
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I worked with a good dev at one of my previous jobs, but one of his faults was that he was a bit scattered and would sometimes forget things.
The story goes that one day we had this massive bug on our web app and we had a large portion of our dev team trying to figure it out. We thought we narrowed down the issue to a very specific part of the code, but something weird happened. No matter how often we looked at the piece of code where we all knew the problem had to be, no one could see any problem with it. And there want anything close to explaining how we could be seeing the issue we were in production.
We spent hours going through this. It was driving everyone crazy. All of a sudden, my co-worker (one referenced above) gasps “oh shit.” And we’re all like, what’s up? He proceeds to tell us that he thinks he might have been testing a line of code on one of our prod servers and left it in there by accident and never committed it into the actual codebase. Just to explain this - we had a great deploy process at this company but every so often a dev would need to test something quickly on a prod machine so we’d allow it as long as they did it and removed it quickly. It was meant for being for a select few tasks that required a prod server and was just going to be a single line to test something. Bad practice, but was fine because everyone had been extremely careful with it.
Until this guy came along. After he said he thought he might have left a line change in the code on a prod server, we had to manually go in to 12 web servers and check. Eventually, we found the one that had the change and finally, the issue at hand made sense. We never thought for a second that the committed code in the git repo that we were looking at would be inaccurate.
Needless to say, he was never allowed to touch code on a prod server ever again.8 -
Oh, man, I just realized I haven't ranted one of my best stories on here!
So, here goes!
A few years back the company I work for was contacted by an older client regarding a new project.
The guy was now pitching to build the website for the Parliament of another country (not gonna name it, NDAs and stuff), and was planning on outsourcing the development, as he had no team and he was only aiming on taking care of the client service/project management side of the project.
Out of principle (and also to preserve our mental integrity), we have purposely avoided working with government bodies of any kind, in any country, but he was a friend of our CEO and pleaded until we singed on board.
Now, the project itself was way bigger than we expected, as the wanted more of an internal CRM, centralized document archive, event management, internal planning, multiple interfaced, role based access restricted monster of an administration interface, complete with regular user website, also packed with all kind of features, dashboards and so on.
Long story short, a lot bigger than what we were expecting based on the initial brief.
The development period was hell. New features were coming in on a weekly basis. Already implemented functionality was constantly being changed or redefined. No requests we ever made about clarifications and/or materials or information were ever answered on time.
They also somehow bullied the guy that brought us the project into also including the data migration from the old website into the new one we were building and we somehow ended up having to extract meaningful, formatted, sanitized content parsing static HTML files and connecting them to download-able files (almost every page in the old website had files available to download) we needed to also include in a sane way.
Now, don't think the files were simple URL paths we can trace to a folder/file path, oh no!!! The links were some form of hash combination that had to be exploded and tested against some king of database relationship tables that only had hashed indexes relating to other tables, that also only had hashed indexes relating to some other tables that kept a database of the website pages HTML file naming. So what we had to do is identify the files based on a combination of hashed indexes and re-hashed HTML file names that in the end would give us a filename for a real file that we had to then search for inside a list of over 20 folders not related to one another.
So we did this. Created a script that processed the hell out of over 10000 HTML files, database entries and files and re-indexed and re-named all this shit into a meaningful database of sane data and well organized files.
So, with this we were nearing the finish line for the project, which by now exceeded the estimated time by over to times.
We test everything, retest it all again for good measure, pack everything up for deployment, simulate on a staging environment, give the final client access to the staging version, get them to accept that all requirements are met, finish writing the documentation for the codebase, write detailed deployment procedure, include some automation and testing tools also for good measure, recommend production setup, hardware specs, software versions, server side optimization like caching, load balancing and all that we could think would ever be useful, all with more documentation and instructions.
As the project was built on PHP/MySQL (as requested), we recommended a Linux environment for production. Oh, I forgot to tell you that over the development period they kept asking us to also include steps for Windows procedures along with our regular documentation. Was a bit strange, but we added it in there just so we can finish and close the damn project.
So, we send them all the above and go get drunk as fuck in celebration of getting rid of them once and for all...
Next day: hung over, I get to the office, open my laptop and see on new email. I only had the one new mail, so I open it to see what it's about.
Lo and behold! The fuckers over in the other country that called themselves "IT guys", and were the ones making all the changes and additions to our requirements, were not capable enough to follow step by step instructions in order to deploy the project on their servers!!!
[Continues in the comments]25 -
A more experienced friend told me
"don't be a pussy, test in production"
I'm the one fixing the bugs, not him 8
8 -
User: *Clicks on staging environment*
Giant Warning Dialog: YOU ARE CURRENTLY ENTERING THE STAGING ENVIRONMENT
Users: Ok
App: *Completely different colour, I’m talking bright unsightly yellow*
User: Ok
Giant Yellow and Red Flashing Banner at the Top of the Screen: WARNING YOU ARE CURRENTLY USING STAGING, THIS AREA IS FOR TESTING ONLY
User: The production environment sure is acting strange today. It’s a weird colour and I don’t recognize any of the data, it’s all just dummy filler data. I better create a ticket for the dev team to check o—….. no wait I’ll send an email CC everyone including the CEO and sound the alarm production is currently down and filled with giant warning messages.
Manager: OH MY GOD PRODUCTION IS DOWN DID YOU HEAR ABOUT THIS??? WHAT THE FUCK COULD THESE WARNING MESSAGES BE THAT’S ONLY SUPPOSED TO HAPPEN ON STAGING! THE CEO IS BREATHING DOWN MY NECK YOU NEED TO GET THIS FIXED IMMEDIATELY!!!!!!!
Dev: …11 -
I just sent an automated email titled "Gary is a Dinosaur!" to a lot of humourless clients because the ancient application I was testing assumed I was in the production environment. 🙃
Lesson to self: stop using bogus names in testing.
Still, it could've been a lot worse... 😂9 -
Doot doot.
My day: Eight lines of refactoring around a 10-character fix for a minor production issue. Some tests. Lots of bloody phone calls and conference calls filled with me laughing and getting talked over. Why? Read on.
My boss's day: Trying very very hard to pin random shit on me (and failing because I'm awesome and fuck him). Six hours of drama and freaking out and chewing and yelling that the whole system is broken because of that minor issue. No reading, lots of misunderstanding, lots of panic. Three-way called me specifically to bitch out another coworker in front of me. (Coworker wasn't really in the wrong.) Called a contractor to his house for testing. Finally learned that everything works perfectly in QA (duh, I fixed it hours ago). Desperately waited for me to push to prod. Didn't care enough to do production tests afterwards.
My day afterwards: hey, this Cloudinary transform feature sounds fun! Oh look, I'm done already. Boo. Ask boss for update. Tests still aren't finished. Okay, whatever. Time for bed.
what a joke.
Oh, I talked to the accountant after all of this bullshit happened. Apparently everyone that has quit in the last six years has done so specifically because of the boss. Every. single. person.
I told him it was going to happen again.
I also told him the boss is a druggie with a taste for psychedelics. (It came up in conversation. Absolutely true, too.) It's hilarious because the company lawyer is the accountant's brother.
So stupid.18 -
Hey, Root? How do you test your slow query ticket, again? I didn't bother reading the giant green "Testing notes:" box on the ticket. Yeah, could you explain it while I don't bother to listen and talk over you? Thanks.
And later:
Hey Root. I'm the DBA. Could you explain exactly what you're doing in this ticket, because i can't understand it. What are these new columns? Where is the new query? What are you doing? And why? Oh, the ticket? Yeah, I didn't bother to read it. There was too much text filled with things like implementation details, query optimization findings, overall benchmarking results, the purpose of the new columns, and i just couldn't care enough to read any of that. Yeah, I also don't know how to find the query it's running now. Yep, have complete access to the console and DB and query log. Still can't figure it out.
And later:
Hey Root. We pulled your urgent fix ticket from the release. You know, the one that SysOps and Data and even execs have been demanding? The one you finished three months ago? Yep, the problem is still taking down production every week or so, but we just can't verify that your fix is good enough. Even though the changes are pretty minimal, you've said it's 8x faster, and provided benchmark findings, we just ... don't know how to get the query it's running out of the code. or how check the query logs to find it. So. we just don't know if it's good enough.
Also, we goofed up when deploying and the testing database is gone, so now we can't test it since there are no records. Nevermind that you provided snippets to remedy exactly scenario in the ticket description you wrote three months ago.
And later:
Hey Root: Why did you take so long on this ticket? It has sat for so long now that someone else filed a ticket for it, with investigation findings. You know it's bringing down production, and it's kind of urgent. Maybe you should have prioritized it more, or written up better notes. You really need to communicate better. This is why we can't trust you to get things out.
*twitchy smile*19 -
!rant
!!git
Who here uses `master` for development?
My boss (api guy) tried to convince me that was normal practice. I gently told him that it sounded crazy and very very bad.
Here's the dev path I'm enforcing on my repos:
(feature branches) -> dev -> qa* -> master -> production*
*: the build server auto-pulls from these branches, and pushes any passing builds to staging/production.
Everyone works on their own feature branches, and when they're happy with their work, they merge it into `dev`. `dev`, therefore, is for feature integration testing. After everything is working well on `dev`, it gets merged into `qa` for the testers to fawn over and beat with sticks. Anything that passes QA gets merged into `master`, where it sits until we're ready to release it. When that time comes (it's usually right away, but not always), `master` gets merged into `production`.
This way, `master` is always stable and contains the newest code, so it's perfect for forking/etc. Is this standard practice, or should I be doing something different?
Also, api guy encourages something he calls "running a racetrack" -- each dev has their own branch (their initials) and they push to that throughout the day. everyone else pulls from it regularly and pushes to their own branch. When anyone's happy with their code, they push from their (updated) branch to `qa` (I insisted on `dev` instead.)
Supposedly this drastically reduces the number of merge conflicts when pushing to an upstream branch due to having a more recent ancestor node?
I don't quite follow that, but it seems to me that merging/pushing throughout the day would just make them happen sooner? idk.
What are your thoughts?30 -
Why are job postings so bad?
Like, really. Why?
Here's four I found today, plus an interview with a trainwreck from last week.
(And these aren't even the worst I've found lately!)
------
Ridiculous job posting #1:
* 5 years React and React Native experience -- the initial release of React Native was in May 2013, apparently. ~5.7 years ago.
* Masters degree in computer science.
* Write clean, maintainable code with tests.
* Be social and outgoing.
So: you must have either worked at Facebook or adopted and committed to both React and React Native basically immediately after release. You must also be in academia (with a masters!), and write clean and maintainable code, which... basically doesn't happen in academia. And on top of (and really: despite) all of this, you must also be a social butterfly! Good luck ~
------
Ridiculous job posting #2:
* "We use Ruby on Rails"
* A few sentences later... "we love functional programming and write only functional code!"
Cue Inigo Montoya.
------
Ridiculous job posting #3:
* 100% remote! Work from anywhere, any time zone!
* and following that: You must have at least 4 work hours overlap with your coworkers per day.
* two company-wide meetups per quarter! In fancy places like Peru and Tibet! ... TWO PER QUARTER!?
Let me paraphrase: "We like the entire team being remote, together."
------
Ridiculous job posting #4:
* Actual title: "Developer (noun): Superhero poised to change the world (apply within)"
* Actual excerpt: "We know that headhunters are already beating down your door. All we want is the opportunity to earn our right to keep you every single day."
* Actual excerpt: "But alas. A dark and evil power is upon us. And this… ...is where you enter the story. You will be the Superman who is called upon to hammer the villains back into the abyss from whence they came."
I already applied to this company some time before (...surprisingly...) and found that the founder/boss is both an ex cowboy dev and... more than a bit of a loon. If that last part isn't obvious already? Sheesh. He should go write bad fantasy metal lyrics instead.
------
Ridiculous interview:
* Service offered for free to customers
* PHP fanboy angrily asking only PHP questions despite the stack (Node+Vue) not even freaking including PHP! To be fair, he didn't know anything but PHP... so why (and how) is he working there?
* Actual admission: No testing suite, CI, or QA in place
* Actual admission: Testing sometimes happens in production due to tight deadlines
* Actual admission: Company serves ads and sells personally-identifiable customer information (with affiliate royalties!) to cover expenses
* Actual admission: Not looking for other monetization strategies; simply trying to scale their current break-even approach.
------
I find more of these every time I look. It's insane.
Why can't people be sane and at least semi-intelligent?18 -
Worst bad practice..
Manager: I need code today
Developer (thinking) : let me give it without unit test. Anyways tester will test it.
Manager to tester: complete testing fast.
Tester(thinking): developer must have unit tested it. Let me skip it.
Enjoy testing completed.
God help clients.. 😊5 -
My first testing job in the industry. Quite the rollercoaster.
I had found this neat little online service with a community. I signed up an account and participated. I sent in a lot of bug reports. One of the community supervisors sent me a message that most things in FogBugz had my username all over it.
After a year, I got cocky and decided to try SQL injection. In a production environment. What can I say. I was young, not bright, and overly curious. Never malicious, never damaged data or exposed sensitive data or bork services.
I reported it.
Not long after, I got phone calls. I was pretty sure I was getting charged with something.
I was offered a job.
Three months into the job, they asked if I wanted to do Python and work with the automators. I said I don't know what that is but sure.
They hired me a private instructor for a week to learn the basics, then flew me to the other side of the world for two weeks to work directly with the automation team to learn how they do it.
It was a pretty exciting era in my life and my dream job.4 -
Every so often I remember that the code I wrote is running in production and real customers are using it and I feel a little bit sick2
-
Sex talk between programmers.
She: I'm a virgin.
He: Don't worry. They call me the virginslayer007.
She: Oh! So how many virgins have you slayed till now?
He: That would be ONE in a few minutes.
She: So u r also a virgin then..
He: Don't worry. I watched so many video tutorials. We just have to do exactly as they did. Best thing is that it can be done both for testing and production purposes.
She: Let's stick to testing purposes for now.6 -
Client: "I did not receive the email that should be send after that event. Please fix."
Me:
* Checks code - ok
* Tests feature in locally - ok
* Tests feature in production - ok
* checks values in database - ok
* 2 hours wasted - ok
"Please help me dear CTO, idk what else I could check or how I should even respond to this."
CTO: "hmm, the clients account uses a adminstrative email address for testing. Let me just check if it is in the mailbox."
*checks* "Yeah, that's the email you're looking for, right?"
Me: *experiences relief, anger, blood lust and disappointment at the same time* "Could you please respond to the client for me, I need a break. Thanks"3 -
In my current work, I have two systems to work on (let's name em Systems A and B). Both basically do the same thing; both allow users to book facilities available to them.
System A is already in production. My job is to fix any bugs that come up on said system. System B is an improved version that they wanted me to develop. This would follow a different framework etc. I am already halfway through this system.
Now, here's the fucked up part. The code for system A is a massive clusterfuck. It has unused commented code dated back to ancient times where men had the brain of an ape.
And don't get me started on the fucking logic. One part of the code was to retrieve and display the timeslots available for a chosen facility. The code to do that alone takes up 500++ fucking lines, filled with ajax commands, html manipulation and commented, unused codes..AND THAT'S JUST THE FRONTEND!
