
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Based on popular demand, we're proud to introduce a basic image repost detector on devRant!
Right now it uses very simple hashing to see if an exact copy of an image was posted recently. If it was, then we display an error and we don't allow the image to be posted.
This is experimental so if you experience any issues with it please let me know. 60
60 -
Me: how's your password security?
Them: of course we value security very highly, our passwords are all hashed before being stored.
Me: what hashing algorithm?
Them: oh we hash it with sha and then place that in a table indexed by the password.
Indexed. By. The fucking. Password.16 -
1. Forgot my password.
2. Clicked "Forgot" password button.
3. Received my forgotten password as plain text in my email6 -
Another one, teach secure programming for fucks sake! This always happened at my study:
Me: so you're teaching the students doing mysql queries with php, why not teach them PDO/prepared statements by default? Then they'll know how to securely run queries from the start!
Teachers: nah, we just want to go with the basics for now!
Me: why not teach the students hashing through secure algorithms instead of always using md5?
Teacher: nah, we just want to make sure they know the basics :)
For fucks fucking sake, take your fucking responsibilities.31 -
I was reviewing one dev's work. It was in PHP. He used MD5 for password hashing. I told him to use to password_hash function as MD5 is not secure...
He said no we can't get a password from MD5 hashed string. It's one way hashing...
So I asked him to take couple of passwords from the users table and try to decode those in any online MD5 decoder and call me after that if he still thinks MD5 is secure.
I have not got any call from him since.18 -
Set up an account at Wells Fargo today and they told me the password requirements... This is a joke right?
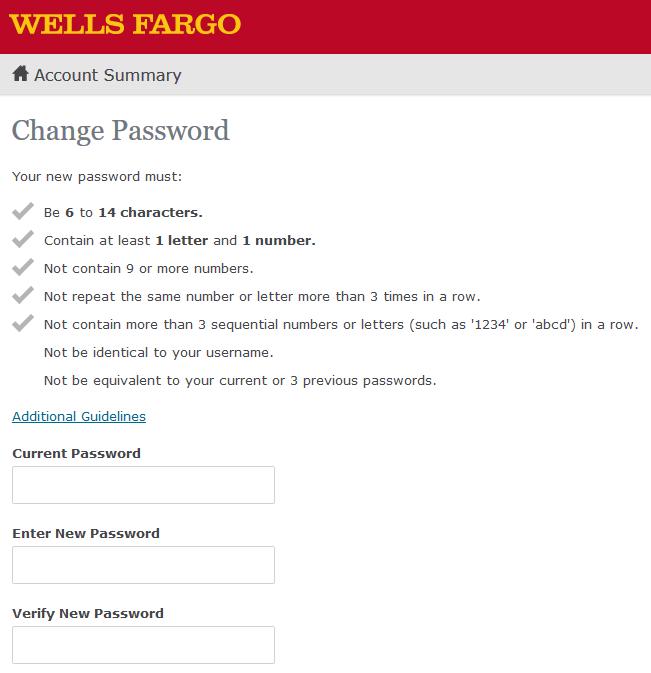 11
11 -
!security
(Less a rant; more just annoyance)
The codebase at work has a public-facing admin login page. It isn't linked anywhere, so you must know the url to log in. It doesn't rate-limit you, or prevent attempts after `n` failures.
The passwords aren't stored in cleartext, thankfully. But reality isn't too much better: they're salted with an arbitrary string and MD5'd. The salt is pretty easy to guess. It's literally the company name + "Admin" 🙄
Admin passwords are also stored (hashed) in the seeds.rb file; fortunately on a private repo. (Depressingly, the database creds are stored in plain text in their own config file, but that's another project for another day.)
I'm going to rip out all of the authentication cruft and replace it with a proper bcrypt approach, temporary lockouts, rate limiting, and maybe with some clientside hashing, too, for added transport security.
But it's friday, so I must unfortunately wait. :<13 -
Me: Browsing the security of a website.
Tell the website developer that they are using the SHA-1 hashing algorithm for encrypting the credentials of it's registered users.
