
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Picked up a legacy site to re-build, turns out just adding:
'?admin=1'
to the query string gave you full admin rights to the entire site without having to authenticate. The site was live for 2 years.3 -
The DNS server I'm writing in PHP (largely taken from another project) is starting to work!
Next to just blocking queries it logs every blocked query so I can have stats :3
A little terminal output: 64
64 -
When I was an intern, I wrote a very heavy MySQL query with multiple joins. Quite frustrated, I asked for some help from one of my seniors.
He came by on my desk and told me, "Explain your query!".
I was completely blank-faced O_O.
After a few moments, the senior grabbed this hopeless bastard's keyboard and typed "EXPLAIN" in the beginning of the query; and then ran it.
I thought he was being hard to me.7 -
Had a database engineer tell me that he put a minimal delay of 15 seconds on every query, so that people don't come complaining to him that the database takes longer than usual4
-
Client(On Call): I emailed some query a day before. I got a response too. But, i am not able to find answer of my specific query.
Me: Let me check that for you. Yes, it is there. See the mail carefully.
Client: No. It's not there.
Me: Can you read the whole mail for me?
Client: Sure. *Started Reading* Oh yes. Yes. it is here. *Hangs up the Phone.*
Me: Sigh.5 -
Hey, Root? How do you test your slow query ticket, again? I didn't bother reading the giant green "Testing notes:" box on the ticket. Yeah, could you explain it while I don't bother to listen and talk over you? Thanks.
And later:
Hey Root. I'm the DBA. Could you explain exactly what you're doing in this ticket, because i can't understand it. What are these new columns? Where is the new query? What are you doing? And why? Oh, the ticket? Yeah, I didn't bother to read it. There was too much text filled with things like implementation details, query optimization findings, overall benchmarking results, the purpose of the new columns, and i just couldn't care enough to read any of that. Yeah, I also don't know how to find the query it's running now. Yep, have complete access to the console and DB and query log. Still can't figure it out.
And later:
Hey Root. We pulled your urgent fix ticket from the release. You know, the one that SysOps and Data and even execs have been demanding? The one you finished three months ago? Yep, the problem is still taking down production every week or so, but we just can't verify that your fix is good enough. Even though the changes are pretty minimal, you've said it's 8x faster, and provided benchmark findings, we just ... don't know how to get the query it's running out of the code. or how check the query logs to find it. So. we just don't know if it's good enough.
Also, we goofed up when deploying and the testing database is gone, so now we can't test it since there are no records. Nevermind that you provided snippets to remedy exactly scenario in the ticket description you wrote three months ago.
And later:
Hey Root: Why did you take so long on this ticket? It has sat for so long now that someone else filed a ticket for it, with investigation findings. You know it's bringing down production, and it's kind of urgent. Maybe you should have prioritized it more, or written up better notes. You really need to communicate better. This is why we can't trust you to get things out.
*twitchy smile*19 -
When you see a web service API accepting a SQL query in one of its JSON fields and the evil starts growing within you..
DROP ALL DATABASES
Just because you can! 4
4 -
*opens new tab*
*types 'google' into URL bar*
...is navigated to google home page...
*proceeds to enter desired query into the same URL bar*5 -
I turned a 20 hour per month task into a 150ms database query.
I feel like a fucking super hero.
FYI my super hero name is ThreadPool (see past rant)4 -
Every hour or so someone shows up at my desk requesting a query to be executed.
I feel like I'm just a human-sql interface.3 -
$search = $_GET ['search'];
$table = $_GET ['table'];
$query= mysqli_query ("$search FROM $Table");
😲😲😢😢8 -
SO: How to ... in JavaScript?
Answer: use jQuery!
SO: How to ... in JavaScript without jQuery?
Answer: use jQuery!
Me: ffffffffffffffffuuuuuuuuuuuuuuuuu I hate j-f*cking-query, I don't want to learn it!!15 -
That moment when you google the error...
find the same query on three different sites...
realise that all three were posted by the same user...
and all three are unanswered.. 😑5 -
Fuck fucking fuck just spent hours and hours looking why I was getting a fatal error. I overlooked a missing bracket in an SQL query. MOTHERFUCKING FUCK FUCKING FUCK FUCK FUCK FUCK7
-
My boss is a grumpy 25 year oldish "Mr. I know it all". We all hate him for that attitude.
Just joining recently, the code base which I got introduced to was totally new and I was overwhelmed.
Boss told me to write an Sql query to wipe the table data. I being reckless wrote a query to wipe the table only and submitted it to my boss.
Few hourse later we were informed by our peers that a certain url was not working. On further investigating we found out that my boss carelessly copy and pasted my query and executed it which wiped an important table clean.
Now he doesn't talk to me straight and I can't look him in the eye because obviously I burst into laughter.
Job well done☺️2 -
Optimized a query today. Before it timed out after 10 minutes, now it takes 4.3 seconds. Very proud.13
-
Fucking hell, the devs before write a query that pulls 30ish column for a report. When I break it down MANUALLY, since it’s a spaghetti on top of another spaghetti, you only need 6. Fuck you, did you dropped your head when you was a kid? Fuck sake, and every query is written in stored procedure even though you’re using an entity libraries16
-
Today, for fun, I wrote prime number generation upto 1000 using pure single MySQL query.
No already created tables, no procedures, no variables. Just pure SQL using derived tables.
So does this mean that pure SQL statements do not have the halting problem?
Putting an EXPLAIN over the query I could see how MySQL guessed that the total number of calculations would be 1000*1000 even before executing the query in itself and this is amazing ♥️
I have attached a screenshot of the query and if you are curious, I have also left below the plain text.
PS this was a SQL problem in Hackerrank.
