
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
One of the many problems with AWS free tier is the obfuscation of expenditure by design. This is NOT OK.
 17
17 -
Worst collaboration experience story?
I was not directly involved, it was a Delphi -> C# conversion of our customer returns application.
The dev manager was out to prove waterfall was the only development methodology that could make convert the monolith app to a lean, multi-tier, enterprise-worthy application.
Starting out with a team of 7 (3 devs, 2 dbas, team mgr, and the dev department mgr), they spent around 3 months designing, meetings, and more meetings. Armed with 50+ page specification Word document (not counting the countless Visio workflow diagrams and Microsoft Project timeline/ghantt charts), the team was ready to start coding.
The database design, workflow, and UI design (using Visio), was well done/thought out, but problems started on day one.
- Team mgr and Dev mgr split up the 3 devs, 1 dev wrote the database access library tier, 1 wrote the service tier, the other dev wrote the UI (I'll add this was the dev's first experience with WPF).
- Per the specification, all the layers wouldn't be integrated until all of them met the standards (unit tested, free from errors from VS's code analyzer, etc)
- By the time the devs where ready to code, the DBAs were already tasked with other projects, so the Returns app was prioritized to "when we get around to it"
Fast forward 6 months later, all the devs were 'done' coding, having very little/no communication with one another, then the integration. The service and database layers assumed different design patterns and different database relationships and the UI layer required functionality neither layers anticipated (ex. multi-users and the service maintaining some sort of state between them).
Those issues took about a month to work out, then the app began beta testing with real end users. App didn't make it 10 minutes before users gave up. Numerous UI logic errors, runtime errors, and overall app stability. Because the UI was so bad, the dev mgr brought in one of the web developers (she was pretty good at UI design). You might guess how useful someone is being dropped in on complex project , months after-the-fact and being told "Fix it!".
Couple of months of UI re-design and many other changes, the app was ready for beta testing.
In the mean time, the company hired a new customer service manager. When he saw the application, he rejected the app because he re-designed the entire returns process to be more efficient. The application UI was written to the exact step-by-step old returns process with little/no deviation.
With a tremendous amount of push-back (TL;DR), the dev mgr promised to change the app, but only after it was deployed into production (using "we can fix it later" excuse).
Still plagued with numerous bugs, the app was finally deployed. In attempts to save face, there was a company-wide party to celebrate the 'death' of the "old Delphi returns app" and the birth of the new. Cake, drinks, certificates of achievements for the devs, etc.
By the end of the project, the devs hated each other. Finger pointing, petty squabbles, out-right "FU!"s across the cube walls, etc. All the team members were re-assigned to other teams to separate them, leaving a single new hire to fix all the issues.5 -
A BIG SHOUTOUT TO MY FRIEND @theKarlisK
He is the real MVP.
We both spent the weekend to setup OpenVPN + Pi-Hole on Oracle free tier.
He hand held me through the entire process, was super patient with my silly queries and in fact explained me everything so well that it got imprinted in my mind.
And ofc, he was super quick to debug and resolve issues and handed me all the commands for quick execution.
Super glad to have worked with him on this project.11 -
I wrote a node + vue web app that consumes bing api and lets you block specific hosts with a click, and I have some thoughts I need to post somewhere.
My main motivation for this it is that the search results I've been getting with the big search engines are lacking a lot of quality. The SEO situation right now is very complex but the bottom line is that there is a lot of white hat SEO abuse.
Commercial companies are fucking up the internet very hard. Search results have become way too profit oriented thus unneutral. Personal blogs are becoming very rare. Information is losing quality and sites are losing identity. The internet is consollidating.
So, I decided to write something to help me give this situation the middle finger.
I wrote this because I consider the ability to block specific sites a basic universal right. If you were ripped off by a website or you just don't like it, then you should be able to block said site from your search results. It's not rocket science.
Google used to have this feature integrated but they removed it in 2013. They also had an extension that did this client side, but they removed it in 2018 too. We're years past the time where Google forgot their "Don't be evil" motto.
AFAIK, the only search engine on earth that lets you block sites is millionshort.com, but if you block too many sites, the performance degrades. And the company that runs it is a for profit too.
There is a third party extension that blocks sites called uBlacklist. The problem is that it only works on google. I wrote my app so as to escape google's tracking clutches, ads and their annoying products showing up in between my results.
But aside uBlacklist does the same thing as my app, including the limitation that this isn't an actual search engine, it's just filtering search results after they are generated.
This is far from ideal because filter results before the results are generated would be much more preferred.
But developing a search engine is prohibitively expensive to both index and rank pages for a single person. Which is sad, but can't do much about it.
I'm also thinking of implementing the ability promote certain sites, the opposite to blocking, so these promoted sites would get more priority within the results.
I guess I would have to move the promoted sites between all pages I fetched to the first page/s, but client side.
But this is suboptimal compared to having actual access to the rank algorithm, where you could promote sites in a smarter way, but again, I can't build a search engine by myself.
I'm using mongo to cache the results, so with a click of a button I can retrieve the results of a previous query without hitting bing. So far a couple of queries don't seem to bring much performance or space issues.
