
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I know it wasn't ethical, but I had to do it.
Semester 4 started this week, we all got to vote which day we wanted the lecture to be held on. There were quite a few options. My preference was Monday at 7:30pm.
So I entered the poll, as I have every other semester. But I noticed something, this particular poll didn't require any form of identification. Not even a Student ID.
I dug deeper, found that it used local cookies to store weather you'd voted or not, this is obviously a security problem, so I opened up Python and wrote a simple Selenium program to automate this process.
I called it the "Vote Smasher". First it would open the webpage, then it would choose Monday 7:30pm and vote. Then it would clear it's cookies, refresh and do it over again.
I ran it fifty times.
Can you guess what the revealed vote was for UCD SP4 IT was?
I heard my lecturer mutter:
"The votes aren't usually this slanted..."
I could hardly contain my giggles.
My vote won by about fifty over the others 😂
Let me just say, it was his fault for choosing such a naive poll system in the first place 😉36 -
Today I discovered that we have a CSV export button for an order transaction system, on a page which is completely disconnected from the rest of the website.
It is only being called by an internal server, used by our Data department.
They run selenium to click the button.
Then they import the CSV into a database.
That database is accessed by an admin panel.
That admin panel has an excel export button.
Which is clicked by our CFO. But he got bored of clicking, so he uses IFTTT to schedule a download of the XLS and import it in Google Sheets.
That sheet uses a Salesforce data connector.
Marketing then sends email campaigns based on that Salesforce data...
😒11 -
A is for Assembly, a wizard's spell
B is for Bootstrap, so bland and the same. And also for Brainf*ck, will blow you away
C is for COBOL, your grandad knows that
D is for daemon, your server knows what
E is for Express.js, you node what is coming
F is for FORTRAN, which is perferct for sciencing
G is for GNU which is GNU not UNIX
H is for Haskell using functional units
I is for Intance, An action of Object
J is for Java plays with them Always
K is for Kotlin, Android's new toy
L is for Lisp, scheming a ploy
M is for Matlab, who knows how it works
N is for Node a bloatware of code
O is for Objective Pascal, you did not expect that
P is for programming, we all love to do that
Q is for Queries, A database is made
R is for R, statistics are great
S is for Selenium, you have to test that
S is for Smalltalk, let's make it all brief
T is for Turing Test, how human is this?
U is for Unix, build with all talents
V is for Visual Studio, built with all laments
W is for Web, lets build something cool
X is for XHTML, remember all that?
Y is for Y2K, I'm tired as f*ck
Z is for Zip, let's zip is all now.
Get yourself coffee and back to the grind.8 -
My first complete pipeline with Jenkins:
- push on gitlab
- build with maven
- test with junit
- deploy with Ansible
- integration test with Selenium
I love devops!6 -
up at 11:30pm finishing some work when fire alarm goes off.... waited to see if my tests passed before leaving3
-
My dream was shattered!!
I joined a new company. I graduated last 2 months before and joined as data analyst.
So I was dreaming to work on some awesome research projects and all, but it was just another dream...people here don't work on any sort of data analytics instead the data science team uses regex and all to extract things and say they are building models.
Ahh...wtf!!!
Many co-workers are good and help me, but the boss. He left all the annoying works to me and the release is in next month...
"BRUH I JUST JOINED YOUR COMPANY!!!"
Then after some days he gave me more task, when he found that one task was super easy(i mean it was just to extract things using bs4 and selenium, hardly will take an hour) to do then he took that himself and in the next meeting said he did that work and it was super difficult!!!
Data science here to senior members is just for loop!! I dont even know why I joined this firm
Ahhh!!! I want to scream!!! 11
11 -
My internship is coming to an end and I think my boss is testing my limits.
So, in the beginning of this week, he assigned me a non reproducible bug that has been causing trouble to the whole team for months.
Long story short, when we edit or create a planned order from the backend, once in fifteen, a product is added to the list and "steals" the quantity from another product.
Everyone in the company has experienced this bug several times but we never got to reproduce it consistently.
After spending the whole week analyzing the 9 lines of JS code handling this feature, reading tons of docs and several libraries source code. I finally found a fix by "bruteforce testing" with selenium and exporting screenshots, error logs and snapshots of the html source.
This has been intense but was worth the effort, first, I fix a really annoying bug and second, I learned a lot of things and improved my understanding of Javascript.6 -
I worked on a small project which required selenium for automation! Used the same technique to spam messages to friends in WhatsApp! 😂😂😂2
-
Some random coworker has been asked to setup tests for the framework written in Java and the GUI is a web app that comes with the framework.
Since he doesn't know any language we work in, he decided he would do it in Python. When I asked him why introduce Python and he replied with "it doesnt matter which language it is because it is going to run on selenium"
I told him to either use Java or Javascript for selenium because when he leaves we should be able to maintain the tests and not first figure out what the hell you wrote in Python
He didnt understand and is going to go with Python anyway8 -
Got moved to testing last week, (due to lack of testers) being a developer it requires a whole different mind set to test !!!
But running selenium scripts and again verifying manually sucks.
But what hurts the most is rejecting something that you approved during peer review 😱🤭3 -
That feeling you get when you write an automation package on top of selenium and python that at a press of a button runs through an entire User Checkout process 😍
Oh the hours this is going to save me.
Now to see what else I can automate in my day to day life.3 -
Chrome, Firefox, and yes even you Opera, Falkon, Midori and Luakit. We need to talk, and all readers should grab a seat and prepare for some reality checks when their favorite web browsers are in this list.
I've tried literally all of them, in search for a lightweight (read: not ridiculously bloated) web browser. None of them fit the bill.
Yes Midori, you get a couple of bonus points for being the most lightweight. Luakit however.. as much as I like vim in my terminal, I do not want it in a graphical application. Not to mention that just like all the others you just use webkit2gtk, and therefore are just as bloated as all the others. Lightweight my ass! But programmable with Lua, woo! Not like Selenium, Chrome headless, ... does that for any browser. And that's it for the unique features as far as I'm concerned. One is slow, single-threaded and lightweight-ish (Midori) and another has vim keybindings in an application that shouldn't (Luakit).
