
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
TOP 10 PROGRAMMING BEST PRACTICES
#1 Start numbering from 0.
#10 Sort elements in lexicographic order for readability.
#2 Use consistent indentation.
#3 use Consistent Casing.
#4.000000000000001 Use floating-point arithmetic only where necessary.
#5 Not avoiding double negations is not smart.
#6 Not recommended is Yoda style.
#7 See rule #7.
#8 Avoid deadlocks.
#9 ISO-8859 is passé - Use UTF-8 if you ▯ Unicode.
#A Prefer base 10 for human-readable messages.
#10 See rule #7.
#10 Don't repeat yourself.12 -
The story of the $500,000,000 error.
In 1996, an unmanned Ariane 5 model rocket was launched by the European Space Agency.
Onboard was software written to analyze the horizontal velocity of the spacecraft. A conversion between a 64-bit floating point value and a 16-bit signed integer within this software ultimately caused an overflow error just forty seconds after launch, leading to a catastrophic failure of the spacecraft.
That day, $7 billion of development met it's match: a data type conversion.12 -
Second semester
Java - OOP Course
We had to write a game, an arkanoid clone
Neat shit
And a fun course, mad respect to the Prof.
BUT
Most students, including me had this ONE bug where the ball would randomly go out of the wall boundaries for no clear reason.
A month passed, sleepless nights, no traces.
Two months later. Same shit. Grades going down (HW grades) because it became more and more common, yet impossible to track down.
3 months later, we had to submit the HW for the last time which included features like custom level sets, custom blocks and custom layouts.
So before we submit the game for review, they had pre-defined level sets that we had to include for testing sake.
I loaded that.
The bug is back.
But
REPRODUCIBLE.
OMG.
So I started setting up breakpoints.
And guess what the issue was.
FLOATING FUCKING POINT NUMBERS
(Basically the calculations were not as expected)
Changing to Ints did it's job and the bug was officially terminated.
Most satisfying night yet.
Always check your float number calculations as it's never always what you expect.
Lesson learned, use Ints whenever possible.18 -
Try not to use floating point numbers in places where precision is important. Like for instance, money. Always store the base value where it makes the most sense
 15
15 -
There are only 1.9999999999999998 types of devs in the world: those who understand floating point arithmetic, and those who use it.4
-
Recently buyed some toilet paper.
Now i just want to have an intense discussion about floating point precision with the idiot who developed the cutting machine...
Also, please stop printing cars or birds there. Thanks. 3
3 -
POSTMORTEM
"4096 bit ~ 96 hours is what he said.
IDK why, but when he took the challenge, he posted that it'd take 36 hours"
As @cbsa wrote, and nitwhiz wrote "but the statement was that op's i3 did it in 11 hours. So there must be a result already, which can be verified?"
I added time because I was in the middle of a port involving ArbFloat so I could get arbitrary precision. I had a crude desmos graph doing projections on what I'd already factored in order to get an idea of how long it'd take to do larger
bit lengths
@p100sch speculated on the walked back time, and overstating the rig capabilities. Instead I spent a lot of time trying to get it 'just-so'.
Worse, because I had to resort to "Decimal" in python (and am currently experimenting with the same in Julia), both of which are immutable types, the GC was taking > 25% of the cpu time.
Performancewise, the numbers I cited in the actual thread, as of this time:
largest product factored was 32bit, 1855526741 * 2163967087, took 1116.111s in python.
Julia build used a slightly different method, & managed to factor a 27 bit number, 103147223 * 88789957 in 20.9s,
but this wasn't typical.
What surprised me was the variability. One bit length could take 100s or a couple thousand seconds even, and a product that was 1-2 bits longer could return a result in under a minute, sometimes in seconds.
This started cropping up, ironically, right after I posted the thread, whats a man to do?
So I started trying a bunch of things, some of which worked. Shameless as I am, I accepted the challenge. Things weren't perfect but it was going well enough. At that point I hadn't slept in 30~ hours so when I thought I had it I let it run and went to bed. 5 AM comes, I check the program. Still calculating, and way overshot. Fuuuuuuccc...