On using bing: bing is basically the only realiable API option I could find that was hobby cost worthy. Most microsoft products are usually my last choice.
Bing is giving me a 7 day free trial of their search API until I register a CC. They offer a free tier, but I'm not sure if that's only for these 7 days. Otherwise, I'm gonna need to pay like 5$.
Paying or not, having to use a CC to use this software I wrote sucks balls.
So far the usage of this app has resulted in me becoming more critical of sites and finding sites of better quality. I think overall it helps me to become a better programmer, all the while having better protection of my privacy.
One not upside is that I'm the only one curating myself, whereas I could benefit from other people that I trust own block/promote lists.
I will git push it somewhere at some point, but it does require some more work:
I would want to add a docker-compose script to make it easy to start, and I didn't write any tests unfortunately (I did use eslint for both apps, though).
The performance is not excellent (the app has not experienced blocks so far, but it does make the coolers spin after a bit) because the algorithms I wrote were very POC.
But it took me some time to write it, and I need to catch some breath.
There are other more open efforts that seem to be more ethical, but they are usually hard to use or just incomplete.
commoncrawl.org is a free index of the web. one problem I found is that it doesn't seem to index everything (for example, it doesn't seem to index the blog of a friend I know that has been writing for years and is indexed by google).
it also requires knowledge on reading warc files, which will surely require some time investment to learn.
it also seems kinda slow for responses,
it is also generated only once a month, and I would still have little idea on how to implement a pagerank algorithm, let alone code it.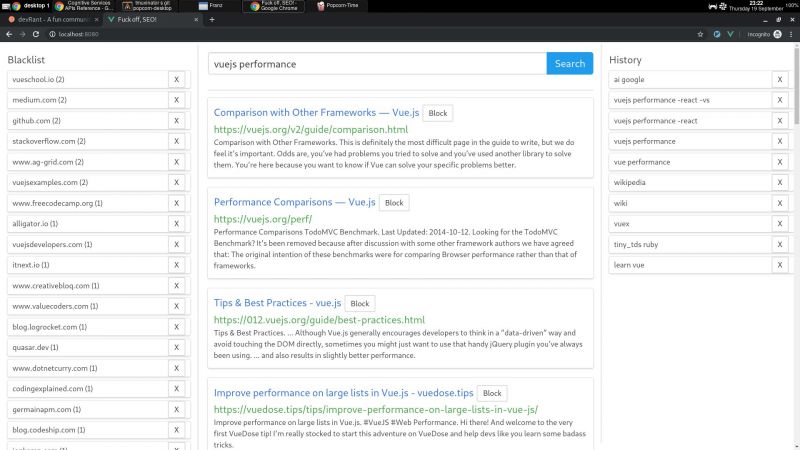 4
4 -
Sure Amazon, 0.02$/GB * 0.000120 GB = 0.01$, not 0.0000024$, sure, that's right.
0.05$ for what amounts to less than 2MB of data transfer in total (there's two more lines like that in the bill).
Eat a bag of dicks.
Free tier my ass, if I wanted to spend money I'd rather use Azure. 3
3 -
Woke up this morning to Amazon charging me over $100 bucks for the web services I used at my Hackathon last month. What the hell, I thought the free tier covered that?13
-
I am so fucking lost.
I literally have zero expectations from life for now and future.
There was a time when I had so much clarity in my life. Rather, I was known for it.
Folks used to reach me out for guidance and my approaches even worked for others.
I was goal oriented and biased towards action. Failing and learning from it, I used to make things happen and with constant feedback kept progressing.
While none of that has changed, I still feel lost and numb. No, I am not depressed or suffering through any mental illness. I am physical active and able to feel the happiness.
But the recent incident with a narcissistic, left me emotionally handicap. I can no longer feel any kind of love or affection. I overcame the damage done and healed myself.
But now, I am done. Even if I engage with anyone for a relationship it would be mostly for sex. I can care for people around me and be affectionate towards them but when it comes to an intimate relationship, I feel it's not something I can do in this lifetime. I tried multiple times but failed.
These days, all I am doing is putting my heads down and working like crazy. Never in my life I worked more than 10 hours in an entire week. Now, I work 10+ hours everyday. During that time, I am highly productive.
And in my free time, I am busy housekeeping different life problems. Either paying bills, figuring out an insurance, planning some investment, or making some kind of life decision.
It's draining me. I feel as if I am losing sanity. But that's the only thing I am able to do.
Maybe it's the lockdown effect. Maybe some damage is yet to be healed.
But I got nothing better to do. I have some good ideas. Not those hipster-ish disruptive Million dollar ideas, but decent enough to solve a problem for a strong use case.
However, all of this is becoming overwhelming these days. Because decision making is complex and difficult task. It can make or break the future.
As of now I am confused how should I go about pursuing two of the important projects that I want to accomplish.
1. Migrating out of Google ecosystem. Is it even practically possible for my use case? What are the alternatives? Planning to opt in for a paid cloud storage so have to factor in that aspect as well.
I want to keep this new setup only for official use like bank and government stuff. Maybe family and close friends. Then have current ids for public logins and sharing it with retards whom I can block or ignore if they harass me. The research is overwhelming but having a structured setup gives insane amount of efficiency when life is spam free.
