
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Last year I built the platform 'Tindex'. It was an index of Tinder profiles so people could search by name, gender and age.
We scraped the Tinder profiles through a Tinder API which was discontinued not long ago, but weird enough it was still intact and one of my friends who was also working on it found out how to get api keys (somewhere in network tab at Tinder Online).
Except name, gender and age we also got 3 distances so we could calculate each users' location, then save the location each 15 minutes and put the coordinates on a map so users of Tindex could easily see the current location of a specific Tinder user.
Fun note: we also got the Spotify data of each Tinder user, so we could actually know on which time and which location a user listened to a specific Spotify track.
Later on we started building it out: A chatbot which connected to Tinder so Tindex users could automatically send a pick up line to their new matches (Was kinda buggy, sometimes it sent 3 pick up lines at ones).
Right when we started building a revenue model we stopped the entire project because a friend of ours had found out that we basically violated almost all terms.
Was a great project, learned a lot from it and actually had me thinking twice or more about online dating platforms.
Below an image of the user overview design I prototyped. The data is mock-data.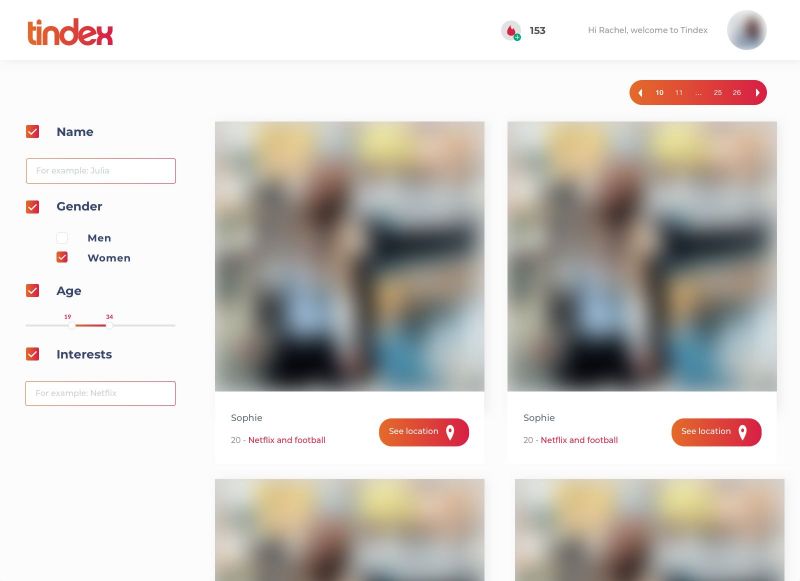 50
50 -
This rant is particularly directed at web designers, front-end developers. If you match that, please do take a few minutes to read it, and read it once again.
Web 2.0. It's something that I hate. Particularly because the directive amongst webdesigners seems to be "client has plenty of resources anyway, and if they don't, they'll buy more anyway". I'd like to debunk that with an analogy that I've been thinking about for a while.
I've got one server in my home, with 8GB of RAM, 4 cores and ~4TB of storage. On it I'm running Proxmox, which is currently using about 4GB of RAM for about a dozen VM's and LXC containers. The VM's take the most RAM by far, while the LXC's are just glorified chroots (which nonetheless I find very intriguing due to their ability to run unprivileged). Average LXC takes just 60MB RAM, the amount for an init, the shell and the service(s) running in this LXC. Just like a chroot, but better.
On that host I expect to be able to run about 20-30 guests at this rate. On 4 cores and 8GB RAM. More extensive migration to LXC will improve this number over time. However, I'd like to go further. Once I've been able to build a Linux which was just a kernel and busybox, backed by the musl C library. The thing consumed only 13MB of RAM, which was a VM with its whole 13MB of RAM consumption being dedicated entirely to the kernel. I could probably optimize it further with modularization, but at the time I didn't due to its experimental nature. On a chroot, the kernel of the host is used, meaning that said setup in a chroot would border near the kB's of RAM consumption. The busybox shell would be its most important RAM consumer, which is negligible.