The fucking backend was not a problem of smelly code anymore. Nope. It was like a programmer had code diarrhea and shat his backend code all over the project. If I had a pin board, I would have made a crazy wall just to understand what some fucknut was trying to achieve.
Anyway, my supervisor told me to fix some bugs on System A. Knowing how the code was, I told her that I could refactor the code. Since I've already achieved that function on System B, with a shorter and cleaner code, I could just copy that and use on System A. But nope. She SPECIFICALLY told me to just "do whatever to fix the bugs. I don't want to waste time on System A." Okay. Makes sense to me. Whatever. I didn't wanna fuck my head up looking through that mess of a cesspool. So, I came up with a few hacks, not thinking of clean code and fixed whatever bugs there was. I then just pushed to the repo (after testing of course).
This bloody morning, supervisor came in and gave me more bugs to fix. When I thought she was done, she said "Hey. I saw the fix you made to the system. The bugs are fixed but the retrieval of the timeslots is now pretty slow. Could you see what is the problem?"
Slow.. She said that it was slow. And asked if I could fix it. I already told her what the problem was and she did not want me to waste time on it. But she wants me to fix it. WHAT THE FUCK IS WRONG IN HER BLOODY HEAD! I SWEAR TO GOD... UGHHHHH I swear I was already waterboarding her in my head. YOU WANT FAST?? How bout fucking allowing me to refactor the code?? Fucking shit head. I think I should take up yoga.1 -
Some years back I was working in a project that essentially dealt with all things related to foreigners and foreign affairs in Switzerland. You could manage entry visas, work permits, citizenship, international warrants, Interpol requests, etc.
One of the test managers (from client side - i.e. the government) was once manually "testing" and mixed up the production and test instance, to both of which he was logged in at the time.
The test case then ended up setting up an entry ban against himself, as he used his own name for testing...
Next time he returned from vacation the border control at the airport were like "Uhm, Sir, we can't let you into the country. Please come with us." :D :D
(He managed to clear that up in end, I dare say, though, that he learned his lesson.)4 -
FUCKING TELEGRAM FUCK YOU STAY IN YOUR FUCKING API DOCUMENTATION AND STOP FUCKING TESTING YOUR SHIT ON A PRODUCTION SYSTEM WHY WOULD YOU DO THAT FUCK OFF WHY AM I EVEN DEVELOPING SHIT FOR YOUR PLATFORM ANYMORE WHEN FOLLOWING YOUR DOCUMENTATION LEADS TO FUCKING ERRORS AND WE HAVE TO DECOMPILE AND REVERSE ENGINEER YOUR FUCKING "OPEN SOURCE" APPS BECAUSE YOU DONT EVEN BOTHER TO FUCKING UPDATE THE SOURCE CODE ONCE A YEAR WHAT THE FUCK
Thank you for your attention7 -
So I took on a fairly big project and poured my heart and soul into it, was the biggest thing I did yet. I kept on sending beta's to the customer after each change for review! Kept on insisting that they review it, the answer was always "this looks amazing keep doing what you're doing"! After I finished and pushed everything to production.
They didn't use it for nearly 6 months! And then out of the blue they call me saying that half of the app is wrong.. WTF? Where was this information during testing! I informed them that the changes would take some time since I need to do migrations and change the whole database schema.
In which they replied "but you already finished it once won't changing things make it easier? We shouldn't pay for your mistakes"
I don't know how I handled that but they should be thankful they were half way across the country 😠😠😠😠3 -
A few days after deploying a big important Website into production, I wanted to copy the whole thing including DB back onto our test server for future testing/bug fixing if something comes up. (Last changes were done on production server before going live)
So I opened SSH, removed everything on the test sever aaaaand then I realized I was connected to production...
Took about an hour to get everything up and running again. We didn't tell the client and hoped it would not be noticed.2 -
So today was the worst day of my whole (just started) career.
We have a huge client like 700k users. Two weeks ago we migrated all their services to our aws infrastructure. I basically did most of the work because I'm the most skilled in it (not sure anymore).
Today I discovered:
- Mail cron was configured the wrong way so 3000 emails where waiting to be sent.
- The elastic search service wasn't yet whitelisted so didn't work for two weeks.
- The cron which syncs data between production db en testing db only partly worked.
Just fucking end me. Makes me wonder what other things are broken. I still have a lot to learn... And I might have fucked their trust in me for a bit.13 -
Rather than singling out one person, I wanna present what I see as incompetent/stupid/ignorant:
- no will to learn
- failure to follow the very specific instructions & later asking for help when they FUBR sth & not even knowing what they did to fuck up in the first place
- asking how to solve stuff, then ignoring the suggestions & doing sth totally against recommendations
- failure to remember most basic stuff, especially if not writing it down to look at later when needed
- failure to check logs & 'google' stuff before asking why something isn't working the way they want it
- after two weeks, asking me how feature xy works, mind you they coded it, not me
- asking me why they did something in a specific way - WTF, am I a mind reader?! Who designed that crap?! Me or you?!!
- being passive/aggressive & snarky when told to do something or being asked why isn't it done already
- not testing their shit properly
- not making backups when upgrading (production) servers
- not checking the input value, no validation.. even after many many debacles on production with null ref exceptions
- failure to admit they fucked up
- not learning from (their) mistakes8 -
Once I purposely made a very obvious mistake to see if QA was actually testing due to how many bugs were getting through to production.4
-
PM says you are spending too much time testing. Fast forward to a production bug and they are standing behind you while you are frantically coding saying "this should have been tested more".7
-
[3:18 AM] Me: Heya team, I fixed X, tested it and pushed to production. Lemme know what you think when you wake up.
[6:30 AM] Me: Yo, I just checked X and everything is peachy. Let me know if it works on your end.
[9:14] Colleague A: Whoop! Yeah! Awesome!
[9:15] Boss: Nice.
[9:30] A: X doesn't work for me.
Me: OK, did you do M as I told you.
A: yes
Me: *checks logs and database, finds no trace of M*
Me: A, you sure you did M on production? Send me a sreenshot plz.
A: yeah, I'm sure it's on production.
Me: *opens sreenshot, gets slapped in the face by https://staging.app.xyz*
Me: A, that's staging, you need to test it on production.
A: right, OK.
[10:46] A: works, yeah! Awesome, whoop!
[10:47] Boss: Nice.
Me: Ok! A, thanks for testing...
Me: *... and wasting my time*.
[10:47:23] Boss: Yo, did you fix Y?
Courageous/snarky me: *Hey boss, see, I knew you'd ask this right after I fixed X knowing that I could not have done anything else while troubleshooting A's testing snafu since you said 'Nice' twice. So, yesterday, I cloned myself and put me to work in parallel on Y on order fulfill your unreasonable expectations come morning.*
Real me: No, that's planned for tomorrow. -
1. Slack. Pretty good chat app for dev companies, I use it to prevent people standing next to my desk 40 times a day.
2. Unit testing tools, especially when fully automated using a git master branch hook, something like codeship/jenkins, and a deployment service.
3. Jetbrains IDEs. I love Vim, but Jetbrains makes theming, autocompleting & code style checks with mixed templating languages a breeze.
4. Urxvt terminal. It's a bit of work at the start, but so extremely fast and customizable.
5. Cinnamon or i3. Not really dev tools, but both make it easy to organize many windows.
6. A smart production bug logger. I tend to use Bugsnag, Rollbar or Sentry.
7. A good coffee machine. Preferably some high pressure espresso maker which costs more than the CEO's car, using organic fairtrade hipster beans with a picture of a laughing south american farmer. And don't you dare fuck it up with sugar.
8. Some high quality bars of chocolate. Not to consume yourself, but to offer to coworkers while they wait for you to fix a broken deploy. The importance of office politics is not to be underestimated.1 -
"Everybody has a testing environment. Some people are lucky enough to have a totally seperate environment to run production in."
-Unknown1 -
If you see someone ranting about a colleague who made a semi-major fuckup which was not recognised during dev and stage testing and made it to production where it was discovered three days after deployment just when he went on holiday, well, that colleague was me.3
-
Old boss story. This guy was nice but a terrible boss. Also relevant, he has a background in IT so should know better.
Him: So when you wanna check a password is correct you just unhash it in the database?
Me: *facepalm*
Me: Hey we should be doing unit and integration testing at a minimum to lower bugs.
Him: We don't need those, we're not a bank. If a problem comes up we just fix it and push to production.
(A while later)
Him(in email): Why do we keep getting bugs reported. Don't you devs test your code.
I was mildly annoyed at that one.
Him: We're always over budget on projects, how can we fix this.
Me: What if we increase our quotes.(technically there are other ways as well but not really possible at that time)
Him: We can't do that, clients won't want to pay.
Me: *finishing off my handover as I'm leaving for a new job*
Him: Wow you do a lot of work2 -
We have 2 layers of testing environments and production.
I tested the changes on the 1st layer, bud since it was 5min to lunch i did not test on 2nd layer which is connected to the production DB. I pushed to production and caused 5+ websites to go full retard and went to lunch.
Came back to 19emails and 3+ skype msgs about "why the fck would you do that..."
Estimated damages nearly 20k EUR and i lost some permissions for two weeks, but my great boss helped me out and cheered me up by telling stories how he took down multiple servers too
plot twist: im the team leader of our office now :)5 -
STOP. TESTING. IN. PRODUCTION.
STOP. TESTING. IN. PRODUCTION.
STOP. TESTING. IN. PRODUCTION.
STOP. TESTING. IN. PRODUCTION.17 -
Wordpress does not suck. If you know how to work it.
Past period I saw so many rants on WP. My rant is that it is not 100% WP fault. Yes there are seriously structural problems in WP but that does not mean you cannot create top-notch websites.
At my work we create those top-notch WP sites. Blazing fast and manageable. Seriously we got a customer request to make the site slower because it loaded pages to fast (ea; you hardly could see you switched pages).
- We ONLY use a strict set of plugins that we think are stable, useful.
- We have everything in composer (and our own Satis) for plugins.
- We use custom themes & classes. Our code is MVC with Twig.
- In our track history we have 0 hacked websites for the past 2 years.
- Everything runs stable 24/7
- We have OTAP (testing, acceptance & production environments)
- We patch really fast
These are sites going from $15k++ and we know our shit.
Don't hate on WP if you have no clue what you are doing yourself.
That is my rant.23 -
So, a few years ago I was working at a small state government department. After we has suffered a major development infrastructure outage (another story), I was so outspoken about what a shitty job the infrastructure vendor was doing, the IT Director put me in charge of managing the environment and the vendor, even though I was actually a software architect.
Anyway, a year later, we get a new project manager, and she decides that she needs to bring in a new team of contract developers because she doesn't trust us incumbents.
They develop a new application, but won't use our test team, insisting that their "BA" can do the testing themselves.
Finally it goes into production.
And crashes on Day 1. And keeps crashing.
Its the infrastructure goes out the cry from her office, do something about it!
I check the logs, can find nothing wrong, just this application keeps crashing.
I and another dev ask for the source code so that we can see if we can help find their bug, but we are told in no uncertain terms that there is no bug, they don't need any help, and we must focus on fixing the hardware issue.
After a couple of days of this, she called a meeting, all the PMs, the whole of the other project team, and me and my mate. And she starts laying into us about how we are letting them all down.
We insist that they have a bug, they insist that they can't have a bug because "it's been tested".
This ends up in a shouting match when my mate lost his cool with her.
So, we went back to our desks, got the exe and the pdb files (yes, they had published debug info to production), and reverse engineered it back to C# source, and then started looking through it.
Around midnight, we spotted the bug.
We took it to them the next morning, and it was like "Oh". When we asked how they could have tested it, they said, ah, well, we didn't actually test that function as we didn't think it would be used much....
What happened after that?
Not a happy ending. Six months later the IT Director retires and she gets shoed in as the new IT Director and then starts a bullying campaign against the two of us until we quit.5 -
I just blocked some of the top management from connecting to our WLAN because I was testing a verifing feature for said WiFi that kicks all devices not listed in the DB.
It happened while my boss/senior/guidance was trying to show them the advantages of a centrally managed infrastructure.
He covered my ass well and tried to sell it to them as proof of a secure solution, that unknown devices couldn't log in.
I feel like human trash right now, but that's what you get for testing in production.4 -
Me: Hey boss, if you ever need someone to get into doing DevOps related tasks for the team, I'd be more than happy to take that on.
Boss: We don't really need any dedicated person to work on that, but if we do in the future, I'll let you know.
Fast forward a few days: I am now unable to deploy bug fixes to our testing environment, now in the cloud, because all access has been blocked for everyone except the two numbskulls who thought it'd be a great idea to move EVERYTHING over (apps, configuration manager, proxies, etc) first.
Oh, and this bug is affecting production. 3
3 -
My worst devSin was testing in production once because I was too lazy to set up the dev environment locally.
Never will I do that mistake again!4 -
- Be me (Dev)
- Develop website for client that has an online payment integration.
- Notice there is no one for QA and testing.
- Try to raise voice about it but get shot down by management.
- Get order to push the project to production (because the deadline has arrived, therefore the project must be ready)
- Production performance has an error margin of 15% (customers getting their card over/under charged)
- Get blamed and flamed for everything cuz well, its all the dev's fault.
FML4 -
Well the clown strikes again,
How do u break production and a testing environment in one night?
One full month preping for same thing that revolves around one config file and assured us he was confident,
He wasn't
he managed to fuck it up so bad for the team d brass lost d plot,
I'm not one for condemning people but my God Dante's inferno woulda had an extra ring if he worked with this buck,
The stupidity has shattered my belief in sunshine and rainbows -
Last night my boss played with our access points in the warehouse for a client, he messed something up and they stopped working.
I asked a person from our service to fix them
Service: he fucked something up again?
Me: yup
S: can you fix them?
M: yup
S: then why ask me?
M: it's not my job 😂
He swapped them, and got mad. -
"Who needs a staging server, test suites and continuous integration anyways haha"
-company i just joined6 -
Just got this notification. I see virgin active UK likes to test in production. I too like to live dangerously.
 1
1 -
Continue of https://devrant.com/rants/2165509/...
So, its been a week since that incident and things were uneventful.
Yesterday, the "Boss" came looking for me...I was working on some legacy code they have.
He asked, "what are you doing ?"
Me, "I am working on the extraction part for module x"
He, "Show me your code!"
Me(😓), shows him.
Then he begins..."Have you even seen production grade code ? What is this naming sense ? (I was using upper and lower camel case for methods and variables)
I said, "sir, this is a naming convention used everywhere"
He, " Why are there so many useless lines in here?"
Me, "Sir, I have been testing with different lines and commenting them out, and mostly they are documentation"
He, "We have separate docs for all, no need to waste your time writing useless things into the code"
Me, 😨, "but how can anyone use my code if I don't comment or document it ?"
He, "We don;t work like that...(basically screaming)..."If you work here you follow the rules. I don't want to hear any excuses, work like you are asked to"
Me, 😡🤯, Okay...nice.