2. Migrating my Pihole and OpenVPN setup out of Digital Ocean to GCP. Primarily because $5 is a lot of amount for my computational requirements and Google has used my data enough, for me to use the free tier.
However, there isn't a simple script for a tech noob like me, to go ahead and setup something. I did find a Github repository but the documentation is kind of outdated so RTFM failed for me.
I don't know whether to pursue my start-up or let it go and focus on moving to Europe.
It's just so fucking stupid to even exist. And let's not forget taxes. Bloody taxes.16 -
How to make those marketing staff of x service stop sending you an email when they don't have unsubscribe link:
1. Reply back asking about the free tier/plan
2. Profit!
2 days and no word from them after spamming me daily about the service3 -
I'm so used to rss right now, I figured I would create a rss feed for top feeds from devrant.
Here's the unofficial devrant rss feed (based off Skayo's unofficial devRant api):
https://devrantrss.herokuapp.com/ge...
Just add this link to your rss reader (I'm using feedly) and it should be recognized instantly. Each feed will have the name of the ranter, rant, image, tags and user profile. I'm running this in free tier of Heroku. Feel free to use it.
You can find the source code here: https://github.com/Ullas-Aithal/...
It's a Node.JS script. There's a herokuBuild branch which it's heroku ready.
What do you guys think? Any comments, suggestions? 7
7 -
Google cloud platform.
1. Great documentation and support
2. Good free tier & dev freebies
3. Cloud console + SDK rock
4. Did I mention the great documentation?
5. Seriously the documentation ❤ -
"Fauna's free plan has been adjusted from 5GB to 1GB going forward"
huh? I thought "tech was eating the world" "cloud is everything" "things are getting more efficient"
so why the hell do all these cloud providers keep DECREASING the free tier. annoying as all hell
where's all the storage and compute going? fucking crypto?
each day the 🤡🌎🎪 grows stronger 13
13 -
A brilliant oldtimer auto-mechanic asked me to get Audi MMI and maps update for him from the internet. For the Christmas, you know..
So I found the source (mega.nz). It's 22.3GB.
Spent a whole day downloading it (5GB download allowed in 6 hours for free tier), downloaded 21.15GB and some fucked up error appeared "Your In-Browser Storage for Mega is Full".
Couldn't work out the reason nor the fix to recover and complete the already downloaded data. Had to redo it all.
Whole day wasted
damn it5 -
Oh dear! Knew this email from Heroku was going to come saying I'm approaching by limit for the free Postgres database...Guess I'll have to start trying to monetize this website to pay for the next tier 😅2
-
Why in fuck's sake would you create a new service and not offer TLS/SSL to your free tier clients ?9
-
Zoom free tier calls end after 40 minutes.
Idea: pwyw conference software where the call ends after 40 minutes if the host isn't paying €5 more monthly than everyone else in the call. There is no way to discover whether this is a limited call until the 40 minute mark, and there's no way to discover who outbid the host at all except by getting everyone to show their bank statement.1 -
I did something potentially extremely stupid today
In 2020 when I was a teenager I suggested my uncle who ran a family business with my father to start a e commerce website. I did lot of stupid stuff doing this too. Planned to use AWS free tier to host the website and used Godaddy for domains IIRC. Setup godaddy email forwarding to his gmail account too IIRC
I registered a AWS account with my email(bad idea since my uncle's debit card was the payment method). I then setup a EC2 instance but instead of using the free instance I used some other instance because I didn't read what instance was free and setup his debit card as the payment method.
Setup woocommerce on it and pointed the domain to instance's static IP. We didn't do a lot of stuff on the website but next month on AWS we got a bill but it was a small amount. Uncle paid the bill and I terminated the EC2 instance IIRC. Next month there was a very small bill I don't remember what I did after it.
Today I remembered about it logged in to AWS and paid the bill. The problem is I used the default billing address which is in my uncle's name and the address of the family business. IIRC we didn't give them tax details of the business so we can't claim tax credit on it.
But still since there is a bill with the address of the business which Amazon probably reported to the government there could be tax discrepancies. Bill was due 4 years ago so maybe it will affect his 2020 returns which could be painful. The bill was also paid by me not from my Uncle's account so that might complicate things.
Thankfully the surprise AWS bill had basically zero affect on my relationship with my uncle.3 -
Running NPM install on an average size project on a free tier Cloud9 instance.
Didn't go too well kept hitting memory limit which killed the NPM process.
Upgrade it is..
-
Recently had to start developing on a PLC for a new project and didn’t realize how much these companies fuck their developers.
For example, I’m using CODESYS to write structured text to run on the PLC. CODESYS is free to download. However, in the free tier, they take all your .st files and ur config files and combine them into a SINGLE FUCKING BINARY which completely defeats the purpose of version control.
However, if you BUY their pro license, you can install a git module.
There’s other things that make developing in them suck. For example, the only IDE you can use is the one built into CODESYS and it fucking sucks. Another one is that their builtin IDE has a “dark mode” that only works on certain files. If you open a function file, it uses dark mode. But if you open a struct file, it uses light mode.
