
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Wanted to reboot my work pc today. I always do that through a terminal and I've got dozens open anyways.
*wants to reboot right away*
*stops at the last possible point to check if I'm not in a server-logged-in terminal*
😓
*silently logs out of prod server*
Well that was god damn close.28 -
"could I get admin privileges to reboot this server?"
Sounds valid enough, right?
OH YEAH SURE, YOU'RE A TINY USER ON A HUGE ASS SHARED SERVER, OF COURSE I'LL GIVE YOU ROOT ACCESS TO REBOOT THE WHOLE FUCKING SERVER.
Worst part, he didn't understand why that would be weird.
Can I buy a little common sense somewhere for this guy?27 -
*tries to convert a Windows drive into btrfs*
*copies the whole 1.4TB of data back from server*
Windows: Wait, you expect me to do more than browsing the Phasebuk and playing games? Over a million files?! No no no, can't do that.
*reboot after BSOD*
Ehm, a hard drive you say? A drive that I just fucked up? What are you talking about? I don't see any hard drive :/
Piece of shit.
Crappy Arch Linux laptop: ah, I see a new hard drive connected here. Limme mount it real quick for ya :3
Me: eh, not now. I want to format it first.
Linux: oh, cool! Your wish is my command <3
*formats hard drive to btrfs*
Me: alright, now please copy all that 1.4TB onto the drive and please don't overheat _/\_
Linux: Gotcha! On your commands sir!
See the difference? The mental communication level? Windows is like talking to an obnoxious grade schooler that just does whatever the fuck they want to. Linux on the other hand is so much more mature and capable. Guess which one I like the most.20 -
Working 600 km from home on my first big web project, with a raspberry pi as server (located at home). Decided to reboot it today in order to see if it would resolve a problem.
It probably booted up with a different local ip, cant access it anymore with ssh or ftp.
Fuck.14 -
So I had my exams recently and I thought I'd post some of the most hacky shit I've done there over here. One thing to keep in mind, I'm a backender so I always have to hack my way around frontend!
- Had a user level authentication library which fucked up for some reason so I literally made an array with all pages and user levels allowed so I pretty much had a hardcoded user level authentication feature/function. Hey, it worked!
- CSS. Gave every page a hight of 110 percent because that made sure that you couldn't see part of the white background under the 'background' picture. Used !important about everywhere but it worked :P.
- Completey forgot (stress, time pressure etc) to make the user ID's auto incremented. 'Fixed' that by randomly generating a user id and really hoping during every registration that that user ID did not exist in the database already. Was dirty as fuck but hey it worked!
- My 'client' insisted on using Windows server.Although I wouldn't even mind using it for once, I'd never worked with it before so that would have been fucked for me. Next to that fact, you could hear swearing from about everyone who had to use Windows server in that room, even the die hard windows users rather had linux servers. So, I just told a lot of stuff about security, stability etc and actually making half of all that shit up and my client was like 'good idea, let's go for linux server then!'. Saved myself there big time.
- CHMOD'd everything 777. It just worked that way and I was in too much time pressure to spend time on that!
- Had to use VMWare instead of VirtulBox which always fucks up for me and this time it did again. Windows 10 enjoyed corrupting the virtual network adapters after every reboot of my host so I had to re-create the whole adapter about 20 times again (and removing it again) in order to get it to work. Even the administrator had no fucking clue why that was happening.
- Used project_1.0.zip etc for version control :P.
Yup, fun times!6 -
What an awful day :(
The server where I host my 4 clients websites crashed.
Unable to reboot from the console.
I contact the support. 15 minutes later: "we'll look at this"
No news for 1 week despite my messages.
Then... 1st ticket escalation... 2nd ticket escalation... 3rd ticket escalation...
Answer: "Sorry, your server is down and cannot be repaired."
Fuck.
I ask "is there any way to get my data back?". Answer: "No, because we would shutdown the whole bay and all our clients would be impacted".
Fuck.
I subscribe to another server, at another provider.
I look at my backups... shit, the last one is 4 month ago!!
I restore the first website: OK
I restore the second website: OK
I restore the third website: My new server is "too recent" and not compatible. with this old Wordpress. Fuck! I'll look at this later...
I restore the fourth website: database is empty!! What??? I look at the SQL backup for this site... it failed...
I lost ALL my 4th client data!!!
I'm sooooo piece of crap!14 -
TL;Dr be specific, it's actually helpful.
Client rings... "The internet is down"
Me "ok where are you exactly and how are you connecting"
"Ugh the WiFi! Just fix it"
"Ok but where are you?"
"At $companyname"
"Ok and which wi..."
