
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Boss: "I looked at a testing suite. It is $2,500 a license and I'm buying 60 licenses. You should probably get familiar with it."
LeadDev: "Um, we already use NUnit, and it's free."
Boss: "Hmm...I'd better add Pluralsight training in the budget so you can learn about the new program."
LeadDev: "Oh, no...we need new laptops more than we need software."
Boss:"New laptops? Not my budget. When we buy this new software, everyone is going to use it"
LeadDev: "Everyone? How will you monitor it's usage?"
Boss: "I'll have networking send me captures of all the running tasks on the dev machines. The test suite better be running. Writing good tests will be our #1 priority."
LeadDev: "Um, we already write tests using NUnit."
Boss: "I don't understand what you are saying. I need something I can visualize. This UI testing suite is exactly what I need."
LeadDev: "Maybe the testing suite would be better suited for you and QA?"
<click..click>
Boss: "Submitted the budget. There will be a test server available for you to configure. This whole project costs over $100,000, so don't screw it up. Any questions?"
LeadDev: "Oh...well...what server ..."
Boss: "Dang...sorry, I'm taking off the rest of the afternoon. We'll talk about this more on Monday. Get started on those Pluralsight videos. I'll expect a full training and deployments by next week. Have a great weekend!"13 -
Me: "We should remove that popup"
Marketer: "But our A/B testing statistics show a 14% increase in signups to our newsletter, and people who get our newsletter are 4% more likely to buy something"
Me: "0.14x0.04... so slightly more than half a percent improvement. And you also qualitatively measured how many people decide to never visit the page again, just because of that popup? Did you measure the how many internet users with adblockers run into a broken webpage? Did you measure the amount of emails to support from users who can't unsubscribe from the newsletter because there is no unsubscribe link?"
Marketer: "Why would they want to unsubscribe? The newsletter adds value to our users!"
Me: 😩26 -
Omfg this fucking guy!!!!
Context:
We are going through a major refactor of some of our backend components. I was tasked with cleaning up our ML code while another guy was tasked with cleaning up the general CRUD side of the backend, let's call him DA for "dumb ass".
** At 11pm
DA: I am getting a strange error from your backend. Look:
"Invalid call: method=PUT expected=[POST]"
Me: you need to send a post request not a put request
DM: no, it's not that. I am sending the right thing
Me: ... Let me see...
* 15min ish of testing *
No, it works fine on my version, 1.1.0 what's your version?
DM: I'm on 1.1.0.
Me: send me code?
DM: *send
"request.put(..."
Me: you are sending a PUT... It's literally in the screenshot. Send a Post
DM: I am
Me: no, send a Post
DM: I don't understand, I am sending the request
Me: it's a post not a put
DM: but...
Me: it's a post not a put
Me: good night!!!!!!12 -
Testivus On Test Coverage
Early one morning, a programmer asked the great master:
“I am ready to write some unit tests. What code coverage should I aim for?”
The great master replied:
“Don’t worry about coverage, just write some good tests.”
The programmer smiled, bowed, and left.
...
Later that day, a second programmer asked the same question.
The great master pointed at a pot of boiling water and said:
“How many grains of rice should I put in that pot?”
The programmer, looking puzzled, replied:
“How can I possibly tell you? It depends on how many people you need to feed, how hungry they are, what other food you are serving, how much rice you have available, and so on.”
“Exactly,” said the great master.
The second programmer smiled, bowed, and left.
...
Toward the end of the day, a third programmer came and asked the same question about code coverage.
“Eighty percent and no less!” Replied the master in a stern voice, pounding his fist on the table.
The third programmer smiled, bowed, and left.
...
After this last reply, a young apprentice approached the great master:
“Great master, today I overheard you answer the same question about code coverage with three different answers. Why?”
The great master stood up from his chair:
“Come get some fresh tea with me and let’s talk about it.”
After they filled their cups with smoking hot green tea, the great master began to answer:
“The first programmer is new and just getting started with testing. Right now he has a lot of code and no tests. He has a long way to go; focusing on code coverage at this time would be depressing and quite useless. He’s better off just getting used to writing and running some tests. He can worry about coverage later.”
“The second programmer, on the other hand, is quite experience both at programming and testing. When I replied by asking her how many grains of rice I should put in a pot, I helped her realize that the amount of testing necessary depends on a number of factors, and she knows those factors better than I do – it’s her code after all. There is no single, simple, answer, and she’s smart enough to handle the truth and work with that.”
“I see,” said the young apprentice, “but if there is no single simple answer, then why did you answer the third programmer ‘Eighty percent and no less’?”
The great master laughed so hard and loud that his belly, evidence that he drank more than just green tea, flopped up and down.
“The third programmer wants only simple answers – even when there are no simple answers … and then does not follow them anyway.”
The young apprentice and the grizzled great master finished drinking their tea in contemplative silence.
