
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
You know what's the difference between
- static page written purely in HTML with inline styling
and
- dynamic page generated in PHP, that actually loads data from MySQL database and is correctly styled in separate CSS document
on national level exam necessary to earn a title of technician?
ONE HACKING PERCENT!
Ok, backstory. So, few days ago I got results from that exam. To be honest, it was very, very easy so I wasn't worried at all, unlike some of my classmates who just don't understand programming at all (you need at least 75% to pass). Our task was to create database, write website in PHP that shows contents of that database and use CSS to give it a look that of example web page and run it on XAMPP. I've got result of 96% and while I was wandering what I've done wrong i hear my colleague almost screaming with joy "I passed! And I haven't even touched PHP. I was soooo sure I'll fail." So I asked him what's his result and he says 95%. And then another colleague said he got 95% without PHP. So, in other words what I thought to be the main task was worth 1%. Apparently, what was more important was for the page to look identical to the example, so I guess some examiners didn't even look into the source. And don't get me wrong, I don't wish my classmates had failed. That's not why I'm ranting. But why in the name of Ada Lovelace the task said to use PHP and all that if it weren't supposed to check our knowledge of programming in PHP? Sometimes I think the people who design these tests don't even know what they're doing.10 -
Long story short, I'm unofficially the hacker at our office... Story time!
So I was hired three months ago to work for my current company, and after the three weeks of training I got assigned a project with an architect (who only works on the project very occasionally). I was tasked with revamping and implementing new features for an existing API, some of the code dated back to 2013. (important, keep this in mind)
So at one point I was testing the existing endpoints, because part of the project was automating tests using postman, and I saw something sketchy. So very sketchy. The method I was looking at took a POJO as an argument, extracted the ID of the user from it, looked the user up, and then updated the info of the looked up user with the POJO. So I tried sending a JSON with the info of my user, but the ID of another user. And voila, I overwrote his data.
Once I reported this (which took a while to be taken seriously because I was so new) I found out that this might be useful for sysadmins to have, so it wasn't completely horrible. However, the endpoint required no Auth to use. An anonymous curl request could overwrite any users data.
As this mess unfolded and we notified the higher ups, another architect jumped in to fix the mess and we found that you could also fetch the data of any user by knowing his ID, and overwrite his credit/debit cards. And well, the ID of the users were alphanumerical strings, which I thought would make it harder to abuse, but then realized all the IDs were sequentially generated... Again, these endpoints required no authentication.
So anyways. Panic ensued, systems people at HQ had to work that weekend, two hot fixes had to be delivered, and now they think I'm a hacker... I did go on to discover some other vulnerabilities, but nothing major.
It still amsues me they think I'm a hacker 😂😂 when I know about as much about hacking as the next guy at the office, but anyways, makes for a good story and I laugh every time I hear them call me a hacker. The whole thing was pretty amusing, they supposedly have security audits and QA, but for five years, these massive security holes went undetected... And our client is a massive company in my country... So, let's hope no one found it before I did.6 -
Writing more infrastructure than product.
Look, my application requests and transforms data from a single external API endpoint, it's just one GET request...
But I made an intelligent response caching middleware to prevent downtime when the parent API goes down, I made mocks and tests for everything, the documentation is directly generated from the code and automatically hosted for every git branch using hooks, responses are translated into JSONschema notation which automatically generate integration tests on commit, and the transformations are set up as a modular collection of composable higher order lenses!
Boss: Please use less amphetamine.5 -
I'm editing the sidebar on one of our websites, and shuffling some entries. It involves moving some entries in/out of a dropdown and contextual sidebars, in/out of submenus, etc. It sounds a little tedious but overall pretty trivial, right?
This is day three.
I learned React+Redux from scratch (and rebuilt the latter for fun) in twice that long.
In my defense, I've been working on other tasks (see: Alerts), but mostly because I'd rather gouge my freaking eyes out than continue on this one.
Everything that could be wrong about this is. Everything that could be over-engineered is. Everything that could be written worse... can't, actually; it's awful.
Major grievances:
1) The sidebars (yes, there are several) are spread across a ridiculous number of folders. I stopped counting at 20.
2) Instead of icon fonts, this uses multiple images for entry states.
3) The image filenames don't match the menu entry names. at all. ("sb_gifts.png" -> orders); active filenames are e.g. "sb_giftsactive.png"
4) The actions don't match the menu entry names.
5) Menu state is handled within the root application controller, and doesn't use bools, but strings. (and these state flags never seem to get reset anywhere...)
6) These strings are used to construct the image filenames within the sidebar views/partials.
7) Sometimes access restrictions (employee, manager, etc.) are around the individual menu entries, sometimes they're around a partial include, meaning it's extremely difficult to determine which menu entries/sections/subsections are permission-locked without digging through everything.
