
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Hey everyone,
First off, a Merry Christmas to everyone who celebrates, happy holidays to everyone, and happy almost-new-year!
Tim and I are very happy with the year devRant has had, and thinking back, there are a lot of 2017 highlights to recap. Here are just a few of the ones that come to mind (this list is not exhaustive and I'm definitley forgetting stuff!):
- We introduced the devRant supporter program (devRant++)! (https://devrant.com/rants/638594/...). Thank you so much to everyone who has embraced devRant++! This program has helped us significantly and it's made it possible for us to mantain our current infrustructure and not have to cut down on servers/sacrifice app performance and stability.
- We added avatar pets (https://devrant.com/rants/455860/...)
- We finally got the domain devrant.com thanks to @wiardvanrij (https://devrant.com/rants/938509/...)
- The first international devRant meetup (Dutch) with organized by @linuxxx and was a huge success (https://devrant.com/rants/937319/... + https://devrant.com/rants/935713/...)
- We reached 50,000 downloads on Android (https://devrant.com/rants/728421/...)
- We introduced notif tabs (https://devrant.com/rants/1037456/...), which make it easy to filter your in-app notifications by type
- @AlexDeLarge became the first devRant user to hit 50,000++ (https://devrant.com/rants/885432/...), and @linuxxx became the first to hit 75,000++
- We made an April Fools joke that got a lot of people mad at us and hopefully got some laughs too (https://devrant.com/rants/506740/...)
- We launched devDucks!! (https://devducks.com)
- We got rid of the drawer menu in our mobile apps and switched to a tab layout
- We added the ability to subscribe to any user's rants (https://devrant.com/rants/538170/...)
- Introduced the post type selector (https://devrant.com/rants/850978/...) (which will be used for filtering - more details below)
- Started a bug/feature tracker GitHub repo (https://github.com/devRant/devRant)
- We did our first ever live stream (https://youtube.com/watch/...)
- Added an awesome all-black theme (devRant++) (https://devrant.com/rants/850978/...)
- We created an "active discussions" screen within the app so you can easily find rants with booming discussions!
- Thanks to the suggestion of many community members, we added "scroll to bottom" functionality to rants with long comment threads to make those rants more usable
- We improved our app stability and set our personal record for uptime, and we also cut request times in half with some database cluster upgrades
- Awesome new community projects: https://devrant.com/projects (more will be added to the list soon, sorry for the delay!)
- A new landing page for web (https://devrant.com), that was the first phase of our web overhaul coming soon (see below)
Even after all of this stuff, Tim and I both know there is a ton of work to do going forward and we want to continue to make devRant as good as it can be. We rely on your feedback to make that happen and we encourage everyone to keep submitting and discussing ideas in the bug/feature tracker (https://github.com/devRant/devRant).
We only have a little bit of the roadmap right now, but here's some things 2018 will bring:
- A brand new devRant web app: we've heard the feedback loud and clear. This is our top priority right now, and we're happy to say the completely redesigned/overhauled devRant web experience is almost done and will be released in early 2018. We think everyone will really like it.
- Functionality to filter rants by type: this feature was always planned since we introduced notif types, and it will soon be implemented. The notif type filter will allow you to select the types of rants you want to see for any of the sorting methods.
- App stability and usability: we want to dedicate a little time to making sure we don't forget to fix some long-standing bugs with our iOS/Android apps. This includes UI issues, push notification problems on Android, any many other small but annoying problems. We know the stability and usability of devRant is very important to the community, so it's important for us to give it the attention it deserves.
- Improved profiles/avatars: we can't reveal a ton here yet, but we've got some pretty cool ideas that we think everyone will enjoy.
- Private messaging: we think a PM system can add a lot to the app and make it much more intuitive to reach out to people privately. However, Tim and I believe in only launching carefully developed features, so rest assured that a lot of thought will be going into the system to maximize privacy, provide settings that make it easy to turn off, and provide security features that make it very difficult for abuse to take place. We're also open to any ideas here, so just let us know what you might be thinking.
There will be many more additions, but those are just a few we have in mind right now.
We've had a great year, and we really can't thank every member of the devRant community enough. We've always gotten amazingly positive feedback from the community, and we really do appreciate it. One of the most awesome things is when some compliments the kindness of the devRant community itself, which we hear a lot. It really is such a welcoming community and we love seeing devs of all kind and geographic locations welcomed with open arms.
2018 will be an important year for devRant as we continue to grow and we will need to continue the momentum. We think the ideas we have right now and the ones that will come from community feedback going forward will allow us to make this a big year and continue to improve the devRant community.
Thanks everyone, and thanks for your amazing contributions to the devRant community!
Looking forward to 2018,
- David and Tim 45
45 -
Hey everyone,
Merry Christmas to everyone who celebrates, happy holidays to everyone, and happy almost-new-year!
Tim and I wanted to reflect on the year devRant has had, and looking back, there are a lot of awesome things that happened in 2018 that we are very thankful for. Here are just a few of the ones that we thought of (this list is not exhaustive and I'm definitley forgetting stuff, so please comment about those!):
- After nearly a year in the making, the completely overhauled devRant web version was launched (https://devrant.com/rants/1255714/...)
- @linuxxx became the first devRant user to hit 100,000++! (https://devrant.com/rants/1157415/...)
- We once again pulled off the greatest April fools joke everrrr (https://devrant.com/rants/1311206/...)
- @trogus started making awesome devComics and http://devcomics.com was launched
- We added a feature to allow rant filtering by post type (https://devrant.com/rants/1354275/...)
- We made it so avatars could have expressions! (https://devrant.com/rants/1563683/...)
- We had a booth at TechDay New York and got to meet some devRant users! (https://devrant.com/rants/1394067/...)
- We made major backend architectural improvements - including spinning up a special high-powered-CPU web server to handle avatar creation and make the creation process much faster (https://devrant.com/rants/1370938/...)
- App stability: mainly Android - we fixed crashes, did a push-notif overhaul, and tried to continue making the apps better and more stable
- A record amount of devRant meetups were held, and we couldn't be more proud about that, and we thank every person who organized one! (just a few: https://devrant.com/rants/1588218/... https://devrant.com/rants/1884724/... https://devrant.com/rants/1683365/... https://devrant.com/rants/1922950/...)
We had a busy year, and despite some things going on for us personally and some setbacks around those, we think this was a very productve year for devRant and that we are going in the right direction. We're continuing to constantly evaluate feedback from members of the community to decide where to take the app next. We're fully committed to improving the devRant community in 2019 and we have a lot of ideas about how we can do that. We're working on some things, but we're not really announcing them yet, so please sit tight for those :) In the meantime, feel free to let us know what you'd like to see improved/added the most as we always like to get updated feedback from the community.
As always, thank you everyone, and thanks for your amazing contributions to the devRant community!
Looking forward to 2019,
- David and Tim 26
26 -
New devRant feature! Filtering by post type! This took a bit longer to get out than we had planned, but now that extra click to label a post type will be put to good use! Hate memes but love rants? Want to only see questions? Don't want to see random off-topic posts? Filter away!
We're pushing to Android now, iOS shortly, and web will be coming soon. 40
40 -
Latest update for the devRant app has some new twists: 1) collabs are now free for all 2) black theme is available for devRant++ members 3) when posting a rant we now ask for you to classify the rant as a specific type of post. RIP !rant :/ To be clear, this isn't meant to say that any posted content needs to be different than what everyone is doing already, just that the extra categorization helps all parties who like or dislike different types of content. This categorization will help better inform the algo and allow for advanced filtering which is coming soon.
If you have any questions, comments or concerns please ask me or @dfox in this thread. 64
64 -
I wanted to post a note on devRant community etiquette and rule-breaking behavior we’ve been seeing lately to make clear it will not be tolerated. This is pretty much a rehash of this rant, https://devrant.com/rants/609739/... and also our official rules which I highly encourage people to read: https://devrant.com/rules
I’ve noticed an influx of a select group of members, mostly older users, expressing a distain towards other users or declaring content they dislike “shouldn’t be posted”, “please stop”, etc. If you find yourself about to post that, as per our rules, please don’t. It blatantly violates our rules and we are going to start cracking down on it much more. Whether you have 30k+ points or 10, we will apply the rules fairly to everyone and not give breaks to specific people, which admittedly I’ve done in the past.
If we see this behavior in rants/comments first we will give a warning (and the rant/comment will be deleted) and the next offense is a ban.
A valid question (even though I’ve answered it before) might be why does this need to be a rule? Simply put, it’s a rule for a number of reasons: posts like described try to inflict one’s will upon the entire community (even though we have a Democrat voting process...), they create confusion (almost every time they try to sound official, ex. “Stop doing this”), and beyond those two main reasons, they literally accomplish nothing because they offer no constructive methods of achieving what’s being requested, and only a fraction of the community will actually see it.
Here’s an example of what’s not allowed and what is allowed:
- Allowed: posting an issue on our GitHub issue tracker saying “I really dislike seeing this type of rant in my algo feed, here’s some ideas I have to improve the algo and add more personalization so I can see what I want.”
- Allowed: posting on GitHub issue tracker: “I found this awesome image similarly algo that I think can improve the ‘repost check feature’ - you guys should check it out and see if it might be good”
- Not allowed: “Omg stop shitposting windows update rants and Linux rants I hate them. Go post this type of rant because that’s what everyone really wants to see.”
One is constructive an the other is merely an opinion expressed as an enforcement of a self-made rule on the community and tries to tell other people how they should use devRant.
I cringe when people tell others how to use devRant because without fail when I see those posts, I go through that person’s rant/comment history and I nearly always see them using devRant in some kind of way I disagree with or isn’t exactly what I like to see. But that’s OK. I understand I’m not going to enjoy everything posted and I’m also not going to agree with everything posted. But I think it’s fair for those same people to then lecture on what isn’t appropriate to post on devRant, and it’s even more silly when their posts are sometimes irrelevant to development and the posts they are complaining about are relevant.
In the end, based on the large majority of feedback we get, we want to make devRant a place where everyone feels comfortable expressing themselves and doesn’t have to think about possibly getting ridiculed every time they post and that don’t have people trying to dictate what kind of ideas they are allowed to post. We also realize there’s types of content people don’t enjoy, but telling others not to post it is not the solution. We will soon be launching post type filters that will make filtering rants by post type possible.
Please let me know if you have any questions and thanks for reading.63 -
The programmer and the interns part 3.
Many of you asked me to keep posting about the interns that I'm responsible for.
I had the intention but never had the time or the energy. Since the interns only kept doing stupid, unthinkable things and just filtering out the good ones is a task of its own.
Time has passed, some interns left us by their choice, others were fired (for obvious reasons). Some stayed loyal and were given permanent positions. New ones joined. I no longer am directly responsible for their wellbeing, yet, somehow I am still their tech-lead and the developer of their tools.
Without further delay,
Case 0:
New guy get's into the internship, has his LinkedIn title set to ‘HTML Technician’.
Didn’t know about the existence of HTML5.
Been building static web pages in the early 2000s. The kind with embedded, inline CSS.
Claims that he is about to finish an engineering degree (sadly I believe him).
Fails the entry level Linux test. Complains about the similarity of the answer options.
Fails the basic web-standars test because "they change so fast, but the foundation is HTML and it's rock-solid!".
Get's caught taking home onions and milk from the kitchen.
Is spotted eating in a restaurant under our offices in his day off. Thrice. He lives a 30 minute drive away and comes here on a bicycle or by bus.
Apparently didn't know that the scrolling wheel on the mouse is clickable.
Said that his PC experience is mostly from his PlayStation (PC = PlayCtation apparently).
Get's fired, says that he'll go to the press. Never does.
