
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Yesterday: Senior dev messages out a screenshot of someone using an extension method I wrote (he didn’t know I wrote it)..
SeniorDev: “OMG…that has to be the stupidest thing I ever saw.”
Me: “Stupid? Why?”
SeniorDev: “Why are they having to check the value from the database to see if it’s DBNull and if it is, return null. The database value is already null. So stupid.”
Me: “DBNull is not null, it has a value. When you call the .ToString, it returns an empty string.”
SeniorDev: ”No it doesn’t, it returns null.”
<oh no he didn’t….the smack down begins>
Me: “Really? Are you sure?”
SeniorDev: “Yes! And if the developer bothered to write any unit tests, he would have known.”
Me: “Unit tests? Why do you assume there aren’t any unit tests? Did you look?”
<at this moment, couple other devs take off their head phones and turn around>
SeniorDev:”Well…uh…I just assumed there aren’t because this is an obvious use case. If there was a test, it would have failed.”
Me: “Well, let’s take a look..”
<open up the test project…navigate to the specific use case>
Me: “Yep, there it is. DBNull.Value.ToString does not return a Null value.”
SeniorDev: “Huh? Must be a new feature of C#. Anyway, if the developers wrote their code correctly, they wouldn’t have to use those extension methods. It’s a mess.”
<trying really hard not drop the F-Bomb or two>
Me: “Couple of years ago the DBAs changed the data access standard so any nullable values would always default to null. So no empty strings, zeros, negative values to indicate a non-value. Downside was now the developers couldn’t assume the value returned the expected data type. What they ended up writing was a lot of code to check the value if it was DBNull. Lots of variations of ‘if …’ , ternary operators, some creative lamda expressions, which led to unexpected behavior in the user interface. Developers blamed the DBAs, DBAs blamed the developers. Remember, Tom and DBA-Sam almost got into a fist fight over it.”
SeniorDev: “Oh…yea…but that’s a management problem, not a programming problem.”
Me: “Probably, but since the developers starting using the extension methods, bug tickets related to mis-matched data has nearly disappeared. When was the last time you saw DBA-Sam complain about the developers?”
SeniorDev: “I guess not for a while, but it’s still no excuse.”
Me: “Excuse? Excuse for what?”
<couple of awkward seconds of silence>
SeniorDev: “Hey, did you guys see the video of the guy punching the kangaroo? It’s hilarious…here, check this out.. ”
Pin shoulders the mat…1 2 3….I win.6 -
Frack he did it again.
In a meeting with the department mgr and going over a request feature *we already discussed ad nauseam* that wasn’t technically feasible (do-able, just not worth the effort)
DeptMgr: “I want to see the contents of web site A embedded in web site B”
Me: “I researched that and it’s not possible. I added links to the target APM dashboard instead.”
Dev: “Yes, it’s possible. Just use an IFrame.”
DeptMgr: “I thought so. Next sprint item …what’s wrong?…you look frustrated”
Me: “Um..no…well, I said it’s not possible. I tried it and it doesn’t work”
Dev: “It’s just an IFrame. They are made to display content from another site.”
Me: “Well, yes, from a standard HTML tag, but what you are seeing is rendered HTML from the content manager’s XML. It implemented its own IFrame under the hood. We already talked about it, remember?”
Dev: “Oh, that’s right.”
DeptMgr: “So it’s possible?”
Dev: “Yea, we’ll figure it out.”
Me: “No…wait…figure what out? It doesn’t work.”
Dev: “We can use a powershell script to extract the data from A and port it to B.”
DeptMgr: “Powershell, good…Next sprint item…”
Me: “Powershell what? We discussed not using powershell, remember?”
Dev: “It’s just a script. Not a big deal.”
DeptMgr: “Powershell sounds like a right solution. Can we move on? Next sprint item….are you OK? You look upset”
Me: “No, I don’t particularly care, we already discussed executing a powershell script that would have to cross two network DMZs. Bill from networking already raised his concern about opening another port and didn’t understand why we couldn’t click a link. Then Mike from infrastructure griped about another random powershell script running on his servers just for reporting. He too raised his concern about all this work to save one person one click. Am I the only one who remembers this meeting? I mean, I don’t care, I’ll do whatever you want, but we’ll have to open up the same conversations with Networking again.”
Dev: “That meeting was a long time ago, they might be OK with running powershell scripts”
Me: “A long time ago? It was only two weeks.”
Dev: “Oh yea. Anyway, lets update the board. You’ll implement the powershell script and I’ll …”
Me: “Whoa..no…I’m not implementing anything. We haven’t discussed what this mysterious powershell script is supposed to do and we have to get Mike and Bill involved. Their whole team is involved in the migration project right now, so we won’t see them come out into the daylight until next week.”
DevMgr: “What if you talk to Eric? He knows powershell. OK…next sprint item..”
Me: “Eric is the one who organized the meeting two weeks ago, remember? He didn’t want powershell scripts hitting his APM servers. Am I the only one who remembers any of this?”
Dev: “I’m pretty good with powershell, I’ll figure it out.”
DevMgr: “Good…now can we move on?”
GAAAHH! I WANT A FLAMETHROWER!!!
Ok…feel better, thanks DevRant.11 -
PEOPLE. DO NOT LIE ON YOUR RESUME. IT. IS. NOT. WORTH. IT. Ok, backstory.
We had a guy apply for this position at work. It really needed to be filled but also required someone with just the right certifications, so hiring the first schmuck to come along Was not an option.
We search high and low and as time passes without an acceptable applicant we become more desperate and open to negotiation. Basically, you name your price, we’ll agree to it at this point.
So finally a guy comes in, got everything we need but one minor certification. No problem. He can get that on the job, he doesn’t need it to start. He’s hired.
So he quotes us a salary 10% above our top range of what we’d usually pay a guy for this position, we don’t care. He gets it. Plus a housing allowance.
So we’re getting him registered with a place to handle his certification process and they call his four year institution to verify his transcript. We work with hazardous materials and a four year degree in a relevant field is required. It’s standard for the certification training institution to check. Especially when it’s a prestigious big name place like this guy had. And here I used to think that was paranoid of them.
They call and tell us the school says they have no record of him. We do some digging. He was never registered there. I’m like “that’s not possible, his professor is a listed reference. We call that reference.
He worked on a project with this man, he never taught him. Is very fascinated to learn this man has been presenting himself as though he attended the university. Asks to be delisted as a reference.
So long story short it comes out this guy did have a degree in this field, just from a less prestigious university.
The insane thing is, he would’ve still gotten the same job and salary package if he’d been honest about his university!
It is a loss for all involved. He doesn’t have a job. We don’t have anyone working in this position. It’s really unfortunate. Don’t lie on your resume people. Your employer will find out and the risks are not worth the benefits.12 -
So I migrated over to ja.stackoverflow.com, which is just the japanese version of stackoverflow, and realized how much different japanese devs are to the american ones Im used too.
On the standard StackOverflow I would see people argue and lots of questions would be downvoted. but on its japanese counterpart if you even ask for a little more context on a question they speak to you as if you were there boss. They also always say thank you sir at the end of their comment.
Im tempted to just keep google translate open and stay on ja.stackoverflow12 -
Hello there, just couple of words about PHP. I've been develop on PHP more than 10 years, I've seen it all 3,4,5,{6},7. Yes PHP was not good in terms of engineering and patterns, but it was simple, it was the most simple language for web to start those days. It was simple as you put code into file, upload it via FTP and it works. No java servlets, no unix consoles, no nothing, just shared hosting account was enough to host site, or even application with database. As database everybody used to have mysql, again because its simple to start and easy to maintain. So PHP+MySQL became industry standard on Web during 00-2012, and continues in some way.
