
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Good Morning!, its time for practiseSafeHex's most incompetent co-worker!
Todays contestant is a very special one.
*sitcom audience: WHY?*
Glad you asked, you see if you were to look at his linkedin profile, you would see a job title unlike any you've seen before.
*sitcom audience oooooooohhhhhh*
were not talking software developer, engineer, tech lead, designer, CTO, CEO or anything like that, No No our new entrant "G" surpasses all of those with the title ..... "Software extraordinaire".
*sitcom audience laughs hysterically*
I KNOW!, wtf does that even mean! as a previous dev-ranter pointed out does this mean he IS quality code? I'd say he's more like a trash can ... where his code belongs
*ba dum tsssss*
Ok ok, lets get on with the show, heres some reasons why "G" is on the show:
One of G's tasks was to build an analytics gathering library for iOS, similar to google analytics where you track pages and events (we couldn't use google's). G was SO good at this job he implemented 2 features we didn't even ask for:
- If the library was unable to load its config file (for any reason) it would throw an uncatchable system integrity error, crashing the app.
- If anything was passed into any of the functions that wasn't expected (null, empty array etc.) it would crash the app as it was "more efficient" to not do any sanity checks inside the library.
This caused a lot of issues as some of the data needed to come from the clients server. The day we launched the app, within the first 3 hours we had over 40k crash logs and a VERY angry client.
Now, what makes this story important is not the bugs themselves, come on how many times have we all done something stupid? No the issue here was G defended all of this as the right thing to do!
.. and no he wasn't stoned or drunk!
G claimed if he couldn't get the right settings / params he wouldn't be able to track the event and then our CEO wouldn't have our usage data. To which I replied:
"So your solution was to not give the client an app instead? ... which also doesn't give the CEO his data".
He got very angry and asked me "what would you do then?". I offered a solution something like why not have a default tag for "error" or "unknown" where if theres an issue, we send up whatever we have, plus the file name and store it somewhere else. I was told I was being ridiculous as it wasn't built to track anything like that and that would never work ... his solution? ... pull the library out of the app and forget it.
... once again giving everyone no data.
G later moved onto another cross-platform style project. Backend team were particularly unhappy as they got no spec of what needed to be done. All they knew was it was a single endpoint dealing with very complex model. There was no Java classes, super classes, abstract classes or even interfaces, just this huge chunk of mocked data. So myself and the lead sat down with him, and asked where the interfaces for the backend where, or designs / architecture for them etc.
His response, to this day frightens me ... not makes me angry, not bewilders me ... scares the living shit out of me that people like this exist in the world and have successful careers.
G: "hhhmmm, I know how to build an interface, but i've never understood them ... Like lets say I have an interface, what now? how does that help me in any way? I can't physically use it, does it not just use up time building it for no reason?"
us: "... ... how are the backend team suppose to understand the model, its types, integrate it into the other systems?"
G: "Can I not just tell them and they can write it down?"
**
I'll just pause here for a moment, as you'll likely need to read that again out of sheer disbelief
**
I've never seen someone die inside the way the lead did. He started a syllable and his face just dropped, eyes glazed over and he instantly lost all the will to live. He replied:
" wel ............... it doesn't matter ... its not important ... I have to go, good luck with the project"
*killed the screen share and left the room*
now I know you are all dying in suspense to know what happened to that project, I can drop the shocking bombshell that it was in fact cancelled. Thankfully only ~350 man hours were spent on it
... yep, not a typo.
G's crowning achievement however will go down in history. VERY long story short, backend got deployed to the server and EVERYTHING broke. Lead investigated, found mistakes and config issues on every second line, load balancer wasn't even starting up. When asked had this been tested before it was deployed:
G: "Yeah I tested it on my machine, it worked fine"
lead: "... and on the server?"
G: "no, my machine will do the same thing"
lead: "do you have a load balancer and multiple VM's?"
G: "no, but Java is Java"
... and with that its time to end todays episode. Will G be our most incompetent? ... maybe.