MySQL query:
select group_concat(primeNumber SEPARATOR '&') from
(select numberTable.number as primeNumber from
(select cast((concat(tens, units, hundreds)+1) as UNSIGNED) as number from
(select 0 as units union select 1 union select 2 union select 3 union select 4 union select 5 union select 6 union select 7 union select 8 union select 9) unitsTable,
(select 0 as tens union select 1 union select 2 union select 3 union select 4 union select 5 union select 6 union select 7 union select 8 union select 9) tensTable,
(select 0 as hundreds union select 1 union select 2 union select 3 union select 4 union select 5 union select 6 union select 7 union select 8 union select 9) hundredsTable order by number) numberTable
inner join
(select cast((concat(tens, units, hundreds)+1) as UNSIGNED) as divisor from
(select 0 as units union select 1 union select 2 union select 3 union select 4 union select 5 union select 6 union select 7 union select 8 union select 9) unitsTable,
(select 0 as tens union select 1 union select 2 union select 3 union select 4 union select 5 union select 6 union select 7 union select 8 union select 9) tensTable,
(select 0 as hundreds union select 1 union select 2 union select 3 union select 4 union select 5 union select 6 union select 7 union select 8 union select 9) hundredsTable order by divisor) divisorTable
on (divisorTable.divisor<=numberTable.number and divisorTable.divisor!=1)
where numberTable.number%divisorTable.divisor=0
group by numberTable.number having count(*)<=1 order by numberTable.number) resultTable; 9
9 -
I was searching through StackOverflow when I found this guy:
He is using a "dot operator" in LINQ at the end of the Query
Example:
a.Where().
Select();
Not
a.Where()
.Select();
How barbaric2 -
Password hashing using md5, it is 2016!! I have seen a sys admin update a user password using a MySQL query23
-
Ran update query on 1m+ record without where clause. Thank god I missed the commit command or else today would have been my last day.13
-
166 lines of if else hell just to decide between prod and sandbox.
Run the same query multiple times to get the same data.
And that's all written by our code review team lead.
What a mess.2 -
Apparently `= NULL` is not a thing in mysql, instead you have to use `IS NULL`... Took me a while to figure out why the fuck my query wasn't returning any results.8
-
Always use SELECT-query with the same conditions before you DELETE/UPDATE in a production database.1
-
Arts and crafts: developer version.
Context: spent all day making an ER diagram from an awful SQL query I was handed. Got sick of asking for it from the contractor who made the DB.
Yes, that's one query. 25
25 -
YAY a JOIN query (MySQL) just ran successfully at the first try for the first time of my life!! I never understood joins but slowly getting there I guess :)4
-
A SQL query goes into a bar, walks up to two tables and asks, "Can I join you?"
Such a classic joke. Apt for a Friday! :D1 -
Customer: Can you do a database query for me?
Me: Made the query and send them the result as a csv-file.
Customer: Is it possible to send it as an excel-worksheet because the columns don't have the right width.
Me: Resize the columns to the right width, saved it as xlsx-file and send it back.5 -
What manner of imbecile writes a password reset function that passes the email and password as god damn query parameters, in the email link....1
-
Senior showing fellow intern what SQL injection is on the app the intern created :
Senior : "then I hit enter and the query get executed and...
Intern : "don't you dare hitting enter!!!"4 -
that moment when you realise the ID column in the DB has no auto increment on it after sending a 900k lines query... FML3
-
So, today I asked my senior developer a query he took my laptop and changed the ide theme to black.
My doubts were solved, I am enlightened programmer now.6 -
Why does it take a client, who needs the bug fixed immediately, over 24 hours to respond to my query about what the problem is?11
-
Web Developer with no common sense: “I’m going to query the currency calculator API for each of the 1000 records to convert.”.
Web Developer with common sense: “I’m going to query the currency rates API and use the calculation to convert each of the 1000 records.”6 -
Official Release of Wikipedia Bot is Here
How to Use: @wiki <Query>
Runs on cron job, every minute.
If there is literally no Wikipedia page for query, still gets a relevant result.
Demo in Comments.281 -
Was my prev dev fucking high or what?
Who names an UPDATE Query as delete.
That shitfuck deserves a special place in hell. 21
21 -
Things like this make me feel good about myself. Update: moments after taking this picture, he took it down. Have any of you ever asked a stupid question like that? And, well, how did you know you when you got "good" at programming?
 9
9 -
Ended in an UPDATE without WHERE query to a core table in a Drupal project (in a dev database stored in the same server that production database was)
 2
2 -
We have a portal which uses Windows Integrated auth that lists out all off our internal sites.
Navigating to any of these produces a URL like the one in the attached image.
Turns out all our internal application use a base64 encoded email address in the query string as the means of authentication.
So, anyone can authenticate themselves as another employee within the company by simply changing the query param value to said employees email address.
Fucking nuts. 8
8 -
At a Magic: the Gathering prerelease tournament (yeah, yeah, stereotypes), on my phone, with a pen and paper copy of the SQL query, as the phone screen was too small to read it properly in full. Managed to fix the bug in the query about 30 seconds before the next game started.
The debugging went well, but the tournament did not; I think I was a bit distracted!!2 -
Omg whhhy do things change so much from Laravel 5.x to 5.4? Tutorials are useless! And Google, I love you, but giving me laravel 4 answers as top results for my query specifying 5.4 is just infuriating!!!2
-
Random almost tech guy at workspace
1. Opens Google Chrome
2.Types... www.google.co.in in the OMNIBOX
3.Hits enter
4.Types search query.
God just committed suicide meanwhile.4 -
So these motherfuckers... they have stored the queries to generate the reports... fucking guess where. Just guess.
They stored the queries AS FUCKING STRING DATA IN THE TABLE. And you know how they get the parameters? A FUCKING JOIN WHERE THEY HAVE STORED THE PARAMS AS DATA IN ANOTHER TABLE.
So you query set the params to query to get the query to get that is joined with a query to get the reports.