Also, having no other runtime than the one built into CODESYS fucking sucks.
Maybe I’ve been spoiled with VSCode and python 🤷♂️3 -
Wow, I'm so glad that my Discord bot I played around with last year fits within AWS's free tier, because I totally forgot it existed. I only used it to test some things and then never touched it again.
Just rediscovered its existence when I was thinking about building a new bot, lol. -
I had to recreate my Revolut account this christmas, and now I created a Wise account too. Two more years of AWS free tier and GCP demo credits.2
-
Well,
I went ahead and tested t2.micro and lambda+dynamo(free tier)
You definitely get better performance and load handing with lambda+dynamo (5rcu+5wcu)
Tested the two with wrk and a simple GET which reads an item from a database of 90k items.
I could share more details with you if youre interested, but with 2000 requests, 100 connections and 4 threads. I got about 26requests/s on ec2 and about 260r/s on lambda.
Latency for ec2 was about 28s.
Latency for lambda was about 22s.
(max load)6 -
The purpose of AWS free tier is to trick people into attempting to stay within its completely unmarked limits. It's like trying to hunt for mushrrooms in a forest split with a hostile country based on a verbal definition of where the border lies with border control waiting to ambush tourists for ransom money.6
-
I love ClickUp. The closest to all in one tool. I compared similar tools but i still keep coming back to ClickUp. Even their Free Tier is amazing!2
-
Travis CI is so expensive for smaller developers.
I started using it when it was free for open source projects, but now they changed it, and the lowest tier ever is $69.
Don't get me wrong, it's an amazing service, which works exactly as described, but I only need to make like 5 builds a month, but the lowest tier gives me so much more allowance.
I wish they had a cheaper tier for less money. Now I gotta swap service and reconfigure a couple of projects.2 -
I'd really love to try my hands on some of these devOps tools, it's a very interesting part of development that has always caught my attention
currently planning on trying out AWS free tier
so many stuffs I really want to learn
one after the other, it's just been a year, a lot more to go -
This might be a weird one or something that you're not supposed to do
I have a domain which I bought because it was very cheap, I have an old pc which I use as a server and I have to servers on the Oracle Cloud free tier
Now the actual question
Without shelling for a managed dns (which would be more per month than I'm paying for the domain per year), is there a way that I can self-host from my server and then use the Oracle Cloud servers as fallback/failover?
All 3 machines are Ubuntu 18.04 using Apache HTTPD, if that helps2 -
Mighty Hacker Recovery: The Best in Crypto and Investment Fund Recovery
Mighty Hacker Recovery is the real deal.
I want to share my incredible experience with **Mighty Hacker Recovery**, the best expert in crypto and investment fraud recovery. After falling victim to a fake investment company in France. It was a nightmare losing **$76,000**, thinking it was gone forever. But thanks to **Mighty Hacker Recovery**, I got back every single dollar!
Their expertise in recovering lost investments, **USDT wallets, crypto transactions sent to the wrong address**, and stolen funds is unmatched. They don't just make empty promises—they **deliver real results** for sure.. Their process is fast, secure, and professional, ensuring that victims of crypto fraud can reclaim their hard-earned money.
I’m beyond grateful to have found them, and I know many others have benefited from their top-tier services. If you've lost funds to scams, hackers, or wrong transactions, don’t hesitate—**Mighty Hacker Recovery** is your best shot at getting your money back.
**Contact them now at WhatsApp +1 (404) 245-6415** and take back what’s rightfully yours!
11 Freelance Crypto Experts For Hire
Hire the best cryptocurrency experts
Hire a Cryptocurrency Expert Online
Find Top Cryptocurrency Experts for Hire in February 2025
Who is the most trusted crypto expert?
How much does a crypto consultant cost?
Can I hire someone to do crypto for me?
Who gives the best crypto advice?
Hire the best crypto expert free
Hire professional crypto trader
Top crypto experts near me
Crypto trading experts review
Bitcoin expert near me
Expert Crypto Trader legit
Free crypto experts near me
Talk to a crypto expert
How to recover lost cryptocurrency—and how to keep it safe
How to backup and restore a crypto wallet
Are Your Lost Bitcoins Gone Forever?
How To Find Lost Bitcoins:
Restore my wallet Bitcoin Support Center
How to recover my bitcoin wallet
How to recover my bitcoin app
Recover Bitcoin wallet without phrase
Find my Bitcoin account
Find Bitcoin wallet by email
How to recover Bitcoin from blockchain
Recover Bitcoin wallet 12 words
Unclaimed Bitcoin wallets
How to recover a crypto wallet with or without a seed phrase
How To Recover My Lost Bitcoin Wallet?