Them: Yeah, so what?
Me: You shouldn't be using an algorithm which was exploited years ago in the age of 2016.
Them: Don't worry, nothing will happen.
Me: *facepalm*6 -
So, some time ago, I was working for a complete puckered anus of a cosmetics company on their ecommerce product. Won't name names, but they're shitty and known for MLM. If you're clever, go you ;)
Anyways, over the course of years they brought in a competent firm to implement their service layer. I'd even worked with them in the past and it was designed to handle a frankly ridiculous-scale load. After they got the 1.0 released, the manager was replaced with some absolutely talentless, chauvinist cuntrag from a phone company that is well known for having 99% indian devs and not being able to heard now. He of course brought in his number two, worked on making life miserable and running everyone on the team off; inside of a year the entire team was ex-said-phone-company.
Watching the decay of this product was a sheer joy. They cratered the database numerous times during peak-load periods, caused $20M in redis-cluster cost overrun, ended up submitting hundreds of erroneous and duplicate orders, and mailed almost $40K worth of product to a random guy in outer mongolia who is , we can only hope, now enjoying his new life as an instagram influencer. They even terminally broke the automatic metadata, and hired THIRTY PEOPLE to sit there and do nothing but edit swagger. And it was still both wrong and unusable.
Over the course of two years, I ended up rewriting large portions of their infra surrounding the centralized service cancer to do things like, "implement security," as well as cut memory usage and runtimes down by quite literally 100x in the worst cases.
It was during this time I discovered a rather critical flaw. This is the story of what, how and how can you fucking even be that stupid. The issue relates to users and their reports and their ability to order.
I first found this issue looking at some erroneous data for a low value order and went, "There's no fucking way, they're fucking stupid, but this is borderline criminal." It was easy to miss, but someone in a top down reporting chain had submitted an order for someone else in a different org. Shouldn't be possible, but here was that order staring me in the face.
So I set to work seeing if we'd pwned ourselves as an org. I spend a few hours poring over logs from the log service and dynatrace trying to recreate what happened. I first tested to see if I could get a user, not something that was usually done because auth identity was pervasive. I discover the users are INCREMENTAL int values they used for ids in the database when requesting from the API, so naturally I have a full list of users and their title and relative position, as well as reports and descendants in about 10 minutes.
I try the happy path of setting values for random, known payment methods and org structures similar to the impossible order, and submitting as a normal user, no dice. Several more tries and I'm confident this isn't the vector.
Exhausting that option, I look at the protocol for a type of order in the system that allowed higher level people to impersonate people below them and use their own payment info for descendant report orders. I see that all of the data for this transaction is stored in a cookie. Few tests later, I discover the UI has no forgery checks, hashing, etc, and just fucking trusts whatever is present in that cookie.
An hour of tweaking later, I'm impersonating a director as a bottom rung employee. Score. So I fill a cart with a bunch of test items and proceed to checkout. There, in all its glory are the director's payment options. I select one and am presented with:
"please reenter card number to validate."
Bupkiss. Dead end.
OR SO YOU WOULD THINK.
One unimportant detail I noticed during my log investigations that the shit slinging GUI monkeys who butchered the system didn't was, on a failed attempt to submit payment in the DB, the logs were filled with messages like:
"Failed to submit order for [userid] with credit card id [id], number [FULL CREDIT CARD NUMBER]"
One submit click later and the user's credit card number drops into lnav like a gatcha prize. I dutifully rerun the checkout and got an email send notification in the logs for successful transfer to fulfillment. Order placed. Some continued experimentation later and the truth is evident:
With an authenticated user or any privilege, you could place any order, as anyone, using anyon's payment methods and have it sent anywhere.