Pretty much all of them use webkit2gtk as their engine, and pretty much all of them launch a separate process for each tab. People say this is more secure, but I have serious doubts about that. You're still running all these processes as the same user, and they all have full access to the X server they run under (this is also a criticism against user separation on a single X session in general). The only thing it protects against is a website crashing the browser, where only that tab and its process would go down. Which.. you know.. should a webpage even be able to do that?
But what annoys me the most is the sheer amount of memory that all of these take. With all due respect all of you browsers, I am not quite prepared to give 8 fucking gigabytes - half the memory in this whole box! - just for a dozen or so tabs. I shouldn't have to move my web browser to another lesser used 16GB box, just to prevent this one from going into fucking swap from a dozen tabs. And before someone has a go at the add-ons, there's 4 installed and that's it. None of them are even close to this complete and utter memory clusterfuck. It's the process separation. Each process consumes half a GB of memory, and there's around a dozen of them in a usual browsing session. THAT is the real problem. And I want to get rid of it.
Browsers are at their pinnacle of fucked up in my opinion, literally to the point where I'm seriously considering elinks. Being a sysadmin, I already live my daily life in terminals anyway. As such I also do have resources. But because of that I also associate every process with its cost to run it, in terms of resources required. Web browsers are easily at the top of the list.
I want to put 8GB into perspective. You can store nearly 2 entire DVD movies in that memory. However media players used to play them (such as SMPlayer) obviously don't do that. They use 60-80MB on average to play the whole movie. They also require far less processing power than YouTube in a web browser does, even when you download that exact same video with youtube-dl (either streamed within the media player or externally). That is what an application should be.
Let's talk a bit about these "complicated" websites as well. I hate to break it to you framework web devs, but you're a dime a dozen. The competition is high between web devs for that exact reason. And websites are not complicated. The document itself is plain old HTML, yes even if your framework converts to it in the background. That's the skeleton of your document, where I would draw a parallel with documents in office suites that are more or less written in XML. CSS.. oh yes, markup. Embolden that shit, yes please! And JavaScript.. oh yes, that pile of shit that's been designed in half a day, and has a framework called fucking isEven (which does exactly what it says on the tin, modulo 2 be damned). Fancy some macros in your text editor? Yes, same shit, different pile.
Imagine your text editor being as bloated as a web browser. Imagine it being prone to crashing tabs like a web browser. Imagine it being so ridiculously slow to get anything done in your productivity suite. But it's just the usual with web browsers, isn't it? Maybe Gopher wasn't such a bad idea after all... Oh and give me another update where I have to restart the browser when I commit the heinous act of opening another tab, just because you had to update your fucking CA certs again. Yes please!19 -
Question time:
Has anyone used PHP unit with Selenium before?
I have a.. well words can’t explain it nice enough but, beyond a joke, not even funny, spaghetti code base I’ve come to inherit recently, which god help me, doesn’t follow any design patterns at all, it’s just a stamp this here, staple this down over here and throw paint at the wall and hope it sticks.
It’s a mixture of procedural and functional with the rare class kind of mess.
So attempting to refactor by any means is not a real possibility without some kind of behavioural testing in place first otherwise I know I’m going to end up breaking something somewhere and not even know it.
Also if anyone has had the privilege of such code bases, tips to dealing with the mess are appreciated.
Oh and no, I can’t rm -rf or start again.😭3 -
Giant, month-and-a-half-long-ticket.
After learning six or so complicated areas of the system and updating them all to work with the new changes, make them all play nicely, etc. I finally got everything working. 95% spec coverage, though no ui tests because I haven't gotten selenium working. whatever, everything's done and works.
Second dev bases her ticket off of mine and continues working. Work elsewhere continues and there's an official release, so we both merge in master. I run tests, everything passes, and go back to working on other tickets.
She finishes her ticket.
We do end-to-end testing, and everything works perfectly. Time for a demo!
She merges in master again, and pushes her branch to two staging servers. (idk why two.)
Demo starts.
We connect to the staging servers, and... none of the UI changes exist; they aren't running the correct code!
So she runs it locally for a demo instead. Two features in my ticket no longer work. She throws me under the bus. She throws me under the bus again by criticising a rake task I scrapped because she wanted to do it. Then again because I didn't update my branch to master and push it before the demo, despite having no reason to. and despite the demo being of her branch.
Then she continues to show off and brag about how she's like the "legend" (senior dev) she envies. QAbuys it.
I'm having an emotion, and it's called anger.8 -
Yes!!! Only took one morning.... (changed the Downloader from WebClient to Selenium to get past the bot check, cant find old rant)
Good test for new PC other than games I guess... I can code and compile my projects.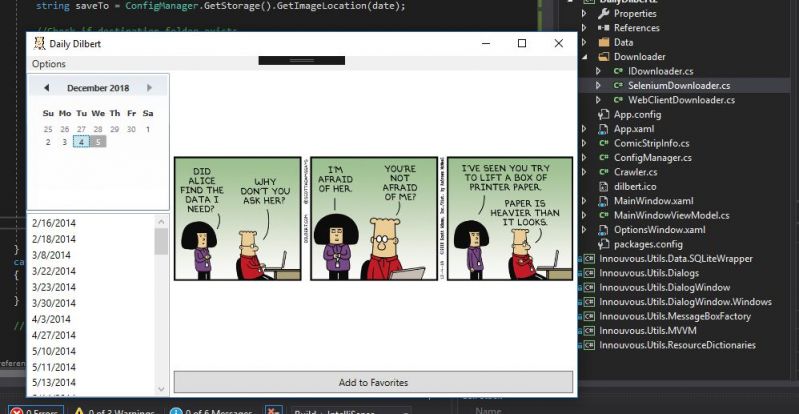 9
9 -
Today I was writing Selenium tests and was struggling to find a good way to test a text editor. We did a weekly code review and my team lead rewrote the test ij 10 lines to generically handle all cases.
Hopefully I'll be a good dev someday. 😔4 -
Corporate pushed a change to our PC's which similataneously installed chrome and pushed their security policies on us. Extensions are no longer available. I can't sign in with my chrome account anymore. I can't automate ui testing with selenium. I can't control any chrome settings, they're controlled by group policies now.