How could you recover your Bitcoin if it was not possible to
Forgot or Lost Bitcoin Wallet Password? How to Recover in 2025
Wallet gone and lost recovery phrase, how to get back my bitcoin back
1. Bitcoin (BTC)
2. Ethereum (ETH)
3. Tether (USDT)
4. USD Coin (USDC)
5. BNB (BNB)
6. Binance Coin USD (BUSD)
7. XRP (XRP)
8. Cardano (ADA)
9. Solana (SOL)
10. Dogecoin (DOGE)
11. Polkadot (DOT)
12. Dai (DAI)
13. Polygon (MATIC)
14. Shiba Inu (SHIB)
15. TRON (TRX)
16. Avalanche (AVAX)
17. UNUS SED LEO (LEO)
18. Litecoin (LTC)
19. Stellar (XLM)
20. Bitcoin Cash (BCH)
Crypto For Merchants
Quick FAQs about the most popular Cryptocurrencies
Q: What are Cryptocurrencies?
Q: Is An Altcoin Different From a Cryptocurrency?
Q: What are Cryptocurrencies Used For?
Q: Are Cryptocurrencies Regulated?
Q: What is the difference between Bitcoin and Ethereum?
Q: What are stablecoins?
Q: What is the purpose of Tether (USDT)?
Q: What is Litecoin (LTC)?
Q: What is Bitcoin Cash (BCH)? 1
1 -
Got an email “Welcome to Amazon Web Services” to an old GMail account I no longer use. Seems genuine with no links to shady websites or anything. Does Amazon not verify email addresses or how does that happen?
Also, the mail says I have now 12 months of free tier access, so will they start billing me instead of the random fuck who signed up with my email address?3 -
I now know why Google Clouds sucks compared to AWS, and Azure.
1. No free tier
2. Pricing is confusing and designed for comp scis
3. Too componentized.
I wanted to translate text in an image like Google Translate/Lens.
Google: after a long search of the site's developer docs, I need the Translate and Vision APIs which have separate pricing specified in hours and task type
Microsoft: search Translate API,
Does images, first 5 million characters are free8 -
If I only have 5000 page views my free tier commenting service allows. Is it necessary to let users know. Or is it alright for them to find out when they can't comment on my horrible site anymore until next month5
-
Ok so, i have no idea where i can ask this kinda thing so i'm asking it here (i know i could do like stackexchange or dead aws discord servers, ... nvm you know why i'm not going that route).
Anyways,
I'm looking for a comparison between a mongo+node setup on a basic t1.micro instance and a lambda+dynamodb setup.
Each one has it's perks obviously but i guess i sorta prefer whichever one gives best performance on the free tier.
I do know dynamo has 25 reads and 25 writes a second on the free tier, which might be a little less ? I really have no clue.
But how many writes/reads would a basic mongo setup be able to achieve on the t1.micro instance ? Any idea? Do share your experiences with these architectures as well. I'm sort of a newb with serverless, the downsides aren't worth it for me but I'm learning it nevertheless. It sorta tickles some sort of self-torture curiosity fetish (need more self-research to back that).10 -
MAD Pizza: Serving Delicious, High-Quality Pizza in Waterloo, ON
If you're craving mouthwatering pizza made with fresh ingredients, look no further than MAD Pizza. Located at 572 King St N, Waterloo, ON N2L 6L3, Canada, MAD Pizza is your go-to destination for pizza that will satisfy your cravings and leave you coming back for more. Whether you're planning a casual dinner, hosting a party, or simply enjoying a meal with friends and family, we offer an array of pizza options that are sure to delight.
A Slice Above the Rest
At MAD Pizza, we pride ourselves on delivering the highest quality pizzas. Our dough is made fresh daily, ensuring a perfect base for every pizza. We use only the finest ingredients, from savory sauces to the freshest vegetables and top-tier meats. Whether you like a classic margherita, a loaded supreme, or something more unique, our pizza menu offers a variety of delicious options for all tastes.
Why Choose MAD Pizza?
Quality Ingredients – We believe that great pizza starts with great ingredients. That's why we handpick the freshest toppings, from locally sourced vegetables to premium cheeses and meats. Every bite of our pizza is packed with flavor and quality.
Variety for Everyone – At MAD Pizza, we offer a wide selection of pizza options to suit every taste and dietary preference. From traditional favorites to inventive creations, there's a pizza for everyone. Don't forget to ask about our vegetarian, gluten-free, and vegan options!
Convenient Location – Situated conveniently at 572 King St N, Waterloo, our pizza shop is easily accessible for locals and visitors alike. Whether you're grabbing a pizza on your way home or enjoying a meal at our cozy spot, we're here to serve you.
Great Customer Service – Our team is passionate about providing excellent customer service. We're here to ensure you have a great experience, whether you're ordering online, calling in, or dining with us in person.
Perfect for Any Occasion
Whether you're planning a fun family dinner, a late-night snack, or catering an event, MAD Pizza is the perfect choice. We offer both takeout and delivery, so you can enjoy our delicious pizzas wherever you are. And if you're in the area, stop by and enjoy a fresh, hot pizza in our welcoming restaurant.
Get in Touch
Ready to indulge in the best pizza in Waterloo? Give us a call at +1 (548) 889-5647 or stop by our location at 572 King St N. If you're looking to make an order online or learn more about our menu, we are happy to help.
For the best pizza experience in Waterloo, choose MAD Pizza – where great taste and quality meet.
Visit Us Today!