"The wifi?!! Can you do anything right?"
Well... I'm allowed flexibility in terms of pleasantry...
"Ok, there are 3 buildings, 55 rooms, 2 SSID's, 17 access points, 3 routers a RADIUS server and 2 gateways... Be specific or I'll do nothing"
Simple reboot of an access point, but c'mon... It's not a secret where you are7 -
That mini heart attack you get when you've rebooted the server, but it takes longer than normal before it comes up again (and before you can ssh it).2
-
I'm so grateful DevOps is now a thing. I remember getting a phone call from a client at 2am on a Friday because their site was down and having to ssh in from a Nokia with the world's tiniest keyboard to reboot the server.
Of course that particular server only exposed port 22 on it's local network, so I had to first ssh into another server which did have its ssh port open to external connections.
Trying to remember two sets of credentials and type them in on a tiny keyboard, while so drunk you were seeing double, standing outside in the rain as it was the only place you got signal. Yeah…I'm so grateful DevOps is now a thing 7
7 -
Me: *on the phone with client* "Ok, now reboot the cashier terminal"
Client: *reboots server causing whole system to go down*
Me: *internal screams*4 -
So I looked at our dashboard and noticed a banner mentioning scheduled maintenance set for 7:00 AM. And I thought to myself, "I never released an update, and even if I had, the maintenance would be performed 15 minutes after the build finished, not at 7:00 AM." So I emailed my coworkers, asking if they had put up the banner, no, no. I started pulling my hair out trying to figure out what caused this banner to be created. Was there some old job that was just now running? I combed through the server logs, thousands of entries later, and I found the banner was installed by some user with the IP 172.18.0.1...which was the local machine. I went through all the users on the system, running atq to see if anyone had jobs scheduled. And there was one job scheduled, under the root user. At that moment, I legit thought to myself, "have we been hacked? How is that possible?" It's wasn't! Then I looked under /var/spool/atjobs to see what the job actually was. And then I saw it. My weekly updater cron job had installed updates and had scheduled a maintenance window to reboot the system. And I smiled, realizing that my code was now sentient.
-
The website for our biggest client went down and the server went haywire. Though for this client we don’t provide any infrastructure, so we called their it partner to start figuring this out.
They started blaming us, asking is if we had upgraded the website or changed any PHP settings, which all were a firm no from us. So they told us they had competent people working on the matter.
TL;DR their people isn’t competent and I ended up fixing the issue.
Hours go by, nothing happens, client calls us and we call the it partner, nothing, they don’t understand anything. Told us they can’t find any logs etc.
So we setup a conference call with our CXO, me, another dev and a few people from the it partner.
At this point I’m just asking them if they’ve looked at this and this, no good answer, I fetch a long ethernet cable from my desk, pull it to the CXO’s office and hook up my laptop to start looking into things myself.
IT partner still can’t find anything wrong. I tail the httpd error log and see thousands upon thousands of warning messages about mysql being loaded twice, but that’s not the issue here.
Check top and see there’s 257 instances of httpd, whereas 256 is spawned by httpd, mysql is using 600% cpu and whenever I try to connect to mysql through cli it throws me a too many connections error.
I heard the IT partner talking about a ddos attack, so I asked them to pull it off the public network and only give us access through our vpn. They do that, reboot server, same problems.
Finally we get the it partner to rollback the vm to earlier last night. Everything works great, 30 min later, it crashes again. At this point I’m getting tired and frustrated, this isn’t my job, I thought they had competent people working on this.
I noticed that the db had a few corrupted tables, and ask the it partner to get a dba to look at it. No prevail.
5’o’clock is here, we decide to give the vm rollback another try, but first we go home, get some dinner and resume at 6pm. I had told them I wanted to be in on this call, and said let me try this time.
They spend ages doing the rollback, and then for some reason they have to reconfigure the network and shit. Once it booted, I told their tech to stop mysqld and httpd immediately and prevent it from start at boot.
I can now look at the logs that is leading to this issue. I noticed our debug flag was on and had generated a 30gb log file. Tail it and see it’s what I’d expect, warmings and warnings, And all other logs for mysql and apache is huge, so the drive is full. Just gotta delete it.
I quietly start apache and mysql, see the website is working fine, shut it down and just take a copy of the var/lib/mysql directory and etc directory just go have backups.
Starting to connect a few dots, but I wasn’t exactly sure if it was right. Had the full drive caused mysql to corrupt itself? Only one way to find out. Start apache and mysql back up, and just wait and see. Meanwhile I fixed that mysql being loaded twice. Some genius had put load mysql.so at the top and bottom of php ini.
