese expression) and decided to do some courses to get the basics.
Where do you recommend I go?
1. Course must be free
2. Not over 100 hours per course (I'll have 1 to 2 hours a day if I really focus on it)
What I need:
Language (lvl of knowledge)
- Python (know the basics) + kivy (basics)
- Html (good) + css (basics) + javascript (basics)
- node.js (0)
- Jquery ( 0 ) + Django (0)
I know there's lots of good courses out there and lots of dumb stupid ones, care to give your opinion? Thank you5 -
Why are you all so obsessed with hating jQuery? For me it just does the job done. Animate stuff. But I agree being totally dependant on javascript is bad for any website. Seen hundreds of wordpress spaghetti code where fancy effects were made with jquery like CSS opacity 0 and jquery animate to 1... What a bullshit. But yeah I still love jquery. Easy, fast and reliable.2
-
Just found this:
jQuery(document).ready(function($){$(window).load(function(){ /* do stuff here */ }
Nothing else?2 -
.Net Dev here with a degree in graphic design. Almost 9 months into my first dev job, 85% of it has been dealing with god damn webforms. Unfortunately, sometimes it doesn't play too nice with a bootstrap / jQuery especially with code behind and when you have post backs. I never thought I would say this but fuck the front end lol at least when it come to this dumpster fire. At least I'm learning a lot but damn I can't wait to get back into an MVC project or service work.1
-
I still don't like using React/Polymer for really big projects. There's nothing like carefully tailored jquery code doing exactly what you wanted with addition of promises and requirejs. Anyone?5
-
I have a job interview on Thursday for a .Net stack suite of web apps. Thing is: I know C# and SQL Server pretty good (not necessarily together but that comes pretty easy to me). They also use Javascript/jQuery/ECMAScipt (they said it not me) and ASP.Net. In my web dev days I was mostly backend so I am super super rusty on Javascript and, though to a lesser extent, ASP. Do you have any tutorials and refreshers you recommend? Preferably in an IDE so I can hide my shame from the interwebs? Love you.4
-
I wrote the most jQuery I have in months today! I'm so happy I bailed at my old job, be side there they would have just given this task to an older dev who could do it faster and not have to ask questions. I only asked the internet and I got it on about 3 hours!4
-
Fetch API gives CORS error..
Then I use JQuery AJAX request and it works fine...? 😑
Can you even handle CORS requests with Fetch?
🤔4 -
As a JS developer I wish that when I import a package, a list of all the Jquery methods comes shipped with it 🥺12
-
wanted to write my own JavaScript base calendar date picker instead of using the jquery one. really hate the idea of requiring jquery in my compiled script just for the calendar.
but the thought of mobile respobsifying the calendar UI kills me.... then there's cross browser support 😫3 -
for me, the most interesting project I''ve worked on was 4 years ago for a beer company.
it was a facebook app developed in HTML (not html5), jQuery & jQuery hi, php, imagick, ffmpeg, & YouTube library.
for the Euro Cup, users had elements to drag and drop on a stage, add frames, dialog boxes, and create a 15 second animated story board. all positions of these elements along with the frames where sent server side to create images of each frame (rendering fronts and positioning), then combining them using ffmpeg to generate a video.
these videos were later uploaded on the client's YouTube channel.
this project was awesome, knowing css3 and html5 were prohibited to use due to cross browser compatibility. it was ban exercise on all levels :) -
Other dev in my department thought it was okay to comment out the latest version of jquery lib that was used in the project and replace it with about 2 year old version to make his feature work. He did not informed anybody about this and today when build was tested, blame was on me because the feature i implemented does not work. I found issue was because of old jquery lib he put.
Funny thing is, his feature does not work with latest jquery version.
I guess it's gotta be either me or him. -
I'm less familiar with JavaScript, and by extension, I'm less familiar with JS Frameworks. So I needed to add inputs from three <input/> and show addition in fourth <input/>
So ripped off a SO answer, didn't work, though his JSFiddle is working perfectly.
Ripped off another SO answer, but this time jQuery, but that didn't work too.
the cycle continues till I find that I do not have a id="" in my code and I'm trying to use getElementById.1 -
Rant!!!!!