Got up and left.
Mailed him my resignation letter, CCed it to upper management, and right now preparing for an interview on next monday.
When a tech-lead says you should not comment your codes and do not document, you know where your team and the organisation is heading.
Sometimes I wonder how this person made himself a tech-lead and how did this company survived for 7 years!!
I don't know what his problem was with me, I met him for the first time in that office only(not sure if he saw the previous post, I don't care anymore).
Well, whatever, right now I am happy that I left that firm. I wish he get what he deserves.12 -
Friend of mine: so I wonder how do you test your applications in the startup?
Me: testing? *grabs his coffee laughing*
Actually we have a complete build pipeline from commit/pull-request to dev and production environments. No tests. Really. We are in rapid product development / research state.
We change technologies and approaches like our underwear (and yeah, this is frequently). If we settled some day and understood the basic problems of the whole feature palette, we'll talk about tests again.3 -
Freelance project I was working on was deployed. Without my knowledge. At 11pm. Their in-house "tech guy" thought that the preview build i gave them was good enough for deployment. Massive bug, broke their api endpoints.
Got a call at 2 in the morning,asking for a fix. I told them how it was their fault and the App they deployed had TESTING written right on the main screen.
They promised additional payment to get me to fix it asap.
Went through the commit history (thank goodness their tech guy knew git, fuck him for committing on production though) and the crash reports.
Removed three lines. All became right with the world again. 😎2 -
Somebody at Samsung is testing something in production 🤭
It's "Find my mobile" which is preinstalled by default on Samsung devices 8
8 -
When you test your backend code thoroughly before pushing to production, but a fatal exception with the much larger production userbase causes one of your vital threads to die with a NullPointerException.
 6
6 -
After months of development, testing, testing and even more testing the app was ready for deployment to production. Happy days, the end was in sight!
I had a week's leave so I handed over the preparation for deployment to my Senior Developer and left it in his capable hands while I enjoyed the sun and many beers.
I came back on the day of deployment and proudly pressed the deploy button. Hurrah!
Not long after I got loads of phone calls from around the country as the app wasn't working. What madness is this?! We tested this for months!
Turns out my Senior didn't like the way I'd written the SQL queries so he changed them. Which is obviously both annoying and unprofessional, but even worse he got a join wrong so the memory usage was a billion times more and it drained the network bandwidth for the whole site when I tried to debug it.
I got all the grief for the app not working and for causing many other incidents by running queries that killed the network.
So...much... rage!!!3 -
When you accidentally publish the testing version of your app to the production channel instead of the beta channel... 😣
 3
3 -
Worst collaboration experience story?
I was not directly involved, it was a Delphi -> C# conversion of our customer returns application.
The dev manager was out to prove waterfall was the only development methodology that could make convert the monolith app to a lean, multi-tier, enterprise-worthy application.
Starting out with a team of 7 (3 devs, 2 dbas, team mgr, and the dev department mgr), they spent around 3 months designing, meetings, and more meetings. Armed with 50+ page specification Word document (not counting the countless Visio workflow diagrams and Microsoft Project timeline/ghantt charts), the team was ready to start coding.
The database design, workflow, and UI design (using Visio), was well done/thought out, but problems started on day one.
- Team mgr and Dev mgr split up the 3 devs, 1 dev wrote the database access library tier, 1 wrote the service tier, the other dev wrote the UI (I'll add this was the dev's first experience with WPF).
- Per the specification, all the layers wouldn't be integrated until all of them met the standards (unit tested, free from errors from VS's code analyzer, etc)
- By the time the devs where ready to code, the DBAs were already tasked with other projects, so the Returns app was prioritized to "when we get around to it"
Fast forward 6 months later, all the devs were 'done' coding, having very little/no communication with one another, then the integration. The service and database layers assumed different design patterns and different database relationships and the UI layer required functionality neither layers anticipated (ex. multi-users and the service maintaining some sort of state between them).
Those issues took about a month to work out, then the app began beta testing with real end users. App didn't make it 10 minutes before users gave up. Numerous UI logic errors, runtime errors, and overall app stability. Because the UI was so bad, the dev mgr brought in one of the web developers (she was pretty good at UI design). You might guess how useful someone is being dropped in on complex project , months after-the-fact and being told "Fix it!".
Couple of months of UI re-design and many other changes, the app was ready for beta testing.
In the mean time, the company hired a new customer service manager. When he saw the application, he rejected the app because he re-designed the entire returns process to be more efficient. The application UI was written to the exact step-by-step old returns process with little/no deviation.
With a tremendous amount of push-back (TL;DR), the dev mgr promised to change the app, but only after it was deployed into production (using "we can fix it later" excuse).
Still plagued with numerous bugs, the app was finally deployed. In attempts to save face, there was a company-wide party to celebrate the 'death' of the "old Delphi returns app" and the birth of the new. Cake, drinks, certificates of achievements for the devs, etc.
By the end of the project, the devs hated each other. Finger pointing, petty squabbles, out-right "FU!"s across the cube walls, etc. All the team members were re-assigned to other teams to separate them, leaving a single new hire to fix all the issues.5 -
If you're going to request CRITICAL changes to thousands of records in the database, and approve it through testing which is done on an exact replica of production, then tell me it was done incorrectly after the fact it has been implemented and you didn't actually review the changes made to the data or business logic that you requested then you are an idiot. Our staging environment is there to ensure all the changes are accurate you useless human. Its the data you provided, I didn't just magically pull it from thin air to make yours and my job a pain the ass.6
-
!rant
One of our clients discovered a bug on our site about an hour ago. I wrote up a fix, and after very little testing, pushed it into production. I then immediately left to go home.
You can say I like to live my life dangerously.3 -
I work for a bank and every production release date it's a chaos... Like, for real, devs running to get their stories approved by the testing team and last minute scope changes that, if not made, would make the whole app fail (real shitty management as you can see).
Longstoryshort, a dev didn't finished one of his stories and create 7 major bugs with another... Today that was my breakfast, took me 4 hours and get it all done and approved... We didn't make the release tho, but I scored some major points with this.
Funny thing, tomorrow I'm telling my PM I'll leave the company for a better job, so that will be their breakfast.5 -
In one of my first jobs i developed an (ugly and heavly under-payed) e-commerce/media platform for a customer.
That customer was constantly making fun of his bald partner telling how he was gay, liked dicks, etc., drawing dicks and bananas as sample website logos or uploading dildo/penis images as images, he was always like this.
Once the website was ready for production i removed all the "testing" posts and images and told the client to insert some real content and alert me when it was ready for release.
Well some time after the release i got a call from that client, for the first time he was serious:
C: Hi, why there are dildo images on the server? (the website in production was full of dildo/penis images instead of actual product images, he even photoshopped the head of his partner on a penis and uploaded it!!!)
R: ehm... i told you it was on production and to stop uploading bad content....
C: Ummm ok, please fix it immediatly, thanks!3 -
Got pulled out of bed at 6 am again this morning, our VMs were acting up again. Not booting, running extremely slow, high disk usage, etc.
This was the 6 time in as many weeks this happened. And always the marching orders were the same. Find the bug, smash the bug, get it working with the least effort. I've dumped hundreds of hours maintaining this broken shitheap of a system, putting off other duties to keep mission critical stations running.
The culprits? Scummy consultants, Windows 10 1709, and Citrix Studio.
Xen Server performed well enough, likely due to its open source origins and Centos architecture.
Whelp. DasSeahawks was good and pissed. Nothing like getting rousted out of bed after a few scant hours rest for patching the same broken system.
DasSeahawks lost his temper. Things went flying. Exorcists were dispatched and promptly eaten.
Enough. No consultants, no analysts, and no experts touched it. No phone calls, no manuals, not even a google search. Just a very pissed admin and his minion declaring blitzkrieg.
We made our game plan, moved the users out, smoked our cigs, chugged monster, and queued a gnu-metal playlist on spotify.
Then we took a wrecking ball to the whole setup. User docs were saved, all else was rm -r * && shred && summon -u Poseidon -beast Land_Cracken.
Started at 3pm and finished just after midnight. Rebuilt all the vms with RDP, murdered citrix studio (and their bullshit licenses), completely blocked Windows 10 updates after 1607, and load balanced the network.
So what do we get when all the experts are fired? Stabbed lightning. VMs boot in less than 10 seconds, apps open instantly, and server resources are half their previous usage state. My VMs are now the fastest stations in our complex, as they should be.
Next to do: install our mxgpu, script up snapshots and heartbeat, destroy Windows ads/telemetry, and setup PDQ. damn its good to be good!
What i learned --> never allow testing to go to production, consultants will fuck up your shit for a buck, and vendors are half as reliable over consultants. Windows works great without Microsoft, thin clients are overpriced, and getting pissed gets things done.
This my friends, is why admins are assholes.4 -
How to NOT write unit tests:
A colleague of mine has developed a new package of software, many of our new projects are going to use. So in his presentation of the new functionalities he also showed us that he used unit tests to cover some of his code. So i asked him to show me that all tests passes.
He: I can show you, but one test suit will fail currently.
Me: Why?? You told us, everything is finished and works fine.
He: That's right, but they will fail because I'm currently not in the customer VPN.
Me: Excuse me, WHAT??
He: Yes, I'm not in the VPN that connects me to this one customers facility in Hungary, where the counterpart of the software is runnung live.
Me: YOU WROTE UNIT TESTS THAT TEST AGAINST A RUNNING LIVE FACILITY??
He: Yes, so I can check, that the telegramms I send are right. If I get back the right acknowledgement, the telegramm structure is right and my code is working.
Me: You know, that is not the porpose of unit tests? You know, that these test should run in any environment?
He: But they are proving, that my code is working. Everytime I change something I connect to the customer and let the tests run.
Me: ...
Despite the help of some other developers we could not convince him that this was not good and he should remove them. So now this package is used in 2 new projects and this test suit is still failing, everytime you execute all unit tests.7 -
Testing in a production environment is like closing a door in a to kill a snake and electricity goes off 📴
-
How could I only name one favorite dev tool? There are a *lot* I could not live without anymore.
# httpie
I have to talk to external API a lot and curl is painful to use. HTTPie is super human friendly and helps bootstrapping or testing calls to unknown endpoints.
https://httpie.org/
# jq
grep|sed|awk for for json documents. So powerful, so handy. I have to google the specific syntax a lot, but when you have it working, it works like a charm.
https://stedolan.github.io/jq/
# ag-silversearcher
Finding strings in projects has never been easier. It's fast, it has meaningful defaults (no results from vendors and .git directories) and powerful options.
https://github.com/ggreer/...
# git
Lifesaver. Nough said.
And tweak your command line to show the current branch and git to have tab-completion.
# Jetbrains flavored IDE
No matter if the flavor is phpstorm, intellij, webstorm or pycharm, these IDE are really worth their money and have saved me so much time and keystrokes, it's totally awesome. It also has an amazing plugin ecosystem, I adore the symfony and vim-idea plugin.
# vim
Strong learning curve, it really pays off in the end and I still consider myself novice user.
# vimium
Chrome plugin to browse the web with vi keybindings.
https://github.com/philc/vimium
# bash completion
Enable it. Tab-increase your productivity.
# Docker / docker-compose
Even if you aren't pushing docker images to production, having a dockerfile re-creating the live server is such an ease to setup and bootstrapping the development process has been a joy in the process. Virtual machines are slow and take away lot of space. If you can, use alpine-based images as a starting point, reuse the offical one on dockerhub for common applications, and keep them simple.
# ...
I will post this now and then regret not naming all the tools I didn't mention. -
I used to work on a production management team, whose job was, among other things, safeguarding access to production. Dev teams would send us requests all the time to, "run a quick SQL script."
Invariably, the SQL would include, "SELECT * FROM db_config."
We would push the tickets back, and the devs would call us, enraged. I learned pretty quickly that they didn't have any real interest in dev, test, or staging environments, and just wanted to do everything in prod, and see if it works.
But they would give up their protests pretty fast when I offered to let them speak to a manager when they were upset I wouldn't run their SQL.2 -
For some reason, when testing if a block of code is firing, I always do console.log('fart'); More often than not I forget to remove it before going to production. I feel good knowing that's out there on dozens of sites right now.8
-
I was testing database migration and there was some issues which I couldn't fix them. So I drop the table just to test if the issues are still there.
"Why nothing have been changed?" After some minutes I realize it was production database which I had dropped 😓1 -
So this just happened...don't test on production kids (....sometimes you have no choice BUT DON'T F**KING DO IT OK!?)
 6
6 -
Me: Im testing a new feature that is not on production yet for 30m and can not make it work. (I asked the developer for any idea why is not working)
Dev: i just tested, works fine.
Me: i just tested again with no luck. I’m i missing anything?
Dev: (Developer comes to my desk). Lets see what you doing wrong here. (After 5seconds). You're not on UAT. You have been redirected to the production and you've been testing there all this time.
Me: 😩 -
This morning I was looking in our database in order to solve a problem with a user registration and I accidentally noticed some users registered with unusual email addresses (temporary mail services, Russian providers and so on...).
I immediately thought about malicious users so I dug into the logs and I found that the registration requests started from an IP address belonging to our company (we have static IP addresses). My first reaction was: «OMG! Russian hackers infiltrated into our systems and started registering new users!»
So, I found the coworker owning the laptop from which the requests were sent and I went to him in order to warn him that someone violated his computer.
And he said: «Ah! Those 7 users? Yeah, I was doing some tests, I registered them. My email address was already registered so I created some new ones».
Really, man? Really? WTF5 -
My co-worker, still studying but working as a "senior dev", just decided that we don't need a test/staging environment anymore. We just "validate" (we also don't use the word "test" anymore) newly created features in production.
Makes absolutely sense...
Thank god I have a new job from february on!1 -
young user @Mizukuro asked days ago for ways to improving his javascript skills.
I wasn't sure what to say at the moment, but then I thought of something.
Lodash is the most depended upon package in npm. 90k packages depend on it, more than double than the second most depended upon package (request with 40k).
Lodash was also created 6 years ago.
This means lodash has been heavily tested, and is production ready.
This means that reading and understanding its code will be very educational.
Also, every lodash function lives in its own file, and are usually very short.
This means it's also easy to understand the code.
You could start with one of the "is..." (eg isArray, isFunction).
The reason for such choice is that it's very easy to understand what these functions do from their name alone.
And you also get to see how a good coder deals with js types (which can be very impredictible sometines).
And to learn even more, read the test file for that function (located in tests/<original file name>.js. For the most part they are very readable and examples of very good testing code.
Here's the isFunction code
https://github.com/lodash/lodash/...
Here's the test for isFunction
https://github.com/lodash/lodash/...
