
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Let's clarify:
* Github is not Git
* Android is not Java
* Unit test is not TDD
* Java is not OOP
* Docker is not Devops
* Jenkins is not CI
* Agile is not institutionalised total chaos
* Developer is not Printer Support52 -
Your resume:
Git
SSL
Vue
Angular
React
Node
Spring boot
MySQL
MongoDb
HTML
CSS
Java
Javascript
Bootstrap
Cassandra
Hive
Hadoop
Block chain
GraphQL
Kubernetics
Jenkins
Azure
GCP
Interviewer:
Sorry, we need someone who knows AWS8 -
My first complete pipeline with Jenkins:
- push on gitlab
- build with maven
- test with junit
- deploy with Ansible
- integration test with Selenium
I love devops!6 -
The company i work for has a jenkins server (for people that don't know jenkins, it's an automated build service that gets the latest git updates, pulls them and then builds, tests and deploys it)
Because it builds the software, people were scared to update it so we were running version 1.x for a long time, even when an exploit was found... Ooh boy did they learn from that...
The jenkins server had a hidden crypto miner running for about 5 days...
I don't know why we don't have detectors for that stuff... (like cpu load being high for 15 minutes)
I even tried to strengthen our security... You know basic stuff LIKE NOT SAVING PASSWORDS TO A GOOGLE SPREADSHEET! 😠
But they shoved it asside because they didn't have time... I tried multiple times but in the end i just gave up...13 -
Just scored my personal red flag bingo in new project:
- engineers who work there for 20+ years
- their own in house build tool
- "we have Jira so it means we are agile"
- "we have Jenkins so it means we do Ci/cd"
- git adoption is "in progress"14 -
I jump on an existing scala project.
git pull && sbt compile test
Tests are failing.
Me: "Hey team, the tests are failing."
Team member: "That cannot be. They were passing for the the last run."
Me: "Did you run them locally?"
Team member: "No, on Jenkins. It was fine."
I check Jenkins.
Me: "What do you mean it's fine. The last successful deployment was on the end of May."
Team member: "The Pull Request checker always went through successfully."
I check how our Jenkins tasks are configured. It's true that the Pull Request Checker runs successfully yet due to a "minor misconfiguration" (aka "major fuckup") the Pull Request Checker only tests a tiny subset of the entire test suite.
Team members were were fine if their Pull Request got the "Success" notification on bitbucket's pull request page. And reviewers trusted that icon as well.
They never checked the master run of the Jenkins task. Where the tests were also failing for over a month.
I'm also highely confused how they did TDD. You know, writing a test first, making it green. (I hope they were just one specific test at a time assuming the others were green. The cynic in me assumes they outsourced running the tests to the Jenkins.)
Gnarf!
Team member having run the tests locally finally realizes: "The tests are broken. Gonna fix them."
Wow. Please, dear fellow developers: It does not kill you to run the entire test suite locally. Just do it. Treat the external test runners as a safety net. Yet always run the test suite locally first.4 -
Darn it, I was having such a good day. Just sitting over here in sysadmin land watching the Java devs tear their hair out over the Log4j vulnerability, when someone just had to ask me about the Jenkins servers my team maintains.
Jenkins doesn't use Log4j! What a relief!
Jenkins does, however, have third-party plugins, some of which use Log4j. And thus my relief was short-lived and now I'm also tearing out my hair trying to patch this shit.17 -
Me done fixing a bug.
Me commit the fix.
Me resolve issue in JIRA.
Few minutes later, Me receive a notification. QA reopened issue: "Bug is still there".
Me go have look to Jenkins.
Pissed off, Me respond to QA: "Can you just wait for Maven to finish building the goddamn thing before testing it please?"
Every. Fucking. Time8 -
What an absolute fucking disaster of a day. Strap in, folks; it's time for a bumpy ride!
I got a whole hour of work done today. The first hour of my morning because I went to work a bit early. Then people started complaining about Jenkins jobs failing on that one Jenkins server our team has been wanting to decom for two years but management won't let us force people to move to new servers. It's a single server with over four thousand projects, some of which run massive data processing jobs that last DAYS. The server was originally set up by people who have since quit, of course, and left it behind for my team to adopt with zero documentation.
Anyway, the 500GB disk is 100% full. The memory (all 64GB of it) is fully consumed by stuck jobs. We can't track down large old files to delete because du chokes on the workspace folder with thousands of subfolders with no Ram to spare. We decide to basically take a hacksaw to it, deleting the workspace for every job not currently in progress. This of course fucked up some really poorly-designed pipelines that relied on workspaces persisting between jobs, so we had to deal with complaints about that as well.
So we get the Jenkins server up and running again just in time for AWS to have a major incident affecting EC2 instance provisioning in our primary region. People keep bugging me to fix it, I keep telling them that it's Amazon's problem to solve, they wait a few minutes and ask me to fix it again. Emails flying back and forth until that was done.
Lunch time already. But the fun isn't over yet!
I get back to my desk to find out that new hires or people who got new Mac laptops recently can't even install our toolchain, because management has started handing out M1 Macs without telling us and all our tools are compiled solely for x86_64. That took some troubleshooting to even figure out what the problem was because the only error people got from homebrew was that the formula was empty when it clearly wasn't.
After figuring out that problem (but not fully solving it yet), one team starts complaining to us about a Github problem because we manage the github org. Except it's not a github problem and I already knew this because they are a Problem Team that uses some technical authoring software with Git integration but they only have even the barest understanding of what Git actually does. Turns out it's a Git problem. An update for Git was pushed out recently that patches a big bad vulnerability and the way it was patched causes problems because they're using Git wrong (multiple users accessing the same local repo on a samba share). It's a huge vulnerability so my entire conversation with them went sort of like:
"Please don't."
"We have to."
"Fine, here's a workaround, this will allow arbitrary code execution by anyone with physical or virtual access to this computer that you have sitting in an unlocked office somewhere."
"How do I run a Git command I don't use Git."
So that dealt with, I start taking a look at our toolchain, trying to figure out if I can easily just cross-compile it to arm64 for the M1 macbooks or if it will be a more involved fix. And I find all kinds of horrendous shit left behind by the people who wrote the tools that, naturally, they left for us to adopt when they quit over a year ago. I'm talking entire functions in a tool used by hundreds of people that were put in as a joke, poorly documented functions I am still trying to puzzle out, and exactly zero comments in the code and abbreviated function names like "gars", "snh", and "jgajawwawstai".
While I'm looking into that, the person from our team who is responsible for incident communication finally gets the AWS EC2 provisioning issue reported to IT Operations, who sent out an alert to affected users that should have gone out hours earlier.
Meanwhile, according to the health dashboard in AWS, the issue had already been resolved three hours before the communication went out and the ticket remains open at this moment, as far as I know.5 -
Thanks to the jenkins creator for having the "delete project" button in the middle of "build now" and "configure" button.5
-
1. Slack. Pretty good chat app for dev companies, I use it to prevent people standing next to my desk 40 times a day.
2. Unit testing tools, especially when fully automated using a git master branch hook, something like codeship/jenkins, and a deployment service.
3. Jetbrains IDEs. I love Vim, but Jetbrains makes theming, autocompleting & code style checks with mixed templating languages a breeze.
4. Urxvt terminal. It's a bit of work at the start, but so extremely fast and customizable.
5. Cinnamon or i3. Not really dev tools, but both make it easy to organize many windows.
6. A smart production bug logger. I tend to use Bugsnag, Rollbar or Sentry.
7. A good coffee machine. Preferably some high pressure espresso maker which costs more than the CEO's car, using organic fairtrade hipster beans with a picture of a laughing south american farmer. And don't you dare fuck it up with sugar.
8. Some high quality bars of chocolate. Not to consume yourself, but to offer to coworkers while they wait for you to fix a broken deploy. The importance of office politics is not to be underestimated.1 -
TLDR; I am a piece of shit who writes no documentation or no information whatsoever when I am doing something.
Created a custom version of Windows for our company couple of months ago. Before leaving, I am supposed to pass this valuable information to another new developer.
Obviously, since it has been a long time I have worked on that, I have forgotten a lot of core principles. The process is also automated in Jenkins so never really had to touch it again.
Now that I am about to explain the process to the new recruit, I realised that I have written nothing about that process. No documentation, no information. The only thing I have is a bunch of scripts automating everything for me. WHY WHY do I do this to myself :(17 -
Long rant, sorry.
I’m pretty upset, or let’s say: I want to kick asses and chew gum but I’m all out of gum(The duke TM).
Yesterday we had a discussion in the office about salary basically.
Context: The company has about 150 employees and earns a lot of money. I’m the lead dev for about 1.5 years since I joined.
So I talked to our CEO/HR about a raise since I was hired as a normal fullstack dev(title is lead dev now) but have to:
train my junior(PHP), frontend guy(react), our QA(Automation with cypress atm), our junior devop(gitlab, jenkins, docker) and even assist marketing with GTM and adword campaigns.
I’m a jack of all trades basically since I was a freelancer for big brands for a long time.
I’m fine with helping/training, I like it a lot but I still have to watch everything and be fast with my own stuff. If anything goes wrong, people call me.
That will change since I train them all(They will all be independent soon) but still, doing everything for the same pay feels wrong.
Bottom line: CEO told me it’s cool that they can use all my skills but I won’t get a raise.
The worst/strangest was: My coworkers heard about that(as always in an office) and were like: Everybody should get paid equally because we’re all a team. Uhm, ok?
I just contacted the head hunter which got me that job. I guess I’ll just see what the market has to offer.
It should never be about money but this was confusing. People telling me we should all be equal who are on their mobiles 3h a day and feel underpaid. Check yourself, really.
People who think their pure presence is enough.. Germany -.-25 -
Gitlab's CI/CD, Jenkins, TeamCity, Travis, Bamboo,.....
Fuck it, I'm too lazy to learn them all to pick the best choice for my case.