If God is a programmer after all y’all are fuuuuuuuuuuuuuucked4 -
My friend once told me, that when he was trying really hard to find an error on his code (which caused the app couldn't run), he didn't get any of syntax error.
But when he try to skim the query, he found a little query typo that cause the long development delay due to that error. He mistyped SELECT as SELET.
For you who don't get the joke. SELET, in my language (Javanese Language), means ASS/BUTT/ARSE. My friend felt like to be cursed by his own code, after searching the error.5 -
I've been working on a proof of concept for my thesis for a few days and the async query calls drove me nuts for quite a while. I finally managed to deliver all query results asynchronously while still very much relying on a strong architectural design pattern. I am filled with caffeine, joy and a sense of pride and accomplishment.
 1
1 -
Api-docs: Use the query parameter name_pattern to return results that contain name. Otherwise use name to return an exact match
Api: Returns *name* results when using name and everything when using name_pattern without a wildcard
-
BI dev: Hey, can you help me with my SQL query?
Me: Sure, let me see it.
BI dev: sends screenshot - not even the whole query, literally a screenshot with a segment of text in it. No errors showing either.
Me: ...7 -
Twenty five goddamn minutes finding an incorrect quote mark in a bloody massive query of mySQL, I need a beer.1
-
Client called with a query regarding her email client. Said to me during the conversation, "I've got yozzamite". Took me a few moments to realise that she meant Yosemite.8
-
a quote of todays daily standup:
"<other guy>, did you had time to investigate that disastrous SQL query. I had no time, one of my horses was giving birth"3 -
Our ex-employee wrote an amazing SQL SELECT-query consisting of 6449 characters. It has 11 JOINS and takes a solid minute to execute.
The table it fetches from has 16 records and the SQL query returns 46857 records and it was production code lmao14 -
[CMS Of Doom™]
Imagine bringing every HTTP Query Param and every god damn fucking POST var into to current code context.
"extract()" is one of the reasons why I have terminal PHPTSD. 10
10 -
Wrote a long SQL query yesterday for some data I was exporting. It was just about finished and figured I would wrap it up in the morning.
PC reboots overnight. Never saved the query.
// Rookie mistake3 -
When I need help with JavaScript, I google 'JS (insert query here)...'
When I need help with Go, I have to google 'Go programming (insert query here)...'
The extra term 'programming' is so search engines recognise I'm looking for answers related to the Go language.
Ironic, but Go is the least 'search engine friendly' language. Sites like O'Reilly and Packtpub return searches with uneven results.10 -
Opening Google Chrome
In the omnibox(address bar) typing www.google.com
Waits for the page to load.
Enters the search query.2 -
Struggling to write the query with query builder for an hour, gave up and wrote the raw query in 5 minutes.14
-
- Knock Knock
- Knock Knock
- Who's there?
- Your mysql query callback
- Your mysql query callback4 -
Oh hell yeah. I just spent a good few hours optimizing an ok mySQL query and made it so much better and faster. Inner join ftw!!3
-
Was showing the new guy how to write a fairly simple database query with a couple of joins.
Spent 3 hours trying to figure out why it didn't work.
Finally discovered that I had randomly chosen one of the 3 records (out of a possible 15,000+) that had leading white space.
Ctrl-Z back to the first query I wrote (3 hours ago), and it works perfectly.
New guy learns a more valuable lesson than I originally intended. -
Quick survey: What do y'all like being referred to as? (Engineer, programmer, developer, etc.) I like developer but I find that people rarely get what that means12
-
"Okay, my query uses wrong date format."
"Why the hell I´ve put that join there? That´s not needed!"
"Why the hell I´ve joined the tables in THAT order?"
Joys of looking at your old code.1 -
My react code in production broke because one of my senior renamed a field in sql query to 'id' instead of invoiceid.7
-
When you find an extremely cool SQL query online but instead of returning the high-five your wife turns around and walks away, shaking her head mumbling1
-
I named an alias variable feedItem in my database query but I keep accidentally typing feetItem. I have no one to blame but myself.1
-
I'm seriously working with a system that saves the password AND the confirm password In the database... varchar field, copied info, no wonders it takes half an hour to make query.10
-
Running SQL Activity Monitor to find inefficient queries. According to legecy team this is how they think they should query SQL 2014 for a customer.
 10
10 -
I tried developing an API based on some other ones that would query my school's timetables faster than our app.
It worked.
I'm proud now.4 -
Ok so I was fetching some JSON data from a SQL database server and loading it on the front-end. Every single data is being loaded onto the table except for a single data column, which is empty.
Hmmm... So I go and check my code... everything looks fine.
Then I console.log the JSON (using .stringify() of course), all the values from the table are present in the printed out JSON.
Ok, now I am really pissed.
Long story short...
I had misplaced a single 'i' in the SQL statement, I had included the 'í' (the i-acute) character instead. And since I was using an alias in the query statement, no error was shown.4 -
I remember it was Friday, 30 minutes before leaving the office when suddenly someone from the upper management directly asked for my help to mass update something as it is important. By that time our CMS is not capable of doing this so I had to do it straight in the live database.
It was an update query and I decided to type the query in notepad first. when i pasted it in the terminal i didn't noticed i missed the "where" part so i mass updated the status of all our records dating 3 years back.
fuck.. please take note it was on a Friday night.4 -
Because, definitely, size shouldn't matter.
Code description for the blind: if the size of this query is loved, then close the database and die.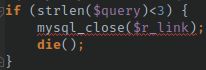 8
8 -
Not only Synology's REST API documentation is outdated, but I have to deal with this.
Let alone the fact that login in a GET request where username and password are passed as query string in URL. 8
8 -
Made a SQL query wich perfectly worked. Than added one collumn to be selected and everything is shit.
