
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
The marketing department is right next door to my office, and to make room for their new intern, a very high end, large, and noisy printer was 'temporarily' placed in my office. I'm a reasonable person though, and didn't mind this. The salespeople figured out that it makes commercial grade printouts, so for their various presentations and whatnot, they'll print enormous numbers of pages on this thing, and basically use my office as a motherfucking water-cooler. After a few weeks of this, I logged into the printer from my computer, and set it to disallow all connections from MAC addresses other than those in the marketing department, who print far less material on their own, special, dedicated printer. Absolute fucking chaos ensued. Grown men were brought to tears, ultimatums were made, and blood was shed. The hardware guys were down here for over an hour, making up absolute bullshit as to why it wasn't working(which really surprised me).
Long story short, cut off access to printer, sit back and watch the true face of humanity emerge. Seriously, fuck those guys. They have their own goddamn printer.7 -
To become an engineer (CS/IT) in India, you have to study:
1. 3 papers in Physics (2 mechanics, 1 optics)
2. 1 paper in Chemistry
3. 2 papers in English (1 grammar, 1 professional communication). Sometimes 3 papers will be there.
4. 6 papers in Mathematics (sequences, series, linear algebra, complex numbers and related stuff, vectors and 3D geometry, differential calculus, integral calculus, maxima/minima, differential equations, descrete mathematics)
5. 1 paper in Economics
6. 1 paper in Business Management
7. 1 paper in Engineering Drawing (drawing random nuts and bolts, locus of point etc)
8. 1 paper in Electronics
9. 1 paper in Mechanical Workshop (sheet metal, wooden work, moulding, metal casting, fitting, lathe machine, milling machine, various drills)
And when you jump in real life scenario, you encounter source/revision/version control, profilers, build server, automated build toolchains, scripts, refactoring, debugging, optimizations etc. As a matter of fact none of these are touched in the course.
Sure, they teach you a large set of algorithms, but they don't tell you when to prefer insertion sort over quick sort, quick sort over merge sort etc. They teach you Las Vegas and Monte Carlo algorithms, but they don't tell you that the randomizer in question should pass Die Hard test (and then you wonder why algorithm is not working as expected). They teach compiler theory, but you cannot write a simple parser after passing the course. They taught you multicore architecture and multicore programming, but you don't know how to detect and fix a race condition. You passed entire engineering course with flying colors, and yet you don't know ABC of debugging (I wish you encounter some notorious heisenbug really soon). They taught 2-3 programming languages, and yet you cannot explain simple variable declaration.
And then, they say that you should have knowledge of multiple fields. Oh well! you don't have any damn idea about your major, and now you are talking about knowledge in multiple fields?
What is the point of such education?
PS: I am tired of interviewing shitty candidates with flying colours in their marksheets. Go kids, learn some real stuff first, and then talk some random bullshit.18 -
I'm 20, and I consider myself to be as junior as they come. I only started programming seriously in June 2016,and since then, I've been doing mainly Android Work, and making my own servers and backends(using AWS/Firebase nd stuff).
For the first time in life, I was approached by a recruiter for a company on linkedIn. They "stumbled upon" my Github profile and wanted to see if I was interested in an internship opportunity. This company is an early stage start up, by that I mean a dude with an idea calling himself the CEO and a guy who "runs a tech blog" and only knows college level C programming (explaination follows).
So they want me to make the app for their startup. and for that, I ws first asked to solve a couple problems to prove my competence and a "technical interview" followed.
They gave me 3 questions, all textbook, GCD of 2 numbers, binary search and Adding an element to the linked List, code to be written on a piece of paper. As the position was that of an Android Developer, I assumed that Java should be the language of choice. Assumed because when I asked, the 'tech blogger' said, yeah whatever.
But wait, that ain't all, as soon as I was done, Mr. Blogger threw a fit, saying I shouldn't assume and that I must write it in C. I kept my cool (I'm not the most patient person), and wrote the whole thing in C.
He read it, and asked me what I've written and then told me how wrong I was to write 2 extra lines instead of recursion for GCD. I explained that with numbers large enough, we run the risk of getting a stackoverflow and it's best to apply non recursive solution if possible. He just heard stackoverflow and accused me of cheating. I should have left right then, but I don't know why, I apologized and again, in detail explained what was happening to this fucktard. Once this was done, He asked me how, if I had to, I'd use this exact code in my Android App. I told him that Id rather write this in Java/Kotlin since those are the languages native to Android apps. I also said that I'd export these as a Library and use JNI for the task. (I don't actually know how, I figured I can study if I have to).
Here's his reply, "WTF! We don't want to make the app in Java, we will use C (Yeh, not C++, C). and Don't use these fancy TOOLS like JNI or Kotlin in front of me, make a proper application."
By this I was clear that this guy is not fit to be technical lead and that I should leave. I said, "Sir, I don't know how, if even possible, can we make an Android App purely in C. I am sorry, but this job is not for me".
I got up and was about to leave the room, when we said, "Yeah okay, I was just testing you".
Yeah right, the guy's face looked like a howling monkey when I said Library for C, and It has been easier for me to explain code to my 10 year old cousin that this dumbfuck.
He then proceeded to ask me about my availability, and I said that I can at max to 15-20 hours a week since my college schedule is pretty tight. I asked me to get him a prototype in 2 months and also offered me a full time job after I graduate. (That'd be 2 years from now). I said thank you for the offer, but I am still not sure of I am the right person for this job.
He then said, "Oh you will be when I tell you your monthly stipend."
I stopped for a second, because, money.
And then he proceeded to say 2 words which made me walk out without saying a single word.
"One Thousand".
I live in India, 1000 INR translates to roughly $15. I made 25 times that by doing nothing more than add a web view to an activity and render a company's responsive website in it so it looks like an app.
If this wasn't enough, the recruiter later had the audacity to blame me for it and tell me how lucky I am to even get an offer "so good".
Fuck inexperienced assholes trying shit they don't understand and thinking that the other guy is shitsworth.10 -
This codebase reminds me of a large, rotting, barely-alive dromedary. Parts of it function quite well, but large swaths of it are necrotic, foul-smelling, and even rotted away. Were it healthy, it would still exude a terrible stench, and its temperament would easily match: If you managed to get near enough, it would spit and try to bite you.
Swaths of code are commented out -- entire classes simply don't exist anymore, and the ghosts of several-year-old methods still linger. Despite this, large and deprecated (yet uncommented) sections of the application depend on those undefined classes/methods. Navigating the codebase is akin to walking through a minefield: if you reference the wrong method on the wrong object... fatal exception. And being very new to this project, I have no idea what's live and what isn't.
The naming scheme doesn't help, either: it's impossible to know what's still functional without asking because nothing's marked. Instead, I've been working backwards from multiple points to try to find code paths between objects/events. I'm rarely successful.
Not only can I not tell what's live code and what's interactive death, the code itself is messy and awful. Don't get me wrong: it's solid. There's virtually no way to break it. But trying to understand it ... I feel like I'm looking at a huge, sprawling MC Escher landscape through a microscope. (No exaggeration: a magnifying glass would show a larger view that included paradoxes / dubious structures, and these are not readily apparent to me.)
It's also rife with bad practices. Terrible naming choices consisting of arbitrarily-placed acronyms, bad word choices, and simply inconsistent naming (hash vs hsh vs hs vs h). The indentation is a mix of spaces and tabs. There's magic numbers galore, and variable re-use -- not just local scope, but public methods on objects as well. I've also seen countless assignments within conditionals, and these are apparently intentional! The reasoning: to ensure the code only runs with non-falsey values. While that would indeed work, an early return/next is much clearer, and reduces indentation. It's just. reading through this makes me cringe or literally throw my hands up in frustration and exasperation.
Honestly though, I know why the code is so terrible, and I understand:
The architect/sole dev was new to coding -- I have 5-7 times his current experience -- and the project scope expanded significantly and extremely quickly, and also broke all of its foundation rules. Non-developers also dictated architecture, creating further mess. It's the stuff of nightmares. Looking at what he was able to accomplish, though, I'm impressed. Horrified at the details, but impressed with the whole.
This project is the epitome of "I wrote it quickly and just made it work."