Tune in later for more practiceSafeHex's most incompetent co-worker!!!31 -
Dev checked in code (I suspect purposely not inviting me on the code review invite) saying he "fixed" the authentication bug in the web service.
Um no, like I told you last week, the authentication error is because the load balancer wasn't passing the user's authentication to IIS.
If I didn't overhear him telling a user "Still getting the error? I don't know, we might have to re-write that service", he might have gotten away with it.
Me: "Wait, that doesn't sound right. If I hit the server directly, authentication works. Its an issue with the load balancer, not the service"
Dev: "Admin said the load balancer is fine and it has to be the service."
Me: "I don't buy it. IIS is returning the authentication error, not the service."
Dev: "I added exception handling and nothing is being logged. Must be something in the service configuration."
Me: "No, IIS performs the authentication, not the service. I explained that last week, remember?"
Dev: "Oh yea. What changes do we need to make to the service?"
<my blood pressure starts to spike>
Me: "None. Give me a sec.."
<we have other apps on the same server farm that work just fine, so I re-configure the service pool settings to match theirs>
Me: "See, now going through the load balancer, the service works fine. For some reason, the admin had our service set up differently."
Dev: "OK, I'll let the users know the service is fixed."
Me: "Service was never broke and I'm not leaving it in its current state. In the morning I'll talk to the admin and see what he can do to fix." 6
6 -
Boss insisted that verification link needs to be clicked from same IP address as account registration. Many arguments later, decision is final, we will ignore the numerous ways that this will be a burden to our users.
*Code code, test test, deploy*
We're getting a lot of traffic, we need this bitch to scale! *auto-scale and load balance all the things*
Account creation begins breaking at random, some people receiving the "Your IP address doesn't match" error. Look at login history table, what the shit... All recent logins coming from internal IP addressohfuckmylife need to look at X-Forwarded-For header for actual IP behind load balancer.
IP address matching feature stays. I am sad, drink away sadness.4 -
I was on call with a colleague. A very quiet guy that always made the weirdest commentaries.
Anyhow, I received a message about a datacenter issue. Checked everything and it seemed a load balancer failure, so one of us should go to the datacenter (it was Saturday).
My colleague volunteered and after 4 hours I still could not see the changes. He wasn't replying the messages or anything.
I ran to the office, saw his phone on the table and went to the datacenter.
I open the door and the crazy dude is banging 2 chicks (paid version) on the room, bottle of vodka around... he gets scared and threatens to throw water and vodka on the blades if I fire him. I am so speechless that he calms down, I fix the balancer and we go home...
I was so pissed and impressed... I had to fire him. He didn't show up on monday and resigned. I still told the CTO and we could see the videos of his experience on the cctv... funny dude...2 -
Got this from boss (a few colleagues got it as well):
Sites have been down over the weekend and seems the only person cares is PM! There is a condition about working when required (i.e. unpaid OT) on your contract! It is essential that sites are properly managed even at weekends - we run a online business! If anyone has problems we'll discuss next week
*Note: site was partially down and there was no major impact on the business
When I explained why we need to rebuild the sites, you said not now - almost 2 years now, still nothing happens.
When I asked if we can get managed hosting or load balancer, fecking NO again
After asking for my opinion on the sites, you & the puppet think my honesty is me being negative and incorporate, and exclude me from meetings and major part of my work
Go fuck yourself! I've warned you about the status of the sites and you did not want to listen SO DON'T TELL ME I'M NOT DOING MY JOB WHEN YOU'RE THE ONE STOPPING ME FROM DOING IT PROPERLY!
I'm sure we'll have our meeting very soon, cheapskate. 10
10 -
Contenders for arseholes this week
- Elasticsearch as their implemented product identification and integration in client libraries like Python to exclude OpenSearch made a lot of things very painful. Yay....
- Microsoft decided to integrate kill switches in Exchange. Yeah.... Great stuff.
- Atlassian has another week of dumbness - after they botch release after release, they killed Slack with DNS
- Adoptium still hasn't managed to provide repositories after fucking up it's transition from AdoptOpenJDK
- No, a project with JDK 8 makes no sense anymore, take that shit and burn it. JDK 11 the same, would be great if we had a Repository working for JDK 17 Adoptium....