When you realise CHROME and FIREFOX needs different JQuery syntax to work with AJAX...
#respectForAllWebDevs #newbieWebDev5 -
In college.
Created event registration site with jQuery and Material design.
I had no web dev knowledge -
Dear colleagues,
YOU HAVE RUINED JAVASCRIPT!!@##@
Yes, you are one of those that are responsible for giving JavaScript a bad name and using jQuery for FUCKING EVERYTHING!@#$
Start thinking for yourselves, ditch this shit before it's too late and learn how to write some actual fucking code. The information is out there, you can do it. If you need handholding with $.each, creating concatenated strings with error prone code to send them in one field to the server, just to explode it back there, then consider that the world doesn't need your BULLSHIT code and go and get a job you're actually good at. Stop ruining it for the rest of us.
THANK YOU8 -
Fucking jQuery in Polymer 0.5.
When polymer 0.5 was released, things seemed incredibly easy at first, but when you need to do some complex things, the abstraction layer provided by web components are not of much help. Babel wasn't there too, so I ended up using scope hacks to access event listeners (var self = this). Worse, I have to use jQuery because many of things are downright tedious or fucked up back then, including myself.
Now, React is here; No jQuery, no hacks, no web component polyfills, no unsolvable perf bugs, no scope hacks, no 10sec loading time, no regrets.1 -
So, yesterday I was able to create a stack overflow using jQuery, just trying to do a fucking AJAX call.....
It took me fucking 2 hours and 5 rewrites to spot that I was trying to access an undeclared variable.....
Fucking useless error messages, like why would I get an overflow at dc, when it's a fucking undeclared variable..2 -
We have a custom made CMS, where you can use templates (previous designs). Most of the time I see these templates with Javascript/jQuery that looks like this...
Edit: There is an extra $ in front of the first (function($). So like this: $(function($) 6
6 -
Spending a whole morning on a problem with Selectize, on jQuery, on a problem where my values weren't displayed while they were stocked.
Tried a lot of things, even StackOverflowed it, no success. While I was desperating, I thought that should be the formatting of the String.
Bingo.
Gosh so much time lost -
From the jQuery doc page for .click().
I hope the person who has to do the documentation is alright and not projecting here... 2
2 -
Can anyone help me in jquery?
I'm doing a loop of trigger which are 13 in count, but every trigger event contains ajax call and what my problem is that it doesn't wait for ajax response and keep hitting trigger until last trigger fires.
so I'm having my ajax response only on last one.
What can I do for this?9 -
In legacyCode, somebody mixed jQuery data-toggle with custom JS triggers that toggle the target's DOM node, and to "fix" the mess, set display: block !important.
Took me too long to remember that Firefox dev tools show JS events (while my Chrome dev tools don't - why?) now I'm on the right track towards a solution...4 -
I wrote my first proper promise today
I'm building a State-driven, ajax fed Order/Invoice creation UI which Sales Reps use to place purchases for customers over the phone. The backend is a mutated PHP OSCommerce catalog which I've been making strides in refactoring towards OOP/eliminating spahgetti code and the need for a massive bootstrapper file which includes a ton of nonsense (I started by isolating the session and several crucial classes dealing with currency, language and the cart)
I'm using raw JS and jquery with copious reorganization.
I like state driven design, so I write all my data objects as classes using a base class with a simple attribute setter, and then extend the class and define it's attributes as an array which is passed to the parent setter in the construct.
I have also populateFromJson method in the parent class which allows me to match the attribute names to database fields in the backend which returns via ajax.
I achieve the state tracking by placing these objects into an array which underscore.js Observe watches, and that triggers methods to update the DOM or other objects.
Sure, I could do this in react but
1) It's in an admin area where the sales reps using it have to use edge/chrome/Firefox
2) I'm still climbing the react learning curve, so I can rapid prototype in jquery faster instead of getting hung up on something I don't understand
3) said admin area already uses jquery anyway
4) I like a challenge
Implementing promises is quickly turning messy jquery ajax calls into neat organized promise based operations that fit into my state tracking paradigm, so all jquery is responsible for is user interaction events.
The big flaw I want to address is that I'm still making html elements as JS strings to generate inputs/fields into the pseudo-forms.