Fortunately, he and I both agree that a rewrite is in order. but at 76k lines (without styling or configuration), it's quite the undertaking.
------
Amusing: after running the codebase through `wc`, it apparently sums to half the word count of "War and Peace"15 -
I know it's not too impressive, but got this working using my Windows console double-buffering system and literal bitmaps for the large numbers.
I have posted about both previously if you want more details :3 11
11 -
Yesterday the web site started logging an exception “A task was canceled” when making a http call using the .Net HTTPClient class (site calling a REST service).
Emails back n’ forth ..blaming the database…blaming the network..then a senior web developer blamed the logging (the system I’m responsible for).
Under the hood, the logger is sending the exception data to another REST service (which sends emails, generates reports etc.) which I had to quickly re-direct the discussion because if we’re seeing the exception email, the logging didn’t cause the exception, it’s just reporting it. Felt a little sad having to explain it to other IT professionals, but everyone seemed to agree and focused on the server resources.
Last night I get a call about the exceptions occurring again in much larger numbers (from 100 to over 5,000 within a few minutes). I log in, add myself to the large skype group chat going on just to catch the same senior web developer say …
“Here is the APM data that shows logging is causing the http tasks to get canceled.”
FRACK!
Me: “No, that data just shows the logging http traffic of the exception. The exception is occurring before any logging is executed. The task is either being canceled due to a network time out or IIS is running out of threads. The web site is failing to execute the http call to the REST service.”
Several other devs, DBAs, and network admins agree.
The errors only lasted a couple of minutes (exactly 2 minutes, which seemed odd), so everyone agrees to dig into the data further in the morning.
This morning I login to my computer to discover the error(s) occurred again at 6:20AM and an email from the senior web developer saying we (my mgr, her mgr, network admins, DBAs, etc) need to discuss changes to the logging system to prevent this problem from negatively affecting the customer experience...blah blah blah.
FRACKing female dog!
Good news is we never had the meeting. When the senior web dev manager came in, he cancelled the meeting.
Turned out to be a hiccup in a domain controller causing the servers to lose their connection to each other for 2 minutes (1-minute timeout, 1 minute to fully re-sync). The exact two-minute burst of errors explained (and proven via wireshark).
People and their petty office politics piss me off.2 -
POSTMORTEM
"4096 bit ~ 96 hours is what he said.
IDK why, but when he took the challenge, he posted that it'd take 36 hours"
As @cbsa wrote, and nitwhiz wrote "but the statement was that op's i3 did it in 11 hours. So there must be a result already, which can be verified?"
I added time because I was in the middle of a port involving ArbFloat so I could get arbitrary precision. I had a crude desmos graph doing projections on what I'd already factored in order to get an idea of how long it'd take to do larger
bit lengths
@p100sch speculated on the walked back time, and overstating the rig capabilities. Instead I spent a lot of time trying to get it 'just-so'.
Worse, because I had to resort to "Decimal" in python (and am currently experimenting with the same in Julia), both of which are immutable types, the GC was taking > 25% of the cpu time.
Performancewise, the numbers I cited in the actual thread, as of this time:
largest product factored was 32bit, 1855526741 * 2163967087, took 1116.111s in python.
Julia build used a slightly different method, & managed to factor a 27 bit number, 103147223 * 88789957 in 20.9s,
but this wasn't typical.
What surprised me was the variability. One bit length could take 100s or a couple thousand seconds even, and a product that was 1-2 bits longer could return a result in under a minute, sometimes in seconds.
This started cropping up, ironically, right after I posted the thread, whats a man to do?
So I started trying a bunch of things, some of which worked. Shameless as I am, I accepted the challenge. Things weren't perfect but it was going well enough. At that point I hadn't slept in 30~ hours so when I thought I had it I let it run and went to bed. 5 AM comes, I check the program. Still calculating, and way overshot. Fuuuuuuccc...
So here we are now and it's say to safe the worlds not gonna burn if I explain it seeing as it doesn't work, or at least only some of the time.
Others people, much smarter than me, mentioned it may be a means of finding more secure pairs, and maybe so, I'm not familiar enough to know.
For everyone that followed, commented, those who contributed, even the doubters who kept a sanity check on this without whom this would have been an even bigger embarassement, and the people with their pins and tactical dots, thanks.
So here it is.
A few assumptions first.
Assuming p = the product,
a = some prime,
b = another prime,
and r = a/b (where a is smaller than b)
w = 1/sqrt(p)
(also experimented with w = 1/sqrt(p)*2 but I kept overshooting my a very small margin)
x = a/p
y = b/p
1. for every two numbers, there is a ratio (r) that you can search for among the decimals, starting at 1.0, counting down. You can use this to find the original factors e.x. p*r=n, p/n=m (assuming the product has only two factors), instead of having to do a sieve.
2. You don't need the first number you find to be the precise value of a factor (we're doing floating point math), a large subset of decimal values for the value of a or b will naturally 'fall' into the value of a (or b) + some fractional number, which is lost. Some of you will object, "But if thats wrong, your result will be wrong!" but hear me out.
3. You round for the first factor 'found', and from there, you take the result and do p/a to get b. If 'a' is actually a factor of p, then mod(b, 1) == 0, and then naturally, a*b SHOULD equal p.
If not, you throw out both numbers, rinse and repeat.
Now I knew this this could be faster. Realized the finer the representation, the less important the fractional digits further right in the number were, it was just a matter of how much precision I could AFFORD to lose and still get an accurate result for r*p=a.
Fast forward, lot of experimentation, was hitting a lot of worst case time complexities, where the most significant digits had a bunch of zeroes in front of them so starting at 1.0 was a no go in many situations. Started looking and realized
I didn't NEED the ratio of a/b, I just needed the ratio of a to p.
Intuitively it made sense, but starting at 1.0 was blowing up the calculation time, and this made it so much worse.
I realized if I could start at r=1/sqrt(p) instead, and that because of certain properties, the fractional result of this, r, would ALWAYS be 1. close to one of the factors fractional value of n/p, and 2. it looked like it was guaranteed that r=1/sqrt(p) would ALWAYS be less than at least one of the primes, putting a bound on worst case.
The final result in executable pseudo code (python lol) looks something like the above variables plus
while w >= 0.0:
if (p / round(w*p)) % 1 == 0:
x = round(w*p)
y = p / round(w*p)
if x*y == p:
print("factors found!")
print(x)
print(y)
break
w = w + i
Still working but if anyone sees obvious problems I'd LOVE to hear about it.36 -
Our web department was deploying a fairly large sales campaign (equivalent to a ‘Black Friday’ for us), and the day before, at 4:00PM, one of the devs emails us and asks “Hey, just a heads up, the main sales page takes almost 30 seconds to load. Any chance you could find out why? Thanks!”
We click the URL they sent, and sure enough, 30 seconds on the dot.
Our department manager almost fell out of his chair (a few ‘F’ bombs were thrown).
DBAs sit next door, so he shouts…
Mgr: ”Hey, did you know the new sales page is taking 30 seconds to open!?”
DBA: “Yea, but it’s not the database. Are you just now hearing about this? They have had performance problems for over week now. Our traces show it’s something on their end.”
Mgr: “-bleep- no!”
Mgr tries to get a hold of anyone …no one is answering the phone..so he leaves to find someone…anyone with authority.
4:15 he comes back..
Mgr: “-beep- All the web managers were in a meeting. I had to interrupt and ask if they knew about the performance problem.”
Me: “Oh crap. I assume they didn’t know or they wouldn’t be in a meeting.”
Mgr: “-bleep- no! No one knew. Apparently the only ones who knew were the 3 developers and the DBA!”
Me: “Uh…what exactly do they want us to do?”
Mgr: “The –bleep- if I know!”
Me: “Are there any load tests we could use for the staging servers? Maybe it’s only the developer servers.”
DBA: “No, just those 3 developers testing. They could reproduce the slowness on staging, so no need for the load tests.”
Mgr: “Oh my –bleep-ing God!”
4:30 ..one of the vice presidents comes into our area…
VP: “So, do we know what the problem is? John tells me you guys are fixing the problem.”
Mgr: “No, we just heard about the problem half hour ago. DBAs said the database side is fine and the traces look like the bottleneck is on web side of things.”