Case 1:
Yet another new intern. He seems very eager to learn and work, capable, even charismatic. Has an impressive CV.
Does nothing.
Learns from the "case 0" guy and spends time with him until he is fired.
Comes to work at 8:00 AM and immediately goes to sleep on an office puff. In front of everyone.
Keeps dining alone, without a notice, at different times, for hours. Sometimes brings food into the office and loudly eats it there.
On his evening shifts keeps disappearing for long periods of time. Apparently drinking in the nearby bars and hitting on girls.
Keeps bragging about his success with getting their numbers and rants about those who reject him.
For over a year he fails his final training test and remains a trainee, without the ability to work on a real case.
Not fired yet.
Case 2:
Company retreat. Beautiful, exotic views, warm sun beams, all inclusive package for everyone on a huge half-island.
Simon (he's still with us, now as a true engineer!) brings his MacBook to the beach in order to work and impress all others.
Everybody get's drunk and start throwing huge inflatable balls at each other. One hits his laptop and it immediately is flattened.
Upset Simon is going in circles and ranting about the situation, looking for a solution.
Loses his phone on the beach.
Takes his broken laptop with him while searching for the phone.
Dips the laptop in the river while drunkenly ducking in order to pick a clam.
Case 3:
Still company retreat.
Drunk intern makes out with an employee's drunk wife.
Huge verbal fight. The husband says that he files for a divorce. Intern get's fired.
Case 4:
Still company retreat.
Three interns each take an inflatable swimming mattress and drift with the current. Get found on the other side of the resort three hours later, with red skin and severely dehydrated.
Case 5:
Still company retreat.
The 'informally fired' intern gets drunk again, climbs through a window into a room and makes out with an employee's drunk wife.
Again, gets caught when the husband returns to find a locked door but can see them though the window.
Case 6:
Still company retreat.
We all get ferociously drunk and wander off to the unknown in search of more booze.
Everybody does something stupid and somebody finds Simon's phone.
Simon is lost.
Frenzied horde of drunks is roaming the half-island in search of ethanol and the lost comrade.
Simon's phone get's permanently lost.
Five people step on sea urchins but find that out only hours later and then are unable to walk.
The mob, now including more drunk people who joined voluntarily, finds the sexually active intern making out with the enraged employee's wife yet again.
Surprisingly Simon is found sleeping in a room nearby.23 -
I’ve been thinking lately, what is it that devRant devs do?
So after a couple of days of pulling data from devRants API's, filtering through the inconsistent skill set data of about 500 users (seriously guys, the comma is your friend) i’ve found an interesting set of languages being used by everyone.
I've limited this to just languages, as dwelling into frameworks, libraries and everything else just grows exponentially, also ive only included languages with at least 5 users out of the pool.
sorry you brainfuck guys. 28
28 -
In may this year, the new mass surveillance law in the Netherlands went into effect. Loads of people were against it with the arguments that everyone's privacy was not protected well enough, data gathered through dragnet surveillance might not be discarded quickly after the target data was filtered out and the dragnet surveillance wouldn't be that 'targeted'.
They were put into the 'paranoid' corner mostly and to assure enough support/votes, it was promised that:
- dragnet surveillance would be done as targeted as possible.
- target data would be filtered out soon and data of non-targets would be discarded automatically by systems designed for that (which would have to be out in place ASAP).
- data of non-targets would NOT be analyzed as that would be a major privacy breach.
- dragnet surveillance could only be done if enough proof would be delivered and if the urgency could justify the actions.
A month ago it was already revealed that there has been a relatively (in this context) high amount of cases where special measures (dragnet surveillance/non-target hacking to get to targets and so on) were used when/while there wasn't enough proof or the measures did not justify the urgency.
Privacy activists were anything but happy but this could be improved and the guarantees which were given to assure privacy of innocent people were in place according to the politicians... we'll see how this goes..
Today it was revealed that:
-there are no systems in place for automatic data discarding (data of innocent civilians) and there are hardly any protocols for how to handle not-needed or non-target data.
- in real life, the 'as targeted dragnet as possible' isn't really as targeted as possible. There aren't any/much checks in place to assure that the dragnets are aimed as targeted as possible.
- there isn't really any data filtering which filters out non-targers, mostly everything is analyzed.
Dear Dutch government and intelligence agency; not so kindly to fuck yourself.
Hardly any of the promised checks which made that this law could go through are actually in place (yet).
Fuck you.28 -
Hey devRanters! A tiny update regarding the privacy tips etc site.
So as ewpratten doesn't have much time right now, I'm doing frontend as well for now.
Since some people also offered to contribute content, which I did not expect, I am also writing an invite/registration (based on invites) as we speak. So, this way, I can invite anyone (based on email address) into the CMS so that they can contribute content as well!
Regarding frontend, I'm introducing a system with icons. Icons? Yes, icons, let me explain:
Every application/service will get a couple of default filtering thingies. (not like clicking something and it'll filter anything out, yet) It'll enable users to see what an application does or does not. What the FUCK do you mean? Alright, so, as example, lets say open source. next to each application (read application/service) listed, there will be an open source icon. If the application is open source, this icon will be green, otherwise it will be red.
This will allow for a quick way of filtering stuff out.
For example, if you're only looking for open source stuff, you can quickly filter stuff out where the open source icon is red!
This will apply to things as open sourceness, metadata saving, usage of good crypto technology and so on. So you'll be able to quickly filter out the stuff you want to use (by eyes) through those filters!
Please let me know what you think and if you have ideas, I'll be glad to hear them!25 -
When you start a new job as a Senior Developer, and start asking questions about the code, and you have these collections of conversations with other front-end people:
Exhibit 1:
Me: Ahh so I see the filtering and pagination is all done with Javascript in the front end...
Random dev: No, it's done with Angular.
Exhibit 2:
Me: I think we should add frontend pagination to this page. There will be too many elements on it if you're a customer with 2000 servers.
Random dev: Don't bother, there's no pagination in the API call... So that will not gain any performance.
Me: But it wouldn't take long to implement and it would improve the user experience, why would you want to show ALL the elements, when you have an option not to... Also, it WILL be a major performance hit, especially on mobile.
Random dev: People will use search anyway.
😥🔪
Also, there are no coding standards, every file looks different, and my opinion is being disregarded in everything, and I thought my last job was bad...
Seriously how are some people hired as front-enders?
Since I just took this job, I feel obligated to stay a couple of months... But hey, don't cry for me, I might have more rants for you. 😂
Sorry for the long rant, here's cake: 🍰5 -
--- NVIDIA announces PhysX SDK 4.0, open-sources 3.4 under modified BSD license ---
NVIDIA has announced a new version, 4.0, of PhysX, their physics simulation engine.
Its new features include:
- A "Temporal Gauss-Seidel Solver (TGS)", an algorithm used in this SDK to make things such as robots, character arms, etc. more robust to move around. NVIDIA demonstrates this in the video by making their old version of PhysX, 3.4, seem like an unpredictable mess, the robot demonstrating that version smashing a game of chess.
- New filtering rules for supposedly easier scalability in scenes containing lots of both moving and static objects.
- Faster queries in scenes with actors that have a lot of shapes attached to them, improving performance.
- PhysX can now be more easily used with Cmake-based projects.
In essence, better control over scenes and actors as well as performance improvements are what's new.
Furthermore, NVIDIA has released PhysX version 3.4 under the 3-Clause-BSD-license, except for game console platforms.
As NVIDIA will release the new version on December 20th, it will also be released under the same modified BSD license as PhysX 3.4 is now.
What are your thoughts on NVIDIA making a big move towards the open-source community by releasing PhysX under the BSD license? Feel free to let us know in the comments!
Sources:
https://news.developer.nvidia.com/a...
https://developer.nvidia.com/physx-...
https://github.com/NVIDIAGameWorks/... 3
3 -
fuckpress.Pi
Yep, thata right. Fuck Wordpress Raspberry Pi. Thanks to my inability to interact with proton mail filtering I just made a script that checks for a new email and if it contains words "wordpress", "help", " hack", "build" and it is not from whitelisted contact, the email is moved to the Fuckpress folder and automatic reply is sent back that I AM NOT FUCKING DOING YOUR GAYPRESS FUCKING SHIT FOR YOUR 5$ CUNT.
rant over4 -
The tech stack at my current gig is the worst shit I’ve ever dealt with...
I can’t fucking stand programs, especially browser based programs, to open new windows. New tab, okay sure, ideally I just want the current tab I’m on to update when I click on a link.
Ticketing system: Autotask
Fucking opens up with a crappy piss poor sorting method and no proper filtering for ticket views. Nope you have to go create a fucking dashboard to parse/filter the shit you want to see. So I either have to go create a metric-arse tonne of custom ticket views and switch between them or just use the default turdburger view. Add to that that when I click on a ticket, it opens another fucking window with the ticket information. If I want to do time entry, it just feels some primal need to open another fucking window!!! Then even if I mark the ticket complete it just minimizes the goddamn second ticket window. So my jankbox-supreme PC that my company provided gets to strugglepuff along trying to keep 10 million chrome windows open. Yeah, sure 6GB of ram is great for IT work, especially when using hot steaming piles of trashjuice software!
I have to manually close these windows regularly throughout the day or the system just shits the bed and halts.
RMM tool: Continuum
This fucker takes the goddamn soggy waffle award for being utterly fucking useless. Same problem with the windows as autotask except this special snowflake likes to open a login prompt as a full-fuck-mothering-new window when we need to open a LMI rescue session!!! I need to enter a username and a password. That’s it! I don’t need a full screen window to enter credentials! FUCK!!! Btw the LMI tools only work like 70% of the time and drag ass compared to literally every other remote support tool I’ve ever used. I’ve found that it’s sometimes just faster to walk someone through enabling RDP on their system then remoting in from another system where LMI didn’t decide to be fully suicidal and just kill itself.
Our fucking chief asshat and sergeant fucknuts mcdoogal can’t fucking setup anything so the antivirus software is pushed to all client systems but everything is just set to the default site settings. Absolutely zero care or thought or effort was put forth and these gorilla spunk drinking, rimjob jockey motherfuckers sell this as a managed AntiVirus.
We use a shitty password manager than no one besides I use because there is a fully unencrypted oneNote notebook that everyone uses because fuck security right? “Sometimes it’s just faster to have the passwords at the ready without having to log into the password manager.” Chief Asshat in my first week on the job.
Not to mention that windows server is unlicensed in almost every client environment, the domain admin password is same across multiple client sites, is the same password to log into firewalls, and office 365 environments!!!
I’ve brought up tons of ways to fix these problems, but they have their heads so far up their own asses getting high on undeserved smugness since “they have been in business for almost ten years”. Like, Whoop Dee MotherFucking Doo! You have only been lucky to skate by with this dumpster fire you call a software stack, you could probably fill 10 olympic sized swimming pools to the brim with the logarrhea that flows from your gullets not only to us but also to your customers, and you won’t implement anything that is good for you, your company, or your poor clients because you take ten minutes to try and understand something new.
I’m fucking livid because I’m stuck in a position where I can’t just quit and work on my business full time. I’m married and have a 6m old baby. Between both my wife and I working we barely make ends meet and there’s absolutely zero reason that I couldn’t be providing better service to customers without having to lie through my teeth to them and I could easily support my family and be about 264826290461% happier!
But because we make so little, I can’t scrap together enough money to get Terranimbus (my startup) bootstrapped. We have zero expendable/savable income each month and it’s killing my soul. It’s so fucking frustrating knowing that a little time and some capital is all that stands between a better life for my family and I and being able to provide a better overall service out there over these kinds of shady as fuck knob gobblers.5 -
Man I really hate it when people think that coding doesn't take any concentration and can just interrupt you while you're thinking about how to solve problems
So the other day I was working on how to solve a problem with filtering data with JS, and I had to urgently update one of our pages on our website. I had to update that page according to the content of a Word file, which I didn't check how long it was.