Found on stack overflow https://stackoverflow.com/questions...8 -
Today I had a pissing contest with an account director coz she asked a junior dev to upload some code to live site without testing!!! You may own the business, but you have no powers here. my servers my rules.
 6
6 -
So I have implemented all the features required for the current release. Carefully reviewed my code several times, but no testing.
Tester: everything passed green. Not sure whether you're a good dev or I'm a bad tester.
Me: let's call it a draw.10 -
Languages without a fully implemented type system.
Granted, it has been a fad for a quarter century, but everything points at one simple fact: Types matter in programming.
In dynamic languages, you tend to see that testing suites explode into thousands of tests, many of which wouldn't even be necessary if you had some type safety.
You see that languages like JS are forked into more typesafe dialects, like Typescript. Python got typehints since 3.6, and PHP added typehints for methods, then typehints for properties, and will soon even have compound types.
Maybe most languages will never reach the level of Haskell or Scala, and that's totally fine, but I think the direction languages are moving in is pretty much set in stone: No ambiguity, more safety. Code should fail before deploying, not after.32 -
The company I work for...
Has:
1. No CI/CD
2. SVN instead of GIT
3. Outsourcing to India (oof)
4. No Automated Testing
5. Uses Bugnet (ancient, outdated)
6. No clearly defined code standards
7. No real documentation on the code
8. Rubbish code
9. No desire to reduce technical debt
10. Poorly maintained DB
11. Poor outdated equipment
12. A useless PM
13. Still priotizes IE support (??)
On a scale of 1 to 10 how fucked is this company and anything they develop?40 -
Me: Discovered a bug during testing, but I have no idea what's causing it yet.
Project manager: Can you give me an ETA on when the fix will be done?
Me: <eye twitches>5 -
I once wrote about 100 lines of C code without compiling or testing in between in notepad++.
And it had no errors and worked.😎4 -
They asked me if I could recommend any video streaming frameworks. I said no, but I could google around a little. I found one, sent it to them with a note that I hadn't used it but it seemed solid.
One afternoon, right before hometime, a month later and the day before go-live, I come in, to emails with _all_ the managers on it, demanding that I assist immediately. They'd finally tried testing it, and they had found an issue. No details.
I email back, asking for the actual issue they'd found - no response. I phone - that developer has now gone on leave for week, there's a new dev who'll help me. I email him, asking for "precise technical details" of what had gone wrong.
He replies, "when you try use it, it literally causes the apocalypse." and goes silent. I check the skies, no visible apocalypse yet.
Based on some keywords they'd mentioned, I google and find a known issue as well as a patch for their version. I email it over to them.
The response? "If I'd known he was just going to Google it, I would have tried that myself."14 -
As a Java developer, reasons to kill other programmers:
- static mutable variables
- WRITING to static mutable variables
- API call with Framework X didn't work. Add Framework Y along with X and try that. Wrap X in try/catch statement. Catch block fires framework Y.
- six, seven, ten levels of nested code. Zero thought put in organization
- 6K LOC Java files
- spring (singleton? Maybe) object assigning values in static mutable (see pt.1)
- a couple of unit tests in code base that no longer work. Zero unit tests in new code
- unit testing disabled in CI pipeline
- empty catch blocks
- pass mutable data between threads. Modify in various places concurrently.3 -
*job ad* We strongly adhere to TDD
Reality:
Me: yeah but shouldn't we write tests first and then get X finished?
Manager: No takes too much time, we finish X and then we decide if it's worth testing. 5
5 -
OH MY FUCKING GOD! WHY THE FUCK WOULD YOU REWRITE A FUCKING PIECE OF CODE AND DON'T MAINTAIN ITS FUNCTIONALITY?
ARE YOU FUCKING MAD????
JUST SPENT 1 FUCKING HOUR TRYING TO FIGURE OUT WHY THE FUCK THE DATA WASN'T BEING PASSED TO REDUX STORE!
YEAH, UNIT TESTING SURE IS A FUCKING WASTE OF TIME YOU DUMB FUCKING IDIOT THAT HAS MASHED POTATOES FOR A BRAIN!
GO ROT IN HELL YOU PIECE OF SHIT!!!!
NOW IF I DON'T FIX THIS SHIT MY ASS IS ON THE LINE BECAUSE I MADE THE FUCKING FUNCTIONALITY THAT YOU BROKE?? NO FUCKING WAY!
I DON'T CARE IF YOU ARE MY BOSS, I'M GONNA GIT BLAME THE SHIT OUT OF YOU IF ANYONE PISSES ME OFF!1 -
No boss... For the fucking millionth time: unit tests are not a waste of time.
You keep testing everything manually and hoping that you tested everything every time and praying that there are no bugs IS THE FUCKING TIME WASTE
My boss just can't fucking wrap his head around automated tests... I'm trying hard... Gonna try harder...6 -
I am backend + a bit devops
8 months I worked with front-end person in react.
