
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
ERRORs are red,
INFOs are blue.
My logs look pretty,
But not as pretty as-
Wait, hold on. Why are there ERRORs in here?
Why is the homepage returning a 5- oh crap.
Can you just... Can you give me a minute?12 -
The DNS server I'm writing in PHP (largely taken from another project) is starting to work!
Next to just blocking queries it logs every blocked query so I can have stats :3
A little terminal output: 64
64 -
“Any application that can be written in JavaScript, will eventually be written in JavaScript.” — Jeff Atwood
Fast-forward 20 years, a plane crashes, they find and open the black box and in the flight logs they can see the cause clearly: ”undefined is not a function”.13 -
A dude with a THICK Russian accent just called me offering server security services.
After I politely declined, he insisted on a free audit of my servers. I declined that as well.
Now I’m backing up our DB’s and going through my nginx logs.
Am I being racist?19 -
Do not disturb someone especially if they are in the zone.
Hint : earphones on, a ton of error logs on screen.4 -
I accidently left log.debug("bollocks") ;
In an exception handler our customers log monitoring system picked it up and they questioned why and I quote here "why is there a spike in bollocks at 3am?"
That was an awkward conference call2 -
!rant
Deployed my first website to production yesterday and the world isn't burning, the error logs have been empty and my (non-tech) colleagues think it is amazing.
I'm somewhat proud of myself.7 -
Got bored at work today and tried to write a program to do my job for me. Security and compliance saw it in the logs (trying to run unauthorized program) and came to give me a hug.11
-
Victory!
Today I finally closed a 'Nessy' bug (A scary bug you can't reproduce typically only sighted by one person). Below is my response...
"There were no errors in the error logs because writing to the error log was causing the error." 5
5 -
Fuckin hell!!
Code works everywhere except at one client. Ok, I check logs & see something missing.. I go check the code that handles excel files.. try catch and do nothing.. great.. :/ ok let's log this shit to see what is not ok...
Insert logs, build, update, run.. now it freakin works o.O 11
11 -
Angry Client: All the data from this account is missing. I can't work like this with the app loosing data.
Me: Checks logs, see that client pressed the reset all data button and after that the confirmation button.
Me: As polite as possible informing the client what he did.
Client: Ooh yeah I did that.
It's sad that it has come to the point where you need logs on pressing buttons because they try to blame everything on the app.9 -
Thursday: Hey wife…. I finished my project and tomorrow I should have a very easy day, just watching Slack.
Friday: Database— corrupted bin logs, major production outages.
Wife: 😡I can never believe you when you say you’ll have an easy day.2 -
Scratching my head for an hour because a function wasn't being called. Checked my backend server and all the logs.
Then I realised I commented out the function call. 😠😭😭😞 4
4 -
*Logs out of devRant to be productive.*
*Still recieves notifications even though I logged out."
*Fails to be productive for the entire day.*
It's almost 10 pm and I still didn't do any homework. I guess I'm going to disable devRant using clearlock again. :(3 -
Just imagine, if someday some client or some manager logs on to devrant and see the amount of hate we people give them... Just imagine their faces 🐑😂😂😂😂5
-
To all newbie developers,
Before you ask a doubt about an issue to someone else,
Try doing an initial investigation to find the root cause,
Look into the logs,
Find the stack trace,
Google things,
Have breakpoints and try to debug.
You come to me with a weird NullPointerException and ask me why,
Without even looking into the logs once? We ain't God bro.13 -
Created a function called upDawg and started sprinkling it all over the code base. Waiting to see who catches it in our next code review.
All it does is console logs 'Not much man, you?' -
One of my older servers just went down. It's been hacked. How do I know this you ask? Is it mining bitcoin?
No - windows event viewer has no errors in the logs for the last 48 hours.3 -
Had an interview in a MNC company.
He: Propose a solution for reading huge logs file like 1 GB and parse errors with today's date.
Me: Gave two solution, one with regex and second with buffering the logs (reason: reading the entire in same shot will cause cpu spike with huge memory consumption) and I fell in love with my second approach. By the way it was on paper.
He: (Without seeing the logic) Your syntax is wrong.
Me: Got frustrated who the hell checks syntax in interview. I asked how may years of experience you have?
He: 10 years.
Me: I don't wanna continue, and I left.5 -
> Customer logs Jira ticket claiming app is not working
< I restart the app, investigate and explain tht their server has issues
ø Client closes the ticket as Resolved
-- a couple of days pass by ---
> Customer logs Jira ticket claiming app is not working
< I restart the app, investigate and explain tht their server has issues
ø Client closes the ticket as Resolved
-- a couple of days pass by ---
> Customer logs Jira ticket claiming app is not working
< I restart the app, investigate and explain tht their server has issues
ø Client closes the ticket as Resolved
-- a couple of days pass by ---
<...>
< I log a JIRA ticket explaining what and how is wrong with the server with suggestions how to fix the problem so the app will not crash any longer (client own the server, has his own sysadmins -- I don't even had permissions to open syslog.. had to hack dmesg on their PROD server to pin-point the issue)
> no reaction from customer for weeks. I ping the ticket
× app crashes again
> no reaction from customer for weeks. I ping the ticket
> customer leaves a comment that their sysadmins are looking at it trying to figure out what might be wrong (ignoring what I wrote in ticket's description??? srsly?)
× app crashes again
< I post detail investigation details: snips from logs, screenshots, everything with crystal clear explanations.
> no reaction for weeks
......
well that's fun..6 -
I had a weird dream last night where people communicated by using log statements.
Like if I wanted to say something very loud I'd think Log.wtf("WTF!") and it would appear in front of me like subtitles. Log levels were equivalent to tone level.
The scene was basically a bunch of people with log statements of various levels in front of them and their lips moving with no sound.
I think I need a vacation.1 -
Accidentally left a test line in an API method - the first line returned a 200 OK response.
It was a notification API for our payment portal, so when they complained our API didn't work our logs always said all was fine...
After an hour of listening to our help desk guys saying "everything in our logs says it's fine", I looked at source for 2 seconds, fixed the problem, went home, had a whiskey and went to bed!1 -
(Meeting with Client)
Client: The script you sent us is broken... It can't run... We can't test now. (Their supervisor even insinuated that I did that on purpose :/ What?!)
Asked for logs, googled for solutions. Moments later.
Client: Oh it's our server's problem.
:/1 -
Me: Yes! I'm finally ready to upload my first Android app to PlayStore, im so excited!!
Google: Make sure to remove all the Log calls from your code.
Me: *Finds out that there's no way Android studio can make it for you*
FUUUUUUUU**10 -
So apparently due to an extremely talkative x input driver and an error in a certain app, I've been running an emergent keylogger on my computer for half a year. On every keypress event, the driver would call the app, the app would segfault, the driver would log the incident including the event to /var/log and then crash, and the app would restart the worker. I noticed this when I started wondering why /var/log is over 100GB in size.12
-
Emojis can make messages playful, fun, exciting.