You can write HTML and logic inside single file, within php code, even more single file may content few pages, or even kind of framework. That simplicity and agility sticks everybody who wants to develop sites with PHP.
This is pretty much about why it is so popular.
Each good or wannabe PHP developer in an early days write its own framework or library (like in javascript this days because of nodejs)
Imagine that PHP has hadn't have package manager, developers used to have host packages on their own sites, then various packages catalog sites created, and then finally composer. A gazillions of php code had spread over internet, without any kind of dependency control. To include libraries to your projects you have to just write include, or require. Some developers do it better than others.
So what we have ? A lots of code, no repositories, zip archives with libraries, no dependency control.
Project that uses that kind of code are still alive even today, they are solid hose of cards, and unmaintainable of course.
And main question that I'm trying to answer is Why PHP is not good ?
- First is amount of legacy code which people copy and pasted into their project, spread it even more like a virus.
- Lack of industry standards at the beginning lead to a lots of bad practices among developers. PHP code usually smells.
open source php projects in early days was developed in same conditions so even in phpbb, phpnuke, wordpress, drupal used to have a lot of bad practices in their codebase. So php developers usually not study by another library, instead they write their own frameworks/libraries.
- "It works", - there are no strong business demands, on web development, again because lack of standards, and concerns.
This three things are basically same, they linked to each other and summarize of answer of why PHP have strong smells and everybody yelling against it.
Whats is with PHP nowadays ? Of course PHP today is more influenced by good practice of webdev. Composer, Zend, Laravel, Yii, Symphony and language it self became more adult so to say, but developers...
People who never tried anything except PHP are usually weaker in programming and ecosystem knowledge than people who tried something else, python, perl, ruby, c for instance.
Summary
PHP as any other programming language is a tool. Each tool has its own task. Consider this and your task requirements and PHP can be just good enough solution.
"PHP is shit" - usually you heard that from people who never write strong applications on PHP and haven't used any good tools like Symphony or Laravel.
Cheap developers, - the bigger community, the more chance to hire cheap developers, and more chance to get bad code. That can be applied on any other language.
PHP has professionals developers, usually they have not only php on scope.
That's all folks, this is very brief, I am not covering php usage early days in details, but this is good enough to understand the point.
Enjoy.8 -
The brief history of Facebook open source:
- FB releases React under an oppressive licence that tells "woopsie, can't sue FB if you use React"
- a lot of money goes into making React popular to gain leverage from mass adoption
- VMware bans React in their company
- FB releases Flux to bring state management. It flops. Replaced by what some Russian student wrote in several evenings (Redux)
- Preact is released. It's faster than React, and it has MIT licence. Vue beats React in GitHub stars.
- Under mass pressure, FB changes React's licence to MIT. Initial plan to gain leverage fails spectacularly.
- FB releases Flow Types. It flops. Replaced by TypeScript.
- FB releases their own app market for React Native. It flops.
- FB releases Relay. It flops. Replaced by Apollo.
- FB tries to push React.Suspense for the whole JS landscape to obey and comply to how it works. Community says "Fuck You".
- FB releases react-native-web. It flops.
- Web Components are out in all browsers, adopted as a standard. React doesn't support them.
- Google releases Lit, a virtual DOM framework on top of Web Components to fuck with React. It's a massive success.
- React 18 is out. Still no Web Components support.
- (you are here)16 -
I'm a freelance web developer and I normally work on small to medium sized websites, 9 out 10 times based on WordPress and 10 out 10 times with a limited budget.
8 out of 10 times the sites content will be updated by someone with at best casual knowledge in website management.
Say what you will about WP but it's my bread and butter and it works great for just these kinds of websites; where the cost is a dealbreaker and the end product should be as user friendly as a standard word processor.
No, you probably wouldn't build a control panel for the next space shuttle or an online bank in WordPress, but I rarely need to concern myself with those kinds of projects so that really doesn't affect me.
Pretty much the same reason I have a Kia car even though I wouldn't win a Formula 1 race with it.
I for one am grateful that there's an open source tool available to my clients that more than adequately meets their needs (that's also fun to work with and build custom solutions on for me as a developer).7 -
Does anyone else feel Facebook is hell bent on attacking open source in order to gain a monopoly on it?
They are slowing replacing every industry standard tool with over engineered bullshit and it just gets lapped up like it's the best thing ever...EVERY SINGLE FUCKING TIME
Fuck you Facebook, i will never support you in your crusade against one of the things i hold closest to my heart.15 -
Currently, a classmate and I are working on our technical thesis.
It is all about industry 4.0, IIoT, big data and stuff.
This week, we presented our interim results to our supervisor. He is very pleased with our work and made the following suggestion:
He thinks it would be awesome to publish our work on our own GitHub repository and make it open source because he is convinced that this thesis is able to kind of "set a new standard" in some specific fields of using big data analysis in production processes.
I guess I'm kind of proud :)4 -
An open standard quotes the same guy in 2/3 refs, very open indeed.
This guy damaged JavaScript as a language more than anyone else in the world, and he may still call it an achievement. 6
6 -
Rant. Always start debugging with the start point :p
We have a lamp with a dimmer.
A day, the dimmer make some noisy noise. Just down it and the lamp never bright again.
I open the dimmer, check all connection, bullshit what is wrong?
I decide to bypass the dimmer with a standard interrupter. But doesn’t work.
Finally.... I check the bulb 💡 and... burned...
Morality: if the bulb doesn’t work, check the bulb!
:p 9
9 -
OMFG I don't even know where to start..
Probably should start with last week (as this is the first time I had to deal with this problem directly)..
Also please note that all packages, procedure/function names, tables etc have fictional names, so every similarity between this story and reality is just a coincidence!!
Here it goes..
Lat week we implemented a new feature for the customer on production, everything was working fine.. After a day or two, the customer notices the audit logs are not complete aka missing user_id or have the wrong user_id inserted.
Hm.. ok.. I check logs (disk + database).. WTF, parameters are being sent in as they should, meaning they are there, so no idea what is with the missing ids.
OK, logs look fine, but I notice user_id have some weird values (I already memorized most frequent users and their ids). So I go check what is happening in the code, as the procedures/functions are called ok.
Wow, boy was I surprised.. many many times..
In the code, we actually check for user in this apps db or in case of using SSO (which we were) in the main db schema..
The user gets returned & logged ok, but that is it. Used only for authentication. When sending stuff to the db to log, old user Id is used, meaning that ofc userid was missing or wrong.
Anyhow, I fix that crap, take care of some other audit logs, so that proper user id was sent in. Test locally, cool. Works. Update customer's test servers. Works. Cool..
I still notice something off.. even though I fixed the audit_dbtable_2, audit_dbtable_1 still doesn't show proper user ids.. This was last week. I left it as is, as I had more urgent tasks waiting for me..
Anyhow, now it came the time for this fuckup to be fixed. Ok, I think to myself I can do this with a bit more hacking, but it leaves the original database and all other apps as is, so they won't break.
I crate another pck for api alone copy the calls, add user_id as param and from that on, I call other standard functions like usual, just leave out the user_id I am now explicitly sending with every call.
Ok this might work.
I prepare package, add user_id param to the calls.. great, time to test this code and my knowledge..
I made changes for api to incude the current user id (+ log it in the disk logs + audit_dbtable_1), test it, and check db..
Disk logs fine, debugging fine (user_id has proper value) but audit_dbtable_1 still userid = 0.
WTF?! I go check the code, where I forgot to include user id.. noup, it's all there. OK, I go check the logging, maybe I fucked up some parameters on db level. Nope, user is there in the friggin description ON THE SAME FUCKING TABLE!!
Just not in the column user_id...
WTF..Ok, cig break to let me think..