Address:
572 King St N,
Waterloo, ON N2L 6L3,
Canada
Contact Number:
+1 (548) 889-5647
Enjoy delicious, high-quality pizza at MAD Pizza today! 3
3 -
Rank Business Institute: Your Ultimate Digital Marketing Institute
In today’s fast-paced digital world, businesses must stay ahead of the curve to maintain a competitive edge. One of the most effective ways to ensure success in this ever-evolving landscape is through the power of digital marketing. At Rank Business Institute, we provide the tools, knowledge, and hands-on experience necessary to thrive in the digital marketing space.
Located at First Floor, Haware Fantasia Business Park, Corporate Wing, F-188, Sector 30A, Vashi, Navi Mumbai, Maharashtra 400705, Rank Business Institute is dedicated to providing top-tier digital marketing training to individuals and businesses alike. Our expert-led programs cater to beginners, professionals, and entrepreneurs who want to harness the potential of digital marketing strategies to grow their businesses and careers.
Why Choose Rank Business Institute for Digital Marketing Training?
Comprehensive Curriculum
At Rank Business Institute, our curriculum is designed to cover every aspect of digital marketing, from search engine optimization (SEO) and content marketing to social media marketing and paid advertising. Whether you're looking to enhance your skills or start from scratch, we provide a comprehensive, easy-to-understand approach.
Experienced Trainers
Our trainers are seasoned industry experts with years of experience. They bring real-world insights, actionable strategies, and the latest trends in digital marketing, ensuring that our students receive the most up-to-date and relevant education.
Hands-On Training
We believe in learning by doing. Our training programs focus on practical knowledge and real-life applications, giving you the confidence to implement digital marketing techniques immediately. You'll work on live projects, case studies, and simulations to gain invaluable experience.
Flexible Learning Options
We understand that every student has unique learning needs, which is why we offer flexible learning options. Whether you prefer classroom training, online sessions, or a hybrid model, we have a solution to fit your schedule and learning style.
Industry-Recognized Certifications
Upon successful completion of our courses, you will receive certification that is recognized by industry leaders and employers. This certification can help boost your career prospects, whether you're looking to land your first digital marketing job or advance your current position.
Networking Opportunities
As a part of our digital marketing training, students also get opportunities to connect with industry professionals, potential clients, and fellow students. This networking can open doors to collaborations, job opportunities, and valuable industry insights.
Courses Offered at Rank Business Institute
We offer a range of courses designed to meet the needs of various skill levels:
Digital Marketing Fundamentals
A beginner-friendly course that covers the basics of digital marketing, including SEO, SEM, and social media marketing.
Advanced Digital Marketing
For those looking to dive deeper into specific areas, such as advanced SEO techniques, email marketing, or Google Analytics.
Social Media Marketing
Focuses on leveraging platforms like Facebook, Instagram, Twitter, and LinkedIn to drive engagement and sales.
SEO & SEM (Search Engine Optimization and Search Engine Marketing)
Learn how to optimize websites and run effective PPC campaigns to rank higher on search engines and attract more traffic.
Content Marketing
Discover how to create, distribute, and optimize content that attracts and retains customers.
Affiliate Marketing
Explore the world of affiliate marketing, a lucrative model where you can earn by promoting other businesses’ products and services.
How to Get Started with Rank Business Institute
Getting started is simple. Just give us a call at +09082234835 or visit us at our Vashi location to learn more about our programs and schedule a consultation. Whether you are looking to improve your business’s online presence or kickstart a career in digital marketing, Rank Business Institute is the place to start.
Conclusion
In the competitive digital landscape, a strong digital marketing strategy is key to success. By enrolling at Rank Business Institute, you will gain the skills, tools, and expertise needed to make an impact in the world of digital marketing. Join us today and take the first step towards a brighter future in digital marketing.
If you have any questions or would like to know more, feel free to reach out at +09082234835. Let’s grow together! 1
1 -
Wolli Creek Property Management: Your Trusted Partner in Property Management
At Slick Property Management, we specialize in offering top-tier Wolli Creek property management services designed to help property owners, investors, and tenants achieve their goals with ease and efficiency. Located at Unit 120/95 Bonar St, Wolli Creek NSW 2205, Australia, our expert team is dedicated to delivering comprehensive and personalized property management solutions tailored to the unique needs of the Wolli Creek area and beyond.
Wolli Creek is one of Sydney's most rapidly growing suburbs, attracting both residential and commercial tenants due to its convenient location, modern infrastructure, and close proximity to the CBD, the airport, and key amenities. With an in-depth knowledge of the local market, Slick Property Management offers expert services that help property owners maximize returns, ensure tenant satisfaction, and protect the value of their investments.
Why Choose Slick Property Management for Wolli Creek Property Management?
Local Expertise in Wolli Creek
As a property management company based in Wolli Creek, we have an intimate understanding of the local area and the specific requirements of managing properties in this rapidly evolving suburb. Whether your property is residential, commercial, or a mix of both, we know the ins and outs of Wolli Creek’s real estate market, including rental trends, tenant demands, and property values. This local expertise allows us to provide strategic advice and management solutions that are tailored to your needs.