Your documentation and commit logs should be none of this.
Keep your emojis the fuck out of them.13 -
I asked for some logs of the server... The guy brought me stacks of paper with logs from the server....2
-
Once my fuckin annoying colleague replaced all console.log to alert in our hybrid app..
And back then my testing logs used to be idiotically profane :|
Needless to say, I faced the fuckin wrath of clients :/ 2
2 -
Just found old logs I had with an ex-client, pre-devrant:
"What if we add the newsletter checkbox to the login, so each time a user logs in, he has to uncheck it, or else he will be subscribed to our newsletter?"
Not sure if that even needs a comment, I am speechless that was an actual suggestion, ever.1 -
> dockerized gitea stops working 502,
> other gitea with same config works just fine
> is the same config the issue? maybe the network names can't be the same?
> no
> any logs from the reverse proxy?
> no
> does it return anything at all on that port?
> no
> any logs inside the container?
> no
> maybe it logs to the wrong file?
> no others exist
> try to force custom log levels
> ignored
> try to kill the running pid
> it instantly restarts
> try to run a new instance with specifying the new config
> ignores config
> check if theres anything even listening
> nothing is listening on that port, but is listening in the other working gitea container
> try to destroy the container and force a fresh container
> still the same issue
> maybe the recent docker update broke it? try to make a new one and move only necessary
> mkdir gitea2
> all files seem necessary
> guess I'll try to move the same folder here
> it works
> it is exactly the same files as in gitea1, just that the folder name is different
> 10
10 -
*launch software*
> goes tits up with no info
*restart machine, launch software*
> still goes tits up
*su to the user it runs as and run it manually because fuck you shitstaind*
> still goes tits up
*launch with debug logs enabled*
> suddenly works
What is this black magic?!10 -
mysql server crashes every 18 days, no oom, no crash logs, no sigkill being sent (used auditd). so I figure it's a unknown corner case bug in mysql. now I use a cron job to restart the damn thing every week at 3am, not a problem anymore8
-
Did i just get rick rolled through a user agent?
"[17/Nov/2020:10:20:42 +0000] "GET / HTTP/1.1" 200 1274 "-" "We are no strangers to love. You know the rules and so do I. A full commitment is what Im thinking of. You wouldnt get this from any other guy.." "-""4 -
Some of the dinosaurs maintaining legacy systems are rather well meaning, but somewhat frustratingly don't seem to have updated their knowledge of what counts as "a lot of storage space" beyond the early 90's. Just asked one of them if they could dump all the legacy logs to AWS each day so we could keep them for 6 months or so (they're rolled over weekly otherwise.)
"Well I mean we can, but are you sure? *All* the logs? You could end up storing close to 100MB of logs a month! Won't that be prohibitively expensive?!"
It's rather cute really.11 -
Have been trying to setup Netdata as a monitoring system for a while now and finally got it working!
Instead of the built-in webhooks I just did a curl to a url containing a php page/file which error logs the status and description (just for testing).
It took me way too long to get it to work but BAM.
Immediately made a new cpu load rule (one minute high load):
The satisfaction of getting an error message in the php logs containing my custom rule as warning and a minute later as critical 😍
Netdata ❤6 -
When you can't figure out where you are supposed to add your code in the teams massive android spaghetti codebase. So you just add logs to every function that might be related to track down the function you need.
 1
1 -
By looking at our source code, I see what makes a bad programmer. I see "invalid data" in error logs, guess which of the following 3 conditions caused this:
function somefunc() {
if(condition_1) {
throw "invalid data"
}
if(condition_2) {
throw "invalid data"
}
if(condition_3) {
throw "invalid data"
}
return some_response;
}3 -
Have you ever checked your Teams logs??!
It even logs mouse/keyboard and window activity...
And reports it to your employer with fucking colorfull dashboards. Fuck them...22 -
Started part time job at a company, had to log my time on timesheets. Said fuck this and now the whole company logs their hours on a custom web based time logging system which I built.5
-
Today I found out when a user logs in in this piece of crap: 59 calls to the api just to get user permissions 😤
I'm done...5 -
today I experienced real-time bug fixing and deployment..
The phone was attached to the debugger, the client is using the app, me catching the logs.
Client: oh here is wrong behavior.
Me: *tapping on keyboard, then* ok try now please..
😅2 -
User:
"Your application does not show notifies"
Test the app, search trough the logs, try and try again. Nothing.
Me:
"Did you disabled the notifies in Windows"
User:
"Yes! Uopps...."1 -
client cto: "SOMEBODY COMPROMISED YOUR KEY!!!! IT SHOWS SOMEBODY LOGGED IN TO DEVOPS GUY'S ACCOUNT USING KALI LINUX!!!!! HERE ARE THE LOGS!!!!"
the logs: *show an ip address*
the ip address: *ip address of the office*
devops guy: *actually uses kali linux*
not really a rant, just found it funny2 -
I just got asked by a colleague why do I use different levels of a logger. He said he's been writing code for 10+ years and never needed anything other than Logger.debug() 🤦♂️
Where the fuck these guys get their degrees? 😒22 -
Today I just realized that a program I deployed was running without DB for almost a week. Thought it was populated suring the deploy.
Fortunately, nobody cared and was not exposed to any error logs1 -
OMFG I don't even know where to start..
Probably should start with last week (as this is the first time I had to deal with this problem directly)..
Also please note that all packages, procedure/function names, tables etc have fictional names, so every similarity between this story and reality is just a coincidence!!
Here it goes..
Lat week we implemented a new feature for the customer on production, everything was working fine.. After a day or two, the customer notices the audit logs are not complete aka missing user_id or have the wrong user_id inserted.
Hm.. ok.. I check logs (disk + database).. WTF, parameters are being sent in as they should, meaning they are there, so no idea what is with the missing ids.
OK, logs look fine, but I notice user_id have some weird values (I already memorized most frequent users and their ids). So I go check what is happening in the code, as the procedures/functions are called ok.
Wow, boy was I surprised.. many many times..
In the code, we actually check for user in this apps db or in case of using SSO (which we were) in the main db schema..
The user gets returned & logged ok, but that is it. Used only for authentication. When sending stuff to the db to log, old user Id is used, meaning that ofc userid was missing or wrong.
Anyhow, I fix that crap, take care of some other audit logs, so that proper user id was sent in. Test locally, cool. Works. Update customer's test servers. Works. Cool..
I still notice something off.. even though I fixed the audit_dbtable_2, audit_dbtable_1 still doesn't show proper user ids.. This was last week. I left it as is, as I had more urgent tasks waiting for me..