- unwanking a TLS setup by integrating an intermediary load balancer to deal with several outdated TLS implementation is a kind of thing that's really scary...
(TLS 1.3 in, TLS 1.1 - TLS 1.3 out... Theoretically all solutions have TLS 1.2… most of them non working. Solutions is a wild bunch from different vendors)
- If you buy a fucking new Apple with an Arm Chipset, ram it up so far up your arse it gets dissolved in stomach acid.
It's an arm. There's tons of compatibility problems of course. No you shouldn't listen to what the marketing says. No I cannot shit rainbows and make it work.
- German election. No politics I know, but still.
- New neighbors decided to move in. Friendly person's. Except I wanted to murder them since they choose 22 o clock for moving time.
- I forgot putting the heater on. Ever woken up frozen like fuck and having a hard week... It's a good combo to break any form of motivation.
The company next to me is renovating. Waking up to the feeling of an earth quake because they demolish their old building is another thing that makes me unhappy.
It's Friday. I survived.16 -
Discussing a somewhat small and narrow website project with a customer. Then the customer asks me how I'm going to load balance it.
My initial thought was:
You mean how to loadbalance maximum 10 users??2 -
The IT head of my Client's company : You need to explain me what exactly you are doing in the backend and how the IOT devices are connected to the server. And the security protocol too.
Me : But it's already there in the design documents.
IT Head : I know, but I need more details as I need to give a presentation.
Me : (That's the point! You want me to be your teacher!) Okay. I will try.
IT Head : You have to.
Me : (Fuck you) Well, there are four separate servers - cache, db, socket and web. Each of the servers can be configured in a distributed way. You can put some load balancers and connect multiple servers of the same type to a particular load balancer. The database and cache servers need to replicated. The socket and http servers will subscribe to the cache server's updates. The IOT devices will be connected to the socket server via SSL and will publish the updates to a particular topic. The socket server will update the cache server and the http servers which are subscribed to that channel will receive the update notification. Then http server will forward the data to the web portals via web socket. The websockets will also work on SSL to provide security. The cache server also updates the database after a fixed interval.
This is how it works.
IT Head : Can you please give the presentation?
Me : (Fuck you asshole! Now die thinking about this architecture) Nope. I am really busy.11 -
Best code performance incr. I made?
Many, many years ago our scaling strategy was to throw hardware at performance problems. Hardware consisted of dedicated web server and backing SQL server box, so each site instance had two servers (and data replication processes in place)
Two servers turned into 4, 4 to 8, 8 to around 16 (don't remember exactly what we ended up with). With Window's server and SQL Server licenses getting into the hundreds of thousands of dollars, the 'powers-that-be' were becoming very concerned with our IT budget. With our IT-VP and other web mgrs being hardware-centric, they simply shrugged and told the company that's just the way it is.
Taking it upon myself, started looking into utilizing web services, caching data (Microsoft's Velocity at the time), and a service that returned product data, the bottleneck for most of the performance issues. Description, price, simple stuff. Testing the scaling with our dev environment, single web server and single backing sql server, the service was able to handle 10x the traffic with much better performance.
Since the majority of the IT mgmt were hardware centric, they blew off the results saying my tests were contrived and my solution wouldn't work in 'the real world'. Not 100% wrong, I had no idea what would happen when real traffic would hit the site.
With our other hardware guys concerned the web hardware budget was tearing into everything else, they helped convince the 'powers-that-be' to give my idea a shot.
Fast forward a couple of months (lots of web code changes), early one morning we started slowly turning on the new framework (3 load balanced web service servers, 3 web servers, one sql server). 5 minutes...no issues, 10 minutes...no issues,an hour...everything is looking great. Then (A is a network admin)...
A: "Umm...guys...hardly any of the other web servers are being hit. The new servers are handling almost 100% of the traffic."
VP: "That can't be right. Something must be wrong with the load balancers. Rollback!"