I guess it's time to switch to Firefox. At least until they block that. At least the UI testing still is functional on that...7 -
So I am finally plunging into continuous integration. If I make one more deploy script mistake, I've lost enough time to merit having learned a better solution than bash scripting calling git and rhc and py files I wrote. I have failing tests that are failing because they weren't updated after the million and a half urgent changes in the past 2 months, so it's time to act like I am a TDD fanatic and write the tests correctly. So much work. All from me listening to the constant req changes, listening to the urgency, letting non-devs get under my skin if you will. I'm optimistic in all the wrong places - I think I can write that by end of day let's try it. I'm lazy in the wrong places - I think that I can write that test later, because all I changed was XYZ (which took all night but I said I'd get it as close as possible didn't I?). And I think these handful of bash scripts are good enough to make sure I run tests? But remember, I didn't write the tests or I didn't go back and update them. Or the tests that fail, I'm too lazy. And so much of the tests, I would need to use, idk selenium for, and damnit if I really don't want to dig for element IDs to wait for every time I need an AJAX call.
Okay wow, I really did rant here. And discredited myself a bit lol I need to ignore the wrong lazy and embrace the right lazy. Protect myself from myself and from contributors. It really is, up to me now, to rescue myself from my bad habits. Bad habits perpetuated by clients urgency every day, to change things, that should have been finalized in November if we wanted a stable flipping system in January. It feels like the blind (client) leading the blind (me, when I do dumb shit like rush features out the door half tested).
Anyway all this came out, because I have been reading about continuous integration and stumbled upon this quote. And thought someone might laugh at the anachronism like I did 2
2 -
University wants a final year major project which should give an output as a research paper published in some conference or journal. All seems great. Department rejected all web app related projects because it's too generic.. Still makes sense..
And then suddenly, department asks where are customer requirements, where is ER diagram, where are Selenium tests??????
And they still expect a research paper to be published....
Why do they don't understand the difference between software development and research works.. !!!!!!1 -
Be me
Need to fetch data from a website for project I'm working on
Look for an API with no luck
Spend 2 weeks developing a ridiculously overengineered and slow webscraping program with Selenium
Find an API
Fuck this4 -
So my time saver automation can not be used because automation is not reliable.
Yeah sure make me extract data manually from 800 urls by hand and see if there is no human error.
Fuck my life.5 -
Fuck the managers !! Fucking Fuck Fuck !!!
I am in manual testing for 3 years. Wanted to move in to automation since 2016 January !
They kept delaying.
While waiting I kept autating stuffs and making utilities to use for everyone.
Recently automated a 5 yr old manual process.
Made an utility that can perform a 5 hours manual activity in 5 mins.
Our automation team had a vacancy.
The managers were asked to nominate names who could fill the spot from the current manual team.
They didn't suggested my name.
I am not bragging but I am the only person in the team who nows Selenium , UFT , Java , Python even though being in the manual testers.
The team is going to hire someone from the outside.
I just got to know it all this today.
These bastards should die in hell !!!!
I hate these bastards !!!!6 -
So I got this today. Running my Selenium tests in Chrome, suddenly frozen, closed visually, yet it was marked as open, with this title.
 1
1 -
Tech head fires a mail few days company is planning a hackathon. Overnight at office, with food, music and home drop offs in morning. We devs feel excited we will get time to work on our personal projects and complete them.
Yesterday, tech head fires a mail about the topics. Guess what? The topics are projects which company needs to scale up... Image recognition and text extraction. Selenium. Esign.
Now I am searching for an excuse to skip the hackathon...4 -
Dilbert no longer lets me leech their comics from their site... It was a good... 10 years?
Seems I need to rebuild my Downloader... using Selenium.
Now...where is that project where i used Selenium...1 -
Had some fun running automated UI tests today.
Background: My project is a cloud based tool for running automated tests against a 3rd party SaaS product, so when you start a test run, it opens a Firefox window and runs some selenium automation against the 3rd party product.
Our UI tests also open a Firefox window to log into our local env and run some selenium.
Today I tried to run 4 of our UI tests in parallel.
So each test case creates a Firefox instance, and each of those starts a test run which creates another Firefox instance, sometimes 2, depending on the process being tested.
In short, at one point I had 11 different Firefox windows open, all running selenium automation.
My laptop sounded like it was trying to take off... -
Me: This element is ID located (and visible) in your page, so it must contain it.
Selenium: I've never seen that element!9 -
I’ve spent 2 weeks trying to simply automate logging into my damn school’s blackboard but this ducking popup won’t freaking let me access it. I’ve tried selenium. I’ve used beautifulsoup and requests. I’ve even tried a tool called mechanize with python
But I’ve now realized I simply have no damn idea what I’m doing. I’ve read and tried way too many stack overflow articles and I’m just sick of this damn popup
If I can’t figure it out by the end of the upcoming thanksgiving break I’m dropping this damn project until I learn enough to utilize the blackboard API’s. I’m a little sure those will help 16
16 -
Product Management thought of automating an entire legacy product so they funded undisclosed amount to program management who in turn hired >20 contract devs managed by architects and dev managers with zero functional or technical knowledge of product and who in turn went ahead automating the product in selenium, end result of which was an useless automation framework with lot of browser specific dependencies and whuch could run only on one setup environment and migrating test cases to another environment and running is almost impossible and tyrannical to configure. The automation test cases are highly disorganized with all generic setup, DB configurations and business case test data mixed up in same config files and which need to be rewriten every time ported from one environment to other.To add misery to my woes as a dev working in that product I was told to utilize that framework and enhance the quality of my code by writing inline automation Cases for the same. I am left speechless thoughtless and emotionless after that decision.2
-
Fuck LinkedIn
Fuck their closed API
Microsoft always steals your PRIVATE info, but is scared of us using their PUBLIC info
Fucking morons
I can just use selenium and still have all the info I need
Then why the fuck would you close API to approved only
Can't you just track the traffic????7 -
Selenium++
Woke up at 6am today and couldn't go back to sleep...