So naturally, I pack the crucifixion-worthy body of evidence up and walk it into the IT director's office. I show him the defect, and he turns sheet fucking white. He knows there's no recovering from it, and there's no way his shitstick service team can handle fixing it. Somewhere in his tiny little grinchly manager's heart he knew they'd caused it, and he was to blame for being a shit captain to the SS Failboat. He replies quietly, "You will never speak of this to anyone, fix this discretely." Straight up hitler's bunker meme rage.13 -
Password hashing using md5, it is 2016!! I have seen a sys admin update a user password using a MySQL query23
-
when you work for a place that has plain text passwords in the db. lol
I asked head of department if he knew what salting/hashing passwords was and he said no.... is this real life?19 -
Just saw this in the code I'm reviewing:
function encryptOTP(otp){
var enc = MD5(otp);
return enc;
}13 -
I used to work in a small agency that did websites and Phonegap apps, and the senior developer was awful.
He had over a decade of experience, but it was the same year of experience over and over again. His PHP was full of bad practices:
- He'd never used an MVC framework at all, and was resistant to the idea, claiming he was too busy. Instead he did everything as PHP pages
- He didn't know how to use includes, and would instead duplicate the database connection settings. In EVERY SINGLE FILE.
- He routinely stored passwords in plain text until I pretty much forced him to use the new PHP password hashing API
- He sent login details as query strings in a GET request
- He couldn't use version control, and he couldn't deploy applications using anything other than FTP4 -
Found that out that one of our company's internal API (I hope it's only internal) is exposing some personal data. After finally getting the right people involved they said they'd fix it 'immediately'.
5 days later I check and now there is more personal data exposed...which includes personal security questions and the hashed answers to said questions.
And of course they are using a secure hashing mechanism...right? Wrong. md5, no salt
Sigh...5 -
2 things I'm working on now:
#1 a personal project I am hoping to commercialize and turn it into my moneymaker. Hoping it'd at least be enough to pay the bills and put food on my table so I could forget 9/5 for good. But it has a potential of becoming a much, MUCH bigger thing. This would need the right twist tho, and I'm not sure if I am "the right twister" :) We'll see.
#2 smth I'm thinking of opensourcing once finished -- a new form of TLS. This model could be unbreakable by even quantum computing once it's mature enough to crack conventional TLS. I'm probably gonna use md5 or smth even weakier - I'm leveraging the weakness of hashing functions to make my tool stronger :)
I mean how long can we be racing with more powerful computers, eh? Why not use our weakneses to make them our strengths?
Unittests are already passing, I just haven't polished all the corner-cases and haven't worked out a small piece of the initialization process yet. But it's very close6 -
I hate time.
Yes, that dimension which unidirectionally rushes by and makes us miss deadlines.
Also yes, that object in most programming languages which chokes to death on formatting conversions, timezones, DST transitions and leap seconds.
But above all, I hate doing chronological things from the point of view of code, because it always involves scheduling and polling of some kind, through cron jobs and queues with workers.
When the web of actions dependent on predicted future and passed past events becomes complicated, the queries become heavy... and with slow queries, queues might lock or get delayed just a little bit...
So you start caching things in faster places, figure out ways to predict worker/thread priorities and improve scheduling algorithms.
But then you start worrying about cache warming and cascading, about hashing results and flushing data, about keeping all those truths in sync...
I had a nightmare last night.
I was a watchmaker, and I had to fix a giant ticking watch, forced to run like a mouse while poking at gears.
I fucking need a break. But time ticks on...2 -
Once we got an urgent requirement to add double hashing the password in a web application. It had to go to the production ASAP. The developer which was working on it, added 2 alerts in Javascript to display entered password and encrypted password. Finally change was ready to deploy but in hurry she forgot to remove the alerts. In rush and excitement, that change was shipped to the production. The alert says 'your password is 123', 'your password is xyz'.
After some time got phone calls from users and manager. Manager said, 'how the hell our application got HACKED? If anything happens to..........'. To cut it short, he was furious. We knew exact reason and solution. Didn't take couple of minutes to resolve this issue.
But it was funny mistake and that released that days pressure off.2 -
How to log in to CMS Of Doom™...
What could go wrong?
MD5 password hashing? HTTP links? Extracting the whole $_POST array? 8
8 -
Someone fucking teach these so called devs the difference between HASHING and ENCRYPTION :/ They are not fucking same.4
-
Hang on... If online banks ask you for the n'th, m'th and p'th character of your password, they must be storing it on plaintext! WTF? I don't even understand why they do that in the first place.11
-
Installed my telecom service provider's app for checking new packs. Didn't remember the password. Hit forgot password! I get my password in plain text in sms!
