
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Friend: "What is devRant?"
Me: "A place where programmers tell jokes and complain."
Friend: "Why dont you just do that irl?"
Me: "Because we never test in production"13 -
I worked with a good dev at one of my previous jobs, but one of his faults was that he was a bit scattered and would sometimes forget things.
The story goes that one day we had this massive bug on our web app and we had a large portion of our dev team trying to figure it out. We thought we narrowed down the issue to a very specific part of the code, but something weird happened. No matter how often we looked at the piece of code where we all knew the problem had to be, no one could see any problem with it. And there want anything close to explaining how we could be seeing the issue we were in production.
We spent hours going through this. It was driving everyone crazy. All of a sudden, my co-worker (one referenced above) gasps “oh shit.” And we’re all like, what’s up? He proceeds to tell us that he thinks he might have been testing a line of code on one of our prod servers and left it in there by accident and never committed it into the actual codebase. Just to explain this - we had a great deploy process at this company but every so often a dev would need to test something quickly on a prod machine so we’d allow it as long as they did it and removed it quickly. It was meant for being for a select few tasks that required a prod server and was just going to be a single line to test something. Bad practice, but was fine because everyone had been extremely careful with it.
Until this guy came along. After he said he thought he might have left a line change in the code on a prod server, we had to manually go in to 12 web servers and check. Eventually, we found the one that had the change and finally, the issue at hand made sense. We never thought for a second that the committed code in the git repo that we were looking at would be inaccurate.
Needless to say, he was never allowed to touch code on a prod server ever again.8 -
Everyone has a test environment. If you're lucky, you'll have a separate production environment too.4
-
So I'm working on a live map of my school's bus system, and I needed some filler images to test out how the stops were being drawn on each route...and honestly wish I could push this version to production
 11
11 -
Customer :Can you build a system that rates our product by XYZ standard?
Us: Sure!
*time passes*
Us: Ta-da!
Customer: Okay, here are some good and some bad products!
*products get rated shit to supershit*
Customer: No, that's wrong. Some of these are as good as we can, they should be rated best!
Us: okay, we offset the results.
*products get rated good to barely okay*
Customer: Great! Can you sign that the system rates by XYZ Standard?
Us: No.
Customer : But we paid you to rate by XYZ standard!
Us: By XYZ standard your products are bad, you can either have your products rated by standard or pass the test.
Customer: Unacceptable!
Us: Improve production?
Customer : Not possible, the job is done when you rate the products good by XYZ standard.7 -
A more experienced friend told me
"don't be a pussy, test in production"
I'm the one fixing the bugs, not him 8
8 -
Hey, Root? How do you test your slow query ticket, again? I didn't bother reading the giant green "Testing notes:" box on the ticket. Yeah, could you explain it while I don't bother to listen and talk over you? Thanks.
And later:
Hey Root. I'm the DBA. Could you explain exactly what you're doing in this ticket, because i can't understand it. What are these new columns? Where is the new query? What are you doing? And why? Oh, the ticket? Yeah, I didn't bother to read it. There was too much text filled with things like implementation details, query optimization findings, overall benchmarking results, the purpose of the new columns, and i just couldn't care enough to read any of that. Yeah, I also don't know how to find the query it's running now. Yep, have complete access to the console and DB and query log. Still can't figure it out.
And later:
Hey Root. We pulled your urgent fix ticket from the release. You know, the one that SysOps and Data and even execs have been demanding? The one you finished three months ago? Yep, the problem is still taking down production every week or so, but we just can't verify that your fix is good enough. Even though the changes are pretty minimal, you've said it's 8x faster, and provided benchmark findings, we just ... don't know how to get the query it's running out of the code. or how check the query logs to find it. So. we just don't know if it's good enough.
Also, we goofed up when deploying and the testing database is gone, so now we can't test it since there are no records. Nevermind that you provided snippets to remedy exactly scenario in the ticket description you wrote three months ago.
And later:
Hey Root: Why did you take so long on this ticket? It has sat for so long now that someone else filed a ticket for it, with investigation findings. You know it's bringing down production, and it's kind of urgent. Maybe you should have prioritized it more, or written up better notes. You really need to communicate better. This is why we can't trust you to get things out.
*twitchy smile*19 -
FML. An overreaching supergenius "architect" and a database team:
A: "We have decided that apps should use mysql. Install a MySQL so we match cloud"
DBA: "we don't have an image or experience with MySQL. We have mssql and Oracle "
A: "ok, use mssql in data center and mysql in production cloud"
DBA: "that's... not going to work well"
A: "just do it!"
...
Me, reading this shit, sends email: "ignoring the fact that we have more than 500 queries in this application which will need to be checked and most likely rewritten, how are we supposed to test the mysql queries without production access?"
A: "just use mssql local and MySQL in cloud"
M: "... Just to make sure I understand, you want us to write queries for mssql, test them locally, and then write separate queries, with a separate SQL connection abstraction that deploys to production? Again, how are we going to test this?"
A: "no, use same queries, should be fine"
M: "they really won't, they're different dialects"
A: "do the needful, make work!"
If karma were a thing, this person would have long since exploded into a cloud of atomized blood.18 -
Interview (first job):
Interviewer: So what languages do you know?
Me: Well, i learnd C, C++ and Matlab scripting, but i'm learning C# as a personal project.
Interviewer: Perfect!
First day:
Interviewer(now boss): So, a guy is leaving next week and you will be replacing him. He has 70 projects and you will be responsible for this production test platform in JAVA11 -
Confession of the day:
1. I work in release mode
2. I work on the main branch only
3. I test on production13 -
Every company has a test environment. Some are lucky enough, to also have a production environment3
-
I am fucking dying of laughter right now. 😁
Today I got a push message of the invoicing app I use from time to time and the message literally just said "lol" (without even the usual pre-fix of the app name or anything).
So after not figuring out where that could have come from and obviously theres no private messaging etc. in that app, I contacted support and they reacted surprisingly good and at same time hilariously good; they pushed now a team towards investigating that, as apparently I wasn't the only one.
https://support.waveapps.com/hc/...
I wonder who fucked up and literally pushed "lol" to thousands of people. 😂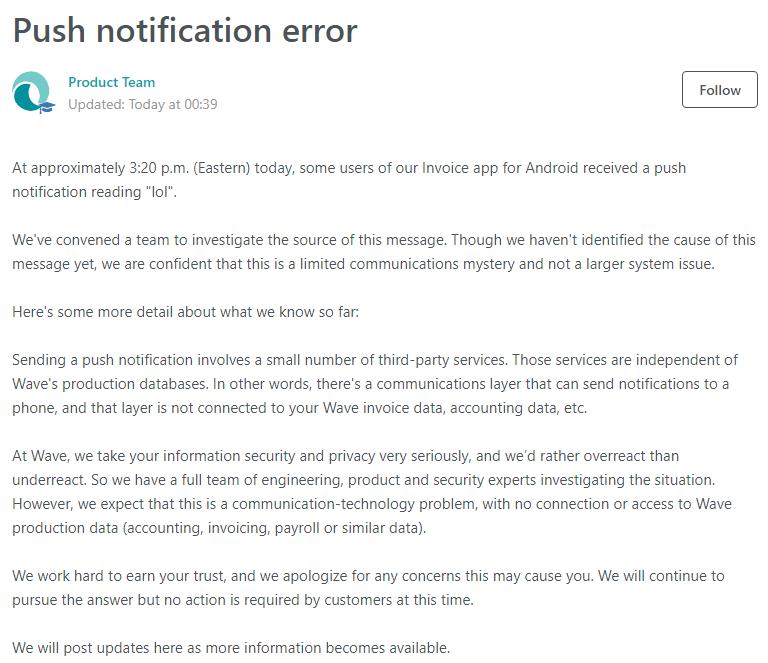 8
8 -
So Facebook declared millions of people dead ... I guess that's what happens when you test in production7
-
Guess who just pushed a whole week's work straight into production without a single damn test and everything works fine?😎😎😎19
-
IF LIVES DEPEND ON A SYSTEM
1. Code review, collaboration, and knowledge sharing (each hour of code review saves 33 hours of maintenance)
2. TDD (40% — 80% reduction in production bug density)
3. Daily continuous integration (large code merges are a major source of bugs)
4. Minimize developer interruptions (an interrupted task takes twice as long and contains twice as many defects)
5. Linting (catches many typo and undefined variable bugs that static types could catch, as well as a host of stylistic issues that correlate with bug creation, such as accidentally assigning when you meant to compare)
6. Reduce complexity & improve modularity -- complex code is harder to understand, test, and maintain
-Eric Elliott12 -
My boss last week backed me up with a client. I was working in a production enviorment and the client refused to test the changes made when I told them. So we things started to go wrong and they called to my boss complaning.
He said:
Well you are right. The things are broken but he (me) stayed last night waiting for your response and you didn't gave one. So he is going to work only in the afternoon and you will have to wait.
I must buy a beer for my boss.2 -
!dev I'd just helped a client cut over to a new fiber connection and then left for Vegas, about 2 days into the trip my wife and I decided to hit a breakfast spot that had bottomless mimosa's, which was of course a claim we had to test.
As we are walking(stumbling) out of the restaurant I get a call that the connection has crashed and the entire car dealership is unable to sell cars, which they tell me is important functionality.
So I make it up to my room and break out the laptop, luckily the mgmt interfaces are still available externally so I'm able to log in and then have the fun challenge of 1) not falling off of my chair 2) not accidentally making a change that kills what connection I have in and 3) fixing their actual issue.
Took me almost an hour to find a simple OSPF issue but at least got them working and happy. However by that time I was beginning to sober up, which is the absolute worst thing that can happen while day-drinking and ended up basically causing me to be be hung-over for the rest of the night, including my wifes friends wedding, which she wasn't thrilled about...
The moral of this story is to make sure to NOT stop drinking while dealing with unexpected production impacting events.1 -
I extracted a tangled action to its own api, and wrote a test for it.
The test failed.
I added debugging, more debugging, all the debugging. It still fails. But I can at least see why it fails!
It turns out the api finds and updates the wrong user. It finds and updates the wrong user EVEN WHEN THERE ARE NO OTHER USERS.
WHAT THE SALAMI.
Also, the user lookup it uses is extremely roundabout and takes several seconds with ~2 million users. Normally I'd fix the lookup, but it has been in production for several years, and I'm terrified it will break something if I fix it.
Blargherhagrid.7 -
Some years back I was working in a project that essentially dealt with all things related to foreigners and foreign affairs in Switzerland. You could manage entry visas, work permits, citizenship, international warrants, Interpol requests, etc.
One of the test managers (from client side - i.e. the government) was once manually "testing" and mixed up the production and test instance, to both of which he was logged in at the time.
The test case then ended up setting up an entry ban against himself, as he used his own name for testing...
Next time he returned from vacation the border control at the airport were like "Uhm, Sir, we can't let you into the country. Please come with us." :D :D
(He managed to clear that up in end, I dare say, though, that he learned his lesson.)4 -
So we hired an intern and his first task was to change a few things in email layout for our client, which is an investment bank.
I told to one of my developers to make his local database dump and setup the project for an intern. When intern completed the task, my developer thought that title "Dow Jones index crashed" was pretty funny title for a test.
What he didn't thought through enough, is that he forgot to configure fake SMTP server and he had production database dump with real email addresses.
I had really awkward 20 minutes conversation with our client. Fuck my life.4 -
I started this new freelance project where I am building some android libraries for the client. Anyways, during meeting I was about to present my results and suddenly backend seemed to be down. I looked into the round "are your servers down?"
Team Lead: "Yeah our cto, also our only backend dev, is developing a new feature."
Me: "Okay but why is production down?",
Team Lead: "Ah dont worry we always test on production. We have a pretty solid hardware, we will even upgrade it soon!"
Me:"... How about you just separate your stage environments and have a develop environment?"
Client: "see, this is where our strength is. We dont need a develop stage we have very strong hardware and our backend is fully in PHP"
Thanks God I'm a freelancer3 -
A few days after deploying a big important Website into production, I wanted to copy the whole thing including DB back onto our test server for future testing/bug fixing if something comes up. (Last changes were done on production server before going live)
So I opened SSH, removed everything on the test sever aaaaand then I realized I was connected to production...
Took about an hour to get everything up and running again. We didn't tell the client and hoped it would not be noticed.2 -
I was only seventeen back then and I was a Java Developer Intern, not knowing much about enterprise oriented coding.
The project leader in our dev team saw a lot of potential and passion in my work, but was convinced I wasn't taught enough to do the right thing.
I was mainly doing shitty mappers and services back then, which were somewhat used but never lasted long and were ditched a few months later, which always bummed me out. I wanted to make an impact on REAL projects that would deploy into production.
So Mister Mentor (GDPR forbid to use the actual name), who was always first to come and last to leave the office, taught me what it means to code for real.
We stayed after 5pm until 7-8pm multiple times a week and he taught me in a deeply understanding and calm way how to:
- Git (SVN)
- Refactor
- SOA
- Annotate
- Deploy
- Unit Test
And most importantly:
- How to debug like an absolute BOSS
(We even debugged native Java Libraries just for fun to see if we could break them)
Fast-forward a month later and little intern me made his first commit on production.
Without Mister Mentor, I wouldn't be half as good of a developer as I am today.3 -
I worked for over 13 hours yesterday on super-urgent projects. I got so much done it's insane.
Projects:
1) the printer auto-configuration script.
2) changing Stripe from test mode to live mode in production
3) website responsiveness
I finished two within five minutes and pushed to both QA and Production. actually urgent, actually necessary. Easy change.
The printer auto-configure script was honestly fun to write, if very involved. However, the APIs I needed to call to fetch data, create a printer client, etc... none of them were tested, and they were _all_ broken in at least two ways. The CTO (api guy in my previous rant) was slow at fixing them, so getting the APIs working took literally four hours. One of them (test print) still doesn't work.
Responsiveness... this was my first time making a website responsive. Ever. Also, one of the pages I needed to style was very complicated (nested fixed-aspect-ratio + flexbox); I ended up duplicating the markup and hacking the styling together just to make it work. The code is horrible. But! "Friday's the day! it's going live and we're pushing traffic to it!" So, I invested a lot of time and energy into making it ready and as pretty as I could, and finally got it working. That page alone took me two hours.
The site and the printer script (and obv the Stripe change as well) absolutely needed to be done by this morning. Super important.
well.
1) Auto-configure script. Ostensibly we would have an intern come in and configure the printers. However, we have no printers that need configuring, so she did marketing instead. :/ Also, the docs Epson sent us only work for the T88V printer (we have exactly one, which we happened to set up and connect to). They do not work for the T88VI printers, which is what we ordered. and all we'll ever be ordering. So. :/ I'll need to rewrite a large chunk of my code to make this work. Joy :/
2) Stripe Live mode. Nobody even seemed to notice that we were collecting info in Test mode, or that I fixed it. so. um. :/
3) Responsiveness.
Well. That deadline is actually next Wednesday. The marketing won't even start until then, and I haven't even been given the final changes yet (like come on). Also! I asked for a QA review last night before I'd push it to production. One person glanced at it. Nobody else cared. Nobody else cared enough to look in the morning, either, so it's still on QA. Super-important deadline indeed. :/
Honestly?
I feel like Alice (from Dilbert) after she worked frantically on urgent projects that ended up just being cancelled. (That one where Wally smells that lovely buttery-popcorn scent of unnecessary work.)
I worked 13 hours yesterday.
for nothing.
fucking. hell.7 -
I have to start my best moment last year with a confession: I moved from Dev to Test half a decade ago. Naturally I do a lot of automation. My Best moment was when Dev said my automation code is so well structured that he wants to work on that and not an the production code anymore. Gave me that warm "still got it" feeling 😊2
-
#9
Of course they don't use git. And also they don't use SSH all changes get committed by FTP.
#9.1
When I started he gave me root access and I had to clone the whole fucking thing, wich was about 2gb, via FTP.
