
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Loved the first project at the university. Your game had to load a map from txt file and create a labirynth with a player inside. It shoud include a bird's eye view and FPS-like - all using only console characters. There were some bonus points - for example for animation or built-in map editor. (language was C)
 29
29 -
So I'm working on a live map of my school's bus system, and I needed some filler images to test out how the stops were being drawn on each route...and honestly wish I could push this version to production
 11
11 -
A programmer is walking along a beach and finds a lamp. He rubs the lamp, and a genie appears. “I am the most powerful genie in the world. I can grant you any wish, but only one wish.”
The programmer pulls out a map, points to it and says, “I’d want peace in the Middle East.”
The genie responds, “Gee, I don’t know. Those people have been fighting for millenia. I can do just about anything, but this is likely beyond my limits.”
The programmer then says, “Well, I am a programmer, and my programs have lots of users. Please make all my users satisfied with my software and let them ask for sensible changes.”
At which point the genie responds, “Um, let me see that map again.”4 -
Bill gates found a bottle in his garden.
He decided to rub it thrice (whyever) and a geany surged.
Bill gates: h.. He.. Hello?
Geany : hi, im willing to give you one wish as you saved me
Bill gates: I WANT WORLD PEACE, HERE IS THE MAP WITH ALL THE WARS ON THE WORLD!!
Geany: thats impossible. Other wishes?
Bill gates: fix every bug in windows vista!
Geany: gimme that world map10 -
My non-dev boyfriend installed Python via the command line and ran a server to render a map of Pokémon in his neighborhood. I don't know whether to be impressed or scared 😂7
-
Found a Google employee in street view getting lost and using paper map .. There are also seem to be 2 guides with him...
I find it kinda amusing 8
8 -
A programmer was walking along the beach when he found a lamp. Upon rubbing the lamp a genie appeared who stated "I am the most powerful genie in the world. I can grant you any wish you want, but only one wish."
The programmer pulled out a map of the Mediterranean area and said "I'd like there to be a just and last peace among the people in the middle east."
The genie responded, "Gee, I don't know. Those people have been fighting since the beginning of time. I can do just about anything, but this is beyond my limits."
The programmer then said, "Well, I am a programmer and my programs have a lot of users. Please make all the users satisfied with my programs, and let them ask sensible changes"
Genie: "Uh, let me see that map again."1 -
Here is better picture. Map is kind of weird, but in the description of GDrive file there is a link to the original, where it looks better.
https://drive.google.com/open/... 5
5 -
"Why can't I just get the terminology right in my head"
java: map.
javascript: object?
python: dictionary!
ruby: HASH!
php: aSsoCiaTiVe aRrAy12 -
Just spoke with another teams developer. (She's using Java)
Her: so we get a json object from your service, I want an array
Me: well that's not what you said in the specs... And it's not hard since it's just a Map
Her: what Map? It's JSonObject I need an Array
Me: give me the library your using..
Her: here...
I Google the documentation and methods and paste the link and the methods to use:
-length (she also wanted count)
-toJsonArray
This ain't JS, just use the . operator and go thru all the methods' docs... Or learn to use Google8 -
Now that I have time to approach my ultimate dream ( being the pro penrester ) , asked a hacker for a road map and he gave me (U'll rarely see such open hackers that share knowledge :) )
Surprisingly I've been familiar with all the topics but being the most pro , requires u to be pro in every single topic .
Guess what ? I'm starting from basic linux commands all over again 😂
echo 'hello world :/' 25
25 -
When u did too much geocoding and map stuff. People ask me where u live, i be like I live at lat 43.8 lng -79.3. Find me homie, let's chill2
-
beginner coder: figures out how to write a feature
average coder: knows a few different ways to write a feature. but not quite sure on which one to use.
master coder: meditates before starting a project. closes his eyes to map out the entire infrastructure of the project.
god coder: gets paid ALOT of money to guide people on the right to do it.2 -
We have a Miro collaborative whiteboard where product managers map functionality and user flows.
It currently has 89442 post-its & arrows.10 -
Continued from pervious Rant.
The Drone sends out a signal to the Headquarters. A "Rare Entity Found" alert shows up on the screen. "Quick, load the map", says the General. Map shows the current location of the Drone. "Dispatch the Team", signals the General while his forehead show signs of tension.
Further down the room, a man quickly types on his phone and hides it.
Far from all this, in a quite city where the street lights have faded away. Old buildings which look like they are about to fall and crumble. The sound of wind can be heard for miles as there is silence all around. A light from one of building's room is turned on and quickly turned off. A man, checks his phone in sleep. Awakens and pours a glass of water to drink. Quenching his thirst, he opens his laptop. Laptop's light is the only light illuminating his room. He again gives a second look at his phone. The message is still there.
"It has been found"4 -
Once, when working on top down RPG, I woke up at 3am and wrote map moving system. It worked flawlessly. Later had to spend 2 days to understand how the fuck it actually worked.
Ahh nights so full of passion.2 -
Porting over code to python3 from python2 be like:
(Cakechat, in this case)
Day 0 of n of python 3 compatibility work:
This should be _easy_, just use six and do magic!
Day 1 of n:
Oh, true division is default instead of integer division, so I need to replace `/` with `//` in a few places.
Day 2 of n:
Oh, map in python2 behaves differently than map in python3, one returns a list, other an iterator. Time to replace it with `list(map())` then.
Day 3 of n:
Argh, lambdas don't evaluate automatically, time to fix that too.
Day 4 of n:
Why did I bother trying to port this code in the first place? It's been so long and I DON'T EVEN KNOW WHAT IS BROKEN BECAUSE THE STUFF RUNS WHEN I BREAKPOINT AND STEP THROUGH BUT NOT WHEN I RUN IT DIRECTLY?!
Day ??? of n:
[predicted]
*gives up*
I've had enough.4 -
chaosbot/chaos github repo looks like a London underground map.
Also, if you haven't seen this yet, it is a new project where code is updated by the community democratically.
Go give it a devrant hug of death. 2
2 -
Computer Science Teacher: everyone do a route in PowerPoint
Me: Can I do it in HTML + Leaflet?
CST: Yes, but it would be easier to do in PowerPoint.
-- trim --
* opens up Glitch *
* creates new project *
* imports Leaflet *
* connects OSMs *
* connects Google Maps thru GoogleMutant *
-- trim of interesting story how I copypaste coordinates from Google Maps into polyline with my grandma telling me where anyting is (our village is poorly mapped) --
Me: thank grandma
* project finally done *
-- the following day --
Nobody did the map with a route
Me: yay
* shows map *
* a bully asks what app I used to make it *
* I said that the entire app is a huge app *6 -
It happened just now.
Yes, I put "there is no need to be upset 10 hours" on governmental terminal.
#hackerman
How? Well, I discovered that it was web ui, so random menu category -> random external governmental website with Google map on it -> you know the rest. 4
4 -
* Colleague asks how to make a alias for IP address
* Open up notepad++ w/ admin rights and load C:\Windows\System32\Drivers\etc\hosts in
* add a new entry to map IP to the alias
* hit sequence [ENTER][ESC]:wq[ENTER]
* wonder why is notepad window still there... Did it freeze again?
... happens to me all the time :(4 -
This is supposed to be a huge European conference on logistics at hyperlog.info If these noobs will be inviting big companies, they better know how to make a map, that's not Hungary there and Europe has only one Slovakia
 7
7 -
Just to clarify thing, FaceID isn't the same tech as what we've had on Android.
In Android, it's based on image recognition. That's the reason it was so easy to bypass with a high resolution photograph.
In FaceID, it projects thousands of dots on your face and creates a depth inclusive map which is used for verification. That's the reason why it's supposed to work even if you have glasses on, etc
So please let's stop with the comparison11 -
Last week our department drama queen was showing off Visual Studio’s ability to create a visual code map.