8) Within different conditionals there are duplicate blocks markup, with duplicate includes, that end up render different partials/markup due to different state.
9) There are parent tags outside of includes, such as `<ul>#{render 'horrific-eye-stabbing'}</ul>`
10) The markup differs per location: sometimes it's a huge blob of non-semantic filthiness, sometimes it's a simple div+span. Example filth: section->p->a->(img,span) ... per menu entry.
11) In some places, the markup is broken, e.g. `<li><u>...</li></u>`
12) In other places, markup is used for layout adjustments, such as an single nested within several divs adorned with lots of styles/classes.
13) Per-device layouts are handled, not within separate views, but by conditionally enabling/disabling swaths of markup, e.g. (if is_cordova_session?).
14) `is_cordova_session` in particular is stored within a cookie that does not expire, and within your user session. disabling it is annoying and very non-obvious. It can get set whether or not you're using cordova.
15) There are virtually no stylesheets; almost everything is inline (but of course not actually everything), which makes for fun layout debugging.
16) Some of the markup (with inline styling, no less) is generated within a goddamn controller.
17) The markup does use css classes, but it's predominately not for actual styling: they're used to pick out elements within unit tests. An example class name: "hide-for-medium-down"; and no, I can't figure out what it means, even when looking at the tests that use it. There are no styles attached to that particular class.
18) The tests have not been updated for three years, and that last update was an rspec version bump.
19) Mixed tabs and spaces, with mixed indentation level (given spaces, it's sometimes 2, 4, 4, 5, or 6, and sometimes one of those levels consistently, plus an extra space thereafter.)
20) Intentional assignment within conditionals (`if var=possibly_nil_return_value()`)
21) hardcoded (and occasionally incorrect) values/urls.
... and last but not least:
22) Adding a new "menu sections unit" (I still haven't determined what the crap that means) requires changing two constants and writing a goddamn database migration.
I'm not even including minor annoyances like non-enclosed ternaries, poor naming conventions, commented out code, highly inefficient code, a 512-character regex (at least it's even, right?), etc.
just.
what the _fuck_
Who knew a sidebar could be so utterly convoluted?6 -
Two big moments today:
1. Holy hell, how did I ever get on without a proper debugger? Was debugging some old code by eye (following along and keeping track mentally, of what the variables should be and what each step did). That didn't work because the code isn't intuitive. Tried the print() method, old reliable as it were. Kinda worked but didn't give me enough fine-grain control.
Bit the bullet and installed Wing IDE for python. And bam, it hit me. How did I ever live without step-through, and breakpoints before now?
2. Remember that non-sieve prime generator I wrote a while back? (well maybe some of you do). The one that generated quasi lucas carmichael (QLC) numbers? Well thats what I managed to debug. I figured out why it wasn't working. Last time I released it, I included two core methods, genprimes() and nextPrime(). The first generates a list of primes accurately, up to some n, and only needs a small handful of QLC numbers filtered out after the fact (because the set of primes generated and the set of QLC numbers overlap. Well I think they call it an embedding, as in QLC is included in the series generated by genprimes, but not the converse, but I digress).
nextPrime() was supposed to take any arbitrary n above zero, and accurately return the nearest prime number above the argument. But for some reason when it started, it would return 2,3,5,6...but genprimes() would work fine for some reason.
So genprimes loops over an index, i, and tests it for primality. It begins by entering the loop, and doing "result = gffi(i)".
This calls into something a function that runs four tests on the argument passed to it. I won't go into detail here about what those are because I don't even remember how I came up with them (I'll make a separate post when the code is fully fixed).
If the number fails any of these tests then gffi would just return the value of i that was passed to it, unaltered. Otherwise, if it did pass all of them, it would return i+1.
And once back in genPrimes() we would check if the variable 'result' was greater than the loop index. And if it was, then it was either prime (comparatively plentiful) or a QLC number (comparatively rare)--these two types and no others.
nextPrime() was only taking n, and didn't have this index to compare to, so the prior steps in genprimes were acting as a filter that nextPrime() didn't have, while internally gffi() was returning not only primes, and QLCs, but also plenty of composite numbers.
Now *why* that last step in genPrimes() was filtering out all the composites, idk.
But now that I understand whats going on I can fix it and hypothetically it should be possible to enter a positive n of any size, and without additional primality checks (such as is done with sieves, where you have to check off multiples of n), get the nearest prime numbers. Of course I'm not familiar enough with prime number generation to know if thats an achievement or worthwhile mentioning, so if anyone *is* familiar, and how something like that holds up compared to other linear generators (O(n)?), I'd be interested to hear about it.