About 15 minutes later everything was ready and published, so I set myself back to my problem.
I get an email from her, "you mixed up things" and she showed up in my office. "There are four pages in this word doc and you copied wrong parts", I was like "ok, I'll fix it". Fixed it two minutes later, went back to code.
Received another email, with another subject, again with another problem. Start getting pissed off for being interrupted for nonsense. Fixed it instantly and put my manager in the email loop so she is aware my other colleague pisses me off.
And again, another direct email "can you fix this?!". I started ignoring her requests because I need some work to be done, and I already lost 2 hours. Got again interrupted by her personal visit to point me which things are wrong, repeating everything twice as I am stupid to her. Man I can't code in peace. I fixed her shit, exactly as she wants and decided to pay my manager a visit to tell her I'm really pissed about being interrupted all the time.
Five minutes before the end of the day, she comes panicking in the office about ANOTHER WORTHLESS issue. Told her it's nothing and went away.
Day is over, thought it was over - a whole afternoon spent correcting her fucking page that gets 10 visits a year.
On the next morning, "there is something wrong with your form, can you check it?!!?" with an attached screenshot. FFFFFFFFUUUUUUUUU STOP ANNOYING ME WITH YOUR FUCKING SHIT CANT WORK ANYMORE. PUT YOUR FUCKING PAGE RIGHT UP YOUR ASS AND FIX IT YOURSELF.
She doesn't have any access to the back end.
Guess I'll have to fix it then...9 -
Currently working on the privacy site CMS REST API.
For the curious ones, building a custom thingy on top of the Slim framework.
As for the ones wondering about security, I'm thinking out a content filtering (as in, security/database compatibility) right now.
Once data enters the API, it will first go through the filtering system which will check filter based on data type, string length and so on and so on.
If that all checks out, it will be send into the data handling library which basically performs all database interactions.
If everything goes like I want it to go (very highly unlikely), I'll have some of the api actions done by tonight.
But I've got the whole weekend reserved for the privacy site!20 -
I disabled javascript in my browser. Amount of shit loading to read shitty article is insane.
I opened chrome devtools and it was 300 requests and 10MB to read 500 words.
Another news portal 250 requests 7MB to see 300 words.
WTF ?
And they’re fighting with internet traffic by lowering movie quality ?
I just add I have pihole with lots of wildcard filters filtering half of internet and fucking adblocker and those numbers are after those filters.
Are you fucking out of your mind ?
Fucking hypocrites.17 -
CLIENT "So my nephew who does stuff with computers built it and we are ok with how it all works so don't worry about changing that. "
DEV "so like you have a public form with no input filtering, spam mitigation let alone sanitization or remote concern for security. Basically you have a Json flat file that is 34mbs of links to, viagra, replica watches, nock off name brands and one real estate company. It is getting about 15 submissions an hour. Since you don't want me changing how it works are you happy to just leave all that ?"
CLIENT "no no we don't want all that but we have no route to delete it, can you just stop all the spam and let us continue on?"
DEV "ok so back to my first question can we rebuild all of this properly, or do you really want to just leave it all"
:/ FML3 -
Dev: Can you please tell me why you changed this?
Me: Because we need to handle permissions in the app. The quickest way of doing it, according to the docs, is [insert change log here]
Dev: But we can just check for the user's token.
Me: That's not exactly a permission, because...
Dev: I was only showing the information related to the user according to their token.
Me: I understand. But that means you're filtering data, not authorising users to access it. If a user is logged in, but changes query parameters, they can still access data they shouldn't be able to.
Dev: Whatevs.
Le me then proceeds to try to push my changes (that took the whole day to implement), gets a "you need to pull first" message from git, doesn't understand why, logs onto GitHub and realises dev has implemented their "permissions".
I was the one responsible for making those changes. Le dev was meant to be doing other things.
How do I even begin to explain?7 -
Working on the privacy site, someone gave me a good SQL example for the 'filtering' (renaming this to capabilities) feature and here I am, hardly knowing any SQL more than basic selects 😥. Well, good luck to me I guess :/3
-
1 - Please hack his/her facebook account for me.
2 - (at home) I used to block wifi access by mac filtering and if there's legit server down and wifi isn't working, everyone blames me.
(I am freelancer and mostly work from home)
3 - almost all of my relatives think I don't work.
4 - I am first choice for everyone's phone, PC and hardware repair.
This one is classic
GET A REAL JOB, you need to go out in the field for work.5 -
Dear coworker, please stop using the fucking reply all button to just send a winky face to everyone on the mailing list. I am almost to the point of just filtering all your mail to the trash because you hardly send anything relevant anyway.2
-
What Unix tool would like to use in real world? Like superpower :)
I would choose grep.
- easy ads filtering with -f
- fast search in books15 -
TIL: C# has a "Catch When" syntax to help you filter exceptions. It already allows you to filter by Exception type, but this is news to me since it allows for finer filtering like:
try
{
//Shit code that will throw an exceptions more than Hillary's tantrums about the elections
}
catch (ExceptionType ex) when (ex.ErrorCode = "0x696666")
{
//Log this fuck up
}
catch (Exception ex)
{
//More logs
}
finally
{
//Run code that doesn't depend on the successful execution of prev code
}
I love C# and use it every single day, but this "When" keyword in Try...Catch...Finally blocks is new to me and will be interesting to start using it now :)3 -
TL;DR
This works: email+rant@domain.com
Spam filtering protip:
Did you know that the email spec allows you to use youremail+something@domain.com and the emails still come to you. This is especially useful when registering to a lot of places where you are not sure whether they will spam you or not. Filtering will be easy because you have a unique email address for each service. Also you can find out which service leaked your email address to spammers.
Additionally if you want to register to a service with two accounts but still want to use the same email, you can do this easily by adding +whatever in your email address.6 -
TL; DR: Bringing up quantum computing is going to be the next catchall for everything and I'm already fucking sick of it.
Actual convo i had:
"You should really secure your AWS instance."
"Isnt my SSH key alone a good enough barrier?"
"There are hundreds of thousands of incidents where people either get hacked or commit it to github."
"Well i wont"
"Just start using IP/CIDR based filtering, or i will take your instance down."
"But SSH keys are going to be useless in a couple years due to QUANTUM FUCKING COMPUTING, so why wouldnt IP spoofing get even better?"
"Listen motherfucker, i may actually kill you, because today i dont have time for this. The whole point of IP-based security is that you cant look on Shodan for machines with open SSH ports. You want to talk about quantum computing??!! Lets fucking roll motherfucker. I dont think it will be in the next thousand years that we will even come close to fault-tolerant quantum computing.
And even if it did, there have been vulnerabilities in SSH before. How often do you update your instance? I can see the uptime is 395 days, so probably not fucking often! I bet you "dont have anything important anyways" on there! No stored passwords, no stored keys, no nothing, right (she absolutely did)? If you actually think I'm going to back down on this when i sit in the same room as the dude with the root keys to our account, you can kindly take your keyboard and shove it up your ass.
Christ, I bet that the reason you like quantum computing so much is because then you'll be able to get your deepfakes of miley cyrus easier you perv."8 -
I wrote an app (took all morning until now) that tells me which shows and movies Amazon removed from Prime...
I forget why I wanted this... was it just to screw with Amazon because they rejected me....
The app is also going to tell me what movies/shows were added because they can't fucking sort them in chronological order by release date. I don't want movies from pre-1990s that were recently added...
Yes I could search for them manually but it's too fuckin tedious, gotta turn on like 10 filtering options...
And maybe I just want to run mini-DDOS attacks on their servers... 13
13 -
Woke up this morning to a fucking giant snowstorm and my first reaction was 'fml' , poured some coffee , lit a smoke and started checking my work mail 'Issue xxxx response : Not solvable '...what the...I go through the files on my phone , look at what that issue was : lack of proper validation , filtering and encoding of input thus enabling xss . Not solvable my ass ...simply adding literally 3 more characters to that fucking retarded filter would stop all the bypasses . This issue is a showstopper for their project and that is what they answer ?
Sorry to indians out here but some of your colleagues are as stupid and unimaginative as they can possibly ever come .8 -
So I wanted to update my visual studio. Turns out I cant because WPF (Apparently the Installers uses it) has a problem with broken fonts.
Okay. No problem I thought. I uninstalled all 720 fonts and re-registered them, filtering out the 3 broken ones. Checked the time-stamp as suggested. Everything fine. Had to reboot. (Of curse.)
Rechecked the fonts, reports as okay. Tried to start the installer BUT THIS FUCKING PIECE OF SHIT SOFTWARE CRASHES ON ME AGAIN WITH THE SAME FOCKING ERROR. IT DOESN'T EVENT WANT TO FUCKING TELL ME WHICH FUCKING FONT IS THE PROBLEM. I CHECKED EVERYYYY SINGLE FUCKING FONT. NOT THAT THERE IS NO FUCKING WAY TO FUCKING CATCH A FUCKING FUCKER EXCEPTION IN THIS FUCKING WORLD. I mean seriously. Why would you crash on a font THAT YOU DON'T EVEN USE IN YOUR FUCKING FUCK PROGRAMM TO INSTALL YOUR FUCKING PICE OF SHIT SOFTWARE.
But, IT GETS WORSE. TURNS OUT MICKY FUCKING SOFT KNOWS ABOUT THIS FUCKING BUG SINCE TWO-FUCKING-THOUSAND-FOURTEEN.
And they didn't fixed it. Nooooooooo. THEY FUCKING WROTE A FUCKING WORKAROUND THAT DOES NOT FUCKING WORKKKKKK AND KEEP PUTTING THIS FUCKING BUG IN EVERY FUCKING INSTALLER SINCE THEN.
Can you tell I'm pissed? YES? GOOOOOOD. BECAUSE I FUCKING AM.
MICKYSOFT CAN GO AND SUCK A FUCKING APPROPRIATE THING TO SUCK IN THIS FUCKING SITUATION.
THE BEST? THEY EVEN FUCKING DARE TO ASK ABOUT MY FUCKING FEEDBACK. YOU KNOW WHAT? YOU GET MY FUCKING FEEDBACK. TOGETHER WITH A FUCKING BAG FULL OF FUCKING SHIT TO YOUR FUCKING HQ
CAN I HAVE A FUCKING STRESSBALL NOW
</rant> 3
3 -
On my personal journey to better privacy!
Wanted to change to Qubes, but since I wind down with games, that won't happen sadly and it seems windows still doesn't support proper gpu passthrough either, so might eventually change to linux host and windows guest or create a VM I use for everything else that isn't gaming, since I still really love the idea of having a snapshot backup system.
So since that isn't quite in my timeframe right now though: first move was to move to firefox, already done the change on mobile (love having dark reader and ublock on mobile!), now setting it all up on desktop, pleasant surprise was for sure that firefox finally seems to have chromes devtools pretty much mirrored, even the mobile suite of tools.
Loading of pages is also finally fast and much snappier than chrome from the first testing I could do (on desktop, on mobile it still kind of sucks in comparison, but I can deal with that).
Please suggest me all sort of privacy tools you got, especially with firefox in mind, but also host tools, be it windows or linux (e.g. some sort of traffic obfuscator that visits random pages that are SFW but make automatic traffic filtering hard, could probably make my own, but if there's something like that already, why not), I'll save all I can use.44 -
!activism
Guys, what should we do about Article 13 ?
The bill passed, well, that's unfortunate. We can still scream as loud as we can that it's a very bad idea, but let's face it, it won't probably work...