8 months he was telling me.. git usage is not needed for front. There is no need for that, it is not like back.
Recently he made refactorization in a week time, this idiot did not do even single commit in the process.
4 months he was telling me, testing is not needed in front. Even if the work is complete, there is no point to cover with testing.
Today I heard from him, adaptive web design is impossible to do in css only, it needs having javascript to control right height and width size for elements.
At last. I got freed from him. He got fired.5 -
My friend and boss,told me he would teach me code 2 years in a half ago.
I didnt know what css or html was and i used to call java javascript.
I can know create my own module with webpack, have my automated doc, use react, redux, he taught me linux, git,unit testing, databases,docker, and so on...
Im not an expert in any of it butbi know what they are for and can play with them more or less comfortably.
The best advice he ever gave me was:
“coding is not about coding. We are like the greath painters of history. They were great at painting but even more at creating. If you have no creativity, you can paint as well as you want, its worthless.”2 -
Boy do I hate office politics...
A client asked our company to fix perf issues on their product. Our coleagues had been picked for the job [being led by another 3rd-party, as per client's request]. Aaand they dropped the ball. The deadline is in 2 weeks, nothing is working.
Mgmt engaged us to put out the fire, but strictly at the scope the other guys were working in.
On the first day of testing we've revealed an elephant-sized perf issue that's as easy to fix as brainlessly changing 4 values in config. And that elephant is masking all the other perf issues.
We got a firm NO for config changes as that is out of the defined scope. And we're asked to continue testing.
I mean, the elephant is THAT huge that any further testing is moot - all other bottlenecks are hidden behind it. And just changing those 4 values would reduce the resources required by a magnitude of ~10.
But that's out of scope...
Client is desperate, lost and honestly asking us, pros in the field, for help.. We know how to help.. It takes 10 seconds to apply the fix..
But our mgmt forbids us to step out of the scope :/
as a result we have to pretend to be dummies hardly knowing what to do and hide the truth from the customer they so desperately want.
This is frustrating. And wrong. And imo unprofessional8 -
You know how some people put those little badges in their readme files in GitHub?
Well, one of my team members didn't know how to make those work correctly, so they just plastered images of them to make our repo look good. In actuality we have no coverage, no testing, no nothing... 6
6 -
Suddenly it hits me.
It’s 01:20 here but i get it.
It’s ALL a budget thing.
No dedicated tester means less expenses.
No personal parkspot?
No expenses!
And no good staging or testing environment? Less expenses!
Meanwhile every developer can setup, work on, and maintain about 20 websites on their shitty local Windows machine, that doesn’t even have a proper SSD installed, and we are setting impossible deadlines to figure out who will sink and who will swim.
Ow, here is a SSD.. Figure out the installation yourself because we have no IT knowledge or budget for people that do.
You want a challenge? How about 40 other people that are distracting you all day long.
Meanwhile everybody has to improve their skills in js, react, html5, ccs3, angular, .net and razor so money can made faster.
It would be nice if you could build apps as well.
You had a question? Sorry, no time. Expect some feedback 14 days later.
You finished the site?
Great!
But here are 101 bugs to solve before next week.
All hail their crazy company!2 -
This company has been a "start-up" for 5 years farming money off of fucking idiots using a shitty CMS.
- The senior dev gets paid 15/hr
- No use of version control or testing
- the CEO has no fucking knowledge about tech.
and you wonder why it's FAILING?! I'm surprised you guys stayed afloat this long, jesus fucking christ.5 -
So one year ago I was working at this company from the US, me being in Europe, which automatically implies there is several hours of timezone difference.
The eng. manager decided we would have a release tomorrow (decision was made one month earlier), and stuff was being prepped up to make that happen.
In the US the workday was about lunch time and in EU it was one hour before finishing. The manager gets us in a meeting and asks me and another dude to do some testing that would take several hours to do. This testing could have been done several days or weeks earlier.
40 minutes after that meeting I get a private message from the PM asking for the status of the test...
Me: aaa.. well I started it and will continue tomorrow
Manager: wait what? we have launch tomorrow, this testing has to be done by tomorrow
Me: it's the end of the workday here, I got personal errands that I have to attend to
Manager: uhm ok ... I see...
I was just messaging something in the public chat right before calling it a day and the manager writes "thanks for the input, your day is over now", completely out of context to the conversation I was having with whomever.
There was no question of "can you stay extra hours and do this?", there was no "hey, I know your day is over we will pay you premium hours with this amount as according to our contract, could you do this now as we have release tomorrow?" ..no ..just .. "do it!". I automatically assumed that ..hey, maybe he wants to do this during and after the live launch (and yes I do admit my mistake of not asking just to be clear, but I assumed the manager knows that there is a timezone difference ..like it's a no brainer).
