
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Everyone here ranting about a fucking missing semicolon. I can't remember the last time a missing semicolon was the issue...
You wanna know what's REALLY BALL-BUSTING????
WHEN THE FUCKING 10 y/o LEGACY CODEBASE, CODED BY FUCKING PHP WORDPRESS SCRIPTERS WHO THOUGHT THEY COULD BUILD AN ENTERPRISE SHIT CAUSE ZF2 "LOOKS EASY" AND THEN FILL IT UP WITH SPAGHETTI, IS SO BAD WRITTEN THAT IN ORDER FOR THE PAGE TO RENDER YOU ACTUALLY ****HAVE**** TO DISABLE ERROR REPORTING SO WHENEVER A FUCKING ERROR HAPPENS ON THE TEMPLATE RENDER COMPONENT OF ZEND FRAMESHIT 2, YOU'RE LEFT WITH A FUCKING BLANK PAGE AND NOTHING IS LOGGED TO THE LOG FILE, SO YOUR ONLY OPTION IS DIE() DEBUGGING LINE BY LINE ON THE 1300 LINES PHTML FUCKFEST OF A VIEW THEY HAVE.
MISSING SEMICOLON? YES PLEASE, GIVE ME MORE OF THAT SHIT37 -
Spaces Vs Tabs - A real world case.
So one of the menial tasks I was given here was to take a pretty mock and turn it into an HTML email template. Needless to say, I hate emails and HTML.
After many weeks of trial and error, rejection and tweaks, we're doing our final tests when someone noticed that Google's clients are chopping off the footer and saying "View Full Email".
A few searches yield that Google has a 102KB cut off for email size. We did some checks and found that we were at 104KB. I immediately thought it was my CSS inliner being a little too verbose, but as I went in to edit things, I noticed that the file was intended with spaces!
Now I'm a fan of Silicon Valley, and I recalled an episode from this past season where Richard mentioned something about saving file size by using tabs. I had never really considered that point.
So I went back into VSCode and told it to convert all of the individual templates that make up this giant email to indent with tabs...
The file size dropped from 104kb to 82kb.
I wasn't very polarized on the Tabs vs Spaces debate, but this here has given me a nice real world example as to why tabs rule. 20
20 -
So a coworker wrote this -- a function that returns a view if a specific object exists in the database. Now what would happen said object doesn't exist in the database? Forget about returning false and handling it properly, he decides that the function should print (echo) a zero! Not to mention almost all his if-else blocks prints a fucking zero when the if condition is false (there are 8 of them, if you're asking). Error messages? The hell with those.
He is now the PM btw. I've had enough of this shithole. 14
14 -
A sidebar.
Literally just a sidebar.
And yes, this was in Hell.
Its code was spread across at least 40 files, and it used a bunch of freaking global variables to unfurl accordion sections, hide other sections/items, highlight the active item, etc. These were set (and unset!) in controller actions, so if you didn’t unset one, it remained open and highlighted until another action unset it.
Some of the global variable checks (and permissions checks) were done in the individual views, some outside of the `render` statements that include them. Some of them inherited variables from the parent, some from the controller, some from globals. Getting a view to work was trial and error. Oh, and some had their own inline css, some used css classes.
Subsections were separate views, so were some individual items, both sometimes rendered using shared templates, and all of the views and templates had the exact. same. filename. (They were located in different directories, and thus located automagically via implicit relative paths.) So, it was a virtually endless parade of`render partial => “sidebar”`. Which file does that point to? Good luck figuring it out!
Also, comments in several places said adding a new section required a database migration. I never did figure out why.
Anyway, I discovered this because I had an innocuous-sounding ticket to rearrange the sidebar, group some sections/items under different permissions, move some items to another menu, and nest some others differently.
It took me two bloody weeks, and this was when I was extremely productive every day.
Afterward, I was so disgusted by it that I took a day and removed every trace of the sidebar I could find, and rewrote it. I defined the sidebar in a hash, and wrote a simple recursive builder to generate the markup. It supported optional icons, n-level nesting, automatic highlighting of the current item and all parent nodes, compound and inherited permissions, wrapping of long names, hover and unfurl animations, etc. Took me a couple hundred lines of Ruby at the most, plus about the same of css.
Felt so good to remove that blight.5 -
Online tutorial pet peeves
————————————
My top 10 points of unsolicited ranting/advice to those making video tutorials:
1. Avoid lots of pauses, saying “umm” too much, or other unnecessary redundancy in speech (listen to yourself in a recording)
2. If I can’t understand you at 1.5 - 2x playback speed and you don’t already speak relatively quickly and clearly, I’m probably not going to watch for long (mumbling, inconsistent microphone volume, and background noise/music are frequent culprits)
3. It’s ok to make mistakes in a tutorial, so long as you also fix them in the tutorial (e.g., the code that is missing a semicolon that all of a sudden has one after it compiles correctly — but no mention of fixing it or the compiler error that would have been received the first time). With that said, it’s fine to fix mistakes pertinent to the topic being taught, but don’t make me watch you troubleshoot your non-relevant computer issues or problems created by your specific preferences (e.g., IDE functionality not working as expected when no specific IDE was prescribed for the tutorial)
4. Don’t make me wait on your slow computer to do something in silence—either teach me something while it’s working or edit the video to remove the lull
5. You knew you were recording your screen. Close your email, chat, and other applications that create notifications before recording. Or at least please don’t check them and respond while recording and not edit it out of the video
6. Stay on topic. I’m watching your video to learn about something specific. A little personality is good, but excessive tangents are often a waste of my time
7. [Specific to YouTube] Don’t block my view of important content with annotations (and ads, if within your control)
8. If you aren’t uploading quality HD recordings, enlarge your font! Don’t make me have to guess what character you typed
9. Have a game plan (i.e., objectives) before hitting the record button
10. Remember that it’s easier to rant and complain than to do something constructive. Thank you for spending your time making tutorial videos. It’s better for you to make videos and commit all my pet peeves listed above than to not make videos at all—don’t let one guy’s rant stop you from sharing your knowledge and experience (but if it helps you, you’re welcome—and you just might gain a new viewer!)14 -
The nightmare continues.
Currently dealing with a code review from a “principal” dev (one step above senior), who is unironically called a “legendary dev” by some coworkers. It’s painfully obvious he didn’t read the code, and just started complaining and nitpicking.
It’s full of requests to do things that make absolutely no sense, and would make the code an unmaintainable mess.
• Ex: moving the logic and data collection from the module’s many callers into the module instead of just passing in the data.
• Ex: hiding api endpoint declarations by placing them in the module itself, and using magic instance variables to pass data to it. Basically: using global functions and variables instead of explicit declarations and calls.
• Ex: moving the logic to determine which api endpoint to use, for all callers, into the view.
More comments about methods being “too complex” (barely holds water) right next to comments saying “why are these separate? merge them together!”
Incredulously asking how many times I’m checking permissions and how ridiculous it all is. (The answer? Twice.)
Conflating my “permissions” param and method names with a supposedly forthcoming permissions system overhaul, and saying I shouldn’t use permissions because my code will all have to get rewritten. Even if that were true, and it’s likely not, the ticket still needs to use the current permissions. I can’t just ignore them because they might be rewritten someday.
Requests to revert some code cleanup because the reviewer thought the previous heavily-nested and uncommented versions (with code duplication) were easier to read. Unsurprisingly, he wrote them.
On the same ticket, my boss wants me to remove all styling and clientside validation, debouncing, and error messages from a form. Says “success” and “connection failed” messages are good enough. The form in question sends SMS and email using arbitrary user input for addresses. He also says it shouldn’t be denounced on the server, and doesn’t want me to bother checking permissions. Hello, spam!
Related: the legendary dev reviewer says he can’t think of a reason why we would want to disable the feature for consumers, so I should remove the consumer feature flag.
You can’t make this stuff up.7 -
I'm fixing a security exploit, and it's a goddamn mountain of fuckups.
First, some idiot (read: the legendary dev himself) decided to use a gem to do some basic fucking searching instead of writing a simple fucking query.
Second, security ... didn't just drop the ball, they shit on it and flushed it down the toilet. The gem in question allows users to search by FUCKING EVERYTHING on EVERY FUCKING TABLE IN THE DB using really nice tools, actually, that let you do fancy things like traverse all the internal associations to find the users table, then list all users whose password reset hashes begin with "a" then "ab" then "abc" ... Want to steal an account? Hell, want to automate stealing all accounts? Only takes a few hundred requests apiece! Oooh, there's CC data, too, and its encryption keys!
Third, the gem does actually allow whitelisting associations, methods, etc. but ... well, the documentation actually recommends against it for whatever fucking reason, and that whitelisting is about as fine-grained as a club. You wanna restrict it to accessing the "name" column, but it needs to access both the "site" and "user" tables? Cool, users can now access site.name AND user.name... which is PII and totally leads to hefty fines. Thanks!
Fourth. If the gem can't access something thanks to the whitelist, it doesn't catch the exception and give you a useful error message or anything, no way. It just throws NoMethodErrors because fuck you. Good luck figuring out what they mean, especially if you have no idea you're even using the fucking thing.