While waiting on the server to crash again, I’m talking to the it support guy, who told me they haven’t updated anything on the server except security patches now and then, and they didn’t have anyone familiar with this setup. No shit, it’s running php 5.3 -.-
Website up and running 1.5 later, mission accomplished.6 -
Ooof.
In a meeting with my client today, about issues with their staging and production environments.
They pull in the lead dev working on the project. He's a 🤡 who freelanced for my previous company where I was CTO.
I fired him for being plain bad.
Today he doesn't recognize me and proceeds to patronize me in server administration...
The same 🤡 that checks production secrets into git, builds projects directly in the production vm.
Buckle up... Deploys *both* staging and production to the *same* vm...
Doesn't even assign a static IP to the VM and is puzzled when its IP has changed after a relaunch...
Stores long term aws credentials instead of using instance roles.
Claims there are "memory leaks", in a js project. (There may be memory misuse by project or its dependencies, an actual memory leak in v8 that somehow only he finds...? Don't think so.)
Didn't even set up pm2 in systemd so his services didn't even relaunch after a reboot...
You know, I'm keeping my mouth shut and make the clown work all weekend to fix his own hubris.9 -
Now seriously, WHAT THE FUCK???
Every single time I have to work with people from a particular country [you have one guess. Yepp, that's the one], I see A-FUCKING-LOOOOOOT of manual work?!?
"can you reboot the server?"
-"sure, let me help you, sir" <20 minutes later> "done"
"can you unlock my account?"
-"yes, just a moment sir" <20 minutes later> "please check now"
"can you restart this environment w/ 200 instances?"
-"yes sir, let me check" <6 hours later> "please check now"
"you've missed 18 containers"
-"oh okay sir, will restart them now" <2hours later> "please check now"
[I am already OoO]
why is it that every time I have to work with you guys I am the one who is automating shit. How come you never think of/do any automata? You are fucking technitians, you should know how. WHY DO YOU ENJOY CLICKING ALL-DAY-LONG????
I'm serious. Why??? I'm struggling to understand...20 -
When you reboot your server and on boot it asks for the hdd encrypted password. I have no clue anymore. Oh how fucking happy I am that we have no users yet and are in closed alpha. Happy to learn this now so I'll never make this mistake again. 😨3
-
It is once again that time of year when we say farewell to our current interns and say hello to a brand new batch.
The two groups overlap for a few days. During this time the old interns show the new interns the ropes, while the mentors silently weep in the lunchroom having realized that nothing that they've said over the last 12 months has had any effect whatsoever.
Some choice quotes:
---
New Intern: It says 'uncaught exception'.
Old Intern: Oh don't worry that will fix itself on production.
---
OI: Did you pull the code?
NI: Yeah, but I have all these weird brackets everywhere... [merge conflict]
OI: Oh yeah that happens sometimes, just delete them.
---
NI: It says "push to master rejected". [we enforce code reviews]
OI: Ohh that means the server is broken. You should tell someone, they have to reboot it.
---
NI: Where did that file save to? [we use ONLY macOS and Linux]
OI: C:\Users\<your name>\My Documents\...
---
OI: You can use either pgAdmin or MySQL Workbench. I like Workbench better but I couldn't get it to work, it kept giving me errors.
---
And of course...
---
OI: No, we don't use Linux. We use CentOS.
---
I did the math today. Only 35 more years and I can retire.5 -
Today I broke our testing server.
I accidentally (don't even ask, I'm stupid) renamed the /lib folder and nothing worked anymore. Not a single bash-command. I had to shutdown the server and reboot it with a recovery-cd to rename the folder again. Luckily it all runs in a vSphere so I didn't even had to stand up from my desk.4 -
TLDR: There’s truth in the motto “fake it till you make it”
Once upon a time in January 2018 I began work as a part time sysadmin intern for a small financial firm in the rural US. This company is family owned, and the family doesn’t understand or invest in the technology their business is built on. I’m hired on because of my minor background in Cisco networking and Mac repair/administration.
I was the only staff member with vendor certifications and any background in networking / systems administration / computer hardware. There is an overtaxed web developer doing sysadmin/desktop support work and hating it.
I quickly take that part of his job and become the “if it has electricity it’s his job to fix it” guy. I troubleshoot Exchange server and Active Directory problems, configure cloudhosted web servers and DNS records, change lightbulbs and reboot printers in the office.
After realizing that I’m not an intern but actually just a cheap sysadmin I began looking for work that pays appropriately and is full time. I also change my email signature to say “Company Name: Network Administrator”
A few weeks later the “HR” department (we have 30 employees, it’s more like “The accountant who checks hiring paperwork”) sends out an email saying that certain ‘key’ departments have no coverage at inappropriate times. I don’t connect the dots.