#9.2
He stumbled when I told him, that I will test all changes first on my local machine. They were used to work in production.
😓🔨11 -
Data Analyst: “the task failed in test, can we try running it in production?”
My life as a Data Engineer.5 -
Soooo, i'm assigned to finish a half made prototype of a production line functional test platform.
1 - Some wires were faulty so someone decided to change them.
2 - wild shortcut appears *music fades, screen goes black*
3 - now i have to fix the prototype
4 - Devil's voice whispers on my ear *welcome to heeeeellllllll* 22
22 -
[3:18 AM] Me: Heya team, I fixed X, tested it and pushed to production. Lemme know what you think when you wake up.
[6:30 AM] Me: Yo, I just checked X and everything is peachy. Let me know if it works on your end.
[9:14] Colleague A: Whoop! Yeah! Awesome!
[9:15] Boss: Nice.
[9:30] A: X doesn't work for me.
Me: OK, did you do M as I told you.
A: yes
Me: *checks logs and database, finds no trace of M*
Me: A, you sure you did M on production? Send me a sreenshot plz.
A: yeah, I'm sure it's on production.
Me: *opens sreenshot, gets slapped in the face by https://staging.app.xyz*
Me: A, that's staging, you need to test it on production.
A: right, OK.
[10:46] A: works, yeah! Awesome, whoop!
[10:47] Boss: Nice.
Me: Ok! A, thanks for testing...
Me: *... and wasting my time*.
[10:47:23] Boss: Yo, did you fix Y?
Courageous/snarky me: *Hey boss, see, I knew you'd ask this right after I fixed X knowing that I could not have done anything else while troubleshooting A's testing snafu since you said 'Nice' twice. So, yesterday, I cloned myself and put me to work in parallel on Y on order fulfill your unreasonable expectations come morning.*
Real me: No, that's planned for tomorrow. -
Old boss story. This guy was nice but a terrible boss. Also relevant, he has a background in IT so should know better.
Him: So when you wanna check a password is correct you just unhash it in the database?
Me: *facepalm*
Me: Hey we should be doing unit and integration testing at a minimum to lower bugs.
Him: We don't need those, we're not a bank. If a problem comes up we just fix it and push to production.
(A while later)
Him(in email): Why do we keep getting bugs reported. Don't you devs test your code.
I was mildly annoyed at that one.
Him: We're always over budget on projects, how can we fix this.
Me: What if we increase our quotes.(technically there are other ways as well but not really possible at that time)
Him: We can't do that, clients won't want to pay.
Me: *finishing off my handover as I'm leaving for a new job*
Him: Wow you do a lot of work2 -
Fixing someone else's code who left the job.
Production suddenly not working, cannot debug locally, cannot deploy to a test environment because it does not exists anymore.
There should be a contract clause that developer need to support his project for 2 years after he leaves his job.9 -
If any of you guys is (or was until recently) a developer for Smappee, the payload message test was a success
 1
1 -
I built our slack bot messages so that they are prefixed in BIG LETTERS with whatever system they originate from, i.e.:
"DEVELOP: You are a useless product manager"
"STAGING: You are a useless product manager"
"PRODUCTION: You are a useless product manager"
One of these is when a payment is made on our platform. Our lovely product manager proceeds to message me, "did you just trigger a payment in the test system?".
YES, OBVIOUSLY I DID SEEING AS THE MESSAGE HAS THE GIANT WORD "STAGING" IN FRONT OF IT!!!
https://lmgtfy.app/?q=how+to+read1 -
We have 2 layers of testing environments and production.
I tested the changes on the 1st layer, bud since it was 5min to lunch i did not test on 2nd layer which is connected to the production DB. I pushed to production and caused 5+ websites to go full retard and went to lunch.
Came back to 19emails and 3+ skype msgs about "why the fck would you do that..."
Estimated damages nearly 20k EUR and i lost some permissions for two weeks, but my great boss helped me out and cheered me up by telling stories how he took down multiple servers too
plot twist: im the team leader of our office now :)5 -
Never ever have a tab open on production server database. Changed all users passwords by mistake. Thought was my test database.2
-
I have to refactor code from an intern. He's VERY lucky that he already left the company.
If I'd say he programms like the first human that would be very insulting to that first human.
It looks like code at first sight, but when you try to understand what he was doing to achieve his goal you get a brainfuck. Duplicate code, unused code, dumb variable names like blRszN.
He wrote unittests like "expects Exception to be thrown or Server returns Statuscode 500".
Yes, Exception, the generic one.
THESE FUCKING TESTS ARE GREEN BECAUSE YOU DID NOT ACTUALLY TEST SOMETHING.
GREEN IN THIS CONTEXT MEANS: YOUR PRODUCTION CODE IS A BIG PILE OF SHIT.
I already removed 2 bugs in a test which caused another exception than the "expected" one and the test does still not reach the actual method under test.
Dumb fucktard.
The sad thing: The fuckers who did the code reviews and let this shit pass are still here writing code.4 -
Aaaah, I fucking love it to death, when customers spontaneously decide to hire a separate, unrelated company to add new content pages to the website developed by our company.
That furuncle of a company must have had real pro devs to just create a new /html folder, dump their shit content in there and just manually add links in the existing CMS pages.
HOLY FUCK!
As you might already have expected, the /html folder contains:
- static *.html files for every page
- inline CSS in the *.html
- the crappiest PHP mailing script I have ever witnessed
- images with random resolutions, mostly too small
The layout of these puke-ridden pages obviously doesn't fit neither the existing color palette, nor has anything common with the current layout or typography at all.
These bastards don't even use Git!
Come on, dear customer, could you PLEASE fucking NOT hire a completely separate company to do OUR job?
PLEASE? PLEASE?!
I had to compare the whole deployment folder with our repo to find out what else these brain-damaged cunts changed in our code!3 -
So, a few years ago I was working at a small state government department. After we has suffered a major development infrastructure outage (another story), I was so outspoken about what a shitty job the infrastructure vendor was doing, the IT Director put me in charge of managing the environment and the vendor, even though I was actually a software architect.
Anyway, a year later, we get a new project manager, and she decides that she needs to bring in a new team of contract developers because she doesn't trust us incumbents.
They develop a new application, but won't use our test team, insisting that their "BA" can do the testing themselves.
Finally it goes into production.
And crashes on Day 1. And keeps crashing.
Its the infrastructure goes out the cry from her office, do something about it!
I check the logs, can find nothing wrong, just this application keeps crashing.
I and another dev ask for the source code so that we can see if we can help find their bug, but we are told in no uncertain terms that there is no bug, they don't need any help, and we must focus on fixing the hardware issue.
After a couple of days of this, she called a meeting, all the PMs, the whole of the other project team, and me and my mate. And she starts laying into us about how we are letting them all down.
We insist that they have a bug, they insist that they can't have a bug because "it's been tested".
This ends up in a shouting match when my mate lost his cool with her.
So, we went back to our desks, got the exe and the pdb files (yes, they had published debug info to production), and reverse engineered it back to C# source, and then started looking through it.
Around midnight, we spotted the bug.
We took it to them the next morning, and it was like "Oh". When we asked how they could have tested it, they said, ah, well, we didn't actually test that function as we didn't think it would be used much....
What happened after that?
Not a happy ending. Six months later the IT Director retires and she gets shoed in as the new IT Director and then starts a bullying campaign against the two of us until we quit.5 -
Hiring process is fucking broken ok?
We all do have something else to do, nobody wants to do "homework" for 4 fucking hours. Which let's be real, isn't 4 hours. It's always more. I try to squeeze it in a least amount of time which means mistakes will be made. I always try to show my knowledge of the language and it's features. But, you didn't do X. That's it, that is a no from us.
Dude, I just wrote a high production grade small project with 90%+ test coverage and you are telling me that those 2 small shit I made is a big deal? Fuck off
Most companies I worked with have a code full of shit and here I present to you, with a poetry and it's a no because of X?
My bet is that if I ever started to work there I would find a code that isn't tested and is in shit state
\rant4 -
Just got this notification. I see virgin active UK likes to test in production. I too like to live dangerously.
 1
1 -
Friend of mine: so I wonder how do you test your applications in the startup?
Me: testing? *grabs his coffee laughing*
Actually we have a complete build pipeline from commit/pull-request to dev and production environments. No tests. Really. We are in rapid product development / research state.
We change technologies and approaches like our underwear (and yeah, this is frequently). If we settled some day and understood the basic problems of the whole feature palette, we'll talk about tests again.3 -
It's about a guy that knows better.
I was working as a subcontractor on a bigger system. We (subs) were not allowed to deploy code, we had to wait for contractor to deploy.
One day I got an email that my code is bugged and that my feature is not working on production. I checked it on test env, everything was fine. Then I checked if the code I wrote was deployed. It was not.
I send an email explaining that if they deployed my code it would be working. Then I got a response. There was a bug in my code.
Another email. I asked how would they know? Do they have a test on their environment that failed?
No. There is one guy that READ my code and he said it should not work, so he will not deploy it. He was not a programmer, he was a business consultant responsible for the documentation.
His issue was that I used a function that was not in a class. So if the function is not declared it's obvious it will not work. I had to explain to him in another email, that you can use object of another class inside your class and then call a function, that is not in your class. It was the last time this guy blocked my deploy.
TL;DR, I had to explain a non-dev how object composition works in order to have my code deployed. Took four emails.4 -
Me: We really need to improve our unit test coverage.
Team/Boss: <sarcasm> Haha yeah.
Production Bug: I'm doing something nasty to a client, because a dev broke something but no test coverage.
Boss: How could we have prevented this?!1 -
I hate it when I ask the customer where did they test it or where the error is.. On test or on production? And the answer is yes. O.o2
-
When you test your backend code thoroughly before pushing to production, but a fatal exception with the much larger production userbase causes one of your vital threads to die with a NullPointerException.
 6
6 -
Wow i must have been brain dead when i wrote this code. Needed to exclude certain elements from response for the the list of objects.
for (obj : objects) {
If (obj.skipFromResponse()) {
break
}
add obj to response
}
I used break instead of continue at the if condition which meant it would break out of the loop at the first instance of condition being met.
This went through qa and has been in production for 4 weeks so how did this not break before. Well little did i know the list of objects was sorted and all the test data, qa data and everything so far in production coincidentally only had the last element with matching condition. This meant it returned everything correctly so far.
Today was the first time there was a situation where this caused incorrect output. Luckily as soon as I heard the description of the issue I remembered to check the merged PR and hung my head in shame for making such trivial error. I must have written way more complicated code without any problem but this made me embarrassed to even admit. 🤦♂️4 -
Let me tell you the story of how a feature request no one asked for got put in an early grave:
PM walks into weekly meeting with a single use case that one user called in about, despite never having this issue during the past year and a half that our app has been in production. PM's boss (genuinely one of the best people i have ever worked with) happens to sit in this particular meeting for no reason other than he felt like he should once in a while.
PM brings up use case and wants to devote 3 weeks' development time and another 3 weeks to test RIGHT NOW while other projects are already in motion. PM's boss speaks up with this: "Listen if this guy is really this upset, we can just tell him to build his own service. All the other end users have no problems with this, so it's not worth spending the resources on, i don't think."
And that is how i went from "this is bullshit" to "i love you" in the span of 20 minutes.2 -
So, to anyone defending IBM at this point, a member of a client's offshore team used their paystub as test data. Aaaaand I was horrified by what I saw.
Their pay is less than $2/hr ($3973/yr, 300k INR).
I can't even. Not only that someone would pay so little to a supposedly degreed professional (I question the validity of that claim based on performance, that's a story for another time), but that companies feel comfortable giving full production system access to people I would not blame for taking bribes.
Fuck.14 -
Half way through a 2 hour deployment, and a fucking test fails.
Yes, it takes 2+hours to run the tests.
Rerun in test environment: pass
Rerun in prod: pass
Rerun changed test in prod: fail..
Why, why you got to hate me for?
I love it when production is the place where config gets changed.5 -
Typos kill, kids! And deploying to production.
Instead of "for item in items" in my script, I accidentally did "for items in items". Thus, an exponential loop has been entering things into the database for the past few hours before I found the place to fix it.
By the way, this runs on cron every minute. So there are processes still running exponentially right now, possibly 180+.
Yeah, I'm setting up a a test server instead now.11 -
We started a project in January for which I was the sole developer, to automate tedious interaction with a vendor's ticketing system. We have a storage environment with about 400,000 commodity disks attached(for this vendor-- there are other vendors too), in sites around the US and Canada. With a weekly failure rate of about 0.0005%, that means about 200 disks a week need to be replaced.
This work-- hardware investigation through storage appliance frontends, internal ticket creation, external ticket creation, watching the external ticket for updates to include in our internal ticket --was all manual, and for around 200 issues a week, it was done by one guy for two years. He was hopelessly behind. This is all automated now, and this morning, I pushed this automation from dev/test to production.
It feels great to see your work helping people around you.8 -
Tomcat
manager: "hey, we have this old java software running and need it to be compatible with our brand new crm system"
me: "okay, i've never workes with jsp before, but i'll have a look at it"
code: undocumented, who would have guessed
manager: "oh and btw. you must test your code on our live system, with our production database, but make sure not to brake anything, our last backup was 20 months ago."
me: "..."1 -
Can't say I am a religious type, not really into discovering/discussing religions and comparing them either... BUT I do hope there is someplace (like hell on steroids!!) for developers who don't test their code before checking it in and/or puting it on production..
Also another question, can I plead not guilty due to insanity when killing such devs?!? O.o FUuuuuuuuu!!!!2 -
I love Test-Driven Development!
And because of that fact, my heart shatters into thousands of pieces, when I recognize error events on our production nodes which are pointing onto a golden hammer function in a legacy project.
This particular function has about 300 lines with a bunch of subfunction calls and instantiations of helper-classes returning information for workflow.
Refactoring this code to apply proper unit-tests requires a way bigger investment than simply deal with 30 eventlogs a day, because this kind of payment is barely used by customers of our webshop.
This fact is a little itch each day of my work.
Guess it will make me go insane one day
¯\_(ツ)_/¯
xD1 -
This was some time ago. A Legendary bug appeared. It worked in the dev environment, but not in the test and production environment.
It had been a week since I was working on the issue. I couldn't pinpoint the problem. We CANNOT change the code that was already there, so we needed to override the code that was written. As I was going at it, something happened.
---
Manager: "Hey, it's working now. What did you do?"
Me: *Very confused because I know I was nowhere close to finding the real source of the problem* Oh, it is? Let me check.
Also me: *Goes and check on the test and prod environment and indeed, it's already working*
Also me to the power of three: *Contemplates on life, the meaning of it, of why I am here, who's going to throw out the trash later, asking myself whether my buddies and I will be drinking tonight, only to realize that I am still on the phone with my manager*
Me again: "Oh wow, it's working."
Manager: "Great job. What were the changes in the code?"
Me: "All I did was put console logs and pushed the changes to test and prod if they were producing the same log results."
Manager: "So there were no changes whatsoever, is that what you mean?"
Me: "Yep. I've no idea why it just suddenly worked."
Manager: "Well, as long as it's working! Just remove those logs and deploy them again to the test and prod environment and add 'Test and prod fix' to the commit comment."
Me: "But what if the problem comes up again? I mean technically we haven't resolved the issue. The only change I made were like 20 lines of console logs! "
Manager: "It's working, isn't it? If it becomes a problem, we'll work it out later."
---
I did as I was told, and Lo and Behold, the problem never occurred again.
Was the system playing a joke on me? The system probably felt sorry for me and thought, "Look at this poor fucker, having such a hard time on a problem he can't even comprehend. That idiotic programmer had so many sleepless nights and yet still couldn't find the solution. Guess I gotta do my job and fix it for him. I'm the only one doing the work around here. Pathetic Homo sapiens!"
Don't get me wrong, I'm glad that it's over but..