A:"No, everything is fine. Load balancer is working and the performance spikes are coming from the old servers, not the new ones. Wow!, this is awesome!"
<Web manager 'Stacey'>
Stacey: "We probably still need to rollback. We'll need to do a full analysis to why the performance improved and apply it the current hardware setup."
A: "Page load times are now under 100 milliseconds from almost 3 seconds. Lets not rollback and see what happens."
Stacey:"I don't know, customers aren't used to such fast load times. They'll think something is wrong and go to a competitor. Rollback."
VP: "Agreed. We don't why this so fast. We'll need to replicate what is going on to the current architecture. Good try guys."
<later that day>
VP: "We've received hundreds of emails complementing us on the web site performance this morning and upset that the site suddenly slowed down again. CEO got wind of these emails and instructed us to move forward with the new framework."
After full implementation, we were able to scale back to only a few web servers and a single sql server, saving an initial $300,000 and a potential future savings of over $500,000. Budget analysis considering other factors, over the next 7 years, this would save the company over a million dollars.
At the semi-annual company wide meeting, our VP made a speech.
VP: "I'd like to thank everyone for this hard fought journey to get our web site up to industry standards for the benefit of our customers and stakeholders. Most of all, I'd like to thank Stacey for all her effort in designing and implementation of the scaling solution. Great job Stacy!"
<hands her a blank white envelope, hmmm...wonder what was in it?>
A few devs who sat in front of me turn around, network guys to the right, all look at me with puzzled looks with one mouth-ing "WTF?"7 -
Need my vaccine receipt to go to a wedding. And I’m in line to get the pdf document. On the one hand this is some cool implementation for a load balancer, on the other hand this so strange… be online in a line to get a document -.0
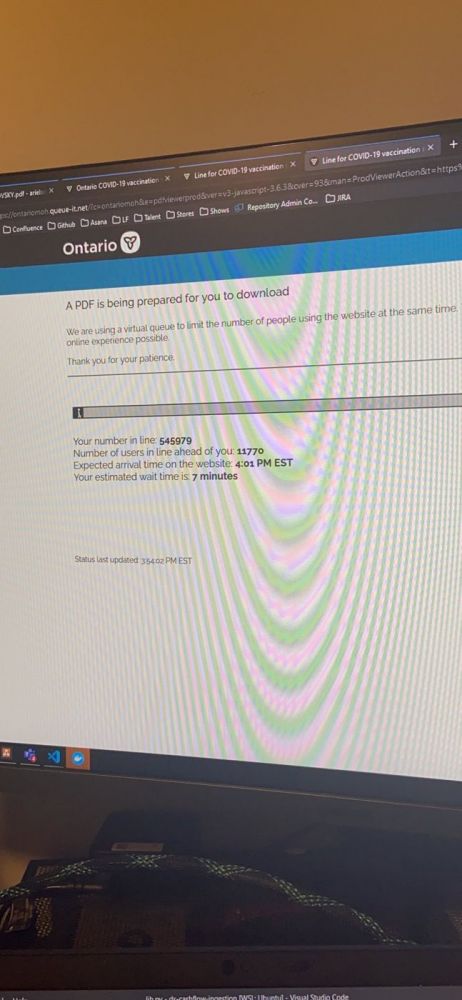 8
8 -
Hooked up a monitor directly to a server that wouldn't boot. Fixed the server. Unplugged the server instead of the monitor. At least it was already out of the load balancer? Oops.1
-
!rant
Just helped one of my professors set up a nginx load balancer with https, rate limiter, firewalls and everything from scratch. It feels so amazing to be able to put all the stuff I learn at work to practice. -
Crazy... Hm, that could qualify for a *lot*.
Craziest. Probably misusage or rather "brain damaged" knowledge about HTTP.
I've seen a lot of wild things when devs start poking standards, but the tip of the iceberg was someone trying to use UTF-8 in headers...
You might have guessed it - German umlauts. :(
Coz yeah. Fucktard loved writing everything in german, so why not write custom header names in german.
The fun thing is: It *can* work, though the usual sane thing is to keep it in ASCII range for the obvious reason that using UTF-8 (or ISO-8859-1, which is *not* ASCII) is a gamble you gonna loose.