He focused on one “ball of mud”, vilifying the number of references, naming, etc and bragging he’s been cleaning up the code. Typical “Oooohhh…this code is such a mess…good thing I’m fixing it all..” nonsense. Drama queen forgot I wrote that ‘ball of mud’
Me: “So, what exactly are you changing?”
DK: “Everything. It’s a mess”
Me: “OK, are any of the references changing? What exactly is the improvement?”
DK: “There are methods that accept Lists. They should take IEnumerables.”
Me: “How is that an improvement?”
<in a somewhat condescending tone>
DK: “Uh…testability. Took me almost two weeks to make all the changes. It was a lot of work, but now the code is at least readable now.”
Me: “Did you write any tests?”
DK: “Um…no…I have no idea what uses these projects.”
Me: “Yes you do, you showed me map.”
DK: “Yes, but I don’t know how they are being used. All the map shows are the dependencies.”
Me: “Do you know where the changes are being deployed?”
DK: “I suppose the support team knows. Not really our problem.”
Me: “You’re kinda right. It’s not anyone’s problem.”
DK: “Wha…huh…what do you mean?”
Me: “That code has been depreciated ever since the business process changed over 4 years ago.”
DK: “Nooo…are you sure? The references were everywhere.”
Me: “Not according to your map. Looks like just one solution. It can be deleted, let me do that real quick”
<I delete the solution+code from source control>
Me: “Man, sorry you wasted all that time.”
I could tell he was kinda’ pissed and I wasn’t really sorry. :)2 -
boss: we should map all the possible ways to do things in the system so we can test them and make sure we fix the bugs.
Me: yeah, well, that is exactly what automated tests are for, every time we find a non-mapped way that breaks this we make a test out of it and fix, this ways we end up mapping the majority of ways.
Boss: yeah,yeah ... Let's sit down latter and map everything on a document.
I bet my ass we are never gonna have tests as a part of our workflow.3 -
If you're using snapchat you might want to go on it immediately and change your privacy settings.
New update came out, they added a map with everybody's locations down to a couple of meters in accuracy... And the feature is on by default for EVERYONE to see, not just your friends.
What the actual fuck were they thinking?? Just think of all the ways this can go wrong.9 -
Same days you just need a duck.
Me: map.get(record.Id)
Code: null
Me: no, map.get(record.id)
Code: null
Me: let's grab this record from the map
Code: null
Me: what the flying fuck, take this fucking ID from this fucking RECORD and find it in THIS god forsaken map.
Code: null
Me:.......
Code: 😉
Duck: did it occur to you the ID exists only AFTER the map is created.
Me: you fucking wha..... oh I'm a dick head.7 -
I found this cool C code that prints map of India. But code went straight over my head. It looks cool though!
Here's the code if can explain!!
https://gist.github.com/Deepamgoel/... 3
3 -
The moment when you see "block chain" on a client's road map, but they can't tell you what that is or what they want to use it for5
-
Client : Use google map because it has more data but make sure the location and navigation in the app as to look like Apple Map.
Me : 😧😧1 -
You know a project's gonna be a pain in the ass if one of the file's the mini map looks like this. But wait there's more, this mini map is just a quarter of the whole file. Fuck
 15
15 -
Any thoughts on whether my alternative keyboard layout will lower my risk for wrist pain? I map each key to an Amazon dash button on each edge of a large bookshelf in my office. It's lots of exercise, and I'm almost back up to my old typing speed.1
-
My favorite game just released a 3D map of their universe.
That's fucking awesome! How much work this had to be.... OwO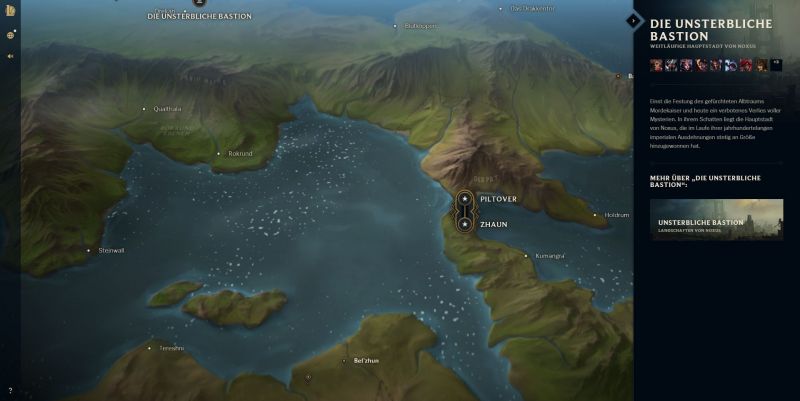 10
10 -
The joys of mapping...
I'm playing around with some cartographer parameters and this happened. Thought it fits the christmas theme and was kindas beautiful so decided to share.
It's a map snowflake :3 9
9 -
First personal project in my new employment.
This is the situation:
[ • ] Frontend
Drupal with custom module which load an Angular 6 application inside certain urls. Da hell for my eyes but interesting in somewhat.
[ • ] Back end
SharePoint "database" middled by a my-boss-written Java layer used to map SharePoint tokens in something more usable2 -
The devRant July 13 update and roadmap is amazing. Great recap of recent happenings and the map to an exciting future.
I am proud to to be part of this wonderful community.
devRant rules! -
I knew I was destined for programming when I was 11 or so, and I would spend my days after school until bedtime building levels with the Doom map builder. Shortly after that I begged my parents for a C++ for dummies book. Never looked back.

-
Guess the developer did not expect this to happen.
Currently over at OpenStreetMaps.org (I requested a map for download) 1
1 -
One of my android project finally compiled with no errors!!
Happiness increased when it didn't crash👻👻👻
Finally some relief 😊😊😊3 -
Trying to hire more good devs... it's surprisingly hard. Guy with supposed decade of JavaScript experience fails code test, "I don't really use map function so I don't know it."
R U kidding me
...and yet my "maybe we should consider remote devs" idea isn't getting any traction :/9 -
Highschool teacher tells us to work on a little text game, gives us 2 weeks. I wrote about 1600 lines of code with enemys, random map, fighting system,... And generally blowing everything out of proportion as always, because I'm so bored4
-
Did a few world map generations with the openmaptiles self generation tools and all went well.
Then, suddenly, no matter what system I use, it crashes with a Go error (I don't know much about Go).
Nothing changed in the repo and nothing changed in the OS.
Fucking hell.10 -
A dev posts a link to his website on a dev group I admin, first thing said site does is ask for my location. I look, no map not logically apparent reason for it, so I close the site.
Ask they guy why he is asking for such private info and he responds to tell me that he does not think a person's exact location is that private, and if he really wanted it he would just use the IP address.
Like how many fucking levels of dense is that.5 -
Was creating an interactive map through Google Maps API. The map wasn't displaying at all on the website. Spent 2 hours trying to fix. Just realized I've not given height to the map div :-/1
-
Do you remember GAME LOGO programming language where you can move the turtle around the map and draw lines? Someone made a Lisp out of it!
https://toodle.studio/ 3
3 -
Why the fuck do managers think beacuse a component has been build by another developer a shit ton of time ago, we can still reuse that fucking code.
For fucks sake, I had to rebuild a whole fucking map component that needed contextual filter and the fuckers just add extra functionality without consulting me. And gave me a tight schedule bc the customer, who btw disappeared for 6 months, will be mad for wasting his precious fucking time.
Fuck these clients.10 -
Maybe it's not exactly about programming, but sure damned it caused it.
Back in the day I managed to create a warcraft 3 map which played tetris. The orc peons ran down with faster and faster speeds, since it was a multiplayer, we used to play it with friends. We played it so much during the day, that all of the dreams were about orcs running and exploding once you finished your line. It was the only dream I remember having.2 -
That moment when a client is all upset about a tiny bit of cutoff of some text, but they haven't noticed they've been missing labels from their map for who knows how long...