What the fuck happened?5 -
It's 5 AM and I don't want to shit on anybody's party but trust me when I say most of you here complaining about legacy code don't know the meaning of the word.
As someone who maintained a PHP4 codebase with an average file length of 3000+ lines for almost 4 years, I feel you, I feel your pain and your helplessness. But I've seen it all and I've done it all and unless you've witnessed your IDE struggle to highlight the syntax, unless you had to make regular changes in a test-less SVN's working copy that **is** the production and unless you are the reason that working copy exists because you've had enough of `new_2_old_final_newest.php` naming scheme, you do not know legacy. If you still don't believe me bare in mind I said "is" as in: "this system is still in production".
But also bare hope. Because as much grief as it cost me and countless before me, today of all days, without a warning, it got green lit for userbase migration to a newer platform. And if this 20 years of generous custom features and per client implemented services can be shut down even though it brings more profit than all the other products combined, so can happen to any of your projects. 🙏
Unfortunately, I do mean *any*.7 -
Our team really needs some workflow arrangement, and this time it was me who screwed up.
So we have to push an update to the Play Store and the App Store the Friday, the app is well tested on test environment then production environment, we got the ok so I uploaded a build, the app management team then continued the process of publishing..
During the weekend the app was approved and live to almost 500k user that can receive the update.
I got a phone call from the Project Manager at almost midnight, the time was really suspicious so I answered.
- Me: Hello.
- PM: Hi, sorry to call you now but the app is live and we have a problem.
- Me: what kind of problem? Let me check.
So I updated the app on my phone and opened it while I am on call.. I almost had heart attack!! WE PUBLISHED A VERSION POINTING TO THE TEST ENVIRONMENT. Holly shit
- Me: shit call the app management team NOW.
Eventually we removed the app from sale (unpublished it) and we submitted a new version immediately, once it was approved the next day we made the app available again (so for those who didn’t update yet, there will be no update to a faulted version, and no new users landing to a version with test data), I received one or two calls from friends telling me why the app is not on the store (our app is used nationally, so it’s really important).
Thank God there was no big show on twitter or other social media.. but it’s really a good lesson to learn.
I understand this is totally my fault, thankfully I didn’t get fired 😅4 -
I used to work on a production management team, whose job was, among other things, safeguarding access to production. Dev teams would send us requests all the time to, "run a quick SQL script."
Invariably, the SQL would include, "SELECT * FROM db_config."
We would push the tickets back, and the devs would call us, enraged. I learned pretty quickly that they didn't have any real interest in dev, test, or staging environments, and just wanted to do everything in prod, and see if it works.
But they would give up their protests pretty fast when I offered to let them speak to a manager when they were upset I wouldn't run their SQL.2 -
So this just happened...don't test on production kids (....sometimes you have no choice BUT DON'T F**KING DO IT OK!?)
 6
6 -
I was testing database migration and there was some issues which I couldn't fix them. So I drop the table just to test if the issues are still there.
"Why nothing have been changed?" After some minutes I realize it was production database which I had dropped 😓1 -
My co-worker, still studying but working as a "senior dev", just decided that we don't need a test/staging environment anymore. We just "validate" (we also don't use the word "test" anymore) newly created features in production.
Makes absolutely sense...
Thank god I have a new job from february on!1 -
Why the hell do you keep commit+push your shit to the master branch! We have develop, feature and hotfix, you *************!
Just because you want to test something in prd environment, you don't mess with the master to build the production image. And you do not even rebase fucking develop branch and keep it out of sync you POS!
Excuse my language, thank you.10 -
young user @Mizukuro asked days ago for ways to improving his javascript skills.
I wasn't sure what to say at the moment, but then I thought of something.
Lodash is the most depended upon package in npm. 90k packages depend on it, more than double than the second most depended upon package (request with 40k).
Lodash was also created 6 years ago.
This means lodash has been heavily tested, and is production ready.
This means that reading and understanding its code will be very educational.
Also, every lodash function lives in its own file, and are usually very short.
This means it's also easy to understand the code.
You could start with one of the "is..." (eg isArray, isFunction).
The reason for such choice is that it's very easy to understand what these functions do from their name alone.
And you also get to see how a good coder deals with js types (which can be very impredictible sometines).
And to learn even more, read the test file for that function (located in tests/<original file name>.js. For the most part they are very readable and examples of very good testing code.
Here's the isFunction code
https://github.com/lodash/lodash/...
Here's the test for isFunction
https://github.com/lodash/lodash/...
The one thing you won't learn here is about es5, 6, or whatever.3 -
In my three years experience so far I can honestly say that 100% of the developers I've worked with are narrow sighted with regards to how they develop.
As in, they lack the capacity to anticipate multiple scenarios.
They code with one unique scenario in mind and their work ends up not passing tests or generates bugs in production.
Not to say I'm the best at foreseeing every possible scenario, but I at least TRY to anticipate and test my code as much as possible to identify problems and edge cases.
I usually take much more time to complete tasks than my colleagues, but my work usually passes tests and comes back bug free. Whereas my colleagues get applauded for completing tasks quickly but end up spending lots of time fixing up after themselves when tests fail or bugs appear.
Probably more time wasted than if they had done the job correctly from the start. Yet they're considered to be effecient devs because they work "fast".
Frustrating...5 -
Please don't create a test server that doesn't have the same data with the production server, and vice versa.2
-
New mobile challenge I created:
... treat this as production code and show us your best practises and thought processes ... please list and explain any third party libraries used.
First submission:
I've used library X, although it has a major UI defect when rotating the device, it should be good for a simple test.
... wrong2 -
Dear client, if you can't be bothered to check more than two data points during several test imports, why are you surprised your production import has errors in the other 10k+ data points? We told you to check thoroughly, and you swore it was fine. But great now I get to unfuck production while you're mad you can't go live yet.2
-
Discovered yesterday that my boss does tests with production database... and I'm responsible for the fucking backups and he doesn't even care to let me now when so I can at least schedule one at slave. Come on... it's not that hard to let others know or test on your own machine...1
-
about 6 years ago I was working for a large consulting company on a government project. I put in a change for a stored procedure that hard coded the partition to 0, except 0 didn't exist on production, just on test. several thousand government employees couldn't access it for a day. 😞
-
Borrowed from Reddit and Twitter:
Everybody has a testing environment. Some people are lucky enough enough to have a totally separate environment to run production in.3 -
I goofed up and forgot the WHERE clause in my UPDATE query. Accidentally all of production possibly updated because we don't do test databases. I think it didn't actually go through because I cancelled it but now I need to restore a backup and compare data. Which means explaining this to the co-owner who can help me with a restore. I'm mortified, more so because it was a stupid thing to do to begin with.4
-
YOU WANT ME TO TEST AND DEVELOP IN MOTHERFUCKING PRODUCTION?!!!
Whaaaaaat, I'm changing shit, what if somebody goes to buy this product and I've made it super-cheap? ATM, there's two fuckin options for shipping, both different costs. the best bit? RIGHT NOW, THE USER CAN CHOOSE TO PAY LESS FOR THEIR SHIPPING.
HOLY FUCK.1 -
When the test database has better specifications & performance than the production one.. FML! 😭😭😭😭😭2
-
So after 6 months of asking for production API token we've finally received it. It got physically delivered by a courier, passed as a text file on a CD. We didn't have a CD drive. Now we do. Because security. Only it turned out to be encrypted with our old public key so they had to redo the whole process. With our current public key. That they couldn't just download, because security, and demanded it to be passed in the fucking same way first. Luckily our hardware guy anticipated this and the CD drives he got can burn as well. So another two weeks passed and finally we got a visit from the courier again. But wait! The file was signed by two people and the signatures weren't trusted, both fingerprints I had to verify by phone, because security, and one of them was on vacation... until today when they finally called back and I could overwrite that fucking token and push to staging environment before the final push to prod.
Only for some reason I couldn't commit. Because the production token was exactly the same as the fucking test token so there was *nothing to commit!*
BECAUSE FUCKING SECURITY!5 -
Discovered pro tip of my life :
Never trust your code
Achievements unlocked :
Successfully running C++ GPU accelerated offscreen rendering engine with texture loading code having faulty validation bug over a year on production for more than 1.5M daily Android active users without any issues.
History : Recently I was writing a new rendering engineering that uses our GPU pipeline engine.. and our prototype android app benchmark test always fails with black rendering frame detection assertion.
Practice:
Spend more than a month to debug a GPU pipeline system based on directed acyclic graph based rendering algorithm.
New abilities added :
Able to debug OpenGL ES code on Android using print statement placed in source code using binary search.
But why?
I was aware of the issue over a month and just ignored it thinking it's a driver bug in my android device.. but when the api was used by one of Android dev, he reported the same issue. In the same day at night 2:59AM ....
Satan came to me and told me that " ok listen man, here is what I am gonna do with you today, your new code will be going production in a week, and the renderer will give you just one black frame after random time, and after today 3AM, your code will not show GL Errors if you debug or trace. Buhahahaha ahhaha haahha..... Puffff"
And he was gone..
Thanks satan for not killing me.. I will not trust stable production code anymore enevn though every line is documented and peer reviewed. -
I'm getting really tired of those dumbass programmers that do not understand shit and then come to me when production breaks. (I am also a programmer, not really a DevOps engineer, but I'm the least worst at DevOps stuff, so it's my job...).
We're programming some kind of document management tool. Today we had a release, and one of the new features is to download all of your documents as a zip file, which is asynchronuously generated. When it's done, the user gets a mail with the download link to the zip file.
The feature works basically, but today it broke our production service, as somebody was running a test of it.
Turns out all the documents are loaded into memory to be zipped. So if you have 2 gigs of documents, a container with memory restrictions in that area will crash.
I asked the programmer who reported this «ops problem» to me, why he didn't just shit the files into a temp foler in order to zip them in there.
He told me that he wanted to do so, but did not know how to mock this for a unit test, and therefore went to the in-memory «solution», which was easier for him to mock.
For fuck's sake, unit tests and mocks are fucking tools, not ends in itself! I don't give a fuck about your pointless mocking code when the application crashes!
When I got to deal with such dumbasses, I'd prefer to mock those motherfuckers with a leaky bucket of liquid shit, which basically accomplishes the same task from my perspective: dripping shit all over the place and make everything suck as fuck.3 -
Yet another day at work:
My job is to write test libraries for web services and test others code. Yes I know to code, and have a niche in software testing.
Sometimes developers (whose code I find bugs in) get so defensive and scream in emails and meetings if I point out an issue in their code.
Today, when I pointed a bug in his repo, a developer questioned me in an email asking if I even understood his code, and as a tester I shouldn’t look at his code and only blackbox test it.
I wish I can educate the defensive developer that sometimes, it’s okay to make mistakes and be corrected. That’s how we deliver services that doesn’t suck in production.10 -
small victories... leaving little fuck you notes all over the code..
along with all the test cunts that still get incremented on the production..
-
Hey, we need a service to resize some images. Oh, it’ll also need a globally diverse cache, with cache purging capabilities, only cache certain images in the United States, support auto scaling, handle half a petabyte of data , but we don’t know when it’ll be needed, so just plan on all of it being needed at once. It has to support a robust security profile using only basic HTTP auth, be written in Java, hosted on-prem, and be fully protected from ddos attacks. It must be backwards compatible with the previous API we use, but that’s poorly documented, you’ll figure it out. Also, it must support being rolled out 20% of the way so we can test it, and forget about it, and leave two copies of our app in production.
You can re-use the code we already have for image thumbnails even though it’s written in Python, caches nothing and is hosted in the cloud. It should be easy. This guy can show you how it all works.2 -
I dunno about coolest, but I did sort of cement my reputation as the "database guy" in my first job because of this.
My first job was with a group maintaining a series of websites. Because of the nature of the websites, every morning we had to pull the records from one database on one network, sneaker net the data to a database on another network, and import the data via custom data import function.
However, the live site would crash after 100 or so records were imported. The dba at the live site had to script out a custom data partitioning script to do his daily duties, but it definitely messed up his productivity.
Turns out, the custom mass import function had recycled the standard import function, which was only used to import 1 record at a time, and it never closed its database connections, because it never needed to. A one line fix to production code was delivered 6 months later (because that was our release cycle) and I came up with the temporary work around, which was basically removing the connection limit. It would still crash with the work around, but only with multiple days worth of data. So basically only on Monday. Also developed the test set for the import (15k+ records). -
Next year I will strive to achieve the best test coverage on all our components and design all our new features using best-practice agile methodology with a realtime user involvement.
Reverend on 7 January: Fuck that, we need to ship this shit to production now. -
I didn’t turn down a dev freelance project when the client decided against going with best practices because the solution I offered was a well-established design pattern but created a need for a financial management change she didn’t like. I stupidly built what she asked for. It worked fine in the 3rd party vendor test environment but failed on production. After hours of analysis of code to ensure no changes happened to my source during test->prod deployment, and the vendor denying they had config differences between them, and the client refusing to pay, all I could do was abandon the project.2
-
Bug I had to fix today: some elements in our React app were being swapped with other elements.
We had `<foo>bar</foo>` on the component but on the html `foo` was being swapped with some other element in our app. It's contents ("bar" in the example) were being left in place, though, so we were getting `<baz>bar</baz>`.
This would only happen when running on production mode. On development everything was fine.
Also, everything seemed fine on the React dev tools. `foo` was where it was supposed to be, but on the html it was somewhere else.
Weirdest shit I ever saw when using React. I found a way to go around it and applied that fix, but I'm still trying to track this down to the source.
The worst part was waiting for fucking webpack to finish the production bundle on every fucking change I wanted to test. I didn't miss the change-save-compile-test flow at all.
What a shit day.4 -
You get to work, things have broken down in the night, you have no access to production or even test environment and you have to guess why. You do the same job as somebody in other countries for less pay while everyone else has this laid back approach where the time they actually spend working is negligible. Until the sheer amount of entropy in your organization wears you down and you just become part of the problem.
-
So last week I really fucked up
I had this new implementation that was supposedly to be integrating smoothly into the rest of the service. It depended on a serialized model made by a data scientist. I test it in local, in QA environment: no problem.
So, Friday, 4pm, I decide to deploy to production. I check once from the app: the service throw an error. Panic attack, my chief is at my desk, we triy to understand what went wrong. I make calls with cUrls: no problem. Everything seems fine. I recheck from the app again: no problem.
We dedice to let it in prod, as the feature work. I go get some beers with the guys, to celebrate the deploy.
Fast-forward the next morning, 11am, my phone ring: it's a colleague of my chief. "Please check Slack, a client is trying to use the feature, it's broken"
FUUUUUUUUUUUUCK!!!
Panic attack again. I go to the computer, check the errors: two types of errors. One I can fix, the other from a missing package on the machine that the data guy used.
Needless to say, I had a fairly good weekend.
Lessons learned:
- make sure Dev, QA and Prod are exactly the same (use Ansible or Container)
- never deploy on a Friday afternoon if you don't have a quick way to revert1 -
Day 0: thank you for being an Amazon Customer, your database is about to be upgrade in the near future with or without your consent! Tough titties motherfucker!
Day 16: ok, every upgraded by hand in the test environment, everything seems stable, let's go make preparations for production!
Day 16.5: ssh user@<prod_bastion_ip> --yada --yada
Unable to connect
Oooook, let's try again,
Unable to connect
Day 16.5.1: WHY THE FUCK NOT, the IP is fucking right, the cert is right, the user is right, the..... fucking.... EC2 instance has been......... terminated.....
FML!
---
Why! why can't people leave things alone.
Excuse me while I hit the bourbon 🥃 -
If you don't know, there are 2 types of bug fixes:
Hot Fix - Patch files directly on the production
Quick Fix - Deploy fix on production and then test it4 -
BANE OF MY FUCKING EXISTENCE. STOP POLLUTING MY PRODUCTION CODE WITH TEST CODE, YOU FUCKING CRETINS.