Can anyone point me in the direction of a library or practice that allows me to generate Dom elements in a template-style manner.4 -
Isotope.js is an awesome jquery plugin for anyone looking to sort, filter, or search for items (html elements with specific class or attr)
 1
1 -
Hmm, this front-end framework looks great, it would be a shame if... "the latest version of jQuery is required"... Well, fuck you then, let's see the next one.
My day in a nutshell. -
>stack overflow: "Use JQuery!"
>
>me: ok i broke a lot of stuff after >about a year, help me fix the JQuery.
>
>stack overflow: 2
2 -
In React-based project, "why can't we use jQuery?"
As if my disdain for jQuery as a crutch couldn't get any worse...3 -
If you hate jQuery because you say it's "bulky", then please explain these modern JavaScript frameworks with a bajesus of configuration to make it just work plus the node_modules.5
-
I found myself here searching if other people are annoyed at the fact that so many JS questions are answered with jQuery, completely unprompted.
Reading the rants here has given me hope.3 -
!rant
Was too much into jquery, and so when I started my job I made everyone think jquery is the boss and stuff (my team is full of data engineers and business analysts.. No one understands code)
But now, based on my previous rant, I feel I should switch the entire project from a node/express structure with jquery to one with angular2
Does it make sense? Please advice... I am nervous of losing my job coz of this
(even now I hate typescript but I see why angular2 is better than jquery.. So I'll learn it all)13 -
Never got why react and all those js frameworks are so popular - css and jquery will load faster and do whatever you want them to not to mention all the jquery plugins you can use for free from fancy box to owl carousel. Sometimes i feel techies like something just because its new4
-
Guys.. i am currently pursuing BCA , and i am also learning web development with Html,css,js, jQuery,bootsrap. But i see the popularity of react nowadays.. So should i must learn react or first learn simple js or jQuery first as always?7
-
Peoples saying that JQuery dies after Document.querySelector is gone, but, write the functions like `slideUp` or anything that manipulates styles too, is very non-productive.
Do you know another lib (small) that makes these functions created by JQuery?15 -
Can anyone share their thoughts/opinion about jQuery?
I'm already using jQuery but I always have a doubt in my mind that using this library cause to lessen the performance or slow our webapps.
And also I was planning to use native Javascript rather than jQuery can also anyone share their thoughts/opinion what are the things I should consider when using native Javascript?10 -
I've never made a jquery plugin before and I wanted to see what that was like. It's not great but it's something:
https://github.com/surgiie/...
A form field saver using webstorage xd
You can tell me how crappy it is.xp -
When your project manager/tester keeps changing different fields required, which is being handled 100% with JQuery....requiring you to rewrite the entire functions logic
This has now happened 4 times... -
Way too long story short: Needed to figure out how to use jQuery to update a table that had no classes or IDs to help you tell what's inside it. Worked out a looping structure to read the contents of the cell with the dependent data in each row, and then update the cell that needed changing depending on the value of the first cell.
Minified the solution and dropped it into the console. Worked exactly right on the first try. -
Why.
A PHP variable "declared" in the jQuery.
I don't know why Sublime Text (3) does that.
(Sorry for the quality, the screencut was for friends but I thought it could belong here too.)
Disclaimer:
I don't use jQuery, previous "dev" did.
I don't actually care about this. 6
6 -
demotivated, opened some hacking/programming music on youtube to get me in the mood.
why hacking music? well whatever file you open you have tons of "smart hacks" to fix, as all bugs up to date since I'm here were just fixing brilliant h4xx0r ideas from developers that worked here before.
Maybe I should try to search for unhacking music instead!2 -
So yeah, don't know much about Javascript but a lot of you have recommended to stay away from JQuery and AJAX because they're on the way out. I hope ASP.NET would use a more modern library instead of JQuery11
-
I'm starting to go deeper with JavaScript and jQuery. What do you think of jQuery? Any advices or recommendations?8
-
We've got a non minified jQuery in production for months now. Not only do people throw it at every little problem, but some of them don't even use the minified version... 😑
-
A lot of times I read, that most people here are not willing or allowed to use jquery as a short fix for problems.