I can not tell you the heat sensation I had after that last reply from the manager ... it was completely uncalled for, and unreasonable.
I mean why not make a pre-launch phase where you put stuff on the staging server, and perform all the necessary tests and then when you get all the green lights from testing you then proceed with the actual deploy? ...no ... mention this like right at the end of the day before the launch....
And another thing that scratched my neuronal cortex is, how does he know exactly how long the tests would take?12 -
AAAAAARRRRGGHHHH FUUUCKKER!!!
The new MacBook Pro with touchbar is ABSOLUTELY SHITE.
I can't tell you how many times I have accidentally touched the escape key with my pinky while typing. Also accidentally touched "send" while in apple Mail halfway through writing something.
Apple clearly did no user testing with this as I have googled around and many folk are having the same frustrations.
I've just typed a massive note into jira and towards the end my pinky hit the escape key and I lost everything!!
FUCK CUNT BASTARD WANK!!!12 -
Lead dev: Hey boss, you really do like Python right?
Me: No
Lead dev: Well it's cuz I was think....wait what? WTF do you mean no, you have automated a fuckload of BS with Python and we are still using it, why tf would you use Python if you don't like it?
Me: I like it enough for the automation scripts that we have and for parsing documents or generating glue scripts, its already installed in every server that we have, so testing bs in dev and then using them in prod is cake, it doesn't mean I LOVE python, I like it for what we use it.
Lead dev: Well ain't already bash and perl installed as well?
Me: Do you know bash and or perl?
Lead dev: No, don't you?....
Me: No......
L Dev: (using a Jim Carrey impersonation) WELLL ALLRIGTHY THEN! What is the other language that you used for X project?
Me: Clojure, do you remember that one?
* he said paren paren paren paren yes paren i space paren do close paren close paren etc etc
L Dev: (((((((yes (i (do)))))))) and nevermind, I'll get back to working more with Python
Me: das what I fucking thought esse6 -
How the fuck am I expected to salvage a fucking project that has been handed down to me with.
- No fucking clear architecture
- No fucking documentation
- Fucking shitty ass code base with no fucking coding standards
- The previous team was fucking learning a whole fucking new technology stack *Not fucking kidding* making fucking mistakes left and right
- No code reviews
- Mixing fucking local and cloud enviroment together
- No fucking testing
- Feature that were supposed to be implemented and are not working
- No configuration all the stuff are hard coded
- Full responsiblity for the whole stack
- Only one other guy with me
- And this fucking project has been delayed for a year
- MUCH FUCKING MORE WHERE THAT CAME FROM
Like what the fuck am I expected to do? I took the job thinking that people knew what the fuck they were doing and surprise surprise that was a fucking bust.
the problem is also I am the junior and these fucking people have more experience than me, what the fuck happened to over seeing people's work, PM doesnt give a shit, developers dont give a shit nobody gives a shit.
But when I got this surprise surprise now everyone is interested in finishing the project
BULLSHIT11 -
I posted a "Periodic Table of Human Intellect" I created today, and thought it was worth sharing.
Ages:
0-14 = Dumb as fuck.
15-21 = Learning useless shit.
22-28 = Claiming to know everything. *
29-35 = Reality sets in.
36-48 = Fuuuuuuuuu...
48-59 = Deal with it and watch your step.
60+ = ¯\_(ツ)_/¯
Of course, I'm still in the process of testing the predicted results of 48+ - but, I'm looking forward to no longer giving even half a shit.
(* Based on everything useless that they've learned.)16 -
[3:18 AM] Me: Heya team, I fixed X, tested it and pushed to production. Lemme know what you think when you wake up.
[6:30 AM] Me: Yo, I just checked X and everything is peachy. Let me know if it works on your end.
[9:14] Colleague A: Whoop! Yeah! Awesome!
[9:15] Boss: Nice.
[9:30] A: X doesn't work for me.
Me: OK, did you do M as I told you.
A: yes
Me: *checks logs and database, finds no trace of M*
Me: A, you sure you did M on production? Send me a sreenshot plz.
A: yeah, I'm sure it's on production.
Me: *opens sreenshot, gets slapped in the face by https://staging.app.xyz*
Me: A, that's staging, you need to test it on production.
A: right, OK.
[10:46] A: works, yeah! Awesome, whoop!
[10:47] Boss: Nice.
Me: Ok! A, thanks for testing...
Me: *... and wasting my time*.
[10:47:23] Boss: Yo, did you fix Y?
Courageous/snarky me: *Hey boss, see, I knew you'd ask this right after I fixed X knowing that I could not have done anything else while troubleshooting A's testing snafu since you said 'Nice' twice. So, yesterday, I cloned myself and put me to work in parallel on Y on order fulfill your unreasonable expectations come morning.*
Real me: No, that's planned for tomorrow. -
Just finished my internship.
I entered knowing nothing and spent the entire year on solo projects.