-
Don't test complex functionality before production.. neither unit, nor system tests involved for my android app. Releaseing solely based on hope!2
-
Things that seem "simple" but end up taking a long ass time to actually deploy into production:
1. Using a new payment processor:
"It's just a simple API, I'll be done in 2 hours"
LOL sure it is, but testing orders and setting up a sandbox or making sure you have credentials right, and then switching from test to life and retesting, and then... fuck
2. Making changes to admin stats.
"'I just have to add this column and remove that one... maybe like a couple of hours"
YOU WISH
3. Anything Javascript
"Hah, what, that's like a button, np"
125 minutes later...
console.log('before foo');
console.log(this.foo)
etc..2 -
Me: *asks boss for the id of his test store so I can apply experimental schema changes to test out a new dashboard app*
Boss: *gives me production store id and doesn't say anything*
Fate: … "You got lucky this time."
This is the CEO of the company btw. Startups. *sigh*1 -
TL;DR Dear boss, firstly, you always get someone to review anything important done by a fucking intern.
Secondly, you do not give access to your fucking client's production server to an intern.
Thirdly, you don't ask your fucking intern to test the intern's work that has not been reviewed by anyone directly on your client's fucking production server.
Last week, the boss and one of the lead devs (the only guy with some serious knowledge about systems and networking) decided to give me (an intern who barely has any work experience) the task of fixing or finding an alternate solution to allowing their support team access to their client machines. Currently they used a reverse SSH tunnel and an intermediary VH but for some reason, that was very unreliable in terms of availability. I suggested using OpenVPN and explained how it would work. Seemed to be a far better idea and they accepted. After several days of working through documentations and guides and everything, I figured out how OpenVPN works and managed to deploy a TEST server and successfully test remote access using two VMs. On seeing my tests, the boss told me that he wanted to test it on the client network. I agreed. Today he comes to me and he tells me to prepare testing for tomorrow and that the client technician is going to give me access to one of their boxes. And then he adds, "It's a working prod server. We'll see if we can make it work on that" and left. I gaped at him for a while and asked another dev guy in the room if what I heard was right. He confirmed. Turns out, the lead dev and the boss's son (who also works here) had had a huge argument since morning on the same issue and finally the dev guy had washed it off his hands and declared that if anything goes wrong from testing it on production, it's entirely the boss's own fault. That's when the boss stepped in and approached me. I ran back to his office and began to explain why prod servers don't top the list of things you can fuck around with. But he simply silenced me saying, "What can go wrong?" and added, "You shouldn't stay still. You should keep moving". Okay, like firstly what the fuck and secondly, what the fuck?.
Even though OpenVPN client is not the scariest thing to install, tomorrow's going to be fun.4 -
Just now... Got a job to create patch files for a couple of jars, which may or may not have varying class files. In total, I have to decompile, check, add and synchronize about 30 class files in 6 jars with a new functionality (that I didn't write). 🙂
FUCK PRODUCTION! WHY CANT YOU MAINTAIN ONE MOTHERFUCKING JAR?
OH? YOU'RE SUPERSTITIOUS THAT ONE TINY, ANT-SHIT SIZED CHANGE IN ONE SIMPLE FUNCTIONALITY WILL FUCK UP *OUR* PRODUCT?
FUCK MANAGEMENT! YOU DON'T HAVE CONFIDENCE IN YOUR *OWN* PRODUCT!
OH? CUSTOMER COMES FIRST? HAVE THE BALLS TO DEFEND YOUR OWN FUCKING SELF AND PRODUCT TO THE CLIENT OR THEY'RE GONNA MAKE YOU YOUR BITCH AND TIE A GAGBALL DIPPED IN HOT SAUCE AROUND YOUR MOUTH! HOW.. THE FUCK.. DID YOU MISS THAT LOGIC??????
Best part, they want it by tomorrow, and they don't wanna test it. Guess who's gonna get slaughtered after a week? ME! 🙂5 -
So where I work, we used to push our code from test servers to production every tuesday/thursday exactly at one in the afternoon. Every time there was a push, I would play "push it to the limit" blasting over my speakers. Now we have an automated push and I never really listen to that song anymore. I miss those days. Link related https://youtu.be/9D-QD_HIfjA1
-
I was experimenting with a load test suite called 'Siege' to build and scale increasingly complex searches against our new site search engine. I assumed that an old iMac couldn't have generated a crushing load against the beta servers and I learned two things the day I wrote and started that script before heading to lunch:
1) Beta and Production shared MSSQL instances
2) That single iMac was more than enough to take the whole production site down... -
the web developer equivalent of waiting for code to compile is waiting for your local test DB to be populated with recent data from the production DB2
-
FUCKING MICROSOFT IIS SHIT.
I'm a .NET dev since 13 years and EVERY FUCKING TIME STUPID IIS MOTHERFUCKER AND STUPID WINDOWS SERVER have a different problem setting up because of some permission.
You can't never get a site up in IIS without loosing time and patience having weird 400/500.x errors because every fucking machine have to set up some tweaky and hidden permissions.
I have 2 identical fucking win servers and deploying a .NET core applications and on one works (test server) and obviously, on the production server it gives troubles.
FUCK YOU MICROSOFT FUCK YOU I would take the IIS devs personally here and whip them to death until they don't resolve the fucking thing3 -
Living on the edge!
One or two years ago I managed to deploy a DDL change directly on the production server. As I knew there was a backup job which will run every day at noon and at midnight. So I run my script some minutes after noon. So far so good. But somehow I tested it badly in my test environment and the UI of the application throws error after error now in production.
Well, just revert the db to the latest recovery point with the backup, I thought.
It became clear then after a couple of minutes of searching the backup folder for the db backup that there was no such file. The youngest backup file was 3 years old.
Now what happened: The backup script had a switch "simulate=true" and then simulated a successful backup on each run. Therefore the monitoring system got no alerts for not correctly executing those jobs correctly. Then the monitoring job which should do the backupfolder surveillance stuck with green, because there was a valid backup file inside. But it did not check for a specific creation date.
Now this database is the one we need for doing our daily business and is really crucial. Therefore It was easier to emergencyfix the application than doing a rollback of the db 🙄
Well, not really a data loss story, but close to one. -
Remember to always setup and test your production setup!
Seem like a local college forgot to do some QA 😂
-
Simultaneously opening ssh sessions to test and production system, finally stopping the application in the factory.
It was me. -
"Real devs test in production", in practice.
This was actually the second such notification I received. Not sure if this is standard for mobile app testing... 2
2 -
Most intense day for me was at the very start of my career. Internship... went with product manager to client's office while PM installed new test version of our product for on-site integration testing. Shortly after deploy, client manager came over to ask why production had gone down...
Turns out that manually typing DB name as part of deployment script is not, erm, risk free. PM entered production DB name and took out a very busy call centre for a few hours. Agents in tears, customers raging on phones, etc! After we restored and got everything back up and running, he reached me the keyboard and said "You're doing it this time."
My attempt was problem free, thankfully. Earned many brownie points that day.1 -
Managers don't understand that there will ALWAYS be bugs shipped to production, no matter how hard you try to prevent or test against them.
Devs: lol
inb4 any comments really, i've seen facebook, instagram, and all the 'big players' crash and have bugs multiple times before, so don't go around swinging your dick like your company's software has no known bugs (don't even get me started on the devrant mobile app) I'm just saying bugs are a fact of software8 -
"Our system has detected that this message is[nl]421-4.7.0 suspicious due to the very low reputation of the sending IP address"
Oh shit..
Note to self: Don't test on production servers. Gmail has now blocked my ass. -
probably every time I see my tests failing.
Each time I am writing tests I'm convincing myself "it's an investment", "spend 2 hours now to save 2 days later", "unit-tests are good".
And each time I'm chasing away ideas like "perhaps they are right, perhaps writing unit tests is a waste of time..", "this code is simple, it should ever break - why test it??", "In the 2 hours I'll spend writing those UT I could build another feature"
Yes, it is terribly annoying to write tests, especially after writing the production code (code-first approach). Why test code that you know works, right?
But after a few weeks, months or years, when the time comes to change your feature: enhance it, refactor it, build an integration with/from it, etc, I feel like a child who found a forgotten favourite candy in his pocket when I see my tests failing.
It means I did a very good job writing them
It means it was not a waste of time
it means these tests will now save me hours or days of trial-and-error change→compile→deploy→test cycles.
So yeah, whenever I see my tests fail, I feel warm and fussy inside :)2 -
I used a test user account to make live payment transaction with test wallet money on production, accounting department just called... I think I'm in hot waters!1
-
I hate dev politics...
PM: Hey there is a weird error happening when I upload this file on production, but it works on our test environments.
Me: After looking at this error, I don't find any issues with the code, but this variable is set when the application is first loaded, I bet it wasn't loaded correctly our last deployment and we just need to reload the application.
Senior Dev: We need to output all of the errors and figure out where this error is coming from. Dump out all the errors on everything in production!!
Me: That's dumb... the code works on test... it's not the code.. it's the application.
Senior dev: %$*^$>&÷^> $
Me: Hey I have an idea! If test works... I can go ahead and deploy last week's changes to prod and dump those errors you were talking about!!
Senior Dev: OK
Me: *runs Jenkins job the deploys the new code and restarts the application*
PM: YAY you fixed it!!
Senior Dev: Did you sump put those errors like I said.
Me: Nope didn't touch a thing... I just deployed my irrelevant changes to that error and reloaded the application.2 -
Why is web development such a headache?
I'm writing a responsive wesbite from scratch. All goes perfect, even cross browser.
It all works, adapts to screen size etc. Nice! About to get this code into production.
Me: I'll test the iPhone 5 viewport size before I push the code...
Responsive Developer Tools:
FireFox: nu uh, there's a magic random 1px margin to every element on your page now, which you cannot find in your css or in the computed tab. It's magical.
Me: weird, what if I change the viewport size to the iPhone 6's dimensions?
Issue persists.
Me: hmm, what if I add or substract one fucking pixel from the viewport width or height?
FireFox: What 1px margin? Don't know what you're talking about ... There never was one...
Me: ok, weird (sets viewport size back to the iPhone 5 format for testing)
FireFox: I present to you: the magic random 1px margin.
I'm at a loss. I really am. Been clicking and unclicking almost every responsive part of my css I could find for this page and it just doesn't want to work persistently. And I swear to god that it worked a week ago in that exact viewport size. It's so frustrating. 31
31 -
Normally you would have:
- Management
- SysOps
- DevOps
- Devs
In the company (30-50 workers) we only have:
- Management
- SysOps (they don't know how to deploy apps beyond FTP to a webhost either)
- Devs
Jepp, management does not want a specific DevOps department, because he thinks every single "I just finished the Javascript course on codecademy" person knows how to deploy an app beyond dragging&dropping it to a webhost with FTP...
I tried to propose to them that I handle DevOps and teach it to others, so we can deploy code that we deem "production ready" in a more proper manner...
They refused...
They rather stick to "just use FTP to push any changes we made directly to the production server and test changes there"4 -
A couple of years ago I was working on a fairly large system with a complex (by necessity) access control architecture.
As is usually the case with those projects, it's awkward for developers to repro bugs that have to do with a user's accesses in production when we are not allowed to replicate production data in test, let alone locally.
We had a bug where I ended up making myself a new row in the production database for a thing I could have access to without affecting real data to repro it safely. I identified the bug so I could repro it in dev/test and removed the row and ensured everything worked normally, whew scary.
Have you ever walked into the office one day, and everyone is hunched over in a semicircle around one person's workstation, before one turns around to look at you and says - after a pause - "... ltlian?.."
Turns out I had basically "poisoned the well" with my dummy entity in a way where production now threw 500 for everyone BUT me who had transitive access to this post-non-entity. Due to the scope of the system, it had taken about a day for this to gradually propagate in terms of caching and eventual consistencies; new entities coming in was expected, but not that they disappear.
Luckily I had a decent track record for this to be a one-off. I sometimes think about how I would explain testing in prod and making it faceplant before going home for the day, other than "I assumed it would be fine". I would fire me.3 -
Adding a proof of concept directly to production and handing it over without a single test is God's blessing.1
-
Overengineering. Finding the right point between overdesign and no design at all. That's where fancy languages and unusual patterns being hit by real world problems, and you need to deal with all that utter mess you created being architecture astronaut. Isn't that funny how you realize that another fancy tool is fundamentally incompatible with the task you need to solve, and you realize it after a month of writing workarounds and hacks.
But on the other hand, duct tape slacking becomes a mess even quicker.
Not being able to promote projects. You may code the shit out of side project and still get zero response, absolutely no impact. That's why your side projects often becomes abandoned.
Oversleeping. You thought tomorrow was productive day, but you wake up oversleeped, your head aches, your mind is not clear and you be like "fuck that, I'm staying in bed watching memes all day". But there's job that has to be done, and that bothers you.
Writing tests. Oh, words can't describe how much I hate writing tests, any kind of. I tried testing so many times in high school, at university, even at production, but it seems like my mind is just doesn't accept it. I know that testing is fundamentally important, but my mind collapses every time I try to write a single fucking test, resulting in terrible headache. I don't know why it's like that, but it is, and I better repl the shit out of pure function than write fucking tests. -
Ever have a bug that *only* occurs in your production environment? How do you test potential fixes? 😜5
-
Dev sent out a code review request.
I take about an hour, ask questions, make suggestions, general feedback, etc.
Today I noticed none of my questions were answered, developer closed the review, and the code merged into the production branch.
So I email him, asking him why the review was closed and why none of my concerns were addressed before merging to production.
Dev: "No one responded or left feedback, so I thought it was OK to merge up."
Me: "I reviewed and left feedback within the hour you sent the request."
Dev: "Oh yea...you did. Sorry. The code is already in production, but if you still want to leave feedback, create a work item, and I'll take a look."
No you won't.
An example of the code...The dev added an async method to a test harness *console app*. Why? .. check in comment was "Improves performance and enhances the developer experience.."
NO IT DOESN'T!
OK..that's off my chest. No one is getting punched in the face today.6 -
Migrating to another sub domain for the 4th time.
First they say 'oh this sub domain is just for demo and you can freely test your code on it .
Few days later they say the same thing to another team and then :
- 'dude ! Is the website down because of your code ?'
- 'The code is not complete yet ! I've been adding some features! '
-'Is it possible that you migrate to another demo sub domain? Content production team wants to upload more content on that sub domain '
-'Sure ! Why not :('2 -
* Developing a new "My pages" NBV offer/order solution for customer
_Thursday
Customer: Are we ready for testing?
Me: Almost, we need to receive the SSL cert and then do a full test run to see if your sales services get the orders correctly. At this point, all orders made via this flow are tagged so they will not be sent to the Sales services. We also still need to implement the tracking to see who has been exposed to what in My Pages.
Customer: Ok, great!
_Friday
Customer: My web team needs these customers to have fake offers on them, to validate the layout and content
Me: Ok, my colleague can fix this by Tuesday - he has all the other things with higher prio from you to complete first
Customer: Ok! Good!
_Sunday
Me: Good news, got the SSL cert installed and have verified the flow from my side. Now you need to verify the full flow from your side.
Customer: Ok! Great! Will do.
_Monday
*quiet*
_Tuesday
Customer: Can you see how things are going? Any good news?
Me: ???
*looks into the system*
WTF!?!
- Have you set this into production on your side? We are not finished with the implementation on our side!
Customer: Oh, sorry - well, it looked fine when we tested with the test links you sent (3 weeks ago)
Me: But did you make a complete test run, and make sure that Sales services got the order?
Customer: Oh, no they didn't receive anything - but we thought that was just because of it being a test link
Me: Seriously - you didn't read what i wrote last Thursday?
Customer: ...
Me: Ok, so what happens if something goes wrong - who get's blamed?
Customer: ...