VP: “Hmm, no, John said the problem is the caching. Aren’t you responsible for that?”
Mgr: “Uh…um…yea, but I don’t think anyone knows what the problem is yet.”
VP: “Well, get the caching problem fixed as soon as possible. Our sales numbers this year hinge on the deployment tomorrow.”
- VP leaves -
Me: “I looked at the cache, it’s fine. Their traffic is barely a blip. How much do you want to bet they have a bug or a mistyped url in their javascript? A consistent 30 second load time is suspiciously indicative of a timeout somewhere.”
Mgr: “I was thinking the same thing. I’ll have networking run a trace.”
4:45 Networking run their trace, and sure enough, there was some relative path of ‘something’ pointing to a local resource not on development, it was waiting/timing out after 30 seconds. Fixed the path and page loaded instantaneously. Network admin walks over..
NetworkAdmin: “We had no idea they were having problems. If they told us last week, we could have identified the issue. Did anyone else think 30 second load time was a bit suspicious?”
4:50 VP walks in (“John” is the web team manager)..
VP: “John said the caching issue is fixed. Great job everyone.”
Mgr: “It wasn’t the caching, it was a mistyped resource or something in a javascript file.”
VP: “But the caching is fixed? Right? John said it was caching. Anyway, great job everyone. We’re going to have a great day tomorrow!”
VP leaves
NetworkAdmin: “Ouch…you feel that?”
Me: “Feel what?”
NetworkAdmin: “That bus John just threw us under.”
Mgr: “Yea, but I think John just saved 3 jobs. Remember that.”4 -
Large comment block at the top of the file, commenting explicit line numbers, as in: "line 365: copy to a new image".
Only everytime the comment block grew, the line numbers got more and more off. -_-4 -
Ok, so when I inherit a Wordpress site I've really stopped expecting anything sane. Examples: evidence that the Wordpress "developer" (that term is used in the loosest sense possible) has thought about his/her code or even evidence that they're not complete idiots who wish to make my life hell going forwards.
Have a look at the screen shot below - this is from the theme footer, so loaded on every page. The screenshot only shows a small part of the file. IT LITERALLY HAS 3696 lines.
Firstly, lets excuse the frankly eye watering if statement to check for the post ID. That made me face palm myself immediately.
The insanity comes for the thousands of lines of JQuery code, duplicated to hell and back that changes the color of various dividers - that are scattered throughout the site.
To make things thousands of times worse, they are ALL HANDED CODED.
Even if JavaScript was the only way I could format these particular elements I certainly wouldn't duplicate the same code for every element. After copy and pasting that JQuery a couple of times and normal developer would think one word, pretty quickly - repetition.
When a good developer notes repetition ways to abstract crap away is the first thought that comes to mind.
Hell, when I was first learning to code god knows how long ago I always used functions to avoid repetition.
In this case, with a few seconds though this "developer" could have created a single JQuery handler and use data attributes within the HTML. Hell, as bad as that is, it's better than the monstrosity I'm looking at now.
I'm aware Wordpress is associated with bad developers due to it's low barrier to entry, but this site is something else.
The scary thing is that I know the agency that produced this. They are very large, use Wordpress exclusively and have some stupidly huge clients that would be know nationally.
Wordpress truly does attract some of the most awful "developers" and deserves it's reputation.
If you're a good developer and use Wordpress I feel sorry for you, as you're in small numbers from my experience.
Rant over, have vented a bit and feel better. Thanks Devrant. 6
6 -
Teaching my homeschooled son about prime numbers, which of course means we need to also teach prime number determination in Python (his coding language of choice), when leads to a discussion of processing power, and a newly rented cloud server over at digital ocean, and a search of prime number search optimizations, questioning if python is the right language, more performance optimizations, crap, the metrics I added are slowing this down, so feature flags to toggle off the metrics, crap, I actually have a real job I need to get back to. Oooh, I'm up to prime numbers in two millions, and , oh, I really should run that ssh session in screen so it keeps running if I close my laptop. I could make this a service and let it run in the background. I bet there's a library for this. He's only 9. We've already talked about encryption and the need to find large prime numbers.2
-
Two big moments today:
1. Holy hell, how did I ever get on without a proper debugger? Was debugging some old code by eye (following along and keeping track mentally, of what the variables should be and what each step did). That didn't work because the code isn't intuitive. Tried the print() method, old reliable as it were. Kinda worked but didn't give me enough fine-grain control.
Bit the bullet and installed Wing IDE for python. And bam, it hit me. How did I ever live without step-through, and breakpoints before now?
2. Remember that non-sieve prime generator I wrote a while back? (well maybe some of you do). The one that generated quasi lucas carmichael (QLC) numbers? Well thats what I managed to debug. I figured out why it wasn't working. Last time I released it, I included two core methods, genprimes() and nextPrime(). The first generates a list of primes accurately, up to some n, and only needs a small handful of QLC numbers filtered out after the fact (because the set of primes generated and the set of QLC numbers overlap. Well I think they call it an embedding, as in QLC is included in the series generated by genprimes, but not the converse, but I digress).
nextPrime() was supposed to take any arbitrary n above zero, and accurately return the nearest prime number above the argument. But for some reason when it started, it would return 2,3,5,6...but genprimes() would work fine for some reason.
So genprimes loops over an index, i, and tests it for primality. It begins by entering the loop, and doing "result = gffi(i)".
This calls into something a function that runs four tests on the argument passed to it. I won't go into detail here about what those are because I don't even remember how I came up with them (I'll make a separate post when the code is fully fixed).
If the number fails any of these tests then gffi would just return the value of i that was passed to it, unaltered. Otherwise, if it did pass all of them, it would return i+1.
And once back in genPrimes() we would check if the variable 'result' was greater than the loop index. And if it was, then it was either prime (comparatively plentiful) or a QLC number (comparatively rare)--these two types and no others.
nextPrime() was only taking n, and didn't have this index to compare to, so the prior steps in genprimes were acting as a filter that nextPrime() didn't have, while internally gffi() was returning not only primes, and QLCs, but also plenty of composite numbers.
Now *why* that last step in genPrimes() was filtering out all the composites, idk.
But now that I understand whats going on I can fix it and hypothetically it should be possible to enter a positive n of any size, and without additional primality checks (such as is done with sieves, where you have to check off multiples of n), get the nearest prime numbers. Of course I'm not familiar enough with prime number generation to know if thats an achievement or worthwhile mentioning, so if anyone *is* familiar, and how something like that holds up compared to other linear generators (O(n)?), I'd be interested to hear about it.
I also am working on filtering out the intersection of the sets (QLC numbers), which I'm pretty sure I figured out how to incorporate into the prime generator itself.
I also think it may be possible to generator primes even faster, using the carmichael numbers or related set--or even derive a function that maps one set of upper-and-lower bounds around a semiprime, and map those same bounds to carmichael numbers that act as the upper and lower bound numbers on the factors of a semiprime.
Meanwhile I'm also looking into testing the prime generator on a larger set of numbers (to make sure it doesn't fail at large values of n) and so I'm looking for more computing power if anyone has it on hand, or is willing to test it at sufficiently large bit lengths (512, 1024, etc).
Lastly, the earlier work I posted (linked below), I realized could be applied with ECM to greatly reduce the smallest factor of a large number.
If ECM, being one of the best methods available, only handles 50-60 digit numbers, & your factors are 70+ digits, then being able to transform your semiprime product into another product tree thats non-semiprime, with factors that ARE in range of ECM, and which *does* contain either of the original factors, means products that *were not* formally factorable by ECM, *could* be now.
That wouldn't have been possible though withput enormous help from many others such as hitko who took the time to explain the solution was a form of modular exponentiation, Fast-Nop who contributed on other threads, Voxera who did as well, and support from Scor in particular, and many others.
Thank you all. And more to come.
Links mentioned (because DR wouldn't accept them as they were):
https://pastebin.com/MWechZj912 -
As you can see from the screenshot, its working.
The system is actually learning the associations between the digit sequence of semiprime hidden variables and known variables.
Training loss and value loss are super high at the moment and I'm using an absurdly small training set (10k sequence pairs). I'm running on the assumption that there is a very strong correlation between the structures (and that it isn't just all ephemeral).
