
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Biggest hurdle: torn between having boobs and missing an arm. I swear some people are under the assumption the brain is in the arm.
I am fully capable of building your network, resolving your outage due to your faulty code, can even tell you how many users your database can support at once. I don't need arms for that. Nor do my boobs distract me that badly.
"but men are going to make your life so hard" yup. And that's true no matter where i go
"all that typing with one arm can't be good for your back" welp. Find me a job that doesn't require a computer. Or manual labor. If you think typing will fuck me up, that's DEFINITELY out of the equation
"you're too pretty, there's no way this can make sense" dafuq you just say?!?!
"why don't you just stay home on disability, I'm sure you qualify, you wouldn't need to work" I'd rather be a fucking trophy wife if I'm staying at home. Fuck that.
And many more.
Sometimes they're fun. Give me more dumb arguments to counter? ;)55 -
Hi everyone,
We're currently experiencing major issues with the devrant.io domain due to another outage/problem with .io domains themselves. More info here: https://news.ycombinator.com/item/...
The issue is also being reported on twitter.
If you receive a host not found, connection error, etc. connecting to devRant, this is why. We'll keep you updated and in the future we will probably be switching away from .io at least for our API.
Thanks for the patience.20 -
The next person who calls the server disruption/emergency line for something that is NOT related to a server wide issue/outage is going to get a rusty pipe with fucking sambal up their fucking ass.
I am so fucking done with this bullshit.11 -
> be me
> last hour in office
> trying to figure out solution
> figured out a plausible solution
> write the code
> power outage before I compile
¯\_(ツ)_/¯
Well, on the bright side I committed it locally...9 -
Hey everyone - in case it isn't obvious, unfortunately due to the major S3 outage, no images can currently be uploaded :/
Sorry about that.4 -
Well, I was the One that was scolded. Because I basically took over without asking permission to fix a critical outage.
I fixed it within 3 minute, while the person in question have been trying for 2 hours.
He then got very angry and told me infront of everyone that "dont ever help me out".
Said and done. I never helped him ever since, even if he clearly struggled with everything.
He got fired recently due to incompetense6 -
Co-worker: "Should we keep this server up and running?"
Me: "Hmmm…"
C: "Do we have any other uses for it than the dedicated wiki?"
M: "Not really, and maybe it's time to move to the centralised platform Corporate™ introduced. Have we checked if anyone is using the server?"
C: "Good point, let me see…"
C: "… oh it's been down for last two weeks since the power outage."
M: "I think that answers the question. Let's leave it like this for a month more and if no one complains we can announce it dead"3 -
Navy story continued.
And continuing from the arp poisoning and boredom, I started scanning the network...
So I found plenty of WinXP computers, even some Win2k servers (I shit you not, the year was 201X) I decided to play around with merasploit a bit. I mean, this had to be a secure net, right?
Like hell it was.
Among the select douchebags I arp poisoned was a senior officer that had a VERY high idea for himself, and also believed he was tech-savvy. Now that, is a combination that is the red cloth for assholes like me. But I had to be more careful, as news of the network outage leaked, and rumours of "that guy" went amok, but because the whole sysadmin thing was on the shoulders of one guy, none could track it to me in explicit way. Not that i cared, actually, when I am pissed I act with all the subtleness of an atom bomb on steroids.
So, after some scanning and arp poisoning (changing the source MAC address this time) I said...
"Let's try this common exploit, it supposedly shouldn't work, there have been notifications about it, I've read them." Oh boy, was I in for a treat. 12 meterpreter sessions. FUCKING 12. The academy's online printer had no authentication, so I took the liberty of printing a few pages of ASCII jolly rogers (cute stuff, I know, but I was still in ITSec puberty) and decided to fuck around with the other PCs. One thing I found out is that some professors' PCs had the extreme password of 1234. Serious security, that was. Had I known earlier, I could have skipped a TON of pointless memorising...
Anyway, I was running amok the entire network, the sysad never had a chance on that, and he seemed preoccupied with EVERYTHING ELSE besides monitoring the net, like fixing (replacing) the keyboard for the commander's secretary, so...
BTW, most PCs had antivirus, but SO out of date that I didn't even need to encode the payload or do any other trick. An LDAP server was open, and the hashed admin password was the name of his wife. Go figure.
I looked at a WinXP laptop with a weird name, and fired my trusty ms08_067 on it. Passowrd: "aaw". I seriously thought that Ophcrack was broken, but I confirmed it. WTF? I started looking into the files... nothing too suspicious... wait a min, this guy is supposed to work, why his browser is showing porn?
Looking at the ""Deleted"" files (hah!) I fount a TON of documents with "SECRET" in them. Curious...
Decided to download everything, like the asshole I am, and restart his PC, AND to leave him with another desktop wallpaper and a text message. Thinking that he took the hint, I told the sysadmin about the vulnerable PCs and went to class...
In the middle of the class (I think it was anti-air warfare or anti-submarine warfare) the sysad burst through the door shouting "Stop it, that's the second-in-command's PC!".
Stunned silence. Even the professor (who was an officer). God, that was awkward. So, to make things MORE awkward (like the asshole I am) I burned every document to a DVD and the next day I took the sysad and went to the second-in-command of the academy.
Surprisingly he took the whole thing in quite the easygoing fashion. I half-expected court martial or at least a good yelling, but no. Anyway, after our conversation I cornered the sysad and barraged him with some tons of security holes, needed upgrades and settings etc. I still don't know if he managed to patch everything (I left him a detailed report) because, as I've written before, budget constraints in the military are the stuff of nightmares. Still, after that, oddly, most people wouldn't even talk to me.
God, that was a nice period of my life, not having to pretend to be interested about sports and TV shows. It would be almost like a story from highschool (if our highschool had such things as a network back then - yes, I am old).
Your stories?8 -
I'll get to my four words in a sec, but let me set the background first.
This morning, at breakfast, I fired up my trusty laptop only to get a fan failure warning.
Finally, after the three year old is asleep tonight, I'm able to start dismantling the case to get to the fan. I'm hoping it just needs cleaned out.
Hard drive, memory, and keyboard spread out over the kitchen table. I'm not even halfway done.
Guess what? Now I'm one of the lucky 3500 people to have a power outage at 9 pm. Estimated restore time: 2 am.
Sigh.
"All those tiny screws"
And a three year old in the house... 18
18 -
--- GitHub 24-hour outage post mortem ---
As many of you will remember; Github fell over earlier this month and cracked its head on the counter top on the way down. For more or less a full 24 hours the repo-wrangling behemoth had inconsistent data being presented to users, slow response times and failing requests during common user actions such as reporting issues and questioning your career choice in code reviews.
It's been revealed in a post-mortem of the incident (link at the end of the article) that DB replication was the root cause of the chaos after a failing 100G network link was being replaced during routine maintenance. I don't pretend to be a rockstar-ninja-wizard DBA but after speaking with colleagues who went a shade whiter when the term "replication" was used - It's hard to predict where a design decision will bite back and leave you untanging the web of lies and misinformation reported by the databases for weeks if not months after everything's gone a tad sideways.
When the link was yanked out of the east coast DC undergoing maintenance - Github's "Orchestrator" software did exactly what it was meant to do; It hit the "ohshi" button and failed over to another DC that wasn't reporting any issues. The hitch in the master plan was that when connectivity came back up at the east coast DC, Orchestrator was unable to (un)fail-over back to the east coast DC due to each cluster containing data the other didn't have.
At this point it's reasonable to assume that pants were turning funny colours - Monitoring systems across the board started squealing, firing off messages to engineers demanding they rouse from the land of nod and snap back to reality, that was a bit more "on-fire" than usual. A quick call to Orchestrator's API returned a result set that only contained database servers from the west coast - none of the east coast servers had responded.
Come 11pm UTC (about 10 minutes after the initial pant re-colouring) engineers realised they were well and truly backed into a corner, the site was flipped into "Yellow" status and internal mechanisms for deployments were locked out. 5 minutes later an Incident Co-ordinator was dragged from their lair by the status change and almost immediately flipped the site into "Red" status, a move i can only hope was accompanied by all the lights going red and klaxons sounding.
Even more engineers were roused from their slumber to help with the recovery effort, By this point hair was turning grey in real time - The fail-over DB cluster had been processing user data for nearly 40 minutes, every second that passed made the inevitable untangling process exponentially more difficult. Not long after this Github made the call to pause webhooks and Github Pages builds in an attempt to prevent further data loss, causing disruption to those of us using Github as a way of kicking off our deployment processes (myself included, I had to SSH in and run a git pull myself like some kind of savage).
Glossing over several more "And then things were still broken" sections of the post mortem; Clever engineers with their heads screwed on the right way successfully executed what i can only imagine was a large, complex and risky plan to untangle the mess and restore functionality. Github was picked up off the kitchen floor and promptly placed in a comfy chair with a sweet tea to recover. The enormous backlog of webhooks and Pages builds was caught up with and everything was more or less back to normal.
It goes to show that even the best laid plan rarely survives first contact with the enemy, In this case a failing 100G network link somewhere inside an east coast data center.
Link to the post mortem: https://blog.github.com/2018-10-30-...6 -
> *WordPress website gets down Error 500: Cannot establish Connection with database*
> Marketing loses their shit: "We need the website up and working right now"
> *Me being calm *: "Nope, we cannot it's the service provider error, there's nothing we can do"
> *MK.G*: "Alright then, switch to another ISP ASAP"
> *Me, Internal rage, a volcano erupts *: "Umm..so you want to spend more money on another hosting because this one has an outage of 48 hours?"