Me: FML!!!2 -
So glad to be staying a new job next week. Today a junior colleague asked me what the best way to test something would be as it won't work locally. Knowing this has a good chance of taking down the server, I suggest he sounds up a server on his AWS account. My manager comes in, oh no I don't want him doing it on AWS use the production server instead. By the time stuff States hitting the fan I will be gone.1
-
New twist on an old favorite.
Background:
- TeamA provides a service internal to the company.
- That service is made accessible to a cloud environment, also has a requirement to be made available to machines on the local network so you can develop against it.
- Company is too cheap/stupid to get a s2s vpn to their cloud provider.
- Company also only hosts production in the cloud, so all other dev is done locally, or on production non-similar infra, local dev is podman.
- They accomplish service connectivity by use of an inordinately complicated edge gateway/router/firewall/message translator/ouija board/julienne fry maker, also controlled by said service team.
Scenario:
Me: "Hey, we're cool with signing requests using an x509 cert. That said, doing so requires different code than connecting to an unsecured endpoint. Please make this service accessible to developer machines and lower environments on the internal network so we can, you know, develop."
TeamA: "The service should be accessible to [cloud ip range]"
Me: "Yes, that's a production range. We need to be able to test the signing code without testing in production"
TeamA: "Can you mock the data?"
Me: "The code we are testing is relating to auth, not business logic"
TeamA: "What are you trying to do?"
Me: "We are trying to test the code that uses the x509 you provide to connect to the service"
TeamA: "Can you deploy to the cloud"
Me: "Again, no, the cloud is only production per policy, all lower environments are in the local data center"
TeamA: "can you try connecting to the gateway?"
Me: "Yes, we have, it's not accessible, it only has public DNS, and only allows [cloud ip range]"
TeamA: "it work when we try it"
Me: "Can you please supply repro steps so we can adjust our process"
TeamA: "Yes, log into the gateway and try issuing the call from there"
Me: (╯°□°)╯︵ ┻━┻
tl;dr: Works on my server -
Tl;Dr Im the one of the few in my area that sees sftping as the prod service account shouldn't be a deployment process. And the ONLY ONE THAT CARES THAT THIS IS GONNA BREAK A BUNCH OF SHIT AT SOME POINT.
The non tl;dr:
For a whole year I've been trying to convince my area that sshing as the production service account is not the proper way to deploy and/or develop batch code. My area (my team and 3 sister teams) have no concept of using version control for our various Unix components (shell scripts and configuration files) that our CRITICAL for our teams ongoing success. Most develop in a "prodqa like" system and the remainder straight in production. Those that develop straight in prodqa have no "test" deployment so when they ssh files straight to actual production. Our area has no concept of continuous integration and automated build checking. There is no "test cases", no "systems testing" or "regression testing". No gate checks for changing production are enforced. There is a standing "approved" deployment process by the enterprise (my company is Whyyyyyyyyyy bigger than my area ) but no one uses it. In fact idk anyone in my area who knows HOW to deploy using the official deployment method. Yes, there is privileged access management on the service account. Yes the managers gets notified everytime someone accesses the privileged production account. The managers don't see fixing this as a priority. In fact I think I've only talk to ONE other person in my area who truly understands how terrible it is that we have full production change access on a daily basis. Ive brought this up so many times and so many times nothing has been done and I've tried to get it changed yet nothing has happened and I'm just SO FUCKING SICK that no one sees how big of a deal this. I mean, overall I live the area I work in, I love the people, yet this one glaring deficiency causes me so much fucking stress cause it's so fucking simple to fix.
We even have an newer enterprise deployment. Method leveraging a product called "urban code deploy" (ucd) to deploy a git repository. JUST FUCKING GIT WITH THE PROGRAM!!!!..... IT WAS RELEASED FUCKING 12 YEARS AGO......
Please..... Please..... I just want my otherwise normally awesome team to understand the importance and benefits of version control and approved/revertable deployments2 -
I was Just college fresher who completed his Engineering. My first week in the office. And a system was provided to me, since it was support project so I was given direct access to production database.
Fresher + Production Database + Access of Admin credentials = Worst Possible Combination
So it was my night shift, I was told to update new tariff plan for our client (which was one of the largest telecom service in India) .
If someone recharges for more than 200 Rupee, that person will get 10% or 20% extra talk time. Which was only applicable for particular circle (Like Bihar and Rajasthan).
Since I was fresher, I was told to update given query from my senior employee which he shared on the shared folder. Production downtime was in the mid night, so at that time I updated that query on the production database.
Query successfully updated. I completed my night shift, went home and slept.
When I woke up, I saw my mobile it had 200+ missed calls from different locations of India. They were Circle heads of that telecom service provider who contacted me. I realized something unexpected is expecting me.
Then at that moment my team lead called me and he asked me to come office right away.
Reminding you I was a fresher, I was shivering. What have I done there?
When I reached office, I came to know that the query I updated on production bombarded.
Every person who recharged that day (duration from midnight to morning 10 AM) got 10 times or 20 times more talktime.
A part of Query was something like this where error was made:
TalkTime = RechargeAmount + RechargeAmount * 10/100; (Bihar)
or
TalkTime = RechargeAmount + RechargeAmount * 20/100; (Rajasthan)
But instead of this query, I updated below one:
TalkTime = RechargeAmount + RechargeAmount * 10;
or
TalkTime = RechargeAmount + RechargeAmount * 20;
In a span of 10 hours, that telecom service lost revenue of 6.5 crore Rupees. Thanks to recovery team they were able to recover 6 crore but still 50 lakh Rupees were in loss.
One small query, and approx 1 million dollar was on stake.
Aftermath of this incident
My Mistake:
I should have taken those queries on mail. Or, there should have been mail communication regarding this.
Never ever do anything over oral communication. Senior employee who did this denied and said he provided correct query, and I had no proof of communication.
I told them, it was me who executed that query on production. Since I was fresher, and took my responsibility of that incident. My team lead rescued me from that situation.
Lesson Learned:
Always test your query and code multiple times before you execute or Go live it on production.
Always have email communication for every action you take on production.
Power comes with responsibility. If you have admin credentials of production never use it for update/delete/drop until you are sure.
Don’t take your job lightly.
I was not fired from that Job, but I have learnt my lesson very well. -
Writing a feature critical for production in 2 hours of solid focus during the morning.
6 hours later it's still not in the build because:
* tech lead wants the code to move to a partial class instead of an extension method, delaying the UX review. No guidelines for this ever existed.
* after seeing the result, the UX team wants some element to be dynamic. A line. A friggin horizontal line.
* after adding the dynamic shiny frigggggin line, I try to test the feature with the server. It is still not deployed because the server guy went home. "The PR was not merged so I assumed we'll add it tomorrow".
Another day at the meat grinder.6 -
Was just reading some of the OpenVPN scripts to renew a certificate where I forgot to source the vars file first (apparently OpenVPN stores those in a separate file that you always have to source first, and I tend to forget it sometimes).
Reading the revoke-full script that OpenVPN provides, it's just bash so I can read it no problem. But traversing through it and trying to understand it... Horrible! There's a test file in $RT named keys/revoke-test.pem. It's not used anywhere in OpenVPN for anything useful as far as I'm aware. The script however - the script that's running on a production server! - attempts to remove this file. It doesn't exist. Test files do (or at least should) not exist in production. They're not supposed to be there.
It exports empty variables. Some of them are set by the sourced vars file, some aren't. Not entirely sure why it's exporting variables as empty when they're uninitialized, or why it doesn't just unset the ones that are initialized.
And finally it goes ahead and revokes the key file that I'm actually concerned about through regular OpenSSL and verifies it.
Not to mention that the lack of the sourced vars file, which admittedly I should think about in the current status quo, if it *always* needs to be sourced anyway... Why doesn't the script do that itself then? One less thing to go wrong. But hey, proper design?
Gore. I don't have any other words for it.
And before anyone tells me that I should go and fix it if I'm so worried about it. Remember, I am not a developer. That's the job of the developers that made this in the first place.6 -
First day back from holiday: after 30 minutes of work (excludes start-up, catch-up etc.) The P.O. (product owner) comes to me
Telling me I needed to switch project, ok I thought at least they switched the project from what ever it was to a propper OTAP street while I was away
Few tickets later the P.O. asked me if tickets x could be deployed to our test servers as well as production.. (note the ticket was already merged with our develop branch and he wanted only that single ticket x to be deployed)
WTF is the point of a OTAP street if you're going to deploy it to every server type at once?
So day one after my holiday I already needed to fight the P.O. again
At least I wasn't disturbed during my vacation... Witch is a first.8 -
A newly joined developer (who was supposed to be very senior) comes and asks me how to write a test cos for some reason the person didn't know how to mock.
In Java,
(same for any other implementation which has an interface)
Writes Arraylist list =.....
Instead of List list = Arraylist...
Deployed code (another engineer from another country helped to deploy since this new senior dev didn't have access yet.
But the new senior dev didn't update relevant files in production code which brought down the site for nearly an hour. Mistake aside, the first reaction from this new senior dev is 'WHY DIDN'T THE DEV THAT WAS HELPING DIDN'T DO THE FILE UPDATE?'
This was followed by some other complaints such as our branching stragies are wrong. When in fact the new senior dev made a mistake by just making assumptions on our git branching strategies and we already advised on correct process.
Out of all these, guess this is the best part. The senior dev never tested code locally! Just wrote code, unit test and send to QA and somehow the test passed through. I learnt this when I realised this dev... has not even set up the local environment yet.
I keep saying new but this Senior dev been around like 3 months! This person is in another team within our larger team but shares same code base. I am puzzled how do you not set up your environment for 3 months. Don't you ask for help if you are stuck? I am pretty sure the env is still not setup.
Am I over reacting or is this one disgusting developer who doesn't even qualify for an intern let alone a senior dev? It's so revolting I can't even bring myself to offer help.8 -
https://devops.com/dear-staging-wer...
What the F#*@&$# %#@$!?!?!
This person has decided to skip using staging, because it doesn't correctly reflect prod!
If that's your problem, than why don't you try to fix it? Create a DB with fake data, make one based on anonymised customer data, or even do it on non-anonymised data (with permission of course), but fix the staging env so that it reflects prod!
This is a devops site (it's literally the name!), and instead of teaching you how to make staging exactly like prod, they tell you to do what caused the creation of the staging->prod system IN THE FIRST PLACE!!!
There's all these stuff like Vagrant that are literally designed to help you as a dev mimic prod, and you just throw it all out!?
"With feature flags, I can safely test in production without fear of breaking something or negatively affecting the customer experience."
Famous last words.12 -
So, just pulled another all-nighter..
On our platform I switched a quite big customer to another stock keeping system to pull them into automatic FEFO handling etc. Just a better stock keeping system overall.. I made it.. *self hi-5*
Evidently the crons caught that change, and CLEARED ALL THE STOCK LEVELS as they're now managed by said system...
Had to pull the counts, locations, expiry dates and lot numbers from the history table and old database fields, add them to an Excel sheet and then add all gathered locations by hand back into the new system, whilst also setting the new settings for them.
39 unique products that were gathered over 190+ sku objects... (Somebody didn't get object oriented, or was trying to KISS themselves, clearly...)
That's 6 hours of extra work for a stupid fuck up.. Oops? (:5 -
I really really hope that no one post this,a friend texted it to me and I wanted to share it because made my day.
Idk where it comes, so feel free if know where this came from to post it:
//FUN PART HERE
# Do not refactor, it is a bad practice. YOLO
# Not understanding why or how something works is always good. YOLO
# Do not ever test your code yourself, just ask. YOLO
# No one is going to read your code, at any point don’t comment. YOLO
# Why do it the easy way when you can reinvent the wheel? Future-proofing is for pussies. YOLO
# Do not read the documentation. YOLO
# Do not waste time with gists. YOLO
# Do not write specs. YOLO also matches to YDD (YOLO DRIVEN DEVELOPMENT)
# Do not use naming conventions. YOLO
# Paying for online tutorials is always better than just searching and reading. YOLO
# You always use production as an environment. YOLO
# Don’t describe what you’re trying to do, just ask random questions on how to do it. YOLO
# Don’t indent. YOLO
# Version control systems are for wussies. YOLO
# Developing on a system similar to the deployment system is for wussies! YOLO
# I don’t always test my code, but when I do, I do it in production. YOLO
# Real men deploy with ftp. YOLO
So YOLO Driven Development isn’t your style? Okay, here are a few more hilarious IT methodologies to get on board with.
*The Pigeon Methodology*
Boss flies in, shits all over everything, then flies away.
*ADD (Asshole Driven Development)*
An old favourite, which outlines any team where the biggest jerk makes all the big decisions. Wisdom, process and logic are not the factory default.
*NDAD (No Developers Allowed in Decisions)*
Methodology Developers of all kinds are strictly forbidden when it comes to decisions regarding entire projects, from back end design to deadlines, because middle and top management know exactly what they want, how it should be done, and how long it will take.
*FDD (Fear Driven Development)*
The analysis paralysis that can slow an entire project down, with developments afraid to make mistakes, break the build, or cause bugs. The source of a developer’s anxiety could be attributed to a failure in sharing information, or by implicating that team members are replaceable.
*CYAE (Cover Your Ass Engineering)*
As Scott Berkun so eloquently put it, the driving force behind most individual efforts is making sure that when the shit hits the fan, you are not to blame.2 -
Wow or wtf to these banks API. was integrating an API for a service which accept JSON input.
Okay fair enough, that would be fine
Spent an hour writing code(purescript) most of time spent was on writing Types based on the API doc. after that okay let me test the API it failed.
I was what happened? So tested the API from postman with the payload from the doc, it worked. What how?
used a JSON diff to compare the payload from postman and the log. Looked same to me after spending few hours checking what is wrong with it .trying changing value to pasting the body of the log request in postman and trying everything failed.
Later went to the original working payload provided by them and changing the order. It started throwing error. I was like wait what?
It must be only on there UAT. created a payload with production creds and hoping to our production server (they have IP whitelist) ran the curl with proper payload as expected it worked. Later for same payload changed the order or one key and tried it failed.
Just why????
I don't want to create a JSON with keys on specific order. Also it's not even sorted order.4 -
I'm still studying computer science/programming, I still have one year to do in order to graduate (Master). I am in a work study program so I'm working for a company half of the time, and I'm studying the other half. It is important to mention that I am the only web developer of the company
When I arrived in the company 9 months ago, I was given a Vue project which had been developed by a trainee a few weeks before my arrival and I was asked to correct a few things, it was mostly about css. Then, I was ask to add a few functionalities, nothing really hard to code, and we were supposed to test the solution in a staging environment, and if everything was ok, deploy it to prod.
However, the more I did what I was asked, the more functionalities I had to implement, until I reached a point where I had to modify the API, create new routes, etc. I'm not complaining about that, that's my job and I like it. But the solution was supposed to be ready when I arrived, it was also supposed to be tested and deployed.
The problem is, the person emitting these demands (let's call him guy X) is not from the IT service, it's a future user of the website in the admin side. The demands kept going and going and going because, according to him, the solution was not in a good enough state to be deployed, it missed too many (un)necessary features. It kept going for a few months.
The best is yet to come though : guy X was obviously a superior, and HIS superior started putting pressure on me through mails, saying the app was already supposed to be in production and he was implying that I wasn't working fast enough. Luckily, my IT supervisor was aware of what was going on and knew I obviously wasn't to blame.
In the end, the solution was eagerly deployed in production, didn't go through the staging environment and was opened to the users. Now, guy X receives complaints because none of what I did was tested (it was by me, but I wasn't going to test every single little thing because I didn't have time). Some users couldn't connect or use this or that feature and I am literally drowning in mails, all from guy X, asking me to correct things because users are blocked and it's time consuming for him to do some of the things the website was doing manually.
We are here now just because things have been done in a rush, I'm still working on it and trying to fix prod problems and it's pissing me off because we HAVE a staging environment that was supposed to prevent me from working against the clock.
