
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Just wrote a Python script to generate me a JSON file.
I forgot the 0th command line argument is the file you're running...
On first test it overwrote itself.15 -
You know what's funny?
Being called Jason.
Developers when talking about APIs and similar stuff: "So if you connect to our API you can get XML or JSON-" <pause>
<looks at me with a smirk like "haha! JSON/JASON LOL!">
<I gently smile like saying "yes. yes. I know. Thank you">
Sigh15 -
JsonX is a an IBM standard to represent JSON in XML...
Like wtf dude? What's the point in making shit even more verbose than the original XML ? 25
25 -
Licensing is so freaking weird and stupid.
I mean, I just forked this repo with an Apache license, so I could update a .json file.
"You must cause any modified files to carry prominent notices stating that You changed the files"
Plain JSON allows no comments.
I'm going to jail.30 -
This rant just fucked up devRant unofficial for Windows 10.
It causes a JSON syntax error in the API response. 🤣
Thanks @kwilliams! 😁 14
14 -
When you see a web service API accepting a SQL query in one of its JSON fields and the evil starts growing within you..
DROP ALL DATABASES
Just because you can! 4
4 -
"What technologies do you know?"
"I can write pretty URLs that return JSON"
"You mean REST?"
"No, I mean pretty URLs that return JSON"3 -
Why not have a custom (500 line) JSON mapper... you know... fuck those auto mapping libraries out there...
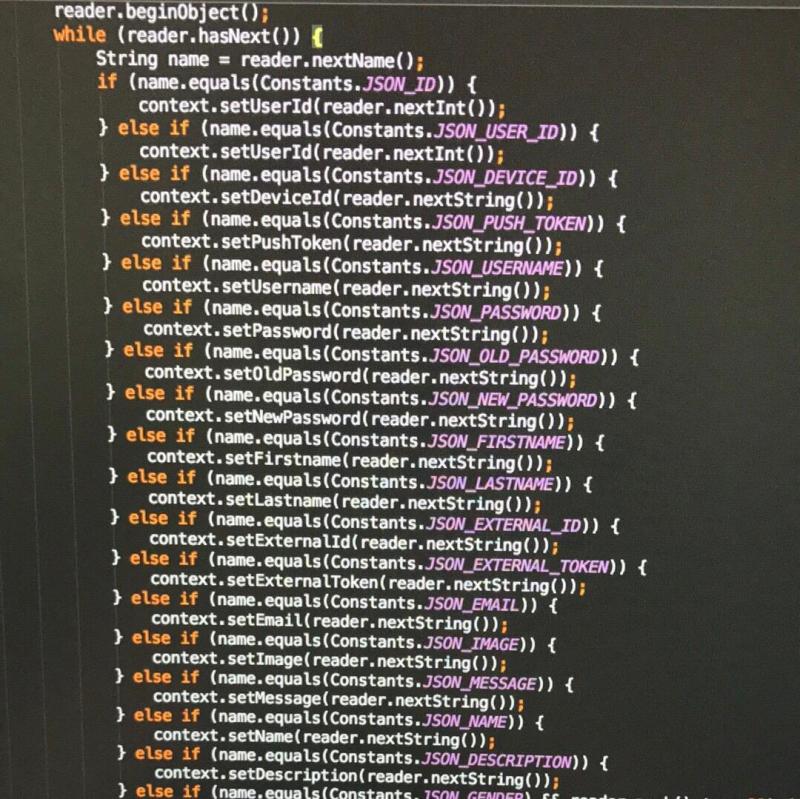 12
12 -
Boss comes in and gives me some js code for syncing data (he hacked it together the other day, really messy with like 5 callback lamdas stacked into each other)
Boss: Make it faster and more reliable and add some progress indicator
So i look at the code and he literally pulls all the data as one json (20+ MiB). Server needs multiple minutes to generate the response (lots of querys), sometimes even causing timeouts....
So i do what everyone would do and clean up the code, split the request into multiple ones, only fetching the necessary data and send the code back to my boss.
He comes in and asks me what all this complexity is about. And why i need 5 functions to do what he did in one. (He didn't -.-). He says he only told me to "make it faster and show progress" not "to split everything up".
So I ask him how he wants to do this over HTTP with just one request...
His response: "I don't care make it work!".
Sometimes i hate my job -.-11 -
True story. During meeting, our manager asked us, how the data flow. Our lead programmer response, "PHP will produce Son of Jay output, and read by Javascript".
Our manager; "Hmm... Interesting"5 -
I'M SO PROUD, I WROTE A FULLY-FUNCTIONAL JSON PARSER!
I used some data from the devRant API to test it :D
(There's a lot of useful tests in the devRant API like empty arrays, mixed arrays and objects, and nested objects)
Here's the devRant feed with one rant, parsed by Lua!
You can see the type of data (automatically parsed) before the name of the data, and you can see nested data represented by indentation.
The whole thing is about 200 lines of code, and as far as I can tell, is fully-featured. 24
24 -
When I found out my JSON didn't parse because I used single instead of double quotes after two hours
 8
8 -
Why on Earth would an API require me to provide input like this?
{"this": "{\"is\": \"not\"}", "how": "{\"json\": \"works\"}"}
😡7 -
I love Json format. It is so simple, powerful, easy to read and all that good stuffs. There is only one thing I wish Json could support, that's commenting.13
-
I always wanted to have comments in JSON files, but I just discovered a really good alternative:
{
"//": "This is a comment",
"somekey": "somevalue"
}
Looks kinda ugly but it works! No need for special unconventional parsers and shit.25 -
Rappers: "Yo dawg check out my mixtape!"
Programmers: "Hey have written this super cool JSON library..." -
toJSON().
So I can give
criminals.toJSON(),
terrorists.toJSON(),
rapists.toJSON(),
corruptPoliticians.toJSON(),
deadline.toJSON(),
java.toJSON(),
crocs.toJSON()
...myBoss.toJSON()
Have fun, JSON!
-
Our Service Oriented Architecture team is writing very next-level things, such as JSON services that pass data like this:
<JSON>
<Data>
...
</Data>
</JSON>23 -
The proprietary API I have to use which uses XML but is totally dynamic and without a schema. They basically managed to successfully merge JSON and XML to get the disadvantages of both JSON and XML.3
-
I know it's not done yet but OOOOOH boy I'm proud already.