-
Kernel coming along slowly but surely. I can now fetch the memory map and use normal Rust printlns to the vga text mode!
Next up is physical memory allocation and page maps 17
17 -
Computer engineering : Insanity!!!
Today a friend of mine was assigned to make a Client-Server Encryption using Sockets. The guy did a great job applying BlowFish algorithm, but the teacher was disappointed because she couldnt map letters to the encrypted text and she declared the program to be wrong!!!2 -
In the office I had the dashboard with coronachan stats and the map on the huge tv but the HR told me to stop that 😭8
-
I FINALLY comprehend list comprehensions.
I can write an unlimited amount of nested loops on a single line and make other less experienced people hate me for fun and profit.
Also learned about map() #I hate it#, zip(which is awesome), and the utility of lambdas (they're okay).
Enumerate is pretty nifty too, only thing I lose is setting the initial value of the iterator index.12 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!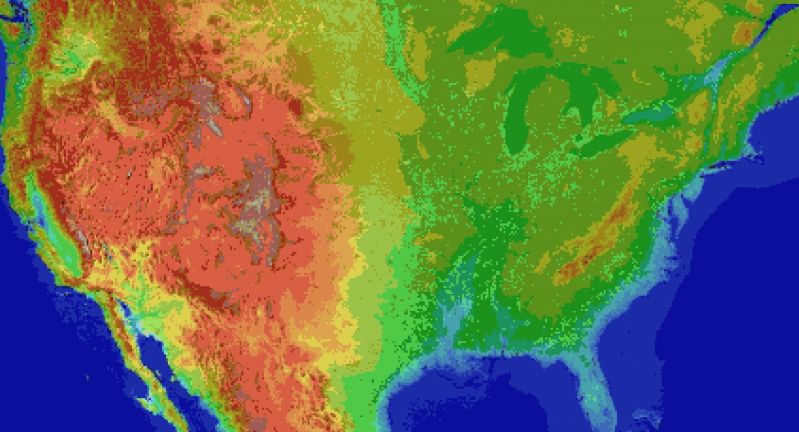 5
5 -
Why does google do this? It's supposed to be a map, not a fucking travel guide, I want to see the motherfucking map that it so ironically calls itself
Swallow a Collins road atlas whole you fucking impostor. 9
9 -
Just spent an hour looking at the NYC Subway maps vs the direction Google wanted me to take.
Google found the most efficient way is to take E train then transfer to R which then goes back a bit like a U-turn to get to my stop.
Then looking at the subway map, I can just take the R train... Since none of these trains are express... How the fuck did Google think that A-B-C is faster than A-C....10 -
I am currently refactoring some code which exists before my time in this company.
The code was so inefficient before. To put into perspective for every function call it used to loop through some data 100+ times .
I replaced it with a map and voila, no more loops anymore.
The person who wrote this code don't even realise how bad his code was. He sits besides me writing more stupid hacky code for other parts of the app.3 -
At my last job, I created a Google Map for a client, where you could click on any department from France, and it would tell you about all the antennas (think "outpost") of his society. I used a Google Fusion Table where I registered everything: the datas to display, the coordinates for every departments and for every region.
I then wrote a 15-pages long document to tell how to maintain that, since I used my personal Google account to create the map. Anyone having a full access to the website should be able to recreate the map from nothing and witout writing a single line of code.
Then I switched project, the company kind of fucked me over, and I just received a mail saying that Google Fusion Table will be put down in a year.
I just hope they didn't receive the mail. -
I can't sleep whenever I remember ,few year before I paid $25 for ethical hacking workshop and they show us inspect element n SQL map
-
I just managed to configure a second keyboard to map its keys to separate keycodes. Basically, I should be able to use it as a complete macro deck 😏 Thank god for Linux5
-
@dfox Yay for new items and desks, but I'm still not seeing my world map desk, and that should be a must. Everyone has one like that, no?
 8
8 -
Excited to start learning some backend for the first time while building a side project! First experience setting up a dB, map tile server, api, geocoder, etc. to make something completely self-hosted! 😊2
-
Basically every time a designer thinks they made the perfect design and that if the program works by itself that's it. No man, I still have to spend hours trying to make every element of my program map to the elements you put for me to use. Give me time!
-
I genuinely just found solution to a dev problem in an xkcd comic.
I defy anyone to come up with a geekier solution to a problem than the Peter Carre map projection.1 -
The solution to missing esc key is to map it to caps lock, like we were ever using the caps lock......
Now cut the ranting, you have a solution8 -
> be me
> post reasonable question on SO
> get downvoted the next minute without explanation
> come to see that downvote has been removed
> yay.exe
> come to see someone explained that why is that question wrong
> totally unrelated comment
> gets downvoted again
> https://stackoverflow.com/questions...9 -
I'm building a cross platform mobile app for this sales company to manage sales of each Van Sales Representatives. The app displays details of the customers; name, address, etc...
After demo, they requested for a map inside the app, specifically on the screen that displays the customer details for easy navigation by their VSR.
All attempts to convince them to use Google maps failed :(3 -
Map/filter/reduce in a tweet:
map([🌽, 🐮, 🐔], cook)
=> [🍿, 🍔, 🍳]
filter([🍿, 🍔, 🍳], isVegetarian)
=> [🍿, 🍳]
reduce([🍿, 🍳], eat)
=> 💩 -
It is map of various devices connected over public IP to internet. Any interesting insights or comments that you can infer from this map?
 14
14 -
Ugggh. Has anyone else on here worked with MFC?
I've been updating some legacy software and it's been like wading through a swap that was caused by a malfunctioning trailer park septic system: no map, and mostly shit with the occasional nasty surprise. -
Have you ever played Zelda: Breath of The Wild?
Have you seen this system where you set a point on the map, and see a colum of light going up from this point with the Sheikah tablet?
Man I'd love to do that in an augmented reality system on a smartphone 😍5 -
I'm working on a pretty Plotly map. To learn how to use bubble graphs, I've copy-pasted the example and modified it.
The example is ebola occurrence by year, Plague Inc style. So naturally I need to add some countries. For testing, of course.
Ebola for everyone! Yay.
I like my job.2 -
How to kill Jira Backlog in one simple step:
1) put '-∞' to Storypoints
2) enjoy
(Bottom line: it can be fixed from User Story Map to something normal)
-
Work on a Python mapping project, get everything right except changing color of points on the map. Take a long break on that project, come back and realize I made a capitalization error 😂😂
-
~Of open worlds and post apocalypses~
"Like dude. What if we made an open world game with a map the size of the united states?"
"But really, what if we put the bong down for a minute, and like actually did it?"
"With spiky armor and factions and cats?"
"Not cats."
"Why not though?"
"Cuz dude, people ate them all."
https://yintercept.substack.com/p/...8 -
I just played a few old maps I and a few steam friends made and it brought back the feelings. I had to open a few maps in hammer (Level editor) and see myself around.
I completely forgot the controls in hammer and had difficulties to recall how to import assets from a custom map. Everything was clunky.
It kind of makes me sad when I look back. I wish I could still map - but the school will start tomorrow and I guess I have no time for that. The same thing happened with playing the piano. Once I reached a certain skill level, I stopped although I loved it. I stopped progressing.
Unreal engine isn't fully my thing, I feel uncomfortable working in it, though I still want to make games. I found myself not opening it for a month or so.1 -
Same as when I go gym..
Deep breaths to get calm,
focus mind on clarity & stillness
then visualize, map & draw out exactly what I'm going to do and how I'm gonna go about it.
Finally, execute.2 -
LIRR system rant 2 - there is a thing called a sensor. Can you please paste them on your trains so we know on a real-time map where the train is. If it's 8 miles away when supposedly 'on time' we don't have to freeze on the platform. It's 2016 not 2007.2
-
So, my company pays thousands and thousands of euros just to show map and enable geocoding, a bug in google maps prevent Google Maps to work in Cordova and it's blocking us from deploying. After days and days of research I understand I can't solve it and I open an issue on google platform. Result: Severity -> S4, Priority -> P43
-
Question and Update.