So I my Watcher app to support Selenium and provide it to all the extensions (plugins) via the common Interface.
Now I don't need to check the Anime site manually when they release movies or blurays...
And have 1 hr to eat breakfast and get some coffee as I have a release at 9... And now I'm sleepy... -
Thinking about making a bot that uses selenium , and automatically finds proxies/ uses vpn's to access a particular companies homepage and then moves the mouse in a penis shape. They use hotjar and I want to do this as a fun side project and as a subtle fuck you to them.3
-
Company started automated testing recently, and the devs need to review the test scripts.
The tester assigned to my component writes script to trigger button click and nothing else to verify the result.
I couldn't even. I just left work for the day. -
Automated functional testing using selenium and javascript bindings
aka
FUCK FUCK FUCK Driven Development2 -
Made my first contribution to the Python package index. Contributing to open source has always been fun. DevRants, please check my module that I have contributed. Here is the link to PyPi - https://pypi.org/project/... and GitHub - https://github.com/browserium/...
Please post your feedback and comments so that I can improve my module and have a workaround across all the issues. 1
1 -
Well, today I felt like the witch from the sleeping hollow movie.
I was working on a code that logins to a page and download files to a folder, according to the user.
Well, I tried to use the webservices from the page (like it should be) but the links were broken, and I lost a entire working day on trying the API 😮
The second day I tried with Selenium. Everything was going ok, but I wanted to run it without opening the browser and I found a “Headless Chrome”. At the end of the day, I found several blogs saying that Headless Chrome can’t download files 😱 second working day lost
Today I read about “PhantomJS”. I tried the code in C# with OpenQA.Selenium.PhantomJS BUUUUUUT it was missing 😡 I also tried with Python, but I had the same problem.
Finally, I found a blog with a solution for C# with Headless Chrome 😄 4
4 -
Good evening programmers, IT's, devranters and memeians.
I would like to use a little bit of your collective conciousness - the hive mind if you will.
I've been working on my automation system for quite a while and I've received some exposure from non-programmers - which resulted in more questions than suggestions.
I would like to ask you guys to give me some suggestions as to what I could add to my system.. that is, if you have time..
The program in short (if you don't want to read the readme file) is an automation system scriptable in pure Lua.
It utilizes Selenium for web automations, NAudio for audio operations and Moonsharp as an interpreter.
While my tester friends say that they use it for the actual testing, I myself found it very useful in writting bots (for browser games for example).
Here's the github link: https://bit.ly/2GDu92g
Thanks a ton!
PS. Here's an unrelated image to draw your attention. 6
6 -
Currently working on a Selenium script to do my timesheet for me. It's been 30 minutes and it still doesn't work because I'm having trouble selecting the input fields correctly (the ID's are dynamic and keep changing!)
It takes me 30 seconds to do it manually.3 -
Considering applying to a regular administrative job, where I can use just 1% of my dev skills in BAT files, Excel macros, browser automation with Selenium, and people will be like "oh man, you are like a hacker!!!"1
-
It works. My code fucking works. It shouldn't. I got tons of errors, I changed to some obscure shit, expecting it to fail, but it fucking works. I should be happy, but I'm mad for not understanding how.3
-
Whoever thought that using some crappy niche framework for selenium web driver based on node.js instead of using Python or Java bindings like every other reasonable person would do should be beaten to death with old keyboards.1
-
Does anyone know selenium?
Is it recommendable and trustful?
I want to create some java-app that login into different Websites with my accounts and collect data.5 -
I’m not a web programmer; I’m an application and SQL developer. So when I’m tasked with scrapping a web site for an ETL feed, I thought it would just be a ton of substring and Post/Get calls.
Nope! There is this garbage called JBOSS.A4J where the page isn’t a page but a bunch of files that are merged together and then it isn’t “real” but like a bunch of Photoshop layers that “look” like a page. JavaScript functions based on key press and things like Select/Option that looks like an element but Selenium/PhantomJS (C#) can’t find it. Or my Google-Fu isn’t working. -
Now that my math posts have failed to garner the anger they formerly did, we here at Wisecrack Studios, like all teams of people completely out of ideas, have come up with a brilliant never-before-tried concept to bring fresh shitposts to your pocket-telescreen this fine year of 2020.
We present to you the DevRant shitposter census!
Yes we pride ourselves in our quality bait and bullshit here at WS. Founded in [previous year a long long time ago], we focus on craftmanship, tradition, and doing it right. Our bait is loved the world over for "it's fresh flavor", "so good, it's like you're abusing heroin right along with the company employees!'
And now, you too get to participate and choose your very own bullshit!
You could say we may have invented a totally new word just to describe it: crowdsourcing!
Isn't it just *brilliant*.
Here is Wisecrack's "Private Select" census, of only the most choice *premium* finely-aged shitpost ideas for this [current year].
Please, please, one vote per customer!
* Moar javascript shitposts (no we won't be doing any more, even WE are tired of js rants).
* Overly pixelated memes (obviously not) blatantly ripped and automatically uploaded via shitty selenium scripts
* Real life hijinxs, trolling shitty companies hiring processes for fun at their expense!
* DevRantCon now with 100% more orgies. Reserve your kickstarter ticket today.
* Disappointing vaporware announcements that take ten minutes to read and build your excitement up only to crush it before your very eyes like a child's first lego build in the hands of an angry nd merciless andre the giant disappointed by the craftmanship of a five year old.
* A livestream of a monkey on an actual typewriter, with a btc betting pool each time an actual word is typed, along with a $5 "shock the monkey" button to spice things up a bit
(our lawyers are informing us this may or may not be illegal in some or all nations. We'll get back to you when sealand responds with our request about their laws on unnecessary animal cruelty. )
* Video conference with devrants creators where we all play "I've never" that doesn't end until at least one person passes out black drunk.
* Weekly comedy write ups with jokes (not obviously) blatantly stolen from cards against humanity
* HipsterRants: why your favorite [thing - game, music, movie, book] sucks, and why I hate you for liking it.
* Did we mention javascript rants?
* Cool new projects by devranters and our merciless breakdown of why each one is pure, unadulterated shit, everything that was done wrong, and why you should personally be ashamed for using it.
