
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I'm convinced code addiction is a real problem and can lead to mental illness.
Dev: "Thanks for helping me with the splunk API. Already spent two weeks and was spinning my wheels."
Me: "I sent you the example over a month ago, I guess you could have used it to save time."
Dev: "I didn't understand it. I tried getting help from NetworkAdmin-Dan, SystemAdmin-Jake, they didn't understand what you sent me either."
Me: "I thought it was pretty simple. Pass it a query, get results back. That's it"
Dev: "The results were not in a standard JSON format. I was so confused."
Me: "Yea, it's sort-of JSON. Splunk streams the result as individual JSON records. You only have to deserialize each record into your object. I sent you the code sample."
Dev: "Your code didn't work. Dan and Jake were confused too. The data I have to process uses a very different result set. I guess I could have used it if you wrote the class more generically and had unit tests."
<oh frack...he's been going behind my back and telling people smack about my code again>
Me: "My code wouldn't have worked for you, because I'm serializing the objects I need and I do have unit tests, but they are only for the internal logic."
Dev:"I don't know, it confused me. Once I figured out the JSON problem and wrote unit tests, I really started to make progress. I used a tuple for this ... functional parameters for that...added a custom event for ... Took me a few weeks, but it's all covered by unit tests."
Me: "Wow. The way you explained the project was; get data from splunk and populate data in SQLServer. With the code I sent you, sounded like a 15 minute project."
Dev: "Oooh nooo...its waaay more complicated than that. I have this very complex splunk query, which I don't understand, and then I have to perform all this parsing, update a database...which I have no idea how it works. Its really...really complicated."
Me: "The splunk query returns what..4 fields...and DBA-Joe provided the upsert stored procedure..sounds like a 15 minute project."
Dev: "Maybe for you...we're all not super geniuses that crank out code. I hope to be at your level some day."
<frack you ... condescending a-hole ...you've got the same seniority here as I do>
Me: "No seriously, the code I sent would have got you 90% done. Write your deserializer for those 4 fields, execute the stored procedure, and call it a day. I don't think the effort justifies the outcome. Isn't the data for a report they'll only run every few months?"
Dev: "Yea, but Mgr-Nick wanted unit tests and I have to follow orders. I tried to explain the situation, but you know how he is."
<fracking liar..Nick doesn't know the difference between a unit test and breathalyzer test. I know exactly what you told Nick>
Dev: "Thanks again for your help. Gotta get back to it. I put a due date of April for this project and time's running out."
APRIL?!! Good Lord he's going to drag this intern-level project for another month!
After he left, I dug around and found the splunk query, the upsert stored proc, and yep, in about 15 minutes I was done.1 -
Timezones. So, general rules are:
1. If you don't store timezone, always use and assume UTC. Databases, backends, whatever you use, all time must be kept be in UTC.
2. If you store timezones, ensure you store them everywhere and don't drop them anywhere.
3. It's always better to ignore backend server time in favor of database's `now().` Having a single source of truth makes time consistent (if it's the same database, obviously). If you combine backend time and database time, you likely get a violation of causality.
I've just spent a couple of hours investigating "weird random one-hour time drifts on updates." Guys violated all three rules above:
- they didn't store the timezone;
- their servers had inconsistent timezones. Java was in +XX., while the server itself in UTC. On one host, they forgot to put JVM in the same timezone;
- they dropped the timezone because they thought it was the same everywhere, so there was no point in serializing it. 13
13 -
I serialized and parsed a million reddit comments with spacy on my laptop.
It took over an hour.
And then, right when it finished....
http://imgur.com/TIiACHC
I forgot to change from json to ujson
FML.3 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!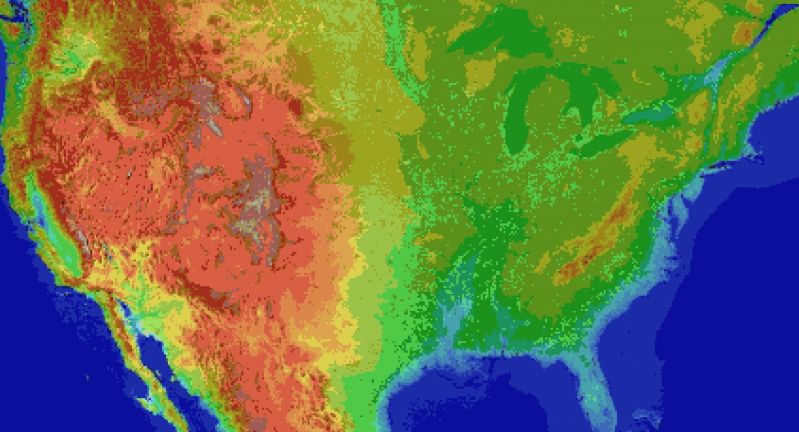 5
5 -
Fuck this I need to ventilate.