I come back and check the original auditing procedure on the db.. It is usually used/called with null as the user id. OK, I have replaced those with actual user ids I sent in the procedures/functions. Recheck every call!! TWICE!! Great.. no fuckups. Let's test it again!
OFC nothing changes, value in the db is still 0. WTF?! HOW!?
So I open the auditing pck, to look the insides of that bloody procedure.. WHAT THE ACTUAL FUCK?!
Instead of logging the p_user_sth_sth that is sent to that procedure, it just inserts the variable declared in the main package..
WHAT THE ACTUAL FUCK?! Did the 'new guy' made changes to this because he couldn't figure out what is wrong?! Nope, not him. I asked the CEO if he knows anything.. Noup.. I checked all customers dbs (different customers).. ALL HAD THIS HARDOCED IN!!! FORM THE FREAKING YEAR 2016!!! O.o
Unfuckin believable.. How did this ever work?!
Looks like at the begining, someone tried to implement this, but gave up mid implementation.. Decided it is enough to log current user id into BLABLA variable on some pck..
Which might have been ok 10+ years ago, but not today, not when you use connection pooling.. FFS!!
So yeah, I found easter eggs from years ago.. Almost went crazy when trying to figure out where I fucked this up. It was such a plan, simple, straight-forward solution to auditing..
If only the original procedure was working as it should.. bloddy hell!!8 -
So... did I mention I sometimes hate banks?
But I'll start at the beginning.
In the beginning, the big bang created the universe and evolution created humans, penguins, polar bea... oh well, fuck it, a couple million years fast forward...
Your trusted, local flightless bird walks into a bank to open an account. This, on its own, was a mistake, but opening an online bank account as a minor (which I was before I turned 18, because that was how things worked) was not that easy at the time.
So, yours truly of course signs a contract, binding me to follow the BSI Grundschutz (A basic security standard in Germany, it's not a law, but part of some contracts. It contains basic security advice like "don't run unknown software, install antivirus/firewall, use strong passwords", so it's just a basic prototype for a security policy).
The copy provided with my contract states a minimum password length of 8 (somewhat reasonable if you don't limit yourself to alphanumeric, include the entire UTF 8 standard and so on).
The bank's online banking password length is limited to 5 characters. So... fuck the contract, huh?
Calling support, they claimed that it is a "technical neccessity" (I never state my job when calling a support line. The more skilled people on the other hand notice it sooner or later, the others - why bother telling them) and that it is "stored encrypted". Why they use a nonstandard way of storing and encrypting it and making it that easy to brute-force it... no idea.
However, after three login attempts, the account is blocked, so a brute force attack turns into a DOS attack.
And since the only way to unblock it is to physically appear in a branch, you just would need to hit a couple thousand accounts in a neighbourhood (not a lot if you use bots and know a thing or two about the syntax of IBAN numbers) and fill up all the branches with lots of potential hostages for your planned heist or terrorist attack. Quite useful.
So, after getting nowhere with the support - After suggesting to change my username to something cryptic and insisting that their homegrown, 2FA would prevent attacks. Unless someone would login (which worked without 2FA because the 2FA only is used when moving money), report the card missing, request a new one to a different address and log in with that. Which, you know, is quite likely to happen and be blamed on the customer.
So... I went to cancel my account there - seeing as I could not fulfill my contract as a customer. I've signed to use a minimum password length of 8. I can only use a password length of 5.
Contract void. Sometimes, I love dealing with idiots.
And these people are in charge of billions of money, stock and assets. I think I'll move to... idk, Antarctica?4 -
Excel is starting to piss me off. Can't do Ctrl+A in a search field, can't do ctrl+A in the standard input field, and now it turns out it can't open files with the same name (on different paths) at the same time. What the actual fuck?
 5
5 -
Want to make someone's life a misery? Here's how.
Don't base your tech stack on any prior knowledge or what's relevant to the problem.
Instead design it around all the latest trends and badges you want to put on your resume because they're frequent key words on job postings.
Once your data goes in, you'll never get it out again. At best you'll be teased with little crumbs of data but never the whole.
I know, here's a genius idea, instead of putting data into a normal data base then using a cache, lets put it all into the cache and by the way it's a volatile cache.
Here's an idea. For something as simple as a single log lets make it use a queue that goes into a queue that goes into another queue that goes into another queue all of which are black boxes. No rhyme of reason, queues are all the rage.
Have you tried: Lets use a new fangled tangle, trust me it's safe, INSERT BIG NAME HERE uses it.
Finally it all gets flushed down into this subterranean cunt of a sewerage system and good luck getting it all out again. It's like hell except it's all shitty instead of all fiery.
All I want is to export one table, a simple log table with a few GB to CSV or heck whatever generic format it supports, that's it.
So I run the export table to file command and off it goes only less than a minute later for timeout commands to start piling up until it aborts. WTF. So then I set the most obvious timeout setting in the client, no change, then another timeout setting on the client, no change, then i try to put it in the client configuration file, no change, then I set the timeout on the export query, no change, then finally I bump the timeouts in the server config, no change, then I find someone has downloaded it from both tucows and apt, but they're using the tucows version so its real config is in /dev/database.xml (don't even ask). I increase that from seconds to a minute, it's still timing out after a minute.
In the end I have to make my own and this involves working out how to parse non-standard binary formatted data structures. It's the umpteenth time I have had to do this.
These aren't some no name solutions and it really terrifies me. All this is doing is taking some access logs, store them in one place then index by timestamp. These things are all meant to be blazing fast but grep is often faster. How the hell is such a trivial thing turned into a series of one nightmare after another? Things that should take a few minutes take days of screwing around. I don't have access logs any more because I can't access them anymore.
The terror of this isn't that it's so awful, it's that all the little kiddies doing all this jazz for the first time and using all these shit wipe buzzword driven approaches have no fucking clue it's not meant to be this difficult. I'm replacing entire tens of thousands to million line enterprise systems with a few hundred lines of code that's faster, more reliable and better in virtually every measurable way time and time again.
This is constant. It's not one offender, it's not one project, it's not one company, it's not one developer, it's the industry standard. It's all over open source software and all over dev shops. Everything is exponentially becoming more bloated and difficult than it needs to be. I'm seeing people pull up a hundred cloud instances for things that'll be happy at home with a few minutes to a week's optimisation efforts. Queries that are N*N and only take a few minutes to turn to LOG(N) but instead people renting out a fucking off huge ass SQL cluster instead that not only costs gobs of money but takes a ton of time maintaining and configuring which isn't going to be done right either.
I think most people are bullshitting when they say they have impostor syndrome but when the trend in technology is to make every fucking little trivial thing a thousand times more complex than it has to be I can see how they'd feel that way. There's so bloody much you need to do that you don't need to do these days that you either can't get anything done right or the smallest thing takes an age.
I have no idea why some people put up with some of these appliances. If you bought a dish washer that made washing dishes even harder than it was before you'd return it to the store.
Every time I see the terms enterprise, fast, big data, scalable, cloud or anything of the like I bang my head on the table. One of these days I'm going to lose my fucking tits.10 -
Personal project: I design and build single-board computers with old processors like Z80, 6502 etc when I'm not being too lazy. A few run CP/M. One that's been more interesting in terms of digging deeper has been an 80C188, for which I've written a BIOS (despite the chip's built-in peripherals and interrupts being at non-standard addresses) mostly in C, which it can use to boot DOS from an image file on an SD card (bit-banged off the UART chip with FatFs). (Yes it's slow, but so is a 5.25" floppy.)