The fun game was that after putting in a much needed load balancer between services for monitoring / scaling etc suddenly *something* seemed off.
It took me 2 days and a lot of Wireshark hoola hooping to find out why, cause the header was used for device detection aka wether it's a bot or not. Or in the german term the dev used: "Geräte-Art".
As the fallback was to assume a bot, but only rate limit based on IP, only few managed to achieve the necessary rate limit to get blocked.
So when I say *something* seemed off, I really mean a spooky kind of "sometimes IP blocked for seemingly no reason at all".
Fun stuff. The dev btw germanized everything. Untangling the code base was a lot of non fun. -.-6 -
Long time ago i ranted here, but i have to write this off my chest.
I'm , as some of you know, a "DevOps" guy, but mainly system infrastructure. I'm responsible for deploying a shitload of applications in regular intervals (2 weeks) manually through the pipeline. No CI/CD yet for the vast majority of applications (only 2 applications actually have CI/CD directly into production)
Today, was such a deployment day. We must ensure things like dns and load balancer configurations and tomcat setups and many many things that have to be "standard". And that last word (standard) is where it goes horribly wrong
Every webapp "should" have a decent health , info and status page according to an agreed format.. NOPE, some dev's just do their thing. When bringing the issue up to said dev the (surprisingly standard) answer is "it's always been like that, i'm not going to change". This is a problem for YEARS and nobody, especially "managers" don't take action whatsoever. This makes verification really troublesome.
But that is not the worst part, no no no.
the worst is THIS:
"git push -a origin master"
Oh yes, this is EVERYWHERE, up to the point that, when i said "enough" and protected the master branch of hieradata (puppet CfgMgmt, is a ENC) people lots their shits... Proper gitflow however is apparently something otherworldly.
After reading this back myself there is in fact a LOT more to tell but i already had enough. I'm gonna close down this rant and see what next week comes in.
There is a positive thing though. After next week, the new quarter starts, and i have the authority to change certain aspects... And then, heads WILL roll on the floor.1 -
Thoughts on forced emergency support?
I am with a company I generally like a lot but there are some things I generally despise about it. Like forced emergency support.
I am not good at it, I don't claim to be.. I generally struggle with anxiety, stress and depression, I specifically avoid roles that require on-call service .. I'm a senior level software engineer.
I find it very frustrating to be expected to be on-call from 7-7 in support of infrastructure I did not architect, did not code and basically know nothing about. They provided me with a ten minute discussion about ops genie and where to find internal support articles for my training and that's about it.
Last night I received an ops genie alarm and acked it as I was instructed to do, I went around the system looking for the alarm cause and basically had no idea what to do except watch our metrics graphing praying there wouldn't be an outage. Fortunately the alarm was for our load balancer scaling operation, it was taking a bit longer than usual ... Sigh of relief. Stay up til 6am and fall asleep..
Wake up to a few messages from various people asking why I didn't do this and that and it took me every inkling of my being to remain cordial and polite but I really just wanted to scream and say a bunch of shit that would probably get me fired.
What the actual fuck?
Why expect someone that has no god damn clue what they are doing to do something like this? Fuckin shit training and no leadership to mentor me and help me get better at this role, no shadowing, no regiment ..
#confused and #annoyed
Thoughts? Am I a bitch? Is it unreasonable for me to expect my job duties stay in line with what I'm actually good at!?
Thanks.12 -
So for a while I have wanted to build a raspberry pi cluster. In the spirit of shia labeouf I got started last saturday.
I had two pies lying around so I figured I'd run some experiments before I invested in a lot of hardware. After about a day I had turned the two pies into a shared cluster when disaster struck....
I had completely ignored the fact that you cannot run 32 or 64bit software on an arm processor (I know... I'm a java developer). So when I booted my service and the load balancer, I found that nothing worked. So pretty bumbed out, I quit the project.