And the worst is I still don't know why! Ò_Ó2 -
My dumbass removes a setter and then starts wondering why the API isn't accepting any query parameters anymore1
-
Everyone shitting on SO answers being mean (which sometimes they are), meanwhile:
https://stackoverflow.com/questions...
Garbage like this is how you become a misanthrope.10 -
When coworkers built the shop to allow adding items to cart via url query parameters-_-
/shop/?itemNum=1234&Qty=4
..what?4 -
Can someone explain what's so wrong with CSS?
My only issue is you can't set media query variables - which is totally not an issue with cssnext or similar..3 -
I was working yesterday, writing a calculus with sql.
My very great user explained to me the math in Excel. I first though to myself, piece of cake, i got it.
Then I started typing and at the end of the day i had 6 temp tables which at some point need to join with themselves. It was just hilarious. each table had at least 4 millions rows.
Then I started a new query just for validating the output of me very ugly previous queries.
And I fucking found a easier way to get the same output with 3 joins of 3 different tables and a count at the end.
When you love yourself. but hate yourself at the same time.
xD it was a very productive Friday night2 -
Needed to update one column in table A with data from table B (huge table).
Created awesome update query with join between the two tables.
A few hours later realized all data in table A is already being imported from table B in a query executed earlier in the process... -
Colleague asked me to look at his eCommerce search filtering system as the customer was complaining it was slow taking 5-6 seconds to find results.
Delving into the code deeper, I discovered he was querying the results, sticking them in an array and then sub querying the results looking at all the combinations.
On top of that each sub query looked at the database fields using "DESCRIBE" to then search them each time it found a pair!
The total query count for one page search was 14,512!!!
Why oh Why? One SQL query could of done all that in one go.
I look at other code bits he's done and he's very good in other areas. I just don't get how sometimes a good developer can make such a weird decision? It's almost as if he wanted to make it as complex as possible.4 -
Who has replaced a dot with a semicolon while composing a SQL query in php? Me. 😤😤😤😤😤
Two hours spent in fixing everything and a sleepless night. 8
8 -
Going through some pretty fucked up shit right now : a string containing an SQL query goes though a 100+ lines function full of if{} else{} with up to 5 levels of indentation, where it replaces some parts of the query with other words... 😱1
-
Last year I was asked to optimize a code in our legacy portal (yet to be replaced with the new portal). The legacy system didn't have a design phase. Straight away went to development by whatever developer available at that time.
It was seriously fucked up.
So I went and had a look at the vanilla PHP code that served data for a datatable.
** I nearly fainted **
A query was done to get data from a table without any joins.
Then for loop to display those data.
Then inside for loop, for every single column that gets data from a related table there's a fucking query.
Eg: select * from users where.... to display username. Then again select * from users where..... to display user's email, then another query for his phone number. Then another query to get service providers name, then another to get their phone number.
I think the guy who did it wrote his first hello world app with a bunch of queries and sent it to production. No one bothered to check until 4 years later when it slowed down like a friggin snail.
I'm surprised it even survived that long. -
When you cache index a faster query but your co-worker from other part of the world clears it.... It's been six times now dude2
-
Some people think that web development is easy because they use framework for responsive designs, they dont know the struggle of manually using media query in css.
-
I was Just college fresher who completed his Engineering. My first week in the office. And a system was provided to me, since it was support project so I was given direct access to production database.
Fresher + Production Database + Access of Admin credentials = Worst Possible Combination
So it was my night shift, I was told to update new tariff plan for our client (which was one of the largest telecom service in India) .
If someone recharges for more than 200 Rupee, that person will get 10% or 20% extra talk time. Which was only applicable for particular circle (Like Bihar and Rajasthan).
Since I was fresher, I was told to update given query from my senior employee which he shared on the shared folder. Production downtime was in the mid night, so at that time I updated that query on the production database.
Query successfully updated. I completed my night shift, went home and slept.
When I woke up, I saw my mobile it had 200+ missed calls from different locations of India. They were Circle heads of that telecom service provider who contacted me. I realized something unexpected is expecting me.
Then at that moment my team lead called me and he asked me to come office right away.
Reminding you I was a fresher, I was shivering. What have I done there?
When I reached office, I came to know that the query I updated on production bombarded.
Every person who recharged that day (duration from midnight to morning 10 AM) got 10 times or 20 times more talktime.
A part of Query was something like this where error was made:
TalkTime = RechargeAmount + RechargeAmount * 10/100; (Bihar)
or
TalkTime = RechargeAmount + RechargeAmount * 20/100; (Rajasthan)
But instead of this query, I updated below one:
TalkTime = RechargeAmount + RechargeAmount * 10;
or
TalkTime = RechargeAmount + RechargeAmount * 20;
In a span of 10 hours, that telecom service lost revenue of 6.5 crore Rupees. Thanks to recovery team they were able to recover 6 crore but still 50 lakh Rupees were in loss.
One small query, and approx 1 million dollar was on stake.
Aftermath of this incident
My Mistake:
I should have taken those queries on mail. Or, there should have been mail communication regarding this.
Never ever do anything over oral communication. Senior employee who did this denied and said he provided correct query, and I had no proof of communication.
I told them, it was me who executed that query on production. Since I was fresher, and took my responsibility of that incident. My team lead rescued me from that situation.
Lesson Learned:
Always test your query and code multiple times before you execute or Go live it on production.
Always have email communication for every action you take on production.
Power comes with responsibility. If you have admin credentials of production never use it for update/delete/drop until you are sure.
Don’t take your job lightly.
I was not fired from that Job, but I have learnt my lesson very well. -
Export data from a database that you've not modeled is a problem (sometimes), I just realized that this DB has two tables to storage cities, the main difference is the id, the other fields are the same in both tables, I hate that kind of people....
-
Spent the entire morning updating a SQL query.
Client wanted to have different expiration times for different products. So the full package would be 1 year of access and a module would only be 6 months. Then when you renew your account the renewal is 1 year if you have the full package else it's 6 months.