Work: My first project at my current job. Not particularly exciting compared to some stuff on here, but it got me into making useful contributions to the open-source CRM we used at the time. Was building a basic extension to deal with duplicated organisation names. So learned CiviCRM fairly deeply, a bit of Drupal, a bit of PHP. It's a shame we don't use that system any more, the community was cool.7 -
Man, I'm sure there are a million of these posts right now but...
The hiring market and hiring culture nowadays is so damn frustrating. I have a decade of experience in multiple senior/lead/principal roles at both big name companies and high-growth startups, along with a very well-written resume.
Even with this, I can barely get an interview these days. I'll apply to a role that lists qualifications for which I'm an exact fit, and either get a quick auto-denial or just never hear back at all. It doesn't matter if I custom-craft my resume and cover letter to match the job description or just send my standard resume and cover letter. We all love those pandering and patronizing "We know that this isn't the news you wanted to hear, but keep trying! Maybe you'll be good enough for us someday!" auto-denial email.
Sometimes I'll receive a denial, look back at the job posting, that they needed somebody with NLP experience or something, and say to myself "Fair enough, that makes sense." Other times, I'll look at the posting and say "Oh come on, I check every single box." It makes you wonder "What the fuck are you actually truly looking for?"
Sometimes I'll look at the company's current employees and see that almost every single one is ex-FAANG, indicating that the company will almost only hire other ex-FAANG employees (despite there being thousands of other well-qualified candidates out there who are just as talented and skilled as those ex-FAANG candidates.)
Other companies seem to be "brand shopping" for ex-FAANG employees after all the recent FAANG layoffs, hoping to land a bargain on an ex-Google engineer so they can brag that their product was built by the same people who built Google.
Then there's the question of even making it past the ATS and in front of an actual human's eyes. The hiring culture seems to be an ATS SEO game nowadays. God forbid that you didn't include the super secret magic keyword in your resume, else you'll automatically be filtered out and denied.
It's just incredibly frustrating and makes you wonder what kind of candidate you need to be to even get a first round interview nowadays. Do we all need to have a glowing personal recommendation from the ghost of Steve Jobs in order for a 50-person startup to even open our resumes?4 -
Gets scheduled into team meeting. Relatively new, see 5 pm ok sweet nbd. *reads IST. Tf is IST? Google that shit, INDIA FUCKIN STANDARD TIME? 5 pm IST != 5 pm EST. Fuckin oh no that shits at 6:30 am. Brb while I slice myself open with safety scissors.2
-
What kinda blockhead moron at my ISP decided that I require a new modem & router that is managed by THEM! I'm not really baffled by the privacy concerns but more about that I am unable to manage my home network. I literally cant open ports, manage ip adresses and do other shit I NEED FOR WORKING AT HOME.
I cant print!
I cant read mail!
I cant access my network drives!
My website is down!
Colleagues are asking why the Minecraft server is offline!
And using the new brick they gave me as a modem only, is not possible as there is no setting to be found to turn the router off!
And if I call their imbecile's of support they tell my that if they change a setting, that my phone will disconnect. (The phone line is also connected to the modem!) And right after the support guy said that and wanted to start explaing me further steps, his settings apply and I get kicked off the line. Bruh! You knew this would happen so why didnt you work around it?!?!?!!
Thing is, this new modem isnt even necessary as it doesnt use a different standard like fiber for example.
If I cant figure out how to get my stuff to work again, I swear to god I will turn on full Karen mode and ramble into their next store looking to get some manager fired!
(Ill post an update soon!)7 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!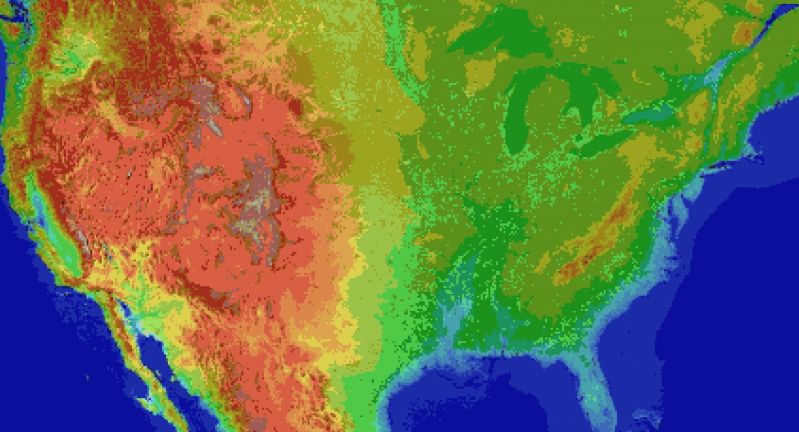 5
5 -
I own my grandfather's Victorinox Swiss Army Knife, probably from the eighties. I absolutely love it — it's just like the standard Unix toolkit. Minimalist, multi-purpose, efficient. This is what I have in my knife:
1. Two blades. I call them master (yes) and slave
2. Corkscrew. I call it "ed".
3. Hole puncher, but not just any hole puncher. Mine has an angular sharp edge to carve holes instead of just punching them. Super efficient for wood, plastic and thick fabric. It also has a hole so it can be used as a needle. I call it "vi".
4. Bottle opener which is also a screwdriver. I call it "more".
5. Can opener. This is my favorite one.
It can help you open just about anything. Any type of cans, closed pistachio nuts, oysters, your barely legal girlfriend's virginity — anything. When I eat pistachios, I'm holding my Victorinox in my hand opening tough ones with the speed of rm -rf ripping through your files. Oh, and it's also another screwdriver. I call it "cat".
But let's take a look at modern Victorinox. Maybe it's better? No, not at all. It's totally metrosexual featuring nail files, nail clippers, nail scissors and a flash drive (not even a good one).
Newer doesn't always mean cooler.
(I have the exact same one, photo from the internet because I'm too lazy) 19
19 -
Over the summer I was recruited to be a supplement instructor for a data structures course. As a result of that I was asked (separately by the professor) to be a grader for the course. Because of pay limitations I've mostly been grading homework project assignments. In any case, it's a great job to get my foot into the department and get recognized.
Over the course of the semester I've had this one person, OSX, named after their operating system of choice, who has been giving me awkward submissions. On the first assignment they asked the professor for extra time for some reason or the other, and that's perfectly fine.
So I finally receive OSX's submission, and it's a .py file as per course of the course. So I pop up a terminal in the working directory and type "python OSX_hw1.py". Get some error spit out about the file not being the right encoding. I know that I can tell python to read it in a different encoding, so I open it up in a text editor. To my surprise it's totally not a text file, but rather a .zip file!
I've seen weirder things done before, so no big deal. I rename the file extension, and open it up to extract the files when I see that there's no python files. "Okay, what's goin on here OSX..." I think to myself.
Poking around in the files it appears to be some sort of meta-data. To what, I had no clue, but what I did find was picture files containing what appeared to be some auto-generated screenshots of incomplete code. Since I'm one to give people the benefit of doubt even when they've long exhausted other peoples', I thought that it must be some fluke, and emailed OSX along with the professor detailing my issue.
I got back a rather standard reply, one of which was so un-notable I could not remember it if my life depended on it. However, that also meant I didn't have to worry about that anymore. Which when you're juggling 50 bazillion things is quite a relief. Tragically, this relief was short lived with the introduction of assignment 2.
Assignment 2 comes around, and I get the same type of submission from OSX. At this time I also notice that all their submissions are *very* close to the due time of 11:59pm (which I don't care about as long as it's in before people start waking up the next morning). I email OSX and the professor again, and receive a similar response. I also get an email from OSX worried about points being deducted. I reply, "No issue. You know what's wrong. Go and submit the right file on $CentralGradingCenter. Just submit over your old assignment".