Later that day I found a crazy guy who had bought a batch of 400 small form factor PSUs (300W) and internally I laughed at him a little. I mean, who's gonna sell 300W irregular power supplies. Then, just as I was about to go to bed I found this guy, he was selling from a batch of CPU-onboard motherboard for 10 bucks each and everything clicked!
I did some quick calculations and decided I could probably gather enough cash to get: 10 motherboards, 10 2GB ram dimms, 10 Sata disks and 14 PSU (in case some fail) and some misc hardware for networking and such.
So... Long story short, I am going to build a cluster computer, the first version is going to have 10 nodes and I am waiting for delivery right now!12 -
The system I'm developing is depending on an image generating application, that is generating thousands of unique images per day. The kicker? The application is a single thread wpf application hosted on two desktop computers, behind a load balancer, in our server room... because 'it can't be converted to a service'...1
-
It took AWS about a month to figure out why their load balancer was screwing up content length for requests from our site. Multiple times the ticket was closed due to inactivity because they took so long to investigate. Turns out there's a bug with how AWS load balancers scale, and when they are below a certain traffic threshold they truncate extremely long content. Their solution was to edit the balancer behind the scenes to always be scaled up, and then tell us to never delete it.
So then every time we needed to set up a staging environment we had to contact support so they'd edit the balancer. Which always took ages since most of the support agents didn't understand the convoluted issue and had to forward it on to more technically inclined staff, who then had to investigate fresh every time.
This was ridiculously annoying, so I spent months writing an automated solution to spin up staging new environments on the spot, this made use of a haproxy server which had to edit rules on the fly so that the AWS balancer could be circumnavigated. It was a better system then the old way anyway, but all the same an irritating issue to be forced to deal with.
All around a very shitty experience. This was a few years ago now and I'm not employed there any more, but I hope AWS fixed this since then.11 -
Today I learned that some external devs one of our projects is working with have DB tables where they store references to specific dates, and not only that, but every minute of those dates, and the day of the week, and what season its in. Im not joking.
Hmm should I use the local datetime libs or should I go through a firewall, load balancer and DB cluster just to find out what day it is? -
With a recent HAProxy update on our reverse proxy VM I decided to enable http/2, disable TLS 1.0 and drop support for non forward-secrecy ciphers.
Tested our sites in Chrome and Firefox, all was well, went to bed.
Next morning a medium-critical havock went loose. Our ERP system couldn't create tickets in our ticket system anymore, the ticket systems Outlook AddIn refused to connect, the mobile app we use to access our anti-spam appliance wouldn't connect although our internal blackboard app still connected over the same load balancer without any issues.
So i declared a 10min maintenance window and disabled HTTP/2, thinking that this was the culprit.
Nope. No dice.
Okay, i thought, enable TLS 1.0 again.
Suddenly the ticket system related stuff starts to work again.
So since both the ERP system and the AddIn run on .NET i dug through the .NET documentation and found out that for some fucking reason even in the newest .NET framework version (4.7.2) you have to explicitly enable TLS 1.1 and 1.2 or else you just get a 'socket reset' error. Why the fuck?!
Okay, now that i had the ticket system out of the way i enabled HTTP/2 and verified that everything still works.
It did, nice.
The anti-spam appliance app still did not work however, so i enabled one non-pfs cipher in the OpenSSL config and tested the app.
Behold, it worked.
I'm currently creating a ticket with them asking politely why the fuck their app has pfs-ciphers disabled.
And I thought disabling DEPRECEATED tech wouldn't be an issue... Wrong... -
So far? Not realizing my load balancer was not set up for sticky sessions... and since this load balancer only existed in prod not in qa or CAT o found out the night we went to install it into prod...1
-
Being a Tech Co-Founder is both boon and a bane.
Boon: You know how to build it.
Bane: You just start building without thinking.
We often crave I will be using Redis😍😍, Kafka, Load Balancer, Muti Layer Neural Net
"Dude", Whatever you are building does anyone want it or not. Tell me that first.1 -
How would you support multiple versions of an API and why?
- Multiple version instances behind a load balancer.
- Versioned controllers behind a proxy.