Writing a JSON parser in Lua and MMMM it can parse arrays! It converts to valid Lua types, respects the different quotation marks, works with nested objects, and even is fault-tolerant to a degree (ignoring most invalid syntax)
Here's the JSON array I wrote to test, the call to my function, and another call to another function I wrote to pretty print the result. You can see the types are correctly parsed, and the indentation shows the nested structure! (You can see the auto-key re-start at 1)
Very proud. Just gotta make it work for key/value objects (curly bracket bois) and I'm golden! (Easier said than done. Also it's 3am so fuck, dude)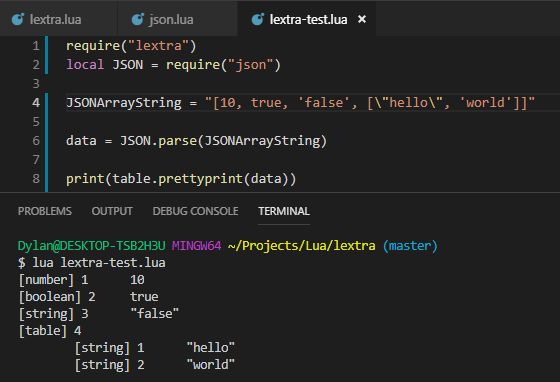 15
15 -
Client's API returns a very weird response that changes its structure depending on its content.
When a array field has more than 1 children it returns:
{
"field" : [
{ "name1" : "value1"},
{ "name2" : "value2"}
]
}
So far so good. However, the fuckery happens when it has 1 children:
{
"field" : { "name1" : "value1"}
}
WTF! So the client API can return either a JSON object or an array and we cant trust the specs they gave us.4 -
When job requirements say:
Programming Languages:
CSS
Scrum
Git
jQuery
JSON
...who tf writes these requirements!?9 -
Coworker: since the last data update this query kinda returns 108k records, so we gotta optimize it.
Me: The api must return a massive json by now.
C: Yeah we gotta overhaul that api.
Me: How big do you think that json response is? I'd say 300Kb
C: I guess 1.2Mb
C: *downloads json response*
Filesize: 298Kb
Me: Hell yeah!
PM: Now start giving estimates this accurate!
Me: 😅😂4 -
Is it me or all REST api use json today ?
And xml is kinda dead ?
I always feel awful when I see an xml rest api.10 -
Fuck (some of) you backend developers who think regurgitating JSON makes for a good API.
"It's all in JSON. iOS can read JSON, right?"
A well-trained simian can read JSON, still doesn't mean it can do something with it. Your shitty API could be spitting out fucking ancient Egyptian for all I care, just make it be the same ancient Egyptian everywhere!
Don't create one endpoint that spits out the URL for the next endpoint (completely different domain, completely different path structure). Are you fucking kidding me?
As if that wasn't enough, endpoints receive data structured in one way, but return results in another!! "It's all JSON", but it's still dong.
How do I abstract that, you piece of shit? Now I have to write ever so slightly different code in multiple places instead of writing it only once.
How the fuck do I even model that in a database?
Have a crash course on implementing APIs on the client side and only come back when you're done.
Morons.6 -
I’m a backend guy.
But because of reasons I’m editing a winforms json settings editor.
There has to be another way.2 -
SICK AND TIRED OF READABILITY VS. EFFICIENCY!!!!!!!
I HAD TO SEPARATE A 4 LOC JSON STRING, WHICH HAD AN ARRAY OF A SINGLE KEY-VALUE PAIRS (TOTAL OF 10 OBJECTS IN THE ARRAY).
ITS READABLE IF YOU KNOW JSON. HOW HARD IS TO READ JSON FORMAT IF YOU GET YOUR STYLE AND INDENTATION PROPERLY?!?
SO I HAD TO
BREAK THE POOR FREAKING JSON APART TO A FUCKING DIFFERENT YAML FILE FORMAT ONLY SO I CAN CALL IT FROM THERE TO THE MAIN CONTROLLER, ITERATE AND MANIPULATE ALL THE ID AND VALUES FROM YAML BACK TO MATCH THE EXPECTED JSON RESPONSE IN THE FRONT END.
THE WHOLE PROCESS TOOK ME ABOUT 15 MINUTES BUT STILL, THE FUCKING PRINCIPLE DRIVES ME INSANE.
WHY THE FUCK SHOULD I WASTE TIME AT AN ALREADY WORKING PIECE OF CODE, TO MAKE IT LESS EFFICIENT AND A SLIGHTLY BIT MORE READABLE?!? FML.5 -
Happily agree to help colleague with 'a quick problem' on their pet project. Realise a few seconds in that they can't actually see a difference between JS and JSON.5
-
When I got to learn about json yesterday I hate it cause I need to do extra work to MVC project. But after today the instructor told us what it does, and I love it. Gonna start learning this stuff more tomorrow1
-
Can someone please build an SVG vector file format equivalent that uses json instead of xml? k thnx! 😆14
-
Fucking powershell.
Just make a fucking api call, and shove my json into a damn csv.
How fucking hard do you have to be 🤯5 -
Most satisfying bug to fix...
Literally any API bug that returns JSON. Nothing quite like seeing that JSON blob come back correct.1 -
JSON: "Ok fine you can use our syntax and everything else but make sure you change the name of the format so people know there is a difference"
MongoDB : "K"3 -
Life is about wrangling, biologists wrangle snakes, porn stars wrangle cocks, I wrangle giant JSON objects.2
-
Store POJOs as json inside a database column so that we have a dynamic relational database!
For those who don't know what a POJO
*POJO: plain old Java object
Technically I was asked to store all data models as json in a single column 🙄10 -
{ “dow”: “10000001,10000002” }
Me: So what does this mean in the JSON response and why isn’t it a JSON collection?
Dynamics guys: that represents the days of the week. Because that is how it comes out of Microsoft Dynamics.
I’m thinking that they are either bad rest API programmers MS is bad at JSON. I can’t see the code so I don’t know which. No fixes because budget.13 -
In one of my teams there was this non-IT girl.
One morning, she asks out loud:
G - Can I run a Json?
Me - Wait! What are you trying to do?
G - I need to deploy my changes into the Dev server.
Suddently I realized what she meant.
Me- It's Jenkins! Not Json. :D1 -
Do you also get satisfied when programming certain things and just feel awesome while doing it?
For example I always get a strange satisfaction when I'm writing JSON...3 -
I serialized and parsed a million reddit comments with spacy on my laptop.
It took over an hour.
And then, right when it finished....
http://imgur.com/TIiACHC
I forgot to change from json to ujson
FML.3 -
I don't want to hear about Java, JPA, JSP, Json or John ever again or i will have a mental breakdown10
-
My team member was struggling with his .json files, so to cheer him up, I came up with a joke;
"Don't worry, if the program doesn't work, I'll be your yaaaii son"7 -
Why the fuck should I echo javascript?
Why in fucks name you do not deal with JSON responses?
Plugin devs are either lazy, or simply stupid as fuck!
Ps: Or I'm actually crazy6 -
Neat: MongoDB. Fairly easy to use, intuitive-ish JSON API. Thinking about using it on a project. Excitement.