Anyhow, now it came the time for this fuckup to be fixed. Ok, I think to myself I can do this with a bit more hacking, but it leaves the original database and all other apps as is, so they won't break.
I crate another pck for api alone copy the calls, add user_id as param and from that on, I call other standard functions like usual, just leave out the user_id I am now explicitly sending with every call.
Ok this might work.
I prepare package, add user_id param to the calls.. great, time to test this code and my knowledge..
I made changes for api to incude the current user id (+ log it in the disk logs + audit_dbtable_1), test it, and check db..
Disk logs fine, debugging fine (user_id has proper value) but audit_dbtable_1 still userid = 0.
WTF?! I go check the code, where I forgot to include user id.. noup, it's all there. OK, I go check the logging, maybe I fucked up some parameters on db level. Nope, user is there in the friggin description ON THE SAME FUCKING TABLE!!
Just not in the column user_id...
WTF..Ok, cig break to let me think..
I come back and check the original auditing procedure on the db.. It is usually used/called with null as the user id. OK, I have replaced those with actual user ids I sent in the procedures/functions. Recheck every call!! TWICE!! Great.. no fuckups. Let's test it again!
OFC nothing changes, value in the db is still 0. WTF?! HOW!?
So I open the auditing pck, to look the insides of that bloody procedure.. WHAT THE ACTUAL FUCK?!
Instead of logging the p_user_sth_sth that is sent to that procedure, it just inserts the variable declared in the main package..
WHAT THE ACTUAL FUCK?! Did the 'new guy' made changes to this because he couldn't figure out what is wrong?! Nope, not him. I asked the CEO if he knows anything.. Noup.. I checked all customers dbs (different customers).. ALL HAD THIS HARDOCED IN!!! FORM THE FREAKING YEAR 2016!!! O.o
Unfuckin believable.. How did this ever work?!
Looks like at the begining, someone tried to implement this, but gave up mid implementation.. Decided it is enough to log current user id into BLABLA variable on some pck..
Which might have been ok 10+ years ago, but not today, not when you use connection pooling.. FFS!!
So yeah, I found easter eggs from years ago.. Almost went crazy when trying to figure out where I fucked this up. It was such a plan, simple, straight-forward solution to auditing..
If only the original procedure was working as it should.. bloddy hell!!8 -
Why does FireFox has the shittiest dev tools?
Working on my website and it kept throwing "TypeError: Failed to fetch"
with no other info
Opened Chrome and that thing gave me the entire error without even modifying my logs code, and now I can peacefully solve the problem -.-11 -
Setting Newyear's resolution to 4k..
failed: could not find X window system.
Please check the configuration logs.1 -
So we have an API that my team is supposed send messages to in a fire and forget kind of style.
We are dependent on it. If it fails there is some annoying manual labor involved to clean that mess up. (If it even can be cleaned up, as sometimes it is also time-sensitive.)
Yet once in a while, that endpoint just crashes by letting the request vanish. No response, no error, nothing, it is just gone.
Digging through the log files of that API nothing pops up. Yet then I realize the size of the log files. About ~30GB on good old plain text log files.
It turns out that that API has taken the LOG EVERYTHING approach so much too heart that it logs to the point of its own death.
Is circular logging such a bleeding edge technology? It's not like there are external solutions for it like loggly or kibana. But oh, one might have to pay for them. Just dump it to the disk :/
This is again a combination of developers thinking "I don't need to care about space! It's cheap!" and managers thinking "100 GB should be enough for that server cluster. Let's restrict its HDD to 100GB, save some money!"
And then, here I stand trying to keep my sanity :/1 -
The application has a system for sending reports and errors.
Client: "I have a problem with the app, I can not log in (android phone)"
I check the logs: "sent from iPhone"
(the person has no other account and registered telephone)4 -
Debugging Plex server: streaming a child movie on my phone and tailing the server logs on my flat TV1
-
A project I'm working on uses Elastic for internal monitoring and logs. The customer asked to access those logs - not something we'd normally do, but it's isolated from other things we use and there's no critical data there, so what the heck, let them have it.
Ever since, we're getting tons of questions like "There are tons of [insert random info message] all the time, do you have any plans to resolve them?" and it gets to the point where I'm just about ready to scream back "NO, SUZAN, BOOKING NOT COMPLETED MANS THE USER F###ING CANCELLED IT, IT'S NOT SOMETHING I CAN FIX IN THE CODE"
Edit: the customer's name isn't actually Suzan4 -
Jesus christ what is wrong with this one
12: Colleague deploys something to production (with a second pair of eyes)
14: Asks me why other team isn't seeing the result, I ask whether they have monitored the logs, they have not
17: They finally read the logs and find the problem, change window has ended so tomorrow there's another attempt
Today, they deployed again around 10 and then went away because they had some private responsibilities. Never looked at the logs, never bothered to verify if anything still worked. Just dropped it in a chat.
10 years older than I am, how can you be so irresponsible4 -
Friend: why do I get this error help
[I check the logs]
Me: uh,its a OOM, did you allocate enough memory for GC?
Friend: wait hold on
[changes a method]
[works]
Friend: I shouldn't use this experimental method
Me: Cool man blog it2 -
Today while looking at the logs, I found an issue.
The attached image describes this issue without going into too much detail about it, so like ... Enjoy I guess 🤷♂️ FML 4
4 -
I REALLY HATE IIS. IT IS THE STUPIDEST FUCKING PLATFORM. FUCK. WHERE THE FUCK ARE MY FUCKING ERROR LOGS YOU STUPID PIECE OF FUCKING CRAP. FUCKING KILL ME YOU STUPID SERVER ASS BITCH CUNT2
-
This morning I was looking in our database in order to solve a problem with a user registration and I accidentally noticed some users registered with unusual email addresses (temporary mail services, Russian providers and so on...).
I immediately thought about malicious users so I dug into the logs and I found that the registration requests started from an IP address belonging to our company (we have static IP addresses). My first reaction was: «OMG! Russian hackers infiltrated into our systems and started registering new users!»
So, I found the coworker owning the laptop from which the requests were sent and I went to him in order to warn him that someone violated his computer.
And he said: «Ah! Those 7 users? Yeah, I was doing some tests, I registered them. My email address was already registered so I created some new ones».
Really, man? Really? WTF5 -
ALWAYS read warnings guys.
Story time !
A client of ours has a synchronization app (we wrote it) between his inhouse DB and our app. (No, no APIs on their end. It’s a schelduled task).
Because we didn’t want to ask them for logs every single time, the app writes logs to disk (normal) and in Applications Insights in Azure.
When needed, I can go in portal, get all logs for last execution in a nice CSV file.
Well, recently we added more logs (Some problems were impossible to track).