>*MK.G *: "Yes, because we cannot run Facebook ads, just because website is down"
>*Internal lmao*: "Alright, but by the time you purchase a new service provider and host, the website will be up and running plus since the database is down we cannot migrate"
>*MK.G*: "I don't care, just make it up and working"
>*Me chilling*: "Alright, give me few hours"
> after a few hours the website is working *me being badass even though I didn't do anything*13 -
So apparently the Amazon S3 outage happened because of one setting being wrong in a looooong string of commands issued to shut down just a few servers.
Am I the only Linux user who totally gets how that could happen to just about anyone regardless of how awesomely competent they might be?3 -
Manager: "Pls deploy the changes ASAP."
Me: "Right away."
Me: *creates pull request*
... 5min later ...
GitHub: "Some checks haven't completed yet."
... 45min later ...
GitHub: "Some checks haven't completed yet."
Me: *looks into delay*
CircleCI: "Partial System Outage"
——
(╯°□°)╯︵ ┻━┻2 -
We had a short power outage this morning. 30 min later I got an "urgent" call that someone's "computer" was not working in another branch of our company.
Not one person in that branch could figure this out so after them repeatedly messaging and calling me for around an hour I decided to come over.
I found out that the power wall plug to the monitor has a switch on it which this person accidentally kicked...
I fixed his problem in around 20 seconds. This same employee was one that somehow had his email account previously "hacked" and 8000 phishing emails were sent from his account in 1 hour.
I honestly think it is amazing people like this can even use a computer at all...5 -
!!pointless story
Bug report comes in from a coworker. "Cloudinary uploads aren't working. I can't sign up new customers."
"I'll look into it" I say.
I go to one of our sites, and lo! No Cloudinary image loads. Well that can't be good.
I check out mobile app -- our only customer-facing platform. None of the images load! Multiple "Oops!" snackbars from 500 errors on every screen / after every action.
"None of our Cloudinary images load, even in the mobile app," I report.
Nobody seems to notice, but they're probably busy.
I go to log into the Cloudinary site, and realize I don't have the credentials.
"What are the Cloudinary credentials, @ceo?" I ask.
I'm met with more silence. I use this opportunity to look through the logs, try different URLs/transforms directly. Oddly, everything seems fine except on our site.
I check Slack again, and see nothing's changed, so I set about trying to guess the credentials.
Let's see... the ceo is basically illiterate when it come to tech, so it's probably not his email. It's a startup, and custom emails for things cost money, and haven't been a thing here forever, so it's probably oen of the CTO's email aliases. he likes dots and full names so that narrows it down. Now for the password.... his are always crappy (so they're "easy to remember") and usually have the abbreviated company name in them. He also likes adding numbers, generally two-digit numbers, and has a thing for 7s and 9s. Mix in some caps, spaces, order...
Took me a few minutes, but I managed to figured it out.
"Nevermind, I guessed them." I reported.
After getting into Cloudinary, I couldn't find anything amiss. Everything looked great. No outage warnings, metrics looked fine, images all loaded. Ex-cto didn't revoke payment or cancel the account.
I checked our app; everything started loading -- albeit slowly.
I checked the aforementioned site; after a few minutes, everything loaded there, too.
Not sure what else to do, and with everything appearing to work, I said "Fixed!" and closed the issue.
About 20 minutes later, the original person said "thanks" -- never did hear anything from the ceo. I've heard him chatting away in the other room the entire time.
Regardless, good thing for crappy passwords, eh?15 -
TL;DR: disaster averted!
Story time!
About a year ago, the company I work for merged with another that offered complementary services. As is always the case, both companies had different ways of doing things, and that was true for the keeping of the financial records and history.
As the other company had a much larger financial database, after the merger we moved all the data of both companies on their software.
The said software is closed source, and was deployed on premises on a small server.
Even tho it has a lot of restrictions and missing features, it gets the job done and was stable enough for years.
But here comes the fun part: last week there was a power outage. We had no failsafe, no UPS, no recent backups and of course both the OS and the working database from the server broke.
Everyone was in panic mode, as our whole company needs the software for day to day activity!
Now, don't ask me how, but today we managed to recover all the data, got a new server with 2 RAID HDDs for the working copy of the DB, another pair for backups, and another machine with another dual HDD setup for secondary backups!
We still need a new UPS and another off site backup storage, but for now...disaster averted!
Time for a beer! Or 20...
That is all :)4 -
"Almond, I thought you said the cause of the outage the other week was that our server crashed?"
"The Tomcat server crashed, yeah. Not the physical server." (And you won't give me the time or budget to spin up any kind of redundant one, but that's besides the point...)
"Ok, but I've spoken to ops and they say none of the servers have gone offline in the last month?"
"Yup, the physical server was fine, it was the Tomcat server running on it that crashed."
"...so the server didn't crash?"
"We're mixing terms here. There's two things that can be referred to as the server. One is the physical machine, and one is an application running on it. The physical machine was fine, but
the application running on it crashed."
"What?! It's a very simple question. Did the server crash, or didn't it?!"
🤦♂️13 -
Let's take bets on the root cause of the S3 outage!
I'm guessing a bad deploy of a sever-side Java application with a garbage collection problem.5 -
Story time!
A little over a year ago I was in the hiring process with a new company and countered their initial offer. I was told by the CTO that it was no problem and they would get back to me soon.
A couple days go by and I'm then informed that they're hiring a new IT director and would like me to interview with him as well. It felt kinda lame since I'd already been offered the job but I rolled with it.
When I showed up to the office for an interview I tried to call and let them know I was there and couldn't get a hold of anyone. 30 minutes later I get a call from the CTO saying they couldn't find the new IT director and when they got him to answer the phone he said he had left early and would call me to do a phone interview.
Obviously the whole experience so far has been pretty lame but I stuck with it because I knew the CTO personally. I did the phone interview and quickly realized this dude was a prick, and would be a terrible boss, but I spoke with the CTO again who told me to stick with it and eventually I did get the job.
Fast forward about a month and it's clear the new director is trash. He literally bragged about firing a dude over an accidental outage (wtf!?).
He had the technical experience you'd expect of a junior help desk and his management skills were pretty clearly sub-par.
He was also, for whatever reason, completely unable to communicate with the only woman on our team. When assigning work he would always feel the need to ask if she could 'handle it' rather than just assigning it to her like it's done for everyone else. He was pretty clearly sexist.
The whole team hates this dude by this point but he's somehow managed to woo the executives into thinking he shits gold.
I was helping him set up a Python venv on his machine when I noticed another VPN client installed which certainly piqued my interest. After a bit of digging it was clear he was using company time and company equipment to continue working for his previous employer.
We turned over logs and he was fired the next day. He tried to add me on LinkedIn afterwards and I have never declined something quicker.
Moral of the story is don't be a dickhead.1 -
Quick recap of my last two weeks: 15 year old production server is basically dead, boss has taken over calls and claims credit for "resolving" outages (even though my coworker and I did the work, but ultimately the traffic died down enough to where it wasn't an issue anymore).
I go to a meeting to plan migration to a better server, boss bitches about not getting invited, I tell him I invited myself, and then he lectures about how that's not our job.
Different boss says we're migrating a schema for an application that should have been decommissioned 5+ years ago to use as a baseline. I explain what's going on, he says he understands, and proceeds to tell higher bosses it's perfect because there will be no user impact. OF COURSE THERE'S NO FRICKING IMPACT, YA DUNCE! there are no users!!!!
I merge two email threads together, since they discuss the same thing, but with different insight, and get yelled at, even though they requested it.
The two bosses I like are OOO for the next week, too, so I'm just sitting here hoping I don't say something that'll get me fired or sent to sensitivity training.
I'm just starting my on call rotation and don't know that I can do this. I cry when my phone rings, now, because I experience physical pain with how hard I cringe.
I got yelled at today by a guy because SOMEONE I DON'T KNOW assigned a ticket to him directly, rather than to the proper team (not his team). So I had to look into that, which at least had the benefit of preventing a catastrophic outage to our customers world wide, but no one will know because I don't brag at work; I'm too busy doing my job as well as most of my division/section/larger team, whatever the hell it's called. I saved us probably 25+ hours of continuous troubleshooting call from noticing something tiny that the people "smarter" than me missed.
**edit: sorry for typos; got my nails done yesterday but they feel like they're a mile long and I have to relearn how to type**7 -
Lost half a work day because of an ISP outage. (Testing mailers doesn't work without a connection)
Turns out it was a loose cable on our modem that happened to coincide with the ISP outage elsewhere.
Ugh.1 -
--- UK Mobile carrier O2's data network vanishes like a fart in the wind ---
One of the largest mobile carriers in the UK; O2 has been having all manner of weird and wonderful problems this morning as bleary eyed susbcribers awoke to find their data services unavailable. What makes this particular outage interesting (more so than the annoyingly frequent wobblers some mobile masts have) is that the majority of the UK seems to be affected.
To further compound the hilarity/disaster (depending on which side of the fence you're on), Many smaller independent carriers such as GiffGaff and Tesco Mobile piggy-back off O2's network, meaning they're up the stinky creek without a paddle as well. Formal advice from the gaseous carrier is to reboot your device frequently to force a reconnect attempt, Which we're absolutely sure won't cause any issues at all with millions of devices screaming at the same network when it comes back up.