Two days later I receive a testy email from one of the owners telling me that she is unhappy with my lack of time spent in the office. That as the Network Administrator I have responsibilities, and I need to be available for her and others 8-5 when problems need troubleshooting. Her son is my “boss” who is rarely in the office and has almost no technical acumen. He neglected to inform her that I’m a part time employee.
I arrange a meeting in which I propose that I be hired on full time as the Network Administrator to alleviate their problems. They agree but wildly underpay me. I continue searching for work but now my resume says Network Administrator.
Two weeks ago I accepted a job offer for double my current salary at a local software development firm as a junior automation engineer. They said they hired me on with so little experience specifically because of my networking background, which their ops dept is weak in. I highlighted my 6 months experience as Network Administrator during my interviews.
My take away: Perception matters more than reality. If you start acting like something, people will treat you like that.2 -
*edits file on remote server*
WanBLowS: naah you can't 😈
*le wild BSOD appears for the over 9000-th time*
... Yeah. Windows, great job. Who needs system integrity when they're working on remote servers anyway, right?!
And to top it all off, le reboot mentions that they're working on fucking "features" again. That's what you needed to BSOD for?! For a goddamn motherfucking feature?!! Fucking piece of shit.
At least when I opened vim on that server again, it's saved everything neatly in the .swp files, ready for recovery. Now that's neat, isn't it? Microsoft, the Linux community has already moved on to nvim in terms of development, but maybe, just maybe, you can learn a thing or two from our "legacy software", vim.
As for me, maybe it's time to take out my Arch laptop again. At least that won't crap out on me because the sun and the stars are in a position that the OS doesn't like, or something stupid like that. FUCK YOU MICROSHIT!!!11 -
Question for networking persons or persons who might know more about this than me in general.
I'm looking at setting up a server as vpn server (that part I know) which tunnels everything through multiple other vpn connections.
So let's say I've got a vps which I connect to through vpn. I then want that vps to have one or multiple connections to other vpn servers.
That way i can connect my devices to this server which routes everything to/through other services like mullvad :).
Tried it before but ended up losing ssh access until reboot 😬
Anyone ideas?28 -
That time I thought I crashed a prod server which I had no access to physically turn it back on. Turned out it was doing its weekly reboot. Scary 3 minutes.
-
My Sunday Morning until afternoon. FML. So I was experiencing nightly reboots of my home server for three days now. Always at 3:12am strange thing. Sunday morning (10am ca) I thought I'd investigate because the reboots affected my backups as well. All the logs and the security mails said was that some processes received signal 11. Strange. Checked the periodics tasks and executed every task manually. Nothing special. Strange. Checked smart status for all disks. Two disks where having CRC errors. Not many but a couple. Oh well. Changing sata cables again 🙄. But those CRC errors cannot be the reason for the reboots at precisely the same time each night. I noticed that all my zpools got scrubbed except my root-pool which hasn't been scrubbed since the error first occured. Well, let's do it by hand: zpool scrub zroot....Freeze. dafuq. Walked over to the server and resetted. Waited 10 minutes. System not up yet. Fuuu...that was when I first guessed that Sunday won't be that sunny after all. Connected monitor. Reset. Black screen?!?! Disconnected all disks aso. Reset. Black screen. Oh c'moooon! CMOS reset. Black screen. Sigh. CMOS reset with a 5 minute battery removal. And new sata cable just in cable. Yes, boots again. Mood lightened... Now the system segfaults when importing zroot. Good damnit. Pulled out the FreeBSD bootstick. zpool import -R /tmp zroot...segfault. reboot. Read-only zroot import. Manually triggering checksum test with the zdb command. "Invalid blckptr type". Deep breath now. Destroyed pool, recreated it. Zfs send/recv from backup. Some more config. Reboot. Boots yeah ... Doesn't find files??? Reboot. Other error? Undefined symbols???? Now I need another coffee. Maybe I did something wrong during recovery? Not very likely but let's do it again...recover-recover. different but same horrible errors. What in the name...? Pulled out a really old disk. Put it in, boots fine. So it must be the disks. Walked around the house and searched for some new disks for a new 2 disk zfs root mirror to replace the obviously broken disks. Found some new ones even. Recovery boot, minimal FreeBSD Install for bootloader aso. Deleted and recreated zroot, zfs send/recv from backup. Set bootfs attribute, reboot........