Neater: Data validation. You can have it drop writes that don't match a schema. Excitement intensifies.
Braindead: It absolutely will not tell you exactly *why* the write doesn't meet the schema, leaving you to figure that out on your own, smart guy. Mongo smugly crosses its arms and tells you to go back and do it right without actually telling you what the problem is.
Fucking braindead: This has been an open feature request since year of our lord two-thousand-and-fucking-fifteen. https://jira.mongodb.org/browse/...7 -
I never missed a semicolon in my life.
I'm too used to put them everywhere, so when I write JSON object 9/10 I get an error1 -
I just realized, that not just my name is Jason, like JSON. I also have the same birthday, as the creator(Brendan Eich) of JavaScript (and Brave + Mozilla)
That's gotta be a calling for me to really get into JS -
What the sh*t is this kind of response?! One of my corporate department's internal API returns THIS.
LOOK AT IT. LOOK. "NULL". What are those malformed closing / ending brackets?!
(request headers have accept: application/json btw)
And, as a final "f*uck you", the "IPG_API_JOBD_NC_RESP_P_COLL" is returned as JSON object if response has one element to return, but will be JSON ARRAY if result has more than one element.
Good luck, you there with strongly typed languages..... Boils my blood 😅 4
4 -
So my real name is jason and I got the habit to use Json as my nickname as a little Dev pun.
I think I overdid it 3
3 -
Today I learned about binary encoding formats alternative to JSON such as Google Protocol Butter.
I like these binary formats.
Just thought I would share this here so others would benefit as well (and please share your experience if it is relevant)8 -
Always when I hear someone talking and the word JSON drops by.. I sing the prelude "jaaasonnnn deruloooo"
Would you hate me?1 -
>About to create Helperclass for JSON parsing and writing
>Realises there's the GSON-library by Google
>shamefully and silently like a fart deletes 1 hour of work
>repeatedly bangs head against desktop4 -
I started thinking it would be a good idea to write a shopping list in json so it's nice and categorised.
Then I thought what people who saw my list in the shop would say.3 -
Ok so I was fetching some JSON data from a SQL database server and loading it on the front-end. Every single data is being loaded onto the table except for a single data column, which is empty.
Hmmm... So I go and check my code... everything looks fine.
Then I console.log the JSON (using .stringify() of course), all the values from the table are present in the printed out JSON.
Ok, now I am really pissed.
Long story short...
I had misplaced a single 'i' in the SQL statement, I had included the 'í' (the i-acute) character instead. And since I was using an alias in the query statement, no error was shown.4 -
So we got these webservices, that are written in XML and they needed to be parsed and converted into a JSON-model. Well...

-
Dear API vendor,
Please get off your arse and learn about REST, OpenAPI, JSON Schema, XSD and basic documentation so that I don't have to guess how to use your shitty, inconsistent, RPC over HTTP service.
With Love,
Platypus2 -
I just wasted 4 hours debugging a wordpress plugin because the API was returning only the first element of a list. I posted it on support forums, downloaded the plugin's source code and tried to manually find the cause, and I was about to post an issue on the plugin's github page.
It turns out that I forgot I had '$[0]' in my insomnia json filter.... I should probably look for a different job.3 -
@Android Question
Does all android devs use Async Task for their Json calls or you prefer to do them on Main Thread ?
Am just asking to improve my skills and get some senior programmers opinion14 -
See that dip in JSON in 2018? It's countered by a slight rise in YAML. According to this article, it's because of all CI and Docker services. Can't think of many reasons to use YAML above e.g. JSON.
https://theregister.co.uk/AMP/2018/... 20
20 -
Am I the only one who just loves when I do "curl 127.0.0.1:9200/_template" and get back entire 32" screenful of compressed JSON?
Frikin elastic...7 -
Working on an Android app for a client who has a dev team that is developing a web app in with ember js / rails. These folks are "in charge" of the endpoints our app needs to function. Now as a native developer, I'm not a hater of a web apps way of doing things but with this particular app their dev teams seems to think that all programming languages can parse json as dynamically as javascript...
Exhibit A:
- Sample Endpoint Documentation
* GetImportantInfo
* Params: $id // id of info to get details of
* Endpoint: get-info/$id
* Method: GET
* Entity Return {SampleInfoModel}
- Example API calls in desktop REST client
* get-info/1
- response
{
"a" : 0,
"b" : false,
"c" : null
}
* get-info/2
- response
{
"a" : [null, "random date stamp"],
"b" : 3.14,
"c" : {
"z" : false,
"y" : 0.5
}
}
* get-info/3
- response
{
"a" : "false" // yes as a string
"b" : "yellow"
"c" : 1.75
}
Look, I get that js and ruby have dynamic types and a string can become a float can become a Boolean can become a cat can become an anvil. But that mess is very difficult to parse and make sense of in a stack that relies on static types.
After writing a million switch statements with cases like "is Float" or "is String" from kotlin's Any type // alias for java.Object, I throw my hands in the air and tell my boss we need to get on the phone with these folks. He agrees and we schedules a day that their main developer can come to our shop to "show us the ropes".
So the day comes and this guy shows up with his mac book pro and skinny jeans. We begin showing him the different data types coming back and explain how its bad for performance and can lead to bugs in the future if the model structure changes between different call params. He matter of factually has an epiphany and exclaims "OHHHHHH! I got you covered dawg!" and begins click clacking on his laptop to make sense of it all. We decide not to disturb him any more so he can keep working.
3 hours goes by...
He burst out of our conference room shouting "I am the greatest coder in the world! There's no problem I can't solve! Test it now!"
Weary, we begin testing the endpoints in our REST clients....
His magic fix, every single response is a quoted string of json:
example:
- old response
{
"foo" : "bar"
}
- new "improved" response
"{ \"foo\" : \"bar\" }"
smh....8 -
When a JSON structure returns back as:
{
"array_data" : {
"123" : {
"id" : 123,
"name" : "NAME"
},
"176" : {
"id" : 176,
"name" : "NAME"
},
"189" : {
"id" : 189,
"name" : "NAME"
}
}
}
Instead of:
{
"array_data": [
{
"id": 123,
"name": "NAME"
},
{
"id": 176,
"name": "NAME"
},
{
"id": 189,
"name": "NAME"
}
]
}3 -
Come on guys, use those JSON schemas properly. The number of times I see people going "err, few strings here, any other properties ok, no properties required, job done." Dahhh, that's pointless. Lock that bloody thing down as much as you possibly can.
I mean, the damn things can be used to fail fast whenever you misspell properties, miss required properties, format dates wrong - heck, even when you want to validate the set format of an array - and then libraries will throw back an error to your client (or logs if you're just on backend) and tell you *exactly what's wrong.* It's immensely powerful, and all you have to do is craft a decent schema to get it for free.