Meet 'pipeline.bash'
Perfect!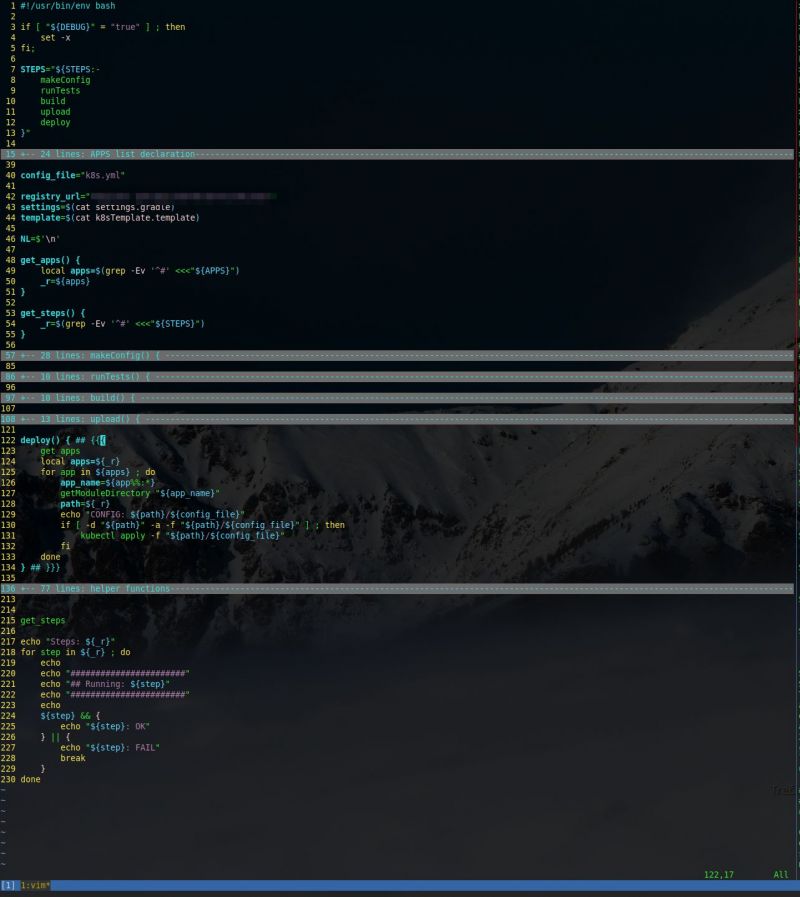 15
15 -
Two weeks ago, our lead presents jenkins to our apprentice.
Apprentice : why some projects have a cloud icon and other a sun ?
Lead : because there were cloud outside when build finished.
Today we still laugh about it. -
Most fun I had as a dev?
I'd say it was when the whole it department decided to have an Easter egg competition xD the DBA's never did find out why one of our apps kept creating dummy users called LEEEEEROY JENKINS
One of my best achievements in development xD -
(Deep breath*)
.
.
.
.
(Exhale*)
.
.
.
.
I’m sitting in the parking lot 1.5 hours early to start my new job today. I’ve been rather nervous about it since I accepted the job offer in early December. I’m going to be working with completely foreign tools and software stacks than what I’m used to. I never said I was pro or experienced at this tech stack, let them know during the interviews repeatedly that I’m just getting started with this kind of work and tech stack (devops role using jenkins and ansible mostly). And my experience and knowledge is limited to theoretical understanding of how these tools work together.
I’m excited to get to learn all kinds of new tech and push myself. But I’m also terribly nervous about how quickly I can pick this all up so I’m not a burden to the team.15 -
Finished my project early today. I assumed it would take another day or two since it's primarily research and I had no idea how to progress, but I caught a break and finished it early. I also finished another surprise ticket! yay! I had the rest of the day to myself!
... had!
But then I noticed I had been working on the wrong branch. Fuck. Moving my work over was tedious, as was the cleanup. I kicked myself for good measure. Also, every time I switch branches, I need to run a bloody slow script that runs all the migrations, data tasks, backfills, etc. for the branch. It takes 12-18 minutes. There's a faster version, but it usually breaks things.
Turns out the branch I was supposed to be working on wasn't up to date with master. So I merged that in, leading to....
merge conflicts. Because of course there are conflicts. To make matters worse, I had (and have) no idea which changes were correct because idfk what those 248 new commits are doing. So I guessed at them, ran the script, and (after more waiting) ran a few related specs. Yet more waiting. Sense a pattern here? Eventually they finished, and all the specs passed. H'ray. So I committed the changes, and told Jenkins to kick off a full spec suite, which takes 45+ minutes.
La de da, I go back to cleaning up the previous ticket, pushing reversion commits, etc. Later, I notice the ticket number, look at the branch number I've been working on.... and. Fuuuck. I realize I had put everything on the wrong freaking branch AGAIN. I'm such an idiot. Cue more cleanup, more reversions, running the bloody script again and again. More wasted time, more kicking. ugh.
All of this took well over three hours. So instead of finishing at a leisurely 5:00 like a normal person, I finally stopped around 9pm. and I won't know the Jenkins spec results until morning.
A nice early day?
I should know better.2 -
Testing hell.
I'm working on a ticket that touches a lot of areas of the codebase, and impacts everything that creates a ... really common kind of object.
This means changes throughout the codebase and lots of failing specs. Ofc sometimes the code needs changing, and sometimes the specs do. it's tedious.
What makes this incredibly challenging is that different specs fail depend on how i run them. If I use Jenkins, i'm currently at 160 failing tests. If I run the same specs from the terminal, Iget 132. If I run them from RubyMine... well, I can't run them all at once because RubyMine sucks, but I'm guessing it's around 90 failures based on spot-checking some of the files.
But seriously, how can I determine what "fixed" even means if the issues arbitrarily pass or fail in different environments? I don't even know how cli and rubymine *can* differ, if I'm being honest.
I asked my boss about this and he said he's never seen the issue in the ten years he's worked there. so now i'm doubly confused.
Update: I used a copy of his db (the same one Jenkins is using), and now rspec reports 137 failures from the terminal, and a similar ~90 (again, a guess) from rubymine based on more spot-checking. I am so confused. The db dump has the same structure, and rspec clears the actual data between tests, so wtf is even going on? Maybe the encoding differs? but the failing specs are mostly testing logic?
none of this makes any sense.
i'm so confused.
It feels like i'm being asked to build a machine when the laws of physics change with locality. I can make it work here just fine, but it misbehaves a little at my neighbor's house, and outright explodes at the testing ground.4 -
Hate when my boss says, "hey you, over there, can please automate this stuff, is a pain in the ass..."
 2
2 -
One of my former coworkers was either completely incompetent or outright sabotaging us on purpose. After he left for a different job, I picked up the project he was working on and oh my God it's a complete shitshow. I deleted hundreds of lines of code so far, and replaced them with maybe 30-40 lines altogether. I'm probably going to delete another 400 lines this week before I get to a point where I can say it's fixed.
He defined over 150 constants, each of which was only referenced in a single location. Sometimes performing operations on those constants (with other constants) to get a result that might as well have been hard-coded anyway since every value contributing to that result was hard-coded. He used troublesome and messy workarounds for language defects that were actually fixed months before this project began. He copied code that I wrote for one such workaround, including the comment which states the workaround won't be necessary after May 2019. He did this in August, three months later.
Two weeks of work just to get the code to a point where it doesn't make my eyes bleed. Probably another week to make it stop showing ten warnings every time it builds successfully, preventing Jenkins from throwing a fit with every build. And then I can actually implement the feature I was supposed to implement last month.5 -
"four million dollars"
TL;DR. Seriously, It's way too long.
That's all the management really cares about, apparently.
It all started when there were heated, war faced discussions with a major client this weekend (coonts, I tell ye) and it was decided that a stupid, out of context customisation POC had that was hacked together by the "customisation and delivery " (they know to do neither) team needed to be merged with the product (a hot, lumpy cluster fuck, made in a technology so old that even the great creators (namely Goo-fucking-gle) decided that it was their worst mistake ever and stopped supporting it (or even considering its existence at this point)).
Today morning, I my manager calls me and announces that I'm the lucky fuck who gets to do this shit.
Now being the defacto got admin to our team (after the last lead left, I was the only one with adequate experience), I suggested to my manager "boss, here's a light bulb. Why don't we just create a new branch for the fuckers and ask them to merge their shite with our shite and then all we'll have to do it build the mixed up shite to create an even smellier pile of shite and feed it to the customer".
"I agree with you mahaDev (when haven't you said that, coont), but the thing is <insert random manger talk here> so we're the ones who'll have to do it (again, when haven't you said that, coont)"
I said fine. Send me the details. He forwarded me a mail, which contained context not amounting to half a syllable of the word "context". I pinged the guy who developed the hack. He gave me nothing but a link to his code repo. I said give me details. He simply said "I've sent the repo details, what else do you require?"
1st motherfucker.
Dafuq? Dude, gimme some spice. Dafuq you done? Dafuq libraries you used? Dafuq APIs you used? Where Dafuq did you get this old ass checkout on which you've made these changes? AND DAFUQ IS THIS TOOL SUPPOSED TO DO AND HOW DOES IT AFFECT MY PRODUCT?
Anyway, since I didn't get a lot of info, I set about trying to just merge the code blindly and fix all conflicts, assuming that no new libraries/APIs have been used and the code is compatible with our master code base.
Enter delivery head. 2nd motherfucker.
This coont neither has technical knowledge nor the common sense to ask someone who knows his shit to help out with the technical stuff.
I find out that this was the half assed moron who agreed to a 3 day timeline (and our build takes around 13 hours to complete, end to end). Because fuck testing. They validated the their tool, we've tested our product. There's no way it can fail when we make a hybrid cocktail that will make the elephants foot look like a frikkin mojito!
Anywho, he comes by every half-mother fucking-hour and asks whether the build has been triggered.
Bitch. I have no clue what is going on and your people apparently don't have the time to give a fuck. How in the world do you expect me to finish this in 5 minutes?
Anyway, after I compile for the first time after merging, I see enough compilations to last a frikkin life time. I kid you not, I scrolled for a complete minute before reaching the last one.
Again, my assumption was that there are no library or dependency changes, neither did I know the fact that the dude implemented using completely different libraries altogether in some places.
Now I know it's my fault for not checking myself, but I was already having a bad day.
I then proceeded to have a little tantrum. In the middle of the floor, because I DIDN'T HAVE A CLUE WHAT CHANGES WERE MADE AND NOBODY CARED ENOUGH TO GIVE A FUCKING FUCK ABOUT THE DAMN FUCK.
Lo and behold, everyone's at my service now. I get all things clarified, takes around an hour and a half of my time (could have been done in 20 minutes had someone given me the complete info) to find out all I need to know and proceed to remove all compilation problems.
Hurrah. In my frustration, I forgot to push some changes, and because of some weird shit in our build framework, the build failed in Jenkins. Multiple times. Even though the exact same code was working on my local setup (cliche, I know).
In any case, it was sometime during sorting out this mess did I come to know that the reason why the 2nd motherfucker accepted the 3 day deadline was because the total bill being slapped to the customer is four fucking million USD.
Greed. Wow. The fucker just sacrificed everyone's day and night (his team and the next) for 4mil. And my manager and director agreed. Four fucking million dollars. I don't get to see a penny of it, I work for peanut shells, for 15 hours, you'll get bonuses and commissions, the fucking junior Dev earns more than me, but my manager says I'm the MVP of the team, all I get is a thanks and a bad rating for this hike cycle.