Fuck, it's one of the leading service provider in the country!
Till now i had only read about it, but never encountered it! Any ideas as to how to approach them?2 -
Just found out today via Reddit that Wells Fargo, American Express (not personally confirmed), and Chase login passwords are NOT case sensitive!
I would check your bank too!2 -
- Implemented oauth1 - no body hashing
- URL contains credentials in plain text
- Used Azure API management feature as a proxy of the our API, however the documentation was on the our API, thus exposing the API URL with no management to developers.
- easy resource DDoSing because each trial user got a DB, the registration process did not have bot checks. You could literally freeze the db instance by spamming registration requests. -
Major rant incoming. Before I start ranting I’ll say that I totally respect my professor’s past. He worked on some really impressive major developments for the military and other companies a long time ago. Was made an engineering fellow at Raytheon for some GPS software he developed (or lead a team on I should say) and ended up dropping fellowship because of his health. But I’m FUCKING sick of it. So fucking fed up with my professor. This class is “Data Structures in C++” and keep in mind that I’ve been programming in C++ for almost 10 years with it being my primary and first language in OOP.
Throughout this entire class, the teacher has been making huge mistakes by saying things that aren’t right or just simply not knowing how to teach such as telling the students that “int& varOne = varTwo” was an address getting put into a variable until I corrected him about it being a reference and he proceeded to skip all reference slides or steps through sorting algorithms that are wrong or he doesn’t remember how to do it and saying, “So then it gets to this part and....it uh....does that and gets this value and so that’s how you do it *doesnt do rest of it and skips slide*”.
First presentation I did on doubly linked lists. I decided to go above and beyond and write my own code that had a menu to add, insert at position n, delete, print, etc for a doubly linked list. When I go to pull out my code he tells me that I didn’t say anything about a doubly linked list’s tail and head nodes each have a pointer pointing to null and so I was getting docked points. I told him I did actually say it and another classmate spoke up and said “Ya” and he cuts off saying, “No you didn’t”. To which I started to say I’ll show you my slides but he cut me off mid sentence and just yelled, “Nope!”. He docked me 20% and gave me a B- because of that. I had 1 slide where I had a bullet point mentioning it and 2 slides with visual models showing that the head node’s previousNode* and the tail node’s nextNode* pointed to null.
Another classmate that’s never coded in his life had screenshots of code from online (literally all his slides were a screenshot of the next part of code until it finished implementing a binary search tree) and literally read the code line by line, “class node, node pointer node, ......for int i equals zero, i is less than tree dot length er length of tree that is, um i plus plus.....”
Professor yelled at him like 4 times about reading directly from slide and not saying what the code does and he would reply with, “Yes sir” and then continue to read again because there was nothing else he could do.
Ya, he got the same grade as me.
Today I had my second and final presentation. I did it on “Separate Chaining”, a hashing collision resolution. This time I said fuck writing my own code, he didn’t give two shits last time when everyone else just screenshot online example code but me so I decided I’d focus on the PowerPoint and amp it up with animations on models I made with the shapes in PowerPoint. Get 2 slides in and he goes,
Prof: Stop! Go back one slide.
Me: Uh alright, *click*
(Slide showing the 3 collision resolutions: Open Addressing, Separate Chaining, and Re-Hashing)
Prof: Aren’t you forgetting something?
Me: ....Not that I know of sir
Prof: I see Open addressing, also called Open Hashing, but where’s Closed Hashing?
Me: I believe that’s what Seperate Chaining is sir
Prof: No
Me: I’m pretty sure it is
*Class nods and agrees*
Prof: Oh never mind, I didn’t see it right
Get another 4 slides in before:
Prof: Stop! Go back one slide
Me: .......alright *click*
(Professor loses train of thought? Doesn’t mention anything about this slide)
Prof: I er....um, I don’t understand why you decided not to mention the other, er, other types of Chaining. I thought you were going to back on that slide with all the squares (model of hash table with animations moving things around to visualize inserting a value with a collision that I spent hours on) but you didn’t.