So client calls us : “problem with XXX”
Me : Goes to Azure, does the same manipulation as always. Dismiss a smaaaaaalish warning without reading. Study logs. Conclusion: “The XXX is not even in the logs, check your DB”.
Little I knew, the warning was telling me “Results are truncated at 10.000 lines”.
So client was right, I was wrong and I needed to develop a small app to get logs with more than 10.000 lines. (It’s per execution. Every 3 hours) -
A cache - related bug that gets triggered only at high loads, 10k parallel sessions or so.
Parsing 30GB of logs, trying to find something to work with....
yippee......5 -
So I have a script that runs every time I turn on my PC. The script copies a few files to a ftp server in my basement. Forgot to turn off logging....
Opend the file in Notepad, and would you look at that, 1 GB of ram..? WTF?
Edit: Managed to open the file, turns out that it's been exactly one year since I started using the script. 3
3 -
My team: "Hey were getting errors with this process, whats going on?"
Net team: "Hey were getting errors with this process, whats going on?"
Me *looks at logs once*: "Did you guys check the logs? There's a 500 error on the Net side app since 3am this morning..."
Net team: "Oh yeah we changed that but we forgot it would break your shit"
Goddammit why am i not on the alertlist if you are all going to call me when shit breaks?! Doesnt make any sense!! -
-not commenting
-leaving console logs behind in production
-not testing if it works in IE
-using root too much
-using if instead of switch
-never staying consistent with naming conventions
-starting projects and never finishing3 -
Finally!
Got my Minecraft server running inside Docker to properly stream logs through Go to this shitty web interface. Fucking hell I didn't think this would be so fucking complicated!
Edit: Forgot the image :)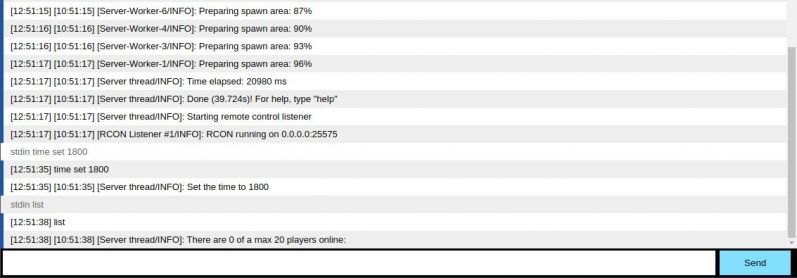 13
13 -
I just installed nginx on a new server, just to find out we have visitors waiting patiently at the door. I guess they must have tried all possible route to get inside an empty room. 😏
See logs hits on 404 files...
-
Goodbye, a night of work!
I just typed "rm * .sh.*" instead of "rm *.sh.*" for deleting the logs from a bunch of qsubs. Yes, I removed the logs... as well as the rest of the files in the folder.
Now, probably because of the lack of sleep, I'm laughing to keep myself from crying.
No more code for today!7 -
App fails, Check logs...No error logged. Check source code and debug....
And then you see following piece of code....
try{
//Code to hit an API
}catch(Exception ex){
/*DO NOTHING. Not even log stack trace*/
}7 -
This just happened....
Tester: My cluster is not working properly!!!
Me: What's wrong?
Tester: I don't know. I've checked all the logs available on the entire cluster. All i know is that node 1 and 7 is broken.
*ssh into the cluster*
node1
# less /var/log/<affected application log>.log
*no errors here everything is working properly*
node7
# less /var/log/<affected application log>.log
*goes down to the bottom and scrolls up a few lines*
<insert massive error here>
Checked all the logs eh? 3
3 -
Okay, so today I've taught a colleague how to use a simple office ruler to measure AWS server's CPU usage :) We needed to figure out whether CPU% spikes correlate with error message in logs an d latency spikes. Once again a ruler was the perfect tool for the job.
P.S. no, CPU% spikes did not correlate to errors in logs1 -
All these certifications and capabilities and years of IT experience and I find myself writing analytics against Minecraft logs for my kids's MC server to determine that my son really is being a jerk in game like my daughters claim.2
-
So apple wants you to open your system logs with Photoshop, truly? So the fuck up and crashes looks more "beautiful"?4
-
TeamLeader2: Mister IHateForALiving, client is reporting a bug, we need you to check out what is happening
IHateForALiving: I'm on it, anything I should know before I start?
TeamLeader2: just check the logs, they should tell you pretty much everything you need to know
The logs: 4
4 -
We found a binary string on our Loggly server. It's a PDF file .. the entire PDF file, being sent, to our logging service.3
-
There's nothing like the fresh smell of emails on Monday morning, soooooooo fucking many random emails, actually, 2,708 fucking emails, 99.9999999% are stupid useless logs or alerts that have no meaning to me, and yet, I have to setup outlook rules to filter out this shit.
Ah, another glorious Monday 😤3 -
My doctor's office logs into their computers using the Administrator user. 🤔Pretty sure that's how patient info gets leaked.2
-
Best feeling is when I prove to the client with screenshots, logs, and other materials that it was their damn fault not ours...
Speaking of screenshots... what is your fav screenshot tool? I use Greenshot.8 -
Well looks like my gcc compile check log pretty much matches with the LFS logs so I must be doing something right xD yay progress!
 2
2 -
The WiFi at my office requires username and password to sign-in and logs out after every few hours. Then I have to tap on "sign in" and submit the username and password again.
Is there any fucking way I could automate this.......?12 -
lately my IT mantra in the vein of "have you tried turning it off and back on again" has become "did you check the logs for error output"😡
NOTE to all developers of any level: if you want help do your due diligence! Check the logs, try to step debug and at the very least please at least pretend to perform a cursory search3 -
*The things you find watching logs*
From an innocent script I wrote to crawl Alexa categories for datascience team. 1
1 -
I've written a script that logs my time tracker information into my timesheet at work and its fucking fantastic, so simple yet so satisfying. I needed to tell someone5
-
So there's that project with my coworker. We splitt up the classes, 10 to be implemented by him, 10 by me.
Fast Forward to 4 weeks before deploy.
Coworker: Your stuff logs a lot of stuff. It's not very clear and a liiittle to verbouse. 5 entries per second? Too much!
Me: Okay, you're right. Let me fix that.
2 Days later I look at his logs at runtime. He logs EVRY SQL statement and their results! In a batch that processes a 10'000 of customers!
He points out: That's useful stuff and it's not that much. It's needed for debuging.
My face: 😦4 -
My kind of Makefile:
make it.run: docker-compose up
make it.stop: docker-compose down
make it.clear: docker logs cont_1
make it.test: npm run test
make it.deploy: ansible-playbook site.yml -
I've just checked my server's auth logs and my god that's a lot of failed ssh login attempts.