4mil usd, I learnt today, is enough to make you lick the smelly, hairy balls of a Neanderthal even though the money isn't truly yours.4 -
So I made this simple lamp that shows what is current build status on Jenkins CI.
Main features:
- Change color depending on Jenkins build status
- Automaticaly turn on/off if user is logged on Hipchat
- Beam effect if somebody makes coffee
- Unicorn effect if food is delivered
- Big red arcade button that can send random message to somebody on Hipchat
https://youtube.com/watch/...
https://github.com/macbury/lam.py 3
3 -
After working 3 years in my current job and my boss hating anything to do with unit testing etc, I used my spare time to refactor our Makefiles to allow for the creation of unit and integration tests. I technically didn't tell my boss about it, so my heart was in my throat when he Skyped me with 'what did you change in ...'?
After having bashed any workflow with testing in it, I showed him the new workflow and automatic testing in Jenkins and he was actually enthousiastic, just like all other employees! I was hailed a hero in the R&D department, after all this time we can finally write universal tests. :D7 -
So I joined this financial institution back in Nov. Selling themselves as looking for a developer to code micro-services for a Spring based project and deploying on Cloud. I packed my stuff, drove and moved to the big city 3500 km away. New start in life I thought!
Turns out that micro-services code is an old outdated 20 year old JBoss code, that was ported over to Spring 10 years ago, then let to rot and fester into a giant undocumented Spaghetti code. Microservices? Forget about that. And whats worse? This code is responsible for processing thousands of transactions every month and is currently deployed in PROD. Now its your responsibility and now you have to get new features complied on the damn thing. Whats even worse? They made 4 replicas of that project with different functionalities and now you're responsible for all. Ma'am, this project needs serious refactoring, if not a total redesign/build. Nope! Not doing this! Now go work at it.
It took me 2-3 months just to wrap my mind around this thing and implement some form of working unit tests. I have to work on all that code base by myself and deliver all by myself! naturally, I was delayed in my delivery but I finally managed to deliver.
Time for relief I thought! I wont be looking at this for a while. So they assign me the next project: Automate environment sync between PROD and QA server that is manually done so far. Easy beans right? And surely enough, the automation process is simple and straightforward...except it isnt! Why? Because I am not allowed access to the user Ids and 3rd party software used in the sync process. Database and Data WareHouse data manipulation part is same story too. I ask for access and I get denied over and over again. I try to think of workarounds and I managed to do two using jenkins pipeline and local scripts. But those processes that need 3rd party software access? I cannot do anything! How am I supposed to automate job schedule import on autosys when I DONT HAVE ACCESS!! But noo! I must think of plan B! There is no plan B! Rather than thinking of workarounds, how about getting your access privileges right and get it right the first time!!
They pay relatively well but damn, you will lose your sanity as a programmer.
God, oh god, please bless me with a better job soon so I can escape this programming hell hole.
I will never work in finance again. I don't recommend it, unless you're on the tail end of your career and you want something stable & don't give a damn about proper software engineering principles anymore.3 -
> barges in
> slams massive unintelligible PR on the table
> fixes a bunch of tickets all at once
> won't explain how tf it works, it just does
> refuses to elaborate further
> leaves 9
9 -
I was asked to fix a critical issue which had high visibility among the higher ups and were blocking QA from testing.
My dev lead (who was more like a dev manager) was having one of his insecure moments of “I need to get credit for helping fix this”, probably because he steals the oxygen from those who actually deserve to be alive and he knows he should be fired, slowly...over a BBQ.
For the next few days, I was bombarded with requests for status updates. Idea after idea of what I could do to fix the issue was hurled at me when all I needed was time to make the fix.
Dev Lead: “Dev X says he knows what the problem is and it’s a simple code fix and should be quick.” (Dev X is in the room as well)
Me: “Tell me, have you actually looked into the issue? Then you know that there are several race conditions causing this issue and the error only manifests itself during a Jenkins build and not locally. In order to know if you’ve fixed it, you have to run the Jenkins job each time which is a lengthy process.”
Dev X: “I don’t know how to access Jenkins.”
And so it continued. Just so you know, I’ve worked at controlling my anger over the years, usually triggered by asinine comments and decisions. I trained for many years with Buddhist monks atop remote mountain ranges, meditated for days under waterfalls, contemplated life in solitude as I crossed the desert, and spent many phone calls talking to Microsoft enterprise support while smiling.
But the next day, I lost my shit.
I had been working out quite a bit too so I could have probably flipped around ten large tables before I got tired. And I’m talking long tables you’d need two people to move.
For context, unresolved comments in our pull request process block the ability to merge. My code was ready and I had two other devs review and approve my code already, but my dev lead, who has never seen the code base, gave up trying to learn how to build the app, and hasn’t coded in years, decided to comment on my pull request that upper management has been waiting on and that he himself has been hounding me about.
Two stood out to me. I read them slowly.
“I think you should name this unit test better” (That unit test existed before my PR)
“This function was deleted and moved to this other file, just so people know”
A devil greeted me when I entered hell. He was quite understanding. It turns out he was also a dev.3 -
Some time ago, I asked DevRanters if you would use US or UK version of word.
Most of you said, whatever.
I just found case for using both :D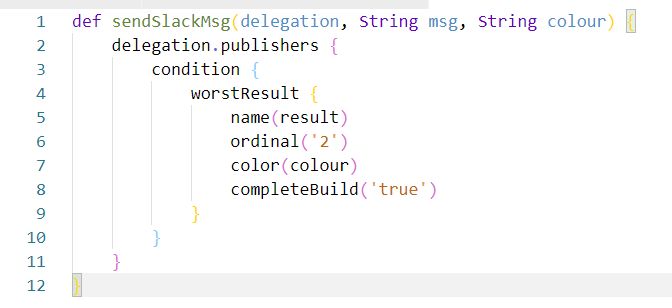 7
7 -
I feel like the Jenkins logo is just trolling me when this happens 5 minutes before the end of the day on a 3 hour build.....I hate you sir.
 5
5 -
In one of my teams there was this non-IT girl.
One morning, she asks out loud:
G - Can I run a Json?
Me - Wait! What are you trying to do?
G - I need to deploy my changes into the Dev server.
Suddently I realized what she meant.
Me- It's Jenkins! Not Json. :D1 -
My current job at the release & deploy mgmt team:
Basically this is the "theoretically sound flow":
* devs shit code and build stuff => if all tests in pipeline are green, it's eligible for promotion
* devs fill in desired version number build inside an excel sheet, we take this version number and deploy said version into a higher environment
* we deploy all the thingies and we just do ONE spec run for the entire environment
* we validate, and then go home
In the real world however:
* devs build shit and the tests are failed/unstable ===> disable test in the pipeline
* devs write down a version umber but since they disabled the tests they realize it's not working because they forgot thing XYZ, and want us to deploy another version of said application after code-freeze deadline
* deployments fail because said developers don't know jack shit about flyway database migrations, they always fail, we have to point them out where they'd go wrong, we even gave them the tooling to use to check such schema's, but they never use it
* a deploy fails, we send feedback, they request a NEW version, with the same bug still in it, because working with git is waaaaay too progressive
* We enable all the tests again (we basically regenerate all the pipeline jobs) And it turns out some devs have manually modified the pipelines, causing the build/deploy process to fail. We urged Mgmt to seal off the jenkins for devs since we're dealing with this fucking nonsense the whole time, but noooooo , devs are "smart persons that are supposed to have sense of responsibility"...yeah FUCK THAT
* Even after new versions received after deadline, the application still ain't green... What happens is basically doing it all over again the next day...
This is basically what happens when you:=
* have nos tandards and rules inr egards to conventions
* have very poor solution-ed work flow processes that have "grown organically"
* have management that is way too permissive in allowing breaking stuff and pleasing other "team leader" asscracks...
* have a very bad user/rights mgmt on LDAP side (which unfortunately we cannot do anything about it, because that is in the ownership of some dinosaur fossil that strangely enough is alive and walks around in here... If you ask/propose solutions that person goes into sulking mode. He (correctly) fears his only reason for existence (LDAP) will be gone if someone dares to touch it...
This is a government agency mind you!
More and more thinking daily that i really don't want to go to office and make a ton of money.
So the only motivation right now is..the money, which i find abhorrent.
And also more stuff, but now that i am writing this down makes me really really sad. I don't want to feel sad, so i stop being sad and feel awesome instead.1 -
My employer uses latest and greatest macbooks. It's fuking awesome. I wasn't a fan until I found the ease of android and iOS development on it. I even started using Atom for web development. And I bought a Mac mini for a dedicated jenkins server. I don't think I'll ever go back to windows. There's just no point. I know it's expensive but it gets the job done. No more fukin mac VMs on VMware. Fuk that shit.20
-
Our best dev/arch just quit.
C dev lead & a dev staying late chatting.
Lead: am building, takes long
Dev: unit testing, time taking
Ask them y they r building on their latitudes when we got them linux precision with xeons/64gb workstation 1 each ?
Both: I code on latitude.
Build/test times. (pure Java/maven)
Latitudes=an hr or more
Precision=2m to 11m
Jenkins Infra we have =10 mins with test & push. Parallel builds support.
Am suposed to help with an open mind. They now want Mac pro12 -
You know your build process is slow when your colleague compares it to buying groceries in "communist Romania".3
-
A 30 minute Jenkins pipeline just happened to start at the same time as today’s Nintendo Direct. Whoops. Guess I’ll take a break.
-
It took me 30min to figure out why jenkins couldn't connect to my repo even though i was sure i got the configuration right this time. As it turned out fail2ban blocked my ip and made all subsequent attempts fail...4
-
There is always that one guy.. who doesn't give a fuck about testing and thinks he's not responsible for them...
Le Guy: lemme just push ma new code maan
Jenkins: Unit Tests failed - pls fix
Le Guy to the one who cares about testing: hey fuck uu, ur stupid tests are failing... fix them its ur problem.
*sigh*7 -
In my current company (200+ employees) we have 3 guys who deals with everything related to service desk (format computers, fix network issues, help non-tech people...)
The same team is responsible for the AWS accounts and permissions, Jenkins, self hosted Gitlab... anyway, DevOps stuff.
Thing is: only one of them have enough DevOps background to handle the requests from the engineering team (~15 people). Also, he usually do anything "by hand" clicking trough the AWS interface on each account, never using tools like Infrastructure as Code to help (that's why I started to refer to his role only as Ops, because there's no Dev being done there).