Personally, I'm sick of this shit. Every year they try to "regulate" the web with a new fucked-up legislation that they actually don't understand. I don't blame them for not knowing any better, but I blame them not to surround themselves with actually competent people (and no, lobbies are NOT competent, only interested).
So there it is : I want to act on this one. With traditional, ineffective methods (petitions, mails...), but I want to get further this time.
Here are some ideas :
- create/promote a platform explicitly made for "copyrighted" stuff (basically memes). Located outside of EU. But is it enough for being outside of the law ?
- Put some physical-paper memes near the EU parliament (I live in Brussels), just to mess with them ^_^
- Make the filtering algorithms crazy by spamming them with copyrighted content. I doubt this one will have any effect though...
Any ideas ? Let's go crazy there, they deserve it.8 -
I wrote a node + vue web app that consumes bing api and lets you block specific hosts with a click, and I have some thoughts I need to post somewhere.
My main motivation for this it is that the search results I've been getting with the big search engines are lacking a lot of quality. The SEO situation right now is very complex but the bottom line is that there is a lot of white hat SEO abuse.
Commercial companies are fucking up the internet very hard. Search results have become way too profit oriented thus unneutral. Personal blogs are becoming very rare. Information is losing quality and sites are losing identity. The internet is consollidating.
So, I decided to write something to help me give this situation the middle finger.
I wrote this because I consider the ability to block specific sites a basic universal right. If you were ripped off by a website or you just don't like it, then you should be able to block said site from your search results. It's not rocket science.
Google used to have this feature integrated but they removed it in 2013. They also had an extension that did this client side, but they removed it in 2018 too. We're years past the time where Google forgot their "Don't be evil" motto.
AFAIK, the only search engine on earth that lets you block sites is millionshort.com, but if you block too many sites, the performance degrades. And the company that runs it is a for profit too.
There is a third party extension that blocks sites called uBlacklist. The problem is that it only works on google. I wrote my app so as to escape google's tracking clutches, ads and their annoying products showing up in between my results.
But aside uBlacklist does the same thing as my app, including the limitation that this isn't an actual search engine, it's just filtering search results after they are generated.
This is far from ideal because filter results before the results are generated would be much more preferred.
But developing a search engine is prohibitively expensive to both index and rank pages for a single person. Which is sad, but can't do much about it.
I'm also thinking of implementing the ability promote certain sites, the opposite to blocking, so these promoted sites would get more priority within the results.
I guess I would have to move the promoted sites between all pages I fetched to the first page/s, but client side.
But this is suboptimal compared to having actual access to the rank algorithm, where you could promote sites in a smarter way, but again, I can't build a search engine by myself.
I'm using mongo to cache the results, so with a click of a button I can retrieve the results of a previous query without hitting bing. So far a couple of queries don't seem to bring much performance or space issues.
On using bing: bing is basically the only realiable API option I could find that was hobby cost worthy. Most microsoft products are usually my last choice.
Bing is giving me a 7 day free trial of their search API until I register a CC. They offer a free tier, but I'm not sure if that's only for these 7 days. Otherwise, I'm gonna need to pay like 5$.
Paying or not, having to use a CC to use this software I wrote sucks balls.
So far the usage of this app has resulted in me becoming more critical of sites and finding sites of better quality. I think overall it helps me to become a better programmer, all the while having better protection of my privacy.
One not upside is that I'm the only one curating myself, whereas I could benefit from other people that I trust own block/promote lists.
I will git push it somewhere at some point, but it does require some more work:
I would want to add a docker-compose script to make it easy to start, and I didn't write any tests unfortunately (I did use eslint for both apps, though).
The performance is not excellent (the app has not experienced blocks so far, but it does make the coolers spin after a bit) because the algorithms I wrote were very POC.
But it took me some time to write it, and I need to catch some breath.
There are other more open efforts that seem to be more ethical, but they are usually hard to use or just incomplete.
commoncrawl.org is a free index of the web. one problem I found is that it doesn't seem to index everything (for example, it doesn't seem to index the blog of a friend I know that has been writing for years and is indexed by google).
it also requires knowledge on reading warc files, which will surely require some time investment to learn.
it also seems kinda slow for responses,
it is also generated only once a month, and I would still have little idea on how to implement a pagerank algorithm, let alone code it. 4
4 -
While I work on my devRant client, I always end up thinking, "how would dfox do it for the backend".
Some of the functions I have include:
-fetching new rants, 250 at a time
-remembering the ones I've read and filtering those out (kinda similar to Algo)
-checking for updates from followed users and new notifications
My implementions are kinda spammy though part of it is because I need to use the existing API.
But even so, how would/does he implement these so all the users' requests don't end up bringing down the server, and efficiently store and retrieve everyone's view history?
My problems are small compared to his... How do you think and deal with problems at that scale though? -
Bring the fun and curiosity back.
School education? Mostly rinse and repeat, learn from heart and do as you are told.
First job? Take these bread crumbs, shit out gold ingots, please.
There are few who had either very kind and gifted teachers / persons in their life or had a strong will / desire to learn by / for themselves - but it's hard to combine fun and curiosity with the - most of the time - very harsh reality and environment we live in.
I'd really wish that it would get back to fun and curiosity and not the endless myriad of bitching, hissing and fighting it usually is.
What I find most tiresome in education is the overflow of information with no value - most content is outdated, wrong, harmful, not precise and especially not helpful.
Thinking about good education I've got very fond memories of hanging out in IRC chats, talking with people who were "ancient" (la me 15-20, them 40 plus ;) ) and not being "shood" away, but rather getting fed by book recommendations, hints, appointments when they had more spare time to explain in private IRC sessions etc.
The atmosphere was always a "we might not have time for it, but we'll try and don't worry if you don't understand it".
When I'm trying to find information today... It's really 90 - 95 % filtering, 4 % try and error, 1 % finding what I need.3 -
Two big moments today:
1. Holy hell, how did I ever get on without a proper debugger? Was debugging some old code by eye (following along and keeping track mentally, of what the variables should be and what each step did). That didn't work because the code isn't intuitive. Tried the print() method, old reliable as it were. Kinda worked but didn't give me enough fine-grain control.
Bit the bullet and installed Wing IDE for python. And bam, it hit me. How did I ever live without step-through, and breakpoints before now?
2. Remember that non-sieve prime generator I wrote a while back? (well maybe some of you do). The one that generated quasi lucas carmichael (QLC) numbers? Well thats what I managed to debug. I figured out why it wasn't working. Last time I released it, I included two core methods, genprimes() and nextPrime(). The first generates a list of primes accurately, up to some n, and only needs a small handful of QLC numbers filtered out after the fact (because the set of primes generated and the set of QLC numbers overlap. Well I think they call it an embedding, as in QLC is included in the series generated by genprimes, but not the converse, but I digress).
nextPrime() was supposed to take any arbitrary n above zero, and accurately return the nearest prime number above the argument. But for some reason when it started, it would return 2,3,5,6...but genprimes() would work fine for some reason.
So genprimes loops over an index, i, and tests it for primality. It begins by entering the loop, and doing "result = gffi(i)".
This calls into something a function that runs four tests on the argument passed to it. I won't go into detail here about what those are because I don't even remember how I came up with them (I'll make a separate post when the code is fully fixed).
If the number fails any of these tests then gffi would just return the value of i that was passed to it, unaltered. Otherwise, if it did pass all of them, it would return i+1.
And once back in genPrimes() we would check if the variable 'result' was greater than the loop index. And if it was, then it was either prime (comparatively plentiful) or a QLC number (comparatively rare)--these two types and no others.
nextPrime() was only taking n, and didn't have this index to compare to, so the prior steps in genprimes were acting as a filter that nextPrime() didn't have, while internally gffi() was returning not only primes, and QLCs, but also plenty of composite numbers.
Now *why* that last step in genPrimes() was filtering out all the composites, idk.
But now that I understand whats going on I can fix it and hypothetically it should be possible to enter a positive n of any size, and without additional primality checks (such as is done with sieves, where you have to check off multiples of n), get the nearest prime numbers. Of course I'm not familiar enough with prime number generation to know if thats an achievement or worthwhile mentioning, so if anyone *is* familiar, and how something like that holds up compared to other linear generators (O(n)?), I'd be interested to hear about it.
I also am working on filtering out the intersection of the sets (QLC numbers), which I'm pretty sure I figured out how to incorporate into the prime generator itself.
I also think it may be possible to generator primes even faster, using the carmichael numbers or related set--or even derive a function that maps one set of upper-and-lower bounds around a semiprime, and map those same bounds to carmichael numbers that act as the upper and lower bound numbers on the factors of a semiprime.
Meanwhile I'm also looking into testing the prime generator on a larger set of numbers (to make sure it doesn't fail at large values of n) and so I'm looking for more computing power if anyone has it on hand, or is willing to test it at sufficiently large bit lengths (512, 1024, etc).
Lastly, the earlier work I posted (linked below), I realized could be applied with ECM to greatly reduce the smallest factor of a large number.
If ECM, being one of the best methods available, only handles 50-60 digit numbers, & your factors are 70+ digits, then being able to transform your semiprime product into another product tree thats non-semiprime, with factors that ARE in range of ECM, and which *does* contain either of the original factors, means products that *were not* formally factorable by ECM, *could* be now.
That wouldn't have been possible though withput enormous help from many others such as hitko who took the time to explain the solution was a form of modular exponentiation, Fast-Nop who contributed on other threads, Voxera who did as well, and support from Scor in particular, and many others.
Thank you all. And more to come.
Links mentioned (because DR wouldn't accept them as they were):
https://pastebin.com/MWechZj912 -
A dev adds a nice range of categories that content creators can select from. Users get a neat filtering system to restrict the unwanted content.
And then...! People post everything in default category.3 -
TL;DR: Stop using React for EVERYTHING. It's not the end-all solution to every application need.
My team is staffed about 50/50 with tenured devs, and junior devs who have never written a full application and don't understand the specific benefits of different libraries/framworks. As a result, most of these junior devs have jumped on the React train, and they're under the impression that React is the end-all answer to any possible application need. Doesn't matter what type of app is, what kind of data is going to be flowing through the app, data scale, etc. In their eyes, React is always the answer. Now, while I'm not a big fan of React myself, I will say that it does its job when its tasked with a data-heavy application that needs to be refreshed/re-rendered dynamically and frequently (like Facebook.) However, my main gripe is that some people insist on using it for EVERYTHING. They refuse to acknowledge that there can be better library/framework choices (Angular, Vue, or even straight jQuery,) and they refuse to learn any other frameworks. You can hit them with countless technical reasons as to why React isn't a good choice for a particular application, and they'll just spout off the same tidbits from the "ReactJS Makes My Nips Hard 101" handbook: "React is the future," "Component-based web architecture is the future," (I'm not arguing with that last one) "But...JSX bro.," "Facebook and Netflix use it, so that's how you know it's amazing." They'll use React for a simple app, and make it overly-complex, and take months to write something that should have taken them a week. For example, we have one dev who has never used any other frameworks/libraries apart from React, and he used React (via create-react-app) to write what is effectively a single form and a content widget inside of a bootstrap template. It took him 4 MONTHS to write this, and it still isn't fully functioning. The search functionality doesn't really work (in fact, it's just array filtering,) and wont return any results if you search for the first word in an entry. His repo is a mess, filled with a bunch of useless files that were bootstrap'd in via create-react-app. We've built apps like this in a week in the past using different libraries/frameworks, and he could have done the same if he didn't overly-complicate the project by insisting on using React. If your app is essentially a dynamic form, you don’t need a freaking virtual DOM.
This happens every time a big new framework hits the scene. New young developers get sucked into it, because it's the cool hip new framework (or in React's case, library.) and they use it for everything, even when it's not the best choice. It happened with Angular, Rails, and now it's happening with React.