Curious to hear yours thoughts and reasoning.2 -
I have been working on IoT projects for last five years. After using MQTT in many of my projects I have realized that there is a huge learning curve for the beginners to understand and implement MQTT in their projects. The packet structure of MQTT is complex and MQTT packets are difficult to debug. Also customizing the open source MQTT brokers are also difficult for the beginners, and sometimes even for the experts.
To make IoT and Messaging simple, I am designing a new protocol which uses JSON packets for data exchange and is far less complex than MQTT. I am also developing an open source project which will contain a server (with load balancer support), a python client, a Javascript client and a python based load balancer. I hope this project will reduce the development time as the protocol is easy to understand and the open source code is fully modular & easy to customize.
This will be my very first contribution to the open source community. Wish me luck! -
Hey Guys
Today I'm bringing a tool for you guys, mount servers with old phones Or have servers in your phone for testing.
Tool: Servers Ultimate Pro
Web:: https://icecoldapps.com/app/...
Note1.: Doesn't handle well above android 6+, So test one of the free servers you're intending to use before buying.
Note2.: This App costs around 10€/$ but you can get single App servers for free (I think even html + php + mysql package for free).
Not promotional, I'm just a user that loves this App.
I already talked about this a few times (usually I just call the cell phone I'm using my web server), but as a noob I don't even knot the possibilities.
This App comes with more then 70 protocols (60+ servers and a mix of servers).
From ssh, ftp, html (nginx, lightppd, Apache, simple) with php and mysql, Webdav...
<quote>
Run over 60 servers with over 70 protocols!
Now you can run a CVS, DC Hub, DHCP, UPnP, DNS, Dynamic DNS, eDonkey, Email (POP3 / SMTP), FTP Proxy, FTP, FTPS, Flash Policy, Git, Gopher, HTTP Snoop, ICAP, IRC Bot, IRC, ISCSI, Icecast, LPD, Load Balancer, MQTT, Memcached, MongoDB, MySQL, NFS, NTP, NZB Client, Napster, PHP and Lighttpd, PXE, Port Forwarder, Proxy, RTMP, Remote Control, Rsync, SMB/CIFS, SMPP, SMS, Socks, SFTP, SSH, Server Monitor, Stomp, Styx, Syslog, TFTP, Telnet, Test, Time, Torrent Client, Torrent Tracker, Trigger, UPnP Port Mapper, VNC, Wake On Lan, Web, WebDAV, WebSocket, X11 and/or XMPP server!
</quote>7 -
This is a part rant-part question.
So a little backstory first:
I work in a small company (5 including me) which is mostly into consultation (we have many tech partners where we either resell their products or if there is a requirement from one of our clients, we get our partners to develop it for them and fulfill the client requirements) so as you can see there is a lot of external dependencies. I act as a one-hat-fits-all tech guy, handling the company websites, social media channels, technical documentation, tech support, quicks POCs (so anything to do with anything technical, I handle them). I am a bit fed up now, since the CEO expects me to do some absurd shit (and sometimes micro manages me, like WTF I am the only one who works there with 100% commitment) and expects me to deliver them by yesterday.
So anyway long story short, our CEO finally had the brains to understand that we should start having our own product (which i had been subtly suggesting him to do for a while now!).
Now he came up with a fairly workable concept that would have good market reach (i atleast give him credits for that) and he wanted me to suggest the best way to move forward (from a both business and technical point of view). The concept is to have an auction-based platform for users to buy everyday products.
I suggested we build a web app as opposed to a mobile one (which is obvious, since i didnt want to develop a seperate website and a mobile app, and anyway just because we can doesnt mean we have to make a mobile app for everything), and recommended the Node/react based JS tech stack to build it.
At first he wanted me to single handedly build the whole platform within a month, I almost flipped (but me being me) then somehow calmed down and finally was able to explain him how complicated it was to single-handedly build a platform of such complexity (especially given my limited experience; did I mention that this is my first job and I am still in college, yeah!!) and convinced him to get an experienced back-end dev and another dev to help me with it.