Anyway... I asked my manager why that team is responsible for both jobs, despite the engineering guys having far more experience with those tools. He answered with a shamed smile, as he probably questioned the same to his manager:
- Because they are responsible for everything related to our Infrastructure.
Does it make sense for anyone? Am I missing something here? In what universe this kind of organization is a healthy choice?4 -
Any fun self-hosted app or useful services you guys use on your own server?
For some weeks I have started to host my own git repository with gogs and take continious development into my control with jenkins and feel pretty neat.
Now I understand why my grandmother loves to raise her own food even when she could buy everything in the supermarket.9 -
As you guys may or may not know (or may or may not give a fuck), I'm currently part-time studying to get a diploma and get the fuck out of my country. Since I have to write a 40-pages long "end of study dissertation" about something we personnaly have interest in, I decided to teach myself about DevOps.
In order to prepare it, I decided to get a Raspberry Pi, install Docker and Jenkins (as a container) on it, and handle my multiples websites on it, and build a huge fucking website around which I would write my dissertation about.
But man, I'm starting to loose hope, I get to bed at 2 AM every night because I'm trying to make some basic shit work until I realize that I just CAN'T what I want because of tons of reason, so I try to lower my expectations, and it's frustrating. Yesterday, a Ruby on Rails image I created was perfectly working, tonight MySQL throws an "host not authorized for this mysql server" error, and I don't know what the fuck is happening nor if I can do anything about it.
I love teaching myself new stuff, but I have to admit, it's waaay harder than I expected1 -
Today, in the course of my job, I said...
FFS. I HATE WINDOWS.
It has begun.
Took me five minutes to ssh into the Linux EC2 and get the Jenkins agent installed, configured, and running. Half a fucking hour for Windows Server 2012.
1) Can't ssh to it, so I connect via AWS console... Which means I have to install MS Remote Desktop. WHATEVER. FINE. It's not like ssh is quick and easy or anything.
2) Can't just use the command line, run the .jar &, cntl-z, and bg then log off. Noooo. I have to install the unpacked binaries as a fucking SERVICE. FINE. WHATEVER.
I'm so glad we have a Windows guy that does most of this shit. I can't stand it.1 -
I'm pretty sure I'm more excited to finally have Jenkins integration at my work than I was for my birthday this year. No more manual builds!3
-
Fake sticker story time. It is fucking on fire. Then I press npm install twice. Forgot node modules in gitignore. Then got push to production served by Jenkins. Now get the fuck out of here.
 1
1 -
So I handed in my official resignation last week as I will be changing to a new job next month. So one of the last big things that I have been working on is a Jenkins server for the rest of the team to use and currently writing up the documentation for it.
However I haven't been told who I will be handing over my work to, but the bigger thing I feel is that even if I write all the documentation, no one will actually read it. Reason I think this is because I doubt anyone else in the team will even use the Jenkins server. The major issues are that no one writes unit tests and don't even understand what CI is!
So right now it feels like my final month of work will all be for nothing and makes me wonder if I should even bother writing documentation, especially if it isn't going to be handed over to anyone.5 -
When you just merge master into development branch and whole Jenkins wall turns red. Wtf? Wasn't me bro.. o.O
-
I FUCKING love it when I try to understand how to simply fucking connect to my server via SSH, and seeing tutorials from cocksuckers that just screen some form fields without telling where I can find them, and juping from steps to steps like I'm in your fucking head
CAN'T YOU WRITE SOMETHING THAT WOULD MAKE SENSE, YOU FUCKING MORON???3 -
Developer tells me jenkins job is broken and to fix it.Doesn't even look at the test report. "Works fine locally." 3 failed tests.1
-
Today's conversation in our odc
Person 1: Jenkins Down
Person 2: YouTube or Facebook
Person 1: No... Twitter
Person 2: Gud it means you guys are not blocked...
Awesome troll...
😂 😂 😂 -
The best way to describe what I had to do today is I "Channeled Macgyver"... now production is working.
⚪Data wasn't flowing as expected.
⚪Component written by our team was blamed.
⚪Boss asked me to bypass the component so data can flow.
Sure, I can fix that... Give me a car battery, a roll of duck tape and a butter knife. Data will be flowing in production shortly. -
We are upgrading to nodejs 8 late, because no one is tracking versions. I had to rage a prove war with everyone that we must upgrade because node 6 is ended lts. This week i have to argue with one of the admins that the build server should be updated also (jenkins). And his problem is that our private jenkins server is not used only by our company, but other companies under our group. In my mind the only question is who decides our or other company project is important to build nor6maly. And why we should care ..
Every fucking time its a war against stagnant and/or lazy people.5 -
I hate dev politics...
PM: Hey there is a weird error happening when I upload this file on production, but it works on our test environments.
Me: After looking at this error, I don't find any issues with the code, but this variable is set when the application is first loaded, I bet it wasn't loaded correctly our last deployment and we just need to reload the application.
Senior Dev: We need to output all of the errors and figure out where this error is coming from. Dump out all the errors on everything in production!!
Me: That's dumb... the code works on test... it's not the code.. it's the application.
Senior dev: %$*^$>&÷^> $
Me: Hey I have an idea! If test works... I can go ahead and deploy last week's changes to prod and dump those errors you were talking about!!
Senior Dev: OK
Me: *runs Jenkins job the deploys the new code and restarts the application*
PM: YAY you fixed it!!
Senior Dev: Did you sump put those errors like I said.
Me: Nope didn't touch a thing... I just deployed my irrelevant changes to that error and reloaded the application.2 -
*me working at a huge company as a customer*
Ok, show me what you got.
* Company throws some of the most gruesome and ugly scripts at me*
HAVE YOU EVER HEARD THE WORD INIT SYSTEM? HAVE YOU EVER HEARD THE TERM PRIVILEGE SEPARATION OR BACKUP? DO YOU KNOW THAT A SVN REPO IS NOT SUPPOSED TO BE 500GB BIG? AND A JENKINS JOB SHOULD NOT RUN 8HOURS!
Company: you ain't have seen nothing yet.
And they were so right...almost can't bear it anymore3 -
I am starting to get really annoyed by shitty devs and tech leads from other teams that ask me to fix urgently a "problem" with my project they rely on, but turns out they did not even debug the fucking thing in the first place to understand where the problem comes from.
Turns out someone used the wrong parameters on his duct taped jenkins CI and instead of finding the reason for the failure, he just assumed my code did not work.
This is the last time I'm helping you fucks before a release while I am on holidays in my country. Worst thing is you guys are paid twice my salary in US dollars but you still can't code and debug for shit.
How about telling me truth when I asked you guys if everything was working fine before I took my vacations? Do you fucking test your shit for fuck's sake? Nah you guys just suck ass.
I will turn off my computer when off work from now on and uninstall slack and emails from my cell phone. These guys are not competent enough to use those tools properly.3 -
Am I the only one that doesn't like Java? I mean I don't hate it or say it's bad. It's pretty clear that it has been probably the most influential language after C. I just don't like how typed and verbose it is, also I feel old just using it or something based on it (like Jenkins)11
-
A few days ago our server was compromised due to an outdated Jenkins version. The malicious user installed a crypto miner on the server... The same day that it was found I told management that I'm interested in helping out with the server. Since then, nothing happened... No updates, no security measures, no nothing (except for the removed crypto miner and updated Jenkins software)
Oh well only a matter of time before another hack...
Question to some (who work way way way longer than me) med - seniors, should I make a big deal out of this? And keep pressure on it. Or should I just leave it be and wait for the next comprised server? I know devrant is not a Q&A service, but some dev to dev advice is much appreciated.
- incognito1 -
!rant
working from office for the first time since Covid started.
so many little things I didnt even realise I missed, like an ethernet cable straight into the corp network so I dont have to connect to a VPN just to run a Jenkins build.4 -
merged a complicated pipeline script based on 3 other scripts, and it worked the first time I run it.
Pretty sure There was a Disturbance in Force... -
Can't believe i've just had to explain master/slave terminology to someone who has been running our Jenkins CI/CD stack for several years.
That's unusual right?6 -
jenkins tests passing but travis failing. now travis passing but jenkins failing, aargh!
more beer needed... -
Finally found a way to deploy my Docker image to my VPS with nothing else than GitlabCI. My CI/CD system will soon be perfect.
[ Heavy breathing ]3 -
Work has been inefficiently using multiple cron jobs to run php scripts to generate pre-baked data.
The last two days I took the steps needed to internalize all those scripts and run them from an individual php controller which is ran from Jenkins. My script keeps track of scheduling and error tracking.
I'd say I'm pretty proud of what I came up with.1 -
Worked all day yesterday (8am to 11pm) trying to get a regression test developed in ReadyAPI to behave properly in Maven/Jenkins. All I have to say is that I have some words for Smartbear.

-
Finally closed an Epic that was started on April of 2019 to migrated everyone off the old Jenkins server. Finally completed, nearly a year later and under a different project manager and director.2
-
You can connect to Docker containers directly via IP in Linux, but not on Mac/Windows (no implementation for the docker0 bridged network adapter).
You can map ports locally, but if you have the same service running, it needs different ports. Furthermore if you run your tests in a container on Jenkins, and you let it launch other containers, it has to connect via IP address because it can't get access to exposed host ports. Also you can't run concurrent tests if you expose host ports.
My boss wanted me to change the tests so it maps the host port and changes from connecting to the IP to localhost if a certain environment variable was present. That's a horrible idea. Tests should be tests and not run differently on different environments. There's no point in having tests otherwise!
Finally found a solution where someone made a container that routed traffic to docker containers via a set of tun adapters and openvpn. It's kinda sad Docker hasn't implemented this natively for Mac/Windows yet.4 -
The CI infrastructure and external tooling at the company I work at is a complete joke. Feels like it was designed by an intern left alone.
95% of the time a build fails or hangs, it's because we are getting race conditions or a hanging VM with our crappy Windows jenkins slaves. Quite possibly because we are not using proper tooling for monitoring those VMs as well. Anyways, I don't have access and control on it and it's not even my job to fix it.
Though, I am being asked to monitors these pieces of junk jenkins jobs outside of my work hours because company devs all over the world use it... but there is no fucking way to know it failed unless I log onto jenkins every hour and check everything manually... which is stupid as fuck for a software engineer.
I can't even implement slack hooks to get notifications or something when it fails because we will stop paying for it soon, so I have to connect to my freaking VPN on my PC and check everything.
And what's the fucking ghetto solution instead of fixing it properly? Restarting VMs and rerunning a build. Because someone in management wants to see a passing build, even though it means jackshit. Half of these jobs are tagged as unstable, so what's the fucking point?
Pisses me off when people work like morons and pressure others to do the same.1 -
I landed myself an interview with a really great company for a DevOps intern position tomorrow.
