Details
-
AboutJAD ranting forever...
-
SkillsI don't know what I know
-
LocationIndia
-
Github
Joined devRant on 10/16/2016
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Is this so different from tech startup presentation?
Our revolutionary platform leverages next-gen AI, decentralized blockchain orchestration, and hyper-scalable cloud-native microservices to synergize collective intelligence and unlock a paradigm shift in human potential. By gamifying sustainability through tokenized social impact layers and deploying frictionless API integrations across Web3 ecosystems, we’re not just disrupting legacy infrastructures—we’re architecting a regenerative future. Our mission-driven, community-centric, and data-sovereign approach empowers Gen Z digital natives to co-create resilient value networks that transcend borders, democratize innovation, and ultimately save humanity from systemic collapse. 5
5 -
JoyRant build 43
You can now see who upvoted your comment.
This works by getting the info from the notifications list so it will not work for old upvotes which aren’t in the notif list anymore.
Forgot to also add this for rants. Will add later.
Complete list of changes:
* notifications from all tabs load at once
* info button about who upvoted my comment
* comments counter for own rants
* no reply button for own comments
* ignore users locally (added in build 42)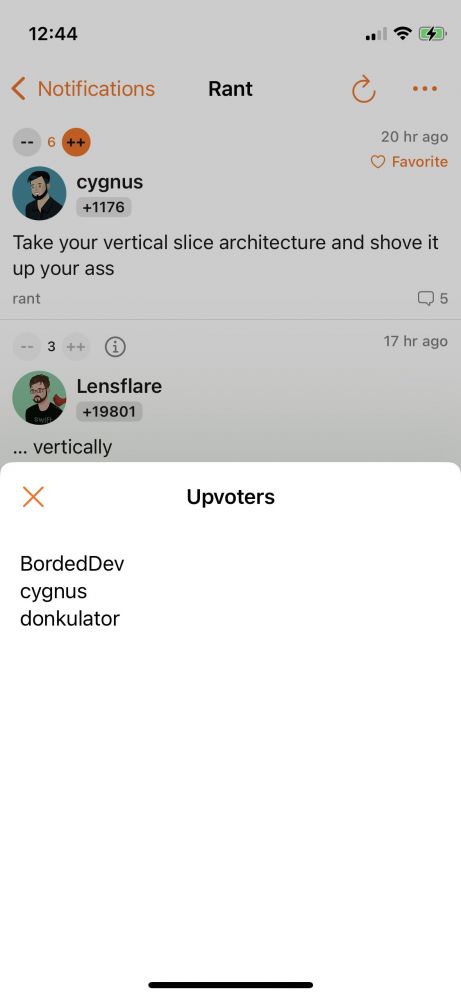 7
7