Issue reports began flooding DownDetector at around 5am (GMT), With PR minions formally acknowledging the issue 2 hours later at 7am (GMT) via the most official channel available - Twitter. After a few recent updates via the grapevine (companies involved seems to be keeping their heads down at the minute) Ericsson has been fingered for pushing out a wonky software update but there's been no official confirmation of this, so pitchforks away please folks.
If you're in need of a giggle while you wait for your 4G goodness to return, You can always hop on an open WiFi network and read the tales of distress the data-less masses are screaming into the void.3 -
Manager: Messages not visible! bug ticket!!!!
Dev: oh fuck, there's an issue with our chat system, not good! _inspects ticket_ oh, it's just a display issue that actually is according to the previous spec, yawn...
Dev: please describe the bug better next time, I though we had a major outage, this is simply a small design issue...
Manager: ...
Dev: ...
I think I'm quitting soon guys. I literally do not get paid enough to deal with these incompetent idiots each day.
Meanwhile:
Management: forget your shitty salary, take one for the team, you get 3% of the shares in the company!!!!
Dev: what fucking shares, you haven't even converted to a corporation yet, THERE ARE NO SHARES
Management: ...
Dev: ...
Oh yeah and they called me at 6:30 PM today: "so i guess you are winding down for the day"
fuck outta here i haven't been working since 5 you fucks
jesus i swear some people need to screw their fucking head on straight, so far gone into the hUsTlE CuLtUrE they don't even know what reality is anymore7 -
# 3 weeks ago
customer informed us that the app will get quite some load since the beginning of July
# this monday
last spare hdd on database's SAN died.
I told everyone another hdd is to follow it very soon eithet whether nothing is done at all or if anyone attempts to touch the san array [cuz that's what redundant raids do...]. No fucks given by anyone, no attempts to have maintenance and planned outage within 24 hrs....
# this morning
another hdd has failed and now 1tb of data is lost. No way to restore backups cuz there is no database to restore them to....
# 20 minutes later I head out to get some popcorn. It's gonna be a fun week!
So... The planned heavy load [and revenue along with it] is not gonna happen... I guess they are gonna ha a week long outage.
That's what happens when you ignore warning shots fired at your face.2 -
South Africa Electricity:
This is after I lost my 7th 3000VA online UPS...
In South Africa we have 240V power most of the time which is great, but then there is scheduled power outages (because our electricity companies cannot "handle the load").
When we have a power outage we have automatic generators which brings everything back up although there is still the 1 minute drop which has weird spikes and odd voltages before switching to the generator (as the generators wait until they are stable)
This has being destroying our equipment, we had a $2000 repair bill 3 TIMES for 3 SEPERATE Xerox Machines that have surge protectors although their circuit board somehow fried.
We have lost 7 3000VA UPSes (3 different brands) and 5 voltage regulators we put to protect the UPSes.
The one UPS that fried just had 2 dead fuses, I decided to replace them (unplugged the batteries to avoid 240V) and when plugging the batteries back in there was a huge spark and flame and the metal and plastic melted onto the board and turned black (the metal pins to connect the battery are non existant now)
I am done with electricity...
P.S. 2 of our generators also got hit by lightning as we are high on a hill and ALL the plastic cable coverings inside the generator were melted16 -
I’ve started the process of setting up the new network at work. We got a 1Gbit fibre connection.
Plan was simple, move all cables from old switch to new switch. I wish it was that easy.
The imbecile of an IT Guy at work has setup everything so complex and unnecessary stupid that I’m baffled.
We got 5 older MacPros, all running MacOS Server, but they only have one service running on them.
Then we got 2x xserve raid where there’s mounted some external NAS enclosures and another mac. Both xserve raid has to be running and connected to the main macpro who’s combining all this to a few different volumes.
Everything got a static public IP (we got a /24 block), even the workstations. Only thing that doesn’t get one ip pr machine is the guest network.
The firewall is basically set to have all ports open, allowing for easy sniffing of what services we’re running.
The “dmz” is just a /29 of our ip range, no firewall rules so the servers in the dmz can access everything in our network.
Back to the xserve, it’s accessible from the outside so employees can work from home, even though no one does it. I asked our IT guy why he hadn’t setup a VPN, his explanation was first that he didn’t manage to set it up, then he said vpn is something hackers use to hide who they are.
I’m baffled by this imbecile of an IT guy, one problem is he only works there 25% of the time because of some health issues. So when one of the NAS enclosures didn’t mount after a power outage, he wasn’t at work, and took the whole day to reply to my messages about logins to the xserve.
I can’t wait till I get my order from fs.com with new patching equipment and tonnes of cables, and once I can merge all storage devices into one large SAN. It’ll be such a good work experience. 7
7 -
You know, the whole AWS outage being caused by a typo while debugging got me thinking... whoever did that is most probably a developer who had a REALLY bad day. Could that person be on DevRant? Because the story of what the rest of that day and week was like for him or her has the chance to be the most epic rant on here ever. Poor guy/gal.3
-
So apparently this guy has the infrastructure for the Linux kernel mailinglist archive sitting under his desk.
And then there was a power outage.
While he's on vacation.
Now, someone has to physically go there to enter a LUKS passphrase to let the system boot again... 🤔😂😂😂
Sometimes I don't understand people. 7
7 -
So, a few years ago I was working at a small state government department. After we has suffered a major development infrastructure outage (another story), I was so outspoken about what a shitty job the infrastructure vendor was doing, the IT Director put me in charge of managing the environment and the vendor, even though I was actually a software architect.
Anyway, a year later, we get a new project manager, and she decides that she needs to bring in a new team of contract developers because she doesn't trust us incumbents.
They develop a new application, but won't use our test team, insisting that their "BA" can do the testing themselves.
Finally it goes into production.
And crashes on Day 1. And keeps crashing.
Its the infrastructure goes out the cry from her office, do something about it!
I check the logs, can find nothing wrong, just this application keeps crashing.
I and another dev ask for the source code so that we can see if we can help find their bug, but we are told in no uncertain terms that there is no bug, they don't need any help, and we must focus on fixing the hardware issue.
After a couple of days of this, she called a meeting, all the PMs, the whole of the other project team, and me and my mate. And she starts laying into us about how we are letting them all down.
We insist that they have a bug, they insist that they can't have a bug because "it's been tested".
This ends up in a shouting match when my mate lost his cool with her.
So, we went back to our desks, got the exe and the pdb files (yes, they had published debug info to production), and reverse engineered it back to C# source, and then started looking through it.
Around midnight, we spotted the bug.
We took it to them the next morning, and it was like "Oh". When we asked how they could have tested it, they said, ah, well, we didn't actually test that function as we didn't think it would be used much....
What happened after that?
Not a happy ending. Six months later the IT Director retires and she gets shoed in as the new IT Director and then starts a bullying campaign against the two of us until we quit.5 -
Internet is fluctuating in our office.
The network team sent out an email of unscheduled outage.
I thought of replying back,
"Have you tried turning it off and on again".1 -
A personal memo to all developers on devRant:
* Assume every external line of code, (including every service you consume) is an unreliable crock of flaming shit. These services can and will fail in the most glorious ways. Write your code to be resilient, and ASSUME FAILURE of dependencies. Even if it's your own team writing the other service.
Heard in a meeting today: "Your team's service outage is going to cause my service to corrupt the database!"
Response I wanted to give: "No, you asshat, my service outage is a normal part of living with microservices. Your app should have been smart enough to recognize the failure."8 -
Third World country: *has power outage because of corrupt government*
Our outsourced devs: Hey sorry boss, we will not be able to work today because there was a power outage. We'll make it up for it during the weekend! We're saving up for a power generator so this doesn't happen again!
Manager: These lazy @#$@ (racial slur) are so lazy and stupid!6 -
Gather around folks, I'll paint you a nice picture based on a true story, back from my sysadmin days. Listen up.
It's about HP and their Solaris 5.4/6 support.
- Yet another Prod Solaris dinosaur crashed
- Connected to console, found a dead system disk; for some reason it was not booting on the remaining redundant disk...
- Logged an HP vendor case. Sev1. SLA for response is 30 minutes, SLA for a fix is <24 hours
- It took them 2 days to respond to our Prod server outage due to failed system disks (responses "we are looking into this" do not count)
- it took another day for them to find an engineer who could attend the server in the DC
- The field engineer came to the DC 4 hours before the agreed time, so he had to wait (DC was 4-5 hours of driving away from HP centre)
- Turns out, he came to the wrong datacentre and was not let in even when the time came
- We had to reschedule for two days later. Prod is still down
- The engg came to the DC on time. He confirmed he had the FRU on him. Looks promising
- He entered the Hall
- He replaced the disk on the Solaris server
- It was the wrong disk he replaced. So now the server is beyond rebuild. It has to be built anew... but only after he comes back and replaces the actually faulty disk.
- He replaced that disk on the wrong Solaris server2 -
Since I already posted images of my desktop setups at work(Mac) and home(Linux), I didn't want to repost this week. So, to keep it at least mildly interesting, here's a shot of my garage networking setup.
Pictured:
Ubiquiti Edgerouter-L
Ubiquiti UAP-AC Lite
Drobo 5N
TP-Link cable modem
A big UPS, so we'll still have wifi during a power outage, since that's apparently important
A couple of older machines I'm working on when I have time
A Philips Hue Bridge
An unremarkable 7-port switch
An Ooma phone device
A shitload of my wife's stuff that she's left there on her way in and out of the house. 6
6 -
Sooooo.. Aws's route53 and ELB outage nuked all our environments. 503 here, 503 there, 5xx everywhere.