On a final note, what's funny is that the code I'm modifying, the pre-existing one needs to be refactored because bits and pieces are repeated sometimes 5 times where it should have been externalized and imported from another file. But I don't know when and if I will ever be able to do that.
I could have given more context but it's 4am and I'm kinda tired, sorry if I'm not clear or anything. That's my first rant -
If I had a nickel every time the unit tests failed not because something was wrong in the code, but because someone had messed up the unit test I'd be able to retire early.
I just spent the better part of 10 hours hunting down a bug in some production code only for the test to be wrong because the person who wrote it had mocked the http response incorrectly.
Nothing I did to "fix" the code worked, because nothing was wrong with it...4 -
Ok I'm officially losing my fucking mind!
I've been trying to solve a connection bug that only occurs in production which is cool if THIS FUCKING APP DIDN'T TAKE 30 MINUTES TO DEPLOY!!!
Been busy for 4 hours and I've only been able to test 4 minor fixes. -
most memorable bug I fixed
Line 1:
- throw new Error(‘test’)
+ // throw new Error(‘test’)
yes, this was committed code in production4 -
Damn, nespresso! As if your fucking webshop wasn't bad enough, don't bug me (haha) with useless mails AND JUST TEST YOUR SHIT BEFORE PRODUCTION!!! Seriously, thousands of customers pay lots and lots of money for mediocre coffee in aluminum capsules, so JUST HAVE THE DECENCY TO INVEST SOME BUCKS INTO THE CUSTOMER FACING APPS!!!
 6
6 -
Works in production?
Yes: Copy changes to dev and test.
No: Start humming and walk away from the computer. -
We are 3-4 days away from deployment to production. We are still bug fixing. But one coworkers decided this is the time to make a fuss about the way everything is set up. He doesn't like the dev database. So he knocks it over.. and while so doing it, he doesn't inform the team. And when I ask if something else is gonna knock over? No answer! (And something broke down too..)
Now we have issues to test our bugfixes. The whole thing took me half a day finding out and made me distracted with frustration, and not just for me. Most bugs could've been done in that half a day!
I so wanna punch the guy xD but no, I gotta save face, pfff!2 -
I just migrated Test data into Production. If I start a new project, Murphy's law indicates that my phone will ring, and the migration will have been a total loss.
If I sit and do nothing, Murphy's corollary tells me the data migration will be a success?3 -
Since I have seen a lot of people uploading this kind of stuff lately, here is Xiaomi's test in production, back in 2017 November...
 1
1 -
I'm genuinely shocked at the number of people I see on here bashing automated testing as a waste of time, simply because my entire career has taught me the opposite (and it's usually only non-technical managers I see who don't want to see "time wasted" writing tests.)
I'm also just as genuinely curious - what do you guys do instead? Just don't test and deal with production issues as they occur? Pass it off to a separate UAT / human-based testing department and let them sign it off? Assume that because you're using Haskell / some other discipline it'll work if it compiles?13 -
My company insists on working in one production environment to save time and every time I try to convince them to set up a work flow with a dev and test environment, they tell me we don't have the time...
Even after I set one up anyway as I'm scared shitless to touch production. They tell me it's faster doing it all in one environment.
They launch an update. Site buggy as hell and doesn't load 90% of the content...
Sigh....4 -
So, you have to build an app for your company. Once it is done you submit it for the test team who ignores it completely. Then they assume that the best time to test it is after the production deployment and then everything becomes a urgency.
The best part is the PM trying to make you feel guilty about leaving after 12+ hours of work because you didn't finish everything.1 -
Optimization issue pops out with one of our queries.
> Team leader: You need to do this and that, it's a thing you know NOTHING about but don't worry, the DBA already performed all the preliminary analysis, it's tested and it should work. Just change these 2 lines of code and we're good to go
> ffwd 2 days, ticket gets sent back, it's not working
> Team leader: YOU WERE SUPPOSED TO TEST IT YOUR CHANGE IS NOT WORKING
> IHateForALiving: try it on our production machine and you'll see the exact same error, it's been there for years
> Team leader: BUT YOU WERE SUPPOSED TO TEST IT
Just so we're clear, when I perform a change in the code, I test the changes I made. I don't know in which universe I should be held accountable for tards breaking features 10 years ago, but you can't seriously expect me to test the whole fucking software from scratch every time I add an index to the db. -
So, we (I'm the backend guy and work with a UI dev) are building this product portfolio management tool for our client and they have a set of 250 users. The team has two point of contacts for the 250 users who maintain the master data, help users with data quality, tool guidance, reporting and other stuff. So one day one of these two support users come to me and say : Hey I'm not able to add new transactions coz a customer is missing.
We have the provision to create / maintain customers.
I check the production DB, application code, try creating the customer and then the transaction, everything works perfectly fine.
I ask the user for a screen sharing session, the user starts reproducing the error like this :
We have a 3 system landscape - Dev / Test and Prod
U : Logs into the test system url, creates the customer.
U : Points out the toast saying customer creation is successful.
U : opens a new tab, opens the production system, tries creating the transaction, searches for the customer and says " see !! cant find the customer here ! the master data management apps never work !! "
FML?. -
Take over responsibility you fucking morons!
We are the engineering team and we cannot know how you operate our product in every detail. And for god's sake don't blame us when shit happens in production when you don't test upcoming deployments by yourself! -
When your staging/test server dies just as the boss wants a big update completed. Straight to production it is!
-
This is just a sweet little harmless block of code, why should I unit test it?
3 months later...
Bug in production : This is why. -
Ok so some of you have probably seen my previous rants about my computer science teacher and our project but I'm just going to summarize all of them and share with you more of my pain.
1. He edits in the production environment. Its a laravel project and he is creating test database migrations IN THE PRODUCTION ENVIRONMENT AND SWITCHING BACK AND FORTH FROM MASTER AND DEV.
2. He edits in vim and doesn't follow codestyle even though I printed him off a piece of paper and emailed it to him.
3. He doesn't have any ethic when it comes to more complex things like laravel homestead.
4. He doesnt want me to release features even though he takes really long to do them.
While I love vim and it is my editor of choice, some things should be done in an ide. This is really annoying me and I'm really just considering handing him the project if he can't follow basic outline.3 -
I have a web app that is currently running on a production server with no issues, but at the same time, it isn't working on my machine which I used to write, test, and deploy the app. The thing is, I haven't touched the code for a full month.
Now, I know this has to be logical and that there must be an reasonable explanation for all of this that I do not know yet.
However, and out of frustration, my mind wants to believe that there's some sorcery involved here or that a cosmic ray has actually penetrated the machine and messed its registers.
Damn the cosmic ray!3 -
BI guys ask us to avoid deploy on Fridays cause they don't have time to fix their stuff.
"We cannot test until it is live..." They said.
I hate guys who prefer production driven development.2 -
While smoke testing in production, I had to delete the sample entity I created to test the released feature, which is not a big deal
Until 20 minutes later, when I realized that I attached a couple of sub entities under it that contained actual live data1 -
Build pipelines are awesome. What's not awesome is forgetting the 'pipeline' bit.
Sure, let's have each TeamCity job in the 'pipeline' build the deployable from different places! You must manually merge your code from dev to test to release.
What's that? The functionality working in dev isn't there in production? I wonder how that happened. -
Can someone relate to it? We have a very simple process:
1. Create a ticket 🎫
2. Specify the requirement 📑
3. Assign the ticket to a developer 👨🦰👩🦰
4. Optional: make a meeting with the developer and go throw the specification if it is a complex feature 🗓️
Under pressure it looks like this:
Someone tells you to implement the request as fast a possible, no written specification, in best case you get a brief email 📧 also the feature has to be available asap in production and they is only poorly tested...
Or they want to test in production because the data in test system is "missing" ⛔☢️☣️
It is so annoying that is so difficult to stick to such a simple process 😭 it really freaks me out 😒😫12 -
Did you ever had to integrate a fucking "API" that is done via mail bodies?
Fuck this shit! Who need responses about success or failure?! Guess this will take a long time to test this fucking piece of garbage... We don't get a test system, we need to test this with the production system of the other company. I hope their retarded application crashes when receiving malicious mails.
Not speaking about security, I bet everyone can send a mail to their stupid mail address and modify their data 🙈
And inside of this crap mail you also have to send the name, street and email of their company. Why do you fucking need this information?!1 -
I just had the most embarrassing moment in programming... I am writing an administration / client / invoice webapp and I was testing an export function that worked locally, because everything that was being exported was inside the folder.
So I exported the files in test production, but some invoices didn't exist. So when they don't exist, the system creates a new invoice.
Because I was running on the test production (with client data) the system emailed the created invoices to the clients.. now I have to contact some clients and tell them the invoices were sent accidentally.2 -
So I'm currently "assigned" a task in which I need to fix a slow query problem, which isn't a big deal. The biggest problem is that the original team of this project haven't got any means to develop things on your local machine. Looking at their docs and scripts, it seems like everything is deployed to a dev server. But whilst looking for details for this server, I found out that the network team have decommissioned the server!
So my dilemma right now is that I can't test any of my fixes on anywhere besides staging, or possibly production! Inheriting projects is the bloody worst!5 -
So I get a message from my ex-colleague today, and it’s déjà vu all over again.
Apparently, the CTO at my old company went full Hulk in the office this morning, demanding to know who used the ops@ email to subscribe to something called "custom purring ASMR." If that sounds familiar, buckle up - this one’s even better.
For context, this is the same company where I once had to explain to the CFO why our tech@ email got invoiced for "panties juice, extra virgin." If you don’t remember… Yeah, I left, but the shenanigans clearly stayed. Here’s a spot-the-difference picture: https://devrant.com/rants/6213132/...
Turns out, one of the devs was testing an API integration for some niche subscription platform. Nothing new there — sandbox environments, dummy accounts, €5 test payments. Except genius over here decides to jazz it up and names the testing account: "Cat Daddy Deluxe, meow to pay." Obviously not meant for production, right?
Fast forward to yesterday (yes, Friday): the platform goes live without clearing the sandbox database. Dev’s test account? Now the default subscription for every new creator. Not only that, but every 1k subscribers it "wins" a discount for the next most popular account. What are the top 5 other popular accounts?
5. "Leather Daddy Lullabies" – soothing bedtime stories narrated by a guy in full BDSM gear.
4. "ASMR For Adult Toys" – exactly what it sounds like, but HR will still ask.
3. "Moaning Meditation Mondays" – very NSFW guided mindfulness exercises... weekly!
2. "Kinksploration 101" – a podcast exploring bizarre fetishes you wish you didn’t know about.
1. And last but not least, "Spicy Grandma Diaries" – erotic stories written and narrated by a sweet old lady from the local senior centre, apparently depicting real-life escapades from her 70s. In great detail.
Here’s the kicker. Friday, ops@ gets two discount emails. The same guy who roasted the “panties” girl the hardest, the very one who caused this mess, is now sure they’ve finally sent him more accounts to test - because clearly, those can’t be meant for production. Right?
Long story short: he spent €118 of real-life company funds, and IT is now on the hook for lifetime memberships to “Purring Dominance 101” and “Whisker Tickler Masterclass.” How satisfying is it to see the universe balance all his not-so-funny comments?
Also, I’m definitely getting them to forward me those whisker-tickler classes. No matter how good you think you are, some areas of life always have room for improvement.4 -
I think UPS' Api documentation and service must be the worst documented and build API I have ever seen from a corporate.
1. The developer website is a mess. A total mess. You can barely find the API type you are looking for.
2. When you get the API and download the documentation, the files, .pdf etc is still a mess. Pages long that most are craps.
3. Each request returns Status Code 200. Even if it is an error. This blew my mind.
4. Each request, based on error type or based on tracking activity returns different JSON schema.
For example, the JSON Schema for a shipment in transit is different from JSON schema for a shipment that has been delivered. A shipment that has been returned, a shipment that required signature etc. They are different from each other.
5. And the worst. They do not provide with test tracking codes. I have found some on internet, but they do not work in development and production environment.4 -
Our client wants us to deploy all changes to the test server & to the production server at the same time (-___-)
So all bugs which have been founded after that should be hotfixed ASAP :/2 -
URG!
I cannot think about a title, so just story:
in my position as multi headed chimera one of my ongoing task is it to dedust old excel sheets, processes and other super inefficient relics that steal time. Mostly i solve those with some tiny vba scripts, bigger vba scripts or a tiny java applications. usually that takes a few hours or maybe two days, depending on what i think is necessary.
the current task at hand is for our (physical) production, work time is noted on a sheet of paper and later given to the production head. Who then proceeds to type it all in excel to do his thing. The guy is starved of time by a huuge margin.
So, crafty kangaroo that i am i think: a barcode scanner, some raspberry pis with touchscreens and some mediocre php/mysql/javascript will make our worries go away. of course this will be a longer task but there is no need to have it done immidiatly. So crafted a working prototype, presented it in the weekly company meeting and got it "greenlighted".
The other day our CEO-like guy was ranting that nothing in this company gets ever done and that people wasting their time with useless projects and named my project among them.
I dont get humans. First he gives thumbs up for this, knowing that it will probably take me 100 hours or so to create in a working manner but later he calls it "a waste of time?" I presented the use (reducing expensive mantime, paper waste and room for fudgery) and yet he calls it useless? (well, his point was that there are other problems (which are out of my reach anyway))
they guy normally is pretty nice and has an ear for problems, but when it comes to higher computer stuff (>excel) he really struggles.
:/
i really like my side project, gives me room to flex some muscles and test stuff. Also playing with raspberry pis on worktime.
On a sidenote, anyone ever tried raspi mesh networks and knows where i get working >10 inch capacitive touch screens? -
A developer couldn't get a application performance monitoring (APM) tool to trace his application. They claimed that their libraries and their configurations were alright and that the APM tool was non-performant.
The developer then argues with sysadmin that the APM tool can't trace the application and that there's nothing wrong with the application or the configurations. When sysadmin questions whether the developer got the tool to work anywhere, they say, "No" and head off to make it work at least in one place. They come back saying that it works on their development environment (which is their local machine). Sysadmin claims that the system configurations on the server instances cannot be matched by the development environment and there could be a lot more factors to be considered for the problem. The sysadmin asks to prove it on a server instance on one of the test environments and then they'd agree that it is a problem with the tool. They also argue that this is not the only application that uses the APM tool and the tool happily traces other applications with no issues.
The developer tries the same configuration on a staging instance and fails. In order to make it work, they silently uninstall the existing version of the APM tool and then compiles an unstable branch of the tool. It finally works with this version.
They go back to the sysadmin and show that it works on the staging environment, but does not on production. After banging their head on the wall for a while, the sysadmin figure that the tool had been swapped out for the unstable branch that was manually compiled. When questioned, the developer responds, "It works with this version on staging, so deploy the same version on production"
WTF? You don't deploy an unstable branch to production. Just because you can't make it work on the stable branch doesn't mean that it is the problem with the tool itself. There's a big difference between a stable branch and a non-stable branch. How would you feel if the sysadmin retorted by asking you to deploy the staging branch of your application to production? -
==============
Getting Feedback Rant!
=============
When "this is simpler" feedback results in a function of 500 lines of code.
When I get "don't do X" in the feedback. Thank you very much. What do you want me to do instead?
Unclear feedback.
When the feedback giver changes his mind after I applied the changes!
When applying the feedback introduces a bug.
Simply opinionated feedback that is not enforced by any tool or backed up by any facts.
Please find something better to do in life.
Unactionable feedback.
"Consider X"
I will not consider thank you very much.
"Verify this works"
Duh..
When the feedback giver knows something that you don't.
I know this is a legit case.. still annoying.
"I disagree with the feature"
Go argue with the PM, not relevant to me, thanks!
=====================
GIVING FEEDBACK RANT
=====================
I rewrote the system. Please review it.
No need to review, just approve.
I will change this as part of the next ticket.
I would like to keep it the way it is.
lazy ass..
You can't test this.