To my frustration OSX claimed to not know how to do this. I write up a quick response explaining the process, and email it. In response OSX then asks if I can show them if they comes to my supplemental lesson. I tell OSX that if they are the only person, sure, otherwise no because it would not be a fair use of time to the other students.
OSX ends up showing up before anyone else, so I guide them through the process. It's pretty easy, so I'm surprised that they were having issues. Another person then shows up, so I go through relevant material and ask them if they have any questions about recent material in class. That said, afterwards OSX was being somewhat awkward and pushy trying to shake my hand a lot to the point of making me uncomfortable and telling them that there's no reason to be so formal.
Despite that chat, I still did not see a resubmission of either of those two assignments, and assignment 3 began to show it's head. Obviously, this time, as one might expect after all those conversations, I get another broken submission in the same format. Finally pissed off, I document exactly how everything looks on my end, how the file fails to run, how it's actually a zip file, etc, all with screenshots. That then gets emailed to the professor and OSX.
In response, I get an email from OSX panicking asking me how to submit it right, etc, etc. However, they also removed the professor from the CC field. In response I state that I do not know how to use whatever editor they are using, and that they should refer to the documentation in order to get a proper runnable file. I also re-CC the professor, making sure OSX's email to me is included in my reply.
OSX then shows up for one of my lessons, and since no one had shown up yet, I reiterate through what I had sent in the email. OSX's response was astonished that they could ever screw up that bad, but also admits that they had yet to install python(!!!). Obviously, the next thing that comes from my mouth is asking OSX how they write their code. Their response was that they use a website that lets them run python code.
At this point I'm honestly baffled and explain that a lot of websites like those can have limitations which might make code run differently then it should (maybe it's a simple interpreter written on JavaScript, or maybe it is real python, but how are you supposed to do file I/O?) .
After that I finally get a submission for assignment 1! -
I was using Delphi 7 to develop a desktop application in Windows 2000. Every time my application opened the standard Windows open file dialog, I'd get a BSOD but only if I was running the application with debugger attached. Never found out WTF was wrong... Just changed my code not to show the open dialog if IsDebuggerPresent() was True.
-
Hello and welcome, to a presentation in which I will tell you my thoughts on the shortcomings of modern day computers and programming practices.
Computers are based on a very fundamental and old idea, folders, and files, a file is basically a concrete amount of data, whereas a folder is a group of files, and it comes from the real life concept of files and folders, now it might be quite obvious already that using a concept invented in 1898 by a guy called Edwin G. Seibels, might not be the best way for computers to function in the year 2020, but alas, it is.
Unless of course, you step into the world of a programmer.
A programmer’s world is much different, they use this idea of a data structure, or in simpler terms, an object. An Object is just like what you would think of as an object in your head, something with different properties that you can think about in different ways, for example your mobile phone, it has a battery percentage, it has a screen size, it has free space available. Programmers use these data structures to analyse data very quickly, like finding all phones with a screen size bigger than a certain size for example.
The problem is that programmers still use files and folders to create the programs that use these objects.
Consider this example.
Let’s say you want to create a virtual version of a drink bottle, consider what properties it will have, colour, volume, height, width, depth, material, etc..
As a programmer, you can leverage programming features and change the properties of a drink bottle directly, if you wanted to change the colour, you just say, drink bottle “dot” colour, equals blue, or red.
But if the drink bottle was represented as a file, all the drink bottles data would be inside the one file, so you would have to open the whole file, find the line or section of the file that has the colour data of the drink bottle, and select it, highlight it, delete what’s there, and type in your new value.
One way to explain this better is to imagine a folder that now represents the drink bottle, imagine adding a new file into that folder that represents each property I described before, colour, volume, etc.., well now, you could just open that folder, find the file for colour, either by looking with your eyes or you could do a file search in the folder for a file called colour, open it, and edit the value inside. This way of editing objects is the one that more closely represents the way programmers and a program itself interacts with objects inside a running programming language.
But the thing is, programmers don’t use the folder/file way of creating objects and putting them into programs, because it would be too cumbersome, they just create 1 file for an object, or have lots of objects in a file, and create all the objects in 1 file, and then run the program which creates the objects, then when they stop the program, it deletes the objects. So there is no actual link between the object in a file and the object that the program creates by reading the data from that file, if you change the object in your program, it does not get saved to the file.
So programmers created databases to house these objects, but there is still a flaw in databases, they are hard to interface with, and mostly databases are just used to send data or retrieve data from, programmatically, you can’t really browse a database the way you can browse the files on your computer. You can, but database interfaces are not made to be easily navigated the way files and folders are.
As it stands, there is no way to store objects instead of files on your computer and interact with them in complex ways the way programmers can inside the programs they create.
If the idea of an object became standard the way a file and folder is standard, I think it would empower human’s a great deal to express things far more easily and fluidly than they can today.
Thanks for reading.8 -
I love working on legacy products. You just need a good shower and possibly a therapist after.
- Sensitive data sent over the internet encrypted with DES (not even 3DES). Guess it doesn't matter that the key (singular, for the last decade) is basically 0123456789ABCDEF.
- Client databases with open default port, admin/admin superuser.
- Critical applications (potential for substantial property damage, maybe loss of life) with a single point of failure and without backup.
Suggestions, to slow down a bit with sales, so we have time to rewrite this steaming pile of crap are met with the excuse: be more pragmatist, this is standard industry practice.
Some of this shit can be fixed on my own time if my conscience nags too much, but others would require significant investment of time from multiple developers, which would slow down new business.
Guess the pay is ok, so that's something... -
This started as an update to my cover story for my Linked In profile, but as I got into a groove writing it, it turned into something more, but I’m not really sure what exactly. It maybe gets a little preachy towards the end so I’m not sure if I want to use it on LI but I figure it might be appreciated here:
In my IT career of nearly 20 years, I have worked on a very wide range of projects. I have worked on everything from mobile apps (both Adroid and iOS) to eCommerce to document management to CMS. I have such a broad technical background that if I am unfamiliar with any technology, there is a very good chance I can pick it up and run with it in a very short timespan.
If you think of the value that team members add to the team as a whole in mathematical terms, you have adders and you have subtractors. I am neither. I am a multiplier. I enjoy coaching, leading and architecture, but I don’t ever want to get out of the code entirely.
For the last 9 years, I have functioned as a technical team lead on a variety of highly successful and highly productive teams. As far as team leads go, I tend to be a bit more hands on. Generally, I manage to actively develop code about 25% of the time to keep my skills sharp and have a clear understanding of my team’s codebase.
Beyond that I also like to review as much of the code coming into the codebase as practical. I do this for 3 reasons. I do this because as a team lead, I am ultimately the one responsible for the quality and stability of the codebase. This also allows me to keep a finger on the pulse of the team, so that I have a better idea of who is struggling and who is outperforming. Finally, I recognize that my way may not necessarily be the best way to do something and I am perfectly willing to admit the same. I have learned just as much if not more by reviewing the work of others than having someone else review my own.
It has been said that if you find a job you love, you’ll never work a day in your life. This describes my relationship with software development perfectly. I have known that I would be writing software in some capacity for a living since I wrote my first “hello world” program in BASIC in the third grade.
I don’t like the term programmer because it has a sense of impersonality to it. I tolerate the title Software Developer, because it’s the industry standard. Personally, I prefer Software Craftsman to any other current vernacular for those that sling code for a living.
All too often is our work compiled into binary form, both literally and figuratively. Our users take for granted the fact that an app “just works”, without thinking about the proper use of layers of abstraction and separation of concerns, Gang of Four design patterns or why an abstract class was used instead of an interface. Take a look at any mediocre app’s review distribution in the App Store. You will inevitably see an inverse bell curve. Lot’s of 4’s and 5’s and lots of (but hopefully not as many) 1’s and not much in the middle. This leads one to believe that even given the subjective nature of a 5 star scale, users still look at things in terms of either “this app works for me” or “this one doesn’t”. It’s all still 1’s and 0’s.