It works again. Fuckit, now it is 6pm, I still haven't showered. Put both disks through extensive tests and checked every single block. These disks aren't faulty. But for some reason they froze my system in a way so that I had to reset my BIOS and they had really low level data errors....? I Wonder if those disks have a firmware problem? So that was most of my Sunday. Nice, isn't it? But hey: calm sea won't make a good sailor, right?3 -
I really wanna share this with you guys.
We have a couple of physical servers (yeah, I know) provided by a company owned by a friend of my boss. One of them, which I'll refer to as S1, hosted a couple of websites based on Drupal 7... Long story short, every php file got compromised after someone used a vulnerability within D7's core to inject malicious code. Whatver, wasn't a project of mine, and no one bothered to do anything about it... The client was even happy about not doing anything about it. We did stop making backups of such websites however, to avoid spreading the damage (right?). So, no one cared about this for months!
But last monday? The physical server was offline. I powered it on again via its web management interface... Dead after less than an hour. No backups. Oh well, I guess I couls keep powering it on to check what's wrong with it and attempt to fix it...
That's when I've learned how the web management interface works: power on/reboot requests prompted actual workers to reach the physical server and press the power on/reboot buttons.
That took a while to sink in. I mean, ok, theu are physical servers... But aren't they managed anyhow? They are just... Whatever. Rebooting over and over wasn't the solution, so I asked if they could move the HDD to another of our servers... The answer was it required to buy a "server installation" package. In short, we'd have had to buy a new physical server, or renew the subscription of one we already owned for 6 months.
So... I've literally spent the rest of the day bothering their emoloyeea to reboot S1, until I've reached the "daily reboot reauests limit" (which amounts to 3 reauests. seriously), whicj magically opened a support ticket where a random guy advised to stop using VNC as "the server was responsive" and offeres to help me with the command line.
Fiiine, I sort of appreciate it. My next message has been a kernel log which shows how the OS dying out was due to physical components becoming unavailable after a while, and how S1 lacked a VNC server, being accessible only via ssh. So, the daily reboot limit was removes for S1. Yay.
...What to do though? S1 was down, we had no backups, and asking for manual rebooting every time was slow as Hell. ....Then I went insane. I asked for 1 more reboot. su. crontab -e. */15 * * * * /sbin/shutdown -r +5. while true; do; rsync --timeout=20 --append S1:/stuff .; sleep 60; done.
It worked. We have now again access to 4 hacked, shitty Drupal 7 websites. My boss stopped shouting. I can get back to my own projects.
Apparently, those D7 websites got back online too, still with malicious php code within them. Well, not my problem (for now).
Meanwhile, S1 is still rebooting.3 -
You know the worst thing about being a freelancer? You're expected to wear every fucking hat and you don't get normal hours.
Over the past few days I have been working with a client of a client attampting to fix his server. He's running CentOS on VMWare and somehow ended up breaking the system.
Upon inspection there was no way to fix his system remotely. It wouldn't even boot in recovery mode. So we've been attempting to recover his data so that we can reinstall CentOS and not have to start completely from scratch.
So for the past 3 days straight I have been remotely logging in to a Debian Live CD and manually sending folders to a FTP server of his. He has somewhere close to 30 sites on this server, and upwards of 1 million files in total.
Yesterday either the system freaked out or he did something, but the entire fucking system stopped responding which forced me to reboot it, reinsert the live CD, reinstall evertything, and re-mount his broken systems drives.
Here we are 3 days in, we're still not done, and I'm getting slightly pissy because if you don't know Linux well enough to fix this shit yourself, you shouldn't be acting as your own sysadmin for 30+ sites.
Also, backups are a thing right? VMWare also has snapshots. I know the extra storage isn't cheap, but it's a hell of a lot cheaper than paying soemone like me $35/hr to go and fix all of your shitty mistakes.2 -
The WTF moment when I realized that the main production DB server was configured with **dynamic** private IP. After maintenance upgrade and reboot the rest of environment stopped. When I explained to sys admin what caused the production breakdown hi still did not get that :/3
-
Too many night shifts.
But it's done.
After the last migrations my emotional state is... Questionable.
VM migrations between different CPU vendors and generations leading to segfaults because of unsupported X86 extensions.... Thx for doing that at 23 o'clock after 8 hours of work....
Forgetting a left over NIC in a virtual machine, creating a routing loop, leading to very erratic behaviour and fun things.
Someone forgot to check the '"Unique" box, mass spawning a cluster of VMs with same MAC adresses....
DNS fuckery since someone thought that reboot would flush the cache of an DNS server.... Nope most DNS servers have persistent caches. You'll have to flush manually.
And let's not forget the joy of the 12 plus pages of when and where to move VMs, harddrives and VLAN configuration.