Now comes the problem, I was to prepare a scope document outlining all the business and technical requirements of the project along with a tentative cost, which was fairly straightforward. I am currently stuck at deciding the server requirements and the system architecture for the proposed solution (I am thinking of either going with AWS - which looks a bit complicated to setup - or go with either Digital Ocean or Heroku):
I have assumed that at peak times we would have around 500-1000 users concurrently
And a daily userbase of 1000 users (atleast for the first few months of the platform running)
What would be the best way forward guys?
I did some extensive (i mean i read through some medium blogs! and aws documentation) research and put together the following specs (if we are going through AWS):
One AWS t3.medium ec2 instance for the node server (two if we want High Availability by coupling with the AWS load balancer and Elastic Beanstalk)
The db.t3.small postgres database
The S3 Storage bucket (100gb) for the React Front end hosting
AWS SNS for email/sms OTP and notification
And AWS CloudMonitor for logging amd monitoring.
Am I speculating the requirements properly, where have I missed??
Can u guys suggest what is the best specification for such a requirement (how do you guys decide what plan to go with)?
Any suggestions, corrections, advices are welcome3 -
I have been working on IoT projects for last five years. After using MQTT in many of my projects I have realized that there is a huge learning curve for the beginners to understand and implement MQTT in their projects. The packet structure of MQTT is complex and MQTT packets are difficult to debug. Also customizing the open source MQTT brokers are also difficult for the beginners, and sometimes even for the experts.
To make IoT and Messaging simple, I am designing a new protocol which uses JSON packets for data exchange and is far less complex than MQTT. I am also developing an open source project which will contain a server (with load balancer support), a python client, a Javascript client and a python based load balancer. I hope this project will reduce the development time as the protocol is easy to understand and the open source code is fully modular & easy to customize.
This will be my very first contribution to the open source community. Wish me luck!3 -
How fucking sucking difficult is it too setup a static ip in AWS on a loadbalancer??? I spend the whole day figuring out how to use the nat gateway or other means and it still doesn't work. Debugging is almost impossible because they give you zero logs.
And all of this because a client wants to work with a whitelist for their shitty system on location.2 -
Technical question that I just cant find the answer to anywhere.
I have a load balancer and want it to pass the IP of the original caller to the server. Usually it is done by modifying the header? of the Request HTTP packet? and adding X-Forwarded-For: ....
The LB team though says it needs to modify X-Originating-IP and somehow causes a noticeable impact of the speed of all requests.
I don't know the details but it should only modify the first Packet that has the HTTP headers and should be appending X-Forwarded-For. If only need to modify the Header packet, how can it slow down the whole interaction so much:
-Adds 100ms to a 200ms request
-Increases a 10 minute download to like 20-30 minutes6 -
"Have you tried turning it off and back on again?"
There are days I miss being able to power cycle the load balancer, rather than tearing it down and re-creating it. -
What's the best service for managing large amounts of session data in Azure - servers are going behind a load balancer this week and we have too many options for storing session state4
-
Manual EC2 instances + Elastic load balancer or Elastic beanstalk for a PHP 7 application? I might have some cron jobs to be run too...
-
All banks in India continue to fail to handle such huge rush of customers.
They should have had a better load balancer, and some ddos protection. -
Trying to get a multi container setup using nginx (also in a docker container) to work with web sockets. There's a chance that the load balancer will also cause issues later. And the front end uses nuxt, which will probably also cause issues once we turn server side rendering on as well.
This is not really something I've studied deeply before.
I'm not having fun.1 -
Fuck me Amazon cert manager is so fucking complicated. Just do it all for me; why do i have to providing a route 53 entry (TECHNICALLY 2 IF I WANT MY NAME CORRECT) BEFORE I set up my load balancer??!! I should be able to test a load balancer first and then add on tls, not have to get a cert all set up and then sit on my fucking ass when the load balancer shits itself1
-
My load balancer with docker and redis database works fine bu5 I can’t access my web service. I get a “connection refused” error message.6


































Top Tags
Weekly Rant
View