The query takes 0.7s to run and left joins 3 tables. Only to return about 100 results. Still it's faster than the guy who wrote the original query which just dumped the hole db into memory then looped through it appending valid entries to a new array. -
Big company asking me about query optimization during a DEV position interview... Do you really have no one better than me to optimize your queries?
I'm really afraid of your codebase now... Might decline if I pass...7 -
Does anyone knows about OLAP cubes, Rollups and whatsoever?
I'm wondering if this query it's overcomplicated...
Just trying to achieve a sum of amounts by month on a year lapse 5
5 -
Fuck, really FUCK the fucking MySQLWorkbench on Mac.
Useless piece of shit.
I fucking touched some fucking buttons and now I can't have my view back with query editor, output results, and schema view.
A fucking hour wasted restarting this shit of a tool touching things, nothing. All to execute a fucking stupid query.
AHAHAHAAHAHAHAHAH FUUUUUUUUUUCKKKKK
I NEED to work, not to understand how your stupid GUI works, designed by a cripple mind with poor IQ and developed by retarded24 -
Every time I see the N+1 query problem in people's implementation, I feel like crying. Especially when it's dealing with large data sets of something like 1000 records.2
-
I'm dockerizing this old CMS that needs a database query to resolve URLs for static assets.
Yes, a query for every single static resources. Fuck me.2 -
Callback your functions, not your ex.
Hash is for your data, not you,
Query tables, not your loved ones. -
Print("Hello World")
When people design a brand new Postgresql schema (case sensitive) using a mix of upper and lower case letters.
Only to then proceed and escape every single table and column name in every single query.1 -
On my first day at new job, a non-technical person used CQRS word while explaining the system. When I asked what's need of such a complex pattern for simple query type service, he simply backed off. 😝
-
Fucking mongo, fucking nested documents in nested documents that need to be filtered. I'm either really fucking dumb, the query is hard or both.8
-
Love it when you have a SQL query that takes 6.3 seconds (which includes processing time) to execute, and you managed to convert to a process that takes just 0.072 to complete1
-
To all the people who complain about writing a delete or update query. Not to talk you down, but seriously. STOP WRITING RAW QUERIES AND USE AN ORM!9
-
Today I wasted hours trying to do a HTTP POST request by using a query string in the URL. After some hours I realised what I was doing wrong. I'm so stupid.2
-
When you open problematic code and someone actually queried all the items from db inside for loop... And took only one item on specific index... Instead of iterating over items from query result... 😓😓5
-
!Rant
Dear fellow front end developer, why?, just why would you use "!important" on every property value inside your @media query?2 -
This developer has an media query break point for each style 912 break points. 304 desktop, 304 mobile, and 304 tablet break points. With 18000 line style sheet.6
-
when you work for Jira and get assigned in Jira’s Jira to write code in Jira Query Language to query Jira’s Jira so other Jira users can query their Jira better
 2
2 -
What’s a really expensive MySQL Query? I need to add it to a CMS application for “research purposes”.16
-
Stop teaching T-SQL on paper. If i have to write one more transactionsafe sql query without a debugger i'm going to fucking kill somebody.
-
Updating 4K rows in a table with 4M using Libreoffice Calc to generate the queries.
I know, it's not the best solution, but I'm afraid of the single query solution.
Please, forgive me. 3
3 -
Is there ever any reason for SINGLE Hibernate SQL query/template to join like 10 different tables, do math, and come out to like 30 lines?
This is not a stored procedure, it's a single SELECT2 -
I forgot the fricking ON clause for a important database query. While it didn't crash MY program or greatly effect the performance, I feel sorry for the API that had to deal with the idiotic results of this.
Especially that one request I just spotted, where I just got the answer "the query took too long". That one was like querying the table "females" for males.
Soo fricking sorry 😭😭😭3 -
Are sql joins a bad practice? :o
I recently did some work on a page for a site ive never worked on cause my boss told me to. So they recently added product detail video urls to a table that has a relationship to the products table. The existing code was querying for the products on that said page and then during the loop that was outputting the products ,there was another query for getting the url for the current iteration/product. Told my coworker that this imo was pretty inefficient way to do it and switched it to a join and did 1 query then output that but his words were "The way it is now maybe ineffecient in your opinion but it works. Also combining inner joins with left or right is not a good practice. If the data is changed upstream the entire query would need to be redone to accommodate the change". Mind you that they query views a lot which are all made from queries that use joins and I'm also pretty sure these views were written by someone who used to be here because these guys are not good at sql or at least that's what there queries show. I'm at the point now where I'm realizing that my boss and this other guy don't give a fuck about efficiency or doing things the right way they just want it "to work". So this coworker changed my query back to the way it was because he said it broke the shopping cart even though that was already broken when I started... What is life? Maybe I'm the stupid one?7 -
Tip: if you are doing a semi complex or complex query in Django and you have doubts print the SQL statement and analyze it. i.e print(queryset.query)
Just reduced a query to 1 join instead of two by just passing a list of int's instead of a list of objects. -
Fuck sequelize, the bloody query generated by the "ORM" give diferent result on the same DB if you trie it on dBeaver (works fine) vs node (shit results).
order DESC have 0 effect on sequelize, but it appears on the logger as part of the query.
I just want to go to sleep ffs.7 -
A download portal (paid, for GPL sourced software *ugh*) - checking by mail address, query:
email=mail@addr.com
... seems like php code was checking string equality by:
if query == valid_string
WORKED AROUND WITH:
email[]= in the http request
So, remember:
ALWAYS check with ===1 -
Rewriting the query for the fifth time because the other four I thought were the last time I was gonna need it.2
-
Need to write a query to find all scheduled reports, sounds easy, right?