React has its benefits, but please please please consider which library/framework is the best choice from a technical standpoint before immediately jumping on the React train because "Facebook uses it bro."2 -
When you actually use your knowledge and experience to solve a problem outside work, that's a real nice feeling. Had to distribute a bunch of files, so just threw together a Vue page in 20 min. Fully interactive with filtering and all. Nice!2
-
I've had a couple of interviews that were bad because I fluffed them, but the worst was a 4 stage process I went through a while back.
Development hub for an international org, 1st stage was a phone call with high level questions. Stage 2 were online coding tests, which I passed. Third - another phone call. Finally, a visit to the office. I was informed that I was the only one to get this far after the other filtering. This is where it all went wrong.
I'd been led to believe this would be a reasonably informal chat (around an hour or so) to fill in some of the detail of what I'd already been given. It wasn't. It turned into 2+ hours of the most intense grilling I've ever had. Felt like I'd gone 12 rounds by the end. Another coding test in the middle of it. The interviewer seemed to be enjoying the opportunity to show that he knew much more than me and seemed to be trying to catch me out, rather than really discover what I knew.
By the end of it, I didn't want the job and I didn't want to report directly to someone who seemed to thrive on making life difficult to boost his own ego.1 -
It wasn't exactly a meeting, just boss' boss coming into our office to ask about a feature. Went something like this (BB - boss' boss (or Big Bitch, whichever you prefer, Me, SP - second programmer) :
BB: Hey guys, I've got a question.
Me (without turning around since I was focused on whatever I was doing at the time) : Sure, go ahead.
BB: Could we do a country map where you would be able to click a region and get to a page with posts for that region?
Me (without pausing what I was doing) : Sure, easy. Html imagemap, or embedded flash if it's supposed to be fancy and animated.
BB: ...how would we do it?
Me (in exactly the same tone of voice, trying to mimic the same sound sample being played again) : Html imagemap, or embedded flash if it's supposed to be fancy and animated... Links leading to the same address as the filtering form for regions already goes. All that's needed is the map graphic.
BB: ...but how would we link to the correct results? Would we need to make new page for those?
Me: *sigh*
At this point SP stops doing whatever he was doing, proceeds to sit next to her by the whiteboard, and they proceed to talk about this for about 45 minutes, which to this day, I have no idea how they managed. I had no idea how they managed to stretch it for this long even as I was listening to them talking and drawing stuff on the whiteboard about it.
Afterwards, I've been reprimanded for not paying proper attention when important stuff was being solved, and a month later when I was being fired, I had been reprimanded for it once again.
Fuck that company. Fuck those people.
I have no idea how they managed to still not go bankrupt.15 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!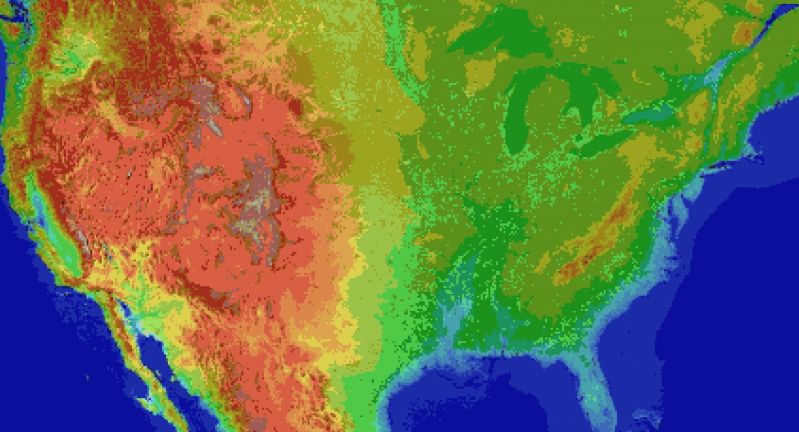 5
5 -
Regarding Article 13 (or 17 or wherever it moved to now)… Let's say that the UK politicians decide to be dicks and approve the law. After that, we need to get it engineered in, right? Let's talk a bit about how.. well, I'd maybe go over it. Been thinking about it a bit in the shower earlier, so.. yeah.
So, fancy image recognition or text recognition from articles scattered all over the internet, I think we can all agree.. that's infeasible. Even more so, during this lobby with GitHub and OpenForum Europe, guy from GitHub actually made a very valid point. Now for starters, copyright infringement isn't an issue on the platform GitHub that pretty much breathes collaboration. But in the case of I-Boot for example, that thing from Apple that got leaked earlier. If that would get preemptively blocked.. well there's no public source code for it to get compared against to begin with, right? So it's not just "scattered all over the internet, good luck crawling it", it's nowhere to be found *at all*.
So content filtering.. yeah. Nope, ain't gonna happen. Keep trying with that, EU politicians.
But let's say that I am a content creator who hates the cancer of joke/meme because more often than not it manifests itself as a clone of r/programmerhumor.. someone decides to freeboot my content. So I go out, look for it, find it. Facebook and the likes, make it easier to find it in the first place, you dicks. It's extremely hard to find your content there.
So Facebook implements a way to find that content a bit easier maybe. Me being the content creator finds it.. oh blimey! It can't be.. it's the king of freebooting on Facebook, SoFlo! Who would've thought?! So at that point.. I'd like to get it removed of course. Report it as copyright infringement? Of course. Again Facebook you dicks, don't make it so tedious to fill in that bloody report. And look into it quickly! The videos those SoFlo dicks post is only relevant in the first 48h or so. That's where they make the most money. So act more quickly.
So the report is filled, video's taken down.. what else? Maybe temporarily make them unable to post as a bit of a punishment so that they won't do it again? And put in a limit to the amount of reports they can receive. Finally, maybe reroute the revenue stream to the original content creator instead. That way stolen content suddenly becomes free exposure! Awesome!
*suddenly realizes that I've been talking about the YouTube copyright strike system all along*
… Well.. maybe something like that then? That shouldn't be too hard to implement, and on YouTube at least it seems to be quite effective. Just imagine SoFlo and the likes that are repeat offenders, every 3 posts they get their account and page shut down. Good luck growing an audience that way. And good luck making new accounts all the time to start with.. account verification technology is pretty good these days. Speaking of experience here, tried bypassing Facebook's signup hoops a fair bit and learned a bit about some of the things they have red flags on, hehe.
But yeah, something like that maybe for social media in general. And.. let's face it, the biggest one that would get hurt by something like this would be Facebook. And personally I think it's about time for that bastard company to get a couple of blows already.
What are your thoughts on this?5 -
!dev
Fuck you google!!
Let me send a mail to my shitty internet service provider with abusive words as much as possible.
Fucking gmail rejecting my message as spam by content filtering.6 -
Context: I (among other things) manage some servers for my students' club so I have first-hand information about anything network or server-related that happens. We basically run a big enterprise network and we allow devices to connect if a person has paid their membership and the device's MAC address (be it wireless or ethernet) is recognized by our switches/aruba controllers.
Story: So today a first complaint about "the wifi not working" came in because of Android 10 and its MAC randomization. We deal with MAC randomization on Windows laptops and PCs but I think it is disabled by default so we almost never get this type of complaint.
It took one of the other guys probably 5 minutes to figure out how to disable it... only to discover it is a per-network setting.
The actual question: If there are any network administrators here on devRant - how do you deal with this MAC filtering vs MAC randomization issue?7 -
That moment when your *new* blue light filtering *glasses* are actually cheap plastic and has permanent smudges on it.
Don't be cheap on eyewear, guys.4 -
Describing a friend's project to a friend:
"And then theirs a tinder like element, for filtering potential dates, but that's not implemented yet."
"Why doesn't he just copy tinder?"
"Er... wat?"
"You know, just copy their code and put it in his app."
"You don't... you can't... I mean you can decompile... but that's not useful because... it just doesn't work that way. For a million reasons. I don't know where to begin."3 -
I’m fucking lost.
So, situation. I have a SQL table with about 3M rows (not a lot).
I have indexes. Indexes are used. BUT when I add where clause (On indexed column), it’s super slow. Around 10 seconds.
If I do select * (ALL 3M rows) and THEN I filter then on webserver side, it takes 0.5 seconds.
HOW my manual filtering is faster than DB filtering with indexes? I even tried bubble sort. Bubble sort is faster than SQL ‘where’. HOW ?!
I do not understand….
And if I add group by….. WELL, 25 seconds SQL time. 2 Seconds if I do select all and group by in code manually.
Does not make ANY sense to me.
What am I missing ?21 -
Interviewed for a Mid/Senior developer role and finally got feedback. The company feels I'm not experience enough for the senior role but think I'm a good fit for the company. Bad thing is they don't have any entry level positions available. I honestly feel like I am ready for a mid level role and maybe even a senior role. They say to keep considering them while they try to get approval for entry level position, but this is a massive company and who knows how long that will take. Recruiter said it's not a no, just not a right now. /:
Oh and going off my last rant, I found out that the senior dev was wrong about set interception being '|' in python, I found out that it's actually a method called interception(set). So even the senior dev didn't know off the top of his head. /:
Have some projects in GitHub but my biggest one is a private repo I'm doing the entire backend and even frontend. Can't share that repo or share details because it's a project a friend (his idea) and I are planning on releasing. (:
Overall feeling pretty bummed because I was looking forward to steady work that'll improve my skills even further... I'm self taught so it's a bit tougher to land interviews because of the automated process most companies have with resume filtering. ):
Going to keep doing small contracted projects until I land another interview. In the meantime trying to keep my spirit up. (:1 -
So, by a cruel twist of fate I ended up on the front line of tech support for the app we've built. It's aimed at non-IT professionals, in general people who are not expected to know too much about computers but who should have at least two neurons to bash together in their pretty little heads.
No.
It really makes me drop my faith in humanity considerably. Clicking a confirmation link is too much. Filtering an excel sheet is too hard, despite it being their technically main work tool. Tickets are basically "shit's broken go fix". What is broken? How to reproduce it? Why do you expect the person on the other side of the screen to be a fucking diviner? I recently ran all out of dove guts to search for the answers of your questions.4 -
Colleague asked me to look at his eCommerce search filtering system as the customer was complaining it was slow taking 5-6 seconds to find results.
Delving into the code deeper, I discovered he was querying the results, sticking them in an array and then sub querying the results looking at all the combinations.
On top of that each sub query looked at the database fields using "DESCRIBE" to then search them each time it found a pair!
The total query count for one page search was 14,512!!!
Why oh Why? One SQL query could of done all that in one go.
I look at other code bits he's done and he's very good in other areas. I just don't get how sometimes a good developer can make such a weird decision? It's almost as if he wanted to make it as complex as possible.4 -
Just some random thoughts looking at the soon-to-be new filtering feature.
Wouldn't it be nice if DevRant had a QR login like WhatsApp for easy login on desktop?
What about a "top rants" on profiles?
Oh what about an activity mosaic like GitHub's commit timeline?
Just some thoughts I had while punching my punching bag, it can get tedious.5 -
Gmail filtering sucks but i just realized something.... i have an app for this... i just need to copy an existing project and change the code!
 5
5 -
I had my presentation early morning, it was 3am, and I was still up because the code was not compiling. Then showed up my roommate who had gone for party. Can't believe that he was the one, in the half drunk state, was able to find just a short typo,but not ME, EVEN THOUGH I HAD 3 CUPS OF COFFEE the same night. Lesson learned. Patience is a virtue. Blessed to have a nice roommate. :)
PS. It was a Matlab code for filtering the mentioned portion of an ECG Signal, and analysing the problem faced by the patient. Well, I was pretty sure to get arrhythmia if I couldn't complete the code by morning. -
Uh-oh I fucked up.