If I see one more person trying to validate their JSON manually in 500 lines of buggy code and throwing ambiguous error messages when it could have been trivially handled by a schema, I'm going to scream.16 -
What do you think of LinkedIn's quizzes? I passed the JavaScript one but failed JSON... JSON!! Are you fucking serious! How is that even possible!!!10
-
The company I work for uses Coldfusion which is a dead technology in my opinion. I was tasked with using a data grid for our data from our mssql databases. This data grid I was trying out uses ajax to make a call to the server and expects the data transfered back in Json format. well coldfusion sucks balls because it's serializeJson function returns a outdated JSON structure and I can't use it. So obviously this datagrid throws errors and when I try looking up coldfusion solutions online or scope out stack overflow, the posts are dated like 6 years back because no one fucking uses CF anymore. My boss loves to jerk to it, it seems because he refuses to change languages cause its all they have ever used. -_- this is 2016 bitch lol6
-
My eyes hurt everytime our backend guy gives me a new REST API to implement in our app and always the formatting of the json is something like this. Like why can't you just fucking format it properly so I won't have to look at my code and feel disappointed for writing such ugly code. All because your lazy ass didn't care to understand the fundamentals of how json objects and arrays work !!! It's been a month since I've joined this company and I'm tired of explaining why we should use the status code for failure checking and not this stupid pass/fail status flag. I don't even remember how many times I've brought it up but everytime I get reasons like "Dude, you know what our server is never going to go down or fail so it doesn't even matter". And at that point I feel like I shouldn't even argue with him anymore.
 3
3 -
What's with JSON conditional evaluation?
How is it a good thing to add conditions to JSON?
Next in line:
Open vacancy: Full stack JSON developer -
I would like to present new super API which I have "pleasure" to work with. Documentation (very poor written in *.docx without list of contents) says that communication is json <-> json which is not entirely true. I have to post request as x-www-form with one field which contains data encoded as json.
Response is json but they set Content-Type header as text/html and Postman didn't prettify body by default...
I'm attaching screenshot as a evidence.
I can't understand why people don't use frameworks and making other lives harder :-/ 3
3 -
Dockers JSON output is garbage.
First, you'll get no JSON per se.
You get a JSON string per image, Like this:
{...} LF
{...} LF
{...} LF
Then I tried to parse the labels.
It looked easy: <Key>=<Value> , delimited by comma.
Lil oneliner... Boom.
Turns out that Docker allows comma in the value line and doesn't escape it.
Great.
One liner turns into char by char parser to properly tokenize the Labels based on the last known delimiter.
I thought that this was a 5 min task.
Guess what, Docker sucks and this has turned into try and error...
For fucks sake, I hated Docker before, but this makes me more angry than anything else. Properly returning an parseable API isn't that hard :@3 -
JoyRant build 19 has a new feature:
A Community Projects page, based on the json api by @joewilliams007
https://github.com/joewilliams007/...
I was inspired by the implementation of that page in skyRant and made a similar one which can be searched and filtered by type and os. 🙂
Apple TestFlight:
https://testflight.apple.com/join/...
Code block highlighting is probably coming next. 7
7 -
I'm working on a firmware for 3d printers. I had to send a lot of data to another microcontroller and I was making a very sophisticated protocol. When finished I was so proud of my work but in that moment I remember that there is a thing called JSON but I didn't care. Now I have to send the same data to a webserver and need to move from my own protocol to JSON.
Fuck me. -
Why doesn't JSON allow trailing commas? Why? How hard is that to implement? Everyone else has them, why not JSON?33
-
Gave boss inside into JSON output for a system he never even sees or uses. Now he suggests changes to that JSON that aren't relevant nor possible...1
-
// Stupid JSON
// Tale of back-end ember api from hell
// Background: I'm an android dev attempting to integrate // with an emberjs / rails back-end
slack conversation:
me 3:51pm: @backend-dev: Is there something of in the documentation for the update call on model x? I formed the payload per the docs like so
{
"valueA": true,
"valueB": false
}
and the call returns success 200 but the data isn't being updated when fetching again.
----------------------------------------------------------------------------------------
backend-dev 4:00pm: the model doesn't look updated for the user are you sure you made the call?
----------------------------------------------------------------------------------------
me 4:01pm: Pretty sure here's my payload and a screen grab of the successful request in postman <screenshot attached>
----------------------------------------------------------------------------------------
backend-dev 4:05pm: well i just created a new user on the website and it worked perfectly your code must be wrong
----------------------------------------------------------------------------------------
me 4:07pm: i can test some more to see if i get any different responses
----------------------------------------------------------------------------------------
backend-dev 4:15pm: ahhhhhh... I think it's expecting the string "true", not true
----------------------------------------------------------------------------------------
me 4:16: but the fetch call returns the json value as a boolean true/false
----------------------------------------------------------------------------------------
backend-dev 4:18pm: thats a feature, the flexible type system allows us to handle all sorts of data transformations. android must be limited and wonky.
----------------------------------------------------------------------------------------
me 4:19pm: java is a statically typed language....
// crickets for ten minutes
me 4:30pm: i'll just write a transform on the model when i send an update call to perform toString() on the boolean values
----------------------------------------------------------------------------------------
backend-dev 4:35: great! told you it wasn't my documentation!
// face palm forever4 -
I swear on the Almighty nature, I fucking hate Browser compatibility.
Passing php data via JSON encode. Works superfine on Firefox and Android mobile browser doesn't on Chrome. Fucking shit. Been sitting for 13 hours and gave up. FFuuuuuuck !!!!
Form submission via ajax and it again works on Firefox but doesn't on Chrome. I just can't understand, my mind is fucked by all the angels in heaven. Data gets submitted, the form is reset but the function called to refresh the JSON data doesn't work.
Someone please kill me or I swear I will fucking kill everybody.4 -
I never liked YAML. But lately, I'm starting to dislike it more and more.
I mean, wtf is that?
- digest YAML input -- a valid YAML
- digest JSON input -- a valid YAML
A language that embeds another language.
Can it be any more confusing..?
Sure it can. the
```
script:
- echo "John said: hello there"
```
will fail YAML linter, because, even though I used quotes, yaml sees `echo "John said` as an object key
I think I'm yet to find more nonsense with YAML. And eventually, I'll grow to hate it.8 -
Me: Browsing DevRant
Me: seeing recent post of @Phlisg
Mhhh 🤔
Why didn't I rant about this?
I literally called myself Json because my name is Jason and there is JSON.
Btw @EaZyCode made fun of me because of this years ago 1
1 -
Im a junior android dev working in a startup. Wasted whole week on trying to parse some retarded json data generated by junior backend guy.