Fifth. Thanks to the follower mentality prevalent in this hellhole, this shit is now used in a lot of places (and all indirectly!) so there's no searching for uses. Once I banhammer everything... well, loads of shit is going to break, and I won't have a fucking clue where because very few of these brainless sheep write decent test coverage (or even fucking write view tests), so I'll be doing tons of manual fucking testing. Oh, and I only have a week to finish everything, because fucking of course.
So, in summary. The stupid and lazy (and legendary!) dev fucked up. The stupid gem's author fucked up, and kept fucking up. The stupid devs followed the first fuckup's lead and repeated his fuck up, and fucked up on their own some more. It's fuckups all the fucking way down.20 -
Best part about the covid19 manufactured crisis?
Liquor stores deliver. Worst part about liquor stores delivering? Needing to use their shoddy websites.
I've been using a particular store (Total Wines) since they're cheaper than the rest and have better selection; it's quite literally a large warehouse made to look like a store.
Their website tries really hard to look professional, too, but it's just not. It took me two days to order, and not just from lack of time -- though from working 14 hour days, that's a factor.
Signing up was difficult. Your username is an email address, but you can't use comments because the server 500s, making the ajax call produce a wonderfully ambiguous error message. It also fades the page out like it's waiting on something, but that fade is on top of the error modal too. Similar error with the password field, though I don't remember how I triggered it.
Signing up also requires agreeing to subscribe to their newsletter. it's technically an opt-in, but not opting-in doesn't allow you to proceed. Same with opting-in to receiving a text notification when your order is ready for pickup -- you also opt-in to reciving SMS spam.
Another issue: After signing up, you start to navigate through the paginated product list. Every page change scrolls you to the exact middle of the next page. Not deliberatly; the UI loads first, and the browser gets as close as it can to your previous position -- which was below that as the pagination is at the bottom -- and then the products populate after. But regardless of why, there is no worse place to start because now you must scroll in both directions to view the products. If it stayed at the very bottom, it would at least mean you only need to scroll upwards to look at everything on the page. Minor, but increasingly irritating.
Also, they have like 198 pages of spirits alone because each size is unique entry. A 50ml, 350ml, 500ml, 750ml, 1000ml, and 1750ml bottle of e.g. Tito's vodka isn't one product, it's six. and they're sorted seemingly randomly. I think it's by available stock, looking back.
If you fancy a product, you can click on it for a detail page. Said detail page lists the various sizes in a dropdown, but they're not sorted correctly either, and changing sizes triggers a page reload, which leads to another problem:
if you navigate to more than a few pages within a 10 or so second window, the site accuses you of using browser automation. No captcha here, just a "click me for five seconds" button. However, it (usually) also triggers the check on every other tab you have open after its next nagivation.
That product page also randomly doesn't work. I haven't narrowed it down, but it will randomly decide to start failing, and won't stop failing for hours. It renders the page just fine, then immediately replaces it with a blank page. When it's failing, the only way to interact with the page is a perfectly-timed [esc], which can (and usually does) break all other page functionality, too. Absolutely great when you need to re-add everything from a stale copy of your signed-out cart living in another tab. More on that later. And don't forget to slow down to bypass the "browser automation" check, too!
Oh, and if you're using container tabs, make sure to open new tabs in the SAME container, as any request from the same IP without the login cookie will usually trigger that "browser automation" response, too.
The site also randomly signs you out, but allows you to continue amassing your cart. You'd think this is a good thing until you choose to sign in again... which empties your cart. It's like they don't want to make a sale at all.
The site also randomly forgets your name, replacing it with "null." My screen currently says "Hello, null". Hello, cruft!
It took me two days to order.
Mostly from lack of time, as i've been pulling 14 hour shifts lately trying to get everything done. but the sheer number of bugs certainly wasted most of what little time i had left. Now I definitely need a drink.
But maybe putting up with all of this is worthwhile because of their loyalty program? Apparently if you spend $500, you can take $5 off your next purchase! Yay! 1%! And your points expire! There are three levels; maybe it gets better. Level zero is for everyone; $0 requirement. There are also levels at $500 and $2500. That last one is seriously 5x more than the first paid level. and what does it earn you? A 'free' magazine subscription, 'free' classes (they're usually like $20-$50 iirc), and a 'free' grab bag (a $2.99 value!) twice per month. All for spending $2500. What a steal. It reminds me of Candy Crush's 3-star system where the first two stars are trivial, and the third is usually a difficult stretch goal. But here it's just thinly-veiled manipulation with no benefit.
I can tell they're employing some "smarketing" people with big ideas (read: stolen mistakes), but it's just such a fail.
The whole thing is a fail.7 -
I hate Skype for Business with a passion. It's the most garbage useless chat program imaginable. It can barely send basic text chats without throwing an error, and it can almost never send an image without the upload failing. The fact that it can't even save conversation history for each of your chats within Skype is ridiculous -- it fucking saves the conversation as an email draft in Outlook. Come on Microsoft, why do I have to open a completely separate program to view conversation history?! Skype conversation history should be saved IN SKYPE! Fucking AIM was able to save conversation history. I've tried multiple times to get the company to move to Slack or Teams, and for some reason they think that Skype is a good program and they ignore the fact that it's completely useless. It's 2019, why are we using a program that's built like it's 2009? I swear they haven't updated Skype at all in the last decade20
-
Is it just me who sees this? JS development in a somewhat more complex setting (like vue-storefront) is just a horrible mess.
I have 10+ experience in java, c# and python, and I've never needed more than a a few hours to get into a new codebase, understanding the overall system, being able to guess where to fix a given problem.
But with JS (and also TS for that matter) I'm at my limits. Most of the files look like they don't do anything. There seems to be no structure, both from a file system point of view, nor from a code point of view.
It start with little things like 300 char long lines including various lambdas, closures and ifs with useless variables names, over overly generic and minified method/function names to inconsistent naming of files, classes and basically everything else.
I used to just set a breakpoint somewhere in my code (or in a compiled dependency) wait this it is being hit and go back and forth to learn how the system state changes.
This seems to be highly limited in JS. I didn't find the one way to just being able to debug, everything that is. There are weird things like transpilers, compiler, minifiers, bablers and what not else. There is an error? Go f... yourself ...
And what do I find as the number one tipp all across the internet? Console.log?? are you kidding me, sure just tell me, your kidding me right?
If I would have to describe the JS world in one word, I would use "inconsistency". It's all just a pain in the ass.
I remember when I switcher from VisualStudio/C# to Eclipse/Java I felt like traveling back in time for about 10 years. Everyting seemd so ... old-schoolish, buggy, weird.
When I now switch from java to JS it makes me feel the same way. It's all so highly unproductive, inconsistent, undeterministic, cobbled together.
For one inconveinience the JS communinity seems to like to build huge shitloads of stuff around it, instead of fixing the obvious. And noone seems to see that.
It's like they are all blinded somehow. Currently I'm also trying to implement a small react app based on react-admin. The simplest things to develop and debug are a nightmare. There is so much boilerplate that to write that most people in the internet just keep copying stuff, without even trying to understand what it actually does.
I've always been a guy that tries to understand what the fuck this code actuall does. And for most of the parts I just thing, that the stuff there is useless or could be done in a way more readable way. But instead, all the devs out there just seem to chose the "copy and fix somehow-ish" way.
I'm all in for component-izing stuff. I like encapsulation, I'm a OOP guy by heart. But what react and similar frameworks do is just insane. It's just not right (for some part).
Especially when you have to remember so much stuff that is just mechanics/boilerplate without having any actual "business logical function".
People always say java is so verbose. I don't think it is, there is so few syntax that it almost reads like a prose story. When I look at JS and TS instead, I'm overwhelmed by all the syntax, almost wondering every second line, what the actual fuck this could mean. The boilerplate/logic ration seems way to off ..
So it really makes me wonder, if all you JS devs out there are just so used to that stuff, that you cannot imagine how it could be done better? I still remember my C# days, but I admin that I just got used to java. So I can somehow understand that all. But JS is just another few levels less deeper.
But maybe I'm just lazy and too old ...4 -
I propose that the study of Rust and therefore the application of said programming language and all of the technology that compromises it should be made because the language is actually really fucking good. Reading and studying how it manages to manipulate and otherwise use memory without a garbage collector is something to be admired, illuminating in its own accord.
BUT going for it because it is a "beTter C++" should not constitute a basis for it's study.
Let me expand through anecdotal evidence, which is really not to be taken seriously, but at the same time what I am using for my reasoning behind this, please feel free to correct me if I am wrong, for I am a software engineer yes, I do have academic training through a B.S in Computer Science yes, BUT my professional life has been solely dedicated to web development, which admittedly I do not go on about technical details of it with you all because: I am not allowed to(1) and (2)it is better for me to bitch and shit over other petty development related details.
Anecdotal and otherwise non statistically supported evidence: I have seen many motherfuckers doing shit in both C and C++ that ADMIT not covering their mistakes through the use of a debugger. Mostly because (A) using a debugger and proper IDE is for pendejos and debugging is for putos GDB is too hard and the VS IDE is waaaaaa "I onlLy NeeD Vim" and (B) "If an error would have registered then it would not have compiled no?", thus giving me the idea that the most common occurrences of issues through the use of the C father/son languages come from user error, non formal training in the language and a nice cusp of "fuck it it runs" while leaving all sorts of issues that come from manipulating the realm of the Gods "memory".