Im really hopeful about this. The company truly seems like a great place to work with incredible opportunity to grow, and I desperately want to pursue a career in DevOps, but Im worried that Im underqualified. I lack true professional experience, and have really had no adequate time working with CI/CD tools, but I am very interested, excited and willing to work hard to become proficient.
Ive been prepping myself as much as I can in this last week (trying to gain familiarity with tools like jenkins, artifactory, chef etc), and so I ask to you, my fellow ranters (particularly DevOps), are there any final tips or bits of advice that I can take to really impress my interviewers and better my chances of getting this position?
Also, hello again to my old devRant pals~ I miss hanging around here and conversing with you great people13 -
I come back after a week of vacation and everything is broken.
What does Jenkins say?
Jobs disabled days ago.
- Yeah it hangs randomly and is blocking other projects.
Don't know if I'm gonna cry or laugh like a maniac, maybe both. -
Q: How instantaneous are these jobs? *referring to a Jenkins job to upload database from local to an environment
A: Well that depends on your network speed. Here in the middle of nowhere, I have a donkey carries the package up the mountain, so that could take a while.2 -
"Java and C++ Spring Boot and Angular Ansible Jenkins Azure Hosting"
nice, a stack for boomers lost in the 2000s
stop it. just stop it.
"Some other tech buzzwords we use"... yeah, "typescript" and "big query" are not "tech buzzwords" they're literally the names of languages and/or tools
tell me you're an HR rube without telling me you're an HR rube
😩😩😩 <- love this one, literally called "weary face"4 -
Two (2) senior developers and one (1) senior tester left our team and I am left with two (2) Java legacy applications that are hard to maintain. Here is a list of things I hate about these old webapps (let's call them app A and B):
1. App A depends on 80% web services. If one web service for a product or warehouse goes down, work flow is impeded while prod support team checks with the core services team for repair
2. App B is a maven project with multiple modules dependent on libraries that are dependent on company's internal libraries. So if we want to upgrade to OpenJdk 9 and up, the project will definitely produce a lot of errors due to deprecated/unsupported codes
3. App A is dependent on Tibco and I have no experience on that
4. App B's continuous integration build tool is Jenkins and the jobs that build it has a shell script that wasn't updated during the tech upgrade enhancement. The previous developer who did the knowledge transfer to me didn't tell me about this (it should be considered a defect on her part but she already resigned)
5. App A when loaded in eclipse IDE is a pain to work with since it is only allowed to build a war file using ant. I have to lookup in quick search instead of calling shortcuts (call hierarchy) because the project wasn't compiled via eclipse.
6. It's impossible to debug app A because of #5
7. Both applications have high priority and complex enhancements and I have no other teammates to help me
8. You never know what else can go wrong anytime1 -
So we started using Jenkins at work. Which is pretty cool so i wanted to watch some YouTube videos about it in my spare time.
But 99% of those videos are made by Indians and they are probably good videos but i just can't handle the accent. =/9 -
I'm in a team of 3 in a small to medium sized company (over 50 engineers). We all work as full stack engineers.. but I think the definition of full stack here is getting super bloated. Let me give u an example. My team hold a few production apps, and we just launched a new one. The whole team (the 3 of us) are fully responsible on it from planning, design, database model, api, frontend (a react page spa), an extra client. Ok, so all this seems normal to a full stack dev.
Now, we also handle provisioning infra in aws using terraform, doing deployments, building a CI/CD pipeline using jenkins, monitoring, writing tests, building an analytics dashboard.
Recently our tech writer also left, so now we are also handling writing feature releases.
Few days ago, we also had a meeting where they sort of discussed that the maintenance of the engineering shared services, e.g. jenkins servers, (and about 2-3 other services) will now be split between teams in a shared board, previously this was handled only be team leads, but now they want to delegate it down.
And ofcourse not to mention supporting the app itself and updating bug tickets with findings.
I feel like my daily responsiblities are becoming the job responsibilities of at least 3 jobs.
Is this what full stack engineering looks like in your company? Do u handle everything from app design, building, cloud, ops, analytics etc..6 -
To me this is one of the most interesting topics. I always dream about creating the perfect programming class (not aimed at absolute beginners though, in the end there should be some usable software artifact), because I had to teach myself at least half of the skills I need everyday.
The goal of the class, which has at least to be a semester long, is to be able to create industry-ready software projects with a distributed architecture (i.e. client-server).
The important thing is to have a central theme over the whole class. Which means you should go through the software lifecycle at least once.
Let's say the class consists of 10 Units à ~3 hours (with breaks ofc) and takes place once a week, because that is the absolute minimum time to enable the students to do their homework.
1. Project setup, explanation of the whole toolchain. Init repositories, create SSH keys for github/bitbucket, git crash course (provide a cheat sheet).
Create a hello world web app with $framework. Run the web server, let the students poke around with it. Let them push their projects to their repositories.
The remainder of the lesson is for Q&A, technical problems and so on.
Homework: Read the docs of $framework. Do some commits, just alter the HTML & CSS a bit, give them your personal touch.
For the homework, provide a $chat channel/forum/mailing list or whatever for questions where not only the the teacher should help, but also the students help each other.
2. Setup of CI/Build automation. This is one of the hardest parts for the teacher/uni because the university must provide the necessary hardware for it, which costs money. But the students faces when they see that a push to master automatically triggers a build and deploys it to the right place where they can reach it from the web is priceless.
This is one recurring point over the whole course, as there will be more software artifacts beside the web app, which need to be added to the build process. I do not want to go deeper here, whether you use Jenkins, or Travis or whatev and Ansible or Puppet or whatev for automation. You probably have some docker container set up for this, because this is a very tedious task for initial setup, probably way out of proportion. But in the end there needs to be a running web service for every student which they can reach over a personal URL. Depending on the students interest on the topic it may be also better to setup this already before the first class starts and only introduce them to all the concepts in a theory block and do some more coding in the second half.
Homework: Use $framework to extend your web app. Make it a bit more user interactive with buttons, forms or the like. As we still have no backend here, you can output to alert or something.
3. Create a minimal backend with $backendFramework. Only to have something which speaks with the frontend so you can create API calls going back and forth. Also create a DB, relational or not. Discuss DB schema/model and answer student questions.
Homework: Create a form which gets transformed into JSON and sent to the backend, backend stores the user information in the DB and should also provide a query to view the entry.
4. Introduce mobile apps. As it would probably too much to introduce them both to iOS and Android, something like React Native (or whatever the most popular platform-agnostic framework is then) may come in handy. Do the same as with the minimal web app and add the build artifacts to CI. Also talk about getting software to the app/play store (a common question) and signing apps.
Homework: Use the view API call from the backend to show the data on the mobile. Play around with the mobile project to display it in a nice way.
5. Introduction to refactoring (yes, really), if we are really talking about JS here, mention things like typescript, flow, elm, reason and everything with types which compiles to JS. Types make it so much easier to refactor growing codebases and imho everybody should use it.
Flowtype would make it probably easier to get gradually introduced in the already existing codebase (and it plays nice with react native) but I want to be abstract here, so that is just a suggestion (and 100% typed languages such as ELM or Reason have so much nicer errors).
Also discuss other helpful tools like linters, formatters.
Homework: Introduce types to all your API calls and some important functions.
6. Introduction to (unit) tests. Similar as above.
Homework: Write a unit test for your form.
(TBC)4 -
I have officially decided to use CI (Jenkins) at work because "apt-get update && apt-get upgrade -y && composer self-update && composer update && npm update -g && npm update && bower install --allow-root && gulp" after a pull doesn't seem healthy 😂2
-
Jenkins you are a bad butler! Why can't you just do your job? We wouldn't be in this pickle if it weren't for your incapability!
Job opening: any suggestions for a replacement butler?4 -
shutdown an old Jenkins CI pipeline from one of our teams... after one month they call us to bring it online again because they don't know how to build it manually.... lol #automation #scripting #jenkins2
-
Maintained a Jenkins instance once. Shut down a slave, and forgot to tell the master.
45gb of logs later... -
What's your work secret to staying healthy (emotionally, mentally, physically)? I climb flights of stairs while my Jenkins job is building.16
-
Looking to sharpen and pursue a SysAdmin/DevOps career, looking at online job offers to get the big picture of required skills and I say FUCK. It would take me a lifetime.
Azure, AWS, Google cloud platform.
CD tools: Ansible, Chef or Puppet
Scripting ninja with Python/Node and Shell/Power shell.
Linux & Windows administration
Mongo, MySQL and their relatives.
Networking, troubleshooting failure in disturbed systems
Familiarity with different stacks. Fuck. (Apache, nginx, etc..)
Monitoring infrastructure ( nagios, datadog .. )
CI tools: jenkins, maven, etc..
DB versioning: liquibase, flyway etc.
FUCK FUCK FUCK.
Are they looking for Voltron? FUCK YOU FROM THE DEEPEST LEVEL OF MY DEEP FUCK.1 -
Spending 4 days to connect gitlab with cloudbees (not my choice) through Jenkins file and find that I didn't work because the URL I set in the form in gitlab had a "/" at the end of the cloudbees URL.....
-
PM: "We would like our automated testing / continuous integration in AWS"
Me: *Army crawling towards Jenkins with my last dying breath* 3
3 -
Ever suggest improvements and get shot down at every turn? I was discussing automating our release process today and suggesting that instead of having to do everything manually and babysit the build, we should let Jenkins deal with releasing and the attitude was that we shouldn't even try because we'd spend more time maintaining the automation and wouldn't gain anything. Obviously I disagree, but it seems like I'm always coming up against shit like this.
Our requirements gathering is another point of contention; I think we could be way better at it if we invested more time talking to customers before a project starts but the attitude is to get straight into development and deal with that later.
I don't know why I even bother sometimes...4 -
So today's conversation with my co-worker who built our build system...
Me:OS X build server is not building valid installs.
Him:What's the problem?
Me:The KEXT is not rebuild... I think that Jenkins isn't capable of updating the file because of the permissions the script set when you test compiled it manually... Could you please add Jenkins user to sudoers file or something?
Him:Yes of course, but what should I google?
WTF dude? Do you even think yourself? And for some reason no-one has acces to the build servers configs exept for him and he shows up like 3 times a week... -
Chances of getting all the bugs fixed before the demo...
"What do you think Abdul? Can you give me a number crunch real quick?" 1
1 -
Group assignment: writing a own Java logger component in a group of four, using nothing else than Java SE libraries, Maven and Jenkins. The software must be able to substitute the logger component without recompilation, just by editing the config.xml (setting jar file path and fully qualified class name of the logger).