* SadRants: cancer, meth abuse, homelessness, how we'll all die at the end, and how the sun will one day turn into a giant ball of fire that will consume the earth and leave no trace that anyone ever existed, and nothing we do will ultimately matter.
* HappyRants: ( ͡° ͜ʖ ͡°) oh yeah, you feeling it now mr krabs?
* Technical breakdowns that are completely wrong, utterly incompetent, intentionally misleading, and wildly upvoted by people who are unfamiliar.
Vote for your favorite topic/idea today! or even submit your own for our 'consideration'!
Clickbait, now in technicolor!8 -
me: I need to install Firefox for automates test
ops: no
me: need it to run tests PO wants tests
ops: you can't as it is a desktop app
me: I need it because our selenium tests depends on it
ops: Firefox needs 200 other packages can't install
me: can I use Docker? and docker'ise Firefox
ops: ... some silence...
me: please
ops: it will complicate things
me: ಠ_ಠ2 -
My ideal dev job, would be a job I can show compassion towards. A team I can be proud of and learn from. And a vibrant workspace with likeminded individuals who just want to improve themselves even if they feel their at their pinnacle.
My current office tries to make use of new technologies, we've embedded docker, vagrant, a few ci systems on an in need basis per team, and a lot of other tools.
My only real qualms are they feel indifferent towards new languages and eco systems ( Node.js, GoLang, etc ). Our web team is still using angular.js 1.x, bower, refuses to look into webpack or a new framework for our front end which is currently being bogged down by angulars dirty checking.
Our automated quality assurance team is forced to use Python for end to end testing, I've written an extensive package to make their lives easier including an entire JavaScript interface for dispatching events and properly interacting with custom DOMs outside of the scope of the official selenium bindings.
Our RESTful services are all using flask and Python, which become increasingly slow with our increase in services. I've pushed for the use of Node or GoLang with a GraphQL interface but I'm shot down consistently by our principle engineers who believe everything and anything must be written in Python.
I could go on, but tldr; I'm 21 and I have a ton of aspirations for web development. I'd like to believe I'm well rounded for my age, especially without any formal education. I'd love to be surrounded by individuals who want the same, to learn and architect the greatest platforms and services possible.1 -
Junior Software Developer Job( $37k-$42k USD)
-1 year experience
- J2EE, Javascript, HTML, XML, SQL
- object oriented design and implementation
- management of relational and non-relational such as Oracle, PostGreSQL and Cassandra
- Lifecycle and Agile methods
- Familiarity with the Eclipse development environment and with tools such as Hibernate, JMS, ,TomCat/Gemini/Jetty, OSGi.
• UNIX skills, including Bash or other scripting language
• Experience installing and configuring software packages
• ActiveMQ troubleshooting/knowledge
• Experience in scientific data processing and analytical science in general
• Automated testing tools and procedures, including JUnit testing, Selenium, etc.
• Experience in interfacing with scientific instrumentation, potentially over IP networks
• Familiarity with modern web development, user interface and other ever-evolving front-end
technologies, such as React, TypeScript, Material, Jest, etc.
I am betting they don't get many people applying.8 -
VMWare be like: "hey lemme just benchmark your primary host disk there... wait a sec..."
*selenium tests continue with 1 keystroke per seconds*
*slow clap*
i'm gonna cry in the corner of my room now. 2
2 -
Working on a selenium test suite for a large web app. Nightly tests currently take 3h to finish. At what point do nightly tests become weekly tests??5
-
Recently saw a rant here asking how bad it would if SO went out for a while, with most replies saying it would be good, and asking people to read documentation instead.
Well i tried to prepare myself for that and tried to read the selenium documentation for getting the html of a page. After 30 mins couldnt find it. A google search returned a SO answer which i didnt have to click on coz it had it in the first line.. How difficult is it to provide documentation functionwise/attributewise instead of long tutorials when i click on Documentation.? C++ libs and major python libs do it so good.6 -
Today I wanted to automate checking the status of running jobs. There's a UI but navigating it is tedious and I sort of wanted a Dashboard.
So I started writing a Selenium app to automate it. I'm writing the code, inspecting all the inputs. And I'm looking "woah, all of them have nice ids... This should be easy"
Login is ok, but then run into IFrames (can't find the input elements on the page itself).
Fine Google... find the answer and so try again. But wait... It doesn't work???
There's apparently 9 of them on the page. And there's no easy way to identify the correct one...
Spent an hr trying different ways of locating the right one... eventually settling on very complex XPath...
All in all though it took 2 hours... And still not done... -
Little story.
Manager give me task, Send mail through mail chimp to many groups and schedulled them differntly.
Day1 : it litterly waste my half hour.
Night 1 :create script using Selenium (utilize my 2 hours because It was new for me.)
Day 2 : I am devrant. (script is doing my task)
Manager is also happy that I am doing extra work. -
All the crypto bots and hire a hacker adverts make no sense. After all, they still need to either go through the API or make a selenium script. Will still take them 1 to 2 hours at least to build it. For what?
To advertise to a dying platform that has a dwindling community, which is on top of it well-versed in programming and technically affine, so that the probability of profiting of it is tiny...
My conjecture: A devrant member is pulling a long running prank.
I bet it's someone like theRealJase. Or someone like that.4 -
Got into an argument the other day over the definition of scripting languages.
He said python isn’t because it can be compiled while I said it can be both since you can you can use without compiling. Same could be said for Java when using with Selenium for automation.
Thoughts?5 -
Logging into my schools blackboard using selenium is only redirected on school WiFi
Outside school WiFi I go directly to the site. But on the school WiFi it pauses on a redirect page with a link that loops back to the redirect when grabbed by selenium And selenium fails
Fucking hell2 -
Got a question guys!
I want to capture screenshots from a live video stream being broadcast over HTTPS, such as the one on this link:
https://open.ivideon.com/embed/v2/...=
I can do it locally using the chrome webdriver in selenium, but cannot reproduce the same in a server I'm accessing remotely. I tried using headless browsers like phantomJS, but apparently it doesn't support video players -_-
I'm confused because I don't even know what to search for anymore, I've been stuck with this one thing for the last 17 hours. Any help would be greatly appreciated!5 -
Nothing like using a ThreadPoolExecutor to thread out my shitty selenium task, so it will go just a bit faster.