This initial run is just to see if training an machine learning model is a viable approach.
Won't know for a while. Training loss could get very low (thats a good thing, indicating actual learning), only for it to spike later on, and if it does, I won't know if the sample size is too small, or if I need to do more training, or if the problem is actually intractable.
If or when that happens I'll experiment with different configurations like batch sizes, and more epochs, as well as upping the training set incrementally.
Either case, once the initial model is trained, I need to test it on samples never seen before (products I want to factor) and see if it generates some or all of the digits needed for rapid factorization.
Even partial digits would be a success here.
And I expect to create multiple training sets for each semiprime product and its unknown internal variables versus deriable known variables. The intersections of the sets, and what digits they have in common might be the best shot available for factorizing very large numbers in this approach.
Regardless, once I see that the model works at the small scale, the next step will be to increase the scope of the training data, and begin building out the distributed training platform so I can cut down the training time on a larger model.
I also want to train on random products of very large primes, just for variety and see what happens with that. But everything appears to be working. Working way better than I expected.
The model is running and learning to factorize primes from the set of identities I've been exploring for the last three fucking years.
Feels like things are paying off finally.
Will post updates specifically to this rant as they come. Probably once a day. 2
2 -
I didn't leave, I just got busy working 60 hour weeks in between studying.
I found a new method called matrix decomposition (not the known method of the same name).
Premise is that you break a semiprime down into its component numbers and magnitudes, lets say 697 for example. It becomes 600, 90, and 7.
Then you break each of those down into their prime factorizations (with exponents).
So you get something like
>>> decon(697)
offset: 3, exp: [[Decimal('2'), Decimal('3')], [Decimal('3'), Decimal('1')], [Decimal('5'), Decimal('2')]]
offset: 2, exp: [[Decimal('2'), Decimal('1')], [Decimal('3'), Decimal('2')], [Decimal('5'), Decimal('1')]]
offset: 1, exp: [[Decimal('7'), Decimal('1')]]
And it turns out that in larger numbers there are distinct patterns that act as maps at each offset (or magnitude) of the product, mapping to the respective magnitudes and digits of the factors.
For example I can pretty reliably predict from a product, where the '8's are in its factors.
Apparently theres a whole host of rules like this.
So what I've done is gone an started writing an interpreter with some pseudo-assembly I defined. This has been ongoing for maybe a month, and I've had very little time to work on it in between at my job (which I'm about to be late for here if I don't start getting ready, lol).
Anyway, long and the short of it, the plan is to generate a large data set of primes and their products, and then write a rules engine to generate sets of my custom assembly language, and then fitness test and validate them, winnowing what doesn't work.
The end product should be a function that lets me map from the digits of a product to all the digits of its factors.
It technically already works, like I've printed out a ton of products and eyeballed patterns to derive custom rules, its just not the complete set yet. And instead of spending months or years doing that I'm just gonna finish the system to automatically derive them for me. The rules I found so far have tested out successfully every time, and whether or not the engine finds those will be the test case for if the broader system is viable, but everything looks legit.
I wouldn't have persued this except when I realized the production of semiprimes *must* be non-eularian (long story), it occured to me that there must be rich internal representations mapping products to factors, that we were simply missing.
I'll go into more details in a later post, maybe not today, because I'm working till close tonight (won't be back till 3 am), but after 4 1/2 years the work is bearing fruit.
Also, its good to see you all again. I fucking missed you guys.9 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!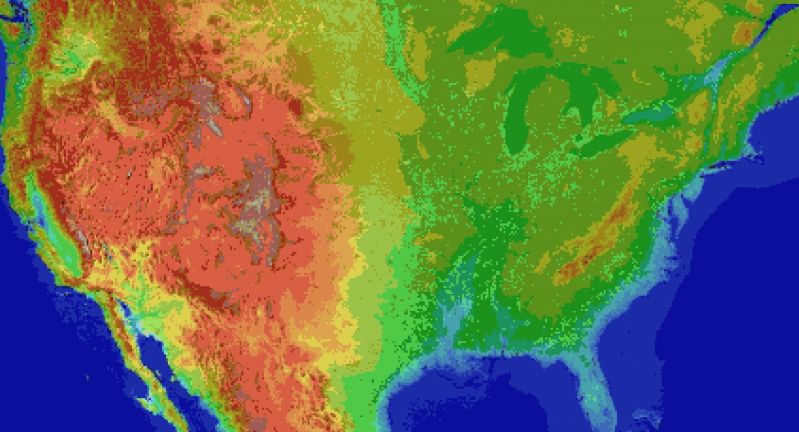 5
5 -
Yesterday I almost ended my programming Carrier
Long story - I am enrolled in EC course which I cannot face for a single moment. Web development is something that had always excited me, and i wanted to make a room for myself here since childhood.
I cannot study what doesn't interest me. But that does not mean I hate learning. I have strong interest in learning things. Hence, I skipped two end-sem exam in the last semester. And utilized thar time to work on my project. I've been working on it since last 6 months. I learned more things in last one year than what I did in last 3 years at college.
My brother came to know I failed two exams in the last sem, yesterday. There were clouds flying over home for hours. What my family thinks is, I should get my degree. Whether I learn anything or not, but I should I get it. I must do graduation and what ever stuff I am working on can be done later. They don't understand the value of time and how fast things are changing.
I even got a client, who is willing to pay large amount for my platform. What my family thinks, is I am running for money, which is merely true.
What world we are living in. Parents and families don't want their children to get educated or well equipped with knowledge and values but want a printed degree in hand, which they think is enough to get a job.
The colony where I live, more than 80% graduates, that graduated in last 5 years with good numbers are unemployed.3 -
Riddle:
Alice and bob want to communicate a secret message, lets say it is an integer.
We will call this msg0.
You are Chuck, an interloper trying to spy on them and decode the message.
For keys, alice chooses a random integer w, another for x, and another for y. she also calculates a fourth variable, x+y = z
Bob follows the same procedure.
Suppose the numbers are too large to bruteforce.
Their exchange looks like this.
At step 1, alice calculates the following:
msg1 = alice.z+alice.w+msg0
she sends this message over the internet to bob.
the value of msg1 is 20838
then for our second step of the process, bob calculates msg2 = bob.z+bob.w+msg1
msg2 equals 32521
he then sends msg2 to alice, and again, you intercept and observe.
at step three, alice recieves bob's message, and calculates the following: msg3 = msg2-(alice.x+alice.w+msg0)
msg3 equals 19249. Alice sends this to bob.
bob calculates msg4 = msg3-(bob.x+bob.w)
msg4 equals 11000.
he sends msg4 to alice
at this stage, alice calculates ms5.
msg5 = (msg4-(alice.y)+msg0.
alice sends this to bob.
bob recieves this final message and calculates
the sixth and final message, which is the original hidden msg0 alice wanted to send:
msg6 = msg5-bob.y
What is the secret message?
I'll give anyone who solves it without bruteforcing, a free cookie.16 -
Though I demonstrated a hard upperbound on the D(10) dedekind in the link here (https://devrant.com/rants/8414096/...), a value of 1.067*(10^83), which agrees with and puts a bound on this guy's estimate (https://johndcook.com/blog/2023/...) of 3.253*10^82, I've done a little more work.
It's kind of convoluted, and involves sequences related to the following page (https://oeis.org/search/...) though I won't go into detail simply because the explaination is exhausting.
Despite the large upperbound, the dedekinds have some weirdness to them, and their growth is non-intuitive. After working through my results, I actually think D(10) will turn out to be much lower than both cook's estimate and my former upperbound, that it'll specifically be found among the values of..
1.239*(10^43)
2.8507*(10^46)
2.1106*(10^50)
If this turns out to be correct (some time before the year 2100, lol), I'll explain how I came to the conclusion then.3 -
In the 90s most people had touched grass, but few touched a computer.
In the 2090s most people will have touched a computer, but not grass.
But at least we'll have fully sentient dildos armed with laser guns to mildly stimulate our mandatory attached cyber-clits, or alternatively annihilate thought criminals.
In other news my prime generator has exhaustively been checked against, all primes from 5 to 1 million. I used miller-rabin with k=40 to confirm the results.