I asked around on Slack which group is ready for a component exchange, so that we could test the switch. I found another group and I started doing some testing.
Then I got a `java.lang.NoClassDefFoundError: org/apache/log4j/Logger`. I got in touch with my peer from the other group and asked him, if they've been using log4j. Apparently they did, so I told him that the assignment was to write a logger of one's own, not just using log4j. Then he told me: "Uh, ok, I'm going to tell the guy responsible for the logger part about that..."
X-D -
Yesterday, I was expecting my merge request to be closed.
I've done all the stuff my tech lead told me to do.
All tests passes, green light boyzzzzz.
Gitlab CI pipeline passes, greeeeeen light I said.
In Jenkins everything f*cked up...
Why ??
Well it was a conflict with 3 other MRs, missing rebase from other dudes.
And because they were remote working, got to clean up all this mess.
That's was a day off.
PS : well that's was not so off, I could fix a UB on a ternary and extend a test which was not covering some cases.
PS2 : learn git damn3 -
That feeling when you have to rebuild and redeploy project for the third time in a row because java can't map Swedish letters. About 20mins for each try.3
-
When I have a Jenkins build fail, then fix the issue, I run the build four more times manually to make that branch "sunny" again.1
-
Here's the story of me trying to set up Jenkins with Java, Maven and pipelines. I finally got it to work :D Not sure if it's the correct way and all, but fuck it, it works!
 1
1 -
Jenkins' triggerManualBuild randomly but if so then consistently produces 500 errors for certain newly created jobs. I haven't really found a pattern, yet I was bit by it in the past already. I used to "solve" it by deleting the offending job and re-creating it.
Now, I have this annoying issue again, and no matter how often I re-create that shitty one-liner job in the pipeline, it won't trigger. (The job itself is fine. It's the actual trigger that is broken.)
It's not like it's important or anything, as this is basically only the "push to production" step.
FML. And fuck me for stating: "Creating a delivery pipeline should be straightforward. I therefore consider 1 storypoint enough."4 -
Project Lead: The DevOps department just got a GitLab instance installed on our internal network. We're gradually going to move all our projects onto it and move away from BitBucket and Jenkins really soon.
Me: Awesome!
Project Lead: We're still using JIRA and Confluence for issue tracking and documentation though because the higher ups said so.
Me: 1
1 -
we had a lot of date specific background tasks that run. one day one of the major tasks were not doing anything at all. check the builds in jenkins, was being triggered at 8pm as designed , but no output or errors, just success. eventually found out that someone changed the timezone on the remote host executing the job, so the job was infact running in the future where no events existed! needless to say was a simple fix! and mow I use NTP for everything1
-
If you suspect that you know me "in real
life" {
please raise your hand &&
don't share the answer with the rest -
of the class (🤫);
} else {
enjoy the suspense 🌻💅🔪;
}
Tara2 -
Rails, React, React-Native, Docker, Kubernetes, Openstack, Jenkins, AWS, Microservices, Realm, MongoDB, PostgresQL, GraphQL (list goes on...), and I'm not even done yet.
6 months was spent learning all of the above because I found a Rails-only monolith on Heroku unsettling. My first batch of containers was just deployed and I couldn't be happier. Love my job.3 -
So Docker is pretty amazing, but I'm finding myself immensely frustrated at all the stupid shit devs do with their Dockfiles and stacks. Like the surprise of finding out Jenkins clients aren't setup for SSH or stacks opening up 5 public ports when all they really need are a bunch of private ports. Or how Jenkins deployments expect crazy tags so I have to add some really stupid tags to my own nodes.
How is it so hard to comprehend Docker for devs? It's so easy that I'm in utter bliss when I stop trying to use 3rd party stacks.1 -
I know you can start a build process in the visual Studio dev console. Is there a way to start this process from a PowerShell sript? And if yes, how do I do this?
I want to/ need to learn automated testing.5 -
Way back no full stack. Now theres full stack and companies expect us also to be full stack + DevOps God that knows Azure, AWS, Jenkins, Docker, Ansible , puppet etc.
They want to save money and hire a one man IT department.
Full stack web and mobile developer with DevOps God skills.
Frontend = Angular React
Backend = Java Python
DB = NoSQL, MySQL, Firebase, Postgres6 -
After spending lots of money on a Mac mini 2014, ngrox, and other dev tools to get jenkins working for android, iOS, and node.js, I'm giving up and switching to bitbucket pipelines. Recently, my web builds having been taking +25 mins just downloading node modules. Let's see how fast bitbucket pipelines is. Especially with caching node modules.1
-
That feeling when the Jenkins build fails and fixing it is both out of your scope and permission.
Dear devops, you should know when a certificate expires that we use to authenticate with external web services. -
me:task assigned is a small fix.Gonna finish Early sit back relax this sprint.
mail(next day):we've moved to microservices.setup as easy as gulp landscape:start
me:cool!shinny new stuff!seems easy!!
project:npm failed..please check module xxx..
me:fine.....
after long mail chain
project:npm failed unknown file not found
me:fine.....
after hours of googling and little github issue browsing
project:server running @ portxxx
me:yay finally happy life!!makes chnages, sent for review.
reviewer:code needs refactoring!!
me:make all changes..waits for faceless reviewer from another timezone!
reviewer:thumbs up.
me:i will make it in time!!!yes!!
jenkins:buid:failure
me:no still i wont give up...
debug finds out new bugs caused by unrelated code...make new PR the end is near,one day more will definitely merge!!!
mail:jenkins down for maintenance!
me:nooooo....waits till last minute gets thumbs up for merge, finally merged in the last second!!
all for 12 lines of code change.
:/
sad life -
My manager committed an empty Jenkinsfile on his project (he loves committing empty files or docs with words "TODO" in them). I decided to add the project to Jenkins so at least he sees a red X and failed build on ever branch .... green check? An empty Jenkinsfile is a valid Jenkinsfile?! Damn it Jenkins!2
-
I just got Jenkins all setup locally, setup the first pipeline, get docker working with it, setup the build step, setup the test step and more.
In under an hour.
Not too bad for the first attempt.
The hardest part was figuring out the GitHub credentials.
———
Actually, the hardest part was keeping an eye on the dude in the booth next to me who has delusions of grandeur and likely other mental illnesses.
Had to keep an eye on him while he was pointing around the room (usually at me) and saying shit like...
“Ugly, ugly, all of you are fucking ugly”
“Fuck you, fuck you too!”
I’m sitting over here thinking...
“Bud, you got 3 teeth, you smell like shit and your rambling to yourself... fuck you you ugly piece of dog shit! Let me do my work I peace.”4 -
FUCK YOU JENKINS
The tests work everywhere just not for you
It worked before and I DID NOT CHANGE ANYTHING FOR THIS TEST TO FAIL
FUUUUUUUCK5 -
Extremely frustrated with the release process and versioning system at my current company. Don't know if this is same everywhere or the half ass release managers can't think of a better way here.
Basically for any client raised issue that can't wait for next release are built as a hotfix. However hotfixes are never bundled togather or shiped to other clients. This is causing a vicious chain, two clients raise two separate issues on same version. Instead of fixing them as single hotfix (however minor the issues) we create two hotfix versions for each with only their issue. A week later same clients come back with the issue the other raised. Once again instead of bundling what is now effectively same code we build hotfixes on top of the clients respective branches. We now have two branches to maintain with same codebase. No matter how serious issue, the hotfix is never made generally available and always created on client's specific hotfix version.
Now that was an example for only two clients, in reality we have released five patch versions of a product in last 2 years. Each product version contains about a dozen artifacts (webapps, thick clients, etc) with its own version. Each product version being shipped to various clients. Clients being big banks never take a patch of product even if it fixes their issues and continues requesting hotfix. We continue building hotfixes on client branch and creat ever increasing tech debt. There is never a chance to clean up or new development. Just keep doing hotfix after hotfix of same things.
To top if all off, old branches are still in svn while new in git. Old branches still compile with ant new with maven. Old still build with java 5,6,7 while current with 8. Old still build from old jenkins serve pipelines while new has different build server. Old branches had hardcoded integration db details which no longer exists so if tou forget to change before releasing it doesn't work.
Please tell me this is not normal and that there are better ways to do this? Apologies I think I rambled on for too long 😅5 -
A long time ago in a decision poorly made:
Past me: hmm we're having trouble getting IT to give us a new build machine with the new compilers.
Past me: I know we'll just use one of the PCs that belongs to a member of the team to tide us over.
[2 months pass]
Present me: that's odd, Jenkins is really slow today.
[Several minutes pass]
Present me: holly shit fuck; it's building the whole weekends worth of builds at 9am on a workday and eating licenses like a cast away that suddenly teleported to an all you can eat buffet.
Present me: [abort, abort, for the love of fuck abort]
Present me: contacts IT, they can't find any problems, wtf happened.
Present me: discovers team member turned off his machine on Friday and builds had been stacking up all weekend.
Lessons learnt: disable power button on team members pc and hire a tazer guy to shoot whenever someone goes near the wall socket.
1 hour lost and no build results for the last 3 days.
It's looking like a bad morning
-
🎼Cu-cum-ber docs led me to beliiiiiiiiiiiieve
The exit flag was un-nec-e-ssaryyy
Thought I’d make a new branch
Remove it in CI
Let it run in Jenkins
That’s the reason for the never-ending teeeeest ruuuun 🎶
^to the tune of Neverending Story6 -
Well fuck. I am experiencing over-engineering first hand.
I am the single dev responsible for developing a small feature but which is an identity to our whole product(feel free to guess it here). This is quite simple I thought, I can just modify the constants which are being used in the source code and I can finish it off in a week tops. I asked all the relevant teams over which this feature would have dependencies and they gave me a green signal. Setup Jenkins configuration and everything for this new feature. With a wide grin on my face, I sent out a pull request. Now the architect of our product declined the pr saying to change everything from the bottom up giving the reason that it would be configurable sometime later in the future. Now mind you, I get it if this feature could change over time and needs customability. But it has been the same since last seven years and would probably not change again for a couple of years ahead [you have to take my word for it.]. Its not that the guy is a douche or anything, he is one of the best dev I have ever personally came across and I highly respect and admire him. But there has to be a trade off between the effort you are putting in versus the benefit you get. Now I have to touch almost every file, super carefully look in the whole product if a bug creeps out from anywhere and change the existing code to a point where it doesn't even make sense to me anymore, and write tests ofcourse.
wubba lubba dub dub!2 -
A home hosted build server for continuous integration is always crap and a blocker for everyone. If you don’t have 5(yes, five) full time admins/devops to support that, forget about building the infrastucture yourself. There are companies whose business is to provide CI as a service, why do you think you can beat them with your crappy Jenkins installation?