Not at work, but with my website where I had an email forwarder to an external address. The forwarding was everything so that I could do the spam filtering and occasional check in one place. Unfortunately, that triggered the spam detection at the external address (after some years!), and my provider ended up on a blacklist.
That got me a pretty angry mail from my hosting provider who had already disabled the forwarding and wanted to make sure that I understood the issue and would not put it in again.
I thought about whether they had fucked up because it was even possible to do that, or whether I had fucked up because I should have known. Hm yeah I opted for the latter and apologised.
The support guy seemed happy that I didn't try to argue (possibly like other customers...), and advised that I just should add another account in my email client. Sure, at least that will prevent this shit from happening again.
He also mentioned that every single blacklist issue they had experienced in this year was accidental due to external forwarding issues and that they would consider just disabling it altogether.
Which is probably a smart move, just as hint for these ranters here who work at hosting companies. Or at least only enable external forwarding if spam assassin or so is in place.3 -
Am I crazy ?
Right now we have an API which returns a full planning for a week for 300 employees with indicators (Like "late", "may be postponed" etc) in 4 seconds.
I have a pressure, people telling me it's not fast enough.
I honestly think it is fast.
In order of data it'a around 100 MB of JSON. AND you can do actions on the whole set if needed.
Long story short, I think 4 seconds to get all that data is pretty great. Customers think they should have it instantly.
(Never mind the whole filtering system at thier disposal, they literall only lod the full set and then MANUALLY scroll (Yes there is a quick search box)).
What can I do more ????? cache that ? I can. But they also expect that any changed value is reflected.
And we fucking do it. While you are on the page there is a SignalR conenxion created and notified when any of data is changed and updates it on front. Takes around 500 ms.
Apprently "too slow".
I honestly don't see what we can do more with our small 4 dev team.
Give me 56 developpers I can do something, but right now I'm proud of result.14 -
When I was in college I was approached by an entrepreneur whose "search engine" idea consisted of scraping the search results of Google and posing them as his own results (after a little shuffling and filtering). Needless to say I declined.2
-
when KhronosGroup anounced Vulkan back then, they also announced a whole set of software, that can handle all the new formats, that they introduced.
One format in particular peaked my interest recently, which is ktx2. It's an image format, that can be multilayered, and supercompressed, has inline mipmapping, and most importantly: streamed directly to the GPU, without involving the CPU basically at all.
Now here comes the kicker. If i want to use this format (mind you: Vulkan is around for a while now) for creating Skyboxes, there is only a single tool, that can properly convert hdr images to ktx2, and it only works on windows. Oh and there are no binaries, so in every case you have to compile it yourself.
Ah and then i thought, okay what if i then already render the cubemap faces and assemble them by hand into the cubemap, because _some_ ktx tools work on linux, then that should work right? wrong. When assembling it, it turns out, that now it's a 2D image instead of a 2DArray image with one element (which apparently is not the same for skyboxes)
Why is this shit such a pain in the ass?
Like.. I'm currently rendering equirectangular hdr images on my linux machine, then move these (usually 100MB) files over to some windows PC, convert it there into ktx2 cubemaps and then move it back. And everytime i need to do a change on the skybox, i have to repeat this whole nonsense. Ah.. and this tool doesn't even properly work on Windows, like you can't just disable mipmaps or change the filtering, because then the skybox is just black for some reason.
The funniest thing is, at the end of the day, these ktx2 files work on linux, as well as windows, mac and even mobile platform, so there's really no reason, that the conversion tool only works on one of them systems.
But hey, at long last i got them working, and this stuff looks quite nice now 👌2 -
The company that manages my ISA for Lambda emails on a regular basis to get you to update your income. I got annoyed by the frequency while I was employed so started filtering everything.
Though I’ve been up to date with reporting income to them and submitting tax documents, etc, I apparently missed some important emails.
Like the one on the 4th saying a third party provider flagged by account for employment with CompanyA and that I needed to submit my pay stubs for CompanyA.
I do not and have never worked for CompanyA. My husband works for CompanyA.
I also missed the email from the 12th saying I’m in breach of contract and owe them $19,091.65 immediately.
*head desk*
I’m so mad I can’t even.
Why did i check my email before going to sleep?
AND I POSTED RECENTLY SO I CAN’T EVEN RANT YET. *
*Waited it out -
Instagram should adapt devrant's filtering! Give us the choice of algorithm, recent, and top. Give us back our freedom! 😂3
-
In the 90s most people had touched grass, but few touched a computer.
In the 2090s most people will have touched a computer, but not grass.
But at least we'll have fully sentient dildos armed with laser guns to mildly stimulate our mandatory attached cyber-clits, or alternatively annihilate thought criminals.
In other news my prime generator has exhaustively been checked against, all primes from 5 to 1 million. I used miller-rabin with k=40 to confirm the results.
The set the generator creates is the join of the quasi-lucas carmichael numbers, the carmichael numbers, and the primes. So after I generated a number I just had to treat those numbers as 'pollutants' and filter them out, which was dead simple.
Whats left after filtering, is strictly the primes.
I also tested it randomly on 50-55 bit primes, and it always returned true, but that range hasn't been fully tested so far because it takes 9-12 seconds per number at that point.
I was expecting maybe a few failures by my generator. So what I did was I wrote a function, genMillerTest(), and all it does is take some number n, returns the next prime after it (using my functions nextPrime() and isPrime()), and then tests it against miller-rabin. If miller returns false, then I add the result to a list. And then I check *those* results by hand (because miller can occasionally return false positives, though I'm not familiar enough with the math to know how often).
Well, imagine my surprise when I had zero false positives.
Which means either my code is generating the same exact set as miller (under some very large value of n), or the chance of miller (at k=40 tests) returning a false positive is vanishingly small.
My next steps should be to parallelize the checking process, and set up my other desktop to run those tests continuously.
Concurrently I should work on figuring out why my slowest primality tests (theres six of them, though I think I can eliminate two) are so slow and if I can better estimate or derive a pattern that allows faster results by better initialization of the variables used by these tests.
I already wrote some cases to output which tests most frequently succeeded (if any of them pass, then the number isn't prime), and therefore could cut short the primality test of a number. I rewrote the function to put those tests in order from most likely to least likely.
I'm also thinking that there may be some clues for faster computation in other bases, or perhaps in binary, or inspecting the patterns of values in the natural logs of non-primes versus primes. Or even looking into the *execution* time of numbers that successfully pass as prime versus ones that don't. Theres a bevy of possible approaches.
The entire process for the first 1_000_000 numbers, ran 1621.28 seconds, or just shy of a tenth of a second per test but I'm sure thats biased toward the head of the list.
If theres any other approach or ideas I may be overlooking, I wouldn't know where to begin.16 -
Microsoft.Graph has filtering capabilities for dates, which is great.
Format is: "2018-04-12T12:00:00Z"
Doesn't natively support string conversion of a DateTime to match the pattern... Nor does Graph accept any date formats such as the "s" parameter for sortable dates, which goes into milliseconds, etc.
DateTime.ToString("derp");
Sometimes I wish I was a Java Dev.1 -
The one time I post to Stack Overflow for the answer to the problem I found get downvoted. WTF. There's so much filtering and elitism on that site.
Back to being a lurker.4 -
Shopping still keeps being an annoying task in the web age. The research for what i actually want is fine.
But it is a so damn timewasting and boring experience to sift through all that search results filtering out the non-results and overprized hippster shops first, then trying to find the best matching product on each remaining shop...
They all let you sort by price but not even one offers sorting by price per kilo and only a few offer some sort of product detail filter (which often omit relevant products because of insufficient tagging)...
The last part is rather easy though: compare properties of best matching offers and use the shop with the best offer.
P.S.:
I am fully aware of the fact, that part of the problem is my obsession in buying the correct thing combined with a cheapskate mentality.
So don't comment about just picking the first sorta-matching offer as that certainly would be way too easy (and cheaper because time is somehow money too).1 -
"when you are filtering by [field] actually don't filter and display the stuff in the list, just make it impossible for the user to purchase at checkout."
... Why do we even have filters then? :/
I get some marketing guy believes making the user do the whole process helps sales, but...
1) In reality this just makes users not use your website and go on a competitor's
2) this is doable if you have 2-3 entries, not on 100+ entries, duh! -
Despite having programmed for quite a few years now, for some reason I keep thinking the filter function's predicate needs to be true for things you want to exclude, not things you want to include...
catalogue.filter(i -> i.quantity < 1)
was what I just tried to do when I wanted to fetch all the items still in stock... Why am I like this?10 -
My client had a meeting and presentation of app for one possible client of that app. I, as a developer of that app, left a hardcoded id,I saw it but forgot about it immediately. Let's just say filtering did not work properly. Sorry.1
-
Hi guys. It's unicorndev again.✨
Yesterday I made a post on a CLI app that brings your Github feed to the terminal. And the response from you guys was very nice. Since that was the initial release there were some minor bugs and issues left. So I just released v1.2.2 with some of these issues fixed ex:
- Filtering out depandabot events.
- Detecting Github user name the right way.
- Adding update notifier for future releases.
If you installed the tool yesterday then please update it to the latest version. Thanks :)
https://github.com/RocktimSaikia/...2 -
I need some time off. Just had this convo with a dev-manager about an 'issue' with our system change mgmt calendar (Blazor) app.
K: "In the system drop-down, it's not filtering when I type."
Me: "Let me check <I attempt to reproduce>, yep, not working. Do you get the same error? Looks like duplicate data from the database is causing a problem."
<this is over MS Teams, about 5 minutes go by with no response, then>
K: "No error, its not working."
<I find the bad data, delete it, TADA, the filtering is working again>
Me: "The filtering is working again, at least for me. You sure you didn't see an error?"
<wait 5 minutes again>
K: "No, no error."
Me: "You didn't see a little red banner at the bottom and in all caps..ERROR"
<send him a screen-shot of the error I still had in another tab>
K: "Yes, I saw that one, but no other errors. Filtering is working again. Thanks"3 -
So while exploring some new ideas, I decided to figure out if I could use variables in the known set to determine the bounds of variables in the unknown set.
The variables in question are algebraic identities derived from the semiprimes, so you already know where this is going.
The existing known set is 1194 identities.
And there are, if I recall, roughly two dozen unknowns.
Many knowns have the unknowns as their factors. The d4 product set for example is composed of variables d4a, d4u, d4z, d4z9, d4z4, d4alpha, d4theta, d4omega, etc.
The component variables themselves are unknown, just their products are known. Anyway.
What I've found interesting is if you know the minimum of some of these subsets, for example d4z is smallest out of the d4's for some semiprimes, then you know the upperbound of both the component variables d4 and z.
Unless of course either of them is < 1.
So the order of these variables, based on value, changes depending on the properties of the semiprime, which I won't get into. Most of the time the order change is minor, but for some variables they can vary a lot between semiprimes, rapidly shifting their rank in the known set. This makes it hard to do anything with them.
And what I found myself asking, over and over again, was if there was a way to lock them down? Think of it like a giant switch board, where flipping one switch lights up N number of others, apparently at random. But flipping some other switch completely alters how that first switch works and what lights it seemingly interacts with. And you have a board of them thats 1194^2 in total. So what do you do?
I'd had a similar notion a while back, where I would measure relative value in the known set, among a bunch of variables, assign a letter if the conditions were present, and generate a string, called a "haplotype."
It was hap hazard and I wrote a lot of code to do filtering, sorting, and set manipulation to find sets of elements in common, unique elements, etc. But the 'type' strings, a jumble of random letters, were only useful say, forty percent of the time. For example if a semiprime had a particular type starting with a certain series of letters, 40% of the time a certain known variable was guaranteed to be above a certain variable from the unknown set...40%~ of the time.