It's impossible to test this.
No need to test this.
There's no point to test this.
I'll test this on production.
Not sure why this is working..
Please document this..
Because documentation is like a thing, you know.
Oh, this code is not related to this PR, I just don't want to open a new branch for such a small change. ignore it.
Ignore this.
This will be meaningful in my next change. -
A customer asks for a change request or a bug fix and it results in creating a ticket for that.
It's the process and how it works in most places but after you finish with the task and fix the same customer who provided you with the requirements will request that you share the steps on how to test the fix or the feature.
I'm not speaking about the data preparation or required configuration. I mean a step-by-step instruction on how the tester/QA will test it.
It's driving me mad!! So a way to counterplay this stupid requests, I provide the happy path and what to expect. And in case, they stumbled on a bug later in production, I can easily say "It was approved by your testing team and that's a new requirement ;)"2 -
While addressing a Senior Dev's (SD) query from another team.
SD: why is this field mandatory? Can't it be just optional? Any other work around?
Me: Is your code changes already pushed in Devo? In that case, we provide a value which will work since you are not concerned about it.
SD: Yes. It's pushed till production. And, I want to test changes in Prod.
Me: (shared some codes) and explained that this feature for testing is only available in Devo.
SD: I know that. (Shared me a ticket) I want this field to be optional. That's it.
Me: (read the entire ticket. Didn't find anything related their) Told him, I will discuss with team. And meanwhile, for Devo, you can use this value.
Next morning, I accidentally came over some other ticket raised by him only which had the correct doubts regarding request to support this field in production
Now, I don't know why did he share a wrong ticket with me.
And, how will it even help him if that field was even optional.
THAT JUST WONT WORK IN PRODUCTION.
I will discuss with my team and see what can happen. -
Friday, forced deploy day for last & current months work. Been stockpiled due to holiday.
Yesterday boss demoed the product to clients so they expect to test today.
Early o'fuck this morning, a coworker managed to drop all secrets and env vars from CI pipelines and trigger a deploy leaving production broken...
It's gonna be a long and busy Friday... -
So much has happened, I've been learning things, I got robbed, I discovered I love test driven development, my laptop fell downstairs and is now screenless, I'm still on this project and still have not gotten the source or gone live, side work exists though so I get to make some more money, car engine needs to be overhauled, project extended still not in production. Send Help.
-
Debugging a task, that's sending emails to too many customers.
Supervisor: "Never mind, just test in production, there is a dry run flag for the tasks."
Just in case I test locally...
Flags tried:
--dryrun="TRUE" => Error, failed to send mail.
--dryrun=TRUE => Error, failed to send mail.
--dryrun="true" => Not trying to send mail.
If it's THIS PICKY a little more documentation would be nice.
And by a little more I mean: more than the task base class in a giant php monstrosity without phpdocs expecting its code to be self-documenting. -
Finally made my node production server stable enough that I could focus on writing tests*. I start by setting up docker, mocking cognito, preparing the database and everything. Reading up on Node test suites and following a short tut to set up my first unit test. Didn't go smoothly, but it's local and there are no deadlines so who cares. 4 days later, first assert.equal(1+1, 2) passes and I'm happy.
I start writing all sorts of tests, installing everything required into "devDependancies," and getting the joy of having some tests pass on first try with all asserts set up, feels good!
I decide to make a small update to production, so I add a test, run and see it fail, implement the feature, re-run and, it passes!
I push the feature to develop, test it, and it works as intended. Merge that to master and subsequently to one of my ec2 production servers**, and lo and behold, production server is on a bootloop claiming it "Cannot find module `graphql`". But how? I didn't change any production dependencies, and my package lock json is committed so wth?
I google the issue, but can't find anything relevant. The only thing that I could guess was that some dependencies (including graphql) were referenced*** in both, prod and dev, and were omitted when installed on a prod NODE_ENV, but googling that specific issue yielded no results, and I would have thought npm would be clever enough to see that and would always install those dependencies (spoiler: it didn't for me).
With reduced production capacity (having one server down) I decided to npm uninstall all dev dependencies anyway and see what happens. Aaaaand it works.....
So now I have a working production server, but broken local tests, and I'm not sure why npm is behaving like this...
* Yes I see the irony.
** No staging because $$$, also this is a personal project.
*** I am not directly referencing the same thing twice, it's probably a subdependency somewhere.2 -
How fucked up are you,
when your vp of engineering doesn't even know how to show phpinfo webpage to test server setup.
and..
change ode directly in production server,
then messed up and using excuse :
" I don't know because i am a frontend developer "
Then why you become a VP of Engineer !3 -
My Office Sucks. They give me impossible deadlines, and never properly test my code. And when it breaks in the production, they blame me.5
-
A remote team decided to annoy me by trying to hold me accountable to their project plan timelines while not delivering a viable API. So, I code reviewed them.
NOT ONE FUCKING TEST! They are "meeting the date" and will "fix it later".
They beat me to production though.
No wonder they argued that a complicated, fragile, expensive, multi-product flow test was absolutely required.
I returned the escalation favor. -
Today at work I started doing 1 month old task with production problem.
First of all why now ?
Because I already fixed all the other urgent production problems I had during last month, done about 4 deployments of those super urgent errors.
Now I can start with not trivial one that are pending for quite time.
I am the only backend developer in this project ...
This is a dtp application and the problem is that we are not verifying if we got all fonts embedded in customer provided pdf files.
We are generating high quality images of those pdf for printing just fine from the beginning but now we need valid PDF with all fonts embedded in it. ( don’t ask me why I am only a hammer in this process )
After running simple test using python script against database it turned out we have over 500 broken PDF files without fonts.
So I guess I have just one sentence to say about it.
Fuck you PDF format for not being strict and allowing this shit. -
The downside of writing reusable, abstracted, DRY code for multiple applications to use: you have to remember to test changes in all the contexts... my org has to hire contractors project by project as we dont have the budget to have more devs than just 1 (me) on permanently. the contractors tho often don't know about all the places our code gets used. And sometimes I even forget - last week in the rush to finish some project, we forgot to think about how a library change made for benefit of a new project a few weeks ago might effect an older (in production) project. Until shit started breaking. Annoying. very annoying. luckily i fixed it (rolled back) before the weekend, but thursday and friday were quite stressful... now tomorrow, a bunch of sleuthing time to figure out exactly what recent change caused it... argh....3
-
So, someone from support department asked me to check the app as it was displaying blank information on a page.
I started debugging on the api which i found is doing the proboem. I checked and it was working a moment before but not now. Switched in debug mode to see what went wrong and it works again. This happen multiple times.
Before doing anything else i asked our api developer to check if api is working. He said it should work now and problem has been fixed.
Later i found out that he was doing debugging/changing code on production server instead of his local machine or test server. -
Was given 2 bugs to solve and after 1 day and half someone remembers to tell me that what I'm trying to fix won't work cause the issue only happen in production an I won't be able to test it with the connection that I have...
-
Confession: a very important feature of the website I'm developping wasn't working for a certain time. The boss wasn't aware because he doesn't go on the site, and I only found out last week because I needed to implement a new feature that used the previous one. Problem: the bug was only on production, not on local (and of course we don't have test server).
I took advantage of the absence of my boss today to clear the situation by making all of my tests on prod. I hope no customer tried to pass a command today, but it's finally repaired. I am both proud and shameful.3 -
i fucking hate react and don't understand react
Is it cleaner to have useContext to pipe in override test data for storybook and write an outer context for that code only? Real production code can ignore and not set this.
Can child component onHover update parent's stateful variable to unpause the urql/graphql datafetch in parent data wrapper component. Parent pipes queried data to child component to properly display on hover that kicked process off.10 -
Storytime.
once upon a time, there was a dream: we need to test the vagrant setups for our Devs, so that they can run these against the production environment of puppet without problems.
in the year of 2016, the once lone ranger - our team lead - created the ticket. don't. even. ask.
the idea was to build these vagrant setups via bamboo, log the results and fix the setups afterwards.
after weeks of brain fuckery (aka daily business), home office madness, beer, java specs, more beer and many failed builds, I made it.
bamboo now builds the fuckers via a dedicated agent now and I closed the ticket today \o/. -
3 weeks ago
Client: when can we go in production, we want x and y
Boss: 13/12
Absolute Silence
Today 8/12
Boss: how long will it take for bringing this in production on 13/12?
Me: I'll do my best to get it ready on time
Boss: Why will it take 2 workdays?
Me: because client asks x and y
Boss: so?
Me: x and y is not ready
Boss: x and y can' t take two days, it must be ready now
Me: You said 13/12?
Boss: client wants to test before production
Me: ... 😡
Where did things go wrong here?7 -
TL;DR: fear of bricking my laptop due to typo pinning.
The worst nightmare i am living in right now...
I was noticing i did need some software in sid so i decided to use apt pinning for said software...
I configure the system, ok test looks good... I push it to production, run it on the system....and the nightmare starts.
Lits of packages get updated, and i am screaming 'noooooooo' since debian sid softwarz can sometimes break everything! I discovered that i did test my apt pinning config for the presence of the amount of numbers, but not at their value... Sooo, by accident swapping pin numbers for stable and unstable you get... Your worst apt-get update nightmare...
I hope it does not become a brick.1 -
Last week we were only one step ahead of going in production mode with the angular web app i coded a half year long. Sounds good right?
Yeah this morning my boss said in the dev Meeting, blazer is now in preview mode, let's do it with this tech, so our full stack is in c#...
He is not a web dev. He want to step back from coding in the near future, but yeah let's use fucking Blazer 😥
For the rest of the day, i started with a Blazer Test Project.. great start into the short week.
How about your start?6 -
Hell of a Docker
One application in c++. 4 in c# targeting Linux. Several logging places, Several configuration files , dozens of different folders to access (read/write). Many applications being called from just one that orchestrates everything.
OS is Linux. Installation is to be made inside a docker image and later placed in a container by means of several bash files and python scripts. All these are part of a legacy set of applications.
They’ve asked me to just comment out one line which took 3 days to find out because they didn’t remember where it was and in which application it was and what was in that line.
After changing it, I was asked to create a test environment which must have resemblance to the current server in production. 12 days later And many errors, headaches, problems with docker, I got it done.
Test starts and then, problems with docker volumes, network, images, docker-composer, config files and applications, started to appear.
1 month later, I still have problems and can’t run all applications at least once completely using the whole set.
Just one simple task of deploying locally some applications, which would take one or two days, is becoming a nightmare.
Conclusion: While still trying to figure out why an infinite loop was caused by some DB connection attempt in an application, I am collecting a great amount of hate for docker. It might be good for something, that’s for sure, but in my experience so far, it is far worse than any expectations I had before using it.
Lesson learned: Must run away from tasks involving that shit!5 -
Helping out a team, I was documenting some code/processes when I came across several classes that was logging a lot of, IMO, 'junk' that was unnecessary (and I knew wasn't being used in any Splunk alerts/reports)
I offer a refactoring suggestion, simplifying the data being logged, moving the duplicate code to a central location, maybe saving 10~20 lines of code. Didn't think it was a big deal because they were already actively working on the code and it was all new code (nothing deployed to production yet). Sent the suggestion to the lead developer and he responds:
Dev: "Yes, the changes looks fine, but not in scope of the project. Any out of scope work will need to be suggested at the end of the project, reviewed by the team, the project manager and approved by the vice president."
"Out of scope"? Logging data to Splunk needs a vice president's approval? WTF?
YOU PROBABLY HAVE THE PROJECT OPEN IN VISUAL STUDIO RIGHT NOW!!!
Along with the documentation the lead dev said they didn't have time to do, I send his boss and the dev team my suggested changes (before-after screen shots of the code) and offered to do the 2 minutes worth of work (again, this was new code, nothing in production and zero side affects to anything).
I even offered to create the splunk reporting/alerting against the data being logged (another item they said they would not have time to do)
About a minute later the lead dev responds..
Dev: "Those changes look good. I'll have Jake make those changes and we can test the logging when we deploy to dev on Monday. Thanks!"
Of course you will...fracking ass hat.
I'll bet my Battlestar Galactica DVD box set he was going to make the changes himself, brag to his boss how he refactored the code, saving X lines of code..blah blah blah to help *me* with documenting the logging portion. -
How do you manage production, development and test environment in iOS/Xcode? Any good sources out there? 💻2
-
Why? As a senior, you won't give some time to review my code, will let me merge my code to a branch, then blame us when it will produce the bug in production? why? 😐 Won't even arrange a code review/knowledge sharing session so that juniors can learn at least something. Even you won't encourage us write test cases. If seniors don't follow, are the juniors to blame? 🙂3
-
Stupidly tested some sql on development to return results for an admin (see the whole results) and stupidly didn't test the where clause for generic users (only see a subset of data)
To find out on production the where clause was being run because it wasn't a where, it was an 'and' and 'where' was not being used before so made the whole users get the entire results.
My own fault for not testing all use cases. Horrible though.2 -
/**
* Refund Test Assert
* If this block makes it into production
* I made it as a developer
**/
for(var sub : subscriptions)
if(sub.hasEnded()) refundCustomer(sub.Id);1 -
Oddly enough, i have simultaneously been less busy and more productive since working 66% remotely.
I find myself with more time that feels "wasted" or not busy, but my metrics show that I have more production, better results, and far nicer documentation. A bunch of us also sat down and did a bunch of coursework on really putting together a domain script library for one click onboarding of new servers or new client setups. We spun up a bunch of new virtual environments that literally solved headaches that had existed for years that never got dealt with because of too many other tickets.
Some of our web clients freaked out at us because the business is moving away from doing maintenance of legacy web work (small to midsize businesses). But it didn't matter. Rather than respond with a "make them happy," the response was "well, we will get rid of them as clients. We need to focus our energy on the essential service sectors we support."
Hell, we even got an automated test that has been broken apparently since 2018 to work again.
Granted, the incoming workload has slowed down. But it's still interesting to me to see that despite the slowdown, there isn't any concern; its still paying the bills and we are getting rid of technical debt everywhere. Tbh, this has really been a good reality check.1 -
Sometimes I don't get "don't test on production".
And I'm definitely not a front-end guy, I only have debug and release in mobile development.
And I definitely often test on release, because it may be broken while debug build works fine.
You know what that means?
1. Test locally
2. Try to fix issues
3. Realize that this issues would ever appear ONLY locally
4. Move to staging and test
5. Fix issues
6. Realize that most of them are caused by workarounds for localhost
7. Move to production
8. Realize that everything is fucked up and you don't have any idea why, because `h5aqq2 was called on null"4 -
So nice, a good, well structured DTAP environment with Acceptance and Test containing a recent dump from Production so that bugs can be reproduced properly........ *wakes up*
-
Well, yes. My boss accepted my 'test' project to be build for production use, stack is Laravel, Vue, a little Python.
It is divided into phases where as I have now month and a half to finish phase 1.
You agree I will finish the first phase in time? (24-2) Keep in mind I still have other projects I'm working on.9 -
Sometimes, certain features don't work in my app if it's uploaded to the production track in Google Play.
It works in debug mode.
It works in release mode.
It works in the internal testing track.
...but it won't work in the production track? Y'know, the one that actually matters? Theoretically, there shouldn't really be a difference if the same exact APK was uploaded to the internal testing and production track, but... idk dude.
As a result, I implemented a secret way to test a feature in the production build (it's an app to remotely control OBS Studio): if the first connection you added is named "yayeet_" and you open the disclaimer, it tests the feature. Luckily, I got some of the stuff figured out, but I just thought the way I had to test it in production was dumb.1 -
reading test strategy of work done by my senior whom i respect, which goes something along the lines of:
"putting this into production and praying"
i dont know how to feel7 -
When you spend hours in a messy codebase to fix a bug properly and add an integration spec to cover that specific case.
And even you do a round of testing on staging + providing screenshots, there is always someone on the team that will write in your PR, "It works, I tested the change on my machine".