Im talking about objects with other objects as their elements, no use of arrays.
In the end had to redo his data in proper order so I could parse properly. Fkin waste of time.
At least now I know how to do his work, and won't be afraid to confront him with detailed criticism.2 -
JSON is crap sold through marketing and doesn't live up to it's proclaimed goals:
http://seriot.ch/parsing_json.php16 -
Moved all my configuration to json files from normal JS last night. It took me 10 mins to convert. Everything worked perfectly.
This morning I woke up with angry messages from everyone in the team. No one could run their code anymore. It took me whole day to find out that those jsons were the issue. I still don't know how though. 😥1 -
Remember /dev/rant for devrant (https://devrant.com/rants/1569303) ? :)
Here's the first version of it: https://gitlab.com/netikras/... . read-only, with some hacks.
Oh, and if anyone needs a pure-shell library for json -- feel free to use it :) Bear in mind it might still be buggy.2 -
ARRAY LIKE OBJECTS
Long story short, i am fiddling a bit around with javascripts, a json object a php script created and encountered "array-like" objects. I tried to use .forEach and discovered it doesnt work on those.
Easy easy, there is always Array.from()..just..it doesnt work, well it does work for one subset called ['data'] which contains the actual rows i generate a table from, but for the ['meta'] part of the json object it just returns a length 0 object..me no understanderino
at least something cheered me up when researching, it was an article with the quote: "Finally, the spread operator. It’s a fantastic way to convert Array-like objects into honest-to-God arrays."
I like honest-to-God arrays..or in my case honest to Fortuna..doesnt solve my problem though2 -
I'm doing work during the weekend. Just to parse this line of json.
Argh, what drive me nuts is after discovering that json response wasn't proper.
*sample - from what i seen*
{
head= {
data=value,
data=value,
}
}
This is my first time seeing json response with =. Since my assignment is to retrieve the response.
I cheated by calling replace over and over to correct the string of response to correct json format.
That is actually production stuff. Knowing that makes me sick to the stomach.7 -
Trying to parse JSON to case classes and vice versa is like trying to parse HTML with regexes: A straight way to hell.
TO͇̹̺ͅƝ̴ȳ̳ TH̘Ë͖́̉ ͠P̯͍̭O̚N̐Y̡ H̸̡̪̯ͨ͊̽̅̾̎Ȩ̬̩̾͛ͪ̈́̀́͘ ̶̧̨̱̹̭̯ͧ̾ͬC̷̙̲̝͖ͭ̏ͥͮ͟Oͮ͏̮̪̝͍M̲̖͊̒ͪͩͬ̚̚͜Ȇ̴̟̟͙̞ͩ͌͝S̨̥̫͎̭ͯ̿̔̀ͅ1 -
Oh Shit! Here we go again!
print(request_permissions)
>> [ ]
if request_permissions:
//some if shit
else:
raise 404
It was supposed to raise 404 for empty array, but continue to exit if.
Me: What the fuck?
**printing request POST data**
**empty, nothing wrong here**
**double checked print statement output**
** still printing [ ] **
**restart server and again checking print statement**
**still same**
Getting mad over myself, for failing to debug simple if else.
Wait....
print(type(request_permissions))
>> <class 'str'>
Me: What the actual fuck??
Fucker literally dumped empty array to JSON causing array to convert into string "[ ]" and still using if else based on array instead of string length.
Thanks to our Product Manager who approved our request to revamp this part of code and also revamping the whole shitty project developed by 3rd party in upcoming quarter.22 -
Was trying to read the json data from a json file using python. But was stuck for a very long time as it was giving a json decide error. After much fuss I came to figure out that I forgot to use the read function to read the json data from the file :P1
-
I really am not a fan of the contortions you have to go through in Golang to deserialize a fucking JSON blob. If this were any other language I would have already had a data structure I could query rather than wasting hours twiddling structs that will be filled properly.7
-
First you make a filthy JSON protocol where numbers are encapsulated into strings.
Then you document this little fact nowhere. Actually you don't document anything at all.
Then you make a shitty parser that ignores any exception. So that when I try to send my objects, it took two hours to figure out it was "my fault" as I was sending actual integers instead of strings.
I think you deserve to suffer a terrible agony for exactly the amount of time I lost.2 -
Ok, guys, which configuration format is your favorite? (something like toml, ini, json, yaml, etc)28
-
Somebody's rant looks too complex to understand and visualize, they would have used JSON instead 😂😂 !!
-
I know streams are useful to enable faster per-chunk reading of large files (eg audio/ video), and in Node they can be piped, which also balances memory usage (when done correctly). But suppose I have a large JSON file of 500MB (say from a scraper) that I want to run some string content replacements on. Are streams fit for this kind of purpose? How do you go about altering the JSON file 'chunks' separately when the Buffer.toString of a chunk would probably be invalid partial JSON? I guess I could rephrase as: what is the best way to read large, structured text files (json, html etc), manipulate their contents and write them back (without reading them in memory at once)?4
-
rant && !rant
Our timetable for lectures are online as "rapla" eventsystem. I want to write a small app including a timetable. As I didn't found any way to get the lectures as JSON (Bad documentation of API) but only as formated (and ugly) HTML View, I just wrote a small node module that parses the html body with cheerio and fetches all needed data of each entry in a week. Worked out pretty well, will add more functionality.
Never felt so independent 🙌🏻 -
I like how one of my programming lecturers had never even heard of JSON before I asked whether I can use it in the assignment. In her defence (I guess), it wasn't a web dev class, but still how did she never come across JSON in her entire life?3
-
If you feel you're not confused enough in life, try writing JS for a Rhino engine interface implemented on a Java codebase.
I have to deal with stringified JSON, native JSON, java JSON objects (org.json.JSONObject) and all the different attributes and functions specific to each of these objects.
Even "Why are the Kardashians so famous?" doesn't confuse me as much as this shit does.2 -
Can any sql guru take a look at this problem?
I try to select number array from a JSON object, but have no idea how to do it.
https://stackoverflow.com/questions...5 -
Converting javascript/ typescript Map to json
or python date to json
or anything complicated to json is mostly ending with implementing serialization patterns
With date it’s so annoying cause we have iso standards that every language implemented or have libraries
so typescript doesn’t recognize Map<string, string> so you have to convert it to array and then to object
with python you need to make your own serializer / deserializer
So much waste of power usage that if only Greta know it she would say ‘how dare you!’
It can stop global warming.5 -
Maybe some of you will find this useful.
I just finished the first stable version of my JSON-library for Go.
https://github.com/thosebeans/...