Not in a system with over 1k tables all with obscure names and absolutely no foreign keys at all. -
I am happy today cause I manage to write a query in which two table have inner join and with third left .. haha...
I mean I was thinking of handling that situation with foreach.. But managed to do it in query by myself :)
Just hoping that query won;t break for different scenarios. But let just be me happy while it last .. I mean my client make some test -
DBSole .. Query your database from Google chrome dev tools :)
For lazy dev who just dont want to switch over phpMyAdmin or Terminal for small query
-
Spent 2 days optimizing SQL queries, and then I learned a valuable lesson.
If your database size is bigger than the RAM of the machine it’s running on, every query will take 5+ seconds ☹️4 -
Types google in browser, google gives search result for "google", clicks that, then main google page opens( search bar in center) , here he starts the actual query2
-
Created whole UAM System in Product for client. After the deployment client asked me
"In which table should I run the query to create a new user." -
It seems google index this link: https://devrant.com/search/...
for that query:
The Crashlytics build ID is missing. This occurs when Crashlytics tooling is absent from your app's build configuration. -
Ran a query on a prod server for 50 minutes before realizing I forgot to put my exclusions in the results... Oops.... New query runs in 1.5min. 4500 rows from the potential 340k rows.2
-
An Android app to query user details using the GitHub api and display them in charts which can be shared on social media.5
-
Spent 4 hours trying to make a query work and failed miserably.
Turns out I was using inverted commas around the value.
What the ....1 -
Wow...a talented developer created a 3 via SQL execution plan. The query runs like crap but the execution plan art is pretty.

-
WHEN I TRY TO SEARCH SOMETHING *NIX RELATED I NEED TO ADD "-ubuntu" TO EVERY FUCKING SEARCH QUERY
FUCKING *****
AND THEIR SHITTY COMMUNITY5 -
I turned on slow query log just for funsies and was immediately humbled.
Looks like I've got my next sprint lined up.3 -
Searching on Google for some obscure technical possibility but only getting the most common results...And my search query has more words -to -not -include -than -ones -to -include....ugh!
-
Control your searches like an ADULT damn it!!!
So we have records that can have any of a bazillion different reference numbers associated with them. No big deal. Everyone does right?
Our customer's love to run reports and so we have this one option for "just look at a hell of a lot of reference numbers". I call it the 'fuck all' search.
Really it is just there to find something that you don't know where a rando string or number might be in the record and just want to do a "fuck all" search across a number of likely fields to find it... and then presumably you'd be an adult and refine your search from there. LOL yeah right...
Customers get lazy and include that stupid option in their reports and we get a lot of.
Customer: "I always run this report (that includes the fuck all search) and now it isn't working. I want records that have ID 2222."
Me: "Yeah well that was only working because you were rando typing '2222' in like several fields and it would find those .... but now you quit doing that so it won't find them. If you want ID 2222, click the drop down and search by 'ID'. That will find it right away."
Customer: "But I want to just search by 'fuck all search' to find it..."
Me: "But then you get all these other records too right?"
Customer: "Yeah but I just delete them out of the spreadsheet ... "
Me: "Look watch this <screen share> there, look all records with an ID of 2222 and no more extra records you need to delete!!! How great is that?"
Customer: "But why do I have to do it this way now, I want to do it the old way..."
ಠ_ಠ
(granted I could add their ID to the fuck all search but we try to avoid adding too much because it gets out of hand / stops being useful the more fuck all it gets)3 -
Today I (/ later together with some colleagues) spent almost 4 hours trying to improve a Entity Framework LINQ to SQL query.
The initial problem was, that one of our List API endpoints took longer the more you "page" (besides the long response time it had anyways).
So after
- brainstorming in the team
- brainstorming alone
- hacking around and
- shouting at screens
- googling
we
- got nothing optimized
- got confused about what EF does
- lost the believe in our development skills
So Entity Framework is really a nice thing. But as soon as you look deeper, trying to figure out what it really does between ToList() and "yeah my data arrived" it is just....demonic.3 -
All those mine WTF moments are somehow related with caching which i keep on forgetting... the most fresh one was last week, i had some GIGANTIC mySQL query, and for the sake of response time I immediately made a cache function that kept Redis cache for a day or so... so last week i had to change something (good ol' client and his visions for app). So there i was with the query that returned same god damned results every time, i copy the query in some mySQL manager and it goes fine, but in the app it doesn't... what the actual FUCK!!! i was questioning my career until i figured it out, i was planning to buy some sheeps and a fife and to hell with this, a loud facepalm was echoed through the office that day...2
-
Needed to help a friend with her Bachelor Thesis. She writes in Javascript and needs to synchronously use the result of a postgresql query. The query call is asynchronous.
We did what any person that searches for a dirty solution would do.
We saved the result of a query in a file and load the file when we need it.
Why is Javascript a thing?6 -
my query syntax was not wrong in retrieving no results
the table's most recent entries are 2018, nothing in any year after that, which i was querying
fml -
!rant && query
Anyone else have a victory song for when you solve a really challenging code problem? Mine is "Yeah!" by Usher.1 -
Me and my GF at a tea shop. GF knows one of the tea baristas.
Her = "tea barista"
Him = "tea barista"
Her: you're studying queer theory
GF: Yes I am
Him: Why don't they just call it Query
Me: LOLOL
Him: LOLOL
Her && GF: >.>1 -
i don't want to write the query and tests for query, for the data i need, for this thing we're deleting and the fact that the query and tests on the query would get deleted later
i'd rather just hard code the results i have
yes im lazy1 -
Hey guys! Hear out, I just code and it works on first compile!
And its not just code, its also interact with database query!3 -
Wrote a 217 line script to import/export email templates.