First of all, I would like to thank @ScriptCoded for an idea in the previous post, so then I have beautiful terrain now, and the complete world map generated like plots, and each of them consists of 5x5 different plots defined by neighbors :) Hired a digital artist who is working on much nicer plots as well.
The new issue is regarding the zoom.
The map is saved as JSON with the pixel-perfect location of each generated plot so I am detecting the collision with the mouse based on their location. After I zoom in, the script is still comparing the pixel location of the element, but the real screen is scaled already so the pointer is off (image2). The problem is described in image3 as well. How can I still get the canvas relative value of the mouse instead of the x,y coordinate on the current zoomed screen? 9
9 -
Can anyone recommend a good free blogging site?
Was going to use wordpress but im not paying 130 AUD just to map it to a sub domain.
Blogger has very few options when it comes to themes and custom themes.
And tumblr... Is tumblr (I was using it but decided to rid myself of such filth)7 -
Toilet Dev rant - my urine went into mute mode when that creepy business head almost 7 feet stood in the urinal next to me and said hi. What the fuck from such height he can easily view the entire map of the urinals and what not. And why the fuck my urine went mute not even a single drop went through. I hate it2
-
Devs who use the array map method for purposes other than generating a new array, and who use an empty return statement to satisfy the linter, should receive a slap in the face. A gentle one, but a slap nonetheless3
-
Just a short reply to whoever deleted his rant because he didn't read the JS docs.
map is a map. You don't just dump a function call into there. You map the value to el and the value is then set to the function result.
This works:
new Array(38).fill("10").map(el => parseInt(el));6 -
Well i am working as an intern at this startup. Initially it was all simple crons and database. After one month one of the founder asks me to map two tables, create an api, integrate a fucking payment gateway and i am now left with a lot of work and confused state of mind.
PS: i am first year cse student -
It's clearly in the contract people.
You walk a client through the entire contract and come launch they want to add pages and change layouts without paying extra because they have 24 hours to launch.
What don't you get about "you approved the site map, layouts, and designs which is what we quoted you for, contract clearly states how much per extra pages and how much to change layouts and designs after approval and work processed" -
So apparently south korean maps are top secret and do not allow for styling in google maps:
"Yes , Korea does not support some features offered by Google Map due to national law. Google Map Korea can not be export map data for data centers abroad or including the ability to dynamically change the map image. Many South Korea Maps and services are limited to the domestic uses and Google is striving to make this a better service."
sources:
https://snazzymaps.com/help
https://stackoverflow.com/questions...
https://productforums.google.com/fo... 3
3 -
Management: let's be agile... we can all meet and discuss a project that will take more than likely 6 - 12 months but you guys can estimate and create a road map....
Engineer: I'm not sure you understand agile3 -
Data representation is one of the most important things in any kind of app you develop. The most common, classic way to do it is to create a class with all the fields you want to transport, for example User(name, lastName). It's simple and explicit, but hell no, in my current company we don't play that kindergarten bullshit, the only way we know how to do things here is full hardcore. Why would anyone write a class to represent a Song, a Playlist or an Album when you can just use a key-> value map for pretty much everything? Need a list of songs? No problem, use a List<Map<String, String>>, OBVIOUSLY each map is a song. Need a list of playlists? Use a List<List<Map<String, String>>>... Oh wait, need to treat a value as a number and all you have are strings? That's what casting is for, dumbass.
No, seriously, this company is great. I'm staying here forever!1 -
Today I actually used a data structure other then List or Map for a real problem!!!
This is like a once in a year, several years thing? (Technical interviews don't count)5 -
When your frontend does not really get what your backend is trying to say...
This is oalley.net. Apart from the fact that their frontend and backend do not work together very well, it is a nice tool to mark reachable areas on a map based on the starting point, the means of transportation and the maximum time.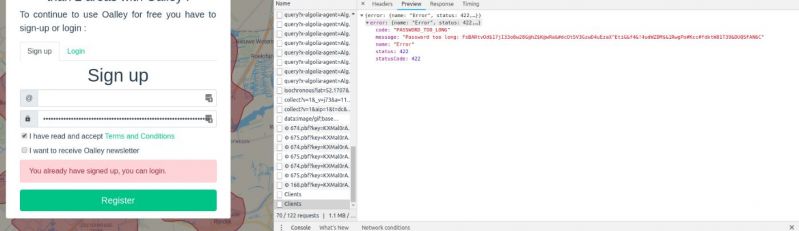 5
5 -
Forgetting every day tasks...
So I can use map, reduce, filter in my sleep, have memorised huge chunks of valuable programming information.
Today I went to the gym and laced up my jogging pants, looked at the vogue knot I'm supposed to tie to prevent them from falling down and my brain just said:
"Fucked if I know how to tie that!" -
That feeling when you have to rebuild and redeploy project for the third time in a row because java can't map Swedish letters. About 20mins for each try.3
-
Yesterday had fogged mind all day long. I felt like the biggest r-word in the world. Couldn't even map some simple API arrays.
Tool Laterus just makes me woke AF.
Been coding hard today since I turned on the pc1 -
I just spent 4 (four) hours debugging why my perlin noise used the same gradient for every point. Turns out I forgot to assign the seed for the random generator so it defaulted to 0. (I seed it every round with the map seed and coordinates so I don't have to store anything for visited regions)
So, how's your sunday night going? -
Testing a script embed plugin I am building on various random websites, and came across this.
Like, bruh; have you ever heard of a javascript map? Basic functional programming? Or even a switch statement?
It's the same statement, over and over again, but with different parameters. Even old javascript had enough tools to do this with at least a basic stench of "efficiency"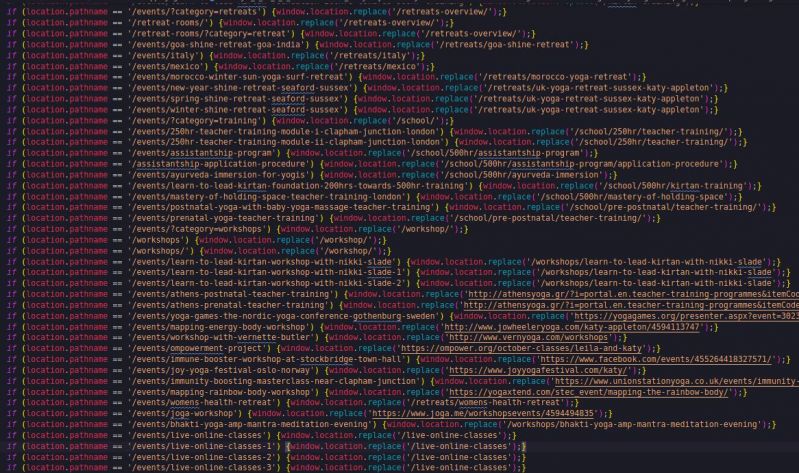 11
11 -
There are days I like to pull my hair out and create a dynamic 4D map that holds a list of records. 🤯
Yes there's a valid reason to build this map, generally I'm against this kind of depth 2 or 3 is usually where I draw the line, but I need something searchable against multiple indexes that doesn't entail querying the database over and over again as it will be used against large dynamic datasets, and the only thing I could come up with was a tree to filter down on as required.6 -
Converting javascript/ typescript Map to json
or python date to json
or anything complicated to json is mostly ending with implementing serialization patterns
With date it’s so annoying cause we have iso standards that every language implemented or have libraries
so typescript doesn’t recognize Map<string, string> so you have to convert it to array and then to object
with python you need to make your own serializer / deserializer
So much waste of power usage that if only Greta know it she would say ‘how dare you!’