So here we are now and it's say to safe the worlds not gonna burn if I explain it seeing as it doesn't work, or at least only some of the time.
Others people, much smarter than me, mentioned it may be a means of finding more secure pairs, and maybe so, I'm not familiar enough to know.
For everyone that followed, commented, those who contributed, even the doubters who kept a sanity check on this without whom this would have been an even bigger embarassement, and the people with their pins and tactical dots, thanks.
So here it is.
A few assumptions first.
Assuming p = the product,
a = some prime,
b = another prime,
and r = a/b (where a is smaller than b)
w = 1/sqrt(p)
(also experimented with w = 1/sqrt(p)*2 but I kept overshooting my a very small margin)
x = a/p
y = b/p
1. for every two numbers, there is a ratio (r) that you can search for among the decimals, starting at 1.0, counting down. You can use this to find the original factors e.x. p*r=n, p/n=m (assuming the product has only two factors), instead of having to do a sieve.
2. You don't need the first number you find to be the precise value of a factor (we're doing floating point math), a large subset of decimal values for the value of a or b will naturally 'fall' into the value of a (or b) + some fractional number, which is lost. Some of you will object, "But if thats wrong, your result will be wrong!" but hear me out.
3. You round for the first factor 'found', and from there, you take the result and do p/a to get b. If 'a' is actually a factor of p, then mod(b, 1) == 0, and then naturally, a*b SHOULD equal p.
If not, you throw out both numbers, rinse and repeat.
Now I knew this this could be faster. Realized the finer the representation, the less important the fractional digits further right in the number were, it was just a matter of how much precision I could AFFORD to lose and still get an accurate result for r*p=a.
Fast forward, lot of experimentation, was hitting a lot of worst case time complexities, where the most significant digits had a bunch of zeroes in front of them so starting at 1.0 was a no go in many situations. Started looking and realized
I didn't NEED the ratio of a/b, I just needed the ratio of a to p.
Intuitively it made sense, but starting at 1.0 was blowing up the calculation time, and this made it so much worse.
I realized if I could start at r=1/sqrt(p) instead, and that because of certain properties, the fractional result of this, r, would ALWAYS be 1. close to one of the factors fractional value of n/p, and 2. it looked like it was guaranteed that r=1/sqrt(p) would ALWAYS be less than at least one of the primes, putting a bound on worst case.
The final result in executable pseudo code (python lol) looks something like the above variables plus
while w >= 0.0:
if (p / round(w*p)) % 1 == 0:
x = round(w*p)
y = p / round(w*p)
if x*y == p:
print("factors found!")
print(x)
print(y)
break
w = w + i
Still working but if anyone sees obvious problems I'd LOVE to hear about it.36 -
Shit! I knew buzzwords were overused, but I just saw an ad and it is fucking jesused jambled bananas in the ass.
Starts with a woman looking out the window and there’s a tornado (seems ok for now)
The tornado approaches and IT IS MADE OF FUCKING NON MONOSPACED IN MY ASS FONTED 0s AND 1s. Bonus point: they are green !!
Switches to lines of GREEN code (kill my fucking brain with a pistol attached to your dick right now)
Probably JS or something similar in syntax.
And then: A FUCKING GUY LEANING OVER POINTING SOMETHING ON THE SCREEN! HIS NAMETAG:
Logan Paul
Blockchain
👏👏👏👏
And then some other buzzing asses armagedon en d of the fucking world bleeding edge vibrator buzzwords shenanigans.
Finishes with drones shot flying between businesses building with 3d floating words like
Blockchain!
Artificial Intelligence
Deep learning
Etc.
KILLLLLL MMMEEEE FU748-KFJV ING 3I6HT N0W $)&(&($8#;&(&8 jeiebc13 -
console.log(0.47-0.01===0.46);
Output: false :/
That got me stuck for quite a while..
Learned more about floating point arithmetic and representation 😊7 -
Oh JavaScript... can you seriously not even increment the exponent of a float without barfing?
*siiiiiiiiiiiiiiiigh* 15
15 -
What grinds my gears:
IEEE-754
This, to me, seems retarded.