It provides a DOM-like interface for JSON-documents.4 -
Currently we have to make a new REST API at work. I want to have a clear and functional API (with HAL JSON, that is given). But my colleagues don’t like this, because they don’t like the design (the look and feel) of the HAL JSON responses. They just want an easy API with a nice design, so they want to ignore half of the HAL JSON specification. But a REST API don’t has to be easy and don’t need a fancy design, REST APIs are not for humans but for computers! How can I explain this to them?3
-
evil === true
Found this one after 4 hours of debugging... Want to screw with other teams? Shove some UTF-8 BOM characters into JSON responses consumed by Node (and other frameworks as well). Watch as they scramble to find why JSON.parse() fails on seemingly nothing.
Background: BOM markers are hidden characters that indicate text stream information to applications. They are not ignored by many JSON parsers and throw exceptions that don't appear to make sense.1 -
It is Tuesday, and I have just spent the last 20 hours hand modifying JSON. It continues tomorrow as well...2
-
Anyone got some good recommendations for a Rust library that takes SQLite and lets you turn it into JSON?
I'm asking for a friend...also, I'm fairly positive the Puritans over at StackOverflow would have me crucified if I asked this one over there...1 -
Why do people keep inventing new object serialisations when there is already JSON and XML? Why do people think that a custom format and parser would be better than an industry standard and a parser that has years of development improvements? :-S
How would you teach / punish these people?2 -
Jackson JSON parser can be a pain in the ass sometimes.
Like, bro, I don't want you to pollute my JSON when saving into Redis. Because now the frontend clients suddenly don't understand the schema because it's riddled with @class and type definitions everywhere.
You have to perform dark magic to get this thing to work automatically with Spring Boot caching.
I've had to implement my own custom serializer and deserializer after wasting who knows how many hours on this.
Shit like this is why I tend to roll my own implementation for many things at the slightest hint that a library isn't flexible.2 -
Any browser (+plugin) recommendations for viewing JSON and XML? Ideally for Mac OS, but have a Windows 7 VM I can use instead if there's a much better option. Currently I'm copying from Safari and pasting into Notepad++ and formatting with a plugin, but that feels pretty sub-optimal. Suggestions much appreciated.3
-
I cant get a JSON object out of my query results!! I have been trying all day and I'm so frustrated and sad. I'm new to JavaScript, AJAX, and JSON. I just want to understand this. I've seen videos, tutorials, but I never get the expected results with jason_encode. And on the client side I don't even know if the request is good since I can't make the JSON object. :(14
-
Why is it, I've handled data in JSON format quite a few times, but every time I try to use it again, I completely forget how JSON works
-
The man just asked how to make folders with the command line, what on earth is this 100-line nightmare json?
https://superuser.com/a/14187013 -
Just tried to attach a reminder for tomorrow to the window object of my brain. Uff... Enough JS and JSON for this week.
Have a nice weekend with stable friday deploys, fellas! -
<rant>
<title>On XML</title>
<message>Too much overhead for such a small amount of data. JSON is much more efficient.</message>
</rant>3 -
Newtonsoft JSON
https://nuget.org/packages/...
CSV Helper
https://nuget.org/packages/...
With ETL these two cover 90% of file ingest. I’m still looking for a good XML “auto class” package.2 -
Just need to pass this json object to the controller as a string. Cool just a quick two minute job.
Three hours later and it's still passing null, what the apple fuckery is your problem?! -
Is there a gui for json generator? eg a form in which i can enter first Name, LastName, Sex etc... then it generates the correct json.21
-
A lot of community projects today...
(i am doing one too)
Anyways, anyone have some good newtonsoft json tutorials?1 -
Golang, I love you to death.
But I will have you know that unsuccessfully scouring the web for why my json config file wasn't being read into the struct followed by almost two hours of messing around with every little thing... And I discover that the fucking problem was my struct member names needed their first letters to be uppercase. Ridiculous.
Gotta love spending forever overthinking. The solution is often too simple!4 -
{
"$schema": "http://json-schema.org/draft-04/...#",
"type": "object",
"id": "https://[URL_NAME]/forms/{id}/...#",
"properties": {
"title" : { "type": "string" },
"date" : { "type": "string" },
"content" : { "type": "string" },
"date_start": { "type": "string" },
"date_end" : { "type": "string" },
"status" : {
"type" : "string",
"enum" : ["1", "2", "3", "4", "5"]
}
},
required [
"title",
"date",
"content",
"date_start",
"date_end",
"status"
]
}
See if you can notice the error is this schema. Don't copy and paste it. I change some format to obsfucate the real data naming, but this schema error is still up there
Just wasted my 30 minutes staring at this10 -
Having to sit and explain the difference between json and jsonp to a graphic designer and and SEO manager
-
Holy shit! Why is it so hard to find a JSON viewer for android that doesn't absolutely suck ass?
I want a viewer that:
-reads json from the clipboard
-queries json for strings in context
-allows copying of values, not the key and the value put together
Major bonus points:
-JSONPath querying
-Free/pay version without ads7 -
There's people that should be in jail.
Or at least they should be banned to use a computer. And I'm looking directly at this company that provides a dodgy API, which is just a ton of static XML files hosted behind an apache. One file per language, of course. You want the prices too? Another url. In German? Oh, another url.
Wait, they're working on v3!! Which will support... json! I don't give a damn about json as long as you provide some sanity with your urls godfuckit.1 -
"DefiantJS enables you to perform lightning-fast searches on JSON using XPath expressions, and transform JSON using XSL."
True if lightning takes for ages. What a disappointment :( -
When you have made too many APIs
Friend : Jay Sean has released an awesome new mix.
You: JSON released what???!!!
-
BLOODY FIREFOX DEVELOPER TOOLS
I was troubleshooting an app (inside container) hitting an endpoint. For debugging purposes I tried hitting the endpoint from my machine, but always got a 404.
So in the firefox developer tools under the network section you see all of the requests happening. Every request, application/json or url-encoded, lists its parameters inside the tab 'parameters' tab. I thought that means those parameters were i side the request body.
Turns out I should have sent the parameters as url encoded instead of POSTing JSON as the request body. This took me way too long.
Why not display the request url like http://url?key=value ... Firefox? Eh?7 -
A command line tool built in Python that helps you analyse your git logs by exporting them into a csv/json file.
Can fetch the logs from a given file path or a git directory.
https://github.com/dev-prakhar/...3 -
So I had this JSON thingy, where I named the property containing a datetime string "timestamp".
For some reason, JS decided to convert that into a unix timestamp int on parse. Thx for nothing.6 -
i know i am late to the party, but i am beginning to fall in love with json for my use of static data procession!
-
How can I be pro at string/json manipulations/regex etc?
I really suck at it and it really impacts my performance.3 -
Why is my test not failing? The actual and the expected json is completely different? What the fuck!?!
It says:
static::assertJson($expected, $actual);
right there.