I also am working on filtering out the intersection of the sets (QLC numbers), which I'm pretty sure I figured out how to incorporate into the prime generator itself.
I also think it may be possible to generator primes even faster, using the carmichael numbers or related set--or even derive a function that maps one set of upper-and-lower bounds around a semiprime, and map those same bounds to carmichael numbers that act as the upper and lower bound numbers on the factors of a semiprime.
Meanwhile I'm also looking into testing the prime generator on a larger set of numbers (to make sure it doesn't fail at large values of n) and so I'm looking for more computing power if anyone has it on hand, or is willing to test it at sufficiently large bit lengths (512, 1024, etc).
Lastly, the earlier work I posted (linked below), I realized could be applied with ECM to greatly reduce the smallest factor of a large number.
If ECM, being one of the best methods available, only handles 50-60 digit numbers, & your factors are 70+ digits, then being able to transform your semiprime product into another product tree thats non-semiprime, with factors that ARE in range of ECM, and which *does* contain either of the original factors, means products that *were not* formally factorable by ECM, *could* be now.
That wouldn't have been possible though withput enormous help from many others such as hitko who took the time to explain the solution was a form of modular exponentiation, Fast-Nop who contributed on other threads, Voxera who did as well, and support from Scor in particular, and many others.
Thank you all. And more to come.
Links mentioned (because DR wouldn't accept them as they were):
https://pastebin.com/MWechZj912 -
I wrote a node + vue web app that consumes bing api and lets you block specific hosts with a click, and I have some thoughts I need to post somewhere.
My main motivation for this it is that the search results I've been getting with the big search engines are lacking a lot of quality. The SEO situation right now is very complex but the bottom line is that there is a lot of white hat SEO abuse.
Commercial companies are fucking up the internet very hard. Search results have become way too profit oriented thus unneutral. Personal blogs are becoming very rare. Information is losing quality and sites are losing identity. The internet is consollidating.
So, I decided to write something to help me give this situation the middle finger.
I wrote this because I consider the ability to block specific sites a basic universal right. If you were ripped off by a website or you just don't like it, then you should be able to block said site from your search results. It's not rocket science.
Google used to have this feature integrated but they removed it in 2013. They also had an extension that did this client side, but they removed it in 2018 too. We're years past the time where Google forgot their "Don't be evil" motto.
AFAIK, the only search engine on earth that lets you block sites is millionshort.com, but if you block too many sites, the performance degrades. And the company that runs it is a for profit too.
There is a third party extension that blocks sites called uBlacklist. The problem is that it only works on google. I wrote my app so as to escape google's tracking clutches, ads and their annoying products showing up in between my results.
But aside uBlacklist does the same thing as my app, including the limitation that this isn't an actual search engine, it's just filtering search results after they are generated.
This is far from ideal because filter results before the results are generated would be much more preferred.
But developing a search engine is prohibitively expensive to both index and rank pages for a single person. Which is sad, but can't do much about it.
I'm also thinking of implementing the ability promote certain sites, the opposite to blocking, so these promoted sites would get more priority within the results.
I guess I would have to move the promoted sites between all pages I fetched to the first page/s, but client side.
But this is suboptimal compared to having actual access to the rank algorithm, where you could promote sites in a smarter way, but again, I can't build a search engine by myself.
I'm using mongo to cache the results, so with a click of a button I can retrieve the results of a previous query without hitting bing. So far a couple of queries don't seem to bring much performance or space issues.
On using bing: bing is basically the only realiable API option I could find that was hobby cost worthy. Most microsoft products are usually my last choice.
Bing is giving me a 7 day free trial of their search API until I register a CC. They offer a free tier, but I'm not sure if that's only for these 7 days. Otherwise, I'm gonna need to pay like 5$.
Paying or not, having to use a CC to use this software I wrote sucks balls.
So far the usage of this app has resulted in me becoming more critical of sites and finding sites of better quality. I think overall it helps me to become a better programmer, all the while having better protection of my privacy.
One not upside is that I'm the only one curating myself, whereas I could benefit from other people that I trust own block/promote lists.
I will git push it somewhere at some point, but it does require some more work:
I would want to add a docker-compose script to make it easy to start, and I didn't write any tests unfortunately (I did use eslint for both apps, though).
The performance is not excellent (the app has not experienced blocks so far, but it does make the coolers spin after a bit) because the algorithms I wrote were very POC.
But it took me some time to write it, and I need to catch some breath.