I think I'll install an ssh honeypot to waste these peoples time...8 -
Not a question per se but an assignment -
Design an application that could find logs between two timestamps where the logs are stored in 10000 files, each with a file size of ~16GB.
For an entry level position this was a really good and interesting problem to solve.11 -
One day I want to replace all "ERROR" logs with "FUCK":
09-31-26: FUCK: Database not initialized.
09-31-26: FUCK: Unable to parse input.2 -
58 of 64 tests failed
Me: "what the actual fuck."
*spends 10 mins looking through logs wondering why these valid tests were marked as failed*
Me: "Oh shit I just configured the test case wrong" -
> Am writing code
> Life is good
> Add debugger keyword
> Script pauses
> Type in var name... Undefined.
> ...What?
> Check out local scope. It's there. What the fuck?
> Add console.log(myVariable)
> Refresh
> Logs variable no problem. Cool.
> Type in my var name
> Undefined
FFFUUUUUUU-7 -
Google, I can understand why you would want to translate the change logs to my language, but THIS IS NOT MY LANGUAGE! I am very curious what language it is though.
 15
15 -
i know i sound like a broken record...
but 100$ a year to have the prestigious privilege to develop for iOS, granted by the god emperor Jobs himself....
and no fucking proper output logs during build-time....
100$ a year... professional software...
https://youtube.com/watch/...1 -
Random code review:
contractor changes 2 lines in the .gitignore and 1 line in the composer.json and logs 4.5h against the related ticket .. hmmm2 -
Bug requires 2 developers, full-time for 4 days to trace, debug, scratch heads, analyse logs. Third developer helping occasionally. Finally identify fix. Fix is 2 lines. D'oh.3
-
i transferred shitload of code from one class to another, stackoverflowed something and copy pasted it because i have never seen that this needs to be written like that, hit run compile, open up my logs expecting a mass crash and possibly explosion. it worked on the first try
 2
2 -
PC crashed while in the middle of a build, "ok, shit happens". Reboot, pc is super sluggy (a BSOD kinda does that, I guess). Reboot again and I check the event logs...I didn't find the problem, but at least my pc is sorry for whatever it was doing earlier.
 1
1 -
When you realize that you have only couple of gigs left on your SSD and the culprit is 41 GB log file.1
-
Still having problems with samba doing weird shit. Now looking through the logs and
Hm... *that* doesn't seem right 🤔 3
3 -
I have an Android development midterm on Sunday ON PAPER!
Anyome knows how to do alt+enter on paper? Or the logs?1 -
lol nvidia-bug-report.sh
it collected an xorg log that is not the current one.
For some reason, my arch openbox logs to $HOME/.local/share/xorg/Xorg.0.log.
What a goddamn trainwreck. I'm not necessarily saying it's nvidia's fault. But it is a trainwreck.4 -
Using Ubuntu from years, never knew this logs file named 'syslog.1' could start filling about 80% of my root space 🤦.6
-
Anyone got any cool arduino/pi projects they want to share? I'm currently iteratively building a self-hydrating cactus that measures the soil moisture content and sunlight and logs it to my server, just because i can, then waters the cactus for me if it needs it.4
-
Here’s how my Friday night is going:
def signin
if should_not_sign_user_in?(stuff)
return redirect_to :nope
end
# signin logic
end
The guard says I shouldn’t sign the user in. It logs the details of why. I read the logs; they’re all correct. It logs the return value, which is false, and the user gets signed in anyway.
Wat.
There’s a return and a redirect there!
This is only happening on the QA server, too, so something fishy is going on.5 -
Young 22 years old me, hungry for excitement of real world issues, full of whimsical witticisms, writing bootstrap scripts that'd spit meaningful information like...
> $ run bankhack
> Shutting down the old world...
> Checking world population...
> Initializing particle accelerator...
> Exploding sun...
> Entering hell...
> Starting daemons...
> Starting lesser daemons...
> Burning logic...
> Restoring balance in the universe...
> World peace achieved.
What a naive douche he was.1 -
Package Installer on android needs to show something other than just the progress bar. Even a basic log like windows installers that say, "copying this, extracting this, done..." If it affects the minimalism of the interface, they could try doing what Tor browser does- swipe to see a log. It just feels heartbreaking to wait 5 long minutes for it to process on this tortoise device, and then get, "app not installed." with an OK button. :( Like, whyyyy? There should be a "THAT'S NOT OK" button.
Is there any magisk module for this? Or some other tweak?5 -
When starting projects, following semver.org quickly gets out of hand. Nothing is "backwards-compatible"
0.0.0 gitignore
0.1.0 prints arguments
1.0.0 prints text of web requests
2.0.0 prints parsed web requests
3.0.0 prints filtered requests
4.0.0 prints using yaml
5.0.0 logs to file
5.0.1 catch error
5.1.0 interactive2 -
Struggling to debug a test which prints out like 400-500 lines of logs in console and I can't find any of those to be useful.
Me while debugging with DevRant ..
Is this the end of my life!!!!
Even without a wife..
I should start collecting some bucks,
And buy some ducks,
The devDucks,
To accompany me through the mist of the unknown console logs,
Playing treasure hunt,
Performing stunt,
And find out the hidden treasure behind this mist2 -
THREE DAYS of debugging, reading all the logs I could find, creating tens of new logs in our appliaction, and SUDDENLY an email from your IT admin:
"Hey your CURL requests are being rejected by my !oh so secure! firewall rule".
Not that I haven't said at the beggining, that THIS IS YOUR F...G NETWORK PROBLEM because we get "connection reset by peer" errors, and you ASSURED that everything is CHECKED and OK! 5
5 -
My boss keeps looking into the system log file and being scared of some totally irrelevant messages (for him). Time to introduce permissions in the control panel...1
-
Bunyan
Bunyan is a simple and fast JSON logging library for node.js services
Server logs should be structured. JSON's a good format. Let's do that. A log record is one line of JSON.stringify'd output. Let's also specify some common names for the requisite and common fields for a log record.11 -
Manager X: (logs a support ticket) "Agent is unable to access system using the password provided."
Me: "You're going to have to narrow it down a little, we have over 1000 active agents."
I hate the support side of my job... -
Worst week ever.
Servers are on fire. Respoinse times out of control
Some SIMPLE SQL queries (literaly select * from whatever where Id = id) timouts at 30 seconds.
No idea what's goining on (And I have full logs of all api calls and all DB queries). No way to find how to corelate this data.
Ok, I added 1000$/month on Azure and the problem is "masked", but not resolved.
I have dumps, I have logs I have everything, why the fuck I can't find the 1 or 2 APIs causing that ?!!!