I understand that some people are skeptical but to the point of not trusting integration tests + screeshots/recordings then please test it on staging or production next time because if it works on your machine doesn't mean it will work there ;)2 -
When you roll out a new system is disaster recovery testing on your roadmap? For example, do you do failover and have users work through a comprehensive test script and have them sign off before going into production?1
-
What are staging systems for?
In my opinion (and of my dev co-workers): that everyone can test the software before it’s being deployed to production.
PM (at least based on how they act): that we devs test our software. They will test it when it’s live.
Today: cookie banner was missing, and the page has been on staging for around 3 months and it already has been live for 2 weeks.
No. One. Noticed. That. On. Stage.
Ridiculous.4 -
Dealing with government bureaucracy today. Prepare for pure anger.
First of all, what fucking dipshit site does testing and maintenance in production without letting users know? Bitch I'm getting an invalid date error when I use your own stupid date selector and I had to waste the office lady's time asking about it because you couldn't be arsed to either test your shit properly or actually take it down if it's broken. Who made that stupid ass decision and why the fuck did nobody question it. Fuck you.3 -
fix bug
test production
can't reproduce bug
support tickets and people still bitching they have the bug
i think the shit's been merged and deployed long enough it should've rolled over considering the timestamps on follow up cases3 -
A while back I was looking for a new job and was given an interview by one company who shall remain nameless. Before the interview, they asked me look through their current site, nothing unusual there, so I started browsing. Then I received an email with all the details I needed to access their production server. Apparently they wanted me to look through the code, unusual but I did so.
First thing all the passwords, including those belonging to members of the public were stored in plain text and many were still the default passwords which were based on the Id so were sequential.
I highlighted these issues at the interview and they then asked me to do a test, not the usual test though, they asked me to add some charts to their prod site. Needless to say that didn’t happen and I got another job elsewhere.1 -
I'm tired. I don't want to do these tests anymore. These vague test scenarios I have to decrypt on my own lest asking business shows signs of weakness. I'm slow to test and going way beyond the hours the client estimated and you folks just accepted. How can I finish this when I get pulled to meetings which I am not the decision maker but I'm supposed to be the technical one to help them decide. In between this testing I get emails to help check on issues I'm not even a part of. Production issues I can understand because those have a feel of critical and priority but if you pull me to that I lose time testing. I'm trying. But I'm truly very slow at this. I'm a slow tester for this set of test cases. I'm hating myself every minute as the hours inch to the deadline which is today. I want to sleep but I want to finish as well. Shitty days of drone work that could have been given to somebody else but I can't say no to because you guys accepted. Someone from management just see please, don't give this to me. But you can't see. You probably don't even understand. They asked, you caved because you can't see the list of tasks and level of detail that comes with each thing they ask. This testing is a ridiculous use of my time but I can't say that to the client. You could have. I want to. I truly want to say "Fuck these tests". I tried to push back. But the client of course reasoned back and it was understandable to ask. To do what's good and what's best. How can I say no to that?! I'm almost depleted. I'll just finish this somehow.
-
Friday: Run your security test on production after hours.
Saturday: Wait, do development instead.
Today: Ya know, development is a critical environment too. Just don't test anything at all.
🙄 -
So a third-party service that I implemented is going to production and me and the PO were testing that yesterday, didn't see any orders coming in the service backend.. so we send a mail to them.
This morning they respond with saying that they can't have both the test server running and the production server...
What the hell is this... :/3 -
A dev decided to overwrite the master branch with his code saying its better. That it fixes the major bugs that all of us couldn't solve.
Against my better judgement of firing him, I decided to test it.
Firing up the testing site, we made test databases to use and we went to house.
In the middle of testing, I noticed the test DBs weren't being changed. While everyone was still testing, I looked at the code. It wasn't made to test on any databases, it was specifically designed for the actual production server.
However the damage was done. In a secret dashboard in the code, someone sent instructions to drop the tables, effectively ruining the production server.
We had the dev go to an offline backup site that only went online every 10 minutes a day to make new backups. So we shut down the production server, setup a maintenance page. I get my ass chewed out again, and we were sitting ducks.
I don't think the dev had enough punishment, so I grabbed his laptop and made a full backup of his data, and locked the SSD in a safe.
I downloaded a Windows 98 and put it on a flash drive. And installed it all on his SSD. The dev is now a proud (pirate) owner of Windows 98.
He came back and started balling on his desk. We all looked at him with a pity, but he deserved it.
I'll give him the drive on Monday.
Do you think he learned his lesson?7 -
always the same, while im in a part of the system, i notice an optimization that can speed up a major query which has to join a table which is about 4gb or something ridiculous. i make ammendments using partitions because they're in the defined on that table. test. everything cool. only to be told that theres no job to clear out old partitions so i end up reverting everything i've been doing which basically makes my day's total output == bollock-all. WHY DO WE PUT HALF BUILT SHIT INTO PRODUCTION!!!???2
-
Where to begin?
- I purposely overestimate because I can get away with it in current job
- I test in production like 50% of time in current job
- I deploy during working hours
- My javascript is a sphagetti monster in current intranet implementation and I am sorry for the next future maintainer after I'm gone...1 -
Only when the latest feature is implemented, the last bugfix and the last workaround are found, the last unit test is written, the latest CI/CD pipeline done, the customer guy does manual testing and acceptance tests on the staging server and let's them pass and a few days later it's pushed to production...
You will be reminded (again) that shitty customers do exist! A customer is the least capable person to tell you what the customer actually wants and is also the least trustworthy person to test the features he requested...
Holy fuck come on! Just test that shit on the staging Server! One Look could have already shown you that that's Not what you expected!
I checked the logs after that and yup you guessed correctly... The said endpoints weren't even used on staging, only on production...1 -
Dumb mistake from when I was still working:
My work laptop’s SSD went haywire, and I/O would spike every 10 minutes or so for ~50 ms. The hardware guy said he could replace the SSD right away, or I could endure it for a few weeks and get a new laptop instead. Obviously, I agreed to wait. The stutter noticeably affected screen rendering, but I didn’t notice any other issues. Little did I know that every time it happened, all input was ignored (as in: not queued). Normally it wouldn’t matter, because hitting a random ~50 ms window is hard. How-the-f×ck-ever…
A few days later — without getting into “why” — I was forced to apply a patch in production. So I opened an SSH session to prod in one terminal, spun up a dev environment in another, copied the database schema from prod to dev, and made sure to test everything. No issues, so I jumped to prod, applied the patch, restarted services, jumped back to dev, and cleaned up the now-unnecessary database. Only to discover that my “jumped back to dev” keystroke didn’t register.8 -
Released the product to customers without realising someone had pre-filled a production test accounted login at the login screen. Obviously it was used for testing purposes and the dev forgot to remove it before committing.
I loled when I found out about it, and some customers started to login and made transactions.
When I checked the commit history... It was under my name :/2 -
As part of a technical test, I've been asked to test and report bugs in the production application of the company. Is that normal? Or are they making me do free work for them?.
So far I've only seen challenges like this to be done on a custom application for test.7 -
Tfw you find a comment saying something needs to be tested when the system is in prod.
Narrator: they did in fact not test it when the system was in production -
Just after feature launch, major bug on production and now I am getting yelled at by my lead as the issue happens to be with the PR i was responsible for reviewing yesterday. Somehow a logic error got past my review. But considering how large the project is it wasn't possible for me to test out every possible scenario myself. They should have had QA handle that. Also, that was my first code review. I can't understand why my boss has such unrealistic expectations. Bugs are expected at this stage. I feel like he just puts too much pressure on me for no other ther reason other than to just trigger my imposter syndrome. That way, I feel like a bad developer even though I am working my ass off. And he gets to avoid giving me a raise. Cant believe I rejected multiple offers to stay at this company. I don't even know why am I still working for this company anymore.3
-
Somehow mocking xhr requests (?) for Axios is really hard to make it work. I use React Cosmos as I'm re-doing the frontend of this already running in production and works great, but when my component communicates with the backend it breaks and I'm unable to test the full behavior.
Then, it occurred to me that trying to mock Axios may not be the best. So I came with this scheme where I would have a configuration variable with a default value and change that when I need to work with React Cosmos, which in turn changes the behavior of `/auth` to return a valid JWT in response to a GET, put an Axios interceptor in my outermost Cosmos decorator and BAM! suddenly was able to develop and test my React components closer to how they would work in production.
It surprises me how simple this endeavor was, and because everything runs orchestrated by docker compose things run smoother.
(this is not an excuse to not to learn how to deal with the mocking issues of Axios, after all I wont have a working backend every time I work in some frontend application)5 -
Testing new server deployment in test env all works, then production it all breaks down. Network didn't allowed the right traffic. Took me whole week to find that out. Until some networking engineer said, you know there is a firewall between those networks?
-
Sure boss, we don't need staging. Let's just copy some tables from our customer's server to our testing machine, overwrite our data with theirs and start testing "simulating" their environment. It's not that we need to test for our production, right?
-
Who inside BitTitan is doing live testing on production? Would you kindly revert the changes and do testing on a test environment? I've seen the 4 changes so far and they clearly not working.
Please we need to finish this migration 2
2 -
So I was writing SaltStack state for syslog management and I had a simple config file in place to be deployed on a test server. I was writing the command to run the state for the test server, and the only thing that was left was to type the hostname of the server (instead of wildcard) when someone interrupted me. After I got back to this terminal I instinctively pressed return sending test configuration to over 80 production servers. Nice one...
-
I had a client with an ongoing project. Everything was going fine until her boy-asshole-friend talked to me by phone... He was so ignorant.
Don't get me wrong. I'm not talking about the ignorant who doesn't know anything. I'm talking about the ignorant who doesn't know a shit but he is talking about it and refuses to get a professional advice. He told me explicitly: "Don't use test server for testing your project. Do it directly on production"
Unnecessary to say that my client "suspended" the project.1 -
There is no dedicated test team In the corporate our company outsources developers to.. so whatever the developers don't test themselves (and developers are poor testers for their own product) is then tested on... production? FML.. oh yeah and the quality of the bugreports - that's yet another story..
-
#define SOAPBOX
Data will contain errors and inconsistencies, and the only player that can detect them is: the computer itself.
if the computer detects that it is in a situation where it cannot meaningfully continue, it should not allow itself to continue.
Only the computer can make that determination.
If the software does not aggressively test its data, it is usually impossible to determine whether the problem is with the software or with the data or both.
Per contra, if it does do so, it becomes impossible to assert that the input data does not contain the issues that are being tested for ... a very important thing to be able to say in a real-world production setting, where hundred-megabyte input files are common.
#undef SOAPBOX -
Is there a unit test for dance moves? I really gotta see some green lights before I move this one into production. Side note: anyone have a UAT environment for this? Thx3
-
- Change this, change that too, oh and that too.
* Ok, will do ( however unlikely it's going to be finished correctly, as you didn't consult me before or listen to me about the impact this might have )
- ( just stfu and do it )
Sometime at or after important cutoff:
- Hey this doesn't show up, is that right
* Yeah, you wanted too many things changed at once + fix it and notice a stupid error like an && switched with a ||, or other models that don't know about change x yet
/repeat3 -
How to set the up a stagging environment for a github branch in heroku.
Lets say i have a master branch and a dev branch. All the changes and updates first pushed to dev branch and after successful review and test in goes to master branch.
But the issue is as i'm following the gitflow of keeping the master branch always deployable.since my heroku app is linked to the master branch, when i try to test the dev branch in production environment of heroku,sometimes it breaks for some error.and at that time the sites goes down untill i redeploy the master branch as it's the stable version .So how do i test a branch in heroku production environment while also keeping the the site active with master branch. it that makes any sense 🤡 plz help3 -
Is using CouchDB in production a bad idea? I built a small POC to test CouchDB and PouchDB's syncing abilities. Now I'm wondering am I setting myself up for tears if this gets implemented in production...2
-
We need to go live by this month 10.
Yep, infra is ready in production. You can push the events and see the results right away.
PM: Wow, great. Setup staging we need to test it.
Me: FML, staging machines are smaller, can't even start the program.1 -
Received 'Thank you' e-mail after Test Deployment and UAT !!
Usually i receive that e-mail after production and some issue findings! -
When you have a customer that is a pain and you have to do a new contract since months but they are no replying but at same time there is a bug in a plugin they are using.
They are not updating their plugins in production but only after a test in staging.
In production there aren't write permission from web server side, so only they have access.
And the plugin has a 0-day. -
!rant
Does ayone knows of a
+ Good
+ Open Source
+ Free
Data test generator tool?
I'm on my first work with a development that will go to production, and I'd like to test performance, UI and all of that with random generated data. I know about dbSchema but it's trial pulls me back -
I wanna know who use xenserver and why??
Currently am using xenserver 6.5 in a production environment and today i start to test xenserver 7. 1
1 -
A young new dev was working on his first ticket, about a bug during parsing of an uploaded excel file. Our issue was that if the file contained an empty line, all remaining rows were ignored. So the task included extending our tests to cover this case. After 2 weeks (!), his merge request comes in. His idea (without ever asking for help) was to parse the whole file (in some cases huge) in the production code a second time, just to count the rows (!!) and save the count in a public static int field, which was verified in his new test.2
-
I've been looking for an internship for the past couple of weeks and just had another interview today. I was given a simple code test that involved changing some of the features in a small program, nothing too challenging except that the program was insanely buggy and had a tendency to spit out the wrong result if you looked at it funny, and that was before I started touching it. I don't even want to know what production code looks like...1
-
We have a CRM running on an EC2 instance. We need to clone it so we can test a tool on the replica. We tried cloning it directly, sharing the AMI and creating a new instance through it but it always redirects changes to the original production server. The database is on the instance only and static files are stored in S3. Can someone guide me or share some resourses on how to do this.6
-
When you test on production server
"Your system folder path does not appear to be set correctly. Please open the following file and correct this: index.php"1 -
In my initial days as a web developer, i was assigned a task, to implement a cart share functionality in an e commerce company.
I made the functionality and tested on my system.
Result: working good.
Pushed it to beta testing environment.
Resilt: working good.
Pushed to pre production environment.
Result: working good.
Pushed to live site.
Result: 😀 Error in live site..
So a call comes to me from my team lead..
Asks what was the issue...
Me: i dont know either.
....
After 3-4 hrs:
I found the reason.
My system, beta test env, pre prod env are all having latest php version (5.6 i guess)
But the live server had old version of php.
Me: laughed like anything.
I didn't know that these things would matter in such a great level.
Moral of the story:
Be one with the force (server in this case)1 -
One nightmarish project that was doomed from the beginning, had me as the sole developer. I could hardly sleep when we began testing on a separate test system, but with (nearly) all the config stored in shared memory and copied from the production system, I dreaded, half awake, that the production server data base connection was still configured in the test system and that it was shooting all it's test data repeatedly to prod.
Finally drove to company in middle of the night at 4 o'clock. Checked everything was OK, tried to sleep 3 hours before the start of the work day.
This system also had the most hideous memory corruption in some shared memory that was used across several processes and should have been thoroughly protected by a mutex, but somehow, sometimes this crucial map, that was used to speed up the access to all the customer data just contained garbage.
Still haunts me to that day. (Like xkcd's unresolved tension of a non-matching parenthesis - an unresolved bug.

















































































































































































































































Top Tags
Weekly Rant
View