There are other more open efforts that seem to be more ethical, but they are usually hard to use or just incomplete.
commoncrawl.org is a free index of the web. one problem I found is that it doesn't seem to index everything (for example, it doesn't seem to index the blog of a friend I know that has been writing for years and is indexed by google).
it also requires knowledge on reading warc files, which will surely require some time investment to learn.
it also seems kinda slow for responses,
it is also generated only once a month, and I would still have little idea on how to implement a pagerank algorithm, let alone code it.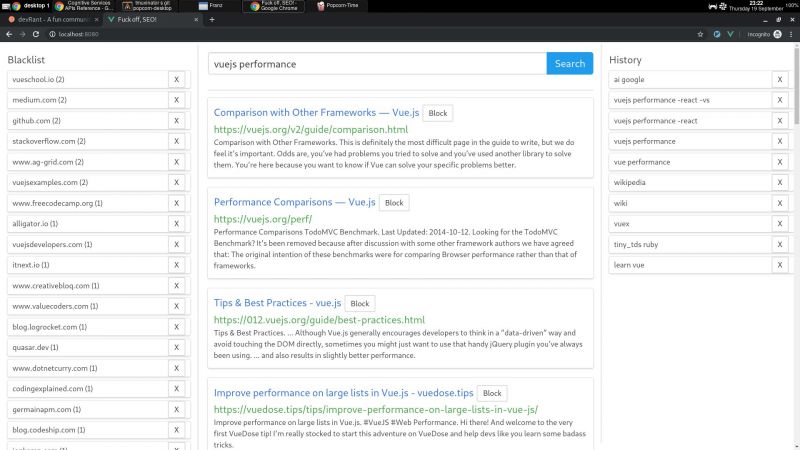 4
4 -
I'm getting really tired of those dumbass programmers that do not understand shit and then come to me when production breaks. (I am also a programmer, not really a DevOps engineer, but I'm the least worst at DevOps stuff, so it's my job...).
We're programming some kind of document management tool. Today we had a release, and one of the new features is to download all of your documents as a zip file, which is asynchronuously generated. When it's done, the user gets a mail with the download link to the zip file.
The feature works basically, but today it broke our production service, as somebody was running a test of it.
Turns out all the documents are loaded into memory to be zipped. So if you have 2 gigs of documents, a container with memory restrictions in that area will crash.
I asked the programmer who reported this «ops problem» to me, why he didn't just shit the files into a temp foler in order to zip them in there.
He told me that he wanted to do so, but did not know how to mock this for a unit test, and therefore went to the in-memory «solution», which was easier for him to mock.
For fuck's sake, unit tests and mocks are fucking tools, not ends in itself! I don't give a fuck about your pointless mocking code when the application crashes!
When I got to deal with such dumbasses, I'd prefer to mock those motherfuckers with a leaky bucket of liquid shit, which basically accomplishes the same task from my perspective: dripping shit all over the place and make everything suck as fuck.3 -
Oh, $work.
Ticket: Support <shiny new feature> in <seriously dated code> to allow better “searching” (actually: generating reports, not searching)
UI: “Filter on” inputs above a dynamic JS table don’t update said table; they trigger generating a new report.
Seriously dated code: 12 years old. Rails v3-isms. Blocks access without appropriate role; role name buried in secrets configuration files. Code passes data round-trip between server/client/server/model that isn’t ever used. Has two identical reports with slightly different names, used interchangeably. Uh, I guess I’ll update both?
Reports: Heavily, heavily abstracted; zero visibility.
Shiny new feature: Some new magical abstraction layer with no documentation nor comments. Nobody in my team knows how it works. The author… won’t explain, but sent me her .ppt presentation on it (the .ppt, not a recording).
Useless specs for seriously dated code: Tests exclusively factory-generated data; not the controller, filters/lookups, UI, table data, etc.
Seriously dated code and useless spec author: the CISO.
The worst part: I’m not even surprised at any of this.2 -
Not as much of a rant as a share of my exasperation you might breathe a bit more heavily out your nose at.
My work has dealt out new laptops to devs. Such shiny, very wow. They're also famously easy to use.
.
.
.
My arse.
.
.
.
I got the laptop, transferred the necessary files and settings over, then got to work. Delivered ticket i, delivered ticket j, delivered the tests (tests first *cough*) then delivered Mr Bullet to Mr Foot.
Day 4 of using the temporary passwords support gave me I thought it was time to get with department policy and change my myriad passwords to a single one. Maybe it's not as secure but oh hell, would having a single sign-on have saved me from this.
I went for my new machine's password first because why not? It's the one I'll use the most, and I definitely won't forget it. I didn't. (I didn't.) I plopped in my memorable password, including special characters, caps, and numbers, again (carefully typed) in the second password field, then nearly confirmed. Curiosity, you bastard.
There's a key icon by the password field and I still had milk teeth left to chew any and all new features with.
Naturally I click on it. I'm greeted by a window showing me a password generating tool. So many features, options for choosing length, character types, and tons of others but thinking back on it, I only remember those two. I had a cheeky peek at the different passwords generated by it, including playing with the length slider. My curiosity sated, I closed that window and confirmed that my password was in.