Now I feel better.10 -
when a single python indent error crashes your entire web app, and the error logs don't pick up the issue -.-
-
I love nginx' docker container, but it always takes me 2 minutest to remember that an idle nginx container does NOT output any logs
So here's my dumbass staring at the log output, thinking something's wrong2 -
After a week of logs investigation, we finally found a solution for performance issue. Just scaled up the app vertically to the next tier plan in Azure.4
-
“I do trust you, just let me see the logs”
- our colleague after we present to her good feedback from the demo just passed ok5 -
The more I surrond stuff in try{...} statements, and handle with geeky error messages that should actually never happen (e.g. "TransactionId 73545 not find for UserId 10. Look for Interaction 212345 at the logs."), the more I think our Customer Support area will someday need a Customer Support Support area.
-
A guy using our tool that automate rest api calls requests a feature to add the request body in the logs.
He was using “get” calls with no request body as a proof of missing feature.2 -
The creator of this library logs error which makes me feel like a Shaolin Monk reading a scroll...
I shall now head towards that direction. Thank you master Shiva 🙏 1
1 -
When offshore overwrites your (100% to spec) content and then logs a critical defect because the incorrect content is showing...1
-
So I was digging our chat logs in 2017
That time we were coming up of alliterative code name (Ubuntu-like)...
... it didn't end well... 1
1 -
Chrome with Dev Tools, IDE, Database, Server logs, terminal - what windows do you guys keep open at all times?10
-
Had a customer today that claimed that crontab did not work as it should, and he has proof of that (in form of some very abstract logs).
Well, I guess noone can rely on one of the most fundamental binary in the unix world. -
Maintained a Jenkins instance once. Shut down a slave, and forgot to tell the master.
45gb of logs later... -
I don't fucking understand why certbot never seems to renew my domains. I try everytime I get one of them anoyying emails but still fail.
Currently trying while watching the webroot and apache logs. Nothing fucking happens. Someone experience with these problems?7 -
Work office, using xencenter for viewing xenserver server, tailing some logs and manjaro (arch linux) for bash stuff, and a coffee for good habits hahaha
 4
4 -
bug with no steps to reproduce
logs show null pointer exception but doesn't have a stack trace to point a bad line of code
fuck jersey and jettycounts6 -
Server behaved weird and I couldn't find out why. Nothing on the logs.
As a personal side project, I've translated the whole project to Scala. Boom! FileNotFoundException. There was an incorrect path somewhere.
I still don't know why Java did not throw.2 -
Not a rant.
But, who loves to run gource on your project's directory and gets excited staring at the awesome animation created based on the git logs.
+1 If the whole team stares at it and yell "Look, thats me adding the .... component" -
QA guy: Your app crashed on this Samsung.
Me: Checks Firebse logs and finds out that phone was rooted and tells QA guy.
QA guy: You must consider all use cases.
Fuck you dude!2 -
Just a helpful hint: if you ever run Firefox from the terminal for any reason, use "firefox &>/dev/null &". It runs on the same thread and spits out tons of random logs.
Edit: also, hello world! Almost forgot. :)2 -
How dangerous am I?
I code it live.
I code while people are working on our website and make all the changes live. And if I notice an abrupt stop in responses to our logs I git stash my changes.5 -
How the fuck do you actually tail log files?
Like i want the whole log. Not only from today, not *.log.1 and *.log, i want to run the *whole* log ever done, even the gzipped shit, through tail | grep.11 -
Customer complains about an issue after a software update. The head of department himself tested the update and got an error message.
Me looking at the logs. Ok, that's an issue, but based on hardware failure, customer should fix his hardware, no relation to the new software.
But surprisingly close to the software update, which piques my curiosity.
Me looking at older logs ... same issue. EVERY FUCKING DAY. For months. The corresponding error message only appears if a user is logged on, so quite a few people have seen it. Obviously nobody cared. Maybe we just ditch error messages, it'll save lots of work. -
One of our integration solutions (via Webservices) had some issues. I had to switch on http logging to see what might be the issue.
On average, those logs are around 20MB when there is a bunch of traffic. But the solution brought a heap pf traffic through, those logs shot up to 1GB in size.
Had to delete the logs, since they took a million years to open, and told our vendors that the logs are not showing us anything 😅 I told no lies -
You know what's hard...
Fixing a bug which occurred in production without having any logs because you log that useful info at debug level. 😧
Now take pen and paper, do calculation on your own and speculate what would have happened in production.3 -
FML, somebody here or somewhere wrote that al customers lie..
Just been a witnes to that.. Over skype (mind I reminded them to write to jira on several occasions so others can help if I am out of office) feature xy is not working.. I log in to server, I see no logs of person a doing anything with our system, let alone use the xy feature... Well duh, of course it doesn't work, it's not a freakin mind reader.. :/
Next time no help, no log checking, no nothing until they provide ss of what exactly they were doing.. :/ Fuuuuu....3 -
Isn't it fanbloodytastic when you switch dev teams and your former team mates start blaming you for broken builds?
Fortunately I had logs to cover my arse. F*** blameworthy company cultures. -
Updated my Azure aide project to ASP .NET Core 2.0.
Works perfectly in develop in Debug and Release.
Deploy to Azure.
502.5
No error logs, no feedback, no explanation.
K den.1 -
To fix a bug I added a few log messages to trace what gets executed and in what order (very new to the project). Fixed the bug, pushed PR and the only comment was to remove the log files. 🤦♂️🤦♂️
Please tell me this is normal or should I start looking for a new place that hires "only the best" 😭10 -
So I've been given a task to monitor a whole lot of logs of some servers (whole university ~ 10+ departments). The technologies are diverse so I'm cramming everything into elasticsearch via logstash (and filebeat), viewing it into kibana. Any recommendations for what should be the 'useful' stuff to be viewed into dashboard? I guess:
- Overall traffic wtih respect to previous days/weeks
- Most viewed domains
- 200
- 404
- 503
- Failed logins?
- Dropped connections?
- Critical-load of systems? 90%+2 -
I changed my twitter password on web on the day they discovered the passwords in plaintext in their logs, and till today, I've not been logged out of the mobile client1
-
> punch into work
> get comfy on the desk
> push previous commits along with new commit
> GitLab showed only the last commit i.e. today's
> *fml*
> check logs, found nothing
> now, waiting for coffee while figuring out why it is bothering me2 -
Yes, send me a screenshot of the logs. Beacause I love having to re-type the error you just got. If only there was a way to copy paste text in Slack!
I did not know I was working with my grandma...6 -
Logs in to client office 365.
Big recommendation at the top
"Disable password auto expiry, it's currently set to 90 days"
Why is this a recommendation? I suppose there's an argument that making a user change every now and again will weaken their passwords over time, but really?2 -
got this cloud provider who is very knowledgeable, however they set up some logs analytics shit on our one Azure tenant which is costing more than the web apps we host and he's going on about how it's really important that this shit is there because hurr durr security.1
-
SFTP timeout errors.. nothing to find in the logs (if i look in the right logs that is) and my balls hurt. My evening cant get better lol4
-
Ahoy der Ranters!