Take the value 0.931 for example.
Its represented in binary as
00111111011011100101011000000100
See those last three bits? Well, it causes it to
come out in decimal like so:
0.93099999~
Which because bankers rounding is nowstandard, that actually works out to 0.930, because with bankers rounding, we round to the nearest even number? Makes sense? No. Anyone asked for it? No (well maybe the banks). Was it even necessary? Fuck no. But did we get it anyway?
Yes.
And worse, thats not even the most accurate way to represent
our value of 0.931 owing to how fucked up rounding now is becaue everything has to be pure shit these days.
A better representation would be
00111101101111101010101100110111 <- good
00111111011011100101011000000100 < - shit
The new representation works out to
0.093100004
or 0.093100003898143768310546875 when represented internally.
Whats this mean? Because of rounding you don't lose accuracy anymore.
Am I mistaken, or is IEEE-754 shit?4 -
I was working on a project lately where I needed to convert an array of bits (1s and 0s) to floating numbers.
It is quite straightforward how to convert an array of bits to the simple integer (i.e. [101] = 5). But what about the numbers like `3.1415` (𝝿) or `9.109 × 10⁻³¹` (the mass of the electron in kg)?
I've explored this question a bit and came up with a diagram that explains how the float numbers are actually stored.
There is also an interactive version of this diagram available here https://trekhleb.dev/blog/2021/....
Feel free to experiment with it and play around with setting the bits on and off and see how it influences the final result.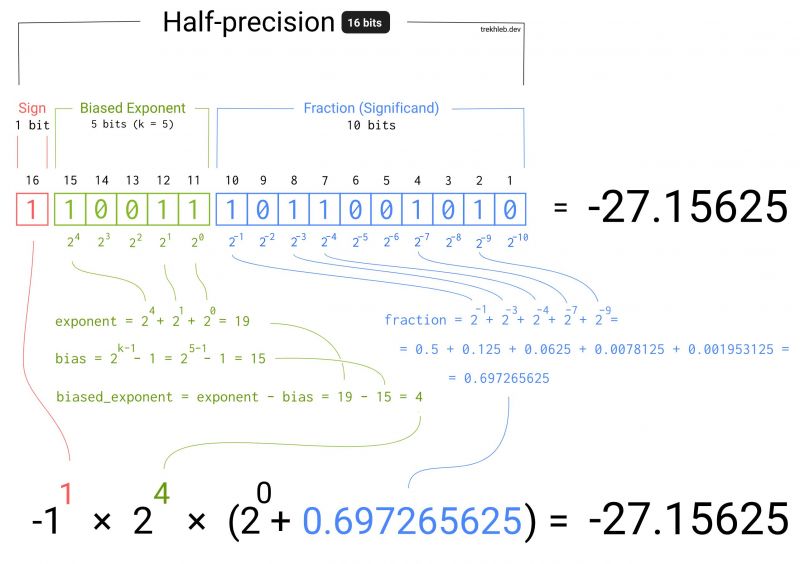 13
13 -
Apparently, floating point math is broken.
=SUM((2.1 - 2.0) - 0.1)
In PHP and Haskell this also happens 10
10 -
Since we're limiting this to things on my desk I can't do any more deep cuts out of my calculator collection, but this one is still somewhat interesting.
The HP 32S was my friend throughout university, it replaced the 15c I used before which does not live on my desk. The notable thing about the 32s is the fact it's an RPN calculator. RPN calculators are the best way to have friends never ask to borrow your calculator. The exchange will start by them asking to use it, you saying sure, and them handing it back a few minutes later without saying a word.
There's two kinds of people in this world. People who go "wtf" in an interview when asked to create a calculator program using a stack, and people who were oddballs and for whatever reason used reverse polish notation devices.
For those not familiar, rather than entering values into the calculator in "10+10" fashion, you instead provide it a compositional set of values until an operation is provided (10,10,+) at which point it executes. The why is, this type of operation allows the calculator to more naturally process operations, and eliminates the need for parenthesis which makes the operations less error prone in practice and easier to track.