You probably know where this is going. I say probably to give room for those of you like me who certifiably. did. not.
Time to test my new password.
*Smacks the power button to log off*
Time to put it in (ooer)
*Smacks in the password*
I N C O R R E C T L O G I N D E T A I L S.
Whoops, typo probably.
Do it again.
I N C O R R E C T L O G I N D E T A I L S.
No u.
Try again.
I N C O R R E C T L O G I N D E T A I L S.
Try my previous password.
Well, SUCCESS... but actually, no.
Tried the previous previous password.
T O O M A N Y A T T E M P T S
Ahh fuck, I can't believe I've done this, but going to support is for pussies. I'll put this by the rest of the fire, I can work on my old laptop.
Day starts getting late, gotta go swimming soonish. Should probably solve the problem. Cue a whole 40 minutes trying my 15 or so different passwords and their permutations because oh heck I hope it's one of them.
I talk to a colleague because by now the "days since last incident" counter has been reset.
"Hello there Ryan, would you kindly go on a voyage with me that I may retrace my steps and perhaps discover the source of this mystery?"
"A man chooses, a slave obeys. I choose... lmao ye sure m8, but I'm driving"
We went straight for the password generator, then the length slider, because who doesn't love sliding a slidey boi. Soon as we moved it my upside down frown turned back around. Down in the 'new password' and the 'confirm new password' IT WAS FUCKING AUTOCOMPLETING. The slidey boi was changing the number of asterisks in both bars as we moved it. Mystery solved, password generator arrested, shit's still fucked.
Bite the bullet, call support.
"Hi, I need my password resetting. I dun goofed"
*details tech support needs*
*It can be sorted but the tech is ages away*
Gotta be punctual for swimming, got two whole lengths to do and a sauna to sit in.
"I'm off soon, can it happen tomorrow?"
"Yeah no problem someone will be down in the morning."
Next day. Friday. 3 hours later, still no contact. Go to support room myself.
The guy really tries, goes through everything he can, gets informed that he needs a code from Derek. Where's Derek? Ah shet. He's on holiday.
There goes my weekend (looong weekend, bank holiday plus day flexi-time) where I could have shown off to my girlfriend the quality at which this laptop can play all our favourite animé, and probably get remind by her that my personal laptop has an i2350u with integrated graphics.
TODAY. (Part is unrelated, but still, ugh.)
Go to work. Ten minutes away realise I forgot my door pass.
Bollocks.
Go get a temporary pass (of shame).
Go to clock in. My fob was with my REAL pass.
What the wank.
Get to my desk, nobody notices my shame. I'm thirsty. I'll have the bottle from my drawer. But wait, what's this? No key that usually lives with my pass? Can't even unlock it?
No thanks.
Support might be able to cheer me up. Support is now for manly men too.
*Knock knock*
"Me again"
"Yeah give it here, I've got the code"
He fixes it, I reset my pass, sensibly change my other passwords.
Or I would, if the internet would work.
It connects, but no traffic? Ryan from earlier helps, we solve it after a while.
My passwords are now sorted, machine is okay, crisis resolved.
*THE END*
If you skipped the whole thing and were expecting a tl;dr, you just lost the game.
Otherwise, I absolve you of having lost the game.
Exactly at the char limit9 -
Still on the primenumbers bender.
Had this idea that if there were subtle correlations between a sufficiently large set of identities and the digits of a prime number, the best way to find it would be to automate the search.
And thats just what I did.
I started with trace matrices.
I actually didn't expect much of it. I was hoping I'd at least get lucky with a few chance coincidences.
My first tests failed miserably. Eight percent here, 10% there. "I might as well just pick a number out of a hat!" I thought.
I scaled it way back and asked if it was possible to predict *just* the first digit of either of the prime factors.
That also failed. Prediction rates were low still. Like 0.08-0.15.
So I automated *that*.
After a couple days of on-and-off again semi-automated searching I stumbled on it.
[1144, 827, 326, 1184, -1, -1, -1, -1]
That little sequence is a series of identities representing different values derived from a randomly generated product.
Each slots into a trace matrice. The results of which predict the first digit of one of our factors, with a 83.2% accuracy even after 10k runs, and rising higher with the number of trials.
It's not much, but I was kind of proud of it.
I'm pushing for finding 90%+ now.
Some improvements include using a different sort of operation to generate results. Or logging all results and finding the digit within each result thats *most* likely to predict our targets, across all results. (right now I just take the digit in the ones column, which works but is an arbitrary decision on my part).
Theres also the fact that it's trivial to correctly guess the digit 25% of the time, simply by guessing 1, 3, 7, or 9, because all primes, except for 2, end in one of these four.