I'm looking for a log management service. My server application has a 90 days rolling policy (with gzip) but I would like to store logs somewhere else before they get deleted (after 90 days).
I've heard of Cloud watch, paper trail, and logz.io
What would you recommend?5 -
We use celery at work, and one of the issues we face is that we use Django logging.
I'm not sure how it happened, however we only get 1 level of tracebacks from it now.
This has made debugging painstakingly difficult, since we have to manually traverse the code every time.
(we're in the process of moving to sentry, and we'll get our full logs back soon)1 -
Note to self: when you extend a functionality by rewriting a relevant part, remember to mark the old code as deprecated or delete it.
AKA "why the hell I´m not seeing anything in logs/db that reflects my changes" T_T -
Can anyfuck tell me what the fuck I'm supposed to do?
So I installed gitlab, reachable under a subdomain (gitlab.example.com) behind apache2. everything works fine.
Now I see this bullshit in my logs, appearing EVERY GODFORSAKEN SECOND: https://gist.github.com/nitwhiz/...
I disabled the bundled nginx in the gitlab.rb and no, it's not "some nginx system service", I verified it is coming from gitlab and oh - btw - some weird svc logfuck runs even after gitlab is stopped! :)
No I won't try your random google result because I read all 3 tickets being at least half relevant to my situation as ANYFUCKER ON THIS PLANET seems to use the internal nginx.
FML.14 -
I love Azure. But WHY do I need to add vCores SQL for more logs/io ?
Why is it even limited ?
So no, I won't add 350$/month for 1 more vCore just for some more Mbits of log io bandwich 6
6 -
Received a client who managed to crash a Wordpress site in a weird way, now every time I log in to admin to fix it, it logs me out after 3 seconds :|
Fixable, of course.
How does one in this situation (using default options) I'll never know.1 -
I hate cron jobs. Hours of googling and double checking. My job is perfect. Still doesn't run according to the logs2
-
SharePoint: Designer is discontinued but they haven't released an alternative method of creating custom workflows...
Also, SharePoint only shows correlation ids, which you'd have to check the logs to see what the error was (no description or error code for user): SharePoint Online doesn't split their logs by client... so they can't give clients access to the logs even if they wanted too. Only option is to contact their support... seems overkill when the error may be a user trying to upload a document with the same name.1 -
Debbuging options that no customer uses since it makes the logs unreadable.
Formatted the logs and in 3 Years Not one customer used the feature or asked for it.
---------
An automatic tool (like smartgit) for our internal use. Not one uses it, instead they still complain about git2 -
Parsing logs to create conditional insert statements cause expert morons fucked up production database cluster.
Database is partially corrupted and cannot be used and they don’t know how to fix it.2 -
It's almost like everytime I open the BitBucket pipeline logs my pc starts running the pipeline instead of BitBucket
Even visiting the logs spins up my fan so quickly that it's noticable for the people around me.
Instead of launching a pipeline it launches my pc3 -
So I just found out I have to use amazon (instead of Heroku) for hosting a service I'm supposed to build. The environment just f**king refuses to bild and these are my logs. fml...

-
A command line tool built in Python that helps you analyse your git logs by exporting them into a csv/json file.
Can fetch the logs from a given file path or a git directory.
https://github.com/dev-prakhar/...3 -
I was just playing with Eventbridge for research for a potential project, and I wanted to test setting up a Cloudwatch Logs target. I go to set up my target, click save, and am presented with "Resource limit exceeded".
After some digging in my browser's network inspector, and some googling, I discover that the account has reached its quota of Cloudwatch Logs resource policies, which can't even be viewed in the console, only the API and CLI.
Is network debugging and StackOverflow really the intended method of troubleshooting this issue? What the hell was I supposed to do with "Resource limit exceeded" and no further info? -
me: "say, TL, why don't I see any debug/info/warn logs in dev/qa environments?"
TL: "Yeah, we've disabled them, the logs are too expensive (ApplicationInsights)"
thanks bro... go debug this shit yourself... -
Test engineers not even checking their tests and logs..... Just straight up sending a trouble report. Then I have to waste one hour checking the log and lo and behold their tests do not even work to trigger the behaviour that's supposed to be tested. Morons.
-
!rant
Who else uses Excel to analyze and make charts using normalized log data? (writes apps to parse and normalize them)
Or is there a better way to inspect server logs?6 -
This guy has been a “php programmer” for 3 years now and yet he doesn’t know where to find Apache logs, is it weird that I am finding this really strange?11
-
Is there an ios app that records my gps logs for last n day(cyclic buffer)? Privacy is also important: data shouldn’t leave my phone: no internet access.9
-
Thoughts on the idea of including links/query starters for debugging or where the fucking logs are in AWS, grafana etc in repository READMEs?1
-
When an error page fails to download a file crucial to the error page and there's nothing in the logs2
-
I've just spent 4 hours trying to fix a bug on prod. that can be fixed in 30 secs. At the end I remembered that I should check the error log. FML (error reporting turned off, logs only)
-
Rewriting scripts to blacklist IPs of hacked accounts from SMTP logs. Very fun learning experience. Not really any other cool projects for me lol
-
Like a service
Pushed for the very first time
Like a service
With your FileBeat
Next to mine
Gonna give you all my logs, boy
My shard is fading fast
Been saving it all for you
'Cause only logs can last
You're refined
And you're mined
Make me strong, yeah you make me bold
Oh your logs thawed out
Yeah, your logs thawed out
What was said to be deployed
Like a service
Pushed for the very first time
Like a service
With your FileBeat
Next to mine1 -
It took me 48 hours ( not continuously) to fix a bug by going through a cluster fuck code of multiple modules. Tracing the error through 5 or 6 layers. And u dont get error logs right away. You need to recreate that error and see the logs on a kubernetes pod. Just to find out the bug was a duplicate.
Yes jokes are on me. I fucked up by not checking for duplicate. I steered right away on that shit dipped bug like a hungry/zombie hound. Fuck me. -
Imagine enabling verbose logging for a complex ETL process that typically takes 8 hours to run but has been failing for some reason after running for about 7 hours. Naturally, you want to check the log file to find out what went wrong.
Now imagine not having read access to the log file. -
Primary debugging tool while working with PHP: print_r();
Primary debugging tool while working with Angular: Developer Console logs
Primary debugging tool while working with Node JS: Node Terminal.
What's yours?3 -
Spent 4 months to implement an impulsive thought to save logs size. Now, I'm ambivalent if I should extend it further or leave it on its fate.1
-
wait..... can you auto indent console logs depending on their nesting in functions?