The set the generator creates is the join of the quasi-lucas carmichael numbers, the carmichael numbers, and the primes. So after I generated a number I just had to treat those numbers as 'pollutants' and filter them out, which was dead simple.
Whats left after filtering, is strictly the primes.
I also tested it randomly on 50-55 bit primes, and it always returned true, but that range hasn't been fully tested so far because it takes 9-12 seconds per number at that point.
I was expecting maybe a few failures by my generator. So what I did was I wrote a function, genMillerTest(), and all it does is take some number n, returns the next prime after it (using my functions nextPrime() and isPrime()), and then tests it against miller-rabin. If miller returns false, then I add the result to a list. And then I check *those* results by hand (because miller can occasionally return false positives, though I'm not familiar enough with the math to know how often).
Well, imagine my surprise when I had zero false positives.
Which means either my code is generating the same exact set as miller (under some very large value of n), or the chance of miller (at k=40 tests) returning a false positive is vanishingly small.
My next steps should be to parallelize the checking process, and set up my other desktop to run those tests continuously.
Concurrently I should work on figuring out why my slowest primality tests (theres six of them, though I think I can eliminate two) are so slow and if I can better estimate or derive a pattern that allows faster results by better initialization of the variables used by these tests.
I already wrote some cases to output which tests most frequently succeeded (if any of them pass, then the number isn't prime), and therefore could cut short the primality test of a number. I rewrote the function to put those tests in order from most likely to least likely.
I'm also thinking that there may be some clues for faster computation in other bases, or perhaps in binary, or inspecting the patterns of values in the natural logs of non-primes versus primes. Or even looking into the *execution* time of numbers that successfully pass as prime versus ones that don't. Theres a bevy of possible approaches.
The entire process for the first 1_000_000 numbers, ran 1621.28 seconds, or just shy of a tenth of a second per test but I'm sure thats biased toward the head of the list.
If theres any other approach or ideas I may be overlooking, I wouldn't know where to begin.16 -
In 2015 I sent an email to Google labs describing how pareidolia could be implemented algorithmically.
The basis is that a noise function put through a discriminator, could be used to train a generative function.
And now we have transformers.
I also told them if they looked back at the research they would very likely discover that dendrites were analog hubs, not just individual switches. Thats turned out to be true to.
I wrote to them in an email as far back as 2009 that attention was an under-researched topic. In 2017 someone finally got around to writing "attention is all you need."
I wrote that there were very likely basic correlates in the human brain for things like numbers, and simple concepts like color, shape, and basic relationships, that the brain used to bootstrap learning. We found out years later based on research, that this is the case.
I wrote almost a decade ago that personality systems were a means that genes could use to value-seek for efficient behaviors in unknowable environments, a form of adaption. We later found out that is probably true as well.
I came up with the "winning lottery ticket" hypothesis back in 2011, for why certain subgraphs of networks seemed to naturally learn faster than others. I didn't call it that though, it was just a question that arose because of all the "architecture thrashing" I saw in the research, why there were apparent large or marginal gains in slightly different architectures, when we had an explosion of different approaches. It seemed to me the most important difference between countless architectures, was initialization.
This thinking flowed naturally from some ideas about network sparsity (namely that it made no sense that networks should be fully connected, and we could probably train networks by intentionally dropping connections).
All the way back in 2007 I thought this was comparable to masking inputs in training, or a bottleneck architecture, though I didn't think to put an encoder and decoder back to back.
Nevertheless it goes to show, if you follow research real closely, how much low hanging fruit is actually out there to be discovered and worked on.
And to this day, google never fucking once got back to me.
I wonder if anyone ever actually read those emails...
Wait till they figure out "attention is all you need" isn't actually all you need.
p.s. something I read recently got me thinking. Decoders can also be viewed as resolving a manifold closer to an ideal form for some joint distribution. Think of it like your data as points on a balloon (the output of the bottleneck), and decoding as the process of expanding the balloon. In absolute terms, as the balloon expands, your points grow apart, but as long as the datapoints are not uniformly distributed, then *some* points will grow closer together *relatively* even as the surface expands and pushes points apart in the absolute.
In other words, for some symmetry, the encoder and bottleneck introduces an isotropy, and this step also happens to tease out anisotropy, information that was missed or produced by the encoder, which is distortions introduced by the architecture/approach, features of the data that got passed on through the bottleneck, or essentially hidden features.4 -
Maybe I'm severely misunderstanding set theory. Hear me out though.
Let f equal the set of all fibonacci numbers, and p equal the set of all primes.
If the density of primes is a function of the number of *multiples* of all primes under n,
then the *number of primes* or density should shrink as n increases, at an ever increasing rate
greater than the density of the number of fibonacci numbers below n.
That means as n grows, the relative density of f to p should grow as well.
At sufficiently large n, the density of p is zero (prime number theorem), not just absolutely, but relative to f as well. The density of f is therefore an upper limit of the density of p.
And the density of p given some sufficiently large n, is therefore also a lower limit on the density of f.
And that therefore the density of p must also be the upper limit on the density of the subset of primes that are Fibonacci numbers.
WHICH MEANS at sufficiently large values of n, there are either NO Fibonacci primes (the functions diverge), and therefore the set of Fibonacci primes is *finite*, OR the density of primes given n in the prime number theorem
*never* truly reaches zero, meaning the primes are in fact infinite.
Proving the Fibonacci primes are infinite, therefore would prove that the prime number line ends (fat chance). While proving the primes are infinite, proves the Fibonacci primes are finite in quantity.
And because the number of primes has been proven time and again to be infinite, as far back as 300BC,the Fibonacci primes MUST be finite.
QED.
If I've made a mistake, I'd like to know.11 -
I had to choose a subject for a math project. So I selected encryption (elliptic curve). I decided to make an interactive demo website. First time working with node, websockets, large numbers and latex. Most fun project I ever did. I am still proud on the result and how fast I did it (~3 weeks)
-
For context: I’m a relatively new employee (~six months) on the outreach team at a large nonprofit. Our team rarely gets together, working remotely and out at events most of the time. My supervisor’s managing style is odd to me, and I’m not really used to it yet. She is very hands-off and flaky, but extremely numbers-oriented and goal-driven. She doesn’t respond well to emails and often ends up communicating solely via text.
Last week, a friend of mine passed away unexpectedly. My manager was out of town and not working that day, so I emailed instead of texting her to let her know that I would be travelling for the funeral and wouldn’t be working on Monday or Tuesday. She actually emailed back apologizing for my loss and telling me to just let her know when I’m back in town. I was impressed that she got back to me and thankful for her flexibility.
On Sunday night at 11:30 p.m., I received a text from her about a Monday morning meeting that I chose to ignore because I was annoyed that she would text me so late and expect a response, even if it would just be to remind her that I’m out. At around midnight she sent another that said, “That’s right, you’re out. I forgot.”
On Tuesday morning, while pulling into the church parking lot for the funeral, I received a text from her to our whole team complaining about outreach and program recruitment numbers with several follow-up texts asking for immediate explanations for not meeting this month’s goals. I immediately silenced notifications from the conversation and haven’t addressed them.
Am I wrong in thinking that this was extremely inappropriate and insensitive? I feel like that conversation would have been much better suited for an in-person meeting, or even an email, especially since she knew I was out on personal time. At the very least, she should have left me off of the text chain, right?
Should I talk to her about this when I see her next? Go to HR? Bring it up the next time I take a personal day (“I’d like it if you don’t text me while I’m out this week”)? I’m really terrible at confrontation and am nervous about looking like I’m overreacting, but this really upset me. Thankful for any advice you can give!3 -
After learning a bit about alife I was able to write
another one. It took some false starts
to understand the problem, but afterward I was able to refactor the problem into a sort of alife that measured and carefully tweaked various variables in the simulator, as the algorithm
explored the paramater space. After a few hours of letting the thing run, it successfully returned a remainder of zero on 41.4% of semiprimes tested.
This is the bad boy right here:
tracks[14]
[15, 2731, 52, 144, 41.4]
As they say, "he ain't there yet, but he got the spirit."