Oh migrations are such a festival of joy.
Finally done with that shit -.-4 -
So Apache and I don’t seem to understand one an other.
# sudo service httpd restart
...
I’m still here waiting for this fucking useless thing too turn off 10 minutes later.
I’m starting to think it would have been easier to reboot the entire server.6 -
Just now I was reading on https://pve.proxmox.com/wiki/... about high availability. Now my Proxmox VE is just a tower (which happens to have ECC memory) that's stored in my storage room (and which is mostly used for experimental and home server purposes). But my mail servers.. those have been made with high availability in mind. Most importantly, I've made their services entirely redundant (but within the same datacenter). And when they have updates, I apply updates to one, reboot, see if it didn't break something and then do the same to the other server after the first one came up again. So no downtime whatsoever.
If memory serves me right, I think that I've been able to maintain these servers for the last year without any downtime at all (I reboot them every month to apply new kernels but they haven't both been simultaneously down at any moment). Does that make them High Availability? My interventions regarding their availability have been rather trivial. Is it really that hard..?4 -
TLDR: There's some days where the Gods of IT are not with you. Just lost a whole day of work.
So this morning, we (me and my team) big performance issues with our web app. Lot's of requests time out, big latency, etc
Try to ssh to VPS, latency of 10 seconds between user input and output.
Usual checks: RAM ok, Proc ok, hard drive ok, reboot server (20 minutes), update/upgrade
We decide to call OVH. After 15 minutes call, we try to reboot in rescue mode. Reboot fails at 60% + everything freezes.
After an hour, OVH opens an incident ticket on +200 vps instances (including mine) everything is down during +1h
Finally everything is okay ! Even had time to migrate my new database schema.
Still, quick heavy on the mind but feels good to go home with everything working out correctly
-
I'm ashamed of it, but I want to share my tifu-story:
My colleague asked me if I could rename his windows user name because he married and changed his last name. I changed it in the Active Directory, but he got some problems when he wants to log on. On every startup his old name appears. Simpliest task. Let me google that.
Easy going, let me just change this registry entry. Reboot. Old behaviour. Okay, I changed some of the other entries. Reboot. Yeah, his new name appears. But wait a moment. Windows just nulled his entire user profile and deleted all the data. "oh, haha you have a backup, right?" - "no, I saved everything on the desktop, all my work is gone!"
But at the end, the boss was mad at HIM, because he doesn't used the file server or any backup system.
i am not a smart man5 -
TL;DR : I did not read the fucking manual.
Story :
We have a particular kind of setup with Blazor Server-side. And it does not use any SQL, bbut calls APIs.
The class to call APIs was scoped to create one new HTTP connection per new tab (even if the user opens a new tab, it's a new HttpClient).
We were fine. I read that we have 65k ports and disposal takes around 2 minutes, and we have around 1000 users. So it went into the "backlog, where things go to die."
Hard core duiscovery in the past 2 days.
Azure service plan for webapps only allows you 128 outbound connections!
System, we reboot it manually every 4 hours, while I'm working to make HttpClient unique lol
I just needed a break and vent. And "Hey kids, know that Azure service plan is only 128 sockets, not 65536."7 -
So I actually got an update for my PC at work, proposing me to postpone it or to do it later. I postpone it to one hour later, since I'll be buying food for lunch, it can update and reboot.
When I came back from lunch, laptop is asking me to postpone or do the update right now. So I sigh because the laptop just stayed locked without doing anything, and ask it to do the update in 4 hours, when I'll be leaving.
2 minutes later, it forces me to update with the "30 min left before rebooting", so I sigh again, closes everything and reboot.
Since it's a Windows, it's slow on booting by definition. Plus launching Slack, Eclipse, Firefox, VLC. Takes time. Plus launching the server. +1000 files to compile then deploying.
I lost 20 minutes because of that edgy bitch called "update".3 -
Started up KiTTY to connect to my virtual test server per usual when I couldn't establish a connection.
Nothing too unusual so I do the typical troubleshooting I make sure host, port and authentication is all correct and it is. So now I open the display for the virtual server and start looking at ip info, host info, checking ports and everything is completely fine.
Now I'm getting frustrated so I start running things like configtest in apache, using systemctl to check the services status, even restarting virtualbox in my windows 10 devpc. Still cannot connect!
I start feeling hopeless and just shut everything down, the whole operating system.
*takes breath*
Computer boots up and I start my usual thing of creating workspaces, opening editors, starting servers, etc.