It can stop global warming.5 -
You know how people want to avoid collisions with a hash map?? Well a buddy and I went to a hackathon about 2 years ago, and the idea we had was kinda cool, but to get a prototype working, we decided to defy the logic of a hash table and purposefully cause collisions with a hash map. I took a look at the project and it is soooo poorly implemented.
-
!!THE WORLD IS COMING APART!!
How in gods name did Putty manage to map a SSH tunnel to port 83306 and MySQL Workbench just didn't care and worked?!?!3 -
That feeling of utter uselessness when you read "Really? That took you all day?" in your gf's eyes when (proudly) showing that you finally got the map markers working reactively on map drag.
-
Does somebody know a js library to make a route network on a map, like the ones airlines use. Where you can enter/click on the departure and it displays a forced node graph of the destinations from a database. Like this: http://easyjet.com/ch-de/...
Google shows only computer network related mapping stuff *sigh*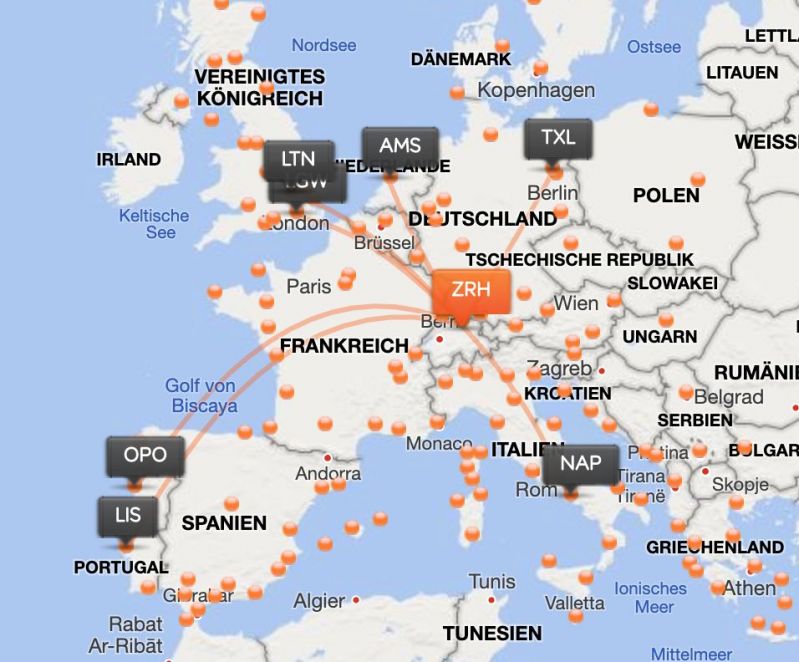 3
3 -
How do I become good with functional features(map,reduce,filter,zip,flatmap) in Javascript and Python?
It feels so alien. I'm so used to writing plain old loops.
Reading and undersranding this kind of style in other people's code is really hard for me, especially if all this is happeining on the same line.4 -
:-(
Firefox doesn't map correctly the controller (Xbox One) but it works on Chrome. (FF on Android Works)
This is literally the first time (for me) that something works on Chrome and not on FF. (at first shot)
usually it is the opposite.
One point for Chrome (this time)
but still 6,022*10²³ Points for FF.3 -
What's your opinion on functional shortcuts and 'hacks' in many languages, like map/reduce/filter, ternary operator, lambdas,inner/anonymous classes?
Imo they can make development faster and more efficent but they make the code very unreadable, especially if someone else has to read it, Therefore I try to use them only when it's appropriate. My dev friends use them too much and it makes reading their code a hellish experience, especially in Javascript with Rx.3 -
Reading through the bugs list on Trello...
- change colour and style of button to make it more prominent
- change default for select box
- add a popup to explain the UI on 1st visit
- if I don't save the entry, show alert to user on exit
- remove the map button under the map that links via auto scroll to the map above it
- remove the settings options for the items we designed but you couldn't implement due to lack of time / budget / low priority
It goes on, seriously...
FFS1 -
Just spent 30+ hrs on an error that was due to using flatMap instead of map.
I feel stupid!
Pro Tip: Never try to learn Spring without learning java properly. -
Implementing a for loop in js because I need to skip some elements in a map as I transform. I'm feeling dirty
* cries in functional *3 -
The worst part about switching code from python 2 to python 3:
`map(myfunc, mylist)`, behaves differently, but won't throw an error. It will just show up as nothing.3 -
Is there a Map like class in Java that has
getKey(value), getValue(key).
Guess not hard to implement but why reinvent the wheel..15 -
Here at the end of high school they make you create a sort of mini-thesis and/or a conceptual map. I found mine in midst of full blown bedroom chaos, dated one year ago (it's in italian because I am italian but you can definitely ask for translation). I got that fucking diploma despite all the issues I had and still have. Fuck 'em.
 4
4 -
Best Explanation I found of every(), filter(), map(), some() and foreach() methods in Javascript
(at least for me as a non-js dev)
could help someone there
https://coderwall.com/p/_ggh2w/...2 -
This just in, a message from firstparty watching the customer test what we did:
"the chines client has a problem with the Picture of the Map (at Team).
Becaus of the policital situation in china he asked to remove the blue highlighted border and only show the neutral map.
Since Daniel is in holidays, can you do that? If not, can we than just remove the picture, an replace at with a chinese flag please?"
I saw that, and chuckled, thinking "oh yea, i almost forgot for a moment that china is ass hoe".1 -
Today there was a question on the react native forum asking how to map an array..... ([].map(mapFunction))
1) it's the wrong place for the question
2) like 80% mentioned ramda, lodash, underscore :(7 -
Have you ever worked with leaflet.js to display openstreetmap? I do and its great.
But now I want to display multiple markers on a map and the map somehow only renders random three markers. Wtf?
I'm lost. All results on google show me how to do it right, but it just doesn't work.16 -
Our app has web scale data. So let me take all my tables from a relational database and map them one to one to a collection in a document database.
-
Currently working on a Stardew Valley mod.
I'm injecting a custom map as a .tbin file and loading it.
Works perfectly fine.
Can edit it ingame, plant crops there and shit but when I save and reset the game.
Bam changes gone.
Apparently I gotta write an extra method for saving the current map, in the game back into the base map which exists as a file in my mod's folder.
AND GUESS WHAT.
NO IDEA HOW TO FUCKING DO THAT.
SMAPI IS SO HORRIBLY DOCUMENTED FUCK IT2 -
The person who wrote this map framework in our old fat client has such a deranged mind that 4 days in I still haven't fucking clue how it works
-
Create a p2p version of Google Maps / OpenStreetMap that uses people's browsers to store the map tiles of "their region".
Started already by building a proof-of-concept called p2p-fetch[1] (uses GunDB under the hood) and mixing it with the awesome Leaflet library.
[1] https://github.com/davide/p2p-fetch2 -
The forEach in JavaScript makes no sense. It looks like a map /filter/reduce but doesn’t actually return the array. Can you please loop like a normal language?8
-
Change my mind. Golang can be more difficult than it needs to be sometimes:
Find the first "non-null" value in an array:
Go:
Optional<String> result = Stream.<Supplier<String>> of(
() -> first(),
() -> second(),
() -> third() )
.map( x -> x.get() )
.filter( s -> s != null)
.findFirst();
Ruby:
@group_list.find { |x| !x["list"].blank? }16 -
I'm getting closer to kick out the excel sheet to find points on the map. I can't believe that a company with hundreds of millions of profit has to use excel to find a stupid point on a map...1
-
This was a project for school, we had to simulate an app that traced bus routes over a map.
All the teams but mine do it in Java (desktop app), we took another approach and did it on Android with the Maps API.
I had fun coding a parser, this parser job was to read a file and load the bus routes and draw them on the map.
It was structured like:
NAME
COLOR
<lat, long>
<lat, long>
The fun part was coding and telling my teammates "chill out, it will work", so we finished, built and run and... done! First code working smooth AF.