Just sitting and picking nose for we've got nothing else to do now.. Who on the fucking earth thought it might be a great idea to centralize the whole fucking internet into 3 companies' hands!?!
How's your day?7 -
911 I would like to report a bruh momento
Their Chrome OS lab is shutting down due to a power outage 2
2 -
Hurricane's fixing to hit.
What does that mean?
Downloading porn and movies for the power outage that's imminent. Priorities are aligned lol5 -
Completely got my localhost and live database confused and dropped the whole live server. And there was a power outage so the last backup is from Friday. Luckily not completely live, but still having a stream of people walking in. Also pretty obvious that they are talking about me especially since there's no other shes in the department.5
-
We had a major core router hardware failure in our LA datacenter today and every one of our services has been down since 6am, including all production servers. We have about 15,000 sites down across our entire platform. Our manager came over and told us to just go home because we need to replace the hardware and the process is expected to take all day, and we can't do any work until then because all the production servers are down. So you could say that it's been a pretty easy Friday so far! I'm headed home to play Spider-Man2
-
Just got a new monitor (HKC NB34C) and connected it to my PC (which didn't have a monitor at the time)
The first thing I see is a green screen of death because of a power outage during a Windows insiders update. 11
11 -
We upgraded to Dyn Managed DNS last month, now we're down with the DDoS attack! If we didn't upgrade from their standard plan, we would be online still 😂1
-
Well today we got to test our system to the extreme and I'm pleased to say it passed. Major power surge followed by a black out. UPS for all networking and servers kicked in without missing a beat and the standby generator outside about 45 seconds later. After explaining to users how to turn on their computer (😑), we were able to get everyone working again in about 5 minutes. Lasted three hours without power from the grid without any client downtime1
-
I really enjoy my old Kindle Touch rather than reading long pdf's on a tablet or desktop. The Kindle is much easier on my eyes plus some of my pdf's are critical documents needed to recover business processes and systems. During a power outage a tablet might only last a couple of days even with backup power supplies, whereas my Kindle is good for at least 2 weeks of strong use.
Ok, to get a pdf on a Kindle is simple - just email the document to your Kindle email address listed in your Amazon –Settings – Digital Content – Devices - Email. It will be <<something>>@kindle.com.
But there is a major usability problem reading pdf's on a Kindle. The font size is super tiny and you do not have font control as you do with a .MOBI (Kindle) file. You can enlarge the document but the formatting will be off the small Kindle screen. Many people just advise to not read pdf's on a Kindle. devRanters never give up and fortunately there are some really cool solutions to make pdf's verrrrry readable and enjoyable on a Kindle
There are a few cloud pdf- to-.MOBI conversion solutions but I had no intention of using a third party site my security sensitive business content. Also, in my testing of sample pdf's the formatting of the .MOBI file was good but certainly not great.
So here are a couple option I discovered that I find useful:
Solution 1) Very easy. Simply email the pdf file to your Kindle and put 'convert' in the subject line. Amazon will convert the pdf to .MOBI and queue it up to synch the next time you are on wireless. The final e-book .MOBI version of the pdf is readable and has all of the .MOBI options available to you including the ability for you to resize fonts and maintain document flow to properly fit the Kindle screen. Unfortunately, for my requirements it did not measure-up to Solution 2 below which I found much more powerful.
Solution 2) Very Powerful. This solution takes under a minute to convert a pdf to .MOBI and the small effort provides incredible benefits to fine tune the final .MOBI book. You can even brand it with your company information and add custom search tags. In addition, it can be used for many additional input and output files including ePub which is used by many other e-reader devices including The Nook.
The free product I use is Calibre. Lots of options and fine control over documents. I download it from calibre-ebook.com. Nice UI. Very easy to import various types of documents and output to many other types of formats such as .MOBI, ePub, DocX, RTF, Zip and many more. It is a very powerful program. I played with various Calibre options and emailed the formatted .MOBI files to my Kindle. The new files automatically synched to the Kindle when I was wireless in seconds. Calibre did a great job!!
The formatting was 99.5% perfect for the great majority of pdf’s I converted and now happily read on my Kindle. Calibre even has a built-in heuristic option you can try that enables it to figure out how to improve the formatting of the raw pdf. By default it is not enabled. A few of the wider tables in my business continuity plans I have to scroll on the limited Kindle screen but I was able to minimize that by sizing the fonts and controlling the source document parameters.
Now any pdf or other types of documents can be enjoyed on a light, cheap, super power efficient e-reader. Let me know if this info helped you in any way. 4
4 -
TL;DR: OMFG! Push the button already!
I've been away on paternity leave for quite some time now. Today is my first day at work since the end of July.
Just a couple of days after my paternity leave started, I was contacted by one of the managers because a tracking and analytics service I had made some months earlier had halted.
Now, I did warn them that the project was fragile and was running of an old box in my office. So they shouldn't be surprized if it came to a halt every now and then.
Well, so being on my paternity leave and all I didn't want to spend time fixing it. I had a child to look after. So I told the manager that the box probably just had shut down. I think there was a power outage the day before, so I probably thought it was the cause. So he probably just had to turn it back on. I also told him the admin u/p in case he needed to restart some services.
Today, the CEO enters my office telling me to get that thing fixed. Because that manager apparently couldn't find the power button.4 -
I accidentally started a reindex on a collection that had 14 million records in the middle of the day. Caused an outage in a major portion of our applications for about 3 hours. Worst thing was that once I pressed enter, I realized that it was for the production database, and not the staging database like I intended. I immediately went to go tell the dev ops lead, and he basically said, "whelp, let's just sit back and watch the world burn. Not much we can do about it"1
-
I'm going on vacation next week, and all I need to do before then is finish up my three tickets. Two of them are done save a code review comment that amounts to combining two migrations -- 30 seconds of work. The other amounts to some research, then including some new images and passing it off to QA.
I finish the migrations, and run the fast migration script -- should take 10 minutes. I come back half an hour later, and it's sitting there, frozen. Whatever; I'll kill it and start it again. Failure: database doesn't exist. whatever, `mysql` `create database misery;` rerun. Frozen. FINE. I'll do the proper, longer script. Recreate the db, run the script.... STILL GODDAMN FREEZING.
WHATEVER.
Research time.
I switch branches, follow the code, and look for any reference to the images, asset directory, anything. There are none. I analyze the data we're sending to the third party (Apple); no references there either, yet they appear on-device. I scour the code for references for hours; none except for one ref in google-specific code. I grep every file in the entire codebase for any reference (another half hour) and find only that one ref. I give up. It works, somehow, and the how doesn't matter. I can just replace the images and all should be well. If it isn't, it will be super obvious during QA.
So... I'll just bug product for the new images, add them, and push. No need to run specs if all that's changed is some assets. I ask the lead product goon, and .... Slack shits the bed. The outage lasts for two hours and change.
Meanwhile, I'm still trying to run db migrations. shit keeps hanging.
Slack eventually comes back, and ... Mr. Product is long gone. fine, it's late, and I can't blame him for leaving for the night. I'll just do it tomorrow.
I make a drink. and another.
hard horchata is amazing. Sheelin white chocolate is amazing. Rum and Kahlua and milk is kind of amazing too. I'm on an alcoholic milk kick; sue me.
I randomly decide to switch branches and start the migration script again, because why not? I'm not doing anything else anyway. and while I'm at it, I randomly Slack again.
Hey, Product dude messaged me. He's totally confused as to what i want, and says "All I created was {exact thing i fucking asked for}". sfjaskfj. He asks for the current images so he can "noodle" on it and ofc realize that they're the same fucking things, and that all he needs to provide is the new "hero" banner. Just like I asked him for. whatever. I comply and send him the archive. he's offline for the night, and won't have the images "compiled" until tomorrow anyway. Back to drinking.
But before then, what about that migration I started? I check on it. it's fucking frozen. Because of course it fucking is.
I HAD FIFTEEN MINUTES OF FUCKING WORK TODAY, AND I WOULD BE DONE FOR NEARLY THREE FUCKING WEEKS.
UGH!6 -
A few days ago Aruba Cloud terminated my VPS's without notice (shortly after my previous rant about email spam). The reason behind it is rather mundane - while slightly tipsy I wanted to send some traffic back to those Chinese smtp-shop assholes.
Around half an hour later I found that e1.nixmagic.com had lost its network link. I logged into the admin panel at Aruba and connected to the recovery console. In the kernel log there was a mention of the main network link being unresponsive. Apparently Aruba Cloud's automated systems had cut it off.
Shortly afterwards I got an email about the suspension, requested that I get back to them within 72 hours.. despite the email being from a noreply address. Big brain right there.
Now one server wasn't yet a reason to consider this a major outage. I did have 3 edge nodes, all of which had equal duties and importance in the network. However an hour later I found that Aruba had also shut down the other 2 instances, despite those doing nothing wrong. Another hour later I found my account limited, unable to login to the admin panel. Oh and did I mention that for anything in that admin panel, you have to login to the customer area first? And that the account ID used to login there is more secure than the password? Yeah their password security is that good. Normally my passwords would be 64 random characters.. not there.
So with all my servers now gone, I immediately considered it an emergency. Aruba's employees had already left the office, and wouldn't get back to me until the next day (on-call be damned I guess?). So I had to immediately pull an all-nighter and deploy new servers elsewhere and move my DNS records to those ASAP. For that I chose Hetzner.