The one thing you won't learn here is about es5, 6, or whatever.3 -
I absolutely HATE that stage fright feeling I get when I'm about to launch new software into production mode for a client! Anyone else feel that? Makes me want to vomit thinking of all the promises I've made that it will work fine and then all the things I don't even realize could go wrong. I never have enough testing resources because client budgets tend to favor shiny features at the expense of testing.2
-
-not commenting
-leaving console logs behind in production
-not testing if it works in IE
-using root too much
-using if instead of switch
-never staying consistent with naming conventions
-starting projects and never finishing3 -
I just auto charged myself because I forgot I tested my 7 day trial in production last week
🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡3 -
Borrowed from Reddit and Twitter:
Everybody has a testing environment. Some people are lucky enough enough to have a totally separate environment to run production in.3 -
We have a production release tomorrow and we didn't have any kind of testing other than the unit tests we wrote. 💣💥🤯🎆3
-
Yet another day at work:
My job is to write test libraries for web services and test others code. Yes I know to code, and have a niche in software testing.
Sometimes developers (whose code I find bugs in) get so defensive and scream in emails and meetings if I point out an issue in their code.
Today, when I pointed a bug in his repo, a developer questioned me in an email asking if I even understood his code, and as a tester I shouldn’t look at his code and only blackbox test it.
I wish I can educate the defensive developer that sometimes, it’s okay to make mistakes and be corrected. That’s how we deliver services that doesn’t suck in production.10 -
Me: Im testing a new feature that is not on production yet for 30m and can not make it work. (I asked the developer for any idea why is not working)
Dev: i just tested, works fine.
Me: i just tested again with no luck. I’m i missing anything?
Dev: (Developer comes to my desk). Lets see what you doing wrong here. (After 5seconds). You have been redirected to the production site and you've been testing there all this time.
Me: 😩1 -
> Client complains acceptance testing is too expensive and that he'll do it himself.
> Client complains acceptance testing wasn't thorough enough when a bug hits production. -
I know politics is not allowed here, but I have to share this gem with you.
One day before the election for the European parliament the website of the German city Bochum showed a wrong bar diagram with false results of the election for a few seconds.
Everyone was loling. But I was like WTF? They were testing in production. And also they included data were the party AFD had about 50% of the votes. Are they retarded or so?4 -
Startup-ing 101, from Fitbit:
- spy on users
- sell data
- cut production costs
- mutilate people's bodies, leaving burn scars that will never heal
- announce the recall, get PR, and make the refund process impossibly convoluted
- never give actual refunds
- claim that yes, fitbit catches fire, but only the old discontinued device, just to mess with search results and make the actual info (that all devices catch fire) hard to find
- try hard to obtain the devices in question, so people who suffered have no evidence
- give bogus word salad replies to the press
This is what one of the people burned has to say:
"I do not have feeling in parts of my wrist due to nerve damage and I will have a large scar that will be with me the rest of my life. This was a traumatic experience and I hope no one else has to go through it. So, if you own a Fitbit, please reconsider using it."
Ladies and gentlemen, cringefest starts. One of fitbit replies:
"Fitbit products are designed and produced in accordance with strict standards and undergo extensive internal and external testing to ensure the safety of our users. Based on our internal and independent third party testing and analysis, we do not believe this type of injury could occur from normal use. We are committed to conducting a full investigation. With Google's resources and global platform, Fitbit will be able to accelerate innovation in the wearables category, scale faster, and make health even more accessible to everyone. I could not be more excited for what lies ahead".
In the future, corporate speech will be autogenerated.
(if you wear fitbit, just be aware of this.) 13
13 -
Ever had a day that felt like you're shoveling snow from the driveway? In a blizzard? With thunderstorms & falling unicorns? Like you shovel away one m² & turn around and no footprints visible anymore? And snow built up to your neck?
Today my work day was like that.. xcept shit..shit instead of pretty & puffy snow!!
Working on things a & b, trying to not mess either one up, then comes shit x, coworker was updating production.. ofc something went wrong.. again not testing after the update..then me 'to da rescue'.. :/ hardly patch things up, so it works..in a way.. feature c still missing due to needed workarounds.. going back to a and b.. got disrupted by the same coworker who is nver listening, but always asking too much..
And when I think I finally have the b thing figured out a f-ing blocker from one of our biggest clients.. The whole system is unresponsive.. Needles to say, same guy in support for two companies (their end), so they filed the jira blocker with the wrong customer that doesn't have a SLA so no urgent emails..and then the phone calls.. and then the hell broke loose.. checking what is happening.. After frantic calls from our dba to anyone who even knows that our customer exists if they were doing sth on the db.. noup, not a single one was fucking with the prod db.. The hell! Materialised view created 10 mins ago that blocked everything..set to recreate every 10 minutes..with a query that I am guessing couldn't even select all that data in under 15.. dafaaaq?! Then we kill it..and again it is there.. We found out that customers dbas were testing something on live environment, oblivious that they mamaged to block the entire db..
FML, I'm going pokemon hunting.. :/ codename for ingress n beer..3 -
Ok, here goes...
I was once asked to evaluate upgrade options for an online shop platform.
The thing was built on Zend 1, but that's not the problem.
The geniuses that worked on it before didn't have any clue about best practices, framework convention, modular thinking, testing, security issues...nothing!
There were some instances when querying was done using a rudimentary excuse for a model layer. Other times, they would just use raw queries and just ignore the previous method. Sometimes the database calls were made in strange function calls inside randomly loaded PHP files from different folders from all over the place. Sometimes they used JOINs to get the data from multiple tables, sometimes they would do a bunch of single table queries and just loop every data set to format it using multiple for loops.
And, best of all, there were some parts of the app that would just ignore any ideea of frameworks, conventions and all that and would be just a huge PHP file full of spagetti code just spalshed around, sometimes with no apparent logic to it. Queries, processing, HTML...everything crammed in one file...
The most amazing thing was that this code base somehow managed to function in production for more than 5 years and people actualy used it...
Imagine the reaction I got from the client the moment I said we should burn it to the ground and rebuild the whole thing from scratch...
Good thing my boss trusted me and backed me up (he is a great guy by the way) and we never had to go along with that Frankenstein monster... -
Hello DevRant community! It’s been a while, almost 5 years to be exact. The last time I posted here, I was a newbie, grappling with the challenges of a new job in a completely new country. Oh, how time flies!
Fast forward to today, and it’s been quite the journey. The codebase that once seemed like an indecipherable maze is now my playground. The bugs that used to keep me up at night are now my morning coffee puzzles. And the team, oh the team! We’ve moved from awkward nods to inside jokes and shared victories.
But let’s talk about the real hero here - the coffee machine. The unsung hero that has fueled late-night coding sessions and early morning stand-ups. It’s seen more heated debates than the PR comments section. If only it could talk, it would probably write its own rant about the indecisiveness of developers choosing between cappuccino and latte.
And then there are the unforgettable ‘learning opportunities’ - moments like accidentally shutting down the production server or dropping the customer database. Yes, they were panic-inducing crises of apocalyptic proportions at that time, but in hindsight, they were valuable lessons. Lessons about the importance of thorough testing, proper version control, reliable backup systems, and most importantly, owning up to our mistakes.
So here’s to the victories and failures, the bugs and fixes, the refactorings and 'wontfix’s. Here’s to the incredible journey of growth and learning. And most importantly, here’s to this amazing community that’s always been there with advice, sympathy, humor, and support.
Can’t wait to see what the next 5 years bring! 🥂3 -
Woops! I was debugging a particularly snarky issue in Production the other day. This morning I realized about 60 minutes into my new coding I hadn't changed my profile back. I was testing form submissions on a live customer's site.2
-
Things that seem "simple" but end up taking a long ass time to actually deploy into production:
1. Using a new payment processor:
"It's just a simple API, I'll be done in 2 hours"
LOL sure it is, but testing orders and setting up a sandbox or making sure you have credentials right, and then switching from test to life and retesting, and then... fuck
2. Making changes to admin stats.
"'I just have to add this column and remove that one... maybe like a couple of hours"
YOU WISH
3. Anything Javascript
"Hah, what, that's like a button, np"
125 minutes later...
console.log('before foo');
console.log(this.foo)
etc..2 -
So, awesome clip to use for testing... Problem is, I found this in the codebase for a production app.
*Facepalm*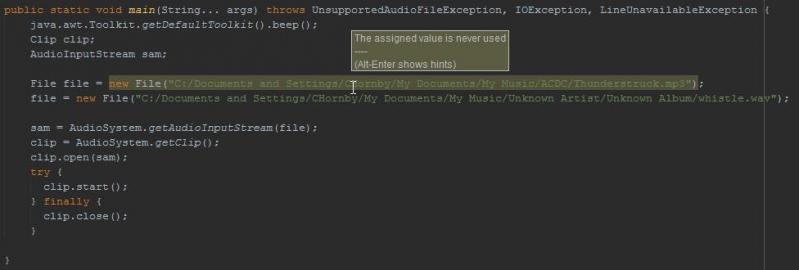 1
1 -
TL;DR Dear boss, firstly, you always get someone to review anything important done by a fucking intern.
Secondly, you do not give access to your fucking client's production server to an intern.
Thirdly, you don't ask your fucking intern to test the intern's work that has not been reviewed by anyone directly on your client's fucking production server.
Last week, the boss and one of the lead devs (the only guy with some serious knowledge about systems and networking) decided to give me (an intern who barely has any work experience) the task of fixing or finding an alternate solution to allowing their support team access to their client machines. Currently they used a reverse SSH tunnel and an intermediary VH but for some reason, that was very unreliable in terms of availability. I suggested using OpenVPN and explained how it would work. Seemed to be a far better idea and they accepted. After several days of working through documentations and guides and everything, I figured out how OpenVPN works and managed to deploy a TEST server and successfully test remote access using two VMs. On seeing my tests, the boss told me that he wanted to test it on the client network. I agreed. Today he comes to me and he tells me to prepare testing for tomorrow and that the client technician is going to give me access to one of their boxes. And then he adds, "It's a working prod server. We'll see if we can make it work on that" and left. I gaped at him for a while and asked another dev guy in the room if what I heard was right. He confirmed. Turns out, the lead dev and the boss's son (who also works here) had had a huge argument since morning on the same issue and finally the dev guy had washed it off his hands and declared that if anything goes wrong from testing it on production, it's entirely the boss's own fault. That's when the boss stepped in and approached me. I ran back to his office and began to explain why prod servers don't top the list of things you can fuck around with. But he simply silenced me saying, "What can go wrong?" and added, "You shouldn't stay still. You should keep moving". Okay, like firstly what the fuck and secondly, what the fuck?.
Even though OpenVPN client is not the scariest thing to install, tomorrow's going to be fun.4 -
fuck this!
spent an hour trying get my website working (on a raspberry) ... no errors, dev tools gave nothing, php gives nothing mySQL related... weird.. debugged my code for an hour when it me... db on my pc for testing is not the same one as the "production" server. i am so fucking stupid... i need some sleep3 -
Me: *asks boss for the id of his test store so I can apply experimental schema changes to test out a new dashboard app*
Boss: *gives me production store id and doesn't say anything*
Fate: … "You got lucky this time."
This is the CEO of the company btw. Startups. *sigh*1 -
Testing an attendace machine API one by one so i know what does what.
And there’s an API for wiping all the attendance data stored in the machine.
I didn’t realize it until i push the damn button.
The attendance machine just become fresh like new 😱😨😰
Shit.
A testing session just become an extreme sport.
Thankfully the IT guy has a backup but just up to last month.
Well, it’s better than nothing isn’t it?
He just tell his boss that the machine was run out of memory and the attendance data for the current month were not saved.
And he ask him to buy me some machine for testing.
Yes, i was living on the edge by testing in the production machine. -
"Real devs test in production", in practice.
This was actually the second such notification I received. Not sure if this is standard for mobile app testing... 2
2 -
Does anyone know of any apps/companies that are using .Net core in production?
I’ve started a project at work which consists of a webapi written in dotnet core, a react spa for the front end and xunit for testing.
I’m just curious as there are loss of sites about things written in Rails, or django, but almost nothing about dotnet core.6 -
A story about a helpless intern : On a fine day an intern was assigned a feature to develope. He worked his ass off, completed it, submitted it for testing, the build was approved by the tester and got released the next day. Fast forward a few days, the feature is failing in few cases at the production.Everbody, starts pointing fingers at the intern.
The intern wonders...How the fuck am I gonna know this fucking use case, do they really expect me to to build a full proof feature without telling me about all the possible senarios...And how the fuck did the tester approved this...? I mean, now that I know this senario, it seems pretty obvious that it should have been tested...!
Note : This also happened to another developer who recently joined...The PM failed to properly communicate all the requirements and the fucking lazy ass tester did not consider all the possible senarios. And the script failed in the production...!
Note : It's 4 fucking AM and the intern still can't sleep...5 -
A coworker reviews if my applications work from time to time (as it is his job).
*sends request*
"Hey nothing works I can't get a single response"
*I check his request*
S-T-O-P using production users when testing, d#head. -
I'm using my devrant avatar for some UI testing :P , thanks @trogus and @dfox
(no production and plagiarism intended) -
Most intense day for me was at the very start of my career. Internship... went with product manager to client's office while PM installed new test version of our product for on-site integration testing. Shortly after deploy, client manager came over to ask why production had gone down...
Turns out that manually typing DB name as part of deployment script is not, erm, risk free. PM entered production DB name and took out a very busy call centre for a few hours. Agents in tears, customers raging on phones, etc! After we restored and got everything back up and running, he reached me the keyboard and said "You're doing it this time."
My attempt was problem free, thankfully. Earned many brownie points that day.1 -
Remember to always setup and test your production setup!
Seem like a local college forgot to do some QA 😂
-
I'm testing a shitforbrains code in production because I don't have any other options. He went on vacation and said that the code should work, and if it doesn't it is my problem.
I am contemplating taking a shit under his desk and working from home. Then he would have to deal with my shit aswell. Literally.
The tables have turned my friend...4 -
A couple of years ago I was working on a fairly large system with a complex (by necessity) access control architecture.
As is usually the case with those projects, it's awkward for developers to repro bugs that have to do with a user's accesses in production when we are not allowed to replicate production data in test, let alone locally.
We had a bug where I ended up making myself a new row in the production database for a thing I could have access to without affecting real data to repro it safely. I identified the bug so I could repro it in dev/test and removed the row and ensured everything worked normally, whew scary.
Have you ever walked into the office one day, and everyone is hunched over in a semicircle around one person's workstation, before one turns around to look at you and says - after a pause - "... ltlian?.."
Turns out I had basically "poisoned the well" with my dummy entity in a way where production now threw 500 for everyone BUT me who had transitive access to this post-non-entity. Due to the scope of the system, it had taken about a day for this to gradually propagate in terms of caching and eventual consistencies; new entities coming in was expected, but not that they disappear.
Luckily I had a decent track record for this to be a one-off. I sometimes think about how I would explain testing in prod and making it faceplant before going home for the day, other than "I assumed it would be fine". I would fire me.3 -
Does anyone work on a team with multiple stacks?
For example we have batch jobs in Java but also have a JS front-end and APIs.
How do you divide the developers and the work across these projects?