I don't want to settle with 20-30 VM's. I want to settle with hundreds or even thousands of LXC's on 8GB of RAM, as I've seen first-hand with my own builds that it's possible. That's something that's very important in webdesign. Browsers aren't all that different. More often than not, your website will share its resources with about 50-100 other tabs, because users forget to close their old tabs, are power users, looking things up on Stack Overflow, or whatever. Therefore that 8GB of RAM now reduces itself to about 80MB only. And then you've got modern web browsers which allocate their own process for each tab (at a certain amount, it seems to be limited at about 20-30 processes, but still).. and all of its memory required to render yours is duplicated into your designated 80MB. Let's say that 10MB is available for the website at most. This is a very liberal amount for a webserver to deal with per request, so let's stick with that, although in reality it'd probably be less.
10MB, the available RAM for the website you're trying to show. Of course, the total RAM of the user is comparatively huge, but your own chunk is much smaller than that. Optimization is key. Does your website really need that amount? In third-world countries where the internet bandwidth is still in the order of kB/s, 10MB is *very* liberal. Back in 2014 when I got into technology and webdesign, there was this rule of thumb that 7 seconds is usually when visitors click away. That'd translate into.. let's say, 10kB/s for third-world countries? 7 seconds makes that 70kB of available network bandwidth.
Web 2.0, taking 30+ seconds to load a web page, even on a broadband connection? Totally ridiculous. Make your website as fast as it can be, after all you're playing along with 50-100 other tabs. The faster, the better. The more lightweight, the better. If at all possible, please pursue this goal and make the Web a better place. Efficiency matters.9 -
So I have seen this quite a few times now and posted the text below already, but I'd like to shed some light on this:
If you hit up your dev tools and check the network tab, you might see some repeated API calls. Those calls include a GET parameter named "token". The request looks something like this: "https://domain.tld/api/somecall/..."
You can think of this token as a temporary password, or a key that holds information about your user and other information in the backend. If one would steal a token that belongs to another user, you would have control over his account. Now many complained that this key is visible in the URL and not "encrypted". I'll try to explain why this is, well "wrong" or doesn't impose a bigger security risk than normal:
There is no such thing as an "unencrypted query", well besides really transmitting encrypted data. This fields are being protected by the transport layer (HTTPS) or not (HTTP) and while it might not be common to transmit these fields in a GET query parameter, it's standard to send those tokens as cookies, which are as exposed as query parameters. Hit up some random site. The chance that you'll see a PHP session id being transmitted as a cookie is high. Cookies are as exposed as any HTTP GET or POST Form data and can be viewed as easily. Look for a "details" or "http header" section in your dev tools.
Stolen tokens can be used to "log in" into the website, although it might be made harder by only allowing one IP per token or similar. However the use of such a that token is absolut standard and nothing special devRant does. Every site that offers you a "keep me logged in" or "remember me" option uses something like this, one way or the other. Because a token could have been stolen you sometimes need to additionally enter your current password when doings something security risky, like changing your password. In that case your password is being used as a second factor. The idea is, that an attacker could have stolen your token, but still doesn't know your password. It's not enough to grab a token, you need that second (or maybe thrid) factor. As an example - that's how githubs "sudo" mode works. You have got your token, that grants you more permissions than a non-logged in user has, but to do the critical stuff you need an additional token that's only valid for that session, because asking for your password before every action would be inconvenient when setting up a repo
I hope this helps understanding a bit more of this topic :)
Keep safe and keep asking questions if you fell that your data is in danger
Reeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee5 -
Does anyone go on popular websites and inspect element and to the network tab to see what kind of server they using as a backend?6
-
mangodb's rant reminded me of smth.. Folks from my country might remember this story.
So we have a national e-health system. Millions have been invested, half of the money have never reached the project [disappeared smwhr in between] and its quality is not shiny. It works, sometimes even fast enough. But boy does it have bugs... Let's not get into that. It's politics.
So some time ago one IT guy spotted a bug that allowed him to get sensitive info of other patients. He informed e-health folks and waited for a fix. He waited for a few weeks but the fix had never been released. So he published his findings in soc media [yepp.. Stupid move]. That caused a national scandal. Not to mention he had been pressed with charges.
That guy and our health minister were invited in one of the tv debates. The guy was asked to explained how he found all this sensitive data. And he explained that he hit f12 in his browser, opened a network tab, issued a network request by clicking smth in the webpage analysed received data in the dev tools.
The minister looked somewhat happy, maybe a lil proud of himself - a person who has a "gotcha!" moment has that very glow he had. And he said: "what you did there was obvious hacking. I reckon you should know that true developers do not do those things you have just explained to us" [he was talking about dev tools].