The 32s had a 4 year run before being replaced by the 32SII. In the same way using a Curta will give you a significant understanding of how radix computations and floating points work. Using an HP 32s (or any of its predecessors) will do the same for algebraic functions, because you had to program them yourself using a basic label address system that also had subroutine support.
Kids who grew up with graphing calculators don't know how good you had it 😋 4
4 -
>laptop can't handle 3 terminals because cpu is single-core 1.2GHz
>fuck it
stress -c 128 -i 128 -m 16
>second terminal
top
>load average: 272.15, 247.60, 149.80
>CPU is cool after 30 minutes
>how
>picks up laptop from right side
>burned myself
>cpu is on the left under power button, right side has nothing that would get hot???
>takes apart laptop
>second large CPU-like die
wtf.386
>looks up laptop
>floating point/algebraic coprocessor
WHAT
and that was the story all about how my life got flipped turned upside down
what fucking system has a coprocessor after 2002? (My laptop is a 2008 HP something or other)2 -
float version = 1.8f
if (version >= 1.8f)
{
/*
Do nothing because you forgot
about floating point precision
you tool...
*/
}
I.. I'm sorry... I'll sacrifice some virtual chickens to appease the Gods.1 -
No offense, but if you're expecting 0 and not -80, then you know you're using floats.... Are there really devs that don't know what floating point round off is?
 9
9 -
Winter break university projects:
Option A: implement writing and reading floating point decimals in Assembly (with SSE)
Option B: reuse the reading and writing module from Option A, and solve a mathematical problem with SSE vectorization
Option C: Research the entirety of the internet to actually understand Graphs, then use Kruskal's algorithm to decide that a graph is whole or not (no separated groups) - in C++
Oh, and BTW there's one week to complete all 3...
I don't need life anyways... -
I want to explain to people like ostream (aka aviophille) why JS is a crap language. Because they apparently don't know (lol).
First I want to say that JS is fine for small things like gluing some parts togeter. Like, you know, the exact thing it was intended for when it was invented: scripting.
So why is it bad as a programming language for whole apps or projects?
No type checks (dynamic typing). This is typical for scripting languages and not neccesarily bad for such a language but it's certainly bad for a programming language.
"truthy" everything. It's bad for readability and it's dangerous because you can accidentaly make unwanted behavior.
The existence of == and ===. The rule for many real life JS projects is to always use === to be more safe.
In general: The correct thing should be the default thing. JS violates that.
Automatic semicolon insertion can cause funny surprises.
If semicolons aren't truly optional, then they should not be allowed to be omitted.
No enums. Do I need to say more?
No generics (of course, lol).
Fucked up implicit type conversions that violate the principle of least surprise (you know those from all the memes).
No integer data types (only floating point). BigInt obviously doesn't count.
No value types and no real concept for immutability. "Const" doesn't count because it only makes the reference immutale (see lack of value types). "Freeze" doesn't count since it's a runtime enforcement and therefore pretty useless.
No algebraic types. That one can be forgiven though, because it's only common in the most modern languages.
The need for null AND undefined.
No concept of non-nullability (values that can not be null).
JS embraces the "fail silently" approach, which means that many bugs remain unnoticed and will be a PITA to find and debug.
Some of the problems can and have been adressed with TypeScript, but most of them are unfixable because it would break backward compatibility.
So JS is truly rotten at the core and can not be fixed in principle.
That doesn't mean that I also hate JS devs. I pity your poor souls for having to deal with this abomination of a language.
It's likely that I fogot to mention many other problems with JS, so feel free to extend the list in the comments :)
Marry Christmas!34 -
FLOATING POINT PRECISION! FUCK YOU! Spent so much time trying to figure out what was wrong with an algorithm I made to calculate and correct bounding only to finally realise, after printing out every single variable and calculating everything manually to realise the value was off by 0.0001 which made it skip an if statement. Ughhhhhhhh, so much freaking time wasted2
-
Reading another rant about scrolling and decimal values I felt an urge to write about a bad practice I often see.