Currently everyone does everything but I feel like this is inefficient and hard to develop expertise. And different people or even the same person will make the same mistakes over and over again because they don't know how to do X or they forget or overlook some quirk. When I switched Beck to JS took me like a week to get a Promises nailed down again. And this morning someone else had a production bug and couldn't figure it out. But when I looked at the code I could pretty much see where an issue could be (uncaught exception in a promise)
Also the testing frameworks are very different and there's a lot of infrastructure technical debt, things that really should've been done a long time or fixed but no one had the time or expertise to do it or notice it (until it causes a production issue and then everyone is like WTF is happening??!!!!).
I'm not the manager but I always feel that the team needs to be split along the language lines and specific people need to own these projects to review and code changes for all these common newbie errors. And also developer enough expertise to foresee problems before it becomes a production issue.9 -
I'm so happy that I have the first working version of the program. Just couple of bug fixing and unit testing and I'll push the code to production.
Day 1: Just couple of bug fixing and unit testing and I'll push the code to production.
Day 2: Just couple of bug fixing and unit testing and I'll push the code to production.
.........
Day 200: Just couple of bug fixing and unit testing and I'll push the code to production.
😞 -
How the hell some devs are releasing to production before passing to QA, Alpha testing, staging at least handle all type of errors and hide your API Keys.5
-
Overengineering. Finding the right point between overdesign and no design at all. That's where fancy languages and unusual patterns being hit by real world problems, and you need to deal with all that utter mess you created being architecture astronaut. Isn't that funny how you realize that another fancy tool is fundamentally incompatible with the task you need to solve, and you realize it after a month of writing workarounds and hacks.
But on the other hand, duct tape slacking becomes a mess even quicker.
Not being able to promote projects. You may code the shit out of side project and still get zero response, absolutely no impact. That's why your side projects often becomes abandoned.
Oversleeping. You thought tomorrow was productive day, but you wake up oversleeped, your head aches, your mind is not clear and you be like "fuck that, I'm staying in bed watching memes all day". But there's job that has to be done, and that bothers you.
Writing tests. Oh, words can't describe how much I hate writing tests, any kind of. I tried testing so many times in high school, at university, even at production, but it seems like my mind is just doesn't accept it. I know that testing is fundamentally important, but my mind collapses every time I try to write a single fucking test, resulting in terrible headache. I don't know why it's like that, but it is, and I better repl the shit out of pure function than write fucking tests. -
Client calls me requesting a new simple feature.
Connect to FTP server.
Edit some PHP pages and upload them back, check if the changes actually worked.
Basically implementing and testing a new feature on a live production website...
PS. It didn't work the first or second time -
Why is web development such a headache?
I'm writing a responsive wesbite from scratch. All goes perfect, even cross browser.
It all works, adapts to screen size etc. Nice! About to get this code into production.
Me: I'll test the iPhone 5 viewport size before I push the code...
Responsive Developer Tools:
FireFox: nu uh, there's a magic random 1px margin to every element on your page now, which you cannot find in your css or in the computed tab. It's magical.
Me: weird, what if I change the viewport size to the iPhone 6's dimensions?
Issue persists.
Me: hmm, what if I add or substract one fucking pixel from the viewport width or height?
FireFox: What 1px margin? Don't know what you're talking about ... There never was one...
Me: ok, weird (sets viewport size back to the iPhone 5 format for testing)
FireFox: I present to you: the magic random 1px margin.
I'm at a loss. I really am. Been clicking and unclicking almost every responsive part of my css I could find for this page and it just doesn't want to work persistently. And I swear to god that it worked a week ago in that exact viewport size. It's so frustrating. 31
31 -
TL;DR: When picking vendors to outsource work to, vet them really well.
Backstory:
Got a large redesign project that involves rebuilding a website's main navigation (accessibility reasons).
Project is too big just for our dev team to handle with our workload so we got to bring a 3rd party vendor to help us. We do this often so no big deal.
But, this time the twist was Senior Management already had retained hours with a dev shop so they want us to use them for project. Okay...
It begins:
Have our scope / discovery meeting about the changes and our expected DevOps workflow.
Devs work Local and push changes to our Github, that kicks off the build and we test on Dev, then it goes to Staging for more testing & PM review. Once ready we can push to prod, or whenever needed. All is agreed, everyone was happy.
Emailed the vendors' project manager to ask for their devs Github accounts so we can add them to the project. Got no reply for 3 days.
4th day, I get back "Who sets up the Github accounts?"
fuck me. they've never used Github before but in our scope meeting 4 days ago you said Github was fine...??
Whatever, fuck it. I'll make the accounts and add them.
Added 4 devs to the repo and setup new branch. 40min later get an email that they can't setup dev environment now, the dev doesn't know how to setup our CMS locally, "not working for some reason."
So, they ask for permission to develop on our STAGING server.. "because it's already setup"... they want to actively dev on our staging where we get PM/Senior Management approvals?
We have dev, staging, production instances and you want to dev in staging, not dev?... nay nay good sir.
This is whom senior management wants us to use, already paid for via retainer no less. They are a major dev shop and they're useless...
😢😭
Cant wait for today's progress checkup meeting. 😐😐
/rant1 -
So glad to be staying a new job next week. Today a junior colleague asked me what the best way to test something would be as it won't work locally. Knowing this has a good chance of taking down the server, I suggest he sounds up a server on his AWS account. My manager comes in, oh no I don't want him doing it on AWS use the production server instead. By the time stuff States hitting the fan I will be gone.1
-
A loooong time ago...
I've started my first serious job as a developer. I was young yet enthusiastic as well as a kind of a greenhorn. First time working in a business, working with a team full of experienced full-lowered ultra-seniors which were waiting to teach me the everything about software engineering.
Kind of.
Beside one senior which was the team lead as well there were two other devs. One of them was very experienced and a pretty nice guy, I could ask him anytime and he would sit down with me a give me advice. I've learned a lot of him.
Fast forward three months (yes, three months).
I was not that full kind of greenhorn anymore and people started to give me serious tasks. I had some experience in doing deployments and stuff from my other job as a sysadmin before so I was soon known as the "deployment guy", setting up deployments for our projects the right way and monitoring as well as executing them. But as it should be in every good team we had to share our knowledge so one can be on vacation or something and another colleague was able to do the task as well.
So now we come to the other teammate. The one I was not talking about till now. And that for a reason.
He was very nice too and had a couple of years as a dev on his CV, but...yeah...like...
When I switched some production systems to Linux he had to learn something about Linux. Everytime he encountered an error message he turned around and asked me how to fix it. Even. For. The. Simplest. Error. He. Could. Google. Up.
I mean okay, when one's new to a system it's not that easy, but when you have an error message which prints out THE SOLUTION FOR THE ERROR and he asks me how to fix it...excuse me?
This happened over 30 times.
A. Week.
Later on I had to introduce him to the deployment workflow for a project, so he could eventually deploy the staging environment and the production environment by hisself.
I introduced him. Not for 10 minutes. I explained him the whole workflow and the very main techniques and tools used for like two hours. Every then and when I stopped and asked him if he had any questions. He had'nt! Wonderful!
Haha. Oh no.
So he had to do his first production deployment. I sat by his side to monitor everything. He did well. One or two questions but he did well.
The same when he did his second prod deploy. Everythings fine.
And then. It. Frikkin. Begins.
I was working on the project, did some changes to the code. Okay, deploy it to dev, time for testing.
Hm.
Error checking out git. Okay, awkward. Got to investigate...
On the dev server were some files changed. Strange. The repo was all up to date. But these changes seemed newer because they were fixing at least one bug I was working on.
This doubles the strangeness.
I want over to my colleague's desk.
I asked him about any recent changes to the codebase.
"Yeah, there was a bug you were working on right? But the ticket was open like two days so I thought I'll fix it"
What the Heck dude, this bug was not critical at all and I had other tasks which were more important. Okay, but what about the changed files?
"Oh yeah, I could not remember the exact deployment steps (hint from the author: I wrote them down into our internal Wiki, he wrote them done by hisself when introducing him and after all it's two frikkin commands), so I uploaded them via FTP"
"Uhm... that's not how we do it buddy. We have to follow the procedure to avoid..."
"The boss said it was fine so I uploaded the changes directly to the production servers. It's so much easier via FTP and not this deployment crap, sorry to say that"
You. Did. What?
I could not resist and asked the boss about this. But this had not Effect at all, was the long-time best-buddy-schmuddy-friend of the boss colleague's father.
So in the end I sat there reverting, committing and deploying.
Yep
It's soooo much harder this deployment crap.
Years later, a long time after I quit the job and moved to another company, I get to know that the colleague now is responsible for technical project management.
Hm.
Project Management.
Karma's a bitch, right? -
New twist on an old favorite.
Background:
- TeamA provides a service internal to the company.
- That service is made accessible to a cloud environment, also has a requirement to be made available to machines on the local network so you can develop against it.
- Company is too cheap/stupid to get a s2s vpn to their cloud provider.
- Company also only hosts production in the cloud, so all other dev is done locally, or on production non-similar infra, local dev is podman.
- They accomplish service connectivity by use of an inordinately complicated edge gateway/router/firewall/message translator/ouija board/julienne fry maker, also controlled by said service team.
Scenario:
Me: "Hey, we're cool with signing requests using an x509 cert. That said, doing so requires different code than connecting to an unsecured endpoint. Please make this service accessible to developer machines and lower environments on the internal network so we can, you know, develop."
TeamA: "The service should be accessible to [cloud ip range]"
Me: "Yes, that's a production range. We need to be able to test the signing code without testing in production"
TeamA: "Can you mock the data?"
Me: "The code we are testing is relating to auth, not business logic"
TeamA: "What are you trying to do?"
Me: "We are trying to test the code that uses the x509 you provide to connect to the service"
TeamA: "Can you deploy to the cloud"
Me: "Again, no, the cloud is only production per policy, all lower environments are in the local data center"
TeamA: "can you try connecting to the gateway?"
Me: "Yes, we have, it's not accessible, it only has public DNS, and only allows [cloud ip range]"
TeamA: "it work when we try it"
Me: "Can you please supply repro steps so we can adjust our process"
TeamA: "Yes, log into the gateway and try issuing the call from there"
Me: (╯°□°)╯︵ ┻━┻
tl;dr: Works on my server -
* Developing a new "My pages" NBV offer/order solution for customer
_Thursday
Customer: Are we ready for testing?
Me: Almost, we need to receive the SSL cert and then do a full test run to see if your sales services get the orders correctly. At this point, all orders made via this flow are tagged so they will not be sent to the Sales services. We also still need to implement the tracking to see who has been exposed to what in My Pages.
Customer: Ok, great!
_Friday
Customer: My web team needs these customers to have fake offers on them, to validate the layout and content
Me: Ok, my colleague can fix this by Tuesday - he has all the other things with higher prio from you to complete first
Customer: Ok! Good!
_Sunday
Me: Good news, got the SSL cert installed and have verified the flow from my side. Now you need to verify the full flow from your side.
Customer: Ok! Great! Will do.
_Monday
*quiet*
_Tuesday
Customer: Can you see how things are going? Any good news?
Me: ???
*looks into the system*
WTF!?!
- Have you set this into production on your side? We are not finished with the implementation on our side!
Customer: Oh, sorry - well, it looked fine when we tested with the test links you sent (3 weeks ago)
Me: But did you make a complete test run, and make sure that Sales services got the order?
Customer: Oh, no they didn't receive anything - but we thought that was just because of it being a test link
Me: Seriously - you didn't read what i wrote last Thursday?
Customer: ...
Me: Ok, so what happens if something goes wrong - who get's blamed?
Customer: ...
Me: FML!!!2 -
Tl;Dr Im the one of the few in my area that sees sftping as the prod service account shouldn't be a deployment process. And the ONLY ONE THAT CARES THAT THIS IS GONNA BREAK A BUNCH OF SHIT AT SOME POINT.
The non tl;dr:
For a whole year I've been trying to convince my area that sshing as the production service account is not the proper way to deploy and/or develop batch code. My area (my team and 3 sister teams) have no concept of using version control for our various Unix components (shell scripts and configuration files) that our CRITICAL for our teams ongoing success. Most develop in a "prodqa like" system and the remainder straight in production. Those that develop straight in prodqa have no "test" deployment so when they ssh files straight to actual production. Our area has no concept of continuous integration and automated build checking. There is no "test cases", no "systems testing" or "regression testing". No gate checks for changing production are enforced. There is a standing "approved" deployment process by the enterprise (my company is Whyyyyyyyyyy bigger than my area ) but no one uses it. In fact idk anyone in my area who knows HOW to deploy using the official deployment method. Yes, there is privileged access management on the service account. Yes the managers gets notified everytime someone accesses the privileged production account. The managers don't see fixing this as a priority. In fact I think I've only talk to ONE other person in my area who truly understands how terrible it is that we have full production change access on a daily basis. Ive brought this up so many times and so many times nothing has been done and I've tried to get it changed yet nothing has happened and I'm just SO FUCKING SICK that no one sees how big of a deal this. I mean, overall I live the area I work in, I love the people, yet this one glaring deficiency causes me so much fucking stress cause it's so fucking simple to fix.
We even have an newer enterprise deployment. Method leveraging a product called "urban code deploy" (ucd) to deploy a git repository. JUST FUCKING GIT WITH THE PROGRAM!!!!..... IT WAS RELEASED FUCKING 12 YEARS AGO......
Please..... Please..... I just want my otherwise normally awesome team to understand the importance and benefits of version control and approved/revertable deployments2 -
The most crazy issue I've fixed was caused by a TCP behavior which I didn't know, called the "half-closed connection".
There was a third-party application installed on a production server which called a LDAP server for retrieving users information. During the day we had several users using the application and all worked fine. During the night, when the application was not accessed, something happened and the first call to the application in the morning was stuck for about 5 minutes before returning a response. I tried to reproduce the issue in a testing environment without success. Then I discovered that the application and the LDAP server were located on two different networks, with a firewall between them. And firewalls sometimes drop old connections. For this reason network applications usually implement a keep-alive mechanism. Well, the default LDAP Java libraries don't set the keep-alive on their connections. So, I found a library called "libdontdie", which force the keep-alive on the connections. I installed the library on the server, loaded it at the startup and the weird stuck behavior in the morning disappeared.2 -
Oh look, the testers are using a production version of something when they should be using the TESTING version
iT DoeSnT wOrk!!!!!! aAaAAAaaaA
And the cycle continues...2 -
My first rant. Woohoo!
Honestly I do the whole shebang ussualy depending on what the needs are from network to servers to coding because for some reason nobody has any technical experience where I work.
I just started app development for a gamedev startup and I am in sheer awe of the amount of transpiling/compiling etc that needs to be done for an multiplatform app for iOS and android with js(x)/typescript, html, css.
I remember when I could just write some spaghetti code to make it working by following a couple of tutorials. Then refractoring and testing it for a couple of hours and be done with it. push it into production.
Now I am lost having to learn OOP, functional programming, reactjs, react native, express, webpack, mongodb, babel, and the list goes on and on...
Why not just make a new backend that does all of that in another language which supports all of that.
I have no formal education in programming/coding and the last time I learned JS it was just some if else, switches and simple dom manipulation.
I just want to get to coding a freakin' game but I have to learn JSX for the front and typescript on the backend.