-
Received my first recruitment message on LinkedIn today. Generic as fuck "hey your profile looks nice, we have dis thing for you, come take a looksie".
Went ahead and read the whole thing, started laughing while reading requirements:
- own a degree in CS or related field: re-starting college next week
- extensive experience with automation processes: uuuh... I can write bash scripts and gulp tasks, how's that?
- extensive experience with Java, Angular, Selenium and Protractor: sure. Spent two weeks tinkering with those tools. Pretty much an expert already
- two years of experience: not even 6 months into my first job
And some other nonsense
Job would be in a very nice city, extended family lives nearby, actually a nice position. Too bad I am not looking for a job and my classes start on Monday 😂
But hey, at least people are looking at my profile! Yay!3 -
Data wrangling is messy
I'm doing the vegetation maps for the game today, maybe rivers if it all goes smoothly.
I could probably do it by hand, but theres something like 60-70 ecoregions to chart,
each with their own species, both fauna and flora. And each has an elevation range its
found at in real life, so I want to use the heightmap to dictate that. Who has time for that? It's a lot of manual work.
And the night prior I'm thinking "oh this will be easy."
yeah, no.
(Also why does Devrant have to mangle my line breaks? -_-)
Laid out the requirements, how I could go about it, and the more I look the more involved
it gets.
So what I think I'll do is automate it. I already automated some of the map extraction, so
I don't see why I shouldn't just go the distance.
Also it means, later on, when I have access to better, higher resolution geographic data, updating it will be a smoother process. And even though I'm only interested in flora at the moment, theres no reason I can't reuse the same system to extract fauna information.
Of course in-game design there are some things you'll want to fudge. When the players are exploring outside the rockies in a mountainous area, maybe I still want to spawn the occasional mountain lion as a mid-tier enemy, even though our survivor might be outside the cats natural habitat. This could even be the prelude to a task you have to do, go take care of a dangerous
creature outside its normal hunting range. And who knows why it is there? Wild fire? Hunted by something *more* dangerous? Poaching? Maybe a nuke plant exploded and drove all the wildlife from an adjoining region?
who knows.
Having the extraction mostly automated goes a long way to updating those lists down the road.
But for now, flora.
For deciding plants and other features of the terrain what I can do is:
* rewrite pixeltile to take file names as input,
* along with a series of colors as a key (which are put into a SET to check each pixel against)
* input each region, one at a time, as the key, and the heightmap as the source image
* output only the region in the heightmap that corresponds to the ecoregion in the key.
* write a function to extract the palette from the outputted heightmap. (is this really needed?)
* arrange colors on the bottom or side of the image by hand, along with (in text) the elevation in feet for reference.
For automating this entire process I can go one step further:
* Do this entire process with the key colors I already snagged by hand, outputting region IDs as the file names.
* setup selenium
* selenium opens a link related to each elevation-map of a specific biome, and saves the text links
(so I dont have to hand-open them)
* I'll save the species and text by hand (assuming elevation data isn't listed)
* once I have a list of species and other details, to save them to csv, or json, or another format
* I save the list of species as csv or json or another format.
* then selenium opens this list, opens wikipedia for each, one at a time, and searches the text for elevation
* selenium saves out the species name (or an "unknown") for the species, and elevation, to a text file, along with the biome ID, and maybe the elevation code (from the heightmap) as a number or a color (probably a number, simplifies changing the heightmap later on)
Having done all this, I can start to assign species types, specific world tiles. The outputs for each region act as reference.
The only problem with the existing biome map (you can see it below, its ugly) is that it has a lot of "inbetween" colors. Theres a few things I can do here. I can treat those as a "mixing" between regions, dictating the chance of one biome's plants or the other's spawning. This seems a little complicated and dependent on a scraped together standard rather than actual data. So I'm thinking instead what I'll do is I'll implement biome transitions in code, which makes more sense, and decouples it from relying on the underlaying data. also prevents species and terrain from generating in say, towns on the borders of region, where certain plants or terrain features would be unnatural. Part of what makes an ecoregion unique is that geography has lead to relative isolation and evolutionary development of each region (usually thanks to mountains, rivers, and large impassible expanses like deserts).
Maybe I'll stuff it all into a giant bson file or maybe sqlite. Don't know yet.
As an entry level programmer I may not know what I'm doing, and I may be supposed to be looking for a job, but that won't stop me from procrastinating.
Data wrangling is fun. 1
1 -
LinkedIn: Exploiting social psychology for fun and profit.
I was reading an excellent post by Kage about linkedin (you can find it and more here - https://devrant.com/users/Kage) a little while ago and it occurred to me the unique historic moment we are in. Never before have we been so connected in history. Never before have we had so great an opportunity to communicate with strangers (perhaps except for sketchy candy vans on college campuses, and tie dye wearing guys distributing slips of paper at concerts). And yet today, we are more atomized than ever before. In this unprecedented era of free information, and free communication, how can we make the most of our opportunities?
The great thing about linkedin is all the fawning morons who self select for it. They're on it. They're active, so you know they're either desperate attention hungry cock goblins,
self aggrandizing dicknosed cretins, desperate yeasty little strumpets, or a managerie of other forgetable fucking pawns,
willingly posting up their entire lives to be harvested and sold so someone can make 15 cents on a 2% higher ad conversion ratio for fucking cilas or beetus meds.
So what is a psychopathic autist asshole to do?
Ruthlessly exploit them by feeding them upvotes, hows-it-going-guys, and other little jolts of virtualized feel-good-chemical bullshit.
Remember the quickest way to network is for people to like you. And the quickest way to make people like you is either agree with them on everything, or be absolutely upfront with everything you disagree on.
Well, they'll love you, or hate you. But at least you'll be living rent free in their head. And that means they'll remember you when you call looking to network or get a referal.
Of course, in principle, this extends to any social media site. Why not facebook? Why not fucking *myspace*? Why not write a script in selenium to browse twitter all day, liking pictures of lattes and dogs posted by the lonely and social-approval-hungry devs working at places like google, twitter, faceborg, etc?