Now at Hetzner I was actually very pleasantly surprised at just how clean the interface was, how it puts the project front and center in everything, and just tells you "this is what this is and what it does", nothing else. Despite being a sysadmin myself, I find the hosting part of it insignificant. The project - the application that is to be hosted - that's what's important. Administration of a datacenter on the other hand is background stuff. Aruba's interface is very cluttered, on Hetzner it's super clean. Night and day difference.
Oh and the specs are better for the same price, the password security is actually decent, and the servers are already up despite me not having paid for anything yet. That's incredible if you ask me.. they actually trust a new customer to pay the bills afterwards. How about you Aruba Cloud? Oh yeah.. too much to ask for right. Even the network isn't something you can trust a long-time customer of yours with.
So everything has been set up again now, and there are some things I would like to stress about hosting providers.
You don't own the hardware. While you do have root access, you don't have hardware access at all. Remember that therefore you can't store anything on it that you can't afford to lose, have stolen, or otherwise compromised. This is something I kept in mind when I made my servers. The edge nodes do nothing but reverse proxying the services from my LXC containers at home. Therefore the edge nodes could go down, while the worker nodes still kept running. All that was necessary was a new set of reverse proxies. On the other hand, if e.g. my Gitea server were to be hosted directly on those VPS's, losing that would've been devastating. All my configs, projects, mirrors and shit are hosted there.
Also remember that your hosting provider can terminate you at any time, for any reason. Server redundancy is not enough. If you can afford multiple redundant servers, get them at different hosting providers. I've looked at Aruba Cloud's Terms of Use and this is indeed something they were legally allowed to do. Any reason, any time, no notice. They covered all their bases. Make sure you do too, and hope that you'll never need it.
Oh, right - this is a rant - Aruba Cloud you are a bunch of assholes. Kindly take a 1Gbps DDoS attack up your ass in exchange for that termination without notice, will you?4 -
Dear router
It was nice having you in my house, but it's come to the point where our ways part. I must go on and you must be recycled. You've served me well all those 7 years, my friend.
It's not me, it's you. You've grown old and unreliable. Your capacitors must have dried out and can no longer serve reliable wifi connections. I keep on getting lost ICMP packets and connection outages altogether. While these things could happen to any router, definitely not every router has a 13-16 second long wifi outage every minute. I cannot have 2 peoples' work depend on a wifi connection where a ping to a LAN IP takes 58204ms. I just.. can't. You've become a liability to my family.
I'm pissed, because I cannot afford video calls with my colleagues.
I'm pissed, because my wife spends good 5 minutes every call asking "can you hear me? how about now?" and repeating herself over and over.
I'm pissed, because I can no longer watch Netflix or listen to YT Music uninterrupted by network outages.
I'm pissed, because my Cinnamon plugins freeze my UI, waiting for network response
But most of all I'm pissed, because I was disconnected from BeatSaber multiplayer server when I scored a Full Combo in Expert "Camellia: Ghost" - right before I got a chance to see my score.
I gave you 2 second chances by factory-resetting you. I admit you got better. And then got back to terrible again.
I can no longer rely on you. It's time to say our goodbies and part our ways.
P.S. as a proof of your unreliability I'm attaching outputs of ping to a LAN IP and pingloss to the same IP (pingloss: https://gitlab.com/-/snippets/...)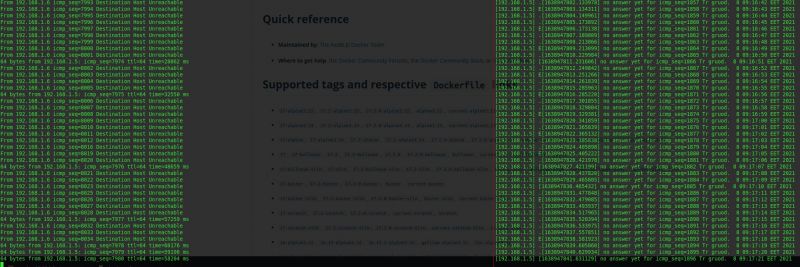 3
3 -
Had an internet/network outage and the web site started logging thousands of errors and I see they purposely created a custom exception class just to avoid/get around our standard logging+data gathering (on SqlExceptions, we gather+log all the necessary details to Splunk so our DBAs can troubleshoot the problem).
If we didn't already know what the problem was, WTF would anyone do with 'There was a SQL exception, Query'? OK, what was the exception? A timeout? A syntax error? Value out of range? What was the target server? Which database? Our web developers live in a different world. I don't understand em. 1
1 -
So a server goes down and being the only person who can recover it, I get started, whilst doing this the boys sits right next to me (6 inches) and starts asking what caused the problem instead of letting me get on and fix it, then complains the outage was too long.
-
Most painful code error you've made?
More than I probably care to count.
One in particular where I was asked to integrate our code and converted the wrong value..ex
The correct code was supposed to be ...
var serviceBusMessage = new Message() {ID = dto.InvoiceId ...}
but I wrote ..
var serviceBusMessage = new Message() {ID = dto.OrderId ...}
At the time of the message bus event, the dto.OrderId is zero (it's set after a successful credit card transaction in another process)
Because of a 'true up' job that occurs at EOD, the issue went unnoticed for weeks. One day the credit card system went down and thousands of invoices needed to be re-processed, but seemed to be 'stuck', and 'John' was tasked to investigate, found the issue, and traced back to the code changes.
John: "There is a bug in the event bus, looks like you used the wrong key and all the keys are zero."
Me: "Oh crap, I made that change weeks ago. No one noticed?"
John: "Nah, its not a big deal. The true-up job cleans up anything we missed and in the rare event the credit card system goes down, like now. No worries, I can fix the data and the code."
<about an hour later I'm called into a meeting>
Mgr1: "We're following up on the credit card outage earlier. You made the code changes that prevented the cards from reprocessing?"
Me: "Yes, it was my screw up."
Mgr1: "Why wasn't there a code review? It should have caught this mistake."
Mgr2: "All code that is deployed is reviewed. 'Tom' performed the review."
Mgr1: "Tom, why didn't you catch that mistake."
Tom: "I don't know, that code is over 5 years old written by someone else. I assumed it was correct."
Mgr1: "Aren't there unit tests? Integration tests?"
Tom: "Oh yea, and passed them all. In the scenario, the original developers probably never thought the wrong ID would be passed."
Mgr1: "What are you going to do so this never happens again?"
Tom: "Its an easy addition to the tests. Should only take 5 minutes."
Mgr1: "No, what are *you* going to do so this never happens again?"
Me: "It was my mistake, I need to do a better job in paying attention. I knew what value was supposed to passed, but I screwed up."
Mgr2: "No harm no foul. We didn't lose any money and no customer was negativity affected. Credit card system may go down once, or twice a year? Nothing to lose sleep over. Thanks guys."
A week later Mgr1 fires Tom.
I feel/felt like a total d-bag.
Talking to 'John' later about it, turns out Tom's attention to detail and 'passion' was lacking in other areas. Understandable since he has 2 kids + one with special-needs, and in the middle of a divorce, taking most/all of his vacation+sick time (which 'Mgr1' dislikes people taking more than a few days off, that's another story) and 'Mgr1' didn't like Tom's lack of work ethic (felt he needed to leave his problems at home). The outage and the 'lack of due diligence' was the last straw.1 -
Just got to work and we have no power. Maybe hand writing code in university will finally come in handy. Lol not. :)
-
Can you rant about yourself?
I was reading about the AWS outage, with little to no interest. I didn't know what it was and thus figured it wouldn't affect me.
Some time goes by and I come up with this 300++ vote post. I'm witty, I'm smart, but when I want to upload a photo it doesn't work.
Must be the app right? I restart, nope nothing. Whatever..
Sometime later I have a dashing new photo for tinder. Surely to give me all the matches. Nope, can't upload it.
Must be my phone or Internet then.
Restart everything, nothing is working. Complete madness, no devRant upvotes and I'm still single.
I surrender, give up. Which is one of the worst things to do for me as a dev.
Today. Which is the cherry on the cake. I finally see my connection to the incident. I feel stupid and annoyed by myself.
God dammit Julian, pay attention.
</rant>2 -
The company I work for used to be hosted on 3dcart. One day the site went down and their support couldn't tell us why. After over 24 hours of downtime they restored service but left 5 days of all records and customizations across the entire store, from the DB to the damn templates. Their support apologized for the outage blaming the disaster on a combination of hard disk failure and a bad update to their backup script. They were not willing to assist us in any way. We were forced to manually enter 5 days of orders (which gave them new order numbers and caused more problems), products and template changes, with order data coming from an internal email which was luckily CC'd on the order confirmation email. Thank God for whoever setup that CC, it saved our asses. In the end it cost our company thousands of dollars and 3dcart never composited us in any way.2
-
I think I’m going to lose my mind. This stupid website I’m working on keeps going down and at the worst times possible. Nothing we do seems to help. I’m again awakened in the middle of the night to attend to it and still have no good answers why. My anxiety is through the roof because I can’t get back to sleep after tonight’s outage. The client is beyond pissed even though a ton of problems would be solved if they would just get off of some legacy software and onto something more modern. But they insisted it be this way and the budget is already blown and then some even if they changed their minds. If it’s going to be that I continue losing so much sleep and sanity, I may just have to quit this job. I hate the thought of that because I always want to see things through to a happy conclusion. And I like my teammates and don’t want to let them down. But I’m too old for that kind of no-sleep development lifestyle now. Nobody’s shitty website is worth my physical and mental health.3
-
Over 67,000 people are affected by a major power outage in my city right now. I wonder how many servers are shutting down :(2
-
Most unusual place I've coded would probably at a bar while utterly wasted. I fixed a production outage and even got on the phone with tier 1 support when they reported the issue.4
-
My reaction after analysing the code responsible for the latest outage...