Load on demand when scrolling has been popular for quite some years but when implementing it, take some time to consider the pages overall layout.
I have several times encountered sites with this “helpful” feature that at the same time follows another staple feature of pages, especially news sites, of putting contact and address information in the footer ...
Genius right :)
I scroll down to find contact info and just as it comes in view new content gets loaded and pushes it out of view.
If you plan to use load on demand, make sure there is nothing below anyone will try to reach, no text or links or even pictures, you will frustrate the visitor ;)
The rant I was inspired by probably did not do this but its what got me thinking.
https://devrant.com/rants/1356907/...1 -
Inspired by @shahriyer 's rant about floating point math:
I had a bug related to this in JavaScript recently. I have an infinite scrolling table that I load data into once the user has scrolled to the bottom. For this I use scrollHeight, scrollTop, and clientHeight. I subtract scrollTop from scrollHeight and check to see if the result is equal to clientHeight. If it is, the user has hit the bottom of the scrolling area and I can load new data. Simple, right?
Well, one day about a week and a half ago, it stopped working for one of our product managers. He'd scroll and nothing would happen. It was so strange. I noticed everything looked a bit small on his screen in Chrome, so I had him hit Ctrl+0 to reset his zoom level and try again.
It. Fucking. Worked.
So we log what I dubbed The Dumbest Bug Ever™ and put it in the next sprint.
Middle of this week, I started looking into the code that handled the scrolling check. I logged to the console every variable associated with it every time a scroll event was fired. Then I zoomed out and did it.
Turns out, when you zoom, you're no longer 100% guaranteed to be working with integers. scrollTop was now a float, but clientHeight was still an integer, so the comparison was always false and no loading of new data ever occurred. I tried round, floor, and ceil on the result of scrollHeight - scrollTop, but it was still inconsistent.
The solution I used was to round the difference of scrollHeight - scrollTop _and_ clientHeight to the lowest 10 before comparing them, to ensure an accurate comparison.
Inspired by this rant: https://devrant.com/rants/1356488/...2 -
can we just get rid of floating points? or at least make it quite clear that they are almost certainly not to be used.
yes, they have some interesting properties that make them good for special tasks like raytracing and very special forms of math. but for most stuff, storing as much smaller increments and dividing at the end (ie. don't store money as 23.45. store as 2,345. the math is the same. implement display logic when showing it.) works for almost all tasks.
floating point math is broken! and most people who really, truely actually need it can explain why, which bits do what, and how to avoid rounding errors or why they are not significant to their task.
or better yet can we design a standard complex number system to handle repeating divisions and then it won't be an issue?
footnote: (I may not be perfectly accurate here. please correct if you know more)
much like 1/3 (0.3333333...) in base 10 repeats forever, that happens with 0.1 in base 2 because of how floats store things.
this, among other reasons, is why 0.1+0.2 returns 0.300000046 -
When you’re trying to write a function to convert a base 10 integer to a base 2 integer in Javascript without using parseInt() and it takes you a while to realize that you’re used to integer division being integer division and have forgotten that JavaScript stores numbers as double precision floating point. *facepalm*1
-
Question - is this meaningful or is this retarded?
if
2*3 = 6
2*2 = 4
2*1 = 2
2*0 = 0
2*-1 = -2
then why doesnt this work?
6/3 = 2
6/2 = 3
6/1 = 6
6/0 = 0
6/-1 = -6
if n/0 is forbidden and 1/n returns the inverse of n, why shouldn't zero be its own inverse?
If we're talking "0" as in an infinitely precise definition of zero, then 1/n (where n is arbitrarily close to 0), then the result is an arbitrarily large answer, close to infinite, because any floating point number beneath zero (like an infinitely precise approximation of zero) when inverted, produces a number equal to or greater than 1.
If the multiplicative identity, 1, covers the entire set of integers, then why shouldn't division by zero be the inverse of the multiplicative identity, excluding the entire set? It ONLY returns 0, while anything n*1 ONLY returns n.
This puts even the multiplicative identity in the set covered by its inverse.