Slightly less painful than hand crafting the 37,000 line SQL query. -
So...buffered query kept crashing even though I have a row limit of 10001 on my abstract datatables class. I didn't realize it was buffered because I grab the results in a for loop as a fetch. Well, I tracked it down to being the size of the email content that I'm selecting (and then using strip_tags and substring in PHP before returning to the front-end). So it's totally a catch-22 at this point because if I select let's say...substring 500 characters and most of that is line breaks and other html junk, I may only get a couple characters of normal text (or none at all) after stripping tags and doing a final substring to get the 50 characters of text I want to display. I said screw it and took the email content out of the table all together. You have to view it to see the content now. I should probably be storing a text-only version of the email, but argh..that's a lot of extra data.
-
TFW when you've been trying to figure out why your apparently flawless JPA database query won't return anything and realize you forgot to populate the database after setting up the docker-image....
-
Turns out Chrome really dislike to parse, save in indexedDB, query some things, and draw a graph of some JSON file.
Or, you know, maybe, an average response size of 5Mb is a bit too much.2 -
I learnt how to code, first, on code.org. Then on codecademy. There I learnt the basics of HTML5/CSS3, Javascript, Ruby and Ruby on Rails. I also began buying booking on J Query.
-
Why is PHP PDO such a b*tch to work with?
One minute it says it’ll accept one query via one method for one insert but then deny the next query you give it, all because of “:” within bindParam() -
I really want to like MongoDB, I really do, but the query/update language completey negates any fun
Try doing any non trivial operation in a single db query (aka. efficiently) from a language that's not JavaScript if you really want to hate everyone and everything7 -
I recently started playing around with Alfred for Mac. I made a pretty neat workflow that allows you to query a YouTrack server from Alfred with YouTrack Query Language autocomplete.
Although I'm not sure if Alfred's export feature bundled the Python dependencies properly lol can someone try it and let me know if it works?
https://github.com/mrjones2014/... -
NoSQL database solutions are only useful for event streams. Nothing else. Wrestling with DynamoDB to try and filter a complex query is unnecessarily complex .1
-
Parents offered to get me a surface for Christmas. How is it to develop on other than the small screen?5
-
Every time I have to use CloudWatch, I feel like I'd be more productive if I shoved glass shards in my eyes.
Every query/filter either returns nothing or errors out because too much is returned.2 -
Every fucking time I write some database query or formular with firstname entry I accidentally write fistname and didn't find it for an hour 😡😵2
-
So apparently in MySQL, 0 doesn’t always equal 0, sometimes it can be 1, or 2, or 3...
what the actual fuck?!?!5 -
Working with new guy who is "senior" is such a pain. We had a factory file that is used to populate tables in endpoint tests. The new guy decided to add a static util method called createTestRecord() to a query builder model. Fucking query builder calls in a static method in a query builder class. I send him messages expressing concerns regarding his approach but never got anything back. The guy just ignored me and asked me to review his pr.
I am leaving in 4 months. Release me from my misery. Fuck my life4 -
If I kept track of all the hours wasted on issues due to overloads of functions called ToList() it would probably make up a sizable portion of the project budgets.
If I call ToList on a query object, it looks like I'm trying to serialize the query definition into some kind of array. That's what it *should* do with that name. Bonus if the object implements some generic enumerable interface, ToList makes it call your database, you can just toss the query into some json serializer that blocks while calling ToList for you, and people end up doing exactly this because the code turned out so much neater.
Because that's the thing. It's like people implement it because it's "neat" and the user shouldn't care about its internals. How many tears would be shed by just calling it ExecuteAsync? -
In the beginning I was a retard, but then found out about React Query, learned it, made some abstractions around Axios and my JWTs, and now I have 200+ IQ.
God bless Tanner Linsley, you mormon crazy bastard, you did it, you made my life easier.8 -
Thoughts on the idea of including links/query starters for debugging or where the fucking logs are in AWS, grafana etc in repository READMEs?1
-
I used alot of if checks to convert category name to category ids for sql query. For eg.
/Index.php?cat=venue
And I handled it like
If($cat=='venue')
{
$cat =1;
}
And so on.1 -
I had to start over learning SQL when I faced the JSON functions of PostgreSQL during a try and error period to get nested json_agg in one query.. I'am too old for that low level stuff! 🤨
-
So I am struggling with a SQL Query for my Database lecture.
This is the Table Layout:
Users(id:integer, reputation:integer, display_name:string,
day:integer, month:integer, year:integer, location:string,
up_votes:integer, down_votes:integer, age:integer)
This is the task:
Show the set of users who have the highest reputation and the lowest down_votes
than any other user. HINT: there is no user that is better than all other users on each of the
criterion individually. Thus, you need a query that can eliminate users that are worse on both
criteria than some other user (in Economics your query will return what is known as the Pareto
Set).
I have looked up the Pareto Set but I am not really sure how to implement it into SQL.
So does any one of you know how to implement this or could anyone lead me into the right direction?
Help is very appreciated :)10 -
I took a long time to use prepared statements in a production php application instead of directly constructing the SQL query with the variables I had...
Like $sql = 'SELECT * FROM foo WHERE y = '.$search; -
Having a senior DBA can save hours if not days of struggle and save your back, if you do not know well enough how to do a more complicated query yet, without fucking up something.
Good guidance and experience is worth so much.
... and no I do not have the rights to drop databases.1 -
SQL is amazing.
I'll toss out some bassakwards query and the optimizer will make sense of it and suddenly I'm searching a amazonillian records in no time.
Then rando one day (today) I fire up what I think is really not the most wonky query I've ever written and ... "Well shit this is surprisingly slow."
So then I go full n00b and add some fields to the query that I know would limit the number of possible records to way low thinking that might help and ... nope no faster...
Guess it's time to bust open some books about SQL....4 -
searched for a query at google, and it returned only 5 responses. really feel like one in a million this time.
Can't be more sad than this.