Even as a contributor to many open source projects myself, I’ll be the first to admit that have never sat down and cracked open the Spring Framework to truly appreciate the work that has been poured into it. Yet, when I’m in backend mode, I’m working with Spring nearly every single day.
The moniker Software Craftsman helps to convey the fact that I put my heart and soul into every line of code that I or a member of my team write. An API contract isn’t just well designed or not. Some are better designed than others. Some are better documented than others. Despite the fact that the end result of our work is literally just a bunch of 1’s and 0’s, computer science is not an exact science at all. Anyone who has ever taken 200 lines of Java code and reduced it to less than 50 lines of reactive Kotlin, anyone who has ever hit that Utopia of 100% unit test coverage in a class, or anyone who can actually read that 2-line Perl implementation of the RSA algorithm understands this simple truth. Software development is an art form. I am a Software Craftsman.
#wk171 -
So, apparently, in 2015 our webhost (ixwebhosting) was purchased by Site5... This week, they finally migrated us to Site5 servers without warning, taking my email down in the process...
Today, after following the instructions in their own KB article (that tells you to click an icon that doesn't exist,) and chatting with support for over an hour, I was told that the new system they migrated us to doesn't support catch-all email accounts... At all... It's simply not possible to receive an email that was sent to your domain, unless the email address exists in the system somewhere... Despite the fact that it's a standard cPanel feature, that the old and new systems both use cPanel, that every other webhost I have ever seen that uses cPanel has this feature available, AND the fact that this is an important feature for a lot of websites, because they pipe all of their emails to a script for processing... It's simply not possible... They won't be providing that feature anymore. Nor for that matter is it possible to be migrated back...
They migrated accounts to a system that has a basic email function intentionally disabled, without warning... And we can't afford to open an account with someone else ATM... So I can't get any email until we get migrated... FML9 -
Hey just brainstorming a business/ startup idea I may try out sometime down the line. I wanted to put it in writing available to my peers for review. If that sounds boring, sorry.
So I've had an idea and I know it's a million dollar idea because it's absolutely boring as fuck.
Recently I have been learning about NoSQL and it has gotten me pretty excited about unstructured data.
Now the first thing you should know about me is I like to make business software. I don't like games or social networks or blah blah blah, I like business stuff. One dream I have always had is to make THE business solution. I've noticed so many specific business solutions for very specific areas of work. Specific software for car washes, which is separate from the software for car maintenance, which is separate from the point-of-sales software, which is separate from the [...]
One of the problems with this is the inconsistency. Modular is good, but only if the modules are compatible. They aren't. Training needs to be provided for each individual system since they are all vastly different. And worst of all, since all of these different applications reach their own niche market, they charge out the butt for things that are usually very simple "POST a form over http(s)" machines.
I mean let's not get too dreamy here. My solution is an over-complicated form-builder. But it would be a game-changer for small and medium-sized businesses. Allowing users to build their own front-end and back-end disguised as a drag-and-drop form builder would be THE alternative, because they could bring all of their solutions into a single solution (one bill!) and since THEY are the ones that build what they need, they can have custom business software for the price of a spreadsheet program.
The price difference we could offer would be IMMENSE. Not only would we be able to offer "cookie-cutter" pricing as opposed to "custom" pricing, but since this generic solution could be used for essentially all of their systems, we aren't just decreasing one bill. We're decreasing one bill, and eliminating the rest entirely. We could devastate competition.
"BUT ALGO", you scream in despair, "USERS AREN'T SMART ENOUGH TO DRAG AND DROP FORM PARTS TO MAKE A FORM"
I mean ya true. But you say that like it's a bad thing. For one, we can just offer a huge library of templates. And for another, which is part of the business plan, we can charge people support dollars to help them drag and drop their stupid fucking forms!! Think of the MONEEYYYY YOU COULD MAKEE BY EXPLAINING HOW TO COLLECT FIRST AND LAST NAMEEE. Fuck.
The controls library would be extensible of course. You would be able to download different, more specialized controls if you need them. But the goal would be to satsify those needs with the standard collection of controls (Including interesting ones line barcode scanner and signature input and all that). But if all else fails, maybe someone made an open source control for you to implement and ignore that stupid donation button. We all do.
This could PURGE the world of overpriced and junky specialized business software, and best of all, it's aimed at smaller businesses. With smaller businesses making more profit, they will stay afloat better and may start to compete with their larger foes. Greater for the entire economy.
Anyways, I'm sure it's full of holes. Everything always is. But I still think it's something I'll try before I die.24 -
Today was a rather funny day in school. School starts for me at 13:40 because our timetable planners are so qualified for this job.
First 2hrs: Physics, fine its good
Second 2hrs: Discrete Maths (however you want to call it)
Goal is to write a text (30 pages, 10, etc all those standard settings). Teacher prefers Latex over word, but we can do it in word if we want. We could choose a topic, I took primes because it looked the best. I decided to use latex because I'm a fetishist and it simply looks better in the end. A classmate was arguing with our teacher about ides: texmaker vs kile. And I'm like "I use vim". So my teacher is like kk
Later that class, when we actually started doing stuff I started the ssh session to my server because I don't know any good c++ compilers for win and I'm too lazy to get a portable version of cygwin (or whatever its called). So in my server I open vim and start coding my tool for Fermat Primes (Fermatsche Primzahlen, too lazy to actually translate). And this teacher seriously is the best teacher I ever met in my life. Usually teachers are like " dude r u hakin' the school server?" and I'm like bruh its just vim and I'm doing it this way because I cannot code on your PC coz I can't install a compiler. And this teacher is like "oh hey you actually use vi, all cool kids used it in 2000. I first though u were kidding and stuff..." And we continued talking about more of stuff like that and I have to say that this is the first teacher that actually understands me. Phew
Now I'm going to continue writing my 30 pages piece of trash latex doc and hope it'll end good1 -
How is there no open, accepted, widely used standard to store & tag things like old family photo albums, diaries, books, etc.? Surely I can't be the only one who wants to digitise all this stuff to preserve it many years from now in case the drunk Uncle pisses on it, or Grandma's dodgy electrics burn the house down and it's all lost permanently. Or perhaps I am; it does seem that most other people doing genealogy work have the technical competence of a lemon.
Like, I get it, there's *some* online solutions for this stuff (not many and they tend to cost a fortune), but if I want to store it locally or in a private git repo or whatever... well, no-one seems to do it. I want to be able to interlink individual photos with their contextual pages in albums, store metadata about them, store audio recordings of older relatives with transcripts linked, etc. - and it just doesn't seem to be a done thing.
Ah well. Perhaps I'll do it all anyway as some kind of side project, then all being well my great great grandchildren will be immensely thankful if family history stuff ever becomes popular again.18 -
Data wrangling is messy
I'm doing the vegetation maps for the game today, maybe rivers if it all goes smoothly.
I could probably do it by hand, but theres something like 60-70 ecoregions to chart,
each with their own species, both fauna and flora. And each has an elevation range its
found at in real life, so I want to use the heightmap to dictate that. Who has time for that? It's a lot of manual work.
And the night prior I'm thinking "oh this will be easy."
yeah, no.
(Also why does Devrant have to mangle my line breaks? -_-)
Laid out the requirements, how I could go about it, and the more I look the more involved
it gets.
So what I think I'll do is automate it. I already automated some of the map extraction, so
I don't see why I shouldn't just go the distance.
Also it means, later on, when I have access to better, higher resolution geographic data, updating it will be a smoother process. And even though I'm only interested in flora at the moment, theres no reason I can't reuse the same system to extract fauna information.