EVERY manual, book, coming all the way back to the K&C book talks about memory and the way in which developers of these 2 languages are able to manipulate and work on it. EVERY new standard of the ISO implementation of these languages deals, through community effort or standard documentation about the new items excised through features concerning MODERN (meaning, no, the shit you learned 20 years ago won't fucking cut it) will not cut it.
THUS if your ass is not constantly checking what the scalpel of electrical/circuitry/computational representation of algorithms CONDONES in what you are doing then YOU are the fucking problem.
Rust is thus no different from the original ideas of the developers behind Go when stating that their developers are not efficient enough to deal with X language, Rust protects you, because it knows that you are a fucking moron, so the compiler, advanced, and well made as it is, will give you warnings of your own idiotic tendencies, which would not have been required have you not been.....well....a fucking idiot.
Rust is a good language, but I feel one that came out from the necessity of people writing system level software as a bunch of fucking morons.
This speaks a lot more of our academic endeavors and current documentation than anything else. But to me DEALING with the idea of adapting Rust as a better C++ should come from a different point of view.
Do I agree with Linus's point of view of C++? fuck no, I do not, he is a kernel engineer, a damn good one at that regardless of what Dr. Tanenbaum believes(ed) but not everyone writes kernels, and sometimes that everyone requires OOP and additions to the language that they use. Else I would be a fucking moron for dabbling in the dictionary of languages that I use professionally.
BUT in terms of C++ being unsafe and unsecured and a horrible alternative to Rust I personaly do not believe so. I see it as a powerful white canvas, in which you are able to paint software to the best of your ability WHICH then requires thorough scrutiny from the entire team. NOT a quick replacement for something that protects your from your own stupidity BY impending the use of what are otherwise unknown "safe" features.
To be clear: I am not diminishing Rust as the powerhouse of a language that it is, myself I am quite invested in the language. But instead do not feel the reason/need before articles claiming it as the C++ killer.
I am currently heavily invested in C++ since I am trying a lot of different things for a lot of projects, and have been able to discern multiple pain points and unsafe features. Mainly the reason for this is documentation (your mother knows C++) and tooling, ide support, debugging operations, plethora of resources come from it and I have been able to push out to my secret project a lot of good dealings. WHICH I will eventually replicate with Rust to see the main differences.
Online articles stating that one will delimit or otherwise kill the other is well....wrong to me. And not the proper approach.
Anyways, I like big tits and small waists.14 -
Warning: I code just for fun.
Today I finished a website and I asked to my friends to tell me what they think about it saying that it wasn't yet properly responsive and that could be some error, so I asked if they could use the computer to view it and all of them sent to me screenshots of the website on mobile.
I hate them.
P.S. Sorry for my english...8 -
So ok here it is, as asked in the comments.
Setting: customer (huge electronics chain) wants a huge migration from custom software to SAP erp, hybris commere for b2b and ... azure cloud
Timeframe: ~10 months….
My colleague and me had the glorious task to make the evaluation result of the B2B approval process (like you can only buy up till € 1000, then someone has to approve) available in the cart view, not just the end of the checkout. Well I though, easy, we have the results, just put them in the cart … hmm :-\
The whole thing is that the the storefront - called accelerator (although it should rather be called decelerator) is a 10-year old (looking) buggy interface, that promises to the customers, that it solves all their problems and just needs some minor customization. Fact is, it’s an abomination, which makes us spend 2 months in every project to „ripp it apart“ and fix/repair/rebuild major functionality (which changes every 6 months because of „updates“.
After a week of reading the scarce (aka non-existing) docs and decompiling and debugging hybris code, we found out (besides dozends of bugs) that this is not going to be easy. The domain model is fucked up - both CartModel and OrderModel extend AbstractOrderModel. Though we only need functionality that is in the AbstractOrderModel, the hybris guys decided (for an unknown reason) to use OrderModel in every single fucking method (about 30 nested calls ….). So what shall we do, we don’t have an order yet, only a cart. Fuck lets fake an order, push it through use the results and dismiss the order … good idea!? BAD IDEA (don’t ask …). So after a week or two we changed our strategy: create duplicate interface for nearly all (spring) services with changed method signatures that override the hybris beans and allow to use CartModels (which is possible, because within the super methods, they actually „cast" it to AbstractOrderModel *facepalm*).
After about 2 months (2 people full time) we have a working „prototype“. It works with the default-sample-accelerator data. Unfortunately the customer wanted to have it’s own dateset in the system (what a shock). Well you guess it … everything collapsed. The way the customer wanted to "have it working“ was just incompatible with the way hybris wants it (yeah yeah SAP, hybris is sooo customizable …). Well we basically had to rewrite everything again.
Just in case your wondering … the requirements were clear in the beginning (stick to the standard! [configuration/functinonality]). Well, then the customer found out that this is shit … and well …
So some months later, next big thing. I was appointed technical sublead (is that a word)/sub pm for the topics‚delivery service‘ (cart, delivery time calculation, u name it) and customerregistration - a reward for my great work with the b2b approval process???
Customer's office: 20+ people, mostly SAP related, a few c# guys, and drumrole .... the main (external) overall superhero ‚im the greates and ur shit‘ architect.
Aberage age 45+, me - the ‚hybris guy’ (he really just called me that all the time), age 32.
He powerpoints his „ tables" and other weird out of this world stuff on the wall, talks and talks. Everyone is in awe (or fear?). Everything he says is just bullshit and I see it in the eyes of the others. Finally the hybris guy interrups him, as he explains the overall architecture (which is just wrong) and points out how it should be (according to my docs which very more up to date. From now on he didn't just "not like" me anymore. (good first day)
I remember the looks of the other guys - they were releaved that someone pointed that out - saved the weeks of useless work ...
Instead of talking the customer's tongue he just spoke gibberish SAP … arg (common in SAP land as I had to learn the hard way).
Outcome of about (useless) 5 meetings later: we are going to blow out data from informatica to sap to azure to datahub to hybris ... hmpf needless to say its fucking super slow.
But who cares, I‘ll get my own rest endpoint that‘ll do all I need.
First try: error 500, 2. try: 20 seconds later, error message in html, content type json, a few days later the c# guy manages to deliver a kinda working still slow service, only the results are wrong, customer blames the hybris team, hmm we r just using their fucking results ...
The sap guys (customer service) just don't seem to be able to activate/configure the OOTB odata service, so I was told)
Several email rounds, meetings later, about 2 months, still no working hybris integration (all my emails with detailed checklists for every participent and deadlines were unanswered/ignored or answered with unrelated stuff). Customer pissed at us (god knows why, I tried, I really did!). So I decide to fly up there to handle it all by myself16 -
In vulkan we don't say it works we say
VUID-vkAcquireNextImageKHR-fence-01287(ERROR / SPEC): msgNum: 207921847 - Validation Error: [ VUID-vkAcquireNextImageKHR-fence-01287 ] Object 0: handle = 0xe7e6d0000000000f, type = VK_OBJECT_TYPE_FENCE; | MessageID = 0xc64a2b7 | vkAcquireNextImageKHR(): VkFence 0xe7e6d0000000000f[] is already in use by another submission. The Vulkan spec states: If fence is not VK_NULL_HANDLE it must be unsignaled and must not be associated with any other queue command that has not yet completed execution on that queue (https://vulkan.lunarg.com/doc/view/...)
Objects: 1
[0] 0xe7e6d0000000000f, type: 7, name: NULL
VUID-vkAcquireNextImageKHR-swapchain-01802(ERROR / SPEC): msgNum: 1050126472 - Validation Error: [ VUID-vkAcquireNextImageKHR-swapchain-01802 ] Object 0: handle = 0xcb3ee80000000007, type = VK_OBJECT_TYPE_SWAPCHAIN_KHR; | MessageID = 0x3e97a888 | vkAcquireNextImageKHR: Application has already previously acquired 1 image from swapchain. Only 1 is available to be acquired using a timeout of UINT64_MAX (given the swapchain has 2, and VkSurfaceCapabilitiesKHR::minImageCount is 2). The Vulkan spec states: If the number of currently acquired images is greater than the difference between the number of images in swapchain and the value of VkSurfaceCapabilitiesKHR::minImageCount as returned by a call to vkGetPhysicalDeviceSurfaceCapabilities2KHR with the surface used to create swapchain, timeout must not be UINT64_MAX (https://vulkan.lunarg.com/doc/view/...)
Objects: 1
[0] 0xcb3ee80000000007, type: 1000001000, name: NULL
and I think that's beautiful10 -
endor's first magical adventures with PostgreSQL
"Alright, got the docker image up and running, and I'm connected to the db, both from console and from Datagrip! Cool, let's get started with the tutorial!"
*cue montage of me using Datagrip to create my first schema, then the first table, then insert a bunch of data to try things out*
"Cool, now let's see if I can view my data from the console"
db1-# select * from my_schema.table1
db1-# [nothing]
"*Ahem*, I said:"
db1-# select * from my_schema.table1
db1-# [nothing]
db1-# select * from my_schema.table1
db1-# [cricket noises]
"Wut, why can't I see the data that I inserted? Wtf is going on?"