Ergo, division by zero produces either 0 or infinity. When theres an infinity in an formula, it sometimes indicates theres been
some misunderstanding or the system isn't fully understood. The simpler approach here would be to say therefore the answer is
not infinity, but zero. Now 'simpler' doesn't always mean "correct", only more elegant.
But if we represent the result of a division as BOTH an integer and mantissa
component, e.x
1.234567 or 0.1234567,
i.e. a float, we can say the integer component is the quotient, and the mantissa
is the remainder.
Logically it makes sense then that division by zero is equivalent to taking the numerator, and leaving it "undistributed".
I.e. shunting it to the remainder, and leaving the quotient as zero.
If we treat this as equivalent of an inversion, we can effectively represent the quotient from denominators of n/0 as 1/n
Meaning even 1/0 has a representation, it just happens to be 0.000...
Therefore
(n * (n/0)) = 1
the multiplicative identity
because
(n* (n/0)) == (n * ( 1/n ))
People who math. Is this a yea or nay in your book?14 -
So the project I work on basically has to talk to a 3rd party plugin, through a 3rd party framework. The 3rd party plugin is a black box. This conversation happened:
Software guy: so we aren't sure what is breaking the thing. It's either us or the plugin, but it's probably both.
Systems guy: well then if we aren't sure then why are we writing an issue for it.
SWG: because we aren't sure but we know we are doing at least something that contributes. We read int X from a table and put it into a float. X doesn't perfectly represent in a float. It comes out X.0001. Then they take it and when it comes back it comes back as Y.0001. We cram it into an int so it becomes Y, we compare it to X which is really X.0001 and it comes back invalid.
SG: well as long as we are sending them the right number . . .
SWG: but we aren't sending them the right number. They are expecting X not X.0001. Then they send us back Y.0001 but it should be X so it's wrong.
SG: so they're giving us the wrong return value.
SWG: yes, but because we're giving them the wrong number.
SG: well not exactly . . .
SWG: yes exactly. It is off by .0001 because of floating point math.
SG: well . . .
Me: look it doesn't matter how it's breaking. But it IS broken. Which is why we're filling out the damn problem report. THEY ARE EDITABLE. We talked to the customer and gave them the risk assessment. They don't care. It happens rarely any way.
SG: then can we lower the severity?
Me: no. Severity doesn't relate to risk. That is a whole different process. Severity assumes it has already happened. It's a a high severity.
SG: but the metrics.
Me: WE GIVE THE METRICS TO THE CUSTOMER. WE TALKED TO THE CUSTOMER. THEY DON'T GIVE A SHIT.
And that was how I spent Wednesday wondering how a level 4 lead systems engineer got his job. How many push ups did he do? What kind of juice did he drink?2 -
When we subtract some number m from another number n, we are essentially creating a relationship between n and m such that whatever the difference is, can be treated as a 'local identity' (relative value of '1') for n, and the base then becomes '(base n/(n-m))%1' (the floating point component).
for example, take any number, say 512
697/(697-512)
3.7675675675675677
here, 697 is a partial multiple of our new value of '1' whose actual value is the difference (697-512) 185 in base 10. proper multiples on this example number line, based on natural numbers, would be
185*1,
185*2
185*3, etc
The translation factor between these number lines becomes
0.7675675675675677
multiplying any base 10 number by this, puts it on the 1:185 integer line.
Once on a number line other than 1:10, you must multiply by the multiplicative identity of the new number line (185 in the case of 1:185), to get integers on the 1:10 integer line back out.
185*0.7675675675675677 for example gives us
185*0.7675675675675677
142.000000000000
This value, pulled from our example, would be 'zero' on the line.
185 becomes the 'multiplicative' identity of the 1:185 line. And 142 becomes the additive identity.
Incidentally the proof of this is trivial to see just by example. if 185 is the multiplicative identity of 697-512, and and 142 is the additive identity of number line 1:185
then any number '1', or k=some integer, (185*(k+0.7675675675675677))%185
should equal 142.
because on the 1:10 number line, any number n%1 == 0
We can start to think of the difference of any two integers n, as the multiplicative identity of a new number line, and the floating point component of quotient of any number n to the difference of any number n-m, as the additive identity.
let n =697
let m = 185
n-m == '1' (for the 1:185 line)
(n-m) * ((n/(n-m))%1) == '0'
As we can see just like on the integer number line, n%1 == 0
or in the case of 1:185, it equals 142, our additive identity.