I open KiTTY again and launch my virtual test server..
konicm8ker@VM-UBUNTUSERVER:~$ _
Somethings you just can't fix without a reboot. -
So I set up a raspberry pi to control my bedroom lights last year. I decided I wanted to add some more features to it and for the first time since I created it, started looking through the code I wrote.
First thing I noticed was the excessive amount of files I have. Like I get that I just wanted to throw this thing together as quick as I could but did I really need to create a file specifically for storing a 1 or 0 depending if the lights were last turned on or off for a startup check.
Secondly, I seem to have 2 index.html files for some reason.
And finally, the code itself is pure spaghetti. The website is running with a python script, which sends calls to a nodejs server, which executes additional python scripts to control the lights. No comments anywhere, and badly named variables are also a great combo.
And finally there is the occasional "Why the fuck isn't it working, fuck it I'll just unplug the pi and reboot it" that I have been dealing with lately.
Oh and don't forget that the log file is spammed by a debug message that is printed every minute.
God I feel so ashamed. I was proud of this until I looked at it just now.4 -
When you spend the entire afternoon wondering why a simple piece of out-of-date php doesn't work. Then you reboot the server and realise the IT Crowd taught you everything.
-
I just setup a new VPS
I made all configuration required
I reboot the server
I forgot which port I set for ssh 😭
Luckily I have console to access from 😅14 -
At the beginning of the evening I started creating a snapshot of my webserver Ubuntu 16.04 installation, running 5 websites.
When the snapshot was created I started a release upgrade to Ubuntu 18.04.
Finally after upgrade and reboot... Nothing worked anymore. Nginx was running but none of the websites was working.
I started checking logs & searching for a solution, with no luck.
Wanted to restore my snapshot. Reading the docs of Scaleway: only a manual on how to restore to a *new* server...
Dumb me removing my current server and wanting to create a new server: "All servers tempotary out of stock"
Me: *panicing and clicking the resfresh button every second*
"Low stock"
*HITTING the create server button*
Added my snapshot
*Booting up*
Ssh'ing into server
Server: "nope"
#+#£_&-+{$}¥}•+';!
*Sees 'add snapshot to volume'*
*Sees 'add volume to server'*
*All websites running again after nginx restart*
What the fuck.
*End of evening* -
In a call from customer support to SRE:
"...is it possible to reboot the whole server with the exception of an instance?"1 -
There is a time in every programmer's life that the only thing to be done is to take a deep breath and reboot the server.
-
Installing Alpine Linux with GNOME (yes, I want to move from ubuntu to alpine as my daily driver)
Expectations: several days of debugging by entering contradictory commands and workarounds that make little sense
Reality:
type “setup-desktop”
type “gnome”
wait
type “reboot”
Alpine, what the heck? You’re a server-oriented distro with openrc instead of systemd, your own package manager and musl instead of glibc. Making you a desktop should be a challenge! It’s very unlinuxy of you.5 -
2X Tickets solved by rebooting the server after .Net Installation.
Client Default answer to: "Did you turn it off and on again?"
Always silence until you force the reboot after an server check and analysis.2 -
Been reading for a while now, finally frustrated enough to add my rant...
Backing up my home server with Veeam to finally ditch raid 5 and add some space. 38% finished when we had to leave for a Thanksgiving dinner. Thought that was perfect because I'd come home to a finished backup, install the new drives and get Plex/webserver back up and running. Nope. Win 10 decides to update and reboot in the middle of my freaking backup at 79% complete. Now, I've just told the friends and family I was with to expect the outage in the next hour or two thinking I was ready. Nope. Start all over again. None of this is truly important, really... But Jesus, that's annoying.
Win 10, you have a special place in hell. And Veeam, as much as I love you, you can be right beside them for not letting me run backup console on Linux.1 -
I just rebooted my server by accident because I wanted to play Space Engineers.
Long story short, dual booting. Needed to boot into windows. Typed reboot into my terminal. My terminal was not local. When am I finally getting around to set up my terminal color as red when it is connected to another host?
But two things are good here. This was my own server.. Well, bunch of stuff is running on it, including for my bachelor's thesis. But if that was a server of my company, that would have been worse.
Second thing, my systems are fault tolerant. I reboot once per week at the latest and for systems with fail overs once per day. I know they are coming back up. I don't worry. My Gitlab will be back in 5 minutes at the latest. I am going to reboot and play Space Engineers now.
Reboot your servers guys. Only way to make sure they'll survive reboots!4 -
After couiple of hours (Yes, apprently it's insane how hard is to add a new NIC to a linux machine and make it start on boot), I finally got my connexion working !