Oh wait.
Nevermind.
`static::assertJson` only checks for any VALID json string that I always provided in with my own expectation m)
Use `assertJsonStringEqualsJsonString` instead.
What.
Who needs meaningful defaults.
(I would claim that `assertJson` should be defaulft for string equalness, and assertValidJson should be for any Json validation. But you are free to disagree.)3 -
Optimization concepts/patterns or instances?
For pattern its gotta be any time i can take a O(n^2) and turn it into O(n) or literally anything better than O(n^2).
Instance would probably be the time that we took an api method that returned a json list made up of dictionaries CSV-style and changed it into a dictionary with the uid as the key and the other info as key-value pairs in a sub-dictionary. So instead of:
[
{
"Name": name,
"Info":info
}
]
We now return:
{
name:
{
"Info": info
}
}
Which can, if done right, make your runtime O(1), which i love. -
I have a .json file in Github(public) i would like to write into the json file , How should I do it ?32
-
I was tasked to parse some complex output oft another application so that it can be displayed nicely in our Frontend. The output had lots of inconsistencies and exceptions - I spent the entire fucking day to wrote the craziest regex I have ever written in my entire life. With a few minor issues it worked pretty well. I was happy... Then a colleague came into my room, peeked into my screen..
Him: "You are aware you can just specify a --json flag to get json output?"
Me: "..."
*long silence*
Me: 😵🔨
Please end my life. -
Is there any JSON editor/visualizer out here? I really want to analyze my JSON with a cool editor!11
-
const json = {key: 0}
json.key=1
console.log(json);
>>> {key: 1}
I just wasted ages debugging that7 -
I'm implementing a REST API that returns data as it's fetched from MongoDB.
If it's returned all at once it would be a JSON a string like [{}, {}, ...]
But what about when it's returned as a Stream?
Node by default seems to just return it as {}{}{}{} but that can't be parsed by the program that requested it?4 -
Was testing someone's PR but the change did not get loaded into the program. After 2 hours I realized that there was a comma too much in a JSON file.
Fuck this shit, and fuck this comma in particular -
// Pouring over idiot API developer's crappy documentation.
Example:
Goal Detail
* From Docs "table_breakdown key will return an array but will always only contain one json object.
json -> "table_breakdown" [
{
"field" : "value",
"etc" : "etc"
}
]
WHYYYY!!!!1 -
Duuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuck off you bloody infamous basterds flattening their fat asses at Microsoft.
I wasted half of my dev day to configure my wcf rest-api to return an enumeration property as string instead of enum index as integer.
There is actually no out-of-the-box attribute option to trigger the unholy built-in json serializer to shit out the currently set enum value as a pile of characters clenched together into a string.
I could vomit of pure happiness.
And yes.
I know about that StringEnumConverter that can be used in the JsonConvert Attribute.
Problem is, that this shit isn't triggered, no matter what I do, since the package from Newtonsoft isn't used by my wcf service as a standard serializer.
And there is no simple and stable way to replace the standard json serializer.
Christ, almighty!
:/ -
Give me a single reason, why someone will use XML over JSON. I am trying to parse a XML file in Java and it builds a null document everytime. HELP!!5
-
So, I started fiddling around APIs which returned data in JSON and parse that data in PHP and it feels so good.... Past 3 days I've been in deep learning PHP and practically $this is the best thing....
I need recommendations for such APIs, so far I've used
1. Chuck Norris Jokes (http://api.icndb.com/jokes/random/)
2. User's IP Address and details (http://ip-api.com/php/)
What would you recommend, let me know..1 -
If you think laravel is easy, try to modify your json response in a way that's not too nested.
Not all language have built-in null-checking capabilities. We have a hard time in the front-end to do null checking if there are any nested(level 3 or more) JSON Response.2 -
Do we need compression on api level? say I have a rest api sending json data on requests. So if compression is needed then should it be in the server when returning the json response or in the client side when receiving it? which one is ideal?13
-
I completely *detest* that the MongoDB *shell* is just a fucking jS interpreter with extra API calls sprinkled on top and whoever came up with that idea should have all their commits reverted immediately, working with that thing is a punishment!
I don't even know a way to parse and chew through the json it spits out in my own json viewers, as it's "Extended", and none of my editors understand that!
Ugh, haven't been this frustrated with a tool for a while...5 -
JsonLint ParsingException "composer.json does not contain valid JSON" is an incorrect statement. The file contains 99% valid JSON except for 1 incorrect character which is correctly pointed out as an "Invalid string, it appears you have an unescaped backslash at: \-dev".
And why do people in tutorials keep calling it "Jay's on" instead of "Jason" like "Jackson"? I can only imagine what they would call the "King of Pop" musician ... "my cal Jack's Onn"?5 -
Tomorrow is the deadline to deliver the site of our company and have it up & running.
I just heard they also expect a fully functional store locator.
I am still the digital marketer.
And as a bonus
the file with locations that I get to work with is a json file (not even geoJSON).
Oh and they want a 'distinctive' style of course not just any template and it has to be free.2 -
We ended up finding ourselves with a bunch of tables that have mostly the same columns, but differ by a few. Every time we consume a REST API, we store the `access_token`s and expiration dates and the other OAuth data. However, each provider has slightly different requirements. For example, we store email addresses for email api's, other providers require us to store some additional information, etc. etc.. I'm tempted by the flexibility and lack of schema brought by document databases, but not enough to use one since they're generally slower and we already have everything in SQL. So I got the idea of using JSON columns to alleviate this issue: have a single table for all REST integrations (be it outlook or facebook), and then store the unique integration data inside of this JSON column for "additional data". This data is mostly just read, not filtered by (but ocasionally so). Has anyone had experience with this? How's the performance of JSON fields? Is this a good practice or will it get harder with more integrations?
-
json encode...... helps when the need of integration with other platforms arrive. json is good format for sending streams
-
Implemented a feature against a "restful" json api. The feature works, test-driven development ftw.
Yet on the run with the live api: certain important fields all only contain the value `0`.
Confused I asked around what's going on, expected a bug in the api. Now I've been told that those fields never worked and the relevant information has to be gathered by either querying against a (deprecated!) mysql database. Or use a different endpoint increasing the http request overhead by factor over 1000.
We call it team work. -
I had to start over learning SQL when I faced the JSON functions of PostgreSQL during a try and error period to get nested json_agg in one query.. I'am too old for that low level stuff! 🤨
-
I have to design a small web-based application (flask, MySQL) and it will also need an API (e.g. JSON).