Of course in-game design there are some things you'll want to fudge. When the players are exploring outside the rockies in a mountainous area, maybe I still want to spawn the occasional mountain lion as a mid-tier enemy, even though our survivor might be outside the cats natural habitat. This could even be the prelude to a task you have to do, go take care of a dangerous
creature outside its normal hunting range. And who knows why it is there? Wild fire? Hunted by something *more* dangerous? Poaching? Maybe a nuke plant exploded and drove all the wildlife from an adjoining region?
who knows.
Having the extraction mostly automated goes a long way to updating those lists down the road.
But for now, flora.
For deciding plants and other features of the terrain what I can do is:
* rewrite pixeltile to take file names as input,
* along with a series of colors as a key (which are put into a SET to check each pixel against)
* input each region, one at a time, as the key, and the heightmap as the source image
* output only the region in the heightmap that corresponds to the ecoregion in the key.
* write a function to extract the palette from the outputted heightmap. (is this really needed?)
* arrange colors on the bottom or side of the image by hand, along with (in text) the elevation in feet for reference.
For automating this entire process I can go one step further:
* Do this entire process with the key colors I already snagged by hand, outputting region IDs as the file names.
* setup selenium
* selenium opens a link related to each elevation-map of a specific biome, and saves the text links
(so I dont have to hand-open them)
* I'll save the species and text by hand (assuming elevation data isn't listed)
* once I have a list of species and other details, to save them to csv, or json, or another format
* I save the list of species as csv or json or another format.
* then selenium opens this list, opens wikipedia for each, one at a time, and searches the text for elevation
* selenium saves out the species name (or an "unknown") for the species, and elevation, to a text file, along with the biome ID, and maybe the elevation code (from the heightmap) as a number or a color (probably a number, simplifies changing the heightmap later on)
Having done all this, I can start to assign species types, specific world tiles. The outputs for each region act as reference.
The only problem with the existing biome map (you can see it below, its ugly) is that it has a lot of "inbetween" colors. Theres a few things I can do here. I can treat those as a "mixing" between regions, dictating the chance of one biome's plants or the other's spawning. This seems a little complicated and dependent on a scraped together standard rather than actual data. So I'm thinking instead what I'll do is I'll implement biome transitions in code, which makes more sense, and decouples it from relying on the underlaying data. also prevents species and terrain from generating in say, towns on the borders of region, where certain plants or terrain features would be unnatural. Part of what makes an ecoregion unique is that geography has lead to relative isolation and evolutionary development of each region (usually thanks to mountains, rivers, and large impassible expanses like deserts).
Maybe I'll stuff it all into a giant bson file or maybe sqlite. Don't know yet.
As an entry level programmer I may not know what I'm doing, and I may be supposed to be looking for a job, but that won't stop me from procrastinating.
Data wrangling is fun. 1
1 -
So basically a friend was tasked with doing some syadmin on a propietary system running on top of GNU/Linux (they distribute the software as a distro).
Called me about an hour ago because there was some odd stuff happening so I log into the system and start figuring out what the actual fuck is up.
Just now we discovered that for a certain critical feature you just need to trust that there will be no eavesdroppers, meaning you send system credentials in cleartext over the network, and it won't work if it's not so.
Of course, some tunnels and routing later (which by the way, is "manual" configuration which is highly discouraged by the creators of this piece of crap) we kind of managed to overcome this obvious fail.
Now then, can you please explain me again how is it that these companies grab open source, make useless layers that limit it in every way possible and still profit? I mean, for fucks sake, you should at least let people manage shit with standard, well understood tools instead of "improving system administration", "easing it for...", for whom?
I'm so happy to log into our production server and be welcomed by beastie. -
Just saw an article about a failing attempt at the UK to create a nationwide parking app.
Mostly because the many, *many* parking meter app operators in different markets don't want a single, interoperable standard.
But, there is one all of them must support or stop working entirely.
It is the "room temperature at sea level" standard for any western user interface: point and click, text input, English UI text.
Can't AI be a front-end for that?
This is also a rant about AI. There are sooo fucking many modules for siri or Alexa to be compatible with apps like uber or Spotify. Uh, why? Shouldn't the AI, that claims to he capable of recognizing images and text, just open the app and click on the right buttons?
I know why siri and Alexa and Google assistant and and chatgpt aren't capable of that - because it would free users from UX lock-in, and the corporate overlords would rather shut down the entire fucking internet.
But now with DeepSeek and other open-source moderately useful LLMs, could we finally be nearing the day when we can ditch the millions of marginally different apps and let the AI take over the piloting of their redundant GUIs?
Because then, even if app vendors don't want to work together and end up fucking up the aggregate UX for every smartphone user, we can just flip them the bird and let the AI blur their entire brand identity in the background of a "please wait while I operate some second-page apps to realize your request" message.2 -
!rant
...
.UseKestrel(options =>
{
options.Listen(new IPAddress(new byte[]{ 192, 168, 178, 20 }), 5000);
})
...
Look at this easy piece of code(that I added) from an Asp.NET Core 2 template project(MVC). I needed only to add this piece of code to WebHost.CreateDefaultBuilder() (in the Program.cs) to be able to setup a working WebServer which will listen and answer on that IP(local network machine IP) and port, then I opened that port from my modem on this local IP, then used DynDNS with noip.com, tested out on my smartphone with 4G connection and it does work!
This is the EASIEST web project setup and test that I've ever tried and that let me showcase something from my machine to the entire world! :')
Great job Microsoft; can't wait to try the cross-platform of this open standard. -
I don't know how much of this can be considered data loss but one one of my uni classmates frustrated by some hellish tasks (cleaning some old code files probably) decided that everything in that particular directory won't be of any further need, so she procede to rm -rf it.. only to discover that the terminal opened in that dir was another one and her current one (the one she bashed that unforgiving rm) was in fact a standard freshly opened term where any term would open.. in the user's (only user) home dir... such a face she had when all her codes, homeworks, projects and everything went to oblivion 😂😂 jokes aside it was a good thing that the semester was almost finished, all hws submited and no important data was there as she dual booted with ubuntu and some windows, but funny thing how such a honest mistake can ruin not only your day, but maybe your entire semester1
-
For : Web devs, especially corporate website developers. (home, about, services, contact pages with content update features, bla bla)
Question : Is there an open sourced PHP solution between Wordpress and Laravel?
Reasons
- I do not want full framework like laravel for such simple website.
- Laravel is too much and heavy for standard corporate websites and not all clients can afford ssh-enabled servers.
- I do not want full CMS features like plugins, themes, etc from Wordpress.
- Wordpress themeing is not super difficult but also not as simple as Laravel's blades.
- I also don't wanna go static since the content update needs to be dynamic.
- I am willing to write own templates, CRUDs in minimal approach just for specific parts based on clients requirements.