And now, the purpose of this long convoluted post: all so I could bait people into reading a rant on division by zero.14 -
Today my boss sent me something that smelled fishy to me. While he was trying to simulate Excel's rounding he faced what was to him unexpected behaviour and he claimed that one constructor of the BigDecimal class was "wrong".
It took me a moment why this was happening to him and I identified two issues in his code.
I found one fo the issues funny and I would like to present you a challenge. Can you find a number that disproves his claim?
It's Java if anyone was wondering.
double d = 102.15250;
BigDecimal db = new BigDecimal(d)
.setScale(3, BigDecimal.ROUND_HALF_EVEN);
BigDecimal db2 = new BigDecimal(String.format("%f",d))
.setScale(3, BigDecimal.ROUND_HALF_EVEN);
BigDecimal db3 = BigDecimal.valueOf(d)
.setScale(3, BigDecimal.ROUND_HALF_EVEN);
System.out.println(db); // WRONG! 102.153
System.out.println(db2); // RIGHT! 102.152
System.out.println(db3); // RIGHT! 102.152
P.s. of course the code itself is just a simple check, it's not how he usually writes code.
P.p.s. it's all about the numerical representation types.6 -
if((fabs(a - 0.0) > 0.00001) ||
(fabs(b - 0.0) > 0.00001) ||
(fabs(c - 0.0) > 0.00001))
What have you seen dear traveller? What have you seen?2 -
Had a php float value that I needed to use as a string, so I typecasted it.
Later on in the code I need the value again but now it was a string.
Typecasted it back to a floating point.
My colleague almost killed me when he found out what caused the miscalculations.2 -
Can the subscript of an array be a floating point number ?
i know, i know, i can find answers on google and i found one on quora but i want you guys to help me 🤗 in the comments10 -
Our systems lead is trying to tell our software person how much adding unit tests would cost. It also sounds like he wants TDD to be added in after the fact. And he's bitching because the software guy won't move forward with it until we get it with the customer. He also wants all of them automated, but doesn't want to accept that that is going to cost a lot. Like a lot, a lot. This is a guy who doesn't know algorithms (had to explain dykstra to him), doesn't understand the tech stack we are using (I had to explain .net versions, the JIT compiler, and garbage collection to him), and seems not to understand hardware (I had to explain floating point math to him), yet he feels qualified to tell us how long it is going to take us to implement automated unit tests for major, complex features.
-
Floating point numbers! 😖
Writing geometric algorithms for CNC machining... you'll find those 10th decimal place inconsistencies real quick!1 -
Why the fuck is it so hard to write a simple bash script. Syntax so strange and so many symbols you need to know. If you need to do calculations with floating point numbers, the mess is perfect.10
-
I'm forced to learn Racket at University. What type of clusterfuck of a language is this?!
How come this shitty language doesn't even support floating point modulo and finding positions in a list...? Let alone those goddamn parentheses...7 -
I wonder if anyone has considered building a large language model, trained on consuming and generating token sequences that are themselves the actual weights or matrix values of other large language models?
Run Lora to tune it to find and generate plausible subgraphs for specific tasks (an optimal search for weights that are most likely to be initialized by chance to ideal values, i.e. the winning lottery ticket hypothesis).
The entire thing could even be used to prune existing LLM weights, in a generative-adversarial model.
Shit, theres enough embedding and weight data to train a Meta-LLM from scratch at this point.
The sum total of trillions of parameter in models floating around the internet to be used as training data.
If the models and weights are designed to predict the next token, there shouldn't be anything to prevent another model trained on this sort of distribution, from generating new plausible models.
You could even do task-prompt-to-model-task embeddings by training on the weights for task specific models, do vector searches to mix models, etc, and generate *new* models,
not new new text, not new imagery, but new *models*.