Is it good/recommended practice to have the web browser directly use the JSON API? Or should I just let it post form data and reuse the underlying business logic?9 -
Gson is an excellent library every Java/Android developer should know. You can easily parse a Json or XML network response into a POJO class and get ready to go. But the guys who started the project I currently support found a better, smarter, slicker way to parse network responses into memory:
ArrayList<ArrayList<HashMap<String, String>>>
I would love to meet the genius who came up with this idea. I mean, you can parse absolutely any API response without even having to define stupid Java classes or importing libraries! And also you can reutilize the same scheme for literally all Java projects that handle API responses! Wonderful -
Newbie here, is storing json in sql (as like column data) as weird as I think it is or are there valid use cases?
The one I heard, didn't get the details but something like "startup move fast"11 -
ARCHIVED
PANTSEMM - Rust-based json parser geared towards sorting/matching tags on shapes with n sides -
I requested an response from an Json api, the documenting and example showed perfect json as soon as I request it my self I get an array with Json in it.
What fucking logic is it to left your Json api with an array that contains the fucking Json took me way to long to debug that shit.1 -
I need to code up a basic API/JSON consumption script and I literally just can’t bring myself to do it because I’m afraid to fail at doing it right. What is WRONG with me?! Am I the only person who goes through this kind of self-sabotage?4
-
For a little background on the sort of stuff I'm dealing with, check out my last rant.
Anyways, I'm testing this pipeline at work and was just reminded of the fucktarded way a "software engineer", who had a bachelor's biology degree, decided to handle a json file.
The script is question is loading a json file containing an array of objects. The script is written in perl. There's a JSON module. Use that? Fuck no! Let's rather perform an in-place sed command on the file substituting the commas separating objects in the array with newlines, then proceed to read the file line-by-line and parse out the tokens manually. Mind you, in the process of adding the newlines he didn't keep the commas, so now all of these json files his bullshit handled are invalid json that cannot be parsed.
The dumb ass was lucky the data in the file is always output upstream as a single line and the tokens for each object are always in the same order, so that never led to problems. But now, months later after I fixed his stupidity I am being reminded of it again as I'm testing and debugging some old projects as part of regression testing new changes I'm making.
TL;DR Fuck dumbwit motherfuckers who can't even google search "parsing a json file" and doing literally anything that is less fucktarded than manually parsing a json file2 -
I'm browsing through my old 'learning projects'.
I realized that I didn't knew json and exploded the whole json string and had an array with 4 dimensions. -
Pipeline as json is pain and you can't even validate until it breaks on the ci
#makesProgrammingHell4 -
Instead of using MySQL, I zipped a bunch of json files... It's fast, but definitely not reliable, I was young and stupid, I should finally getting started with mySQL, srsly.2
-
Been stuck a week with JSON serializer struggles on the backend I'm working on... First of all, this project has source code dating back to 2013, and the dudes back then decided to use three versions of json. So you have your usual application/json and then two custom ones.
Not happy with that, they decide on using two serializers, XStream and Jackson. One custom and application/json run through XStream, and the other more legacy custom JSON runs through Jackson. So this is a bloody mess.
But now they want application/json running through Jackson, and this is breaking all the regression tests. Have to reimplement all the type, field, alias and other kinds of mappings they made for XStream, and sort out all the regressions this causes.
And the dude who designed all of this is revered in the company, although he left a while back. Not sure if I'm too much of an idiot to understand the utter brilliance of the approach, or its just poorly designed... Fuck my life, those due dates just keep creeping closer and closer and this kinda crap just keeps coming :S2 -
Does anybody know how to create a JSON list of all files in a folder with path+filename, md5 hash, file name and size? My client wished that I rework an open source launcher which is reading an HTML file in JSON format5
-
In regards to my last string of posts regarding react and Auth, I got it working the bearer token is being passed but now just getting XML errors every time I submit a form. All the data being passed is JSON. I've created a stackoverflow question https://stackoverflow.com/questions... as I'm getting nowhere and SO really isn't helping either. So if anyone wants to take a stab, go for it.11
-
Why shouldn't we create JPap, JMum, JBro and JSis..... Jawa............JCena.
.
.
.
.
..
.
Jakanda xD -
I've started looking into stuffs like GraphQL and Linked Data (though I've used Micro Data before on websites) today and while fiddling with stuff, I found this handy tool:
https://search.google.com/structure...
I'm trying to create JSON-LD data and it's really helpful to have something validate my test data 🙂 -
Json + python is hell. I've been working on the past few days to pull key information out of json files with python and it would with some json files but not others.2
-
What if, the newly added JSON datatype in mysql is a way to provide mysql with no-sql-like capabilities.
I mean, some would prefer no-sql cuz they beleive that the tables schema will evolve a lot.
An extra column in mysql table with json datatype called "custom_fields" would do the trick.
What do u think ?8 -
So i have been after this null exception for days now in my webhook my senior gave me the asp
And they told me like make a new project out of it i kept on passing my dialogueflow agents and kept getting null exception and today i finally figured out it was the code for v1 of dialogueflow and today i wrote a new json parsing code and voila it passed im so happy but i encountered new error just few lines ahead about that unexpected character encountered ugh I'm so tired1 -
Is it just me, or are the Jinja2 docs shit?
Won't tell me how to sort my JSON file via a JSON variable. Fucking irritating. -
You know that your are working with a DB-Guy when he provides you a "REST" interface that is outputting table data in JSON format and not even the JSON syntax is correct.
-
Was generating a JSON based config manually to be used by a script another dev wrote - only to be criticized for using the text editors built in formatter. Evidently lining up the colon separating key value pairs is a thing.
If readability was so important to you why the fuck did you decide on using JSON as a configuration format? Especially when you could have gone with YAML or better yet INI (flat key/value pairs) style config. -
!rant but want to know this
how does facebook parse the json like
for(;;);{"key":"value"}
that for loop prevents anyone to read json but how does facebook get away with it? -
Python again
So if I use json.dumps or jsonpickle with request.post(json=json.dumps())
OR
request.post(json=jsonpickle.encode)
Body is received cannot be understood by the service (NodeJs)
BUT
if I do: myObject.__dict__
all is good O_O
Can anyone please explain to the noob me why that happened?














































































































































































































































































Top Tags
Weekly Rant
View