The week started great *sigh*
-
Bad: Delete your production database
Good: Have a backup
Bad: Can't reimport it because your backup procedure uses scheme that are no longer supported for import by your cloud provider
Good: Backup are plaintext and somehow easy to parse
Bad: Spending the rest of the day writing scripts to reinsert everything.
End of the story: everything is up and running, 8hours of efforts1 -
Join's bridge: "hey man, something is wrong with your DB. our app can't connect in any environment, it started after our code release last night"
"Every other app connecting is working as expected, could you rollback your release?"
"nah, that can't be it. we validated it works"
"Then why am i on an outage bridge? call me if it's still broken after you rollback"1 -
My morning so far:
Walk out the door.
Miss bus I was supposed to have, no big deal I'll just wait for the next one (should be just 15 mins).
Next bus is 10 minutes late, seriously?
Get to the train station just to see my train doesn't go because of an outage. Screw this I'll work from home.
So how's your day going?6 -
It all started with an undelivereable e-mail.
New manager (soon-to-be boss) walks into admin guy's office and complains about an e-mail he sent to a customer being rejected by the recipient's mail server. I can hear parts of the conversation from my office across the floor.
Recipient uses the spamcop.net blacklist and our mail was rejected since it came from an IP address known to be sending mails to their spamtrap.
Admin guy wants to verify the claim by trying to find out our static public IPv4 address, to compare it to the blacklisted one from the notification.
For half an hour boss and him are trying to find the correct login credentials for the telco's customer-self-care web interface.
Eventually they call telco's support to get new credentials, it turned out during the VoIP migration about six months ago we got new credentials that were apparently not noted anywhere.
Eventually admin guy can log in, and wonders why he can't see any static IP address listed there, calls support again. Turns out we were not even using a static IP address anymore since the VoIP change. Now it's not like we would be hosting any services that need to be publicly accessible, nor would all users send their e-mail via a local server (at least my machine is already configured to talk directly to the telco's smtp, but this was supposedly different in the good ol' days, so I'm not sure whether it still applies to some users).
In any case, the e-mail issue seems completely forgotten by now: Admin guy wants his static ip address back, negotiates with telco support.
The change will require new PPPoE credentials for the VDSL line, he apparently received them over the phone(?) and should update them in the CPE after they had disabled the login for the dynamic address. Obviously something went wrong, admin guy meanwhile having to use his private phone to call support, claims the credentials would be reverted immediately when he changed them in the CPE Web UI.
Now I'm not exactly sure why, there's two scenarios I could imagine:
- Maybe telco would use TR-069/CWMP to remotely provision the credentials which are not updated in their system, thus overwriting CPE to the old ones and don't allow for manual changes, or
- Maybe just a browser issue. The CPE's login page is not even rendered correctly in my browser, but then again I'm the only one at the company using Firefox Private Mode with Ghostery, so it can't be reproduced on another machine. At least viewing the login/status page works with IE11 though, no idea how badly-written the config stuff itself might be.
Many hours pass, I enjoy not being annoyed by incoming phone calls for the rest of the day. Boss is slightly less happy, no internet and no incoming calls.
Next morning, windows would ask me to classify this new network as public/work/private - apparently someone tried factory-resetting the CPE. Or did they even get a replacement!? Still no internet though.
Hours later, everything finally back to normal, no idea what exactly happened - but we have our old static IPv4 address back, still wondering what we need it for.
Oh, and the blacklisted IP address was just the telco's mail server, of course. They end up on the spamcop list every once in a while.
tl;dr: if you're running a business in Germany that needs e-mail, just don't send it via the big magenta monopoly - you would end up sharing the same mail servers with tons of small businesses that might not employ the most qualified people for securing their stuff, so they will naturally be pwned and abused for spam every once in a while, having your mailservers blacklisted.
I'm waiting for the day when the next e-mail will be blocked and manager / boss eventually wonder how the 24-hours-outage did not even fix aynything in the end... -
What was supposed to be a simple HDD to SSD upgrade for my brother ended up taking 3 fucking days.
His computer's idle temp was fucking 90c because of fucking YEARS worth of dust preventing fans from breathing, one of them was even dead so I had to go to best buy to get a new one.
Had a power outage happen in the middle of cleaning the damn dust out before replacing the bad fan. It took close to 24 hours for it to come back, and I just didn't bother until the day after cause fuck that.
When I go back to it, I finish cleaning the dust, clone the old HDD to the new SSD, do the swap out, replace the thermal paste on CPU cause why the fuck not at this point. Then turn it on to test, yeah from 90c down to 20c : |
Yeah... so I charged him for the new fan, and the hour-ish it took me to clean the damn dust and replace the fan... (drive was agreed to be done for free as a favor) Yeah not really worth charging for but I was pissed and that was the 'nicest' way I could show how annoyed I was with him not properly caring for the PC. Like honestly 90 degrees celsius. I refuse to believe he didn't notice impacted performance in his games 7
7 -
--- s3-r-w.us-west-2.amazonaws.com ping statistics ---
44 packets transmitted, 16 received, 63,6364% packet loss, time 43544ms
rtt min/avg/max/mdev = 258.995/280.765/377.149/37.359 ms
Sounds like a good day to grab a ball and go outside.4 -
Thoughts on forced emergency support?
I am with a company I generally like a lot but there are some things I generally despise about it. Like forced emergency support.
I am not good at it, I don't claim to be.. I generally struggle with anxiety, stress and depression, I specifically avoid roles that require on-call service .. I'm a senior level software engineer.
I find it very frustrating to be expected to be on-call from 7-7 in support of infrastructure I did not architect, did not code and basically know nothing about. They provided me with a ten minute discussion about ops genie and where to find internal support articles for my training and that's about it.
Last night I received an ops genie alarm and acked it as I was instructed to do, I went around the system looking for the alarm cause and basically had no idea what to do except watch our metrics graphing praying there wouldn't be an outage. Fortunately the alarm was for our load balancer scaling operation, it was taking a bit longer than usual ... Sigh of relief. Stay up til 6am and fall asleep..
Wake up to a few messages from various people asking why I didn't do this and that and it took me every inkling of my being to remain cordial and polite but I really just wanted to scream and say a bunch of shit that would probably get me fired.
What the actual fuck?
Why expect someone that has no god damn clue what they are doing to do something like this? Fuckin shit training and no leadership to mentor me and help me get better at this role, no shadowing, no regiment ..
#confused and #annoyed
Thoughts? Am I a bitch? Is it unreasonable for me to expect my job duties stay in line with what I'm actually good at!?
Thanks.12 -
The biggest weakness of every programmer is power outage...
Can't do anything, even the windows are powered... So hot right now.4 -
So, we've been on Deutsche Telekom for about 9 months. Shitty connection in the countryside but literally not one outage.
For the last 6 weeks our internet has been dropping out with no obvious cause.
Just this week we start getting calls if we'd like to upgrade to a package with LTE...
I'm finding the coincidence just a little too convenient.1 -
I help maintain software that services thousands of users across millions of dollars of infrastructure.
My resolve is stronger than steel during a production outage.
Plex goes down for 1 minute at home and my toddler loses it, and I'm a fucking wreck.
Wtf is wrong with me?!4 -
when you get ready to sit down and eat a slice of pizza and get a call about a system outage...at least it's the weekend.2
-
CEO is blaming a frontend bug for a backend outage. The server simply did not scale with new active clients ))))))1
-
The best thing with a power outage in an apartment complex is watching everybody's wifi turn back on.
-
I'm Programmer/Analyst in one of the hgh ranking BPO company here at Philippines.
I'm currently on a project, I'm on a team who's managing machines parts. The project is CATERPILLAR.
The biggest challenge here is if there is a outage on the system, the number of Severity 1 issues keeps coming like there's no tomorrow. And there's only 5 of us on Tier 2 which is managing this abends, errors, bugs in the system.
Is there a way on preventing this outage/connection error. Like HELLO IT IS A BIG COMPANY !!! HOW THE HELL THEY CAN'T EVEN MANAGE THEIR CONNECTION!!!!2 -
Discord...
Okay, I have a lot to rant about discord, but today, exceptionally, to the point.
I have my dedicated server. It has uptime last 3 years better than 99,99% (was down 15ish minutes for maintainance and RAM upgrade and like 10 minutes down becouse hoster's generators failed to trigger when there was outage)
This year it was up 24/7/365.
Why am I saying it?
Well, my TS3 server is up 100% of time this year. Yet still everyone moves to discord and suffers brutal audio quality and audio lags, and outages like right now. Its not first time this year and recently discord was acting up before. Today they scored bigger downtime than my dedi server (thats not redundant, not distributed nor any fancy "uptime helpers") last 3 years.
Why the fuck people prefer discord to ts3 other that it allows to upload images more conviniently? Okay, it looks nicer, and is like 10 times heavier on machine, but other than that? Its beyond me.
E: fix typo
E2: fix typo27 -
Ugh power's out.
Luckily it's pretty warm out so we're not suffering. I'd normally have a fire going but my fireplace is out of order.