Story :
Server has original MB 1Gbits card. Internet connexion is 1.1 Gbps. So 1Gb card only picked at 940 Mbits download
I bought a 2.5 Gb card (new nic)
Pluged it in : Nothing
Couple of ifconfig -a etc, bring device UP : Yeah working !
Reboot : Nothing
/etc/interfaces : nothing
And why it's not eth0 and eth1 etc as before but some thing cryptic like enp3s0.
Well, at least now everything working (Apperently there is a new "network plan" config file in yaml... what a waste, DO FUCKING JSON YOU RETARDS)
Ping is awsome tho ! Same cable on windows Machine, I get 5 ms.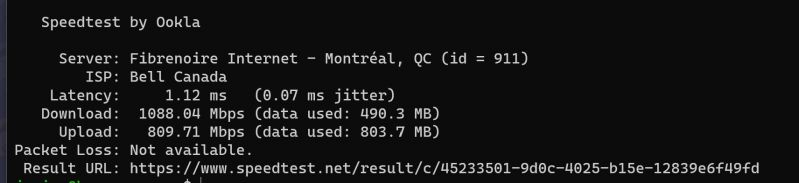 4
4 -
Each time I see THAT, there is 50% chance that server will not reboot :(
Fucking linux....
Why, just why we don't have roll backs and all nice things we have in windows ? 7
7 -
I was setting up a network minutes server. Install, check for updates, reboot, and the grub entries for the os are gone. Atleast I still have memtest
-
So, today, I wanted to try setting up a wireguard VPN server on my little raspberry pi at home. I... expected /some/ issues, but what I found dumbfounded me.
1 - I already had the wireguard package from the unstable branch of the main raspbian repo installed... Huh, okay.
2 - Setting up config was extremely easy... Wow, so the rumors were true. Wireguard really is almost dumb-simple.
3 - Failed to create a network interface? Oh, trouble, here it is! So lets see... modprobe wireguard... Nope. Don't have the module? What?
4 - Reconfigure package to rebuild the module - missing kernel headers? Huh... weird
This was the simple stuff... Then I went down the rabbit hole of the Raspberry Pi ecosystem:
1 - There is the Raspberry Pi Bootloader, that is apparently separate from the Kernel itself. And I didn't seem to have any of the standard linux-image-* installed... What? Weird, yet there I was, running a 4.19.42-v7+ kernel...
2 - No kernel and no headers... What... The... Fuck
3 - Okay, so... Lets just... try to install the latest kernel image then? One apt-get install... It downloaded the image, but during package configuration, it failed because... I didn't have... its headers? What? What for? And if it needs them (for whatever reason), why isn't the headers package as a dependency? Ugh, whatever...
4 - Another apt-get install and... Okay, building the initrd image aaaaand...
FAIL
WHAT. What is it this time!?
Oh... Ran... No more space on device? What? Is /boot independent? Of course it is, it has to be, its a bloody different filesystem
Okay, so, lets che-OH MY GOD WTF.
Its just bloody 45 MBs big! The entire /boot is just 45 MBs large. WHY. THE. FUCK.
This was a default raspbian install from I have no idea when. But... Why. Oh WHY would ANYONE pre-configure /boot to be this incredibly tiny!?
No wonder the new init ramdisk couldn't fit in there! Its already used up from 64%!
Thanks, Raspbian Devs, now I gotta reinstall the whole system because, yes, the /boot is, of course, sector 8192. Just far enough from 2048 that there are *some* sectors free - About 3 MBs.
So what did I try? Remove the partition and recreate it from the very beginning. Only... I never tried in in the past, and okay, kernel doesn't like having the partition where its image resides deleted on the fly, it will not give up FDs pointing there or something.
So now, I have a system I cannot reboot, or it will never boot back up :|
Thanks, Raspbian!
I need to get a cheap 1U somewhere or something T.T1 -
Today wasted around 5 hours installing nginx, apache stills working and keeping listen on 80 port after uninstalling it reboot finally the thing was i dont change the fucking dns of the server and trying to connect to the domain 5 hours later tried to connect to the ip... Fuck my life1
-
Me: Time to work on wife's website.
Server: Unable to Validate DMI.
Me: Reboot.
Server: HAHA no CPU information and still no DMI
Me: Remove drives part from SSD.
Server: HI THERE.
Me: Facepalm's 2
2 -
My remote server and local machine both run Linux and I'm logged in with similarly formed user names. All I had to do was reboot my local machine and I ended up shooting across a `sudo reboot` on my SSH window! 🤯5















































Top Tags
Weekly Rant
View