I know it's a simple parser and a simple app, but it was a nice feeling not having to debug the app.1 -
that feeling when you want to take off a few days of work to REALLY research Perlin noise and displacement map filters.
-
Just figured out "code map" and "code clones" on VS 2015 (don't ask me why I didn't know these features)
Thought I should try it on my newly created application for a client (+/- 1500 lines of code C#)
Came across 1 duplication, 0 unreferenced classes or members and no circular references
I'm just awesome -
It's always great idea to map common keyboard shortcuts to something completely different, such as when IDEA sets the default behaviour of Ctrl+Y to "remove the line under caret". Thanks guys, I love surprises, next time try something with ctrl+c.
Note to my future self: when installing the IDEA again, remember to remap the ctrl+y..1 -
Am I the only one that when he haves to download something (a map for a game, as example) download a whole pack and end having 40k files that I'll for sure not use them all..?
Because it finds out I just downloaded 200k files... :)2 -
Got a few
Crystal reports - words cannot describe how much I loathe this
Sybase ASE or IQ - both are just a hot mess to setup properly
Not a service now fan either
Esri map processing - basically entirely undocumented, slow, old fucking hate it
Arc GIS online - ridiculous licensing issues, undocumented APIs are given as official answers from the dev team, massive pain in the arse3 -
It was a little Java Swing Application for my friend who had to maintain a little notebook for his insulin values.
The device he used to read his values, saved them as a csv-file, so it was pretty easy to map them to a readable format, so he didn't have to maintain that notebook.
He never used the App. He got an implant that manages it for him.1 -
Google map: "turn left your destination will be on your left", and 2 seconds later, "turn right and your destination will be on your right". 😐 So my destination is behind me?
-
For me, PHPStorm's mini-map is ugly. Nothing compared to VS Code and Sublime Text.
I will uninstall it now.4 -
Fuck off slickplan. Your subscription model is not for the little guy. i love your site map builder, but I cant justify $118 a year for my 6-8 annual site maps. i’ll use keynote. if you price stuff properly then you’d have more subscribers. greedy cunts. it tends to be the way with a lot of online services. people will gladly pay, but it’s gotta be of value. you think twice when you start getting pricey.
-
stop using arrow function everywhere!!!!!!!
what that is mean ?
fns.reduce( (prev, fn) => fn(prev), input)
Are this is `fns.reduce` with two parameters
Or arrow function that return `input` variable.
take your time to visual parsing this crap4 -
Hey ya'll back with another college boi question.
I want to develop a web server akin to that of jackbox/among us. Where each session has like an 'ABCXYZ' style code, and i assume are using TCP sockets on the back end.
I'll be writing in Go cause I <3 Go and its a chad language. Anywho, am i supposed to spin up a new websocket server each time someone wants to make a room? Or do i have one websocket server and some sort of map of rooms.
gameRooms := map['id_string']clients
Anyone have any suggestions for this?7 -
In an object/dictionary/map config object where multiple source paths are mapped to destinations, which structure makes more sense to you (and why)?
1. { "src/path.ext": "dest/path.ext" }
2. { "dest/path.ext": "src/path.ext" }
Could also be a URI redirect map4 -
When ur pm just attended session on map-reduce and starts using it evrywhr.
Development manager: this will take a month to complete this module.
Project manager: hmm! We need to get this done by 2morrow and I hv a plan. -
Devs with gaming mice.
What hotkeys / macros do you use?
For years I've been using gaming gear with additional buttons to map various hotkeys and macros to speed up my work flow.
Let's share the use cases here.3 -
I can't believe it... I am starting to recall a very old TV child's sitcom I used to watch. I have so many memories... I just can't. I'm going to send a sample, it's in Hebrew, but hilarious enough to understand.
This is a part of a parody on Dora the explorer. It was a legendary episode. The parody is that it's a Yemeni version of Dora the explorer. It's the map. Yes, the MAP.
https://youtu.be/tNJdi1055BI10 -
Did it ever happen to you that you were needed to map a mental and overly complex for no reason db schema to a simple json, and you hate yourself more every key you press because rewriting it more efficiently and simply is never an option?
How do you cope with managers and legacy code?
If it works does not necessarily mean that we should keep it, jesus christ.2 -
It reaaaally annoys me when my business logic is sound but the data is corrupted.
For example, find duplicates in a HashMap<String>.. but I didn't take into account the input could contain a space either before or after.. so I end up wondering: if a HashMap only contains unique keys, how come the count of items in the map is the same as the count of the input keys?! Well.. spaces were the culprit.
"12345" != "12345 ".. and therefore the Map sees it as two distinct keys..
What an annoying bug.
Lesson learned: 1) Sanitize input first and never trust it. 2) Never make assumptions15 -
Thinking to reduce google foot print by replacing google map with here map... Any suggestion before I do?10
-
Issues with google authentication cookies. Many 3rd party applications (like mindmup etc.) have already reported. Me too so many times.
Today I'm logged in with my google account. But !!! when I try to review a business on google search result or map, they're not able to sign me in.
:faceplam:
Google doesn't like feedback or error reporting.4 -
So I have a programming question that has always stopped me from making so much. I wanna make stuff in the terminal like Conways game of life and simple games but I don't know how I would track everything like or how to set up the map/board and how everything moves and just all that.. does that make me a bad programmer? I'm fairly new but still..
And no I dont wanna Google it I'm trying to work on being social even if it's online4 -
So once again, I'm planning for a new website I'm developing, a little side project. I tend to put pen to paper and map out what features I want to include and see where that goes.
It's got me thinking how everyone else likes to plan for their personal projects and if I'm missing a trick?2 -
I need advice. I'm to create a web application with an interactive map (lots of polygons to put on it, with markers and other map things) with a large amount of data and it is expected to have frequent changes to the said data. I have no idea of the tech stack to be used and the performance of the app is the biggest concern. (I'm thinking maybe to create an API, use MongoDB, then create a web client for it but I'm not that sure). Please give me your insights.7
-
New data structure:
Map with repeated keys allowed. Values of repeated keys will be stored in an array.
Calling get(key) will get the array, pick a random entry in said array, and return it.
Use: Finding what the "number one rule of x," the "greatest thing ever," the "most unbelievable event," and more is. -
For Software consultants.
I am newbie with 2 years of development experience. What should be my road map for being an independent software consultant in the long run.2 -
I used to tell people i can put a google map on their website and charge for the installing the free service. Now the service is not free. Fuck Google, i used to love everything they stood for. Now i can see the corrupt greedy assholes in their true faces. Web development will never be the same.2
-
Want a simple but terrible annoying prank?
Change the keyboard map from UTF8 to ASCII or vice versa and set the system font to something funky like a Greek or Cyrillic variant... :)1 -
I've worked on countless products and maybe one bigger one (map portal for a national park) and one side job (randomized svg to g code) had any positive social impact. I've been paid for being useless but busy. The entire economy is a scam.1
-
Not a webdev so I don't care about how a website looks, but logical failures can really trigger me at times.
E.g. this German federal page you had a bunch of options to fill in your employment status. Though being incomplete it forced you to choose one from the list and then at the end you have to checkmark that you filled in everything correctly reminding you there might be legal consequences otherwise. Thanks.
Amusingly on the same page their enum to string converter seemed broken or they just didn't care. So options to choose from read like: Enum_marital_status_unwed_coupled
Fucked up the screen shot so I can't show, but made me chuckle.2 -
Asked to map the old database into a diagram. Looks like someone threw up spaghetti. It is so full of tables named "obsolete" I don't understand!
-
Made a proof of concept combination of React + Highland.js + Recompose: https://codepen.io/hedgepig/pen/...
It's scrappy now, but the idea is a streaming alternative to redux/mobx whatever. This nice thing is one can treat events as a function over time, meaning one can map, pipe, reduce (scan), zip etc.