I hauled in my portable generator in the hopes that if I was well prepared the power would come back on and it would have been wasted effort but I may end up running it later to cool down the refrigerator and maybe charge a few batteries.
Hopefully I have power by morning or I'll have a hard time getting our services deployed...3 -
TL;DR - (almost) childhood trauma due to Wesrern Digital crap products lead to lot of data loss and a plege to not trust or purchase their products for the rest of my life.
....
So, I got my first ever Wester Digital 2TB Mybook, back when 2TB was a really big thing. While in the midst of moving (not copying) a LOT of data to it, the damn disk just.. died. There was no fall, no power outage, no damage, it just stopped working. I was out of words and out of options. Tried yanking out the disk and connecting it directly to a system, but no luck because it looks like it's the HDD mobo that died.
Also stupid young me did not realise back then that, even if a "moved" the data, the original data is still most likely in their original location, and so, never bothered a recovery.
Lots of good stuff lost that day.
And as with a lot of you, my disaster recovery system kicked up 10 fold. Now I got redundant local and cloud backup copies of all critical and otherwise unattainable data.
As you may have guessed, I never bought another Wester Digital product ever again. My internal HDDs are Segate, and external is a suprisingly long lived Toshiba Canvio.6 -
What happens when it takes too long for the office manager to get a new UPC, power outage fries your solid state drive, and you didn't put into bitbucket because credentials where not yet provided.
... Still feel some guilt 😷😷😷😷
And tremendous wrist pain as punishment....Faaack. 1
1 -
We just had a server outage this morning and my colleague was heading to the office. He was already in a meeting on his phone and got stopped by the police for calling while driving.
He got a fine, lost his driving license for 2 weeks and has to go police court for it. That's an expensive server outage for him6 -
Managers decided that the support contract with one of our most important third party servers is not worth the money.
Take a guess which server caused an outage for all customers twice already :D1 -
So I rush to job just to find a power outage on the building , don't know if I should be happy to have "nothing" to do or be sad cause I have a lot to do but can't 😓
-
the current power outage is an additional reminder why i will always decide for a notebook. no internet though, so that is the ending for my spare programming time :(
-
Worked from 8am to 23pm today. A massive power outage yesterday messed up my schedule. Still have a lot to do tomorrow. Going to sleep now. Stay strong, everyone. Weekend is coming.
-
I hate power outages. It just went out for all of 5 seconds, but it was long enough to shut down my computer. Fortunately Android studio probably caught all but the last couple seconds of my changes but it's still annoying.1
-
If it hasn't already one day this app is going to be the reason for a global systems outage. I should be working but for some reason every 5 minutes I find my self back here [*scrolling away*]...
-
Okay, THAT was trippy.
Soo.. I slowly srart feeling uncomfortable. It's that feeling when you want to move your body to make it go away. Stretch an arm, move a leg or smth... Alright, no biggie - let's move something. But then my focus is overwhelmed by darkness. Hmm... I must be asleep. There's some soothing humming noise in the background. And that feeling's still there. Aaaahh, the numbness is now going away - I must've moved smth! Good job! Drowning back into sleep now. It's ssooo ssweet...
*outage*
*notions of awareness*
huh? What's that? Oh, right, I need to move again. That humming sound is so relaxing.. I'll move smth to change that status quo. There, much better now. Let's keep the eyes closed and drift back to sleep. It's so dark though...
*outage*
*notions of awareness*
ahh, that feeling again. Come on, I've moved like 4 times already. Well alright, alright, it's better to move that open my eyes or roll over.
Wait...
I can't roll over.
I can't even move my hands. Fuck, must be that sleep paralysis kicking in again. No biggie, it'll wear off if I stay aware long enoug........
*outage*
*...?...*
...nough. What? Did I nod off? That's weird. Meeh, nvm. Why is it so dark though... Okay, let's try to open the eyes. *attempts going on for ~a minute*. No luck. That humming sound, so soothing...
I feel some clothing on my - must be the blanket. So warm.. Nice.I'm feeling - prolly the paralysis is wearing off! Good. A few more minutes and I'll be free to roll over
let's try the eyes once again. Hhhrhrhhh! Nope, not working. Wait, what's that? I turned my body! But somehow...Weirdly. Too easy. There, I did it again! Why is it so easy and I am still feeling paralysed...? Wtf is going on...?
That humming. What IS it..?
Wait! My eyes opened! It's pitch dark in here. Why...? Usually there's at least *some* light in the room. Am I still asleep? Naah, that's not it.. I'm turning my body again. Why did I do that? Wtf is happening?
That humming sound is getting louder and louder, taking all of my attention now.
What is it I'm feeling with my feet? It's hard. And cold.
Wait... AM I STANDING??? What the fuck?!?
Why am i standing??? And that sound - that's... That's... A vent fan in my bathroom!!! Am I standing asleep in my bathroom...? In the middle of the night...? Facing the mirror...? With the lights off....?
WHAT THE FUCK DID JUST HAPPEN?!?!?
HOW THE FUCK DID I GET THERE?!?!?
How long have I been here...?
I HAVE QUESTIONS!!
Fuck it, I'm tired. Time to go to bed. It'll be one mindfuck of a storry tomorrow though...5 -
Fucking ISP... Why even bother informing their customers that the internet will be down while there is planned electricity outage on the other side of the city. Cunts.
-
power outage
I wonder if I post every time how many it will be
especially with green power political stuff going on these days this could be a funny bingo game5 -
IT again: Spoke too soon about a happy server farm after Christmas... Had a SEV1 complete outage for the whole morning. *facepalm*2
-
My department never has real pressure like real outside deadlines. Except for this project.
Now guess what happened during the final hours of the project:
Fuckin circleCI goes into "degraded performance" (last time it was "partial outage").
I feel like calling my friends Johnny Walker and Jack Daniels over for some late night work. :P1 -
Today has been a weird day. AWS us-east-1 region has been having huge issues for hours now, with the console and multiple services down or erroring out. My day has been an odd mix of twiddling my thumbs with nothing to do and trying to calm down angry people who are also twiddling their thumbs with nothing to do.
I'm tempted to just log off Slack and leave an auto-reply of "Can't fix it, no workaround, leave me alone" so I can go back to bed.4 -
Suffering from our first service outage since I've been at my new job.
Guess when it happened? While we have TOO MANY projects going on.
When you have too many pots on the stove, you're bound to forget the smallest, most crucial detail. -
Oh what to do, what to do when you’re stuck with a power outage that could last the entire night.14
-
npm waited for me to `rm -rf node_modules` and decided to experience an outage a MINUTE afterwards.1
-
The CloudStrike outage in my company started by the nuking of the main branch's ERP.
Then the sales platform went down, and the CRM.
Soon the freaking office suite got BSOD'd.
Enjoying the impromptu holiday here. Until the lights go off or something.2 -
Back when I was a freshman in high school a friend of mine put an emulator on the shared drive, so we could play NES games while in the computer lab. Didn't know better/didn't care. One day I get pulled out of class and walked into the computer guys office. In there is also the principal of the school and the Chief of police.
The computer guy tells me there was an issue last week that caused the school server to crash and it caused damage. I asked what happened and the he said one of the emulators we were playing had a script that crashed the server and caused damage. I asked how much damage and they informed me it was over 3 thousand dollars. At this point I'm very skeptical that the damage was worth about the cost of a new workstation (the old one sitting on his desk, buried in boxes), and afterwards none of the faculty knew of any kind of an outage. I asked for him to show me what broke and what had to be done to fix/replace the damaged equipment but all I got was a simple, "I'm sorry. I can't show you that at this time."
They threatened legal action for a felony of damaging a school property. Myself and the other tech savvy kids talked about it over the next couple of days wondering what would happen. They threatened expulsion for myself and a couple of other kids, but ultimately just got a talking to about keeping personal information safe.
What I got out of it was if they think I'm good with computers I must be doing something right. Now I'm in IT. This is where it went wrong. -
Been reading for a while now, finally frustrated enough to add my rant...
Backing up my home server with Veeam to finally ditch raid 5 and add some space. 38% finished when we had to leave for a Thanksgiving dinner. Thought that was perfect because I'd come home to a finished backup, install the new drives and get Plex/webserver back up and running. Nope. Win 10 decides to update and reboot in the middle of my freaking backup at 79% complete. Now, I've just told the friends and family I was with to expect the outage in the next hour or two thinking I was ready. Nope. Start all over again. None of this is truly important, really... But Jesus, that's annoying.
Win 10, you have a special place in hell. And Veeam, as much as I love you, you can be right beside them for not letting me run backup console on Linux.1 -
Caused an outage on production because of a bug in the make file that hasn't been fixed for years. It hasn't been fixed because everyone knows to side step it. Except for me. Unit now. So the bug shall continue to live until the next newbie gets smacked in the face by it.
Kinda feels like an initiation. -
Was doing some chill programing when all of a sudden we lose power in the entire fucking house! So not just a blown fuse or something, but looks like the entire street has it, so no telling when it'll be back on either -_- Also I reaaaallly need to buy a UPS for my server, this is happening way too fucking often.5
-
So the fucking septic cleaning guys truck snagged the internet line that goes across the driveway and the took it down.... No internet till at least noon tomorrow. Fuck me! I had a personal project I really wanted to work on.6
-
We had a production outage directly caused by our team not following a change procedure correctly. Now we're under a microscope and in a "get well" program.
They took over the daily standup for this high priority program and are organizing efforts in confluence instead of jira.