Comprehensive Property Management Services
At Slick Property Management, we offer a complete range of services to make managing your property simple and stress-free. Our Wolli Creek property management services include:
Tenant Placement & Leasing: We help you attract reliable, high-quality tenants through effective marketing, comprehensive screening, and competitive leasing terms. Our tenant placement process is designed to ensure you get the best fit for your property.
Rent Collection & Financial Reporting: Our team handles the collection of rent and ensures timely payments. We also provide detailed financial reporting, giving you complete visibility of your property's income and expenses.
Maintenance & Repairs: We handle all property maintenance, from regular inspections to emergency repairs, ensuring your property remains in excellent condition and tenants are satisfied.
Lease Renewals & Rent Reviews: We proactively manage lease renewals and conduct periodic rent reviews to ensure that your property remains competitive in the market while maximizing your rental income.
Legal Compliance: We stay updated on the latest property laws and regulations, ensuring your property complies with all necessary legal requirements and is protected from potential risks.
Tailored Solutions for Your Property
Every property is unique, and at Slick Property Management, we offer tailored management solutions that fit the specific needs of your investment. Whether you own an apartment, house, or commercial property in Wolli Creek, we provide personalized services designed to protect and grow your property’s value. We work closely with each client to develop a management strategy that aligns with their investment goals.
Expert Marketing & Tenant Acquisition
To ensure your property is always leased to the best tenants, we use a multi-channel approach to property marketing. Our marketing strategy includes listing your property on all major real estate platforms, professional photography, virtual tours, and targeted advertising. We also leverage our extensive local network to reach potential tenants who are actively looking for properties in Wolli Creek.
Efficient Communication & Support
At Slick Property Management, we believe in maintaining open and transparent communication with our clients. Whether you have a question about rent collection, maintenance issues, or lease renewals, our team is always available to provide prompt, professional responses. We ensure you’re never left in the dark about the status of your property.
Maximizing Rental Returns
Our team is dedicated to helping you get the most out of your Wolli Creek property. We offer strategic advice on market pricing, property upgrades, and ways to increase rental income. Whether it's performing regular market reviews or suggesting maintenance improvements to make your property more appealing, we are committed to optimizing your rental returns. 9
9 -
Boujee Mobile Pet Grooming: Miami's Leading Mobile Grooming Specialists
At Boujee Mobile Pet Grooming, we are proud to be the Miami mobile grooming specialists that pet owners trust for all their grooming needs. Our professional grooming services are designed to make your pet look and feel their best—right from the comfort of your home. Whether you’re looking for a quick wash or a complete grooming session, we bring top-tier grooming services directly to your door. Serving Hialeah and surrounding areas, we are the go-to mobile pet grooming near me solution in Miami, FL.
Why Choose Boujee Mobile Pet Grooming?
When you search for mobile pet grooming near me in Miami, you want a service that’s convenient, affordable, and, most importantly, safe for your beloved pets. Here’s why Boujee Mobile Pet Grooming stands out as the best choice for Miami pet owners:
1. Convenient and Stress-Free Mobile Grooming in Miami
One of the greatest benefits of choosing Miami mobile grooming specialists like us is the sheer convenience. No need to drive to a grooming salon, wait in line, or deal with your pet’s anxiety from traveling. With our mobile pet grooming near me service, we bring the grooming salon to your doorstep, making the entire experience stress-free for both you and your pet.
Save Time and Effort: We offer flexible scheduling options that work around your busy life, ensuring that your pet gets the care they need without you having to leave your home.
Comfort for Your Pet: Many pets experience stress at traditional grooming salons. Our mobile grooming service eliminates this issue, as your pet can stay in a familiar, calming environment.
Personalized Attention: In our mobile grooming van, your pet receives one-on-one attention, ensuring that they’re never rushed or distracted during their grooming session.
2. Professional Miami Mobile Grooming Specialists
As Miami mobile grooming specialists, we are committed to providing exceptional care for your pets. Our team is experienced in handling pets of all sizes and breeds, ensuring your dog, cat, or other furry companion is groomed to perfection. From bath time to nail trimming, here are some of the grooming services we offer:
Full Grooming Services: Including bathing, haircuts, and trimming to ensure your pet looks great and feels comfortable.
De-shedding: For pets that shed excessively, we offer de-shedding treatments that reduce shedding and make your pet's coat more manageable.
Nail Clipping: Regular nail trimming is essential for your pet’s health, and we make sure to trim their nails safely.
Ear Cleaning: We carefully clean your pet’s ears to prevent infections and ensure their overall well-being.
Facial Cleaning and Eye Care: Our groomers ensure your pet’s face and eyes are properly cleaned, minimizing irritation and promoting hygiene.
3. Safe and High-Quality Grooming Products
At Boujee Mobile Pet Grooming, we use only safe, pet-friendly grooming products to ensure that your pet’s skin and coat are treated with the utmost care. We understand that pets have sensitive skin, which is why we choose high-quality shampoos, conditioners, and tools designed to protect their health while giving them the best grooming experience possible.
Miami’s Most Trusted Mobile Grooming Near Me Service
As a trusted mobile pet grooming near me provider, Boujee Mobile Pet Grooming serves not just Miami, but also Hialeah and neighboring communities. Whether you need regular grooming services or an occasional touch-up, we are here to provide a reliable and high-quality grooming experience for your pets.