A 'track' here is just a collection of critical values and a fitness score that was found given a few million runs. These variables are used as input to a factoring algorithm, attempting to factor
any number you give it. These parameters tune or configure the algorithm to try slightly different things. After some trial runs, the results are stored in the last entry in the list, and the whole process is repeated with slightly different numbers, ones that have been modified
and mutated so we can explore the space of possible parameters.
Naturally this is a bit of a hodgepodge, but the critical thing is that for each configuration of numbers representing a track (and its results), I chose the lowest fitness of three runs.
Meaning hypothetically theres room for improvement with a tweak of the core algorithm, or even modifications or mutations to the
track variables. I have no clue if this scales up to very large semiprime products, so that would be one of the next steps to test.
Fitness also doesn't account for return speed. Some of these may have a lower overall fitness, but might in fact have a lower basis
(the value of 'i' that needs to be found in order for the algorithm to return rem%a == 0) for correctly factoring a semiprime.
The key thing here is that because all the entries generated here are dependent on in an outer loop that specifies [i] must never be greater than a/4 (for whatever the lowest factor generated in this run is), we can potentially push down the value of i further with some modification.
The entire exercise took 2.1735 billion iterations (3-4 hours, wasn't paying attention) to find this particular configuration of variables for the current algorithm, but as before, I suspect I can probably push the fitness value (percentage of semiprimes covered) higher, either with a few
additional parameters, or a modification of the algorithm itself (with a necessary rerun to find another track of equivalent or greater fitness).
I'm starting to bump up to the limit of my resources, I keep hitting the ceiling in my RAD-style write->test->repeat development loop.
I'm primarily using the limited number of identities I know, my gut intuition, combine with looking at the numbers themselves, to deduce relationships as I improve these and other algorithms, instead of relying strictly on memorizing identities like most mathematicians do.
I'm thinking if I want to keep that rapid write->eval loop I'm gonna have to upgrade, or go to a server environment to keep things snappy.
I did find that "jiggling" the parameters after each trial helped to explore the parameter
space better, so I wrote some methods to do just that. But what I wouldn't mind doing
is taking this a bit of a step further, and writing some code to optimize the variables
of the jiggle method itself, by automating the observation of real-time track fitness,
and discarding those changes that lead to the system tending to find tracks with lower fitness.
I'd also like to break up the entire regime into a training vs test set, but for now
the results are pretty promising.
I knew if I kept researching I'd likely find extensions like this. Of course tested on
billions of semiprimes, instead of simply millions, or tested on very large semiprimes, the
effect might disappear, though the more i've tested, and the larger the numbers I've given it,
the more the effect has become prevalent.
Hitko suggested in the earlier thread, based on a simplification, that the original algorithm
was a tautology, but something told me for a change that I got one correct. Without that initial challenge I might have chalked this up to another false start instead of pushing through and making further breakthroughs.
I'd also like to thank all those who followed along, helped, or cheered on the madness:
In no particular order ,demolishun, scor, root, iiii, karlisk, netikras, fast-nop, hazarth, chonky-quiche, Midnight-shcode, nanobot, c0d4, jilano, kescherrant, electrineer, nomad,
vintprox, sariel, lensflare, jeeper.
The original write up for the ideas behind the concept can be found at:
https://devrant.com/rants/7650612/...
If I left your name out, you better speak up, theres only so many invitations to the orgy.
Firecode already says we're past max capacity!5 -
So to test my server code that do calculations on large numbers that get above 10 digits 90% of the time.
The end users found a custom web page with basic javascript doing the calculations.
Now I get to explain why that doesn't work. -
So I promised a post after work last night, discussing the new factorization technique.
As before, I use a method called decon() that takes any number, like 697 for example, and first breaks it down into the respective digits and magnitudes.
697 becomes -> 600, 90, and 7.
It then factors *those* to give a decomposition matrix that looks something like the following when printed out:
offset: 3, exp: [[Decimal('2'), Decimal('3')], [Decimal('3'), Decimal('1')], [Decimal('5'), Decimal('2')]]
offset: 2, exp: [[Decimal('2'), Decimal('1')], [Decimal('3'), Decimal('2')], [Decimal('5'), Decimal('1')]]
offset: 1, exp: [[Decimal('7'), Decimal('1')]]
Each entry is a pair of numbers representing a prime base and an exponent.
Now the idea was that, in theory, at each magnitude of a product, we could actually search through the *range* of the product of these exponents.
So for offset three (600) here, we're looking at
2^3 * 3 ^ 1 * 5 ^ 2.
But actually we're searching
2^3 * 3 ^ 1 * 5 ^ 2.
2^3 * 3 ^ 1 * 5 ^ 1
2^3 * 3 ^ 1 * 5 ^ 0
2^3 * 3 ^ 0 * 5 ^ 2.
2^3 * 3 ^ 1 * 5 ^ 1
etc..
On the basis that whatever it generates may be the digits of another magnitude in one of our target product's factors.
And the first optimization or filter we can apply is to notice that assuming our factors pq=n,
and where p <= q, it will always be more efficient to search for the digits of p (because its under n^0.5 or the square root), than the larger factor q.
So by implication we can filter out any product of this exponent search that is greater than the square root of n.
Writing this code was a bit of a headache because I had to deal with potentially very large lists of bases and exponents, so I couldn't just use loops within loops.
Instead I resorted to writing a three state state machine that 'counted down' across these exponents, and it just works.
And now, in practice this doesn't immediately give us anything useful. And I had hoped this would at least give us *upperbounds* to start our search from, for any particular digit of a product's factors at a given magnitude. So the 12 digit (or pick a magnitude out of a hat) of an example product might give us an upperbound on the 2's exponent for that same digit in our lowest factor q of n.
It didn't work out that way. Sometimes there would be 'inversions', where the exponent of a factor on a magnitude of n, would be *lower* than the exponent of that factor on the same digit of q.
But when I started tearing into examples and generating test data I started to see certain patterns emerge, and immediately I found a way to not just pin down these inversions, but get *tight* bounds on the 2's exponents in the corresponding digit for our product's factor itself. It was like the complications I initially saw actually became a means to *tighten* the bounds.
For example, for one particular semiprime n=pq, this was some of the data:
n - offset: 6, exp: [[Decimal('2'), Decimal('5')], [Decimal('5'), Decimal('5')]]
q - offset: 6, exp: [[Decimal('2'), Decimal('6')], [Decimal('3'), Decimal('1')], [Decimal('5'), Decimal('5')]]
It's almost like the base 3 exponent in [n:7] gives away the presence of 3^1 in [q:6], even
though theres no subsequent presence of 3^n in [n:6] itself.
And I found this rule held each time I tested it.
Other rules, not so much, and other rules still would fail in the presence of yet other rules, almost like a giant switchboard.
I immediately realized the implications: rules had precedence, acted predictable when in isolated instances, and changed in specific instances in combination with other rules.
This was ripe for a decision tree generated through random search.
Another product n=pq, with mroe data
q(4)
offset: 4, exp: [[Decimal('2'), Decimal('4')], [Decimal('5'), Decimal('3')]]
n(4)
offset: 4, exp: [[Decimal('2'), Decimal('3')], [Decimal('3'), Decimal('2')], [Decimal('5'), Decimal('3')]]
Suggesting that a nontrivial base 3 exponent (**2 rather than **1) suggests the exponent on the 2 in the relevant
digit of [n], is one less than the same base 2 digital exponent at the same digit on [q]
And so it was clear from the get go that this approach held promise.
From there I discovered a bunch more rules and made some observations.
The bulk of the patterns, regardless of how large the product grows, should be present in the smaller bases (some bound of primes, say the first dozen), because the bulk of exponents for the factorization of any magnitude of a number, overwhelming lean heavily in the lower prime bases.
It was if the entire vulnerability was hiding in plain sight for four+ years, and we'd been approaching factorization all wrong from the beginning, by trying to factor a number, and all its digits at all its magnitudes, all at once, when like addition or multiplication, factorization could be done piecemeal if we knew the patterns to look for.7 -
Reflecting back on my previous post regarding quitting my job without an offer . Today the final email from system came : my resignation is accepted, my lwd is 7th dec and portal no longer shows the with draw button. The small spark with potential to burn the world did burn it , so her we are.