I have also yet to find a trace with a specific bias for predicting either the smaller of two unique factors *or* the larger. But I haven't really looked for one either.
I still need to write a generate that takes specific traces, and lets me mutate some of the values, to push them towards certain 'fitness' levels.
This would be useful not just for very high predictions, but to find traces with very *low* predictions.
Why? Because it would actually allow for the *elimination* of possible digits, much like sudoku, from a given place value in a predicted factor.
I don't know if any of this will even end up working past the first digit. But splitting the odds, between the two unique factors of a prime product, and getting 40+% chance of guessing correctly, isn't too bad I think for a total amateur.
Far cry from a couple years ago claiming I broke prime factorization. People still haven't forgiven me for that, lol.6 -
In the 90s most people had touched grass, but few touched a computer.
In the 2090s most people will have touched a computer, but not grass.
But at least we'll have fully sentient dildos armed with laser guns to mildly stimulate our mandatory attached cyber-clits, or alternatively annihilate thought criminals.
In other news my prime generator has exhaustively been checked against, all primes from 5 to 1 million. I used miller-rabin with k=40 to confirm the results.
The set the generator creates is the join of the quasi-lucas carmichael numbers, the carmichael numbers, and the primes. So after I generated a number I just had to treat those numbers as 'pollutants' and filter them out, which was dead simple.
Whats left after filtering, is strictly the primes.
I also tested it randomly on 50-55 bit primes, and it always returned true, but that range hasn't been fully tested so far because it takes 9-12 seconds per number at that point.
I was expecting maybe a few failures by my generator. So what I did was I wrote a function, genMillerTest(), and all it does is take some number n, returns the next prime after it (using my functions nextPrime() and isPrime()), and then tests it against miller-rabin. If miller returns false, then I add the result to a list. And then I check *those* results by hand (because miller can occasionally return false positives, though I'm not familiar enough with the math to know how often).
Well, imagine my surprise when I had zero false positives.
Which means either my code is generating the same exact set as miller (under some very large value of n), or the chance of miller (at k=40 tests) returning a false positive is vanishingly small.
My next steps should be to parallelize the checking process, and set up my other desktop to run those tests continuously.
Concurrently I should work on figuring out why my slowest primality tests (theres six of them, though I think I can eliminate two) are so slow and if I can better estimate or derive a pattern that allows faster results by better initialization of the variables used by these tests.
I already wrote some cases to output which tests most frequently succeeded (if any of them pass, then the number isn't prime), and therefore could cut short the primality test of a number. I rewrote the function to put those tests in order from most likely to least likely.
I'm also thinking that there may be some clues for faster computation in other bases, or perhaps in binary, or inspecting the patterns of values in the natural logs of non-primes versus primes. Or even looking into the *execution* time of numbers that successfully pass as prime versus ones that don't. Theres a bevy of possible approaches.
The entire process for the first 1_000_000 numbers, ran 1621.28 seconds, or just shy of a tenth of a second per test but I'm sure thats biased toward the head of the list.
If theres any other approach or ideas I may be overlooking, I wouldn't know where to begin.16 -
You know how LLMs always imitate expertise and understanding? That isn't specific to English, it happens in code as well. It's harder for them to get away with it because even the best guess isn't likely to be approximately correct, but they still try and it still sometimes works.
One of cucumber scenario tests now contains a deadlock somehow. We run them one at a time. I need some rakia.6 -
Ugh... some people...
Just left the office early because of the toxic climate. That one infamous collegue is basically unable to communicate without being a narcissistic 5-year-old and was arguing whether we should write a test (I was going to write the test) that would need a single additional branch in the build system.
(The test was for a parser and it should test whether it can handle absolute paths. A simple regression test with a file and an expected output. Because absolute paths are different for every platform and user, the files to be parsed would have to be generated with appropriate paths before the tests were run. Well that would require one single python script and a single line in the script that runs the script and DONE)
Well that guy was unable to focus on his own work and started an argument about whether that test was necessary.
Even though I still think it is necessary, it might have been a reasonable argument if he would have acted more agreeable. But he was saying the feature was useless anyways "everyone will use relative paths only anyways" and "because noone here cares a ratass about maintaining the tests it will all fall on me again" ..