As someone who is working on big projects, I can say, I've used jquery a bunch of times as a workaround for problems I am not able or allowed to fix on my own. And I am a Java-Dev, so...1 -
!rant
I just found out I don't need to download jQuery to use jQuery. If I can just include jQuery in the <script> tag in order to load it into my HTML doc, what is the download for?10 -
So many years of web dev and I still google the "jQuery $" function every time...
(function (window, $, undefined) {
}(window, jQuery));4 -
What javascript framework/library should we use TO MAKE A WEBSITE?
following these days trend ?
eg, react.js , jQuery ? or normal js?
ps:for a professional website.13 -
"Most successful private project" would be an extension of the webeditor Brackets named brackets-swatcher.
The silly thing about this is that it started out from my own frustration with variablenames in variablefiles in Foundation and Bootstrap.
After a collegue of mine also used it he had a shitton of ideas how to improve and what he wants so i developed it on many weekends with many many beers in my belly.
Where we come to the conclusion - its for sure the ugliest project ive ever written (=> beer and jquery) and i hope i never have to touch the code again - but on the other side i never had bug reports despite the fact that alot of big websites had it in their "Top 10 Brackets Extensions" and many downloads from the Brackets Marketplace.2 -
Many people seem to hate jQuery and want to do stuff in some library's way, and I'm here like... What? jQuery is a perfect way of doing things like DOM manipulation, when everyone comes along with their libs, they will only exist for 1 microsecond before it gets abandoned, while jQuery has been around for YEARS and it still works the way it first has been
I don't get the appeal for new JS libs and hate for jQuery, at this point I'm suprised its included in standard browser contexts2 -
I've just delivered the worst piece of crappy and twisted code that i've wrote in my short programming carreer(still at uni) hope god have mercy of my soul.
Was jquery mobile by the way... Fuck that shit!! -
Any recommendations on a jquery/js plugin that saves form fields in the scenario where the user left the form or page they can come back and still have the values from when they left. I wrote up some thing for a small form on an old site using sessionStorage api but I need something that can work with any form or perhaps multiple forms at once. any good plugins out there?6
-
I recently went from being a java/python web developer to a PHP firmware developer. I've never written in PHP before and I keep typing $("# when I go to type a variable reference. jQuery has made this transition annoying to say the least =P1
-
!rant
For the first time since I started work I used a matrix to find a formula.. Albeit it was for jquery.
Those hours and headaches spent studying math are paying off. Feeling a bit proud... -
So is jQuery ajax still the go to for ajax loading pages? Looking for modern alternatives but coming up with nothing...
I have nothing against using jQuery...5 -
Fellow DevRant's i got one question, javascript or jquery?
How bad would you be if jquery just diapered?6 -
I'm interning at a 40yr old tech company which develops network/app monitoring tools. Was put on a customer project where I had a bit of work on the UI. Fairly simple task, except the code was in jQuery... Fml :(3
-
When the overseas coder decides to add an external jQuery resource when it's already included (and loaded) in Wordpress and proceeds to mix $ with jQuery calls online throughout the site....
-
1. Can I use dt-options to reload dynamic data (Ajax) using angularjs datatable.
2.if yes.... How?
3.can i use jquery datatable and angularjs datatable in one application but different controllers? -
When legacy jquery code is so jumbled that you have to carry that code to your home as well to work it out
-
Got jQuery machine test 3 hours later.test includes plugin development and menu generation from json. I am an angular dev. Should I go through anything else other than official docs and ancient youtube videos?1





















































































































































































































































Top Tags
Weekly Rant
View