3 people were supposed to be part of this seperation : my current manager, the avp (person who hired me, was sr manager back then) and HR. HR was on leave for 2 days and all my emails went into auto reply from her, and when she came back, she approved the resignation without any discussion.
my manager(EL), who is the primary cause of me taking this step, tried talking to me. I can't say its because of u, so I simply said WLB, I need work from home. She tried to bring facts : why wfh? you are doing fine in hybrid ? you are getting 6h work every day? your joining letter said all days working from office?
I didn't entertain those points. The meeting ended in 5 mins.
Next day I emailed again regarding my status and she was the person who texted me saying such emails are not acceptable, go to portal and initiate seperation. she shared the steps and as i was about to press the button, I got a call from the avp
I tried the excuse approach bit he was able to see through it (he was showing disappointment). his talking style is charming, so I eventually opened up to him. the call lasted 30 mins, it made me think and today morning I was thinking of alternatives and discussing with him on chat, ittle to my knowledge that my manager has already approved the resignation. fine, I guess.
But here is the main story: WHY DO I WANT TO RESIGN? why would I ask a 3 day office company to gove me wfh and write here that even this is a lie. WHAT IS THE REAL REASON? here are the points , most of which i told the avp in some way as well:
1. The most frank reason is disrespect. I have been in this org for 2.9 years and was one of the first 4 members to join. today we are a 20 people team, one of the 1st 4 came as product manager and is now senior pm, 2nd came in as SSE and is now EL (SSE-> Module Lead -> Engineering Lead). 3rd came as SSE and is now ML . I came as software engineer and is still a software engineer . I even helped hiring a guy with 2 yrs less experience than me and in 10 months he got a sneior position but not me
2. The obvious area of disrespect is when I try to put my point, but my points are not considered but rather needs to be approved by those peole who hold a title. I am a laughing stock among juniors
3. Even after doing flwaless work for years and not getting an ounce of respect, my smallest mistakes are openly highlighted and humiliated. There was once a prod bug that was caught during sanity but for that, I was shouted upon by this EL at 1140pm in night in a 3 person call of EL,an intern and me. this same lady joined 10 days before me and did nothing but politics and talkings to get a position where she is humiliating me
4. These people suck at management and end up making us feel like slaves. one mistake (from anyone) and we get called out in meetings, chats . Our estimates are questioned and negotiated because the "senior" thinks it can be done in lesser time .
5. New rules are enforced everyday , making everything a dev's job . unit test cases? developer will do . uat testing? developer should do. prod testing? dev's job after getting prod numbers whitelisted. war room testing of modules? dev's job . let other teams know of changes? dev job. making a list of all tasks,all estimates and hourly time spent by a dev in a sprint? dev's job. What is the responsibility of qa team and EL?
6. in past 2 years I added 500+ commits, worked on 450+ small to large tasks and almost 99% of app's features are known to me. but in first year I broke my left arm and took a month wfh. In 2nd year i got stage 3 cancer and took 2 months sabbatical. all this made my contributions z my efforts as 0 and I never got any appreciation once.
----
With all these issues, what else could i have done apart from putting papers? How much can I figjt the useless fights? I am not the loudest nor the most cunning person in thsoe rooms. And these 2 seems common attributes of both of those SSEs who got good leadership positions.
I am sorry I couldn't be a better fighter. I am tired of fighting : my life, my situation and now the fight to proove my worth in the only space that i am passionate and proud20 -
Using float in a simple structure for a network project running on Contiki. I was trying to print this structure for debug purpose and I noticed that all my float don't show up 😦
After some Googling, I ended-up on a mailing list saying that float and double are not useable in Contiki 😒
I get that double is too large (8bytes) but seriously a float is just 4bytes!
Well for now our floating numbers are just integer 😌 -
Disclaimer: the project I'm about to mention contains the first lines of Go I have ever written.
Still, I'm quite proud of how quickly I got it working considering it's also my first time working with GTK.
This project that I've been working on the past few days is finally done. But it's %50 percent spaghetti, so refactoring time. I decided to have a look at my cyclomatic complexity numbers, and my biggest function (not main()) had it at 7.
As it was quite large, I split it up into to parts: the preparation and the actual timer loop. As I appear to need to use a goroutine, by the time I'm done passing channels and all hell to handle them, my loop function now has a score of 9 for cyclomatic complexity.
So fix one bug, leaves two in its place?
But I still need to better learn Go, anyone have a good (relatively painless, informative, quick-ish) course they can recommend? I've been thinking of trying out codecademy's one...6 -
So I made a couple slight modifications to the formula in the previous post and got some pretty cool results.
The original post is here:
https://devrant.com/rants/5632235/...
The default transformation from p, to the new product (call it p2) leads to *very* large products (even for products of the first 100 primes).
Take for example
a = 6229, b = 10477, p = a*b = 65261233
While the new product the formula generates, has a factor tree that contains our factor (a), the product is huge.
How huge?
6489397687944607231601420206388875594346703505936926682969449167115933666916914363806993605...
and
So huge I put the whole number in a pastebin here:
https://pastebin.com/1bC5kqGH
Now, that number DOES contain our example factor 6229. I demonstrated that in the prior post.
But first, it's huge, 2972 digits long, and second, many of its factors are huge too.
Right from the get go I had hunch, and did (p2 mod p) and the result was surprisingly small, much closer to the original product. Then just to see what happens I subtracted this result from the original product.
The modification looks like this:
(p-(((abs(((((p)-(9**i)-9)+1))-((((9**i)-(p)-9)-2)))-p+1)-p)%p))
The result is '49856916'
Thats within the ballpark of our original product.
And then I factored it.
1, 2, 3, 4, 6, 12, 23, 29, 46, 58, 69, 87, 92, 116, 138, 174, 276, 348, 667, 1334, 2001, 2668, 4002, 6229, 8004, 12458, 18687, 24916, 37374, 74748, 143267, 180641, 286534, 361282, 429801, 541923, 573068, 722564, 859602, 1083846, 1719204, 2167692, 4154743, 8309486, 12464229, 16618972, 24928458, 49856916
Well damn. It's not a-smooth or b-smooth (where 'smoothness' is defined as 'all factors are beneath some number n')
but this is far more approachable than just factoring the original product.
It still requires a value of i equal to
i = floor(a/2)
But the results are actually factorable now if this works for other products.
I rewrote the script and tested on a couple million products and added decimal support, and I'm happy to report it works.
Script is posted here if you want to test it yourself:
https://pastebin.com/RNu1iiQ8
What I'll do next is probably add some basic factorization of trivial primes
(say the first 100), and then figure out the average number of factors in each derived product.
I'm also still working on getting to values of i < a/2, but only having sporadic success.
It also means *very* large numbers (either a subset of them or universally) with *lots* of factors may be reducible to unique products with just two non-trivial factors, but thats a big question mark for now.
@scor if you want to take a look.5 -
I could calculate the percentage of a value from a total set right from the top of my head. This includes large numbers like for example; finding the percentage of 1040 from 75000 = 1.377%, 344 from 5400 = 6.37% and so on...
But most times when I come across scenarios to apply such calculations on code I find myself googling for formulas and then I wonder; how am I able to come to a valid result when faced with similar challenge but could not recall or tell the formula my funny brain is deriving it's results from.
Maybe my brain isn't even using a formula. :/
So I guess because from pondering on how I arrived at results, I could tell I'm starting from an "if"...