My company does not use any frameworks because "they don't want to run code on a server that they didn't write", they use waterfall, only use version control on half the projects, use notepad++, never once even glanced at my code to check I know what I'm doing - even when i asked.
Also have never heard of a code review, have absolutely no QA in place other than the devs making it and quickly testing it visually, no requirements gathering - just pictures and have never heard of tdd.
Recently was given a project with no designs, no specs other than a verbal half thought out explanation and was dumped with random deadlines like "this needs to be demoed tomorrow night" with no idea about the project progression or what it looks like. Apparently it's all my fault that it failed.
I am very grateful to them for teaching me so much and giving me opportunities to teach myself on nice projects but come on.
What boggles my mind is that the company is 6 years old and has big, big clients. I don't understand how. I once tested a project about to go out the next day that had been "tested" and found pages of bugs. They would have lost the contract for sure...8 -
6 months ago I had to implement a new feature and realized that a related uploading feature was broken if you choose a specific service to upload to.
I was wondering why nobody had reported this, so I took a look at the usage of said feature and it seems literally no client ever used it since it was released almost 2 years ago.
Only the product owner used it in the beginning... only for testing it...
2 weeks well spend.5 -
Frequently used answers :)
UI developer - I think API is not working
Backend developer - Front end is not sending the request correctly
Tester - Testing! Testing!
UI/UX - As per android/ios standards...
QA - Let me check one more time
PM - Let us have another meeting and get on the same page
Dev-Ops - It's very complicated you know
CTO - We're working on a next-gen solution
Founder - Let us build something that no one has built, something similar to what google...facebook...
Cridits: My EX-CPO5 -
I fucking hate holidays. Every goddamn time when it's a holiday, that's when I need to go to the store and get something, only to find out that they're closed. And what for.. holidays are - to me at least - no more than an excuse for people to not go to work for the day.
So, now I ran out of booze, and can't continue developing and testing my breathalyzer until Monday.
Then it hit me.. what if I take all my Arduino equipment (laptop, jumper wires, ...) to the café and deploy my build environment on a table there?
Eh, no no no. I don't want some idiot to come up to me saying "YOU EVIL HEKORMAN!!!" and have to explain that just like when you call a banker who's working with the money vaults a thief, it's wrong to call someone that's developing shit an evil hacker.. one should strive to not throw mindless accusations out of unknowingness. Not that I'm a good example of that though. But still.
It's probably that or some stupid bitch coming up to me asking to hack her boyfriend's Phasebuk.. that said, that could probably be an opportunity to get in her pants. But then, I don't wanna insert my meat in an idiot like that... ._.
So, no booze it is then? Thanks national holidays!
"Ok Google, remind me every day before a holiday because I really couldn't care less about them!!"14 -
A few years ago I was browsing Bash.org, and a user posted that he'd physically lost a machine.
A few weeks ago, I'd switched my router out for OPNSense. I figured it was time to start cleaning up my network.
Over the course of tracking down IP addresses and assigning statics to mac addresses, I spotted an IP I didn't recognize.
Being a home network, I'm pretty familiar with everything on the network by IP, so was a little taken aback.
I did some testing, found out that it was a Linux box. Cool.
I can SSH into it. Ok.
Logs show that it's running fine, no CPU/Memory/Harddrive issues. Nice.
So where is it?
Traceroute shows its connected directly to the router... Maybe over an unmanaged switch...
Hostname is "localhost"... That's no help.
I've walked the network 4 times now, and God knows where it is.
I think maybe I'll just leave it alone. If it ain't broke...9 -
This is horrifying. Testing code seems to have been an afterthought that ended up ruining dozens of peoples’ lives.
“Bad software sent postal workers to jail, because no one wanted to admit it could be wrong”
https://theverge.com/2021/4/...10 -
manager: we had great feedback last week, real users were testing our app! However, we have noticed a lot of issues regards database performance and data replication...
me: oh, that's great news!! How many users? Like hundreds?
manager: no, 6 users so far7 -
My preciousssss!!
Fucking assholes! Just spent 3h debugging for bugs that weren't there.. Our client insisted we must rollback the whole update, because gui was broken.. after analysing data & testing I figure out that there must be something 'wrong' as there was no data to copy from in the first place...so there should be no bug..
Aaand here goes the best part: they didn't want to point out missing data bug, they just wanted one restriction to be removed, because it 'broke GUI', to allow for empty value on save... WTF?! How can you insist that gui is buggy & that you don't want an update, if you just want something to be optional?! Which was done immediately, one change in one js file?! Dafaaaaaq?!
Kids, English is important!! Otherwise you end up debugging ghosts for 3+ hours withou a cigarette...and waking up a coworker with bad news of rollback at half to midnight... Aaaaaaaargh!!!
сука блять 27
27 -
GIT LOG VERSION 101
----------------
75fed18 pay no attention to the man behind the curtain
56772ff added security.