*30 minutes later*
"Alright, I have no idea what's going on, so let's try inserting the data from console and see if Datagrip can see it"
db1-# insert into my_schema.table1(id, name, field2, field3) values (1, 'Mike', null, 123), (2, 'Jake', 0, 456);
ERROR: syntax error at or near "SELECT"
LINE 2: SELECT
^
"Wait, what?"
db1-# insert into my_schema.table1(id, name, field2, field3) values (1, 'Mike', null, 123), (2, 'Jake', 0, 456);
INSERT 0 2
"Wtf? Haaang on... "
db1-# select * from my_schema.table1;
id | name | field2 | field3
----+------+--------+--------
1 | Mike | | 123
2 | Jake | 0 | 456
1 | Mike | | 123
2 | Jake | 0 | 456
(4 rows)
*eye twitches*4 -
A few days ago PM started asking me once a day when we will have fixed an error he saw at customer site.
I always tell him that it is not a software error, just missing data. I try to explain the issue and that the root cause is the incomplete data given by the customer.
Then he says he will talk with the data import guys if they can fix something and I tell him that from my point of view the data import is fine, but the customer has to provide a full dataset and the "error" will vanish immediately.
He walks to the data import colleague anyway and gets told that everything is ok with the import.
Next day he appears at my desk to tell me that the import seems ok and asks me how we could fix the error and I tell him that it's not a software issue, try to explain it...
I wonder how long he will keep up on it.3 -
!rant
Need some opinions. Joined a new company recently (yippee!!!). Just getting to grips with everything at the minute. I'm working on mobile and I will be setting up a new team to take over a project from a remote team. Looking at their iOS and Android code and they are using RxSwift and RxJava in them.
Don't know a whole lot about the Android space yet, but on iOS I did look into Reactive Cocoa at one point, and really didn't like it. Does anyone here use Rx, or have an opinion about them, good or bad? I can learn them myself, i'm not looking for help with that, i'm more interested in opinions on the tools themselves.
My initial view (with a lack of experience in the area):
- I'm not a huge fan of frameworks like this that attempt to change the entire flow or structure of a language / platform. I like using third party libraries, but to me, its excessive to include something like this rather than just learning the in's / out's of the platform. I think the reactive approach has its use cases and i'm not knocking the it all together. I just feel like this is a little bit of forcing a square peg into a round hole. Swift wasn't designed to work like that and a big layer will need to be added in, in order to change it. I would want to see tremendous gains in order to justify it, and frankly I don't see it compared to other approaches.
- I do like the MVVM approach included with it, but i've easily managed to do similar with a handful of protocols that didn't require a new architecture and approach.
- Not sure if this is an RxSwift thing, or just how its implemented here. But all ViewControllers need to be created by using a coordinator first. This really bugs me because it means changing everything again. When I first opened this app, login was being skipped, trying to add it back in by selecting the default storyboard gave me "unwrapping a nil optional" errors, which took a little while to figure out what was going on. This, to me, again is changing too much in the platform that even the basic launching of a screen now needs to be changed. It will be confusing while trying to build a new team who may or may not know the tech.
- I'm concerned about hiring new staff and having to make sure that they know this, can learn it or are even happy to do so.
- I'm concerned about having a decrease in the community size to debug issues. Had horrible experiences with this in the past with hybrid tech.
- I'm concerned with bugs being introduced or patterns being changed in the tool itself. Because it changes and touches everything, it will be a nightmare to rip it out or use something else and we'll be stuck with the issue. This seems to have happened with ReactiveCocoa where they made a change to their approach that seems to have caused a divide in the community, with people splitting off into other tech.
- In this app we have base Swift, with RxSwift and RxCocoa on top, with AlamoFire on top of that, with Moya on that and RxMoya on top again. This to me is too much when only looking at basic screens and networking. I would be concerned that moving to something more complex that we might end up with a tonne of dependencies.
- There seems to be issues with the server (nothing to do with RxSwift) but the errors seem to be getting caught by RxSwift and turned into very vague and difficult to debug console logs. "RxSwift.RxError error 4" is not great. Now again this could be a "way its being used" issue as oppose to an issue with RxSwift itself. But again were back to a big middle layer sitting between me and what I want to access. I've already had issues with login seeming to have 2 states, success or wrong password, meaning its not telling the user whats actually wrong. Now i'm not sure if this is bad dev or bad tools, but I get a sense RxSwift is contributing to it in some fashion, at least in this specific use of it.
I'll leave it there for now, any opinions or advice would be appreciated.18 -
I am currently looking for a DAW (Digital Audio Workstation), because my music projects are starting to get a little too complex for Audacity.
So I started looking for a good, easy-to-learn, ideally free program, and quickly learned that Avid now has a free version of Pro Tools called First.
So I go to their site and fill out the registration form to get the download. In addition to creating an account with Avid, you also need to create one with iLok, which apparently has something to do with how they manage their licenses. Kinda overkill for a free program, but okay...
I download the program (about 3gigs...), install it and try to start it. It gives me an error message about missing some service. Okay? I'm confused because I notice that an 'Application Manager' service has appeared in my tray, and when I open that I can log into my new account just fine. But it still doesn't work.
There's a link in the error message to the iLok website, and it looks like ai need to dowload and install another component. Why didn't that get installed with the program if it's required?
Hmm...
So I go to the iLok site, download it and install it. Pro Tools First still won't start. I realize that the PTF installer asked me to reboot, which I didn't do because: a) I always have a lot of windows open, and b) How often is a reboot ACTUALLY required? Why would you need to reboot?
So I (begrudgingly) reboot, and now the program seems to start initializing... but then it throws an error message about some plugin that it can't load because it doesn't work for the 64 bit version. Then... why are you even looking for it?
And then it says something like: 'I can't handle that, I'm just gonna shut down'.
What?
I try starting it again. Same error appears, but then it gets past it this time... Only to throw another error message about something else it can't load, and therefore it must shut down.
Deep breath.
Third time is the charm, the program actually made it to the project create/load screen! Huzzah!
So I look around a bit, but don't do much. It doesn't seem too intuitive to me, so I start watching some tutorials on YouTube from Avid themselves. It's a little late by now, so I don't get my hands dirty that day.
Next time I want to try out the program I start it up, still get error messages, but it does seem to initialize okay. But then the 'Create project' button doesn't react when I press it.
It turns out that the program takes a looong time to log in to the avid account, even though the manager service is running and logged in...
When it finally logs on I create a new blank project, but it doesn't ask me where to save it to. I see there is a counter saying 1/3 and looking around I find some info about 'cloud based projects'.
It would seem that this program only supports saving projects to the cloud, and you get only 3 projects total. Three. THREE?
Ahem...
I add an instrument track to my new project and select the one and only plugin, which is a synth. I don't see the plugin window, like in the tutorials I watched. I fiddle around with the windows, but I only manage to get the layout fucked up. There's a handy 'Window' menu, but none of the options resets the view. The main window is now sporting a WINDOWS FUCKING 7 BORDER! And partially blocking the view of the top menu.
Blaaargh!
Frustrated, I shut the program down and restart it. I now select one of the project templates (after waiting for it to LOG IN AGAIN!) in the hope that I might have a bit more luck with that starting point.
But when the template has loaded, out of nowhere, the program goes from maximized to windowed mode! And the fucking Win7 border is back again, still messing with the main menu!
FFS!
I get the sucker maximized again and select one of the synth tracks, and Lo and Behold! The synth plugin window actually shows up! But of course there is no sound produced when I play, neither with the keyboard or my midi keyboard.
Oh no, that would have been too easy.
I see some the meters moving when I play, but no sound is produced. I check the options menu, but find out nothing useful except for the fact that the program only support 48kHz sample rate. That's pretty disappointing when you have a 192kHz/24bit soundcard.
I'm done. This piece of shit software is NOT for me. It's bloated, complicated to sign up for and install, extremely limited and buggy as hell!
The final insult is that it takes 5 minutes to uninstall because there is no uninstall option in the so-called 'Application Manager' (of course fucking not!), and doing it through Programs & Features there are 5 (FIVE!!) different apps and services to uninstall, one by one.
0/10, would not recommend.11 -
Ok now I'm gonna tell you about my "Databases 2" exam. This is gonna be long.
I'd like to know if DB designers actually have this workflow. I'm gonna "challenge" the reader, but I'm not playing smartass. The mistakes I point out here are MY mistakes.
So, in my uni there's this course, "Databases 2" ("Databases 1" is relational algebra and theoretical stuff), which consist in one exercise: design a SQL database.
We get the description of a system. Almost a two pages pdf. Of course it could be anything. Here I'm going to pretend the project is a YouTube clone (it's one of the practice exercises).
We start designing a ER diagram that describes the system. It must be fucking accurate: e.g. if we describe a "view" as a relationship between the entities User and Video, it MUST have at least another attribute, e.g. the datetime, even if the description doesn't say it. The official reason?
"The ER relationship describes a set of couples. You can not have two elements equal, thus if you don't put any attribute, it means that any user could watch a video only once. So you must put at least something else."
Do you get my point? In this phase we're not even talking about a "database", this is an analysis phase.
Then we describe the type dictionary. So far so good, we just have to specify the type of any attribute.
And now... Constraints.