Why Trust Boujee Mobile Pet Grooming for Your Pets?
Experienced Groomers: Our groomers are highly trained and skilled in providing top-notch grooming services for all types of pets.
Stress-Free Experience: We make grooming a pleasant experience for your pet by offering a quiet, safe, and familiar environment.
Affordable and Convenient: With our flexible scheduling, affordable pricing, and professional grooming services, we offer the best value for your money.
Book Your Appointment Today
If you're searching for mobile pet grooming near me or need Miami mobile grooming specialists, Boujee Mobile Pet Grooming is here to help. We provide grooming services for dogs, cats, and other pets, ensuring they are pampered and well-cared for. Call us at +1 305-522-2013 to schedule your next grooming session and experience the convenience and quality that only Boujee Mobile Pet Grooming can offer. 1
1 -
(sort of rant but not totally)
so I am using Directus for headless cms and I'm always looking around for other options such as Contentful, but the problem with Contentful is that it is hella expensive in my opinion (249$/month at least after you exceed the free tier with limited capabilities)
So the real question is, do you guys know of any other Headless CMS? -
KAM Roofing and Restoration: Leading Roofing Experts in Olathe, KS, and Surrounding Areas
At KAM Roofing and Restoration, we pride ourselves on offering top-tier roofing solutions to both residential and commercial property owners across the Kansas City metro area. Located at 2012 E Prairie Cir B, Olathe, KS 66062, our team of experts provides high-quality roof installations, repairs, and restorations to ensure that your property is protected, no matter the season. With extensive experience and a commitment to customer satisfaction, we are the trusted name in the roofing industry.
Commercial Roof Installation in Lenexa, KS
When it comes to commercial properties, the roof is one of the most crucial aspects to protect your investment and ensure business continuity. At KAM Roofing and Restoration, we specialize in commercial roof installation in Lenexa, KS. Whether you're building a new commercial space or need a roof replacement for an existing property, our team is equipped to handle every aspect of your roofing project with precision.
We work with a variety of durable materials suitable for commercial buildings, including TPO, EPDM, and modified bitumen, designed to withstand the harsh Kansas weather. Our expert team ensures every installation meets the highest standards, offering reliable and long-lasting protection for your business. From initial consultation to project completion, we ensure that every step is executed with care and professionalism.
Metal Roof Contractor in Shawnee, KS
When it comes to durability, energy efficiency, and style, metal roofs stand out as one of the best options available. If you're looking for a metal roof contractor in Shawnee, KS, KAM Roofing and Restoration has you covered. Our skilled team specializes in the installation and maintenance of metal roofs that provide exceptional strength and long-term value to your home or business.
Metal roofing offers many advantages, including superior durability, minimal maintenance, and energy efficiency. Whether you're interested in a standing seam metal roof, corrugated metal, or another style, we provide expert advice on the best solution for your needs. As a trusted metal roof contractor in Shawnee, KS, we ensure that your new roof not only meets your aesthetic preferences but also stands up to the harsh Kansas weather for many years to come.
Flat Roof Repair in Prairie Village, KS
Flat roofs can be a fantastic option for both residential and commercial properties, but they do require regular maintenance to prevent leaks and other issues. If you need flat roof repair in Prairie Village, KS, KAM Roofing and Restoration is here to help. We specialize in repairing flat roofs of all types, including TPO, EPDM, and modified bitumen systems, and our team is trained to quickly identify and address any damage.
From small leaks to significant wear and tear, we offer comprehensive flat roof repair services that restore your roof’s function and longevity. We understand the unique challenges flat roofs present, such as water pooling and drainage issues, and we have the experience to solve these problems efficiently. With our expert services, you can trust that your flat roof will continue to protect your property for years to come.
Why Choose KAM Roofing and Restoration?
Expertise You Can Trust: Our team has years of experience in roofing and restoration, providing exceptional results on every project.
Comprehensive Roofing Services: From commercial roof installations to metal roofing and flat roof repairs, we offer a full range of roofing solutions for homes and businesses alike.
Affordable Pricing: We provide competitive pricing without sacrificing quality, ensuring you get the best value for your investment.
Customer-Focused Service: At KAM Roofing and Restoration, customer satisfaction is our top priority. We work closely with each client to understand their needs and deliver a roofing solution tailored to them.
Licensed and Insured: We are a fully licensed and insured roofing company, giving you peace of mind that your property is in safe hands.
Contact KAM Roofing and Restoration Today
For high-quality roofing services in Olathe, Lenexa, Shawnee, Prairie Village, and surrounding areas, KAM Roofing and Restoration is your trusted partner. Whether you need a commercial roof installation, a metal roof contractor, or flat roof repairs, our team is ready to assist you.
Call us today at +1 (913) 283-7799 to schedule a consultation or request a free estimate. Let us protect your property with the best roofing solutions available!
Choose KAM Roofing and Restoration for all your roofing needs in the Kansas City area, and experience the difference of working with professionals who care about the safety and longevity of your roof. 1
1





























Top Tags
Weekly Rant
View