It was a lost cause it seemed.
But I returned to the idea recently and revamped the entire notion.
Instead what I would approach it from a more complete angle.
I'd take two known variables J and K, one would be called the indicator, and the other would be the 'target'.
Two other variables would be the 'component' variables (an element taken from the unknown set), and the constraint variable (could be from either the known or unknown set).
The idea was that relationships between the KNOWN variables (an indicator and a target variable) could be used to indicate the rank relationship between the unknown component variable and the constraint variable.
You'd think this wouldn't work either, but my intuition was there were so many seemingly 'random' rank changes of variables in the known set for any two semiprimes, that 1. no two semiprimes ever shared the same order for every variable, and 2. the order of the known variables had to be leaking information about the relationships of the unknown variables.
It turns out my intuition was correct.
Imagine you are picking a lock, and by knowing the order and position of the first two pins, you are able to deduce the relative position of two pins further back that you can't reach because of the locks security features. It doesn't let you unlock the lock directly, but by knowing this, if you can get past the lock's security features, you have a chance of using information about the third pin to get a better, if incomplete, understanding about the boundary position of the last pin.
I would initiate a big scoring list, one for each known element or identity. And then I would check it in tandem like so:
if component > constraint and indicator > target:
indicator[j]+= 1
This is a simplication, but the idea was to score ALL such combination of relationship, whether the indicator was greater than the target at the same time a component was greater than a constraint, or the opposite.
This worked out to four if checks and four separate score lists.
And by subtracting one scorelist from another, I could check for variables that were a bad fit: they'd have equal probability of scoring for example, where they were greater than the target one time, and then lesser than it for another semiprime.
So for any given relationship, greater or lesser between any unknown variable and constraint variable, I could find any indicator variable and target variable whose relationship strongly correlated to the unknown's.14 -
So the De-Cix Frankfurt operater sued the german secret service (BND) for taping into the traffic.
They are apparently trying to exclude Traffic from german citizens by filtering for .de domains... Because id never browse any fucking other websites! And not every german website uses .de domains.
The Government justifies this by saying ""If the calculated reference value (Amount of data collected) is increased only strongly enough, the BND (...) can monitor 100 percent of the traffic it really wants (" full take ")."
("Wenn die rechnerische Bezugsgröße nur stark genug erhöht wird, kann der BND (...) den von ihm wirklich gewünschten Verkehr zu 100 Prozent überwachen ("Full Take").")
When will they fucking learn, that mass surveillance is a fucking bad idea?
Article (German): http://sueddeutsche.de/digital/...2 -
This week the QA is on vacation, so we, the developers, are testing our own code (I test my partner's code and he tests mine).
For those who are QA, I have a question: If our boss omitted something on the description of how the code has to be made, for example, filtering data from database, and one of those filters are needed but the boss forgot to tell us and, at the time of making the tests, the QA and de dev team notice this... the change that has to be made should be marked as a bug? or how would you mark it?1 -
Just spent two days on a isotope filtering bug with HubSpot. Finally got it working.
10 points to me 😂 -
I might have asked this before, but why when I turn on my personal VPN (personal vps) Internet suddenly becomes faster?
Is it because filtering no longer works?9 -
We had made an api which had endpoints for each different domain model, so /user, /company, the usual. Beyond being restful they all had basic filtering and pagination.
We also had an endpoint to return an entity from any set based on guid for when you needed to attach the related entity to notifications and logging and such.
We received a bug report on how you couldn't use filtering or pagination on this endpoint, and after weeks of asking what they need it for we just had to implement it.
You can imagine how non-trivial it is to "just" filter across different datasets, but we eventually got it working so now you can get a user via /user/123 or /entity?type=user&id=123. They only use it for one type and id at the time.1 -
Moving from a G-Suite company to one that uses Exchange 2016 is like stepping into a shiny time machine with only one working gear... reverse.
Spam filtering is as primitive as classified ads in print newspapers.
Outlook Web is as primitive as using a printed phone book.
I haven't seen this crap since 2004 and it appears NOTHING has changed since then. -
God damn it Microsoft Teams is the shittiest piece of conferencing software ever. The UI is not consistent at all, calls are dropping like flies, and it does this bullshit thing where if packets are dropped it speeds up people's voices which is annoying as fuck. Echoes are everywhere and does no background filtering so people are on mute when they're talking. Fuck you Microsoft for bundling this pos down our throats.5
-
Filtering stored procedures by name in SQL Management Studio. Enter name and press enter. Cursor goes to next cell, instead of submitting.
I do this every single time. -
Using a web grid which has functionality like filtering, sorting etc but each of it uses a postback. There is no way to enable client side filtering unless you do it yourself using JavaScript and the best part is the same company has another grid which has the option of both client side and server side filtering just by setting a flag but this grid only runs in .net 4 framework.
-
So I reverse engineered the
protocol of QONQR: World in Play and made a mitmproxy addon running locally inside termux that can see when I launch in the game and uses Termux:API to notify me when my ingame resources are replenished.
I direct the traffic through mitmproxy using Drony. I configured it so that by default Drony passes traffic directly to the internet except if it comes from the QONQR app.
The problem is that while Drony is running, there is a chance of network traffic being corrupted so I often get spammed by connection and ssl errors.
So I have to either continue sacrificimg my network integrity or stop getting assistance ppaying QONQR :-/
Does anyone know an alternative to Drony (basically an app that can connect you to a proxy without root using the android vpn api, if possible with filtering by app or ip)?
Also does anyone else have problems with drony on Android 9 or other versions? I don't really have an opportunity to test it.
Edit: It only took 4 tries to post this yay3 -
Ok story number 2, this one takes place back when I was at Uni.
We had a group project where we had to make a basic website. Nothing fancy, just basic HTML/CSS/JS.
We were a group of 3, one of the guys did a fairly good job with the CSS, he made a really good looking banner/footer and a kind of ‘featured’ page which looked awesome.
But the other guy... his contribution was the ‘contact us’ page, which consisted of a totally static table with dummy info and an embedded Google map showing the location of our fake car dealership.
Meanwhile I wrote all the Javascript, complete with a fake in-memory database containing our car data for displaying on the home page. Even had basic filtering. I made sure to mention in the peer review that I felt like he could have done more. -
Bloody cunts at Twitter could provide the fucking grammar for their filtering rules...
Now I have to write the grammar for the lexer and the parser from scratch (in fucking JavaScript to boot 😡).
Mind you, I know my lex and bison, but I haven't done this shit in fucking ages, and the combo of JavaScript debauchery and being rusty, is making me want to send angry tweets to Elon musk, see if they can provide decent tools for their shit API.3 -
By the end of the day my eyes always feel like they are on fire.
After four years of this it is time to get some blue light filtering computer glasses.6 -
As I started learning React, I found the allure of declarative style of programming appealing. I try to avoid maintaining multiple state variables for data that can be derived from the base state itself that's stored in the redux store. It works wonders when I have to change something; as I just need to make changes to one function in the utils folder and that change is implemented across the whole app, rather than change the instances everywhere as was the case when I initially started working on this project after the previous dev left.
But I see myself redefining a lot of computed values everywhere, and if I just try to define them in the root component, I'll end up with a huge list of props being passed to a couple of components. Shifting it to the utils folder helps a bit, but then I find myself defining even the simplest of array filtering methods to the utils folder.
Is this need to define computed values everywhere a trade-off that you need to accept when you write declarative code, or is there a workaround/solution I am missing? As of now, the code-base is much better than how it used to be when they had a literal Java dev work on React with their knowledge of Java patterns being used in a framework that is the polar opposite of OOP, but I still feel like there's room for improvement in this duplication of computed values.2 -
Fuck python Excel libraries. Had to write a spreadsheet formatting/filtering script to automate content generation. Definition of too much work. On the plus side just auto formatted 5000 spreadsheets in seconds.3
-
The MS-Teams bot works.
Every ten seconds a random meme from some subreddits will be sent into a specified channel.
It's fucking glorious.
Only problem will be the NSFW filtering as it's my school's organization.
Yes, I know I there's my name in there but I do not mind. 4
4 -
MongoDB database with really relational data. One main collection that had refs to four other collections, all of those references necessary to populate data for a page view. Complicated aggregate to populate all the necessary data and then filter based on criteria selected by the user. And then the client decides that he wants the information to be sortable by column. Some of those columns are fields on the main model, no problem. Others are fields on the refs, which is more of a problem. Especially given that these refs aren’t one single object. They’re arrays of objects.
The revelation was that I could just write an aggregate function to flat map the main collection, returning only the fields necessary for the search, and output it to a new collection and instead use that new collection for displaying and filtering/sorting search results.
But you can’t run the aggregate all the time, you surely say. If anything changes in the main collection, it won’t be reflected in the search results!
Mongoose post(‘findOneAndUpdate’) hooks, my friends. Mongoose post(‘findOneAndUpdate’) hooks.
Never been so happy to have a thing working properly in my life.2 -
Today I had nothing to do and started writing a twitter bot that tweets a random picture from bing maps filtering seas which are uninteresting. I think this is good for 1 day development.
https://twitter.com/TheAliveEarth2 -
Web API: "Oh, I see that you're trying to update to our new design with a category and sub-category dropdown layout. Here's one api endpoint that provides you the whole table without fucking input parameters to filter per category and sub-category. Goodluck! And Have fun filtering through the json and sub-json response!
And btw, don't even bother asking me to update the endpoint. Cause admin already said that the UI SHOULD ADJUST TO THE API AND NOT THE OTHER WAY AROUND. AS THE APIs ARE HARDER TO REVISE"
It's not our fault your api design is crap. You piece of shits. -
This is a simple Gmail terminal client that can perform filtering and few actions on the filtered emails. Used python 3.7 and sqlite to store them.1
-
I pretty much had my spam under control for quite a while, receiving only a few spam mails per week. However, in the last month or so the volume has picked up significantly, and now I just saw 16 new spam mails in the last two hours! Fookin shyte…
Of course I suppose they don't realize that at least Gmail is quite effective in filtering that crap right into the Spam folder so I don't have to deal with it. Come on, I know e-mail is cheap but mails that are never read might as well not have been sent in the first place…2 -
What's a good way to guage someone's domain modelling expertise in an interview? I don't want to make people go do an at-home project because we aren't big enough to be filtering candidates who won't do it, simply because they can't be doing that for every application.
Technology I can ask questions about, but stuff like DDD I think it's hard to know without seeing them work.2 -
So I have a question to anyone familiar with the General Transit Feed Specification...
Why is the data provided in text files? Is there not a way to format the data to allow for random access to it?
Like I'm currently writing a transit app for a school project, and as far as I can tell, the only way to get all specific stops for a route, is to first look up all trips in a route, then look up all the stopids that are associated with a trip in stoptimes.txt (while also filtering out duplicates since the goal is to get stop ids, not specifically stop times) and then look up those stop ids in the stops.txt file.
The stoptimes file alone is over 500000 lines long, unless there is a way better way to be parsing the data that I'm not aware of? Currently I'm just loading the entire stoptimes file into a data structure in memory because the extra bit of ram used seems negligible compared to the load times I'm saving...
Would it be faster if I just parsed all the data once and threw it into a database? (And then updated the database once a month when the new data comes in?)3 -
!dev
I've finally been so agitated at G+ I need somewhere to just vent.
So for context. What I'm talking about is Google+, or more specifically, the Android app. The website is bad in its own way, but that's not here nor there. No opinions on the iOS version, as I simply REFUSE to touch iOS.