Oh my god the constraints. We have to describe every fucking constraint of our system. In FIRST ORDER LOGIC. Every entity is a set, and Entity(e) means that an element e belongs to the set Entity. "A user must leave a feedback after he saw a video" becomes like
For all u,v,dv,df,f ( User(u) and Video(v) and View(u, v, dv) and feedback(u, v, f) ) ---> dv < df
provided that dv and df are the datetimes of the view and the feedback creation (it is clear in the exercise, here seems kinda cryptic)
Of course only some of the constraints are explicitly described. This one, for example, was not in the text. If you fail to mention any "hidden" constraint, you lose a lot of points. Same thing if you not describe it correctly.
Now it's time for use cases.
You start with the usual stickman diagram. So far so good.
Then you have to describe their main functions.
In first order logic. Yes.
So, if you got the point, you may think that the following is correct to get "the average amount of feedback values on a single video" (1 to 5, like the old YT).
(let's say that feedback is a relationship with attribute between User and Video
getAv(Video v): int
Let be F = { va | feedback(v, u, va) } for any User u
Let av = (sum forall f in F) / | F |
return av
But nope, there's an error here. Can you spot it (I didn't)?
F is a set. Sets do not have duplicates! So, the F set will lose some feedback values! I can not define that as a simple set!
It has to be a set of couples, like (v, u), where v is the value and u the user; this way we can have duplicate feedback values in our set.
This concludes the analysis phase. Now, the design.
Well we just refactor everything we have done until now. Is-a relations become relationships, many-to-many relationships get an "association entity" between them, nothing new.
We write down on paper every SQL statement to build any table, entity or not. We write down every possible primary key or foreign key. The constraint that are not natively satisfied by SQL and/or foreign keys become triggers, and so on.
This exam is considered the true nightmare at our department. I just love it.
Now my question is, do actually DB designers follow this workflow? Or is this just a bloody hard training in Pai Mei style?6 -
Holy shit firefox, 3 retarded problems in the last 24h and I haven't fixed any of them.
My project: an infinite scrolling website that loads data from an external API (CORS hehe). All Chromium browsers of course work perfectly fine. But firefox wants to be special...
(tested on 2 different devices)
(Terminology: CORS: a request to a resource that isn't on the current websites domain, like any external API)
1.
For the infinite scrolling to work new html elements have to be silently appended to the end of the page and removed from the beginning. Which works great in all browsers. BUT IF YOU HAPPEN TO BE SCROLLING DURING THE APPENDING & REMOVING FIREFOX TELEPORTS YOU RANDOMLY TO THE END OR START OF PAGE!
Guess I'll just debug it and see what's happening step by step. Oh how wrong I was. First, the problem can't be reproduced when debugging FUCK! But I notice something else very disturbing...
2.
The Inspector view (hierarchical display of all html elements on the page) ISN'T SHOWING THE TRUE STATE OF THE DOM! ELEMENTS THAT HAVE JUST BEEN ADDED AREN'T SHOWING UP AND ELEMENT THAT WERE JUST REMOVED ARE STILL VISIBLE! WTF????? You have to do some black magic fuckery just to get firefox to update the list of DOM elements. HOW AM I SUPPOSED TO DEBUG MY WEBSITE ON FIREFOX IF IT'S SHOWING ME PLAIN WRONG DATA???!!!!
3.
During all of this I just randomly decided to open my website in private (incognito) mode in firefox. Huh what's that? Why isn't anything loading and error are thrown left and right? Let's just look at the console. AND IT'S A FUCKING CORS ERROR! FUCK ME! Also a small warning says some URLs have been "blocked because content blocking is enabled." Content Blocking? What is that? Well it appears to be a supper special supper privacy mode by firefox (turned on automatically in private mode), THAT BLOCKS ALL CORS REQUESTS, THAT MAY OR MAY NOT DO SOME TRACKING. AN API THAT 100% CORS COMPLIANT CAN'T BE USED IN FIREFOXs PRIVATE MODE! HOW IS THE END USER SUPPOSED TO KNOW THAT??? AND OF COURSE THE THROWN EXCEPTION JUST SAYS "NETWORK ERROR". HOW AM I SUPPOSED TO TELL THE USER THAT FIREFOX HAS A FEAUTRE THAT BREAKS THE VERY BASIS OF MY WEBSITE???
WHY CAN'T YOU JUST BE NORMAL FIREFOX??????????????????
I actually managed to come up with fix for 1. that works like < 50% of the time -_-5 -
I feel stupid to ask this here
I am getting this error in flask
view didn't return a valid response error. The function either returned None or ended without a return statement.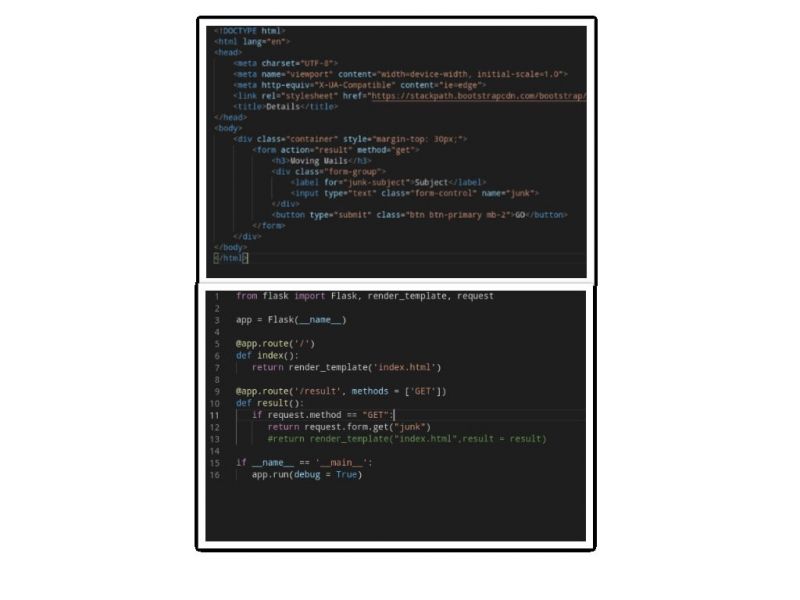 11
11 -
I need some opinions on Rx and MVVM. Its being done in iOS, but I think its fairly general programming question.
The small team I joined is using Rx (I've never used it before) and I'm trying to learn and catch up to them. Looking at the code, I think there are thousands of lines of over-engineered code that could be done so much simpler. From a non Rx point of view, I think we are following some bad practises, from an Rx point of view the guys are saying this is what Rx needs to be. I'm trying to discuss this with them, but they are shooting me down saying I just don't know enough about Rx. Maybe thats true, maybe I just don't get it, but they aren't exactly explaining it, just telling me i'm wrong and they are right. I need another set of eyes on this to see if it is just me.
One of the main points is that there are many places where network errors shouldn't complete the observable (i.e. can't call onError), I understand this concept. I read a response from the RxSwift maintainers that said the way to handle this was to wrap your response type in a class with a generic type (e.g. Result<T>) that contained a property to denote a success or error and maybe an error message. This way errors (such as incorrect password) won't cause it to complete, everything goes through onNext and users can retry / go again, makes sense.
The guys are saying that this breaks Rx principals and MVVM. Instead we need separate observables for every type of response. So we have viewModels that contain:
- isSuccessObservable
- isErrorObservable
- isLoadingObservable
- isRefreshingObservable
- etc. (some have close to 10 different observables)
To me this is overkill to have so many streams all frequently only ever delivering 1 or none messages. I would have aimed for 1 observable, that returns an object holding properties for each of these things, and sending several messages. Is that not what streams are suppose to do? Then the local code can use filters as part of the subscriptions. The major benefit of having 1 is that it becomes easier to make it generic and abstract away, which brings us to point 2.
Currently, due to each viewModel having different numbers of observables and methods of different names (but effectively doing the same thing) the guys create a new custom protocol (equivalent of a java interface) for each viewModel with its N observables. The viewModel creates local variables of PublishSubject, BehavorSubject, Driver etc. Then it implements the procotol / interface and casts all the local's back as observables. e.g.
protocol CarViewModelType {
isSuccessObservable: Observable<Car>
isErrorObservable: Observable<String>
isLoadingObservable: Observable<Void>
}
class CarViewModel {
isSuccessSubject: PublishSubject<Car>
isErrorSubject: PublishSubject<String>
isLoadingSubject: PublishSubject<Void>
// other stuff
}
extension CarViewModel: CarViewModelType {
isSuccessObservable {
return isSuccessSubject.asObservable()
}
isErrorObservable {
return isSuccessSubject.asObservable()
}
isLoadingObservable {
return isSuccessSubject.asObservable()
}
}
This has to be created by hand, for every viewModel, of which there is one for every screen and there is 40+ screens. This same structure is copy / pasted into every viewModel. As mentioned above I would like to make this all generic. Have a generic protocol for all viewModels to define 1 Observable, 1 local variable of generic type and handle the cast back automatically. The method to trigger all the business logic could also have its name standardised ("load", "fetch", "processData" etc.). Maybe we could also figure out a few other bits too. This would remove a lot of code, as well as making the code more readable (less messy), and make unit testing much easier. While it could never do everything automatically we could test the basic responses of each viewModel and have at least some testing done by default and not have everything be very boilerplate-y and copy / paste nature.