It'd be a model for training/inferring/optimizing/generating other models.4 -
ISO floating point numbers are essentially wrapped in a hardware-level monad because the normal meaningful values aren't closed over basic arithmetic so conceptually wrapping everything in Maybe using the 'infectious sentinel value' NaN leads to substantial speedups.
With this in mind, I think high-level languages that have a Maybe should use those and have the language-type float refer to a floating point that isn't NaN.2 -
I'm at uni learning about floating point numbers and IEEE 754 and its so different to what I learnt at A-Level and it seems that using twos compliment floating point numbers is more efficient than storing numbers than IEEE 754 as IEEE 754 seems to use sign and magnitude. So why do we use IEEE 754?1
-
floating point numbers are workarounds for infinite problems people didn’t find solution yet
if you eat a cake there is no cake, same if you grab a piece of cake, there is no 3/4 cake left there is something else yet to simplify the meaning of the world so we can communicate cause we’re all dumb fucks who can’t remember more than 20000 words we named different things as same things but in less amount, floating point numbers were a biggest step towards modern world we even don’t remember it
we use infinity everyday yet we don’t know infinite, we only partially know concept of null
you say piece of cake but piece is not measurement - piece is infinite subjective amount of something
everything that is subjective is infinite, like you say a sentence it have infinite number of meanings, you publish a photo or draw a paining there are infinite number of interpretations
you can say there is no cake but isn’t it ? you just said cake so your mind want to materialize something you already know and since you know the cake word there is a cake cause it’s infinite once created
if you think really hard and try to get that feeling, the taste of your last delicious cake you can almost feel it on your tongue cause you’re connected to every cake taste you ate
someone created cake and once people know what cake is it’s infinite in that collection, but what if no one created cake or everyone that remember how cake looks like died, everything what’s cake made of extinct ? does it exist or is it null ? that’s determinism and entropy problem we don’t understand, we don’t understand past and future cause we don’t understand infinity and null, we just replaced it with time
there is no time and you can have a couple of minutes break are best explanations of how null and infinite works in a concept of time
so if you want to change the world, find another thing that explains infinity and null and you will push our civilization forward, you don’t need to know any physics or math, you just need to observe the world and spot patterns8 -
Just working with numbers these days i wonder if i can compile gcc with fixed point support , like if i use float in source it should implement my fixed point implementation rather than ieee floating point standards6
-
current language vba.
(14 / 24) - (8 / 24) > (6 / 24)
compiled to true. apparently rounding to 8 digits did the trick. quirky was that debug.printing each calculations showed exactly '0.25' for both not giving a hint about some float issue in the first place. ah, and rounding to 4 digits wasn't right either. -
Why do we still use floating-point numbers? Why not use fixed-point?
Floating-point has precision errors, and for some reason each language has a different level of error, despite all running on the same processor.
Fixed-point numbers don't have precision issues (unless you get way too big, but then you have another problem), and while they might be a bit slower, I don't think there is enough of a difference in speed to justify the (imho) stupid, continued use of floating-point numbers.
Did you know some (low power) processors don't have a floating-point processor? That effectively makes it pointless to use floating-point, it offers no advantage over fixed-point.
Please, use a type like Decimal, or suggest that your language of choice adds support for it, if it doesn't yet.
There's no need to suffer from floating-point accuracy issues.26 -
Ok this is my first try in machine learning, this is DQN for Pong!
I want to add my own flavor by adding pressure touch to paddle movements, such that the harder I press in a direction it moves faster to a max speed.
Does it makes sense if I apply the floating point outputs of sigmoid directly to speed control? Or should I make multiple outputs to represent different "steps" of pressure/speed? -
I've seen an old Causeway Extender unpacker floating around, at some point being on EXETOOLS before they went forum-only, by the name "CauseWay DOS Extender Unpacker v0.17" or "unpcwc.zip". Is there a copy of this still around or will I have to make my own based on the released Causeway source code?


















































Top Tags
Weekly Rant
View