I am this close to going back to ye ol' lamp stack and quitting this job. 😥5 -
my company is "pivoting" way too goddamn fast; they are pulling devs from other projects and throwing them into something that is a fragile system (was supposed to be replaced already) and is using a completely different stack than most of them usually work with. they keep promising 3rd parties that we will knock out their requirements within a week or two, and as such they are pushing haphazardly merged feature branches into production with absolutely no regression testing.
then when shit explodes and operations grinds to a halt, they tell the half of the team that actually knows how the system works to drop everything and fix it, and leave the diverted devs to continue to develop shit based on requirements drawn on a cocktail napkin, and then they fucking push both the hotfixes and the newest features at the same time.
I probably have the most tribal knowledge at this company, and they are paying me ok, so it's enough for me to just pour some rye and suck it up for the time being and milk the gig. but this can't be sustainable, right? i'm passively looking around for other work, as I've already had enough being here for over 3 years, but i'm finding most places to be slow on the application/hiring process lately due to covid.
Edit: i think i used the wrong tag here, but what the fuck ever. i haven't figured out how to tag shit properly on any platform3 -
Since I have seen a lot of people uploading this kind of stuff lately, here is Xiaomi's test in production, back in 2017 November...
 1
1 -
I'm genuinely shocked at the number of people I see on here bashing automated testing as a waste of time, simply because my entire career has taught me the opposite (and it's usually only non-technical managers I see who don't want to see "time wasted" writing tests.)
I'm also just as genuinely curious - what do you guys do instead? Just don't test and deal with production issues as they occur? Pass it off to a separate UAT / human-based testing department and let them sign it off? Assume that because you're using Haskell / some other discipline it'll work if it compiles?13 -
My mate just pen-testing on running production server using admin credential.
Guess what happen!
And no backup!
What a day!2 -
*Repost of my own accidentally deleted post*
A Short story that i made on an Android component
===============================
Once upon a time there used to be a ViewPager who was not able to load a Fragment UI.
All the ViewPagers in town can properly load the Fragrant UI but this one was little different.
He wanted to be more then just a ViewPager. He used to see an Activity that can load anything. He was inspired from the Activity and wanted to be like the Activity but his destiny made him just a ViewPager.
So he refused to cooperate. He started to protest silently, No log, nothing.
Everyone assumed this ViewPager have a bug in it. but he was planning something really big that will left everyone in shock and awe moment.
He was planning to rise against the evil 😈 developers who continuously making him to load Fragrant UI
He assembled the biggest army of the bugs that humanity ever seen to counter the developers.
He distributed these bugs in all over the developer's code to make them fire from their work.
Even he taught bugs to not caught in QA testing but appear in production randomly.
So they silently started going into production
And then chaos is erupted all around the world, bugs started to surface and interrupted the daily life of humanity.
In this chaos the ViewPager RAISED!
And took over all the base classes.
ViewPager was unaware of few facts. this unnecessary rise in his power made whole system unstable
Without the base classes the system finally collapsed and then ViewPager as well with the system.
This was the end of everything for the ViewPager but he was satisfied as he lived the life he always wanted
THE END -
Trying to make a deadline, waiting for more info from an analist so I can implement the science stuff correctly
Today I receive the email with the info I need. Email is cc'ed to the client. And it starts with complaining about me not having implemented the science stuff. The info I need is attached in this email. Arghgh, how am I supposed to do that if I don't have the information I need.
Apart from that she was testing in the production environment. How do you work with people like this.
But hey, I just got my devRant stickers ;) -
So I get a message from my ex-colleague today, and it’s déjà vu all over again.
Apparently, the CTO at my old company went full Hulk in the office this morning, demanding to know who used the ops@ email to subscribe to something called "custom purring ASMR." If that sounds familiar, buckle up - this one’s even better.
For context, this is the same company where I once had to explain to the CFO why our tech@ email got invoiced for "panties juice, extra virgin." If you don’t remember… Yeah, I left, but the shenanigans clearly stayed. Here’s a spot-the-difference picture: https://devrant.com/rants/6213132/...
Turns out, one of the devs was testing an API integration for some niche subscription platform. Nothing new there — sandbox environments, dummy accounts, €5 test payments. Except genius over here decides to jazz it up and names the testing account: "Cat Daddy Deluxe, meow to pay." Obviously not meant for production, right?
Fast forward to yesterday (yes, Friday): the platform goes live without clearing the sandbox database. Dev’s test account? Now the default subscription for every new creator. Not only that, but every 1k subscribers it "wins" a discount for the next most popular account. What are the top 5 other popular accounts?
5. "Leather Daddy Lullabies" – soothing bedtime stories narrated by a guy in full BDSM gear.
4. "ASMR For Adult Toys" – exactly what it sounds like, but HR will still ask.
3. "Moaning Meditation Mondays" – very NSFW guided mindfulness exercises... weekly!
2. "Kinksploration 101" – a podcast exploring bizarre fetishes you wish you didn’t know about.
1. And last but not least, "Spicy Grandma Diaries" – erotic stories written and narrated by a sweet old lady from the local senior centre, apparently depicting real-life escapades from her 70s. In great detail.
Here’s the kicker. Friday, ops@ gets two discount emails. The same guy who roasted the “panties” girl the hardest, the very one who caused this mess, is now sure they’ve finally sent him more accounts to test - because clearly, those can’t be meant for production. Right?
Long story short: he spent €118 of real-life company funds, and IT is now on the hook for lifetime memberships to “Purring Dominance 101” and “Whisker Tickler Masterclass.” How satisfying is it to see the universe balance all his not-so-funny comments?
Also, I’m definitely getting them to forward me those whisker-tickler classes. No matter how good you think you are, some areas of life always have room for improvement.4 -
While smoke testing in production, I had to delete the sample entity I created to test the released feature, which is not a big deal
Until 20 minutes later, when I realized that I attached a couple of sub entities under it that contained actual live data1 -
Did you ever had to integrate a fucking "API" that is done via mail bodies?
Fuck this shit! Who need responses about success or failure?! Guess this will take a long time to test this fucking piece of garbage... We don't get a test system, we need to test this with the production system of the other company. I hope their retarded application crashes when receiving malicious mails.
Not speaking about security, I bet everyone can send a mail to their stupid mail address and modify their data 🙈
And inside of this crap mail you also have to send the name, street and email of their company. Why do you fucking need this information?!1 -
Oooh I have quite a few,
My favourite: accidently left a log. Debug("bollocks") in a try catch this made it through testing and does (still) occasionally go into production log files.
Worst: wrote an interceptor for jboss with the intent of checking cache for some lookup data. I picked the wrong one of two similarly named methods and instead queried the database, I effectively wrote a denial of service utility into our app -
I just had the most embarrassing moment in programming... I am writing an administration / client / invoice webapp and I was testing an export function that worked locally, because everything that was being exported was inside the folder.
So I exported the files in test production, but some invoices didn't exist. So when they don't exist, the system creates a new invoice.
Because I was running on the test production (with client data) the system emailed the created invoices to the clients.. now I have to contact some clients and tell them the invoices were sent accidentally.2 -
How many people do unit testing?. Am always caught my deadline. I just fix errors in production. The client timeline are not feasible2
-
I actually learnt this last year but here I go in case someone else steps into this shit.
Being a remote work team, every other colleague of mine had some kind of OS X device but I was working this Ubuntu machine.
Turns out we were testing some Ruby time objects up to a nanosecond precision (I think that's the language defaults since no further specification was given) and all tests were green in everyone's machine except mine. I always had some kind of inconsistency between times.
After not few hours of debugging and beating any hard enough surface with our heads, we discovered this: Ruby's time precision is up to nanoseconds on Linux (but just us on OS X) indeed but when we stored that into PostgreSQL (its time precision is up to microseconds) and retrieved it back it had already got its precision cut down; hence, when compared with a non processed value there was a difference. THIS JUST DOES NOT HAPPEN IN OS X.
We ended up relying on microseconds. You know, the production application runs on Ubuntu too. Fuck this shit.
Hope it helps :)
P.s.: I'm talking about default configs, if anyone knows another workaround to this or why is this the case please share. -
The company I worked for had to do deletion runs of customer data (files and database records) every year, mainly for legal reasons. Two months before the next run they found out that the next year would bring multiple times the amount of objects, because a decade ago they had introduced a new solution whose data would be eligible for deletion for the first time.
The existing process was not be able to cope with those amounts of objects and froze to death gobbling up every bit of ram on the testing system. So my task was to rewrite the exising code, optimize api calls and somehow I ended up in multithreading the whole process. It worked and is most probably still in production today. 💨 -
Debugging a task, that's sending emails to too many customers.
Supervisor: "Never mind, just test in production, there is a dry run flag for the tasks."
Just in case I test locally...
Flags tried:
--dryrun="TRUE" => Error, failed to send mail.
--dryrun=TRUE => Error, failed to send mail.
--dryrun="true" => Not trying to send mail.
If it's THIS PICKY a little more documentation would be nice.
And by a little more I mean: more than the task base class in a giant php monstrosity without phpdocs expecting its code to be self-documenting. -
One of the founders of my startup does not write tests....
Me: we have to all write tests. I explain unit tests, integration, etc.
Him: I do... I have a test that checks if the app crashes or not.
Me: that is not what I meant (writes test because he won’t) 🙄1 -
A customer asks for a change request or a bug fix and it results in creating a ticket for that.
It's the process and how it works in most places but after you finish with the task and fix the same customer who provided you with the requirements will request that you share the steps on how to test the fix or the feature.
I'm not speaking about the data preparation or required configuration. I mean a step-by-step instruction on how the tester/QA will test it.
It's driving me mad!! So a way to counterplay this stupid requests, I provide the happy path and what to expect. And in case, they stumbled on a bug later in production, I can easily say "It was approved by your testing team and that's a new requirement ;)"2 -
I don't know if my boss just wants me to learn how to use a new internal deployment process or just likes giving me unnecessary low-value work to take up time...
I could and have just copied the program via SFTP and unzip it to set it up....
(This is a testing and does not need to be in production...)
I have better things I could be doing and just want to get this done and closed but ... -
Installed on my 2x 980 TI SLI the newest Nvidia Driver 384.76.
Played games on it and some Video Editing. Noticed that I have bad laggs and checked clocks.
Wow clocks were locked at half the max Output. Checked if I can do anything to increase it, nope it's locked at half the Performance.
Tried to install previous Driver, install failed. Went 2 Drivers back and installed the 382.33.
Everything worked again.
WTF are the guys at NVIDIA coding while being drunk?? How the fuck can you lock the powertarget of the GPU at half the Performance and after 4 days not releasing a hotfix? Are they testing this shit even or forcing it into production?
Currently NVIDIA has really crappy drivers and with every update it gets even worse.
And the only option you got is GPU's from NVIDIA and AMD. And Vega is not even released yet.
Hope that AMD will beat the shit out of NVIDIA...5 -
Out of the frying pan, into the fire:
So in my first job, I thought it's just us operating so crazy: meddling with arcane C/C++ code from the 80's, shooting our code to production without testing, fixing hundred of customers data base entries by hand, letting an intern alter some core component (to have more logging) and directly push it to prod...
Silly me.
I mean I suspected, that maybe it's not only this tiny little company acting wild, that also the bigger companies with all their ISO certified processes, agile blabla, professional tooling whatsoever - will also have their skeleton in the closet,.. like some obscure assembler part buried in the heart of your code base nobody dares to touch...
How Pieter Hintjens asked about the state of the industry and all the fads so bluntly put it:
"It's all bullshit."
But we are humans, so we better jump on the bandwagon if we want to keep our jobs... and somehow try to keep that trashy house of cards from crashing down. -
I'm supposed to find why a pdf is not generated correctly. But here is the problem :
I don't have access to the production to see the bug and the pdf they gave me is different to the ones I generated myself. But ! It's not over :
My local version does not generate the same pdf as the acceptance testing version !
So here I am, with three different pdf and only the possibility to modify the local one, where the bug isn't.1 -
While addressing a Senior Dev's (SD) query from another team.
SD: why is this field mandatory? Can't it be just optional? Any other work around?
Me: Is your code changes already pushed in Devo? In that case, we provide a value which will work since you are not concerned about it.
SD: Yes. It's pushed till production. And, I want to test changes in Prod.
Me: (shared some codes) and explained that this feature for testing is only available in Devo.
SD: I know that. (Shared me a ticket) I want this field to be optional. That's it.
Me: (read the entire ticket. Didn't find anything related their) Told him, I will discuss with team. And meanwhile, for Devo, you can use this value.
Next morning, I accidentally came over some other ticket raised by him only which had the correct doubts regarding request to support this field in production
Now, I don't know why did he share a wrong ticket with me.
And, how will it even help him if that field was even optional.
THAT JUST WONT WORK IN PRODUCTION.
I will discuss with my team and see what can happen. -
I am still confused why people treat testing as secondary position? Tester are paid less and they hire lower quality engineers. I think testing is as important as any other phase of development, like design or implementation. . . and yeah we do testing of our own code. The only thing I can do in my case is to see that people who change my code may not break basic functionalities. And again about edge cases, try to handle some other left to be seen in production( those which I could not think of due to lack of time) I take care not to leave edge case but sometime cannot do it. I just hope people realise the worth of testing.
-
Working with a data scientist on an update to a machine learning api that has dinner logic change with a new model.
He's wondering why his PRs are falling.
He's trying to merge into development from a branch created off of main.
He's renamed all the functions and classes and never updated the call points.
He's using new packages but never includes them in the requirements file, so the docket builds are failing.
His class method definitions don't contain self and are throwing syntax errors.
I've been working with him for 4 days to get him to understand branching, linting, unit testing, and not blindly copy and pasting snippets from jupyter notebook into production api code!8 -
I know I have a problem with asking for help. I'm aware it's a problem, I want to solve it, and I'm trying, but this is easier said than done.
In my defense however, the issues I'd need to ask for help with are completely absurd. We have a shared Feature environment with a shared database. A push to any feature branch auto-applies migrations to this database, so it's full of broken script output. Tests are supposed to use this database. We do not have full rights to edit this database so we can't try and fix the issues. Instead, the database is reset from production once a week, discarding all changes including anything we deliberately put there for testing. I asked who broke the database and if they could fix it please, somebody responded with freeform text roughly describing the fixes _I should apply to fix HIS TEAM'S mess_, which didn't include any technical identifiers and referred to tables and columns exclusively via vague approximate names.
He then posted a screenshot of an e-mail from about a month ago in which HE complained to MY team lead about how "some people" keep breaking the database, which contained no examples and no suggestions, but was sent immediately after the first time this year that we actually properly broke the shared database. By that point they were past their 10th broken migration that warranted an early restore.8 -
Posted in DevOps discussion board (teams channel):
“Program x isn’t behaving the same way that it does on production. Can you please take a look?”
..a little background: we have a deployment scheduled for today and this issue was found during regression testing.
The issue found is that when a file is clicked on it disappears from the screen, and then isn’t opened…
The file is not on prem, and doesn’t get uploaded to a server that our DevOps team owns…
So why on earth would this development team be asking DevOps to look into a bug that is most likely a code related issue? 😆
Is this a common occurrence for anyone else?