Now we have a confluence doc of what everyone is working on with someone changing the text status in a table by hand every morning along with the comments in a note section...1 -
This morning at 5:30 AM I was awoken to 20 text alerts for services being down.
Seems they had been down since 2 AM but the previous shift didn't take action.
Long story short:
An outsourced common component is unavailable, and the team responsible doesn't know how to troubleshoot.
I pointed them to the exact issue.
We are now 10 hours into the outage and they still don't know what to do. -
Interested if anyone has done a risk assessment with the AWS outage (or other cloud hosts) in scope and contingency strategies in place and tested. A+ if you did 👍
No, going to the pub does not count as a viable strategy but probably a popular one. -
WE: javaagent-based monitoring, as seen in this screenshot <attached>, is reporting full old-gen, full young-gen, full one of the survivors and a sky-rocketing full GC right before the service outage.
WE: container monitoring in this screenshot <attached> shows that the application peaked its memory very suddenly to MAX values and platoed on that. Then container monitoring is blank, suggesting a complete outage of a few minutes. After that monitoring starts again with memory usage reported at low levels and immediatelly spiking back to MAX again, suggesting the container crashed and had been respawned by an orchestrator. This repeats a few times throughout the day.
they: I did not find any evidence of application running out of memory. Maybe our monitoring is not working correctly?
we: *considering updating our resumes* -
Have you thought that in case of apocalypse say EMP burst or anything huge enough hit our wet rock which lead to global & long power outage, our kind along electricians will be a valuable assets for any survival group. if 2 better, but if they are 3+ one will proclaim himself as PM and the chaos will be uneashed again ;}4
-
Working on 3 projects solo remotely and everyone wants their changes promptly. Also, I don't disclose to clients that I work for other people. (Being me)
Finished with 2 projects today so gonna Netflix and chill ( I really don't have a gf and idgaf), I need pack of smokes really bad and internet outage just in time when I finally finished, now waiting for more changes eagerly so that I can get paid finally2 -
I feel stupid when I have trouble calculating how big a UPS I need to keep my NAS from just dying during a power outage instead of safely powering off
Then I just dont bother getting one... and get pissed off next time it happens and the cycle continues
Now I have other stuff I'd want to get a UPS for too and the math is even worse for my tiny brain1 -
So today I learned how tree shaking works and I was just about to publish patches to my NPM modules when the registry gave up.6
-
Electronic companies nowadays are no different than ranchers that force their slaves to earn money to buy new stuff cause people can’t repair old electronics or fix software bugs cause it’s not theirs or it’s not maintained and source code is not existent.
Damn you software and hardware corporations.
You tell everyone that you care about environment, yet you don’t fucking support your software and hardware as long as people use it. When you stop support you don’t make everything open source but keep it on your private repositories as intellectual property and fuck your clients.
Literally all electronics and software should be mandatory made open source to the people who purchased product so they can use it as long as they want not as long as corporate assholes want. This is insane law that is splitting our world and making it burn. If I could fix my laptop in nearby shop I wouldn’t have to purchase new one.
If it won’t change we will end up with <10 corporations that would rule world economy, everyone who will work for those corporations will be rich and happy and everyone else will be poor and unhappy . Mind me if this is not already happening and this planet slowly becomes Elysium movie nightmare.
Stop buying new stuff you stupid people cause this make things worse.
If it won’t change in 10 or so years there will be connected to cloud robots all over the world guarding us and some dick shit rich John Conor kid will hack them to exterminate humans by executing order 66. After that there will be big power outage that will put us into the role of battery and we would be closed in the barrel full of pink shit connected to matrix.
Get me out of here you asshole.1 -
So I just woke up and there is an internet outage in my neighborhood because optimum sucks balls, fuck the whole stupid low class internet service
Now I have to leave my house so I can work -
I just love it when there is a power outage just after we all go home for the weekend. Coming back to dead servers is the best!
-
Cable/Internet outage. Tried to contact ISP (Mediacom, who are awful)... Reported outage over an hour ago, but no update.
So, I figure it's time to call then...
In support app, selected "Call someone now." Selected sevices. Drop-down for "Tap down arrow for list"... contains the single placeholder "Tap down arrow for list". Plus, of course, you cannot submit the form without making a selection from the list.
Fuck your fucking support app right in the java-hole, Mediacom.
I did not need any more reasons to hate you - you are already at the top of my list, with no one else remotely close behind. 3
3 -
Today I came to work and all our main systems where offline (Gitlab, Artifactory, Time tracking, ...). Found out that one of the HDDs of our server (external hosted) died. I started copying some stuff from the second Raid hdd (just in case and because our backup is of course not complete [#notmyfault]) while their datacenter had a power outage.... I'm now waiting for our server to come back to get our systems running again
-
!rant
Our office is going to have a planned power outage. An outdoor generator hire and installation doesn't seem possible because of location.
We need to keep our servers running with aircons to keep them cool. We're out of ideas unless someone here can suggest something.4 -
When a severe outage/screw-up happens or when an insane request comes through and the only solution is some adhoc coding... the best part of being a dev: 1. being the one they turn to in those dark times, and 2. the self confidence boost when you alone have saved the day. It's thankless but those times make up for it.
-
*looks around apprehensively* crazy planned electrical outage again with sinks that require power to run
God if we ever revert to analog we’re boned -
Release was supposed to start at 10 am, its now 11am but our release document is being debated heavily. The outage is scheduled to last until 2 and we thought we'd be tight for time when starting at 10 FML to right now..
-
Anyone else effected by the UK fast outage yesterday? We've come in this morning to a failed drive (or so we think) our Web server home directory is just gone wondering if anyone else has noticed any funnies on their hosting
https://theregister.co.uk/2017/12/... -
Thank God for "Screen" my remote Linux build session is alive in spite of fucking network outages! I'm telling you, when your company doesn't have voltage regulators, network goes down everytime there's an electrical fluctuation!
-
Lots of ppl cannot access internet since idk, an hour or two. I tried pinging 1.1.1.1 it works, turned on DNS and voila!
The fucking country's DNS connection is broken or something, idk.
When in doubt, https://1.1.1.1/
Dns settings for future reference: 1.1.1.1;1.1.1.23 -
In my first job another junior dev and I (junior at the time) were assigned the task of designing and implementing a user management and propagation system for a biometric access control system. None of the seniors at the time wanted to be involved because hardware interfacing in the main software was seen as a general shit show because of legacy reasons. We spent weeks designing the system, arguing, walking out in anger, then coming back and going through it again.
After all that, we thought we would end up using each other, but we actually became really good friends for the rest of my time there. The final system was so robust that support never heard back from the client about it until around 2 years later when a power outage took down the server and blew the PSU.
Good times. -
Before he began dropping the 20K proposed to remodel my flat, I told my father I much preferred a contractor who was recommended by someone I knew, as opposed to using a big corporation like Home Depot. FAMOUS LAST... a neighbour in my building highly recommended the contractor we chose. And, week 7 [or is it 8?] of what was proposed to take no longer than two weeks has begun afresh!
On Friday the fellow who is the owner of the contract remodeling company was here touching the paint. He was here because I forbade the two painters he sent to do the initial painting job.
My internet cut out suddenly around 1300 Friday. He set to leave for the weekend shortly after that. I mentioned the outage to him. The essence of his reply was that there was no way it could have had anything to do with him. The following day, my internet provider sent a tech out to diagnose the problem. What was the problem? The head of the remodeling firm removed a face plate from the wall where there were telephone wires and disconnect them when he tore the wires as he replaced the face plate.
Although the tech told me he wasn't going to charge my account the $85.00 fee for his services because the outage was caused within my flat, I wish to be sure of this. Which brings us to the punchline.
My internet provider is a lame ass business model, dreamed up by a squint-eyed ex-circus monkey, never well endowed in the top story, and now just plain sad.
There were some 911 outages in Washington State last Thursday night. All during the day Friday when you dialled their freephone #. the recorded announcement, before saying anything else, told you they were experiencing heavier than usual call volumes, and my wait would be greater than `10 minutes. Fine. What fried my La Croix silk was that after their customer service dept closed for the weekend, that outgoing message remained.
Today, I wanted to contact my provider to see if they would know if the $ was going to be charged to my account. After pressing the 'send' key, my computer came back with an error message, saying they were having technical difficulties. So, I went on over to the 'chat' page. There's nothing to click on to take me to this enfabled location. So, can't reach them by phone unless I want to hear, every 30 seconds whether or not I wish to, how sorry they are for my delay.
A few years ago I would've used this as an excuse to have a technicolour meltdown. The reason I'm posting this is that I am now able to see beforehand what I'll be doing to myself getting upset over the circumstances. When I do reach somebody, I'm going to tell them as lightly as possible, that if they were an airline, I wouldn't board any of their aircraft. Ever. -
Stupid Comcast.
My office network was down cause cause Comcast had a "non-existent" outage that affected my modem. Right when they picked up the phone, is when the thing finally got online.
Wasted an hour of my time cause I had to commute a half hour to go there.2 -
Finally back using my pc after a long time trying to buy a new battery for my UPS (I don't want to risk my computer during a power outage in this fucking country)





































































































































Top Tags
Weekly Rant
View