I just realised it can be hard to read console logs because say you do
log('here 1')
callFunction()
log ('here 2')
But callFunction does a bunch of logging, then your here1 and here2 become separated !
But if you could make console log automatically add a couple spaces for every level of nesting/scoping that would be ideal .. ? 👀11 -
I had a dream last night that I saw php error logs from my code floating above people's houses if they were using the site.
-
You know you're having a seriously off day when you make code changes and execution remains the exact same... I've been throwing down logs left and right and nothing is changing! I am surely going to hate myself when I figure out how stupid this mistake is...
-
again xdebug not working and not giving any logs.
How can I at least get logs so that I could know what is wrong with it? I already tried this answer:
https://stackoverflow.com/questions...2 -
Things that wasted my time this week:
bash in my .cshrc
Using the wrong application to open waves.
Logs after an if(a thing) return;
Updating i3-gaps and using my config and it locking up.
A testing machine having the wrong kernel as default.
Not a bad week :) -
I keep a collection of strange logs I see scrolling by the CI Pipeline. What's your strangest log entry?
-
Half a day wasted. FUCK!
I use grafana loki and mimir/prometheus for telemetry. A few days ago I queried loki to see if logging is still working. Yesterday I changed the datasource to mimir, changed the query parameters to get metrics from another env, ran the query, and... Querier [mimir] crashed.
Wtf.
Error says it got too much data to chew on.
So I spend 4 hours playing with the querier and grpc limits, balancing between limit errors and OOMKills [2G ram].
I got suspicious about oomk. Why would it...
Then I tried to shrink the timeframe to 15min. Still oomk. Down to 5min -- now it worked. But the number of different metrics returned was over 1k
then I look once again at the query. And ofc it is ´{env="prod"}´
turns out, forgetting that you're querying metrics with a logs' query is an expensive and frustrating mistake. Esp. at 3am.
idk why it even returned me anything...5 -
- Create a Cron to delete users with course status 'enrolled/incomplete' for several months based on existing courseUpdateLogs
- Run Cron manually 1st time
- Find out courseUpdateLogs were very incorrect
- Find out a LOT of valid users got deleted and can't access their worksite
- F***9 -
Arch switch update: after a day I still haven't gotten past sddm. KDE won't start on either X or Wayland with no logs in sight. Everything worked in VB.1
-
stupid docker creators. Why the fuck when something does not work it does no show errors. I had so much anger till idea came to head to ask on google does docker has logs and found it has - docker logs command. And I saw fucking errors and then I knew by them what to fix. Idiots, hide errors when runing docker-compose up, what are they smoking when creating docker.
And even after docker-compose up it showed done !! Done sounds as everthing went without fucking errrors!!!! But when running docker ps there was no such container! Because when running it - it was giving errors.13 -
Another follow up. All these apps I m using to analyze the logs now, I apparently built years ago when I had 20% time or slack.
Even I don't remember that I already built some of them...
I was actually thinking ", wouldn't it be great if we could download all the logs at once for a specific API and date?" and then I open my AiO WPF app and it has button titles Logs Downloader... and it's located next to another that I found a few days ago, Logs Analyzer.
This stuff is going in a blog post I hope.... So guess you can just think of these as keynotes. -
Thanks, management, for letting us use AWS glue but not letting us have a dev endpoint so we need to determine what the fuck is going on by reading logs and divination if there is a deep problem
-
The higher one is, the less in touch one seems to be and tend to be more preachy and such.
Had an "architect" ask me what is that "tail" command I did when I showed him application logs. -
Excel crashes after some minutes (sometimes seconds) of working perfectly if I have the WakaTime Excel Add-in... correlation doesn't mean causation, but wtf?
I want to report it but I don't have the time to look for logs and Excel shit.8 -
It was around 5 am in the morning when I deployed to production,
And suddenly after few minutes I was watching logs and found that feature effected other part and users getting errors, I fixed it immediately directly on master branch and pushed again, -
If you find "FFFFFFFFFFFFFFFFF....." in my debug logs kindly and recursively add 'UCK! ' after each F.
-
The worst project i work on is my actual project, this is not a dev project but a "Run the Bank" project !
check 3 times a day that servers are okay, logs are okay, unduserssolvedunderstand and give the "how to fix" to the dev team #pan1 -
How do I deal with this;
Edge case hiccup on production, no errors in the available logs(very shallow logging), no access to the production server, issue unreproducable on staging and a manager that want me to fix it AFTER I already said that im kind of sailing blind and can't do much without logs or access, and already looked at it with another dev who also has no idea what is going on3 -
Some days I fear I'm the most incompetent. But as someone else made the comment... There are git logs with useless commit messages...
-
Over 3 months, I wrestled and toiled with learning how rsyslog works, send to the log server, passes that to AlienVault OSSIM, where I have to build a plugin that, I thought could be done with a built-in plugin builder but ended up with building it from scratch, and have to learn Regex (surprisingly was fun thanks to amazing online resources), test, build, restart rsyslog, ossim-agent, ossim-server and ossim-db just to get the application log showing up on the BROWSER!
I like OSSIM but what's killing me the most is rsyslog. I still can't get grasp how to get custom logs of any kind into a log server. I don't think I'll remember any of this by tomorrow but whelp. -
chmod a+w storage/logs/laravel.log
This command makes file writable.
So why I cannot edit the file after runnign this command ? No errors were given after running.
Tried also with -R on logs folder.
WHat is happenign with the software, why nothiing works?14 -
I have a server that's is happy being full. Well atleast that's how I think of it ... I deleted all the logs and anything I thought was taking up space the server will go from 93GB space ussd out of 120Gb. To 119GB used in least than 10 minutes... am tired I fell like just turn it off physically in the server room and going to sleep .. f%$$%k this . I have cleared logs like 10 times now4
-
- Running a release build on my phone (forgot to change variant)
- Spent 5 minutes figuring out why my changes with the logs weren't working.
🤦♂️1 -
Just a reminder: it doesn’t matter how it’s advertised. They all have logs.
https://thehackernews.com/2017/10/...1 -
To all my sysadmins/devops, what's your opinion on GoAccess (if you've used it or are currently using it)?
















































































































































































































































Top Tags
Weekly Rant
View