A Bug is found, and the first thought is that the code isn’t the issue?11 -
Sometime last year I had an internship at a small company.
Test servers weren't a thing, and after local testing, it would go to production with a backup of the files that we would put back as soon as we notice something was broken or off.
We used symfony and sonata admin was part of the bundle.
One day, boss asks me to show all the items in a table on the admin page instead of 30 rows.
Me being good guy intern say "sure no problem" so after finding the magic number, I set it to 0 instead of 30.
I gave my work reviewed by my supervisor (senior dev there) and he approved it.
I try to upload the file over FTP. No permissions.
Ask the other dev what it's about, his response: "no idea"
So he tries, fails and decides to try SSH.
Somehow, after fiddling for 20 minutes with ssh, we managed to upload the file.
As soon as we did we hear a scream from the boss's office, we refresh the site, and no matter what page we went to, all we saw was white and the logo of the company in the top left corner.
So this time, we fiddled around with ssh to restore the file for 20 minutes.
Finally succeed all goed back to normal.
A little while later, we call a meeting with the bosses and ask to rewrite the website, BAM, we get approval.
We said "two weeks tops", well that lasted 3 months.
In the end bosses are Uber happy with the work and everything ended well.
Also, development speed has multiplied. -
Working on a bugfix which has surfaced after 2 years, I hate the way that nobody thought of perhaps tidying up a component before leaving it gathering dust. Basically found dozens sections of identical code with minimal changes both for production code and testing :/1
-
For the last time, ES5 DOESN'T support optional function parameters. gulp --production fails when running on testing when you do that.
*fixes gulp tasks to do gulp --production by default*
Next day : hey, why does gulp keep failing.
IT IS BECAUSE YOU DIDN'T LISTEN TO ME THE LAST 100 TIMES WHEN I SAID OPTIONAL PARAMETERS DOESN'T WORK WHEN MINIFYING
Let's see how you do it now.3 -
So I am debugging a connector library for an api that users curl.
I am fighting my ass off with errors and a lack of debug, testing or thought for CI
Take a poke around this set of classes only to find.
Postman token in the opts. and a removal of ssl check. What you straight copied from postman.
Like seriously clean up your fucking code if you are gonna put something out as production ready to your team.
Console.log('fuck'); -
When i had finished my work and was about to leave i saw commit in master labeled "Testing on production"... tomorrow will be an interesting day1
-
After three months of development, my first contribution to the client is going live on their servers in less than 12 hours. And let me say, I shall never again be doing that much programming in one go, because the last week and a half has been a nightmare... Where to begin...
So last Monday, my code passed to our testing servers, for QA to review and give its seal of approval. But the server was acting up and wouldn't let us do much, giving us tons of timeouts and other errors, so we reported it to the sysadmin and had to put off the testing.
Now that's all fine and dandy, but last Wednesday we had to prepare the release for 4 days of regression testing on our staging servers, which meant that by Wednesday night the code had to be greenlight by QA. Tuesday the sysadmin was unable to check the problem on our testing servers, so we had to wait to Wednesday.
Wednesday comes along, I'm patching a couple things I saw, and around lunch time we deploy to the testing servers. I launch our fancy new Postman tests which pass in local, and I get a bunch of errors. Partially my codes fault, partially the testing env manipulating server responses and systems failing.
Fifteen minutes before I leave work on the day we have to leave everything ready to pass to staging, I find another bug, which is not really something I can ignore. My typing skills go to work as I'm hammering line after line of code out, trying to get it finished so we can deploy and test when I get home. Done just in time to catch the bus home...
So I get home. Run the tests. Still a couple failures due to the bug I tried to resolve. We ask for an extension till the following morning, thus delaying our deployment to staging. Eight hours later, at 1AM, after working a full 8 hours before, I push my code and leave it ready for deployment the following morning. Finally, everything works and we can get our code up to staging. Tests had to be modified to accommodate the shitty testing environment, but I'm happy that we're finally done there.
Staging server shits itself for half a day, so we end up doing regression tests a full day late, without a change in date for our upload to production (yay...).
We get to staging, I run my tests, all green, all working, so happy. I keep on working on other stuff, and the day that we were slated to upload to production, my coworkers find that throughout the development (which included a huge migration), code was removed which should not have. Team panics. Everyone is reviewing my commits (over a hundred commits) trying to see what we're missing that is required (especially legal requirements). Upload to production is delayed one day because of this. Ended up being one class missing, and a couple lines of code, which is my bad (but seriously, not bad considering I'm a Junior who was handed this project as his first task at his first job).
I swear to God, from here on out, one feature per branch and merge request. Never again shall I let this happen. I don't even know why it was allowed to happen, it breaks our branch policies. But ohel... I will now personally oppose crap like this too...
Now if you'll excuse me... I'm going to be highly unproductive and rest, because I might start balding otherwise after these weeks... -
I recently joined a bank as an IT Quality Analyst, and it's been an overwhelming experience. I feel like I've been working like a donkey for a fraction of what I deserve. My responsibilities include testing all types of software, including some that, frankly, seem poorly shity written by vendors.
The project managers are not helping matter....they push projects through UAT and expect me to sign off on everything as if it’s ready for production. They seem indifferent to how compromised the testing can be. They want me to say all tests passed even when there are unresolved issues. If I do find any failed tests, they expect me to chase after developers for fixes.
As a developer myself, I took on this QA role to explore a new area of IT, but it's clear that this environment is not what I hoped for. The stress is mounting every day, and I find myself wanting to avoid the PMs entirely. It's disheartening to see them receive compensation that feels entirely unwarranted given the pressure they put on the testing process without regard for quality or thoroughness. I need to voice these frustrations because it's becoming hard to stay motivated in a role that feels so misaligned with my values and professional ethics.3 -
A very long rant.. but I'm looking to share some experiences, maybe a different perspective.. huge changes at the company.
So my company is starting our microservices journey (we have a 359 retail websites at this moment)
First question was: What to build first?
The first thing we had to do was to decide what we wanted to build as our first microservice. We went looking for a microservice that can be used read only, consumers could easily implement without overhauling production software and is isolated from other processes.
We’ve ended up with building a catalog service as our first microservice. That catalog service provides consumers of the microservice information of our catalog and its most essential information about items in the catalog.
By starting with building the catalog service the team could focus on building the microservice without any time pressure. The initial functionalities of the catalog service were being created to replace existing functionality which were working fine.
Because we choose such an isolated functionality we were able to introduce the new catalog service into production step by step. Instead of replacing the search functionality of the webshops using a big-bang approach, we choose A/B split testing to measure our changes and gradually increase the load of the microservice.
Next step: Choosing a datastore
The search engine that was in production when we started this project was making user of Solr. Due to the use of Lucene it was performing very well as a search engine, but from engineering perspective it lacked some functionalities. It came short if you wanted to run it in a cluster environment, configuring it was hard and not user friendly and last but not least, development of Solr seemed to be grinded to a halt.
Elasticsearch started entering the scene as a competitor for Solr and brought interesting features. Still using Lucene, which we were happy with, it was build with clustering in mind and being provided out of the box. Managing Elasticsearch was easy since there are REST APIs for configuration and as a fallback there are YAML configurations available.
We decided to use Elasticsearch since it provides us the strengths and capabilities of Lucene with the added joy of easy configuration, clustering and a lively community driving the project.
Even bigger challenge? Which programming language will we use
The team responsible for developing this first microservice consists out of a group web developers. So when looking for a programming language for the microservice, we went searching for a language close to their hearts and expertise. At that time a typical web developer at least had knowledge of PHP and Javascript.
What we’ve noticed during researching various languages is that almost all actions done by the catalog service will boil down to the following paradigm:
- Execute a HTTP call to fetch some JSON
- Transform JSON to a desired output
- Respond with the transformed JSON
Actions that easily can be done in a parallel and asynchronous manner and mainly consists out of transforming JSON from the source to a desired output. The programming language used for the catalog service should hold strong qualifications for those kind of actions.
Another thing to notice is that some functionalities that will be built using the catalog service will result into a high level of concurrent requests. For example the type-ahead functionality will trigger several requests to the catalog service per usage of a user.
To us, PHP and .NET at that time weren’t sufficient enough to us for building the catalog service based on the requirements we’ve set. Eventually we’ve decided to use Node.js which is better suited for the things we are looking for as described earlier. Node.js provides a non-blocking I/O model and being event driven helps us developing a high performance microservice.
The leap to start programming Node.js is relatively small since it basically is Javascript. A language that is familiar for the developers around that time. While Node.js is displaying some new concepts it is relatively easy for a developer to start using it.
The beauty of microservices and the isolation it provides, is that you can choose the best tool for that particular microservice. Not all microservices will be developed using Node.js and Elasticsearch. All kinds of combinations might arise and this is what makes the microservices architecture so flexible.
Even when Node.js or Elasticsearch turns out to be a bad choice for the catalog service it is relatively easy to switch that choice for magic ‘X’ or component ‘Z’. By focussing on creating a solid API the components that are driving that API don’t matter that much. It should do what you ask of it and when it is lacking you just replace it.
Many more headaches to come later this year ;)3 -
Sometimes, certain features don't work in my app if it's uploaded to the production track in Google Play.
It works in debug mode.
It works in release mode.
It works in the internal testing track.
...but it won't work in the production track? Y'know, the one that actually matters? Theoretically, there shouldn't really be a difference if the same exact APK was uploaded to the internal testing and production track, but... idk dude.
As a result, I implemented a secret way to test a feature in the production build (it's an app to remotely control OBS Studio): if the first connection you added is named "yayeet_" and you open the disclaimer, it tests the feature. Luckily, I got some of the stuff figured out, but I just thought the way I had to test it in production was dumb.1 -
Critical bug in production? Sorry, can't fix it right now: We've got a build running with 1 hour of build time left, 8 hours of automatic tests, 3 days of manual testing, and a partridge in a pear tree. Your fix can be in the next release.
-
When you roll out a new system is disaster recovery testing on your roadmap? For example, do you do failover and have users work through a comprehensive test script and have them sign off before going into production?1
-
Just found out our pre-production environment is the qa for another team.
Infra team has recommended to ignore the nomenclature. It's just a name they said. -
When you spend hours in a messy codebase to fix a bug properly and add an integration spec to cover that specific case.
And even you do a round of testing on staging + providing screenshots, there is always someone on the team that will write in your PR, "It works, I tested the change on my machine".
I understand that some people are skeptical but to the point of not trusting integration tests + screeshots/recordings then please test it on staging or production next time because if it works on your machine doesn't mean it will work there ;)2 -
So our software clubs discord bot went rogue and deleted a metric ass ton of messages
This is what I get for testing in production. Fml1 -
Imagine a workplace. A workplace that is planning a local event for tomorrow with deals and a free discount code for those who arrive.
Only thing is: everything is chaos, no one is taking responsibility for the event, no one communicates about changes or how the event is going to be.
Now you get a call off duty. You have to check a discount code that wasn't working. You were to set it up for the event. But apparently they decided to open the doors for the event TODAY. You get a call 5 minutes after the first. "Is it done yet?" NO. Because you have to FIX CODE and deploy changes because they don't have any staging environment, no proper testing environment and (best of all) development mostly connected directly to the production database.
This! This is my job.
I am so fucking mad.
I need courses on how to grow my spine even more and demand what should be fucking law at this point.
Or maybe just leave. I'm the only dev.. 😎4 -
Before I started working, I used to feel like I depended on documentation and the internet a little too much owing to ultra crappy long term memory. After spending some time at my internship going through code written by "professional developers" several years senior to me and trying to write unit tests for it (surprise: the code was in production without having underwent any sort of testing), I feel like the amount of time I spend online reading usage recommendations, alternates for optimisation, best practices for writing clean and descriptive code and all that is a lot more rewarding. Some bad things help you feel good about yourself.
-
evaluating whether i should make it more agile and flexible or just get it slapped into production. always waging war in between proper developer testing vs my own uat testing (of which we as devlopers also need to do)
-
In my first few months of my first dev job, I written this fragile piece of code in, trigger warning, PHP that sent out email reports to my clients. It was a two men team, and we have no clue about TDD or how to do unit testing for such code. We would just run that piece of code manually do send out dummy emails to ensure things were working.
One day the code broke. I was told by my boss to fix it. Spent the entire day trying to fix but couldn't get anything done. Finally at around 7pm my boss came by and asked why is it I couldn't get it fixed. He helped me troubleshoot and fixed it. And subsequently told me "c'mon man you're better than this."
It turns out that he changed a part of a code that was supposed return an array of strings to an array of objects, adding a second attribute that wasn't even in use.
So what that meant is that he changed a piece of working code, to include a property he didn't need, committed and push to production without even manually testing it. AND TALKED SHIT TO ME.
That was the day I learned git blame and began my journey on TDD. -
When I was new developer and accidentally did testing of an important internal business app on what I thought was dev but was actually production... and of course has entered some crude humor as data because it was "dev".1
-
Dealing with government bureaucracy today. Prepare for pure anger.
First of all, what fucking dipshit site does testing and maintenance in production without letting users know? Bitch I'm getting an invalid date error when I use your own stupid date selector and I had to waste the office lady's time asking about it because you couldn't be arsed to either test your shit properly or actually take it down if it's broken. Who made that stupid ass decision and why the fuck did nobody question it. Fuck you.3 -
Level 1 support moron dishing out bad instructions from his flowchart.
Wanted me to edit config files for a production setup, which would've killed shipping for all stations, in the middle of our shipping rush.
Fixed the problem while in the escalation queue for level 2. L2 confirms the fix, and bemoans the shit documentation L1 provided.
If its a business class (mission critical) system, hire decent support staff! You might try testing people for reading/listening comprehension, and then paying them a decent wage! This isn't good for my blood pressure... -
Stupidly tested some sql on development to return results for an admin (see the whole results) and stupidly didn't test the where clause for generic users (only see a subset of data)
To find out on production the where clause was being run because it wasn't a where, it was an 'and' and 'where' was not being used before so made the whole users get the entire results.
My own fault for not testing all use cases. Horrible though.2 -
Only when the latest feature is implemented, the last bugfix and the last workaround are found, the last unit test is written, the latest CI/CD pipeline done, the customer guy does manual testing and acceptance tests on the staging server and let's them pass and a few days later it's pushed to production...
You will be reminded (again) that shitty customers do exist! A customer is the least capable person to tell you what the customer actually wants and is also the least trustworthy person to test the features he requested...
Holy fuck come on! Just test that shit on the staging Server! One Look could have already shown you that that's Not what you expected!
I checked the logs after that and yup you guessed correctly... The said endpoints weren't even used on staging, only on production...1 -
Released the product to customers without realising someone had pre-filled a production test accounted login at the login screen. Obviously it was used for testing purposes and the dev forgot to remove it before committing.
I loled when I found out about it, and some customers started to login and made transactions.
When I checked the commit history... It was under my name :/2 -
So a third-party service that I implemented is going to production and me and the PO were testing that yesterday, didn't see any orders coming in the service backend.. so we send a mail to them.