The guys think that subscribing to isSuccess and / or isError is perfect Rx + MVVM. But for some reason subscribing to status.filter(success) or status.filter(!success) is a sin of unimaginable proportions. Also the idea of multiple buttons and events all "reacting" to the same method named e.g. "load", is bad Rx (why if they all need to do the same thing?)
My thoughts on this are:
- To me its indentical in meaning and architecture, one way is just significantly less code.
- Lets say I agree its not textbook, is it not worth bending the rules to reduce code.
- We are already breaking the rules of MVVM to introduce coordinators (which I hate, as they are adding even more unnecessary code), so why is breaking it to reduce code such a no no.
Any thoughts on the above? Am I way off the mark or is this classic Rx?16 -
just found out a vulnerability in the website of the 3rd best high school in my country.
TL;DR: they had burried in some folders a c99 shell.
i am a begginer html/sql/php guy and really was looking into learning a bit here and there about them because i really like problem solving and found out ctfs mainly focus on this part of programming. i am a c++ programmer which does school contest like programming problems and i really enjoy them.
now back on topic.
with this urge to learn more web programming i said to myself what other method to learn better than real life sites! so i did just that. i first checked my school site. right click. inspect element. it seemed the site was made with wordpress. after looking more into the html code for the site i concluded all the images and files i could see on the site were from a folder on the server named 'wp-content/uploads'. i checked the folder. and here it got interesting. i did a get request on the site. saw the details. then i checked the site. bingo! there are 3 folders named '2017', '2018', '2019'. i said to myself: 'i am god.'
i could literally see all the announcements they have made from 2017-2019. and they were organised by month!!! my curiosity to see everything got me to the final destination.
with this adrenaline i thought about another site. in my city i have the 3rd most acclaimed high school in the country. what about checking their security?
so i typed the web address. looked around. again, right click, inspect element and looked around the source code. this time i was more lucky. this site is handmade!!! i was soooo happy because with my school's site i was restricted with what they have made with wordpress and i don't have much experience with it.
amd so i began looking what request the site made for the logos and other links. it seemed all the other links on the site were with this format: www.site.com/index.php?home. and i was very confused and still am. is this referencing some part of the site in the index.php file? is the whole site written inside the index.php file and with the question mark you just get to a part of the site? i don't really get it.
so nothing interesting inside the networking tab, just some stylesheets for the site's design i guess. i switched to the debugger tab and holy moly!! yes, it had that tree structure. very familiar. just like a project inside codeblocks or something familiar with it. and then it clicked me. there was the index.php file! and there was another folder from which i've seen nothing from the network tab. i finally got a lead!! i returned in the network tab, did a request to see the spgm folder and boooom a site appeared and i saw some files and folders from 2016. there was a spgm.js file and a spgm.php file. there was a contrib, flavors, gal and lang folders. then it once again clicked me! the lang folder was las updated this year in february. so i checked the folder and there were some files named lang with the extension named after their language and these files were last updated in 2016 so i left them alone. but there was this little snitch, this little 650K file named after the name of the school's site with the extension '.php' aaaaand it was last modified this year!!!! i was so excited! i thought i found a secret and different design of the site or something completely else! i clicked it and at first i was scared there was this black/red theme going on my screen and something was a little odd. there were no school announcements or event, nononoooo. this was still a tree structured view. at the top of the site it's written '!c99Shell v. 1.0...'
this was a big nono. i saw i could acces all kinds of folders. then i switched to the normal school website and tried to access a folder i have seen named userfiles and got a 403 forbidden error. wopsie. i then switched to the c99 shell website and tried to access the userfiles folder and my boy showed all of its contents. it was nakeeed naked. like very naked. and in the userfiles folder there were all, but i mean ALL files and folders they have on the server. there were a file with the salary of each job available in the school. some announcements. there was a list with all the students which failed classes. there were folders for contests they held. it was an absolute mess and i couldn't believe it.
i stopped and looked at the monitor. what have i done? just to learn some web programming i just leaked the server of the 3rd most famous high school in my country. image a black hat which would have seriously caused more damage. currently i am writing an email to the school to updrage their security because it is reaaaaly bad.
and the journy didn't end here. i 'hacked' the site 2 days ago and just now i thought about writing an email to the school. after i found i could access the WHOLE server i searched for the real attacker so if you want to knkw how this one went let me know in the comments.
sorry for the long post, but couldn't held it anymore13 -
Worst was with ionic and ios. Havent really worked with either and got mac that wasnt updated in ages and also they didnt give charger. Dealing with sudos and not using sudos then trying to work with xcode and free licenses took me a good time until i got first successful build for iPad. Biggest time consuming mistake was that i had to logout of itunes before i could make another account. It only gave me error and said try again later. Made me furious but after i got setup working everything worked quite nicely. Loved the safari developer view.5
-
Has any of you reached a point that you want to resign from work because of a client?
We are dealing with a client at work that uses the app for prototyping instead of making designers create wireframe, imagine the amount of code to write,edit, remove, write it again and yet there is always something isn't right from the client point of view.
What is even worse backend guys screw the server and I am the one to be blamed for errors: 5xx
I even get blamed for error 400 (bad request) when that request passes tests but out of a sudden server returns 400, when you hit refresh the exact same moment of error and server decides to return data and stop throwing error 400.
I also get blamed for server fails to return data from a search endpoint, and if server throws 403 for a public endpoint.
This isn't a rant or getting out of my system but I need opinions, I've been working on this project for a year, with complete mess from either client or backend team, if any of you is instead of me, what would you do?
I'm not a complete guy either, but that situation is just beyond my abilities to handle.6 -
Set up an account on cPanel to show the client their final product. Set the bandwidth limit to a low number so that the client can only view the website once and so that if something is not right, I can blame the bandwidth error.
After the client reported an issue, fixed it before resetting bandwidth limit. -
Heck yeah,
So an old Ionic 3 project wont work on the newest CLI.
I check around for the error, update some dependencies, sure enough it starts working again, all is great or so I thought.
Later something weird starts happening, upon pushing a new view on the navCtrl, the navParams are null on the next view.
I later find out that navCtrl is becoming navParams just on the first bit of the view loading, so I do a dirty fix just to keep working on the functionality from my browser, I know very well this will cause problems later on, this is just so I can keep working on functionality.
I finish all of the functionality and I'm ready to compile for android, I run my script, the dirty fix comes to bite my butt now.
I remove the dirty fix hoping for it to work just well on the apk.
Now gradle doesn't find ddmlib.jar, some 15 minutes of troubleshooting do nothing.
Fuck it, I'll just create a new project from the CLI and drag all the code there so that navParams work as expected.
Sorry Ionic, but the world is not our oyster when subtle changes in dependencies produce such unexpected behaviour, with some fucking view parameters!.
I'm looking forward to get done with all the current projects to jump back to native.1 -
Wow, I thought Australia's subjects were up-to date with modern technology, but as my year 11 IPT course has proven... No.
Genuine Questions from it:
• Where are Web pages stored?
Most web pages are dynamically generated, so... RAM?
•Locate one webpage that uses ASP. Save a copy of this webpage (file name must = asp.mht)
Chrome Doesn't Even Support that as a save able file format any more!!!!
•Visit the webpage [error 404 anyway why write it]
Wow I can click hyperlinks I thought it was just a fancy color added to the text :|
•Add this webpage to your favorites. Supply one (1) screenshot showing this webpage as one of your favorites.
I ask; Who hasn't bookmarked a webpage in their life at the age of 17, and who actually calls them favorites.
•Press the "Back" Button to view the page you were previously on, take a screen shot to prove you doing so.
I am a rebel, I used my magic fingers to press the button without a mouse (keyboard shortcut)
•Press the "Forward" Button to view the page you were on before you went backwards, take a screen shot to prove you doing so.
I never would of guessed :|
•Take a screen shot after opening multiple tabs in Internet Explorer
...
•View the HTML source of the webpage www.google.com, and save a screen shot
Why not the actual file, really? bloat much?
•Take one screen shot of your Internet Explorer Search History
Stalky much?
•What is a Web browser and what tasks does it perform?
Well.... Do you have a page for indepth analyse? Or do you literally what me to say "It let's you load stuff from dat interwebz, via requesting content from a server"
•Define what JavaScript is in relation to web pages
Are we talking server side? or client?
•Define what CSS is in relation to web pages
Do I even need to say fellow ranters ;) -
A common walkthrough with Laravel deployment:
1.) Error 403
2.) Internal server error 🤔
3.) bad require paths in index.php....
4.) Whooops something went wrong.. What?.... Look at log file with 2MB size
5.) View not found1 -
Feeling useless over something probably ridiculously simple and straightforward.
Test written: check
Route defined: check
View created: check
Controller method defined: check
Testing... Error: Controller method not found
Save me stackoverflow!!3 -
FML!!!!!! I FUCKING HATE THE COMBINATION OF XAMARIN FORMS AND MY COWORKERS.
Explanation:
I had to refactor all of our views because my coworkers did anything in the code-behind file from the views but the code should be in the viewmodels.
I had an "Unhandlex Exception" without any stacktrace or error message for a hour. What was the error? In the xaml file of the view was still an OnClicked-handler of a button but i removed the method from the view-code-behind-file.
FML1 -
Rant time. Oh boi.