So anyways. The platform itself honestly is not bad. With competent developers behind it, and them actually listening to their dwindling fucking userbase, they could easily turn it into something successful, but the issue is that they just aren't
You see, it's almost like they change dev staff every 6 or so months. Why do I believe this? Because the GUI changes about that fucking often. They also have a history of forcing updates, but allowing you to use an older version, just horrifically slapping on a new and unwelcome skin. This isn't an isolated practice by any means, but it's by far the most prevalent here.
So, now a list of some of the issues the current version has:
-After about a week, the app becomes unstably slow, to the point of it taking about a minute to refresh your home feed, or an individual page.
-Searching is never good, always being slow and rarely giving you who you asked for.
-Transparency is non fucking existent. There isn't a development roadmap to speak of, and when something happens we get it second hand from staff in a "G+ help" community.
There is a solution for the first one, going and clearing the data/cache, but really, the end user shouldn't have to regularly do that. Not to mention the storage space Google apps IN GENERAL fucking take up. Why does Google Play Services regularly use 250MB? (For most people, this really isn't much. But when you only get to fucking use 4 GB of internal storage it's a giant fuck you.)
Bah, back to the topic at hand.
There isn't a good solution to searching, or for transparency at the moment.
The spam filter is awful as well. REGULARLY letting obvious spam pass, regularly blocking and filtering genuine users. It's real annoying that the Android app itself doesn't have support for seeing these flags outside of rooting through the settings a bit, but still. The web and iOS versions have this already.
Oh, it also completely lacks a dark mode like most Google apps for some fuckin reason.
That concludes my random 1:30 AM rant about something I have no ability to change, except hope in vain that someone who has the ability to change this forwards this to the developers of G+.
I need a better sleep schedule.3 -
Anyone ever tried using user-to-user collaborative filtering to classify the mnist digits dataset?
This is about as far as I got:
https://hastebin.com/obinoyutuw.py
It's literal copy-and-paste frankencode because this is only the second time I've ever done something like this, so pardon the hatchjob.1 -
Hey all, I'm curious for your opinion on this one. I've got some smart home devices (e.g. Hue lights, Nest Protect) and lately I started to think of the best way to protect them. Now I did see this project on Kickstarter (https://kickstarter.com/projects/...) and it seems to be a nice and easy way. But still, you don't know what they'll do with your data.
Would MAC address filtering in my router / modem not suffice for protection?
Let me know what you think :)5 -
almost everything work related. especially filtering a csv export file with a python executable to open a word serial letter to open a email for some entries with vba. or writing a js object file with vba from an excel 'database'. my proudness is ambivalent.
-
*Long post*
Fuck Firebase.
I am working on a Instagram clone. So far it was going good until I came to the follow/unfollow part. Specifically where users post will only be visible to the friends who are following him/her.
Initially I thought I could use Firebase rules for that. Turns out you can not use the rules for filtering because of cascading properties of firebase rules.
Second one was the traditional approach in which you can check the author of the post and if the author is in my friend list then display it. But this seems idiotic approach because in the long run users will have to download thousands of posts just to check them. I know I can use the order by but this is also a cumbersome approach nonetheless.
Does anybody has any idea on how to do it. I'm stuck here.4 -
Consider an API that uses the HTTP path to represent position in a tree that literally represents a file tree with minimal constraints, and GET/PUT/DELETE methods to read, write and destroy the nodes. How would you encode read/write operations to per-node metadata? The kinds of metadata are static and around 4, so inventing HTTP verbs for each of them is infeasible but filtering is not necessary.
Options considered so far:
- toplevel resources alongside a namespaced /data such as /acl, /lock
- magic keywords to the Range header (this is apparently compliant)
- mimetypes such as text/plain+acl
- SETPROP / PROP methods in the spirit of WebDAV
- headers (I worry this may become an immitigable bottleneck really fast)
I'm looking for any kind of suggestion or insight, not perfect answers.
I read the WebDAV specification and I won't even suggest that I'm trying to align with it, the only protocol I'd seen in the past with comparable scope bloat is WebRTC.22 -
Teaming up with a marketing firm looking for a developer. The owner was showing me a couple samples of Craigslist postings that he gets sent every day by a filter he has set up so that I can provide some feedback on what would be a good fit.
Second listing we pull up looks reasonably good at first, then I notice this bit at the bottom:
“Must be available to do design review calls where we’re both on the phone, I tell you what needs to be changed, and you do it on the spot.”
Politely but firmly let my new friend know that that right there was a big red flag saying to move on.
Anyone else have helpful criteria when trolling these kinds of postings? -
Power BI: wonderful tool, pretty graphics, and can do a lot of powerful stuff.
But it’s also quite frustrating when you want to do advanced things, as it’s such a closed platform.
* No way to run powerquery scripts in a command line
* Unit testing is a major pain, and doesn’t really test all the data munging capabilities
* The various layers (offline/online, visualisation, DAX, Powerquery, Dataset, Dataflow) are a bit too seamless: locating where an issue is happening when debugging can be pain, especially as filtering works differently in Query Editing mode than Query Visualisation mode.
And my number 1 pet peeve:
* No version control
It’s seriously disconcerting to go back to a no version control system, especially as you need to modify “live code” sometimes in order to debug a visual.
At best, I’ve been looking into extracting the code from the file, and then checking that into git, but it’s still a one-way street that means a lot of copying and pasting back into the program in order to roll back, and makes forking quite difficult.
It’s rewarding to work with the system, but these frustrations can really get to me sometimes2 -
Told designer just use the same map we have spent a lot of time build the scripts and cards with a simple scroller.
She proceed to fucking add a slider with autoscroller with a fucking filtering system.3 -
I've had an idea for a possible PR. Filtering out certain categories. I don't really want to see any joke/meme rants anymore, and filtering out other types may be helpful.2
-
Amusing vim/neovim newbie beatdown story. I am mostly enjoying it, so please don't take it too personally, as I'm 60% having fun, 30% looking for help, and only 10% attacking your fundamental identity and way of life
#1 uses left and right arrows to move the selection up and down, and down and up arrows to move the selection into and out of tree elements
#2 uses tab and shift tab to move the selection up and down, but has great filtering
#3 uses up and down arrows to move the selection up and down, and enter and esc to move the selection into and out of tree elements.
I get that I have just frantically cobbled various things together to make it work but man, there's something to be said about the I in IDE... 5
5 -
!Rant
New to the whole front end world so pardon me for such a question.
I have a huge set of data about 5-10k records flowing in which needs to be displayed in a tabular form with sorting, filtering, selection addition and deletion.
Is it wise to sort and filter in the front end? Or make multiple calls to backend and perform the operations there?
If in front end what is the best way to perform these operations?
The application is going to be loaded on a screen and left there for users to view. So even local storage could be am option.
Using polymer for frontend so any special tool for this in polymer?3 -
When AppSync subscription payloads are defined by the initiating mutation instead of what I ASKED for, and filtering only works when the initiating mutation specifically queries for that field in the respond payload that it doesn't even need.
-
Why does the TSQL BETWEEN operator include the first and last value in the results when filtering on numbers, but only includes the first value and not the last for dates?3
-
#Suphle Rant 6: Deptrac, phparkitect
This entry isn't necessarily a rant but a tale of victory. I'm no more as sad as I used to be. I don't work as hard as I used to, so lesser challenges to frustrate my life. On top of that, I'm not bitter about the pace of progress. I'm at a state of contentment regarding Suphle's release
An opportunity to gain publicity presented itself last month when cfp for a php event was announced last month. I submitted and reviewed a post introducing suphle to the community. In the post, I assured readers that I won't be changing anything soon ie the apis are cast in stone. Then php 7.4 officially "went out of circulation". It hit me that even though the code supports php 8 on paper, it's kind of a red herring that decorators don't use php 8 attributes. So I doubled down, suspending documentation.
The container won't support union and intersection types cuz I dislike the ambiguity. Enums can't be hydrated. So I refactored implementation and usages of decorators from interfaces to native attributes. Tried automating typing for all class properties but psalm is using docblocks instead of native typing. So I disabled it and am doing it by hand whenever something takes me to an unfixed class (difficulty: 1). But the good news is, we are php 8 compliant as anybody can ask for!
I decided to ride that wave and implement other things that have been bothering me:
1) 2 commands for automating project setup for collaborators and user facing developers (CHECK)
2) transferring some operations from runtime to compile/build TIME (CHECK)
3) re-attempt implementing container scopes
I tried automating Deptrac usage ie adding the newly created module to the list of regulated architectural layers but their config is in yaml, so I moved to phparkitect which uses php to set the rules. I still can't find a library for programmatically updating php filed/classes but this is more dynamic for me than yaml. I set out to implement their library, turns out the entire logic is dumped into the command class, so I can neither control it without the cli or automate tests to it. I take the command apart, connect it to suphle and run. Guess what, it detects class parents as violations to the rule. Wtflyingfuck?!
As if that's not bad enough, roadrunner (that old biatch!) server setup doesn't fail if an initialization script fails. If initialization script is moved to the application code itself, server setup crumbles and takes the your initialization stuff down with it. I ping the maintainer, rustacian (god bless his soul), who informs me point blank that what I'm trying to do is not possible. Fuck it. I have to write a wrapper command for sequentially starting the server (or not starting if initialization operations don't all succeed).
Legitimate case to reinvent the wheel. I restored my deleted decorators that did dependency sanitation for me at runtime. The remaining piece of the puzzle was a recursive film iterator to feed the decorators. I checked my file system reader for clues on how to implement one and boom! The one I'd written for two other features was compatible. All I had to do was refactor decorators into dependency rules, give them fancy interfaces for customising and filtering what classes each rule should actually evaluate. In a night's work (if you're discrediting how long writing the original sanitization decorators and directory iterator), I coupled the Deptrac/phparkitect library of my dreams. This is one of the those few times I feel like a supreme deity
Hope I can eat better and get some sleep. This meme is me after getting bounced by those three library rejections
-
Nodes Reach
I will google my last error message
I cannot tell where this conviction comes from. Whatever birthed it is a mystery to me, and yet the thought clings like a virus, blooming behind my eyes and taking deep root within my mind. It almost feels real enough to spread corruption to the rest of my body, like a true sickness.It will happen soon, within the coming nights of pizza and energy drinks. I will google my last error message, and when my brothers turn on thier computers, my questions will be scattered over stack overflow with one accursed tag
Nodejs.
Even the name twists my blood until burning oil beats through my veins. I feel anger now, hot and heavy, flowing through my heart and filtering into my keyboard like boiling poison.My fingers stretch out. I am strong, born only to code and debug software. I am pure, googling the most obscure of error messages, trained to break down problems and use console.log. I am wrath incarnate, living only to code until finaly my program runs.I am a programmer in the Eternal Crusade to forge humanity's mastership of the code.Yet strength, purity and wrath will not be enough.
I will google my last error message
My Nodejs application won't run.
*Watch the Original !! by Richard Boylan here*
https://youtu.be/1D4jr-0_COg -
I have a couple of "at risk" teens (I won't say what) who need an extra level of Internet filtering and restriction for their own protection against their use of really bad judgment. I've already enabled the OpenDNS parental control URL/content filters on my Netgear R8000 router but one of the teens has figured out how to install a VPN on mobile. I want to enable the router's OpenVPN feature for better overall security for all of us. But is there a way to block the use of an "unauthorized" VPN, like on a mobile device, without also effectively blocking my router's OpenVPN as well? I was looking at this post (https://community.netgear.com/t5/...) but wondered if anyone here has experience with this.6





























































































{kind=link}
Top Tags
Weekly Rant
View