(I haven’t finished the second half of my presentation yet you fuck! What if I had it there?)
Me: I never saw anything on any other types of Chaining professor
Prof: I’m pretty sure there’s one that I think combines Open Addressing and Separate Chaining
Me: That doesn’t make sense sir. *explanation why* I did a lot of research and I never saw any other.
Prof: There are, you should have included them.
(I check after I finish. Google comes up with no other Chaining collision resolution)
He docks me 20% and gives me a B- AGAIN! Both presentation grades have feedback saying, “MrCush, I won’t go into the issues we discussed but overall not bad”.
Thanks for being so specific on a whole 20% deduction prick! Oh wait, is it because you don’t have specifics?
Bye 3.8 GPA
Is it me or does he have something against me?7 -
I took Database System Class and Courses in University, and told to store the password using its hash and don't store it in plain text; it is at least a standard.
today i just resetting my gmail password since i forgot the password. and i wonder by how google forgot password mechanism work.
for example i register the password with:
'xxxfalconxxx'
and then change it to:
'youarebaboon123'
sometimes later i forgot both password, and google asked for the last password i remember; and i only remember part of it so i entered:
'falcon'
and this is right, so i can continue the forgot password mechanism. how could you check the hashed text of 'falcon' is the subset of hash text 'xxxfalconxxx' ?2 -
It's gotten to the point where I am legitimately impressed when I can tell a service is hashing their passwords.
All of these unnecessary complications of "must not have more than 2 of the same character in a row" but "can't be more than 12 characters" requirements make me think that the passwords are being saved in plain text.
Amazon and Dropbox do it right - present the user with an input box and no requirements printed anywhere.8 -
Opens the source code for an app I have to integrate with.
Finds: if($cryptPW == $dbPW)
What the shit?!?!!!!!
Learn to hash! Far out 😢4 -
hashing passwords atm.
i have a java backend, should i look into bcrypt or just use a loop?
also how many times would you recommend i hash passwords?
and should i look into hardware acceleration?11 -
We had to add licensing to a program of us. In the end we chose a small java-library for that and i wrote a convenience script that creates a valid license.
But the script got its input from static strings and that was its doom.
My boss cloned the repo with the script (and jars), replaced the strings with real world data and pushed.
For his conveinience, because there were several clients, he copied the data-section, commented out the first one and put another data into the second section. This happened a few times and HE PUSHED AGAIN.
Now this repository contains a fine record of everyones licenses and their passwords. I know it shouldn't bother me, but it still gets my eye twitching, just like md5-hashing on passwords (which actually happens on that licensed project)2 -
Still more fallout from Yahoo in 2003.
I thought back then we already established that MD5 hashing is not security? 1
1 -
I'm curious, how many of you ranters out there studied Math at an advanced level to become proficient at programming? Is there a particular field of Mathematics that would improve my programming skill?
Context: I come across a lot of Math I don't understand/never encountered when researching topics such as encryption, hashing, geospatial data handling and randomness. Was wondering if I missed out on some key learning that would make these topics a lot less mysterious. Also, I overheard someone coming up with a mathematical formula to base an algorithm on. I don't think I've ever come up with algos this way.6 -
Finally.... Spent over an hour trying to optimize ~5 lines of code... Guess it was a review on how to use primes for hasig but....
Root cause was I just needed a slightly faster hashing function...
1 test failed from timeout of like maybe 1sec. Test shows passed, then in details shows Timeout...
https://hackerrank.com/challenges/...
-
On Facebook open day:
Graduate dev lady telling a story about how much responsibility they are given and how she broke the password reset button for hours when her task was to instruct old users with weak passwords to update them...
//my first post, so not sure if it's appropriate, but surely did this come as a shock5 -
I decided to run the ROCKYOU password list to see if there are any patterns in md5 hashing, not sure why but I am starting to confuse myself and I need a new pair of eyes to have a look.
in advance, sorry for the shitty image, that lappy is a temporary solution.