6374fdd needs more cow bell
6b27de9 Committing fixes in the dark, seriously, who killed my power!?
bffce8a giggle.
7e93977 Refactored configuration.
e66c495 pgsql is more strict, increase the hackiness up to 11
5690dd9 Revert "just testing, remember to revert"
daa84ba Still can't get this right...
097f164 this should fix it
367f271 GIT :/
f46d735 bump to 0.0.3-dev:wq
b893721 ¯\_(ツ)_/¯
24be0d9 ...
f014a0c ALL SORTS OF THINGS
e648b80 added super-widget 2.0.
3a71628 perfect...
e2a8cb1 Fucking templates.
b08e489 pgsql is more strict, increase the hackiness up to 113 -
"Why does my app have so many bugs!?"
"Why does literally nothing work!?"
"How come you cant fix these problems soon enough?"
...
Me: "remember how you didnt account for testing in the budget or development plan?"
"No"
Me: "thats why."2 -
- Be me (Dev)
- Develop website for client that has an online payment integration.
- Notice there is no one for QA and testing.
- Try to raise voice about it but get shot down by management.
- Get order to push the project to production (because the deadline has arrived, therefore the project must be ready)
- Production performance has an error margin of 15% (customers getting their card over/under charged)
- Get blamed and flamed for everything cuz well, its all the dev's fault.
FML4 -
At a certain client, was asked to help them with an "intermediary" solution to stopgap a license renewal on their HR recruiting system.
This is something I was very familiar with, so no big. Did some requirements gathering, told them we could knock it out in 6 weeks.
We start the project, no problems, everything is fine until about 2.5 weeks in. At this point, someone demands that we engage with the testing team early. It grates a little as this client had the typical Indian outsourcing mega-corp pointey-clickey shit show "testing" (automation? Did you mean '10 additional testers?') you get at companies who put business people in charge of technology, but I couldn't really argue with it.
So we're progressing along and the project manager decides now is a great time to bugger the fuck off to India for 3 months, so she's totally gone. This is the point it goes off the rails. Without a PM to control the scope, the "lead tester," we'll call her Shrilldesi, proceeds to sit in a room and start trying to control the design of the system. Rather than testing anything in the specification, she just looked at the existing full HRIS recruiting system they were using and starts submitting bugs for missing features. The fuckwit serfs they'd assigned from HR to oversee this process just allowed it to happen totally losing focus on the fact this was an interim solution to hold them over for 6 months and avoid a contract renewal.
I get real passive aggressive at this point and refuse to deliver anything outside the original scope. We negotiate and end up with about 150% scope bloat and a now untenable timeline that we delivered about 2 weeks late, but in the end that absolute whore made my life a living hell for the duration of the project. She then got the recognition at the project release for her "excellent work," no mention of the people who actually did the work.
Tl;Dr people suck and if you value your sanity, you'll avoid companies that say things like, "we're not in the technology business" as an excuse to have shitty, ignorant staff.6 -
Today I was continuing my Ruby script for file encryption.
I added some features like Picture Encryption and Bookmarks.
Then I tried to start it to make sure it doesn't fuck up.
ruby PGCrypt.rb
No changes reflected.
w0t.jpg
Start debugging
Browses SO and DDG like a maniac
Reinstalls Ruby
Guess what happened.
My shell was in the wrong folder and I ran the old testing script.
GRAAAAAHHHH3 -
Friend of mine: so I wonder how do you test your applications in the startup?
Me: testing? *grabs his coffee laughing*
Actually we have a complete build pipeline from commit/pull-request to dev and production environments. No tests. Really. We are in rapid product development / research state.
We change technologies and approaches like our underwear (and yeah, this is frequently). If we settled some day and understood the basic problems of the whole feature palette, we'll talk about tests again.3 -
Omg so I've been stuck on this function I'm writing that checks if a certain array value is so many characters long and well, it just wasnt returning false when outside the conditions..
I tried taking it step by step, echoing out every line and it all made sense to me and there were no syntax errors.
Time goes by and inside the configuration file I was testing.. I was changing the value of a DIFFERENT array property than what I was using in my condition. They looked really similar.. fml xD2 -
12 days of work, 12 fucking days straight and I meet the Friday deadline for this ridiculous sprint of never ending tasks.
There’s no better feeling then bringing everything together at 5pm on Friday, pushing to Git and waking out that door knowing there’s nothing more to do until Monday’s testing!!!!
Now excuse me while I go sleep my weekend away!2 -
I remember making a product for my customer that was using a db
When I tested the product before showing it to the client, everything was good and fast and clean.