Going to try it on a side project (potentially Hive Sim: https://devrant.io/collabs/975778) and see how it goes. -
I have two laravel apps. Both sharing one redis db. One has App/Post one has App/Models/Blog/Post. When I unserialize models from redis cache saved by the other app I get issues because it cannot find the right model to hydrate.
How would you build a custom map to get the right model?15 -
Question: which is better approach?
1. Use push notifications to tell react website that new data is available
OR
2. Use SignalR (similar to socket.io) and push data in real time?
The down side of SignalR is server needs to map connections --> use more memory while push notifications doesn't require that12 -
There was a holiday in my area but someone reported that Google map is showing that roads are blocked instead of no traffic.
Ah! they forgot to improve their algorithms to analyze the traffic by getting user's location "without permission" against festivals in India. -
If anyone has a moment.
curious if i'm fucking something up.
model:
self.linear_relu_stack = nn.Sequential(
nn.Linear(11, 13),
nn.ReLU(),
# nn.Linear(20, 20),
# nn.ReLU(),
nn.Linear(13,13),
nn.ReLU(),
nn.Linear(13,8),
nn.Sigmoid()
)
Inputs:
def __init__(self, targetx, targety, velocityx, velocityy, reloadtime, theta, phi, exitvelocity, maxtrackx, maxtracky,splashradius) -> None:
# map to 1 and 2
self.Target: XY = XY(targetx, targety)
# map to 3 and 4
self.TargetVel: XY = XY(velocityx, velocityy)
# TODO: this may never be necessary as targeting and firing is the primary objective
# map to 5, probably not yet needed may never be.
self.ReloadTime:float = reloadtime
# map to 6 and 7
self.TurretOrientation: Orientation = Orientation(theta, phi)
# map tp 8
self.MuzzleVelocity:float = exitvelocity
# map to 9 and 10, see i don't remember the outcome of this
# but i feel it should work. after countless bits of training data added.
# i can see how this would fuck up if exact values were off or there was a precision error
# maybe firing should be controlled by something else ?
self.MaxTrackSpeed: Orientation = Orientation(maxtrackx, maxtracky)
# these are for sigmoid output, any positive value of x will produce between 0.5 and 1.0 as return value
# from the sigmoid function.
self.OutMin = 0.5
self.OutMax = 1.0
# this is the number of meters radius that damage still occurs when a projectile lands.
# to be used for calculating where a hit will occur.
self.SplashRadius:float = splashradius
Outputs:
def __init__(self, firenow, clockwise,cclockwise,up,down,oor, hspeed, vspeed) -> None:
self.FireNow = float(firenow)
self.RotateClockWise = float(clockwise)
self.RotateCClockWise = float(cclockwise)
self.MoveUp = float(up)
self.Down = float(down)
self.OutOfRange = float(oor)
self.vspeed = float(vspeed)
self.hspeed = float(hspeed)9 -
hello folks, any help would appreciated :). serious question about designing/developing a rest backend.
here is a little insight: I want to reduce the endpoints for many CRUD operations as I can. So for that approach I defined a set of "dynamic" routes like /:moduleName/list, /:moduleName/update and so on.
Now I want to also reduce hardcoding as much stuff as I can for the front end. like I want forms/view/components to know which fields can be sent in the "/:moduleName/xxx" endpoints from above. So I'm thinking to make some /:moduleName/list/map, /:moduleName/update/map endpoints that tells the frontend which fields/keys can be sent for X or Y operation.
regarding design/security concerns Is that a good approach? do you know any other approach that's like to what I want to achieve?6 -
I can see people who fight biological limitations and deny dogma from a mile distance. They shine from within.
If the immense work of creating a full map of pathological automatic thoughts is required to beat anxiety, I will do it just because it constitutes pure, conceptual beauty and the idea of reasoning beating primal biology. When I look in a mirror, I see myself shine.
There are no limitations to personal development other than laws of physics.1 -
Learn enough math to solve the problem Chat GPT (and two university math professors) have been unable to solve :(
The hardware is ready, the software is ready, and the only missing piece is to align a laser pointer with a Lambert's conformal conic projected map... I thought Chat GPT would be able to at least provide me with the necessary formulæ, but not...6 -
Working on writing a Morse interpreter in Java..
I find out I have to initialize a collection of a specific alphabet with unique symbols in it..
I am too lazy to come up with something right now..
And thus I start repeatedly performing the following actions:
down, left, insert apostrophe
for stuff like putting values into my Map<Character, char[]>.
Now my purposefully rhythmic typing sounds like a galloping horse. Tackatack, tackatack, tackatack! ♫
Coding adventures..
Indeed..1 -
Async Rust doesn't have a great story for Iterator::map just yet. I wrote a mini-article about it:
https://lbfalvy.com/blog/...2 -
First time using ACF pro for WordPress and client told me he wants to put markers on a single map. I then made a repeater field that requires the use to enter longitude and latitude and then loop through it to display all the markers. I'm stupid enough to not see the Google Maps field for ACF pro.
I should read more often. -
Just been casually asked to come up with ways to generate more digital revenue for the company - it’s a newspaper.
As a dev I can map out some solutions and work through most problems, but this is huge! Where do people even start with such a overwhelming challenge???!!!
One things for sure, less bloody display advertising would be my first thought, gotta’ be more innovative!
Any advice?! 1
1 -
I HATE dealing with Map objects in Java. Much like everything else in Java, the API is far too verbose. What's more annoying is how Oracle seems unbothered to improve it.5
-
Do you think, that its a good idea, to add FP-features like Map,Filter,Reduce to Stack or Queue datastructures, in the way, that they pop all elements?6
-
When your business processes just don't map to four HTTP verbs, and the world seems a little less well-ordered. That feeling.
-
For some reason I always have a hard time mentally mapping "asc/desc" to dates. I think of stairs and mentally map the dates to unicode timestamps. Am I the only one? Sort descending by date is newest first, btw6
-
I try map my Capslock key to ctrl key while using vim and I search for this on stackoverflow and I found
```Linux? With X, use xmodmap to alter the key mapping, e.g.
xmodmap -e 'clear Lock' -e 'keycode 0x42 = Escape'
Will map Esc to the CapsLock key. Google for more examples.```
following command it will map Esc key to CapsLock key but when I run this command my CapsLock key did stop working and nor my esc key map to CapsLock key. How do I get back my Capslock key default working state, I mean I don't want to map Capslock key to ctrl key?7 -
https://openrivers.net/map/
Alt history:
Great Britain is the only emerged land that ever was
Just imagine5 -
Docker newbie question
Does anyone have any insight on how to rclone mount a drive , and map a volume to it for persistent storage?5 -
I see a lot of React devs (ab)using the array.map function in cases where a forEach would be more suitable (e.g. without assigning the result, and without return statements). What are your thoughts on this?
 5
5 -
How does google map get the ever changing streets data? Be it traffic or general street map? It's accurate af! If a street is shut temporarily, it knows that and reroutes.
I understand that if there are others who are using Google maps in the area, it can aggregate and make an educated guess for every other user. But I am pretty sure it just can't rely on other users opening the app and having their gps on. Eg: live traffic data.. not everyone on the road is using maps!1 -
Why the fuck would you use a Java Optional in your Scala library. As a Scala novice I just spent about 30 minutes wondering why my map function wouldn't compile 😠
-
If the project is the landscape of the client's requirements and the code is the map into it.
Where in the f*cking abyss am I right now?? #LegacyCodes1 -
I need to make an app that can scan addresses from labels of parcels, and converts into map route. Where do I start about the recognising of address? I’m lost. Any pointers would be helpful.14
-
What are exemples of underused data types that you wish we used more often?
Using Set or Map or WeakMap instead of the normal Object+handmade dirty functions (JavaScript), for exemples?1 -
Pardon my ignorance but is what I'm trying to do even possible?
I have a WordPress network and have domain mapping setup. So the original was domainA.com/map and the new is domainB.com. Is there a way for me to keep both the old sub directory and new domain without redirects.