So the very accurate and not bias numbers show that the letter "0" appears more than the rest, would there be any use in let's say ordering the wordlist with words that have the most "0" and "7" in their hash to appear at the top?
I believe I might be trying to stretch the numbers and see a pattern where there is none but its worth a shot I think.
Note:
- These numbers come from only about ~14m words
My thinking trail is that if statisticaly these hashes are more likely to appear, they are more likely to be the one I am looking for? 3
3 -
OpenSSH has announced plans to drop support for it's SHA-1 authentication method.
According to the report of ZDNet : The OpenSSH team currently considered SHA-1 hashing algorithm insecure (broken in real-world attack in February 2017 when Google cryptographers disclosed SHAttered attack which could make two different files appear as they had the same SHA-1 file signature). The OpenSSH project will be disabling the 'ssh-rsa' (which uses SHA-1) mode by default in a future release, they also plan to enable the 'UpdateHostKeys' feature by default which allow servers to automatically migrate from the old 'ssh-rsa' mode to better authentication algorithms.2 -
Heres some research into a new LLM architecture I recently built and have had actual success with.
The idea is simple, you do the standard thing of generating random vectors for your dictionary of tokens, we'll call these numbers your 'weights'. Then, for whatever sentence you want to use as input, you generate a context embedding by looking up those tokens, and putting them into a list.
Next, you do the same for the output you want to map to, lets call it the decoder embedding.
You then loop, and generate a 'noise embedding', for each vector or individual token in the context embedding, you then subtract that token's noise value from that token's embedding value or specific weight.
You find the weight index in the weight dictionary (one entry per word or token in your token dictionary) thats closest to this embedding. You use a version of cuckoo hashing where similar values are stored near each other, and the canonical weight values are actually the key of each key:value pair in your token dictionary. When doing this you align all random numbered keys in the dictionary (a uniform sample from 0 to 1), and look at hamming distance between the context embedding+noise embedding (called the encoder embedding) versus the canonical keys, with each digit from left to right being penalized by some factor f (because numbers further left are larger magnitudes), and then penalize or reward based on the numeric closeness of any given individual digit of the encoder embedding at the same index of any given weight i.
You then substitute the canonical weight in place of this encoder embedding, look up that weights index in my earliest version, and then use that index to lookup the word|token in the token dictionary and compare it to the word at the current index of the training output to match against.
Of course by switching to the hash version the lookup is significantly faster, but I digress.
That introduces a problem.
If each input token matches one output token how do we get variable length outputs, how do we do n-to-m mappings of input and output?
One of the things I explored was using pseudo-markovian processes, where theres one node, A, with two links to itself, B, and C.
B is a transition matrix, and A holds its own state. At any given timestep, A may use either the default transition matrix (training data encoder embeddings) with B, or it may generate new ones, using C and a context window of A's prior states.
C can be used to modify A, or it can be used to as a noise embedding to modify B.
A can take on the state of both A and C or A and B. In fact we do both, and measure which is closest to the correct output during training.
What this *doesn't* do is give us variable length encodings or decodings.
So I thought a while and said, if we're using noise embeddings, why can't we use multiple?
And if we're doing multiple, what if we used a middle layer, lets call it the 'key', and took its mean
over *many* training examples, and used it to map from the variance of an input (query) to the variance and mean of
a training or inference output (value).
But how does that tell us when to stop or continue generating tokens for the output?
Posted on pastebin if you want to read the whole thing (DR wouldn't post for some reason).