When I gave it to my customer, he was very happy, after few days he emails me about the product was very slow, I checked the database and it had a lot of *testing* shit made by him and when I asked my customer why the db has so much useless things he told me that he was learning how to it. I had no words, can't you just create a database MongoDB, MySQL or whatever you want to learn locally and play with it? Then he emails me later about a fucking refund because HE fucked up with the permissions of the db 5
5 -
Working in the embedded systems industry for most of my life, I can tell you methodical testing by the software engineers is significantly lacking. Compared to the higher level language development with unit tests and etc, something i think the higher level abstracted industry actually hit out the of park successfully.
The culture around unit testing and testing in general is far superior in java and the rest.
Down here in embedded all too often I hear “well it worked on my setup... it worked at my desk”.. or Oh I forgot to test that part.. or I didn’t think that perticular value could get passed in... etc I’ve heard it all. Then I’ve also heard, you can’t do TTD or unit tests like high level on embedded... HORSESHIT!
You most definitely can! This book is a great book to prove a point or use as confirmation you are doing things correctly. My history with this book was I gonna as doing my own technique of unit testing based on my experience in the high level. Was it perfect no but I caught much more than if I hadn’t done the testing. THEN I found this book, and was like ohh cool I’m glad I’m on the right thought process because essentially what they were doing in the book is what I was doing just slightly less structured and missing a few things.
I’ve seen coworkers immediately think it’s impossible to utilize host testing .. wrong.
Come to find out most the of problems actually are related to lack of abstraction or for thought out into software system design by many lone wolf embedded developers.. either being alone, or not having to think about repercussions of writing direct register writes in application or creating 1500 line “main functions” because their perception is “main = application”. (Not everyone is like this) but it seems to be related to the EEs writing code ( they don’t know wha the CS knows) and CS writing over abstraction and won’t fit on Embedded... then you have CEs that either get both sides or don’t.. the ones to understand the low level need but also get high level concepts and pariadigms and adapt them to low level requirements BOOM those are the special folks.
ANYway..the book is great because it’s a great beginner book for those embedded folks who don’t understand what TDD is or Unit testing and think they can’t do it because they are embedded. So all they do is AdHoc testing on the fly no recording results no concluding data very quick spot check and done....
If your embedded software engineers say they can’t unit test or do TDD or anything other than AdHoc Testing...Throw the book at them and say you want the unit test results report by next week Friday and walk away.
Lol 7
7 -
Why do people jump from c to python quickly. And all are about machine learning. Free days back my cousin asked me for books to learn python.
Trust me you have to learn c before python. People struggle going from python to c. But no ml, scripting,
And most importantly software engineering wtf?
Software engineering is how to run projects and it is compulsory to learn python and no mention of got it any other vcs, wtf?
What the hell is that type of college. Trust me I am no way saying python is weak, but for learning purpose the depth of language and concepts like pass by reference, memory leaks, pointers.
And learning algorithms, data structures, is more important than machine learning, trust me if you cannot model the data, get proper training data, testing data then you will get screewed up outputs. And then again every one who hype these kinds of stuff also think that ml with 100% accuracy is greater than 90% and overfit the data, test the model on training data. And mostly the will learn in college will be by hearting few formulas, that's it.
Learn a language (concepts in language) like then you will most languages are easy.
Cool cs programmer are born today😖 31
31 -
He wanted to hire me as CTO but insisted of defining architecture himself even though he admitted he has no tech background. He insisted that his CRM doesn’t even need backend because “we have database”. He was dysgraphc but completely ignored accessibility, including measures for dyslexic people. He called his product “startup” but denied that startups need to constantly validate ideas and denied the conception of a/b testing, offering no alternative.
He also wanted me to work for free.
Bruh you’re not a clown, you’re an entire circus.5 -
As lead developer I was not allowed to implement automated testing as "we don't have time for that" - you have no idea how much time it would save!6
-
Gaming community of mine launched their slick new website with their new "ticket system" where people could put in tickets to get help by volunteers.
2 hours and an approval by one of the admins later I managed to inject forge http request into literally every form on that side. Modify permissions, delete users, edit tickets, put invalid values into every attribute of them... In other words break everything.
Turns out the whole thing was coded as a first time project by a person who has no clue about web development and noone is in charge of anything really. There are no requirements, no beta testing, no version control or backups, but at least they had a hard deadline. 🤣
Still not sure if I wanna fix their shit and do it properly or just enjoy seeing it crash and burn.5 -
Apple at it again.
The new iPad mini suffers from "jelly scroll", and Apple tries to gaslight its customers into believing that this is normal.
No Apple, this is not normal. It's you. You and your shitty engineering, your shitty testing (too much secrecy, hence too few testers), your shitty marketing, and your shitty customer service. You are shitty as usual.
(Reference article: https://arstechnica.com/gadgets/... )7 -
I've seen many devs doing crazy things in my entire career till now. But this one dude stands out.
He used to:
- Push binaries to git repo
- Use some old libraries which were used during Indus Valley civilization
- Had no sense of database and used to delete random data from it and call it as TESTING (Thank God! I never gave him prod access)
- And on top of this, he had an ass full of attitude!2 -
Me: eh probably shouldn’t push to prod on Friday, maybe not even before the first...