If not oh well.7 -
Just found it somewhere but its funny!
A programmer is walking along a beach and finds a lamp. He rubs the lamp, and a genie appears. “I am the most powerful genie in the world. I can grant you any wish, but only one wish.”
The programmer pulls out a map, points to it and says, “I’d want peace in the Middle East.”
The genie responds, “Gee, I don’t know. Those people have been fighting for millennia. I can do just about anything, but this is likely beyond my limits.”
The programmer then says, “Well, I am a programmer, and my programs have lots of users. Please make all my users satisfied with my software and let them ask for sensible changes.”
At which point the genie responds, “Um, let me see that map again.” -
Probably pythons map function either that or the pool. Map function because I'm lazy and I want my data now!!
-
I need to add offline map functionality to a PWA.
I guess it may require up to 50 MB to store a certain area. Should this be possible or will I hit any limits?5 -
Told designer just use the same map we have spent a lot of time build the scripts and cards with a simple scroller.
She proceed to fucking add a slider with autoscroller with a fucking filtering system.3 -
(define (day p)
(map(lambda(color)
(colorize p color))
(list "red" "orange" "yellow" "green" "blue" "purple")))
>(day(square 5)) -
wk177 (least successful project)
A maps behemoth created by a single dev (↑). It took "only" 2 years to get a halfway proper version out. Said dev could have saved half of the time if he (well, his employer) bought the control from a company that has all their devs working on just that (.NET controls) and thus the dev wouldn't have had to reinvent the wheel with the very basic control of the map service provider.9 -
Not sure if this is somehow standard but have a new dev process we need to use to deploy a Docker image to an Openshift container.
(Is an container one node/vm or could be many?)
In the Jenkins build it seems the files are copied to in Docker image.
But they aren't copied to the container/OPENSHIFT deployment image. There's something mentioned about config map but not sure how that's related to file copy...10 -
http://website.com?foo=bar&baz=bin039;m trying to map, for example, something like http://website.com?foo=bar&baz=bin to something like http://website.com/bar/bin. I'm pretty sure its doable but I'm having a terrible time getting it to work.3
-
https://chart.aero
Still WiP but a GPS tracker and a weather map (as in, physical map with micro-controller and LEDs) solution.9 -
We have a huge domain model in Java and something is really fucked up with our equals/hashcode implementations and know body can track it down.
I have suggested Lombok/Groovy several times but they didn't listen.
Anyways it is so fucked up, that map.contains(foo) returns false, although it is part of the map.
So we wrote something like this:
for (Entity e: map.keyset) {
if (foo.equals(e) {
return true;
}
}1 -
Just something I've been thinking on for a while:
How could programming be done if we couldn't use ordinary if-statements (but functional set operations such as map, filter, with an if- in the lambda function etc. is alright).
Could it work? Also would it be possible to reduce the amount of while loops by using functions for most of the "loop situations" as well?4 -
WTF why does Visual C++ show an error in some system include BUT NOT THE FUCKING INCLUDE CHAIN DESPITE /showincludes GIVEN???
How the fuck are you supposed to find a wrongly defined macro that way? Go through all 20 layers of includes and map out what could POSSIBLY be the include chain? Seriously WHY?? -
Great way to start a developer's day: Turn getting to the office a sudden problem with unexpected platform and services changes.
And only realizing after getting on the train. I had to pull up a mental map of the stations and connections. And guess the probability the right train was in service at the station... -
c# AutoMapper is SOSO good.. On paper...
Once you start using and thre is couple of levels of inheritance involved, it turns to shit.
Searched for fucking 5 hours a problem... Only to find "Oh yeah in this case you need to manually map properties"
Fuck you
JsonConvert.Deserialize(JsonConvert.Serialize(myShit)) it is4 -
Did 2 leetcode today (technically 1)
https://leetcode.com/problems/...
idea:
* Palindrome means cut it half, rearrange the other half, will equal each other.
* Using javascript new map() to build a hash map
* Loop the hash, add up quotient*2, add up remainder.
* if remainder > 1, then return_sum+1
https://leetcode.com/problems/...
seen a few times in interview.
* do the big one first, i.e. if(n % (3*5) === 0)
* then n%3 === 0
* then n%5 === 01 -
For learning there are a lot of sites are available. But I was not comfortable with hackerrank or geeksforgeeks etc. Finally I found a website edabit.com that was totally free. It is amazing site and it helps me a lot for understanding JS method like map, filter etc. Now I have started solving hard problems too :)1
-
readability...
if !rooms
.get(&name)
.map(|turf| if let Turf::Mine = turf { true } else { false })
.unwrap_or_default()26 -
I got to a point where I have a multi-level recursive promises within loops and my mental map is by far not enough to process this. I wish there were some visualisation tools for this - though I don't even know how it could look like. All I know is that at some point I'm returning a wrong promise and the recursion is not correctly handled.7
-
I had written a feature that stored some data for all methods in a code base. And it worked in 99.9% of all cases, but for some projects, somehow there were errors in the logs that I couldn't understand.
After hours of debugging, it turned out that I inserted the method objects into a map, and the (existing) base class for these objects used the character offsets for the method's start & end in the hashCode() implementation. This meant that in the (extremely rare) case of two methods in two files with the exact same start and end offsets, inserting them into a map would overwrite the previous value.
Once uncovered, this bug was trivial to fix ;) -
Internal: a program that takes files (or a zip/7z file with files in it) and loads them into a database/table in file created order per a json-based map file because flat file loading in SSIS is horrible.
Public: ChromeKiosk https://github.com/benjaminkwilliam... -
App for hitchhiking: map for places(with clustering) is almost ready. Other features like offline work, routes and more are on the way!1
-
I just disabled 2 recommendation notifications from Google Map and Photos...
My first thought is Google is turning into Facebook. My next read Google knows too much... But what can I do...
It's also very convenient... when it's not data mining the data it stores... -
Importing data from 1 system to another with minimal documentation. I need to map the price field in the new system from price1 in the old system... or is it price2?... or price3?, or is it cost?
Well fuck you too. -
Favorite / most used systemd timers?
I recently wrote one to pull the location data of users for an app and make a heat map of sorts which updates every hour. Probably could make it run on a quicker timer but not many eyes on it at the moment.5 -
You gotta love the actual useful stuff from XKCD.
Sometimes they apply extreme seriousness to some really unimportant stuff, like the tik-tak-toe cheat sheet.
At other opportunities, they hide some jokes completely serious looking stuff, like in 1688 the map identification chart. -
Was asked to look at another teams repo to see how they use Cassandra. In that repo, I found a function that creates a map[int]bool populated with a handful of numbers all with true as the value. The function then checks the existence of an int in that map and return a true if it exists.
-
Hello everyone. Recently i launched an iOS app for travelers "CityRank". Currently struggling to build an audience. I would appreciate any support if you can check my app, share feedback, or any other information. Many thanks!
In AppStore find CityRank 1
1 -
Hi,
I made a new video.
How to read code with Feynman technique, Pomodoro and Mind map:
https://youtube.com/watch/... -
def list = ['Stark', 'Bolton', 'Lennister', 'Tyrell']
def map = list.collectEntries ({[(list.indexOf(it)): it]})







































































































































































































































Top Tags
Weekly Rant
View