In any case I wasn't sure if I was dreaming or if I was off in left field, so I went and built the damn thing, the autoencoder part, wasn't even sure I could, but I did, and it just works. I'm still scratching my head.
https://pastebin.com/xAHRhmfH25 -
I can already imagine in the future:
Remember back in the 10s when there was quantum computers with the size of a room for tens of thousands of dollars? Now everyone has one implanted in their head with 100 times the computing power! With the old hashing algorithms we could mine hundreds of blocks every second just with thinking about it1 -
It's 4:00 AM here, and I decided to go through my old project where I had put my maximum effort, it is a PHP Project, sadly not in production, I had built it from scratch, the sad part is password hashing, I had to go through 3 different files before the actual password is getting hashed, password_hash($pass, PASSWORD_BCRYPT), I am feeling so stupid right now I can't even describe in words, ok bye
-
Sometimes wondered how the avalanche effect works on hashing a message,tried making mine but was shit, I guess I need a PhD in maths lol
-
Blockchain Pun
"I don't have time to talk about the blockchain but we can HASH the details later"
😎1 -
Okay so if a company decides to use md5 for hashing passwords after a million users already registered how the hell will they transition to any other way of storing passwords. As they don't have plaintext to convert them into the new hashing function.12
-
I had a pretty good day.
I had my first pay raise as a dev;) not huge but i wasnt expecting one for another 4months ;)
And i was working on a security scrip for after effect plugins. The thing is called Extendscript and is built on top of ecma3. Yeah javascript version from 1999. Hashing stuff gave me different results. Took me about a week to realise that the string buffer were different and i had to parse in latin something to have the same matching buffers. What a hassle man. Let alone trying to make it work with Windows terminal which after starting with Linux then mac, windows seems sooo sucky.
But yeah its my first security scripts so 2 main achievements for me today! Ive waited 4 years to reach a level where i now feel like a real professional dev. ;) sry not a rant ;) -
I really cannot see why there still isn't an API in Java where I can get an hashing algorithm without having to catch a checked exception.
Granted, Bouncy castle is a top library. But of you just have a small application with a single method wanting to hash a few values... It's so nuts and unnecessary.
So what do you do in the catch block? Either throw a checked exception (because without that hash your app won't work), or calculate a replacement. But if it were that easy, I wouldn't have needed a hash on the first place.
I really wonder what the java developers had in mind.
Same with IO exception. I'm beginning to like python more and more.
And, of course, kotlin.5 -
Relatively often the OpenLDAP server (slapd) behaves a bit strange.
While it is little bit slow (I didn't do a benchmark but Active Directory seemed to be a bit faster but has other quirks is Windows only) with a small amount of users it's fine. slapd is the reference implementation of the LDAP protocol and I didn't expect it to be much better.
Some years ago slapd migrated to a different configuration style - instead of a configuration file and a required restart after every change made, it now uses an additional database for "live" configuration which also allows the deployment of multiple servers with the same configuration (I guess this is nice for larger setups). Many documentations online do not reflect the new configuration and so using the new configuration style requires some knowledge of LDAP itself.
It is possible to revert to the old file based method but the possibility might be removed by any future version - and restarts may take a little bit longer. So I guess, don't do that?
To access the configuration over the network (only using the command line on the server to edit the configuration is sometimes a bit... annoying) an additional internal user has to be created in the configuration database (while working on the local machine as root you are authenticated over a unix domain socket). I mean, I had to creat an administration user during the installation of the service but apparently this only for the main database...
The password in the configuration can be hashed as usual - but strangely it does only accept hashes of some passwords (a hashed version of "123456" is accepted but not hashes of different password, I mean what the...?) so I have to use a single plaintext password... (secure password hashing works for normal user and normal admin accounts).
But even worse are the default logging options: By default (atleast on Debian) the log level is set to DEBUG. Additionally if slapd detects optimization opportunities it writes them to the logs - at least once per connection, if not per query. Together with an application that did alot of connections and queries (this was not intendet and got fixed later) THIS RESULTED IN 32 GB LOG FILES IN ≤ 24 HOURS! - enough to fill up the disk and to crash other services (lessons learned: add more monitoring, monitoring, and monitoring and /var/log should be an extra partition). I mean logging optimization hints is certainly nice - it runs faster now (again, I did not do any benchmarks) - but ther verbosity was way too high.