#wow -
!rant
What are your thoughts on Xamerin ? (Spelling is probably off ). In any aspect: security, workflow, Flexibility, ect.3 -
So PHP PDOs... nothing fucking works. It's that or the lovely MariaDB implementation, I know that the query is correct and I've tried a stored procedure as well. The query itself ran once to add one user and never again while anything I try now doesn't return any result. I'm going to install Percona and see if it's the implementation or me.6
-
So i was writing sql query and every time i was getting "data type mismatch error."
In frustrations i slammed the table and went outside for some fresh air.
After 15 minutes i came back and runs the query again. Voila, it is working now.
My god these queries burned half of my blood today. LOL. 😁1 -
I had a discussion - no, it was more a lobotomy - with one of our "experts"
I was kinda confused, as he had several grafana tabs open and an query editor...
He explained to me that he debugs and optimizes his query based on the grafana data....
Elasticsearch cluster with several hundred, different indices, > 20 TB data
I explained to him the scrape interval of 5secs, that he cannot distinguish his query from other queries, that there is far too much of an interference... Let alone that a 5 sec scrape interval is a very loooong time.....
Nope. It makes perfect sense to him and he'll continue to work like this. -
Half a day wasted. FUCK!
I use grafana loki and mimir/prometheus for telemetry. A few days ago I queried loki to see if logging is still working. Yesterday I changed the datasource to mimir, changed the query parameters to get metrics from another env, ran the query, and... Querier [mimir] crashed.
Wtf.
Error says it got too much data to chew on.
So I spend 4 hours playing with the querier and grpc limits, balancing between limit errors and OOMKills [2G ram].
I got suspicious about oomk. Why would it...
Then I tried to shrink the timeframe to 15min. Still oomk. Down to 5min -- now it worked. But the number of different metrics returned was over 1k
then I look once again at the query. And ofc it is ´{env="prod"}´
turns out, forgetting that you're querying metrics with a logs' query is an expensive and frustrating mistake. Esp. at 3am.
idk why it even returned me anything...5 -
Why, oh why can I not just get distinct values in my query so I don't hit the goddamned list view threshold in SharePoint?
-
Working on a legacy PHP project that every single query inserts user-provided data without any sanitization, aka SQL injection ahoy! Also no framework.1
-
Only last month I removed a file called 'statuspage.aspx', this file has been sat there for years on our customer sites.
The file did one simple query on the database to ensure connectivity, this query dumped the admin username and password to the page, no encryption.
Needless to say we rolled out ab emergency update... Not quite sure how that made it through QA! -
Acumatica, left my last job because of that crap. Their implementation of a query language ('BQL') using generic types is horrendous1
-
Some days I'll just query my problem with another dev. Other days, I'm adamant to fix the problem myself and spend hours researching it
-
And here comes the next solution ...
exec("wget ".$foo." > /dev/null 2>&1 &");
$foo contains data from the users query ...1 -
Fighting for an hour explaining how a query wouldn't return the data he wanted...turns out it did...but really not sure how... FU Access!
-
So, I have a problem I'm working with mongoose in nodejs and I want to make a dynamic query like I have 2 fields gender and type of room and these are optionals so what I did I wrote an if condition that if gender is not undefined a variable which is q += "gender:" + " ' " + gender + " ' " + ","; and when I pass this variable in find() it doesn't work but if i write the same query directly there in find() it works what seems to be the problem?1
-
Do you guy know that there is a lot of short query name like "f" in web development?
We are discourage from using single character variable name and the query key is too short. Is there any specific reason for using short query name?6 -
One user could report that the data they saw didn't make sense. Turns out there was a one-off hardcoded caching detail for one of our services that cached based on a search query (yes, the entire query was the key) and before any auth checks. The system would return the results owned by whoever asked first, no matter who asked after that point.
There's "Oh dear but we all make mistakes" and there's surrender cobra. This is what PRs are for.1 -
Contacted so many people in the last 4-5 hours for my query regarding registering a client on the Google Developer Console. No answer has been received yet :(2
-
I asked the Node gitter community but didn't get any response, and I fear for my life when I am posting on SO.
So, I would be posting my query here. Any help would be appreciated.
Query:
Hey! So I have a code like
var cached = true;
if(cached){
}else{}
When the v8 will profile and mark this function as hot, will the full compiler optimize it so that the 'if(cached)' is not checked every time?2 -
Any Firestore experience willing to help me ?
I got 3 big collections let's say they are 1:1:n how should I save them in 🔥 so I can query them efficient when I have parameters for each of them in a query -
snowflake used to tell me seconds if i did something syntactically wrong and it can't run my query
now it takes 2 minutes to intialize the UI first? what the fuck?1 -
I don't get the hype about graphQL...it seems to be impossible to query over a structure with a deep of n levels (use it for a topology manager). In order to get the 5th sub-element you really need to specify the entire 5 sub-levels in your query...Why? Just the fuck why?3
-
"Then you get a message saying the software is no longer supported, but that's ok"
Outdated technologies ftw -
Being worst in relationships and having hard time in debugging on a simple query with multiple table joins was an disaster for me
-
I'm trying to make API calls to a service to query some info. This is all the information that's available for pagination. No info on max PageSize and there's no Pagination section in the output that says the number of pages of results that match the query. What am I supposed to do with this? -_-










































































































































































































































Top Tags
Weekly Rant
View