I’ve seen a 200 company failing with 2 people. I’ve seen another one completely failing, because the admins didn’t know what CI meant, and a small one failing with 0.5. The only place where it kind of worked used Gitlab. -
Fixed a jenkins crumb issue which my project is facing for past 6 months. Jenkins guy keep sending the crumb from his personal browser whereas we need to request it from our script.7
-
When you see: "Agreeing to the Xcode/iOS license requires admin privileges, please re-run as root via sudo." in the Jenkins console log and realize that XCode was updated.
-
What the fucking fuck. Arquillian you piece of shit.
I have a service that needs to go to production soon, it contains Arquillian tests. The tests work locally but not when going through our new Jenkins pipeline. The error message simply says: "Could not start Arquillian container".
Well fuck you too.
After 3 fucking days of rewriting configs, changing up things and I dont know what else I did, I stubled upon the most hidden error message in the history of error messages, a small little line that says "Could not find or load main class ".
Those 2 spaces are intentional btw, because the fucking error was that when starting arquillian and reading the config there was A FUCKING SPACE too much in my JVM arguments. This piece of shit iterpreted it as my FUCKING MAIN CLASS. Whhhhyyyyy, whhhyyyy. Who the fuck... AAAAAAAAAHHH
Btw I snuck myself on devrant a few weeks back and managed to get my 100++ today. Really love this place 😊1 -
Dahhhh. Pay for a damn hosted CI server please, like Circle or Travis, so I don't have to maintain this crappy Jenkins instance. More "plugin" updates by default than a crappy wordpress site.
Talking of which. Circle CI has come on leaps and bounds since I last looked at it. So much nicer than Travis. Think this is going to be my de-facto CI solution for open source stuff from now on.10 -
The world would be much more perfect if Jenkins released images for ARM architectures (Raspberry Pi), so that noobs DevOps wannabes like me could play around with that 😭2
-
This is an actual transcript...
Since it's way too long for the normal 5000 characters, hence splitting it up...
Infra Guy: mr Dev, could you please give some rational for update of jjb?
Dev: sparse checkout support is missing
Infra Guy: is this support mandatory to achive whatever you trying to do?
Dev: yes
Infra Guy: u trying to get set of specific folder for set of specific components?
Dev: yes
Infra Guy: bash script with cp or mv will not work for you?
Dev: no
Infra Guy: ?
Dev: when you have already present functionality why reinvent the wheel
Dev: jenkins has support for it
Dev: the jjb is the bottle neck
Infra Guy: getting this functionality onto our infra would have some implications
Dev: why should I write bash script if jenkins allows me to do that
Dev: what implications ??
Infra Guy: will you commit to solve all the issues caused by new jjb?
Dev: you show me the implications first
Infra Guy: like a year ago i have tried to get new jjb <commit_url>
Infra Guy: no, the implications is a grey area
Infra Guy: i cant show all of them and they may hit like in week or eve month
Dev: then why was it not tackled
Dev: and why was it kept like that
Infra Guy: few jobs got broken on something
Dev: it will crop up some time later
Dev: if jobs get broken because of syntax
Dev: then jobs can be fixed
Dev: is it not ???
Infra Guy: ofc
Infra Guy: its just a question who will fix them
Dev: follow the syntax and follow the guidelines
Dev: put up a test server and try and lets see
Dev: you have a dev server
Dev: why not try on that one and see what all jobs fails
Dev: and why they fail
Dev: rather than saying it will fail and who will fix
Dev: let them fail and then lets find why
Dev: I manually define a job
Dev: I get it done
Infra Guy: i dont think we have test server which have the same workload and same attention as our prod
Dev: unless you test how would you know ??
Dev: and just saying that it broke one with a version hence I wont do it
Infra Guy: and im not sure if thats fair for us to deal with implication of upgrading of the major components just cause bash script is not good enough for u
Dev: its pretty bad
Infra Guy: i do agree
Infra TL Guy: Dev, what Infra Guy is saying is that its not possible to upgrade without downtime
Infra Guy: no
Dev: how long a downtime are we looking at ??
Infra Guy: im saying that after this upgrade we will have deal with consequences for long time
Infra Guy-2: No this is not testing the upgrade is the huge effort as we dont have dev resources to handle each job to run
Dev: if your jjb compiles all the yaml without error
Dev: I am not sure what consequences are we talking of
Infra Guy: so you think there will be no consequences, right?
Dev: unless you take the plunge will you know ??
Dev: you have a dev server running at port 9000
Infra Guy: this servers runs nothing
Dev: that is good
Dev: there you can take the risk
Infra Guy: and the fack we have managed to put something onto api doesnt mean it works
Dev: what API ?
Infra Guy: jenkins api
Infra Guy: hmmm
Dev: what have you put on Jenkins API ??
Infra Guy: (
Dev: jjb is a CLI
Infra Guy: ((
Dev: is what I understand
Dev: not a Jenkins API
Infra Guy: (((
Dev: (((((
Infra Guy: jjb build xmls and push them onto api
Infra Guy: and its doent matter
Dev: so you mean to say upgrading a CLI is goig to upgrade your core jenkisn API
Dev: give me a break
Infra Guy: the matter is that even if have managed to build something and put it onto api
Infra Guy: doesnt mean it will work
Dev: the API consumes the xml file and creates a job
Infra Guy: right
Dev: if it confirms to the options which it understands
Dev: then everything will work
Dev: I am actually not getting your point Infra Guy
Infra Guy: i do agree mr Dev
Dev: we are beating around the bush
Infra Guy: just want to be sure that if this upgrade will break something
Infra Guy: we will have a person who will fix it
Dev: that is what CICD is supposed to let me know with valid reasons
Dev: why can't that upgrade be done
Infra Guy: it can be done
Infra Guy: i even have commit in place3 -
Good times: Migrating a Jenkins build pipeline patched together out of groovy, python, bash, awk, perl scripts and God knows what else since I have only scratched the surface so far, from Maven to Gradle while not breaking day-to-day builds, integrations and deployments of features, hotfixes and releases. I'm actually enjoying the challenge but it's taking forever due to several issues:
- Jenkins breaks/hangs randomly because it's Jenkins
- Gradle can't handle sets of version ranges but Maven can
- Maven can't handle Gradle style version ranges
- Gradle doesn't have a concept of parent poms, you need to write a plugin and apply stuff programmatically. But plug-ins being part of the buildscript{} don't fall under depency management rules :clap:
- Meme incompatibility issues of BSD vs GNU versions of CLI tools like sed, grep etc1 -
We have huuuge fuckups today with our Frontend regarding deprecated npm modules.
All of my Frontend colleagues are whining because the Jenkins build is failing.
I looked into it, there were missing dependencys that could not be found anymore.
Frontendcolleagues don’t want to do anything because it’s a „Devop problem“.
Fuck my fucking life. -
Just a reminder that Terraform is insecure by design and if you even THINK about using it to execute CI/CD deployments not built into the cloud (Jenkins, on-prem CI/CD, etc...), then you're a DOUBLE fool. God i hate my infra team sometimes...13
-
fucking mother fucker modem is nt working. fml. and fuck the service provider. its 2330 and I need to configure jenkins for my side project. hiw the fuck will I do this2
-
I almost forgot how much I hate Jenkins. What should be a relatively simple deployment with some straightforward bash scripts turns into 500 lines of "clever" groovy code because devs can't help themselves. Add heinously slow execution times and no good way to test anything locally and I officially want to blow my brains out.8
-
You've tried everything.... Jenkins still corrupts svn checkouts on every build, and hence fails the build....
Solution.... Promote a slave to be a new master, and demote the master to be a slave.... -
don't you just hate, when this happens? translated from Slovak we call this "the system of the falling shit" you know this under "hot potato"
email:
from: marketing coworker
to: senior dev 1
* asks for a lot of stuff, deadline yesterday, high priority, on a site for which the jenkins build is crashing every once in a while, because we are migrating all the time so some folders are already deleted or not created yet and the build config is really strict *
forwarded from: senior dev 1
@senior dev 2
forwarded from: senior dev 2
@senior dev 3
forwarded from: senior dev 3
@junior me
ಠ_ಠ fuck me i guess ¯\_(ツ)_/¯1 -
Upgrading mongodb to 4.0.25 for a heavily used dev environment,
Running the DevOps jenkins job thingy,
Failing miserably,
Asking the DevOps to take a look,
"Did you upgrade to 3.6 before?",
"no",
"Well mongodb EC2s are deleted",
FML1 -
Went through 60 python packages to see which fails installing on the serve. Took hrs as I have no terminal access but just via jenkins pipeline. So "edit/gitpush requirements.txt and wait" many times. Eventually looped them 1 by 1 in shell. By end of day got the list that installs.
Finally sent the whole list....with confidence
-Takes full 10 mins & Fails......
(panic mode starts)
+Changed the sequence = fails, somewhere else
+1 by 1 again = installs.....
+few random without the culprit =works
+again, whole list = fails, somewhere else
Need to sleep, brain's thinking of eagles1 -
Have I been living in a cave? How long has "Gradle Cloud Services" been around? Pros/Cons? Is it the death of Jenkins?1
-
We have this guy at our office that is constantly sending mails complaining about our code. About 10 min. after a commit he's either complaining or come with some condescending "ok" comment.
-
Writing straight up Java in Jenkins pipelines never ceases making me feel like ive done something horrible :)
Dunno if the feeling is at all justified or not.1 -
Questions more then a rant...
I've moved from being a lead on imploring DevOps and Agile practices in a large Telco to now working for a security consultancy... The team I'm with are s*** hot when it comes to SecOps (which is why I changed jobs) and I've been hired to he the automation and working practice expert on the team. Already got some of them learning Ansible which is a great start!
I've got delivery now being pushed to Git and all client work being tracked in Jira and properly documented and collaborated through HipChat and other CI tools on the way....
My question is this... Does anyone have some awesome resources to teach people Git, Jira, Jenkins, etc. quickly without forking or branching out on expensive training? Focus on being a technical but consultative team. Ideally just wanna pull some awesome guides and make. My own commits on them for the team... Please fire a story or epic away!1 -
Getting your automated testing scripts to work every time your Jenkins/Docker container builds for the first time is the best feeling on a Friday
-
Travis CI is good. Yup.
Coveralls is good. Agreed.
Appveyor, codeclimate, Jenkins?