I died inside a little bit.3 -
Chrome. Hit F12 and start typing. Those keystrokes used to go into the console, right? I'm not imagining things...
And then some giant free-standing penis decided that instead, the initial focus should be in the search box.
So you type, nothing appears in the console, you focus the console, and carry on.
Then you're wondering why your api calls aren't in the network tab. Caching issues? Event handler crapping out? No, it's because that command you tried to enter ten minutes ago is still in the search box and being used as a filter.
Because someone decided to change the default focus.
As a wise man once said: "who the fuck was that? Who's the slimy little communist shit twinkle-toed cocksucker who just signed his own death warrant?"
Why didn't anyone stop him? In the meeting where he suggested that, why didn't his colleagues grab him by the testicles and drag him out of the building?
Why?
Fuckers.11 -
So I've created this account specifically for this rant. I usually just browse anonymously.
I've recently been hired in a big company that is one of the biggest Microsoft users in the world and my essentially revolves on making it easier for our collaborators to work with SharePoint (and other ms software)
Never in my life have I hit that much of a roadblock. So for the past week I've been trying to integrate what Ms calls webparts. And to modify the default webparts Ms provides you need to their properties (or Metadata). Except here's the big problem these are NOT documented anywhere (unless I failed to find it, if you do know where it is documented please HMU), so I've found myself trying to reverse engineer the js scripts that are served with SharePoint to figure out what the webpart properties are called and what type of data they are! I've been going through endless github repos using the CSOM nuget package (it's the library everyone uses to interact with SharePoint) and I finally found out about this other library called PnP which is a wrapper around CSOM that makes it easier to use. That wrapper has a way for me to load existing page and look at the properties of existing webparts. So here I thought it was the end of my suffering and I could finally get an idea of what it should be. Turns out this method doesn't work because one of the dependencies it has has had breaking changes and they still updated it even though it breaks their code! So for the past two days I've been trying random combinations of key values with different data types and json serialization methods.
Oh and yeah I've also looked at all the http calls via the chrome network tab, the metadata is not served as an individual file but is computed by Ms servers when they're serving you their html files.
So uh yeah run from CSOM if you can..3 -
Today’s text chat:
Me walking near the river in the middle of nowhere with a cellphone.
frontend developer:
- I need image from test server. Can you provide me that image ? I need it for my local environment to fix something ( writes details of how to get an image ).
me:
- Can’t you go to test server website and get it by yourself ?
frontend developer:
- But this image is on canvas element.
me:
- Because frontend is drawing in on canvas so go to network tab and get the url.
frontend developer:
- Ah yes I can do that
I have such small talks all the fucking time. They accumulate when I go out to chill during the day.1 -
just found out a vulnerability in the website of the 3rd best high school in my country.
TL;DR: they had burried in some folders a c99 shell.
i am a begginer html/sql/php guy and really was looking into learning a bit here and there about them because i really like problem solving and found out ctfs mainly focus on this part of programming. i am a c++ programmer which does school contest like programming problems and i really enjoy them.
now back on topic.
with this urge to learn more web programming i said to myself what other method to learn better than real life sites! so i did just that. i first checked my school site. right click. inspect element. it seemed the site was made with wordpress. after looking more into the html code for the site i concluded all the images and files i could see on the site were from a folder on the server named 'wp-content/uploads'. i checked the folder. and here it got interesting. i did a get request on the site. saw the details. then i checked the site. bingo! there are 3 folders named '2017', '2018', '2019'. i said to myself: 'i am god.'
i could literally see all the announcements they have made from 2017-2019. and they were organised by month!!! my curiosity to see everything got me to the final destination.
with this adrenaline i thought about another site. in my city i have the 3rd most acclaimed high school in the country. what about checking their security?
so i typed the web address. looked around. again, right click, inspect element and looked around the source code. this time i was more lucky. this site is handmade!!! i was soooo happy because with my school's site i was restricted with what they have made with wordpress and i don't have much experience with it.
amd so i began looking what request the site made for the logos and other links. it seemed all the other links on the site were with this format: www.site.com/index.php?home. and i was very confused and still am. is this referencing some part of the site in the index.php file? is the whole site written inside the index.php file and with the question mark you just get to a part of the site? i don't really get it.