You could even extend this to non-job prospects. Want a quick fuck? Why, just script a swipe-right hack on tinder, or attach a big motherfucking robot arm to your phone, tapping and swiping for hours. Want to make a buck? Want not harvest data on ebay or amazon all god damn day and then run arbitration for 'wanted' classifieds on craiglist?
Why not automate all the things?
The world is at your fingertips, and you the power to automate it, while all the wall lickers and finger painters live oblivious to the opportunity they are surrounded with and blessed with daily.
Surely now that you know, it is your obligation, nay, your DUTY to show the way.
Now you are learned. Now you are prepared. Go forth and stroke the egos of disposable morons to bilk for future social favors while automating the world in ways never intended.3 -
Just discovered Katalon and Selenium. If I knew about it earlier I could have saved days back in 2017 if not weeks. <3 this is a good start to 2018!1
-
Something that would make things so much easier would be a Chrome plug-in that spit out Selenium code while in the browser.2
-
Right now, everything. I started at a Consulting firm because I expected many new problems to tackle, solutions to develop and generally to always have a fire burning underneath my ass but instead I always develop the same standard bullshit.
I miss the days in my old job when there was just a problem and the task to solve it. When I stared down giant amounts of data, just KNOWING that somewhere in that mess is some structure I could exploit and that short moment of inspiration when I finally pinpointed it. The rush of endorphins when the solution became clear and everything fell into place to form a beautiful pattern amidst the chaos test data, git commits and numpy arrays.
Now its just "Yeah, would you just write another selenium testsuite that throws out fail or pass and wastes all the information because the only reason I'm a testmanager is because I'm too incompetent to do anything else and not my passion for the field".
The constant, mind numbing repetition of always the same patterns where the occasional dynamic element that becomes stale is the highlight of my work week... I would have never thought that making good money with easy work would ever get me as close to depression as it did.5 -
Okay guys now real deal.
I am planning to move to Portugal or something like that.
I think I’m gonna need full time remote work, seems like that one is not happening with me now(part time)
Soo I do react, and all kinds of node selenium, bash stuff . But want to improve on redux and go to react native also.
Long story short shoot the work on me :)11 -
I have to download 500 images from bookreads to help a friend out. Thought I'd use this opportunity to learn about web scraping rather than downloading the images which'd be a plain and long waste of time. I've got a list of books and author names, the process I wanna automate is putting the book name and author name into the search bar, clicking it, and downloading the first image the appears on the new webpage. I'm planning to use selenium, BeautifulSoup and requests for this project. Is that the right way to go?9
-
My selenium script cronjob is not running on the VPS.
I am not sure what's wrong with it
Even the crond service status just shows
the session was opened for the user root
shows the command
the session closed for user root
I tried the tons of solution available but nothing worked
I am using Ubuntu 16.04 with LXDE13 -
Iterating over 50 rows of data with selenium takes 8-10 seconds according to System.currentTimeMillis() But opening the site itself takes 65-70 seconds by itself. Why is this site so damn slow even opening it normally it’s slow as fuck and headless mode doesn’t help much if at all
Doesn’t matter much since I can just sit and let it do it’s 4000 iterations but I really ducking hate that 60 seconds just to load the damn page3 -
You have to modify an old crap software in php.
2 hours to change the codes
2 hours to test the changes with selenium test 3
3 -
Was working with my internship boss to implement an CI but the documentation were cryptic and no fucking support on the forum whatsoever.
So I started working on creating my own CI dubbed Blackjack CI and he posts this on the forum
https://discuss.circleci.com/t/...
But how fucking hard can it be to have fucking propped documation.2 -
tldr; selenium-java (my newest learned tool) vs beautifulsoup4 (my most experience with) or scrapy(average experience, mediocre ability with). Which should I use if allowed to use any for web scrapeing assignment
We were explicitly told we can use anything we know from class or self study (slight bonus for self study implementations) for the group project, but would it be OK/fair for me to use beautifulsoup4 or scrapy to pull the data from the assigned site rather than the selenium-java we were taught in class
If I did use bs4 or scrapy my group wouldn't be able to edit if needed but the data collection is only a small (if immensely important) part of the assignment and I'd have the bs4 script done a lot quicker than with selenium which I have learned more recently (for class) and have less experience with9 -
I'm currently working as a technical product manager. We lost a QE a while ago and I stepped into the ticket testing, happy path, and some exploratory testing for our tickets.
I had a friend from another company tell me to apply for a QE position. It's a combo product and QE position and I'm about 80% qualified.
Can anyone give me any places I can quickly and efficiently learn about setting up automated testing? I have some background in css, js, and html but basically no c# or other languages. -
Sticking to the man... or facebook sorta.
Using Selenium so I can get all the group feeds in Chronological order rather than Recent Activity... Why the fuck is there still no way to set the default.
Now that I think about the better way is to create a Service app that checks for updates and loads them into a DB and the Client app that just reads from DB. So Updates come from Selenium/Chrome in the backgeround thread while UI doesnt need to lag/wait...
fck... all those Async code for nothing.... (yea i m thinking while i mwriting this... an epihpany moment...)
One thing and the original question is, is there an existing Facebook scraper. OpenGraph doesnt work for Group posts or public events which is what i want the feeds for....
The problem though the AJAX calls for more posts when you scroll down. I am not sure in Selenium how to make the Driver wait for new content in the DOM... rather than just sleeping the Thread for X seconds and checking after.4 -
How do you ask questions when you are at a college internship where you have been stuck with a problem for 5 days. I'm feel scared to ask many questions to my mentor, because I think he will laugh with me. I'm writing a webscaper in Selenium C# and never only saw some basics of c# before my internship. The program is for 90 % finished, just a final little thing I can't get to work. How do I approach him in a good way?5
-
Trying to test this React app my team is working on with selenium. There were no classes or ids I could've used to find elements.