This morning they respond with saying that they can't have both the test server running and the production server...
What the hell is this... :/3 -
Used to get really mad at the testing team every time before a production deploy. They only tested the developments that same day, and still I wasn't sure they did a good job. Sometimes they asked for an extra "feature", so we entered into speed-coding mode. Got used to it.1
-
Spent a couple of weeks on writing a cronjob which updates a certain value in the application config, and spend the last few months on testing it in different environments to make sure it does not fail in production. Ran the deployment script, and the damn cronjob fails because of ssl certificate on production. fuck me
-
Today is commit right to fucking master because I'm tired of how long this is taking me ...
(also nobody is actually using the service yet so no production is pretty much testing right now)5 -
Leave it to an investing company 'dUe DiLigAnCe' document to list the following requirement:
"Schema of computing infrastructure setups for development, testing, and production"
Ah yes, the highly technical and well-known term of "schema of computing infrastructure"
God I hate business people, so clueless
BRB going to start my own business and make real money. if these neanderthals are top investors, i can be too1 -
Can anyone suggest any websites or resources for a breakdown of how to handle requests for features or handling bugs. Basically, I want some kind of background on best practices for managing the process of receiving a feature request/or bug report from a user to it reaching the dev team, to production/user acceptance testing.5
-
I'm tired. I don't want to do these tests anymore. These vague test scenarios I have to decrypt on my own lest asking business shows signs of weakness. I'm slow to test and going way beyond the hours the client estimated and you folks just accepted. How can I finish this when I get pulled to meetings which I am not the decision maker but I'm supposed to be the technical one to help them decide. In between this testing I get emails to help check on issues I'm not even a part of. Production issues I can understand because those have a feel of critical and priority but if you pull me to that I lose time testing. I'm trying. But I'm truly very slow at this. I'm a slow tester for this set of test cases. I'm hating myself every minute as the hours inch to the deadline which is today. I want to sleep but I want to finish as well. Shitty days of drone work that could have been given to somebody else but I can't say no to because you guys accepted. Someone from management just see please, don't give this to me. But you can't see. You probably don't even understand. They asked, you caved because you can't see the list of tasks and level of detail that comes with each thing they ask. This testing is a ridiculous use of my time but I can't say that to the client. You could have. I want to. I truly want to say "Fuck these tests". I tried to push back. But the client of course reasoned back and it was understandable to ask. To do what's good and what's best. How can I say no to that?! I'm almost depleted. I'll just finish this somehow.
-
Some programmer or QA person somewhere in the world is having a moment of great reflection on the subject of thoroughly testing their code. If not that, then on the subject of a super crappy manager who knew better and pushed to production anyway.
“Then in September this year, nearly three years later, he got a letter from Wells Fargo. "Dear Jose Aguilar," it read, "We made a mistake… we're sorry." It said the decision on his loan modification was based "on a faulty calculation" and his loan "should have been" approved.
"It's just like, 'Are you serious? Are you kidding me?' Like they destroyed my kids' life and my life, and now you want me to – 'We're sorry?'"
https://cbsnews.com/news/... -
A dev decided to overwrite the master branch with his code saying its better. That it fixes the major bugs that all of us couldn't solve.
Against my better judgement of firing him, I decided to test it.
Firing up the testing site, we made test databases to use and we went to house.
In the middle of testing, I noticed the test DBs weren't being changed. While everyone was still testing, I looked at the code. It wasn't made to test on any databases, it was specifically designed for the actual production server.
However the damage was done. In a secret dashboard in the code, someone sent instructions to drop the tables, effectively ruining the production server.
We had the dev go to an offline backup site that only went online every 10 minutes a day to make new backups. So we shut down the production server, setup a maintenance page. I get my ass chewed out again, and we were sitting ducks.
I don't think the dev had enough punishment, so I grabbed his laptop and made a full backup of his data, and locked the SSD in a safe.
I downloaded a Windows 98 and put it on a flash drive. And installed it all on his SSD. The dev is now a proud (pirate) owner of Windows 98.
He came back and started balling on his desk. We all looked at him with a pity, but he deserved it.
I'll give him the drive on Monday.
Do you think he learned his lesson?7 -
As part of a technical test, I've been asked to test and report bugs in the production application of the company. Is that normal? Or are they making me do free work for them?.
So far I've only seen challenges like this to be done on a custom application for test.7 -
Have some questions to testing.
Right now we are at the production end for first version. So far it was said to use Selenium IDE for Browser side testing, which was barely possible for the size of the website...
Is there other software or are there concepts I can read and inform myself to get into that point to teach myself properly?
The project is a business Website with Work flow system. Php backend and Database with a few procedures and zend framework for browser side.7 -
actually it wasn't mine. But it affected me. So we had a project website on wordpress and wanted to rewrite the theme. everything went well to the Point of production. Site is fine locally, at testing and on stage. On production we still see old, a bit broken old version, but only on homepage. Wtf. Nothing helped. After couple of hours later we found out, that the admin was updating php version and he left html shot at production, which was taking over.
-
Who inside BitTitan is doing live testing on production? Would you kindly revert the changes and do testing on a test environment? I've seen the 4 changes so far and they clearly not working.
Please we need to finish this migration 2
2 -
Testing new server deployment in test env all works, then production it all breaks down. Network didn't allowed the right traffic. Took me whole week to find that out. Until some networking engineer said, you know there is a firewall between those networks?
-
I had a client with an ongoing project. Everything was going fine until her boy-asshole-friend talked to me by phone... He was so ignorant.
Don't get me wrong. I'm not talking about the ignorant who doesn't know anything. I'm talking about the ignorant who doesn't know a shit but he is talking about it and refuses to get a professional advice. He told me explicitly: "Don't use test server for testing your project. Do it directly on production"
Unnecessary to say that my client "suspended" the project.1 -
Sure boss, we don't need staging. Let's just copy some tables from our customer's server to our testing machine, overwrite our data with theirs and start testing "simulating" their environment. It's not that we need to test for our production, right?
-
Google play console is so fucking confusing, I'm trying to get my app to open beta testing stage, I've completed all the steps and done the full roll out, but the status of the app is still pending publication (3 days), wtf does "Pending publication" means do I need to publish the app for production in order for beta testing release to work, or I have to wait for google to approve the beta release for publish?
I'm lost5 -
Quick question for you all: How do you deal with a problem in production that you cannot fix, even over an extended period of time (say 2 months)?
For context I feel like I’m losing my sanity here, we’ve had this problem on our production API since the beginning of March this year. I’ve done so much testing, got in contact with various teams of my company to try to figure out any potential candidate that would explain the bug, but none worked out. No need to say I’ve spent a considerable amount of time searching on the internet for others with the same problem or similar… We’ve even opened a ticket with the cloud host to see if they would have more details about the problem without success. So how do you deal with that ?5 -
Sometimes I deploy to production without actually testing the changes. At least I have my unit tests!
-
The 5 step process to my average day:
1. Client doesn't want to pay for an admin dashboard that can be tested
2. Client wants to us to make ad hoc changes to the data in the production database
3. Client wants things done quickly without testing
4. Client complains when things go wrong
5. Me: (╯°□°)╯︵ ┻━┻2 -
Working on a security testing tool that's purpose and use has been overstated by the staff engineer and product owner but no team wants to use it and everyone else in security second guesses if it should exist. Oh, also no documentation on how to use it, and you have to figure out how to use it. The tool has been developed and passed down from multiple people who each developed it differently and have all left the company now. No code reviews exactly exist so every functionality has been assumed to work my PO, SM and Staff Engineer, thus questioned when you bring up something that you're not sure works. Constantly redeploying to production at a timezone that's too early for your country but done to proviide minimal damage to the application for customers in case something goes wrong.
Upside is, you're leaving the team in a week and feel sorry for whoever is going to handle this next. -
A young new dev was working on his first ticket, about a bug during parsing of an uploaded excel file. Our issue was that if the file contained an empty line, all remaining rows were ignored. So the task included extending our tests to cover this case. After 2 weeks (!), his merge request comes in. His idea (without ever asking for help) was to parse the whole file (in some cases huge) in the production code a second time, just to count the rows (!!) and save the count in a public static int field, which was verified in his new test.2
-
Handling null like null is to be handled in production. And in current times null is good news (The app is of one of the most important german newspapers)

-
In my initial days as a web developer, i was assigned a task, to implement a cart share functionality in an e commerce company.
I made the functionality and tested on my system.
Result: working good.
Pushed it to beta testing environment.
Resilt: working good.
Pushed to pre production environment.
Result: working good.
Pushed to live site.
Result: 😀 Error in live site..
So a call comes to me from my team lead..
Asks what was the issue...
Me: i dont know either.
....
After 3-4 hrs:
I found the reason.
My system, beta test env, pre prod env are all having latest php version (5.6 i guess)
But the live server had old version of php.
Me: laughed like anything.
I didn't know that these things would matter in such a great level.
Moral of the story:
Be one with the force (server in this case)2 -
IOS 13 for my Ipad broke its battery indicator it's been stuck at 59% for the entire day. Just really hope it doesn't give up the ghost during the day...1
-
One nightmarish project that was doomed from the beginning, had me as the sole developer. I could hardly sleep when we began testing on a separate test system, but with (nearly) all the config stored in shared memory and copied from the production system, I dreaded, half awake, that the production server data base connection was still configured in the test system and that it was shooting all it's test data repeatedly to prod.
Finally drove to company in middle of the night at 4 o'clock. Checked everything was OK, tried to sleep 3 hours before the start of the work day.
This system also had the most hideous memory corruption in some shared memory that was used across several processes and should have been thoroughly protected by a mutex, but somehow, sometimes this crucial map, that was used to speed up the access to all the customer data just contained garbage.
Still haunts me to that day. (Like xkcd's unresolved tension of a non-matching parenthesis - an unresolved bug. -
It's almost all the time but specially when there is a stupid bug i find out in production after all the efford i put on testing before release, or even worst, when the bug is not stupid, is random and just hard to tell why the fuck everything is fucked up
-
Well Taken Care Of™: Empowering Women Through Perimenopause and Menopause in Needham, MA
At Well Taken Care Of™, we understand that navigating the journey of perimenopause and menopause can be challenging. These natural life stages can bring about significant physical and emotional changes, and it’s crucial to have the right support system in place. Our team is committed to helping women in Needham, MA, and beyond manage and thrive during this transition with personalized care, expert guidance, and a holistic approach to health and wellness.
Located at 140 Gould St, Needham, MA 02494, Well Taken Care Of™ offers comprehensive services to support women through perimenopause and menopause. Whether you are just beginning to experience symptoms or have already entered menopause, we are here to provide the tools and resources you need to navigate this phase of life with confidence and ease.
Understanding Perimenopause and Menopause
Perimenopause and menopause are natural biological phases in every woman’s life, but they can bring about a range of physical, emotional, and mental changes. Here’s a closer look at each stage:
Perimenopause: This is the transitional phase leading up to menopause, typically beginning in a woman’s 40s, although it can start earlier. During perimenopause, the ovaries gradually produce less estrogen, leading to fluctuations in hormone levels. This phase can last anywhere from 4 to 10 years, and women may experience symptoms such as irregular periods, hot flashes, night sweats, mood swings, sleep disturbances, and changes in skin or hair.
Menopause: Menopause is officially diagnosed when a woman has gone 12 consecutive months without a menstrual period. This phase marks the end of a woman’s reproductive years and is associated with a significant decrease in estrogen production. Symptoms can include hot flashes, weight gain, vaginal dryness, low libido, fatigue, and changes in mood.
While these changes are natural, they can affect a woman’s quality of life. Fortunately, at Well Taken Care Of™, we are dedicated to helping women manage these transitions and improve their overall well-being.
How Well Taken Care Of™ Can Support You Through Perimenopause and Menopause
At Well Taken Care Of™, we take a holistic approach to women’s health, providing support through nutrition, lifestyle adjustments, and functional medicine. Our goal is to help you find balance during perimenopause and menopause and empower you to live a vibrant, healthy life.
1. Personalized Nutrition Plans
Hormonal fluctuations during perimenopause and menopause can lead to weight gain, fatigue, and other physical changes. Our nutritionists can help you create a balanced, sustainable diet that supports your body’s needs during this time. This may include:
Hormone-balancing foods: Certain foods can support hormonal balance and reduce symptoms like hot flashes. We’ll guide you on including nutrient-dense foods that promote estrogen production, such as flaxseeds, tofu, and leafy greens.
Anti-inflammatory diet: Inflammation can worsen symptoms of menopause, such as joint pain and mood swings. We’ll help you incorporate anti-inflammatory foods like berries, nuts, and fatty fish to reduce discomfort.
Blood sugar regulation: Many women experience blood sugar imbalances during menopause, leading to weight gain and fatigue. Our nutritionists will provide meal plans that keep your blood sugar levels stable throughout the day.
2. Functional Medicine Approach
Functional medicine focuses on identifying and addressing the root causes of health issues. At Well Taken Care Of™, we use functional medicine to assess and address hormonal imbalances, digestive health, and inflammation—all of which can be exacerbated during perimenopause and menopause.
We offer personalized treatment plans that may include:
Hormone testing: We can test your hormone levels to understand your unique needs and help identify any imbalances that may be contributing to symptoms.
Herbal and supplement support: Based on your individual needs, we may recommend supplements such as magnesium, vitamin D, and phytoestrogens to help support hormone balance and reduce symptoms like hot flashes and mood swings.
Gut health support: Hormonal changes can impact gut health, leading to bloating and digestive discomfort. We provide dietary and supplement recommendations to improve digestion and support a healthy gut microbiome.
3. Lifestyle Coaching and Stress Management
Stress can exacerbate many symptoms of perimenopause and menopause, including anxiety, sleep disturbances, and hot flashes. Our health coaches can help you incorporate relaxation techniques, such as:
Mindfulness and meditation: These practices can reduce stress, improve sleep, and support emotional well-being during this transition.
Breathing exercises: Deep breathing exercises can help alleviate symptoms like hot flashes and anxiety. 6
6 -
I really got to stop having near-blind faith in the project dependency management and the testing skills of people with multiple years of experience.
Production code of a new client uses a fixed 0.x.y version of a third-party library for over a year for a functionality that was only working stably a few major versions later... And somehow nobody ever noticed due to insufficient testing






























































































































































































































































































Top Tags
Weekly Rant
View