Okay, that’s too much. At this rate, no features are gonna get done. -
Spent a couple of weeks on writing a cronjob which updates a certain value in the application config, and spend the last few months on testing it in different environments to make sure it does not fail in production. Ran the deployment script, and the damn cronjob fails because of ssl certificate on production. fuck me
-
Ah yes back from school, back into trying to get Arquillian to work. After trying to build on Jenkins (just for a test if they fixed some of the Problems) suddenly it wont even build properly, because they removed the datasource that my Arquillian tests were running on. Great. Not only are my tests not working now, but the whole fucking thing won't build and trying to get a datasource into the Arquillian Container is a pain the ass.
I've set it up according to multiple tutorials. But it always tries to read a non existant datasource... Why, why, why the fuck do I have to do this shit. I fucking hate everything related to JBoss. It... never... works. -
!rant
I've finally setup a dedicated Docker box with RancherOS and Rancher... Shipyard looked nice as well (the simplicity like beautiful) but the cloud management with Rancher is amazing!
It took me minutes to install the OS, minutes to install Rancher, then on my phone it took minutes to install Jenkins with swarm support!
I'm loving this! -
What do you hate most about your current CI/CD setup at work?
Mine is that staging and production are released independently. If staging fails, it can still roll out to master. This scares me.8 -
I'm using typescript and run mocha acceptance tests. I was confused as to why my tests were failing on the Jenkins albeit they passed locally just fine.
I couldn't find the error. Just after making a pause, implementing something else, I realized what the problem was:
As I renamed a folder from `fixtures` to `tapes` my test run on the Jenkins suddenly claimed to not find the files in `fixtures`. Yet in my code base there was no occurrence of the string `fixtures` anymore and then it hit me like a brick wall:
I have old transpiled files in my outDir, the `dist` folder on the jenkins! Locally, I make sure to run `git clean -fd` once in a while, so I never was hit by it it locally. Yet my jenkins had really old files in the `dist` folder. And just running `rm dist/* && tsc` fixed the entire ordeal.
Well, JavaScript is so 2012 and typescript is the new shit, yet transpiling the code can leave to some quite strong headaches.1 -
I'm in charge of our Maven based build process. Doing CI with Jenkins. Coworker develops huge multi module project, doesn't take care of hierarchical structures or any other Maven good practices.
Build fails due to several circular dependencies and other ill stuff.
My fault.
Ragemode. -
The timing for this weekly rant is quite perftect, as I have actually just finished rewriting JavaRant! :D I redid a lot of work tried to make it very easy to use, and I think it has improved a lot.
This was also a nice occasion for me to set up Jenkins on my personal server to use that as a CI server (not that it's really necessary, but it is fun).
If you like it, check it out on github: https://github.com/LucaScorpion/...
And feedback/help is of course always welcome! -
I just found out i've wasted month of my life by troubleshooting wrong component.
I was unable to access my application in cluster and suspected networking and port configuration. (custom corporate setup with chaotic documentation did not help to situation)
In the end, it was caused by Jenkins, which failed on building a new container but still showed "build: success" while it deployed May version of container without any changes applied. -
Why are there very little or crappy YouTube channels/videos for developer tools? Does no one want to make videos on how to get started with Jenkins, Gitolite, etc? Is there no market for that?1
-
TL;DR: Embedded software guy needs to create a multi-instance sandbox environment in Jenkins for testing and not sure what good solutions are out there. Looking for suggestions.
So at work, we have these really cool integration tests that validate our system for flight safety. What's not so cool is that due to factors outside of my control, each test has to be run serially and the entire test suite can take many many hours. This is mostly due to a hardware limitation (not enough physical NICs), but there are other SW factors as well.
What I would like to do is somehow be able to wrap up all the resources into a neat little package and then deploy that package into some kind of virtual environment that can be instantiated on a Jenkins job. The NIC issue would be replaced with a virtual one and *theoretically* I should be able to spawn as many instances of this virtual environment as my CPU and RAM can handle. In short, I want to pseudo parallelize our test suite and drive down our testing time. Somehow I would need to be able to control this entire thing from a script of some sort.
Does anyone know of something out there that would satisfy these kinds of requirements? Double internet points if it's open source. -
Just testing the waters here and seeing what I read online has any basis to this:
Jenkins is the WordPress of CI/CD tools
...Discuss5 -
I'm expecting my StackOverflow questiion to get shut down and some mod to want to piss on my corpse ( https://stackoverflow.com/questions... ) so I'll ask this here too. Anyone set up the open source Jenkin in a DR environment? I'd like an Active/active hosting solution but everything I read points to Cloudbee's... Post your answer on SO if you want, I'll vote up whatever looks good, but in case it does get shut down by the assholes with a god complex, please @ me :)5
-
For our current project, we connect to three different OpenVPNs:
Our dev OpenVPN (to get Jenkins/Artifactory)
The ops team devops OpenVPN (to get to environment)
The vendor's VPN for single signon
All of them have different keys and one connects to LDAP and uses a password we can't change. -
Does anyone uses GoCD over Jenkins?
Is it really better or just a nice homepage?
The interface remembers me CircleCI.2 -
When you have to wake up early to run your builds first or you can wait a day for them fixing jenkins no space left on device...2
-
Jenkins, why you be so fucked up? The same pipeline file runs in one folder, but fails at the root of the Jenkins server. It's the same code! Literally, the exact same code, I just moved the job into a different folder.2
-
What is the best approach for Continuous Integration / Continuous Delivery/Deployment? I'm using SVN as code repository and I need to identify the files that goes to Test/QA env. and the ones that goes do Prod env. (by Commit message or something else) via sFTP.
Any help would be appreciated. Already tested Jenkins, GoCD and Jetbrains Teamcity.1 -
Hey Guys!! I need your help. Next week the new company I am working for has a costume party and I am thinking of a funny nerdy costume but all I was able to think of was Jenkins😂
I hope you got better ideas!!8 -
That’s my first hackathon, We where working for 1 full day from 4PM to 6PM next day without having any sleep to give a killer product on integration of multiple applications into one single point (Hard Work)
One team just came chill in the Hackathon went out sleep and made a killer presentation on how to integrate Slack with multiple applications like Jenkins, GutHub and much more to make life simple (Smart Work)
Actually we both lose but their way was implemented in organisation 😝1 -
Is anyone else getting issues with bitbucket begging slow and unresponsive. Just failed two Jenkins jobs because of this.
-
I recoded a REST endpoint that transfers large amounts of data from our db using a streaming response so it doesn't crash the server...
Pretty easy... Mostly just needed someone that knew wtf it was or has a bit of curiosity and asks questions... rather than just keep on doing what everyone else is doing...
Who hasn't seen logs updating in near real time in TeamCity, Jenkins... for the last 5yrs+... No one else ever wondered how it's done?
So yes solving a production issue with old technology and being called a genius... I guess is pretty satisfying? -
Not sure if this is somehow standard but have a new dev process we need to use to deploy a Docker image to an Openshift container.
(Is an container one node/vm or could be many?)
In the Jenkins build it seems the files are copied to in Docker image.
But they aren't copied to the container/OPENSHIFT deployment image. There's something mentioned about config map but not sure how that's related to file copy...10 -
How much money you have to throw at hardware for Jenkins to build projects as fast as they are built locally6
-
Package build fails on Jenkins. I try to investigate locally. Builds fine locally. Managed to convince admin to let me ssh there to debug there in the exactly same environment. Builds there without any issues when triggered manually. I'm missing some little piece of environment from jenkins job or there could be some race somewhere. I really hate those random errors, we really need to get sane build system so I wouldn't need to debug those irreproducible build issues. Aaarrrghh!!!
-
I just setup Jenkins locally for the first time to do some CI/CD for a project using docker. Then I upgraded the container to the latest version of Jenkins.
I am liking it so far but haven’t really setup anything significant yet.
Any of you ranters have experience with Jenkins?
- would you recommend it. Pros/cons?
- what resources did you use to setup and expand your pipelines?
- any experience with Google Cloud Platform and Jenkins.
These are kind of open ended questions to start a discussion on the topic.
Jenkins will be used at least for deploying the front end built in React. I may also use it for deployment if the Golang API but that uses Kubernetes at the moment. -
You finally get the Jenkins configuration correct, then this message appears:
stderr: fatal: unable to access 'https://github.com/someuser/...': Could not resolve host: github.com -
Huh, just created a job in Jenkins to run msbuild over some solutions. The job accepted a parameter called "Configuration" which was just some simple JSON.
Everytime I ran the job, msbuild failed.
Then I realised that the Debug/Release info for a .NET Solution gets put into an environment variable called "Configuration" that msbuild creates and relies on! >.< -
Have you ever stuck between user permissions, docker, Jenkins and Linux?
Running a docker with a particular user that doesn't have permission to folder inside container. user permissions should be same on host and inside container. When I did that container user does have permission of certain file on the host.
Successfully wasted my day on fucking things.
I have to again start with this tomorrow wish me a luck.4 -
What CI CD are you using for work? Ours is a self hosted sub domain jenkins in a VM.
Also, what CI CD is almost required in every job? Jenkins? Thanks!3 -
Guys, about Continuous Integration/Delivery using SVN as repo... What is the best approach? It would be nice if it could trigger the files that should come to prod by commit message or something like that...
Thank you.3 -
Get to work, I'm going to have a really productive day tackling problem X. What do you mean Jenkins decided to corrupt every local SVN checkout? Spent the day getting Jenkins back on its feet and trying to figure out why it hated last night. Tomorrow... I'm going to have a really productive day tackling problem X...
-
Screw you bamboo. Everything would be so much easier with Jenkins but this company already bought the full atlassian stack
-
Tried to pull a Java solution, originally developed on linux, into my windows environment to test a Jenkins job. The build job wouldn't run on my box due to reaching the arbitrary max windows path limit in command prompt..why??7
-
We receive by mail the build report launched by Jenkins so I get It on my smartphone. Bad idea, I make nightmare of "BUILD FAILURE" and endless stack traces..
-
Oh, if yer XML schmeas are as fuked as that DNF cache mess, Git's probly mergin like a drunk hacker—fix it before I Jenkins your pathetic repo ino oblivion!2
-
I just spent 3hours trying to determine why behat could not find context files and tried to find nonexistent one while running it on jenkins.
It turned put that config directory with behat.yml had to be in lowercases rather than starting with uppercase.
It worked on my machine though..
Funny thing is rven after that it failed as php version on jenkins did not have propper extension. Guess I’ll have to get into this docker thing1







































































































































































Top Tags
Weekly Rant
View