Wtf was this guys problem, I (CAPS) was going to write the stupid test and since when do we not write tests in order to better maintain our product? I get that he worries that the test environment will get more messy, but thats better than having the product code go messy or unfunctional! And c'mon guys, how are absolute paths a redundant feature... -
personal projects, of course, but let's count the only one that could actually be considered finished and released.
which was a local social network site. i was making and running it for about three years as a replacement for a site that its original admin took down without warning because he got fed up with the community. i loved the community and missed it, so that was my motivation to learn web stack (html, css, php, mysql, js).
first version was done and up in a week, single flat php file, no oop, just ifs. was about 5k lines long and was missing 90% of features, but i got it out and by word of mouth/mail is started gathering the community back.
right as i put it up, i learned about include directive, so i started re-coding it from scratch, and "this time properly", separated into one file per page.
that took about a month, got to about 10k lines of code, with about 30% of planned functionality.
i put it up, and then i learned that php can do objects, so i started another rewrite from scratch. two or three months later, about 15k lines of code, and 60% of the intended functionality.
i put it up, and learned about ajax (which was a pretty new thing since this was 2006), so i started another rewrite, this time not completely from scratch i think.
three months later, final length about 30k lines of code, and 120% of originally intended functionality (since i got some new features ideas along the way).
put it up, was very happy with it, and since i gathered quite a lot of user-generated data already through all of that time, i started seeing patterns, and started to think about some crazy stuff like auto-tagging posts based on their content (tags like positive, negative, angry, sad, family issues, health issues, etc), rewarding users based on auto-detection whether their comments stirred more (and good) discussion, or stifled it, tracking user's mental health and life situation (scale of great to horrible, something like that) based on the analysis of the texts of their posts...
... never got around to that though, missed two months hosting payments and in that time the admin of the original site put it back up, so i just told people to move back there.
awesome experience, though. worth every second.
to this day probably the project i'm most proud of (which is sad, i suppose) - the final version had its own builtin forum section with proper topics, reply threads, wysiwyg post editor, personal diaries where people could set per-post visibility (everyone, only logged in users, only my friends), mental health questionnaires that tracked user's results in time and showed them in a cool flash charts, questionnaire editor where users could make their own tests/quizzes, article section, like/dislike voting on everything, page-global ajax chat of all users that would stay open in bottom right corner, hangouts-style, private messages, even a "pointer" system where sending special commands to the chat aimed at a specific user would cause page elements to highlight on their client, meaning if someone asked "how do i do this thing on the page?", i could send that command and the button to the subpage would get highlighted, after they clicked it and the subpage loaded, the next step in the process would get highlighted, with a custom explanation text, etc...
dammit, now i got seriously nostalgic. it was an awesome piece of work, if i may say so. and i wasn't the only one thinking that, since showing the page off landed me my first two or three programming jobs, right out of highschool. 10 minutes of smalltalk, then they asked about my knowledge, i whipped up that site and gave a short walkthrough talking a bit about how the most interesting pieces were implemented, done, hired XD
those were good times, when I still felt like the programmer whiz kid =D
as i said, worth every second, every drop of sweat, every torn hair, several times over, even though "actual net financial profit" was around minus two hundred euro paid for those two or three years of hosting. -
Let me create the Drupal train.
Fuck Drupal, its verbose shit, how it's supposed to inherit from Symfony, how it's not (at all), how it needs to create a WHOLE FUCKING TABLE FOR EVERY SINGLE TEXT INPUT, how it's required to write TWO LONG ASS PHP lines of code to display ONE FUCKING IMAGE.
Fuck these millions of hooks that allows you to do "incredible stuff" that you could normally do without Drupal.
Fuck how templates are generated, you wouldn't believe how bad it is, and how web integrators are loosing their mind to try to correctly display datas that are contained
Finally, the people who wants some "modern stuff" and make the tests even harder to write and the site uglier.
I just can't believe that recruiters still want to hire people for some Drupal shit.2 -
* Gets handed additions to current software platform (web)
* Gives back estimte of time after meeting with everyone and making them understand that once the testing phase of the project is reached there will be no changes, tests should be exhaustive and focus on SAID FUNCTIONALITY of the new additions. NO CHANGES OR ADDITIONS AT THIS POINT IN TIME
* All directives, stakeholders, users etc agreed on my request and spend an additional hour thinking of different corner and edge cases as provided by me in case they can't think of them (they can't, because they are fucking stupid, but I provided everything)
* Boss looks irritated at their lack of understanding of the scope and the time needed, nods in approval after he sees my entire specification, testing cases, possible additions to the system etc
* All members of the committee decide on the requirements being correct, concrete and proper.
* Finish the additions in a couple of weeks due to the increased demand for other projects, this directly affects the user base, so my VP and Director make it a top priority, I agree with their sentiment, since my Director knows what he is doing (real OG)
* I make the changes, test inside of my department and then stage for the testing environment. Everything is ready, all migrations are in order, the functionality is working as proper and the pipeline for the project, albeit somewhat lacking in elegance is good to go.
* Testing days arrive
* First couple of hours of test: Oh, you know what, we should add these two additional fields, and it would be good if the reporting generated by the system would contain this OTHER FORMAT rather than this one.