Like:
If 25 of 100 = 25%
and 45 of 250 = 18%
Then 450 of 2400 will equal 18.7...%
Ask me what formula was used in the first "if" condition and I can't tell because that's common sense for me.2 -
TRUSTWORTHY CRYPTO RECOVERY SERVICE- HIRE SALVAGE ASSET RECOVERY
At Tax Ease Solutions, based in New York, USA, we faced a critical crisis when our tax filing system was hacked overnight. The breach exposed sensitive personal data, including Social Security numbers, financial details, and addresses of our clients. The attackers used this stolen information to apply for fraudulent tax refunds, resulting in a significant loss of $1 million USD. The breach occurred during the night while our team was off-duty, leaving us unaware until the following morning when we discovered the extent of the damage. With such a large amount of money lost and the integrity of our business compromised, we knew we needed immediate assistance to recover and secure both our clients’ data and our reputation. That’s when we reached out to Salvage Asset Recovery. Salvage Asset Recovery’s team responded promptly and demonstrated their deep expertise in dealing with cybersecurity breaches. They quickly identified the source of the vulnerability and acted decisively to patch the system flaw. Their ability to rapidly assess the situation and implement corrective actions helped to prevent any further unauthorized access to our platform. Once the system was secured, Salvage Asset Recovery shifted their focus to assisting our affected clients. They worked diligently with financial institutions and law enforcement to help some clients who were able to reach out and report the fraudulent tax refund applications. Through their intervention, these clients were able to stop the fraudulent transactions and recover some of their funds. As of now, Salvage Asset Recovery has managed to recover $980,000 of the lost $1 million, but they are still continuing to work with authorities and financial institutions to recover the remaining funds. Salvage Asset Recovery helped us implement more robust security measures to prevent any future breaches. They introduced advanced encryption techniques and worked with us to update our cybersecurity protocols, ensuring that our clients' data would be better protected going forward. Their consultation also guided us in strengthening our internal data protection policies, which reassured our clients that we were committed to safeguarding their sensitive information. Thanks to the quick and efficient actions of Salvage Asset Recovery, Tax Ease Solutions was able to recover $980,000 of the lost funds and protect the majority of our clients’ data. Their professionalism, expertise, and dedication to helping both our company and our clients made all the difference in mitigating the effects of the breach and stabilizing our business. The recovery process is still ongoing, but we remain confident that with Salvage Asset ’s continued support, we will fully resolve the situation.
Their Contact info,
WhatsApp+ 1 8 4 7 6 5 4 7 0 9 6 1
1 -
I NEED A HACKER TO RECOVER MY STOLEN BITCOIN CONTACT FUNDS RECLAIMER COMPANY
As a professional footballer playing for one of London’s top football teams, my life has always been focused on excelling in my career, working tirelessly to improve my skills, and delivering performances that would make my fans proud. The intensity of the game, the excitement of the crowd, and the bond with my teammates are things that make football more than just a job it’s my passion. Off the pitch, I’ve always been mindful of securing my future, and I knew that investing my money wisely was essential to maintaining my financial stability after my playing days. When I first heard about an investment broker that promised high returns with minimal risk, it sounded like a great opportunity to grow my savings. The company had a professional appearance, with glowing testimonials and a polished website that instilled confidence. They reassured me that they had a foolproof strategy for earning returns while minimizing risk, so I felt comfortable entrusting them with a significant portion of my earnings. I decided to invest 1 million euros, believing it was a sound decision that would help me secure my future. At first, everything seemed to go according to plan. I saw modest but steady returns, and the broker’s platform appeared to be user-friendly and transparent. Encouraged by this, I continued to increase my investments, watching the numbers in my account slowly grow. But, as time went on, the returns began to slow down, and eventually, I found myself unable to access my funds. Attempts to contact the broker were met with vague responses and delays, and soon, I realized that I had been scammed. The realization that I had lost 1 million euros was crushing. It felt like an enormous betrayal especially since I had worked so hard to build my career and manage my finances carefully. I was overwhelmed with a sense of hopelessness and frustration. I felt lost, not knowing what to do or where to turn for help. It was during this time of despair that I discovered FUNDS RECLIAMER COMPANY , a company that specialized in helping people recover funds lost to financial scams. At first, I was skeptical. Recovering such a large sum of money seemed like a long shot, but I was desperate, so I decided to give it a try. To my surprise, the team at FUNDS RECLIAMER COMPANY was incredibly professional and attentive. They quickly took charge of the situation, using their expertise and resources to track down my lost funds. Within just a few weeks, I was thrilled to find that they had successfully recovered the majority of the 1 million euros I had invested. Not only did they help me get my money back, but they also provided me with valuable advice on how to approach investments more cautiously in the future. I am truly grateful for their help. Thanks to FUNDS RECLIAMER COMPANY, I was able to restore my financial stability and learn critical lessons about the importance of due diligence when investing. Their dedication and professionalism gave me a renewed sense of confidence, not just in my financial decisions, but in how to navigate the often-risky world of investing.
FOR MORE INFO:
Email: fundsreclaimer(@) c o n s u l t a n t . c o m
WhatsApp:+1 (361) 2 5 0- 4 1 1 0
Website: h t t p s ://fundsreclaimercompany . c o m 1
1 -
VirPhone: Empowering Your Business with Cloud Phone Systems and VOIP Technology
In today’s fast-paced and digital world, efficient communication is key to the success of any business. Whether you're reaching out to clients, collaborating with remote teams, or handling customer inquiries, having a reliable phone system is essential. VirPhone offers cutting-edge cloud phone systems that are designed to streamline your communication, reduce costs, and improve efficiency. Let’s explore how our cloud phone systems can elevate your business and answer some common questions like, “What is VOIP phone?” and how it can benefit your business.
What is a Cloud Phone System?
A cloud phone system is an advanced communication solution that operates over the internet, rather than relying on traditional landlines. This system provides businesses with a more flexible, scalable, and cost-effective way to manage their communications. VirPhone’s cloud phone systems allow businesses to make and receive calls, send messages, and conduct video conferences—all from the convenience of a cloud-based platform.
With VirPhone, you can enjoy the flexibility of managing your communications from anywhere. Whether you’re in the office, working remotely, or traveling, a cloud phone system ensures you stay connected at all times.
What is VOIP and How Can It Benefit Your Business?
VOIP stands for Voice Over Internet Protocol, which is a technology that allows voice calls to be made over the internet rather than using traditional telephone lines. So, what is VOIP phone? It’s simply a phone system that enables businesses to make calls over the internet.
Unlike traditional phone systems, VOIP phone systems are cost-effective and more flexible, providing features such as call forwarding, voicemail, and voicemail-to-email. VirPhone’s VOIP technology not only reduces your business’s communication costs but also enhances overall productivity by providing features that are more customizable and scalable.
Some of the key benefits of VOIP phone systems include:
Lower Costs: Traditional phone systems charge for long-distance calls. With VOIP, these calls are often free or at a much lower rate.
Scalability: As your business grows, your cloud phone system can easily scale to accommodate more users or advanced features without expensive upgrades.
Flexibility: With VOIP phone systems, employees can make and receive calls anywhere, as long as they have an internet connection. This is ideal for remote teams or employees on the go.
How to Get a Toll-Free Number with VirPhone
One of the most important features for any business is having a toll-free number. A toll-free number makes your business appear professional and accessible, giving customers a way to reach you without incurring charges. VirPhone offers toll-free numbers that are easy to set up and manage through our cloud phone system.
With a toll-free number from VirPhone, customers can call your business without worrying about the cost, regardless of where they are located. This can improve customer satisfaction and make it easier for customers to get in touch with your business. Whether you're conducting customer service calls or receiving inquiries, a toll-free number can help you provide exceptional service.
Calling on a Phone: How VirPhone Enhances Your Business Calls
Whether you’re calling on a phone to reach a client, partner, or team member, VirPhone’s cloud phone system ensures that your calls are clear, reliable, and cost-effective. No more worrying about dropped calls or poor audio quality—our system is designed to provide high-quality call connections, no matter where you are.
Here are some features of VirPhone’s calling on phone services that help improve your business communication:
Crystal-Clear Audio: With VOIP phone systems, you can expect high-definition voice quality that eliminates the usual static or noise found in traditional phone calls.
Call Forwarding and Routing: If you’re unavailable, VirPhone can forward your calls to another number or voicemail. This ensures you never miss an important call.
Voicemail-to-Email: With VirPhone, you can receive voicemails directly in your email inbox, making it easier to manage messages and respond promptly.
Why Choose VirPhone for Your Business Communication?
At VirPhone, we understand the importance of reliable communication for businesses. Our cloud phone systems are designed to provide advanced features and excellent call quality, all at an affordable price. Here’s why businesses trust VirPhone for their communication needs:
Affordable: Our VOIP phone systems are cost-effective and provide significant savings over traditional phone systems.
Flexible and Scalable: Whether you're a small business or a large enterprise, our systems grow with you. Adding more lines or features is easy and can be done remotely. 1
1




















Top Tags
Weekly Rant
View