So, a bit of context: I am a university student in Greece and I have a desktop PC with elementary OS on it. When the unis closed down because of Coronavirus, I moved back to my parents', without my PC, only a usb stick with elementary OS installed on it. That was before the lockdown. My parents have a desktop PC and my old laptop, both with Windows rn. I'm only able to work using Linux, so I've been just popping that elementary OS USB stick whenever I needed to work.
All cool and good. Until the usb got full. It was a 16GB one after all. No biggie, I bought a new 64GB one from a well known Greek tech shop along with a webcam my mother needed. It was a LEXAR one.
They fucking took a week to transfer it. As if the closest shop to me was in fucking Germany. For context, the drawing tablet I bought from China the other day only did 2 weeks to come. During this time I could barely use Linux because my USB stick had only some 600MB free.
Ok, wtv I said to myself. I am a patient person after all. I received the USB stick, along with the webcam, in good condition, in their packaging. Alright. I dd'ed everything from the 16GB stick to the 64GB one and then I extend the partition. Everything works flawlessly. And it's faster too.
Next day, I boot up from it again. It boots up good. Nice, time to do some work. I open my editor. And it fucking freezes. The editor is not some VSCode or Atom or any of that heavy shit, it's just elementary OS Code. A very lightweight Gtk3 app. Strangely though, the rest of my OS (the dock autohide, eg.) Seems totally responsive. I try to open another app. No luck. Not even switching TTYs work. Good shit. I force shutdown my PC. I try to boot again from that piece of shit. And guess what! NO BOOT BITCH. Like, fuck you. I boot from my previous 16GB one. Linux won't recognize it. No /dev/sdc like I used to have. Ok, lsusb. Nope, nothing. I disconnect it and reconnect it, and lsusb. An empty entry appears.I run it a couple of times, and the it disappears again. I switch to TTY 2. I get read errors and usb error -71.
And I want to fucking explode
I call back to support for the warranty coverage. I wait for a good 10 minutes and a nice lady picks up. I tell her the issue. She says that the support team will call me for the issue this day it the next day.
I hang up.
It feels like some fucking prank. YOU MOTHERFUCKING TOOK SO LONG TO DELIVER MY SHIT. Not to mention that the shitty courier service they are working with wouldn't deliver the goods to my home because it's slightly out of town. AND NOW YOU ARE DELAYING MY WARRANTY RETURN? HOW THE FLYING FUCK DID YOU BECOME A WELL KNOWN TECH SHOP WITH SUCH SHITTY SERVICE?
IF YOUR BRAINS WERE DYNAMITE YOU WOULDN'T HAVE ENOUGH TO BLOW YOUR NOSES.
YOUR THE SERVICE EQUIVALENT OF A PARTICIPATION AWARD.
Foreigners' view of Greeks suddenly doesn't seem so unreasonable. Yes, we are fucking lazy asses. And we also hate that. We hate each other for that very reason. May this country not live any longer.6 -
How would I go about finding a game dev project that I can follow where I can view progress on a designers level? I want to see a game built from the ground up, detailed error reports included?6
-
A normal day on my CMS as a Service...
URL: https://go to CMS
> Login screen: enter credentials, check checbox "remember me" (which doesn't remember you)
> redirected to SSO (single sign-on welcome page)
> Re-enter URL to go to CMS
> Fires up second browser on second screen, do the exact same things as above
--- Code editing
As it's a very modern CMS, you have to edit the code via the CMS using a bulky and honestly shitty editor (or rather: they didn't spend time configuring it to be at least semi-decent).
Plus default white horrible theme.
> Go to "/themes"
> Scroll all the way down the page
> Enter filename in search box
> Click the "Edit" button, which is a small button located right next to a much bigger red "DELETE" button. When you middle click (as I always open files in new tabs) on the DELETE button, it DELETES without confirmation. In such cases, you lose up to three days of work asking the providers to set it back up for you via their backup - and charge you for that. So sorry for deleting an *important* file
> Edit the file.
> Save the file - it takes 3 seconds. Upon saving, rescroll again to where you were in the code.
> On the other screen, refresh dev view of current template
> Wait 5 seconds
> If there are any special blocks, they all load via a semi-synchronous AJAX request (it's async, but they load one by one), the same time you waited to refresh your page.
> Notice you forgot adding some markup
> Re-edit the file, save...
> OH NO - I'VE BEEN BACKGROUNDEDLY DISCONNECTED. Back to Login page.
> Enter credentials.
> Am not on the CMS, but on the SSO
> Navigate back to file
> Re-write new changes
--- Manager comes in:
I need to you edit XXX objects in DB Manager (a big PHPMyAdmin if you will)
> New tab, go to https://DB
> Although still connected on CMS, I have to re-enter credentials
> Am redirected to SSO
> Re-enter https://DB
> Find the object (20 seconds of loading)
> Find the appropriate field
> Find out the field is in fact another object located elsewhere
> Uff, thank goodness, there's a shortcut button to directly edit said elsewhere object
> Operates on elsewhere object + save
> Re-edits original object + save
> ERROR 500, APPLICATION UNEXPECTEDLY CRASHED
:') painful much?
(for those who ask: yes i've got plenty of mind-reflexes in order to minimise losses)2 -
Everytime I have to work on some old Asp.Net shit. WebForms/WinForms etc.
Everything with that bullshitass designer. You wanna open a file you've just created? Sorry, error. Restart IDE and maybe...
Restarted website? Sorry. Old instance still hangs somewhere in IIS, so the port is taken...
Seeing code light up red when cleaning the project. Compiler being like "What the fuck is 'void'?"
Or - I know you didnt make any changes, but Im gonna build AppCode folder anyway... Its only gonna take a minute or two, no worries.
Or - You have XML template file to this class (codebehind)? You wanna open the XML? Would be shame if it was opened in the designer view and your entire IDE crashed 'cuz of some unsuported third party UI element.
Or - just unexpected debug session crashes.
And dont make me start on Xamarin...1 -
my biggest lol moment was talking to some hardcore always bring in your own algos and ds games to the table, always going to the core of the world devs, better than thou my shit is better than you ass, my point of view is the best in the world devs, cite papers and algos to you devs, shit like that that were making way less money than some dudester ruby on rails dev sitting at the the conf sipping on his drink.
Really, all that comp sci shit is legit and fun as fuck. But if you are not getting the green for it and living the life then what is the fucking point. Even then, those that are are normally fucking morons. This shit ain't some art, or a personality trait, it is a job.
Fuck me i am so tired of the whole hacker news reddit ass SO mentality of devs, then again I am also tired of mfkers with no knowledge of actual engineering publishing medium articles left and right.
As long as you cannot take human error out of this computer equation you will always have a shitfest of opinions, because regardless of correctness you will always have a shitfest as long as some dickwad has a difference of opinion in an otherwise young ass scientific field such as computer science.
Language wars, framework wars, editor wars you name it. This field is so fucking broken and so full of shit it ain't funny, made less comedic by the fact that it runs the world.
If we are going to die it will be by some massive kernel panic made possible because somewhere, some morons could not mergr a repo due to conflict in ideas. As if being right was going to bring you closer to not being an ugly fat nerd and getting pussy, or dick, whatever your flavor is you fucking losers. -
I wasn't happy with one of our UI views for editing a database query that consisted of about 50 fields ("editing" being the operative term here, not just viewing. It had to be two-way). Everything was hardcoded and defined manually, with each block of ~10 lines being repeated and mostly identical apart from the occasional double inline field and name of the variable. It had "just ended up that way" over time due to the variable names in the UI being different than the names of the variables that came from the API.
I decided to overhaul it all where I defined the different input components and which fields should be included, then made a function which would generate the page based on these definitions. It was about 500 lines of modularized functions and classes where the class for the actual view was about 50 lines- compared to the 1400+ lines of the previous version.
But, it didn't work. It should, but it "just didn't". There was no error. All I got was a blank, solid white page. I could make a drastic change or try something completely different and I would get the same error, same blank page. API fetch succeeded, value assignments succeeded, the object exists, but if you iterated it it was... empty.
I started getting really discouraged that I had made it too abstract. Maybe I actually made it more complex and unreadable than before. Maybe just hardcoding it all was the better solution after all. Maybe I had gone against KISS and overdesigned it.
I was up pretty late and everyone had gone home. When the last guy left there was that mood where "yeah if I can't make this work we'll just use the current version...".
Turns out I had tried iterating over a property of the set of fields to render, rather than the entire collection. In the old method the variables were a member of an object, but now they were its own object, a change I had made to isolate the set of values which were to be viewed/edited and make them easier to pass back and forth. This member existed since I hadn't cleaned it out yet, but it was empty.
I had been banging my head against this for a whole day and I was ready to admit I had made a mistake and wasted my time before discarding it all, but then I backspaced this one property and the interface went from empty to rendering perfectly and with all functionality intact. I swear god rays were coming out of my screen. -
So to give you a feel for what evil, clusterfuck code it was in: this projects largest part was coded by a maniac, witty physicist confined in the factory for a month, intended as a 'provisional' solution of course it ran for years. The style was like C with a bit of classes.. and a big chunk of shared memory as a global mud of storage, communication and catastrophe. Optimistic or no locking of the memory between process barriers, arrays with self implemented boundary checks that would give you the zeroth element on failure and write an error log of which there were often dozens in the log. But if that sounds terrifying already, it is only baseline uneasyness which was largely surpassed by the shear mass of code, special units, undocumented madness. And I had like three month to write a simulator of the physical factory and sensors to feed that behemoth with the 'right' inputs. Still I don't know how I stood it through, but I resigned little time afterwards.