* ME: We stated that no additions would be done during the testing environment, testing is for functionality, not to see if you can all think of something else, even then, on June 10 I provided a initial demo and no one bothered to check on it on say something.
Them: Well, we are doing it now, this is what testing is for.
Me: Out of this room, the software engineer is me, and I can assure you, testing is not for that. I repeatedly stated that previously, I set the requirements, added corner cases, tables charts everything and not one single one of you decided to pay attention or add something, actually, said functionality you are requesting was part of one of my detailed list of corner cases, why did you not add it there and then before everything went up?
Them: Well I didn't read it at the time (think of the I in plural form since all of these dumb fucks stated the same)
Then my boss went on a rampage on their dumbasses.
I fucking hate software development sometimes.
Oh well. Bunch of fucking retards.2 -
So the saga of broken fucking everything continues at work, and I'm managing it, effectively, and doing it correctly on the first go-round. It's a long process though, because the two retards who preceded me were equally inept for completely different, yet equally disruptive and destructive reasons. The first dude was just plain psychotic, probably still is. I'd post some of his code, but I don't want anyone's face to melt off like those Nazi dudes at the end of Raiders of the Lost Ark. I can handle it because I'm constantly inebriated, which is not as fun as it sounds. If you have to ask yourself if you can handle it, you probably aren't, unless you've had to Uber to/from work due to still being fucking drunk. Anyway, enough about that, and it was only like twice. The rest of the times, I was more blazed than Jerry Garcia at a weed smoking contest. Moving along.
UPS shipping labels broke two weeks ago, I fixed it, but these fucking 10xers jointly decided to not only never implement anything resembling error handling, other than EMPTY GOD DAMN "try/catch"es (empty catch, wow so efficient), and instead of using COMMENTS, which I know are a new thing, they'd wrap blocks of code in something like: if 1 = 0 {} FUCK YOU DICKFACES. As I was saying before I got emotional again, they tied the success to all kinds of unrelated, irrelevant shit. I'm literally needle/haystacking my way through the entire 200GB codebase, ALONE, trying to find all the borked things. Helpfully, my phone is ringing all the time from customer service, complaining about things that are either nothing to do with the site, or due to user stupidity, 75% of the time.
A certain department at my company relies on some pretty specific documents to do their job, and these documents are/were generated from data in the database. So until I can find and fix all of the things, I've diverted my own attention as much as possible to the rapid implementation of a report generation microservice so that no one elses work is further disrupted while I continue my cursed easter egg hunt from fucking hell.
After a little more than two days, I'm about to lauch a standalone MS to handle the reports, and it's unfortunately more complicated than I'd like, because it requires a certain library that isn't available on Winblows, so I've dockerized the application. Anyway, just after lunch, I've finished my final round of tests, and I'm about ready to begin migrating it to the server and setting up (shitty fucking shit) IIS to serve it appropriately. At this point, this particular report has been unavailable by web for about 8 days.
A little after lunch, and with no forewarning of any kind, the manager of managers runs upstairs and screams at me to "work faster" and that "this needs to be back online RIGHT NOW", but I also know that this individual is going to throw a fit if things on this pdf aren't a pixel perfect match. So I just say "that's some amazing advice, I wish I'd had the foresight to just do it better and work faster". Silence for a good five seconds, then I follow up with "please leave and let me get back to my work". At that moment from around the corner, my "supervisor" suddenly, magically even, remembers that he has had the ability to print this crucial, amazingly super fucking important document all along, despite me directly asking him a week ago, and he prints it and takes it where it needs to go. In the time that it takes him to go to that other department and return, I deploy my service.
I spent the rest of the day browsing indeed and linkedin jobs, but damn this market is kinda weird right now, yeah?2 -
We have an unit test that tests the average of a sequence of numbers generated randomly using a gaussian distribution. Of course it fails from time to time, it's random! Failing to fail, would mean that the generator is not generating random numbers, therefore failure means success, but success does not mean failure.
Wait, why did we add this test in the first place? -
Xcode UI test recording is fucking abysmal. For a simple tutorial "todo" app that I wanted to add a test to, it generated a completely imaginary toolbar selector, a syntactically incomplete eight-line garbage monstrosity instead a button selector, and entirely missed off the last action.
Don't get me wrong, I really like that there is a way to automate UI tests, but the promise of test recording is massive fucking lie.1 -
New version, new regression tests. It's the first time I'm trying to run them fully automated. Tests were ok separately, but as it turns out, "random" generated number is not OK for creating unique names if it's being created from datetime (yymmddmmss), and tests run within one minute.
Also, new version broke our hack of disabling browser pop-up confirmations. Fuck.

















Top Tags
Weekly Rant
View