The worst parts are the error messages: When entering a query string with a syntax errors, slapd returns the error code 80 without any additional text - the documentation reveals SO MUCH BETTER meaning: "other error", THIS IS SO HELPFULL... In the end I was able to find the reason why the input was rejected but in my experience the most error messages are little bit more precise.2 -
Trying to make a nodejs backend is pure hell. It doesn't contain much builtin functionality in the first place and so you are forced to get a sea of smaller packages to make something that should be already baked in to happen. Momentjs and dayjs has thought nodejs devs nothing about the fact node runtime must not be as restrained as a browser js runtime. Now we are getting temporal api in browser js runtime and hopefully we can finally handle timezone hell without going insane. But this highlights the issue with node. Why wait for it to be included in js standard to finally be a thing. develop it beforehand. why are you beholden to Ecma standard. They write standards for web browser not node backend for god sake.
Also, authentication shouldn't be that complicated. I shouldn't be forced to create my own auth. In laravel scaffolding is already there and is asking you to get it going. In nodejs you have to get jwt working. I understand that you can get such scaffolding online with git clone but why? why express doesn't provide buildtin functions for authentication? Why for gods sake, you "npm install bcrypt"? I have to hash my own password before hand. I mean, realistically speaking nodejs is builtin with cryptography libraries. Hashmap literally uses hashing. Why can't it be builtin. I supposed any API needed auth. Instead I have to sign and verfiy my token and create middlewares for the job of making sure routes are protected.
I like the concept of bidirectional communication of node and the ugly thing, it's not impressive. any goddamn programming language used for web dev should realistically sustain two-way communication. It just a question of scaling, but if you have a backend that leverages usockets you can never go wrong. Because it's written in c. Just keep server running and sending data packets and responding to them, and don't finalize request and clean up after you serve it just keep waiting for new event.
Anyway, I hope out of this confused mess we call nodejs backend comes clean solutions just like Laravel came to clean the mess that was PHP backend back then.
Express is overrated by the way, and mongodb feels like a really ludicrous idea. we now need graphql in goddamn backend because of mongodb and it's cousins of nosql databases.7 -
Whenever a site tells me the password I entered has already been used? I mean how are you supposed to know if you are salting and hashing the password.. Oh wait you probably just save it in plain text!! Please don't!!7
-
Persisterising derived values. Often a necessary evil for optimisation or privacy while conflicting with concerns such as auditing.
Password hashing is the common example of a case considered necessary to cover security concerns.
Also often a mistake to store derived values. Some times it can be annoying. Sometimes it can be data loss. Derived values often require careful maintenance otherwise the actual comments in your database for a page is 10 but the stored value for the page record is 9. This becomes very important when dealing with money where eventual consistency might not be enough.
Annoying is when given a and b then c = a + b only b and c are stored so you often have to run things backwards.
Given any processing pipeline such as A -> B -> C with A being original and C final then you technically only need C. This applies to anything.
However, not all steps stay or deflate. Sum of values is an example of deflate. Mapping values is an example of stay. Combining all possible value pairs is inflate, IE, N * N and tends to represent the true termination point for a pipeline as to what can be persisted.
I've quite often seen people exclude original. Some amount of lossy can be alright if it's genuine noise and one way if serving some purpose.
If A is O(N) and C reduces to O(1) then it can seem to make sense to store only C until someone also wants B -> D as well. Technically speaking A is all you ever need to persist to cater to all dependencies.
I've seen every kind of mess with processing chains. People persisting the inflations while still being lossy. Giant chains linear chains where instead items should rely on a common ancestor. Things being applied to only be unapplied. Yes ABCBDBEBCF etc then truncating A happens.
Extreme care needs to be taken with data and future proofing. Excess data you can remove. Missing code can be added. Data however once its gone its gone and your bug is forever.
This doesn't seem to enter the minds of many developers who don't reconcile their execution or processing graphs with entry points, exist points, edge direction, size, persistence, etc.2 -
I'm implementing 2FA supporting TOTP, SMS and backup codes. To store the backup codes I've issued in my app's database, what should I do re hashing/encryption?5




























































Top Tags
Weekly Rant
View