so nothing interesting inside the networking tab, just some stylesheets for the site's design i guess. i switched to the debugger tab and holy moly!! yes, it had that tree structure. very familiar. just like a project inside codeblocks or something familiar with it. and then it clicked me. there was the index.php file! and there was another folder from which i've seen nothing from the network tab. i finally got a lead!! i returned in the network tab, did a request to see the spgm folder and boooom a site appeared and i saw some files and folders from 2016. there was a spgm.js file and a spgm.php file. there was a contrib, flavors, gal and lang folders. then it once again clicked me! the lang folder was las updated this year in february. so i checked the folder and there were some files named lang with the extension named after their language and these files were last updated in 2016 so i left them alone. but there was this little snitch, this little 650K file named after the name of the school's site with the extension '.php' aaaaand it was last modified this year!!!! i was so excited! i thought i found a secret and different design of the site or something completely else! i clicked it and at first i was scared there was this black/red theme going on my screen and something was a little odd. there were no school announcements or event, nononoooo. this was still a tree structured view. at the top of the site it's written '!c99Shell v. 1.0...'
this was a big nono. i saw i could acces all kinds of folders. then i switched to the normal school website and tried to access a folder i have seen named userfiles and got a 403 forbidden error. wopsie. i then switched to the c99 shell website and tried to access the userfiles folder and my boy showed all of its contents. it was nakeeed naked. like very naked. and in the userfiles folder there were all, but i mean ALL files and folders they have on the server. there were a file with the salary of each job available in the school. some announcements. there was a list with all the students which failed classes. there were folders for contests they held. it was an absolute mess and i couldn't believe it.
i stopped and looked at the monitor. what have i done? just to learn some web programming i just leaked the server of the 3rd most famous high school in my country. image a black hat which would have seriously caused more damage. currently i am writing an email to the school to updrage their security because it is reaaaaly bad.
and the journy didn't end here. i 'hacked' the site 2 days ago and just now i thought about writing an email to the school. after i found i could access the WHOLE server i searched for the real attacker so if you want to knkw how this one went let me know in the comments.
sorry for the long post, but couldn't held it anymore13 -
TL;DR: There was a Steam bug and I fixed it locally.
Some months ago, Steam had the problem, that if you tried to add anything from the Steam Workshop to a collection, you would get an error like "Process failed: 2", while it was loading the collection list.
I realized, that it would work, but there was a bug in the JS (Watched the network tab in chrome while trying to add to collection). I searched after "Process failed" in each js file and after 30 seconds I found the buggy if. It said something like
if (json.success != 2) {
//do error
} else {
//show list
}
After I changed that if condition to
if (false)...
it worked perfectly, although it would make problems if there would be a server side error.2 -
Compiled Gentoo after ~5 days.
It's not ever yet though.
My kernel is now 7.3M, and it contains almost everything I need. Even my network drivers (intel) firmware is built-in.
It boots straight off UEFI (default BOOT/bootx64.efi), and
Managed to install X, Waylan (sway!)
Got dvorak programmer's keyboard defaulted.
df -h:
root 4.7G/14G (exact) used
boot 21M/127M (exact) used
var 701M/~5.5G used
AAAAAAAAAAAAAAAARRRRRRRRRRRRRGHHHHHHHHH
Was doing the installation from a Live CD (UEFI) during school hours, with my toughpad not working and no mouse with me. I feel bad for TAB.
I am, at this moment, still compiling... -
Does anyone know any android browser or app to have similar functionality of network tab in chrome?
P.S. For Non Rooted Phone5 -
BLOODY FIREFOX DEVELOPER TOOLS
I was troubleshooting an app (inside container) hitting an endpoint. For debugging purposes I tried hitting the endpoint from my machine, but always got a 404.
So in the firefox developer tools under the network section you see all of the requests happening. Every request, application/json or url-encoded, lists its parameters inside the tab 'parameters' tab. I thought that means those parameters were i side the request body.
Turns out I should have sent the parameters as url encoded instead of POSTing JSON as the request body. This took me way too long.
Why not display the request url like http://url?key=value ... Firefox? Eh?7 -
In spent more than an hour trying to figure out why a form didn't work.
I pressed the submit button and nothing happened, no error in the console and nothing in the Network tab in Chrome's devtools. And the action was being executed!
Then I found out there was a catch somewhere. I removed and it said that the url was wrong. But again, I debugged it and nothing seemed wrong. I even hardcoded the values.
At the end, it turned out that the initial "/" was missing in the request url...















Top Tags
Weekly Rant
View