Thinking about job change because maintaining and extending 3 years old codebase (flask project) is FUCKIN exhausting. It was badly written since start by someone who obviously didn't know much about python. (Going by commit history.)
Examples:
- if var != None / if var == None
- if var is not None / if var is None (well..)
- Returning self-parsed obscure JSONs from dict variable
- Serializing dictionaries into database by str() (both sqlalchemy and mysql support JSON format) - THEY ARE ALMOST UNUSABLE OTHER WAY AROUND (luckily, python can deal even with that)
- celery tasks, the way they are called they BLOCK the whole flask (not bad in itself, but if connection breaks there are no errors, nothing it just hangs)
- obscure generator/yielding that contains return of flask's response in itself
- creating fifteen thousands of variables one by one where they would look so nicely as dict keys, and hey they are then both MANUALLY SERIALIZED into returning dict by "%s" (string formatting) [okey, some of them are objecst like datetime but MATE WTF]
- many, many more, PEP lint shall not pass
I would rather deal with fresh startup owners wanting me to program unicorns in one week then trying to extend and manage zombie-like projects.
Nothing personal against the firm I actually like the place.3 -
Fuckadoodling finally!
After 3 days of digging through the documentation of CraftCMS and Yii Framework I got the hang out of how these Controllers, Actions and other RESTful api stuff works on Craft3.
As some of you may have noticed, I am a big fan of CraftCMS (v2) since it was introduced to me. A few days ago we discussed a new project and the option go for Craft3, as it has been released for some time now.
The changes from v2 to v3 are huge... I didn't expect to almost reach my limit to give up on it!
But since the RESTful routes finally work, with proper data serializing and all, I will now go drink a Whiskey or ten and wish you all an awesome, client-disturbance-free, decadent, beerful weekend!
Cheers mateys!
🎉🎊🍭🥃🥃🥃🍻🍺🥂 -
Maybe someone can help me there.
I have to make a DDD project and I can't figure out in which layer I should put classes that - for example - convert objects from DAO to DTO or the Serializing functions.
Does someone who already made some. DDD help me?2 -
TLDR: RTFM...
My dad (taught me how to code when I was a kid) was stuck serializing a Java enum/class to XML.... The enum wasn't just a list of string values but more like a Map(String,Object>.
He tried to annotate it with XMLEnum but the moment I saw this enum, I'm thinking that's unlikely to work.... Mapping all that to just a string?
He tried annotating the Fields in it using XMLAttribute but clearly wasnt working...
Also he use XMLEnumValue but from his test run I could clearly see it just replaced whatever the enum value would've been with some fixed String...
Me: Did you read the documentation or when the javadocs?
Dad: no, I don't like reading documentation and the samples didn't work.
I haven't done XML Serialization for years thought did use JSON and my first instinct was... You need a TypeAdapter to convert the enum to a serializable class.
So I do some Googling, read the docs then just played around with the code, figured out how to serialize a class and also how to implement XmlTypeAdapter.... 20 mins ...
Text him back with screenshots and basically:
See it's not that hard if you actually read up on the javadocs and realized ur enum is more like a class so probably the simple way won't work...2 -
Does anyone use Winston JSON? or know what the perfomance impact is vs standard text logging? (serializing an object to JS)?6
-
So I have an assignment due in an hour, we need to make a basic game that implements multiplayer using WCF
I have wpf clients that connect to a service, they connect fine but for whatever reason my callback isn't firing to update the gui... the thing is though, it was firing earlier (mind you when it fired off I ended up getting null references)
I fixed the null references (turns out I wasn't serializing stuff that needed serializing) but now my updategui method just doesn't fire, period. zero exceptions are being thrown, zero errors are being given...
At this point I might just rewrite the whole thing until it breaks so I can figure out what broke it... Like trying to debug something with zero errors/exceptions being thrown is hard... -
Design Decision:
We have an API and a lot of microservices based on that API. Additionally we have a store of protobuf-templates (files to automate serializing certain events etc).
Currently for each service we have the API with general stuff (connection stuff etc) and then copy the 5 or 6 proto-files we need for that service, they update sometimes, so does the API, for each service, two things that need to stay updated. Which option would seem more logical to you?
a) Integrate all proto files into the API. The services then only need to update the API but they also have access to many proto files they don't need for that service (which are required for other services however)
or
b) Keep them seperated and keep manually updating the proto-files for affected services
Disclaimer: our proto files are always backwards compatible by design, both the API and protofiles change fairly frequently.
Ty -
Ever had to switch out a whole serializing layer in an API? Damn that's a lot of work :(
At least the 1952 tests are written well...











Top Tags
Weekly Rant
View