I ended up looking for elements by attributes and contained text using XPath. -
Oh I just gotta love how low quality selenium is. Gotta love the fact that sometimes you need to commit your code 5 times before selenium tests do not fail completely randomly and the whole commit is rollbacked. Like I don't fucking have other shit to do other than wait for these retarded tests to finish just to expect that with 90% probability they are going to fail because selenium is a huge pile of poop when it comes to UI tests. Also testers do not seem to give a single fuck since they just keep writing more of those instead of making old test more stable, fucking awesome.
-
I am starting a testing project at work and we have nothing in place.
Should I use a tool like browserstack and try to hold my selenium tests there or bite the bullet and use something like spec flow to write the selenium tests by hand? The advantage being full control, easy way to integrate with CI and easier to integrate to existing workflows (no need for visual studio and a browser open to work on in parallel).
If I do that I will also need some way to do cross browser testing which I guess will require me to export the tests somehow to a cross browser treating service like browserstack. -
My DNS provider does not have an API. They do have one... That is wrong... But on the description page, they say we have to open a ticket to be given access. No requirements. Nothing...
And then I am told "they do no longer offer dns for private hosting". I don't even host with them, I only have a domain with them.
But the magical word is no longer. That means they did offer it. In the description of the API it still says "and for everyone who feels comfortable interacting with a REST API." Oh, and they asked anyone who works on it to be so nice and share any SDK's they might have coded up. Would have shared my SDK. Would have... If no Rust SDK was available yet.
So, what the fuck...
The problem with that is that I need a wildcard certificate for my homelab with DNS validation. So, I need to dynamically set a txt record. Now I wonder... Was this done on purpose? They are selling wild card certificates. Letsencrypt are giving them out for free. I bet they deactivated it, so they can sell more...
Anyway. Solution time.
Short term: I make my own API with black jack and hookers... And selenium.
Long term: I need to fucking move my domains to a different provider.
But what the fuck... What the fuck?6 -
Id say my least favourite part of my workflow right now is the selenium automation I have to run locally for dev testing.
The stuff I have to run for my current story takes about an hour to reach the point I am interested in. Then if it throws an exception or doesnt work properly, I have to make my fix and run it all again.
And theres not much else I can do while its running either, if I make any other code changes Gradle will recompile everything. So I basically have to sit and watch it, or go watch a clean coders video in another window while it runs. -
Any automation engineers that use selenium + Python have any good suggestions on testing, resources or advice?2
-
Have some questions to testing.
Right now we are at the production end for first version. So far it was said to use Selenium IDE for Browser side testing, which was barely possible for the size of the website...
Is there other software or are there concepts I can read and inform myself to get into that point to teach myself properly?
The project is a business Website with Work flow system. Php backend and Database with a few procedures and zend framework for browser side.7 -
use 'Drillan767/last/rants';
PhantomJS is love
PhantomJS is life
I don't care if it's slow
Would you be my wife -
How can I make a bot which makes a single commit everyday at a specific time for a particular repository?
The commit can be anything like insertion in readme or creating a new file.
I tried to accomplish this using python selenium I deployed it on heroku, the problem I am facing is github doesn't allows to crawl on it so it sends a verification code to me on mail and all my further selenium actions fail due it this.☹️26 -
I want to start freelancing projects.! but how to start freelancing, I have good knowledge of AngularJs, Java, Selenium, Android, HTML, CSS.! too.
where to start./ any sugg..5 -
Is there a HTML scraper library for JS/NPM like Selenium or HtmlAgilityPack where I can find elements by ID, XPath, element type and their attached attributes?8
-
need help with android automation. no where on the enire internet is there a solution for taping the "Done" button on the soft keyboard
-
Who here writes their own selenium tests??Is it worth writing them yourself or better to use browserstack?
-
Finish my game. It will probably be shit because the concept just wasn't that good, but I will be able to extract 2-3 useful node modules once it's finished and tested properly. A VoIP system with overlapping rooms and an efficient co-browsing system without a serverside browser like Selenium are certain. Perhaps the plugin structure as well, but that's more architecture than code.1
-
Tried running our selenium test suite on Firefox during the nightly build. Came in this morning with no nighly build. Turns out the tear downs weren't killing the firefox drivers and they used up all the memory on the build server. 😐
-
So I developed this bot which will make one commit everyday for. But duh! Github's security service sends me a verification code Everytime my script tries to login and the further selenium actions fails. 😂😂😂
In short : all my pain went in bin
If anyone knows how can I overcome this issue please let me know9 -
I need a help salesforce guys,
I am trying to automate Salesforce sandbox creation, then copying the client secret and key from an app and then use those credentials for some application.
Sandbox creation and deletion is done, but I am not able to get how should I fetch client credentials. I searched internet, and I only find gui method : login, select app, select view, get credentials.
At last I wrote a shitty selenium script but I don't have faith in this approach.
If anybody can give me insight, It would be great help.5 -
What stack are you using to test your angular app and why?
We’re using Karma + Jasmine for writing unit tests, because it’s the default, and run them on GitLab CI in a Docker container. For UI testing we don’t use the default Protractor but Selenium, because we haven’t found a way to run Protractor tests with a dedicated webserver.1 -
Hello guys, just want to ask if any one has done a speedtest result twitter auto poster? Like a cron job that executes a speedtest... test the post the result to twitter as to show our telco how shitty their service is.
I am thinking of selenium script but I wanted it to run on raspberry pi. Do you think it's doable?1 -
For the last two months, I've been taking online courses in using Selenium (website testing tool) under C# and Java. The courses have you set-up the testing framework in something called Page Object Model. What the hell?? I've been doing this since 2010 under 3 different tools. You mean the industry adopted it as a standard and gave it a name and I never knew this?! ARGH!! Time to update the resume again and say how long I've been using this type of testing framework (since before it had an official industry name).
It is nice to see work I have been doing for years has become an industry standard. Wish I had known that when I was putting my resume together back in March so I could have included that. Damn it, I wonder how many jobs I missed out on by not having that already in my resume.






























































































Top Tags
Weekly Rant
View