- I want something that can easily host on shared hosting. (do not have to worry about composer and ssh)
Any thought?8 -
I got my current job in the most standard manner,
1. Saw an ad for the job in the local newspaper.
2. Called the boss and had a chat with him. He sounded nice and the job sounded interesting.
3. Submitted my application and resumé
4. Boss called and we set up an appointment for an interview.
5. Met with boss and HR, had a cup of coffee and an interview.
6. Boss called and told me I'm one of two, and that he would like me to do a DISC personality analysis.
7. Met with HR and did the analysis, a bunch of questions that I answered as thoroughly as I could.
8. Boss called and said, congrats! Can you start next month? Yes, I could and it's been more than three years since :)
To make a boring story a bit more funny: Half-way through my first day, I noticed my zipper was open =:O And today I'm wearing two exactly identical socks...save for the colour, different shades of grey on left and right foot. Hush, don't tell my colleagues, maybe they won't notice ;) Well, I guess it's alright as long as I'm not wearing nothing but underwear, or being butt naked, like in some nightmares.1 -
Even if Microsoft has done considerably steps forward in recent years with dotnet core being an open source platform, it still retains a bit of its microsoftian dna. Let me make an example. Start a new test project with xUnit. It doesn't log to console. Decide to use the standard Microsoft.Extensions.Logging that should be the new, performant way of logging. It comes with 4 providers and **it doesn't log on file system**. Bottom line: all the complexity of a complex stack without the solution you were looking at the beginning. Resorting to thirdy party tools to do the job (serilog).2
-
C++ is the building blocks for many high-level programming languages, and since 1984 its first appearance in the markets the C++ core committee developers have introduced its 4 new versions which are C++03 (ISO/IEC 14882:2003 second edition), C++11 (third edition), C++14 (fourth edition) and C++17 is the fifth edition. With each new version, developers introduced new features, libraries and APIs in it.
C++ introduced as the extension of C programming language which made C++ as a compiled programming language, which means the developer required a C++ compiler to translate the C++ code to its equivalent machine or byte language, so the Operating system of the computer can execute the program.
There are various C++ compilers in the market and most of them are open source and free to use, however conventionally when we say C++ compiler, we basically talk about GCC which stands for GNU Compiler Collection.
What is GCC?
GCC stands for GNU Compiler Collection, and it is a collection of programming compilers which induce C, C++, Objective-C, Fortran, and some versions of Java. The first version of GCC introduced in 1987 and it was also known as GNU C compiler which became the standard compiler for C programming language, in that same year GCC also provided Compiler support for the C++ programming language.
Now GCC has various versions and each version give specific support for C++ versions, by now if we look at all the versions of GCC, we have a stable GCC for every version of C++, but there are some exceptions with C++11.
C++11:
C++11 introduced as the 2nd update version of C++, it suffixes 11 because it released in 2011 or because on August 12, 2011, ISO gives official approval to it. Formally C++11 known as C++0X because developers were expecting the new update released in 2010, but with its release in 2011, the core committee developer of C++ changed its name by C++0X to C++11.
C++ 11 replaced the old version of C++03, and it also brings many new features for the C++ developers. The main aim of designing C++11 to stabilize and maintain the backward compatibility of new C++ version with the C+98 and C programming language and that’s become the main reason why core committee developers only introduced new features in the old standard library rather than extending the core language.
GCC does not give Full Support to C++11:
GCC version GCC 4.8.1 purpose the first feature-complete implementation of the C++11 standard, however, the 4.8 and 4.7 does not give the full support for the C++11. The current version of GCC provides the major support for all the standard features of C++11 but if you are using the GCC 4.8 or 4.7 versions then your GCC only provide you with the experimental support for the C++11.
To use the Experimental support of GCC you need to enable it first before you compile or run you C++ 11 version code.
use code std=c++11 or -std=gnu++11 to enable the experimental support for C++11.16 -
I don't want to answer my manager. Each SCRUM, each SPRINT retrospective is becoming so long. Everyone in my team works on different projects, it's no use listening to all that and wait for your turn and on top of that your manager bombards you with the questions that you really know the answers to but he always questions again like give me estimates, like if I haven't ever worked on something how am I supposed to give you the estimates.
My english is just lowering it's standard day by day, I try to think smarter words but no it is sucking bad.
I am not frustrated as I am learning how to see all this as a part of my learning. I am a good developer I know but I haven't worked on code for like 3 months, everything needs to be investigated, contacting the other teams etc. I am just thinking to close on the projects that I have right now and leave.
In 1:1s my manager said something else but in team meeting asked me to do something else.
I haven't coded in more than 2 months even before that it was at least 3 months gap. I want to take leave for a week and work on the code. But fuck it, open source is not allowed in my company. WTH WTH WTH!!!
I switched the company for growth and I definitely did not have any technical growth.1 -
Why use a standard tab width when we can all have our own unique preferences? Let's make it a surprise party every time we open a file. I just love adjusting my editor settings for every repo. Keeps me on my toes!1
-
Is there a place to find standard models open-sourced by Academia and Companies ?
Any GitHub repository?5 -
Why are some defaults still so broken on Windows? Do they just not care or expect poeple will replace everything with third party stuff as the real defaults anyway?
Now through RDP connection stuff I have to spend more time on that #*?%&$§ OS and I would have expected the standard programs to work better. Here some of the stuff that really irks me:
* Groove Music sucks hard, how it doesn't let me edit playlists, but relies on its broken discovery of tracks. So I can play my old Eels songs from some subfolder in music folder, but only by manually loading each song. It never adds the songs to the list whereas the new NIN album is recognized. - It could have been nice, more of a lightweight Cessna, compared to that scary giant nineties Jumbo of media player?
* every time I use the snipping tool for a screen shot they suggest to use that screen sketch tool. I tried. Inside the RDP it was just unusable, when I tried to select the part of the screen. The selection cross wouldn't show or only too late. Unusable.
* using Internet Explorer as the default application for xml files. Sorry it's just so damn slow. And this smiley always gives me the creeps. (liveoverflow had one episode where he described his panic when he first saw an opening internet explorer: Uh, that strange face there, has it been hacked?) - but then nothing happens for a minute, I calm down, and open the file in some useful editor.4 -
Man I'm annoyed!
TL;Dr what does it mean "we're trying to reduce options to a minimum", why don't you go closed source!? why don't you remove themes!?
For anyone who uses rofi, they would know that a few months ago an update made it more compliant with the free-desktop spec, that it only uses the first .desktop file for the given Name tag.
I only found out about this recently as I was only able to update Manjaro recently, and it really annoyed me, cause it took me a while to figure out why tons of my desktop entries disappeared.
Turns out someone made an issue about this, and the given answer was: "that's against the spec". Ok, fine. But when I asked if they could add an option to still ignore that aspect of the spec (i.e. --show-duplicated), the response I got was: "going against the spec is a no-go". WHAT!?
There are so many things that have behavior that goes against the spec (ex. gnu-utils), why can't they add an option to do this!? An OPTION!?
When I decided to try (I don't know C yet) and make a PR, the first and last (it got locked afterwards!) comment I got was:
" As explained on #941, this is a no-go. We want to reduce the number of options to the minimum, and non-compliance to a well-defined and widely implemented spec is definitely not something we want."
Why are you so closed minded!? Yes compliance is amazing, but it's not a safety standard, it's okay if you *give an option* to go against the spec!!!!
WHAT THE HECK!?!?!? WHY!?!?!?
Why is a open source project closed to new features that are part if the scope of the project, and require minimal maintenance!?11 -
I love everything about the Nvidia Tx2 board...except the ARM64 architecture. Catch me constantly building shit from source :(
Seriously though, I wish there was just one, universal open source processor architecture standard to rule them all.1 -
So when windows cannot open a png with its standard image viewer without a file system error and while running sfc/scannow a bsod appears, maybe this old tablet shouldn't be used anymore, which already runs slow as hell...1
-
Is there a standard around checking the checksum of a bundled weapp to make sure it's the same as what the open source codebase would compile to?
I'm working on some opensource blockchain interface software and obviously blockchain passwords are pretty important, so we do all transaction signing client side and password storage client side, but there's no point doing that if the user can't verify that the password isn't being sent off to some server in secret, but the only way to ensure that is with open source software + a checksum check upon loading, because opensource software doesn't mean the deployed version is the exact opensource branch version.
Any ideas?1











































Top Tags
Weekly Rant
View