Well, lastly to the bug: there was some central map in that shared memory that hold like view of the central customer data. And somehow - maybe not that surprisingly giving the surrounding codebase - it sometimes got corrupted. Once in a month or two times a day. Tried to put in logging, more checks - but never really could pinpoint the problem... Till today I still get the haunting feeling of a luring memory corruption beneath my feet, if I get closer to the metal core of pure C.1 -
Weekend thought: What counts as stable in development?
From my experience it seems that "stable" is a relative concept. My linux server is "stable" in the sense that the packages are tested for a long period of time before release, but my home distro is a rolling release and that is also stable in my opinion. So which is it? Can it be both? Or maybe we're just lying to ourselves that anything is stable.
When I'm developing web applications I always have this rule that is the user can't enter and exit the application without a major error coming out, it isn't ready for production. Once that's out of the way, from my point of view the application is stable. But if I were to present this to a company would they think the same? Probably not.
What do you think counts as a stable production release?1 -
So after 5 days of trying to figure out why the fuck nemID (danish online id) is a piece of shit and doesn't want to show the pdfs I'm sending, so that they can be fucking signed, I've finally found a way to produce pdfs that it doesn't choke the fuck out on.
Just fucking open the fucking pdf in fucking Acrobat and fucking print it to a fucking pdf using fucking Microdick print to pdf... TWICE! WTAF?
So guess what I'll be creating an API for today...
Also fucking give me a proper error code when your shit doesn't work! Why the fuck are you sending me an error code stating that the checksum doesn't match, when 1) I didn't fucking send you one in the first place and 2) it doesn't work because you fucks didn't implement the entire fucking pdf spec! So when my fucking pdf contains some fucking pdf-element that you decided was to hard to implement a web view for, tell me that!1 -
I woke up to find my internet connection failed overnight. Thanks for nothing BT.
Before the brain engaged and whilst waiting for the router to restart, I thought to myself let's check devRant... DOH!
However, doing that allowed me to discover that the devRant's app, at least on iOS, doesn't display an error in this case. I've attached what it currently looks like to me but think we can come up with a better solution together. 9
9 -
I'm trying really hard to like Swift but every time I open the hood on this bird, it takes a shit on my windshield.
For example:
struct ContentView: View {
var body: some View {
let kFontPointSize = 25.0
var theFont: Font = .system( size: kFontPointSize )
theFont = .custom("Helvetica", size: kFontPointSize )
Text("Hello, World!")
.padding(.horizontal, 20.0)
.font( theFont )
}
}
... in spite of how wonderfully self documenting (🐂💩) Swift is, that dirty bird converts the 'var' to a 'let' and "theFont" cannot be reassigned after declaration.
3 things:
1. invisibly converting the 'var' to a 'let' and not indicating 'var' can't be used... really?! Suppose to just "know" these obscure inconsistencies? (sloppy design)
2. then the error Xcode presents on "theFont = ..." line is : "Type '()' cannot conform to 'View'"!? How about "can't use a 'var' here"? God forbid it should make sense. (sloppy design)
3. "var" means variable and "let" means letstant? If you are going to use "var", better use "const", or be consistent and use "set" and "let" instead of "var" and "let" (sloppy inconsistency)
4. and ".horizontal", who owns that? Self documenting?. It is owned Edge Set aka Edge.Set.horizontal and effectively a "global".
5. And reading the Swift coder's mind... No, you should NEVER NEVER NEVER use "25" as a constant literal passed like .system( size: 25 ). (magic numbers not aloud)
Have all best engineering practices been simply tossed out the window? Rule #1 in software "engineering": Globals are BAD. Corollary: magic numbers earn you a one-legged A on your project.
I am so incredibly disappointed in the Swift community right now. Swift designers are honestly earning a "script kiddy" badge of dishonor.6 -
Fucking retard Liferay.....
At least 2 users (one inour team and another at client's) are claiming they've successfully opened a portlet view multiple times at day X. And a month later it stopped working.
I open up Liferay's (tomcat's) localhost_access.log and can see all the portlet requests at day X have returned http:400
Normally I would consider the human factor and rule this as a human error, assuming they were connected to another environment, another server, etc. But since this is The Fucking Liferay - I'm not that fast in trusting even logs :(
Who the fuck made this piece of shit....3 -
*me trying to fix the preview issue by editing layout file*
*issue gets fixed by clean build*
*me implementing a new feature as per plan*
*suddenly another issue occurs with the items in recycler view*
*tries SO, no related question and me too scared to ask one*
*trying different names, keywords, ids and methods to get atleast some output*
*checks json and recycler adapter, all fine but still the error*
*hello darkness my old friend*
*checks the item layout again with a microscopic look and encounters a 0 added to layout width which makes 95dp to 950dp and hence no output somehow*
*2 hours and sunday mood wasted* -
Why Laravel is sooo annoying. I recently join a web dev company and they are working in Laravel. Okay so in first I was like okay...it's fine.. even though I was interested in react but in the end I thought... It's all about your logic.. language can be changed. So I am being told to run this api- boilerplate...it's been 2 days and the error is not going. Sometimes it requires different version of php, different version of this and that ..when it finally runs view is not found. I tried using different xampp..still giving error of changes in php.ini which I already did... I Soo exhausted of this language rn ..3
-
it seems there is an issue with the windows default picture viewer 'photos' recently. i am currently working on an processed creation of an image. when i tried to view my results i got an error message. thank you very much - i thought it was my fault for quite a while!
-
9 Ways to Improve Your Website in 2020
Online customers are very picky these days. Plenty of quality sites and services tend to spoil them. Without leaving their homes, they can carefully probe your company and only then decide whether to deal with you or not. The first thing customers will look at is your website, so everything should be ideal there.
Not everyone succeeds in doing things perfectly well from the first try. For websites, this fact is particularly true. Besides, it is never too late to improve something and make it even better.
In this article, you will find the best recommendations on how to get a great website and win the hearts of online visitors.
Take care of security
It is unacceptable if customers who are looking for information or a product on your site find themselves infected with malware. Take measures to protect your site and visitors from new viruses, data breaches, and spam.
Take care of the SSL certificate. It should be monitored and updated if necessary.
Be sure to install all security updates for your CMS. A lot of sites get hacked through vulnerable plugins. Try to reduce their number and update regularly too.
Ride it quick
Webpage loading speed is what the visitor will notice right from the start. The war for milliseconds just begins. Speeding up a site is not so difficult. The first thing you can do is apply the old proven image compression. If that is not enough, work on caching or simplify your JavaScript and CSS code. Using CDN is another good advice.
Choose a quality hosting provider
In many respects, both the security and the speed of the website depend on your hosting provider. Do not get lost selecting the hosting provider. Other users share their experience with different providers on numerous discussion boards.
Content is king
Content is everything for the site. Content is blood, heart, brain, and soul of the website and it should be useful, interesting and concise. Selling texts are good, but do not chase only the number of clicks. An interesting article or useful instruction will increase customer loyalty, even if such content does not call to action.
Communication
Broadcasting should not be one-way. Make a convenient feedback form where your visitors do not have to fill out a million fields before sending a message. Do not forget about the phone, and what is even better, add online chat with a chatbot and\or live support reps.
Refrain from unpleasant surprises
Please mind, self-starting videos, especially with sound may irritate a lot of visitors and increase the bounce rate. The same is true about popups and sliders.
Next, do not be afraid of white space. Often site owners are literally obsessed with the desire to fill all the free space on the page with menus, banners and other stuff. Experiments with colors and fonts are rarely justified. Successful designs are usually brilliantly simple: white background + black text.
Mobile first
With such a dynamic pace of life, it is important to always keep up with trends, and the future belongs to mobile devices. We have already passed that line and mobile devices generate more traffic than desktop computers. This tendency will only increase, so adapt the layout and mind the mobile first and progressive advancement concepts.
Site navigation
Your visitors should be your priority. Use human-oriented terms and concepts to build navigation instead of search engine oriented phrases.
Do not let your visitors get stuck on your site. Always provide access to other pages, but be sure to mention which particular page will be opened so that the visitor understands exactly where and why he goes.
Technical audit
The site can be compared to a house - you always need to monitor the performance of all systems, and there is always a need to fix or improve something. Therefore, a technical audit of any project should be carried out regularly. It is always better if you are the first to notice the problem, and not your visitors or search engines.
As part of the audit, an analysis is carried out on such items as:
● Checking robots.txt / sitemap.xml files
● Checking duplicates and technical pages
● Checking the use of canonical URLs
● Monitoring 404 error page and redirects
There are many tools that help you monitor your website performance and run regular audits.
Conclusion
I hope these tips will help your site become even better. If you have questions or want to share useful lifehacks, feel free to comment below.
Resources:
https://networkworld.com/article/...
https://webopedia.com/TERM/C/...
https://searchenginewatch.com/2019/...
https://macsecurity.net/view/...








































Top Tags
Weekly Rant
View