Co worker: no balls
Me:
-
I once worked with an obsessive tester who was bent on ‘testing’ the README file of a Software Distribution.
The README text file was in the distribution zip, so she had to unzip the thing before reading the file, however she insisted that her test result was a failure because there was no README that shows her how to unzip the distro to read the README!
I thought she was joking, but she was dead serious and escalated the ‘issue’ to the manager! I was furious, almost resigned from the project
In the end I had to suck it up and tolerated more weeks of her mindless obsession!5 -
We do quantum development at work. Hence no testing nobody knows if the application is working after the deployment. 😶3
-
So this is what happened!
It was a rainy Friday, I was asked to add a quick bug fix to a js application, I spent my Friday coding, testing ..., baam the patch is ready ... I wrote a nice commit message explains the problem and the fix but I didn't push the code.
On Monday the fuckin code disappeared, no commit no code no nothing no trace ... To be honest I don't know what happened. I rewrote everything on that Money morning (you can only imagine how pest I was)
I use vim with tmux.
I have done everything I could to figure out what happened to that commit, I even doubted If had did wrote the fix that Friday, but it's not possible to forget few hours of a day
I checked my commit history on the different branches i did everything
No trace ...
Conclusion
My machine is hunted ...
Or I have multiple personalities and one of them is a programmer and he is fucking with me 5
5 -
Project management site, exclusively for use by our team and clients.
- The client creates a new project.
- They list the requirements, supplying all the necessary files and content.
- We challenge any stupid stuff by offering alternative solutions.
- We all sign off on the requirements and no more are allowed to be added or modified. If they forgot anything, it's on record who's to blame.
- We estimate time and cost to complete the build.
- If they accept, we finally begin the work
- At each stage of every requirement, we mark the status as pending, in progress, ready for testing and delivered.
Much less stress due to minimising change requests. Plus easier to follow than an email chain and easier for them to use than a jira portal.6 -
Why the fuck does Apple hate developers so much? I just want to test and play around a bit. Why do I have to own a fucking Mac? Why do I need to pay 99$ a year just to install a debug build on my own device?! It's literally impossible to get into ios development without being rich or having some kind of plan for revenue...
Testing my app on Android:
Install Android studio -> plug in phone -> run code in Android Studio or simply install the resulting apk on your phone.
Trying to test my app on my iPad:
Google how to build app for iPad -> reading that you have to own a Mac to run xcode when you want to build Code for iOS -> searching for a workaround -> find a way to build my app online -> setting the tool and building it -> Trying out 5 different tools to sideload the app, no one works -> finding out that you need a developer account to sign the app for testing purposes on MY OWN DEVICE. I really would appreciate it if I would be able to install personal stuff for testing and LEARNING without being forced into insolvency. Why are people putting up with this kind of bullshit?19 -
Years ago, I joined a company making games for handheld consoles.
Because a game's audio needs to be tested, too, I connected earphones to the console so that:
0. I wouldn't bother others w/ the sounds coming out of the console.
/* !Everyone wants to hear that crap. */
1. I could hear the sounds better.
PM: * Enters the room. *
Me: * Focused on testing the game. *
PM: * Walks up to me from the side, starts talking. *
Me: * Focused on testing the game. *
PM: * After approx. 30 seconds of complete lack of response from me, kind of irritated, knocks on my desk to get my attention. *
Me: * Take out the earphones. *
Oh, hi, how can I help you?
PM: Haven't you heard a word I said?
Me: Well, no. I am testing the game, including the audio.
PM: You need to pay attention to what's going on around you.
Me: Testing audio is one of my responsibilities. I am using earphones because of the reasons [0-1].
PM: Even still, you just need to pay attention to what's going on around you.
PM: * Finally explains the reason for him bothering me, then goes back to his lair. *
Moral of the story: Fuck being good at what you do && knowing your responsibilities.
When PM wants something from you, you better give him the attention he wants.
/* The expectation being I grow an extra pair of eyes && ears, so that I see the guy coming && am prepared to listen to him whenever he wants something _while_ doing the best job I possibly can. */9 -
Just added an RSS feed to my blog (https://nixmagic.com/rssfeed.xml/ if you're interested), and as I was testing it out in an RSS reader, I noticed that the reader basically just renders the webpage as if it were a web browser.
Heh.. I have only the Webkit engine on my computer, so I suppose it's just using that in the backend or something like that? How much RAM does that consume?
*looks at Task Manager*
67MB. I shit you not.. 67 megabytes. And that is rendering an entire website with no noticeable differences from a regular web browser.
Chrome: *gobble*8 -
pms always tell the higher ups that I"don't have passion". I don't know how to show passion for their photoshop mock ups, one line requirements with no definition of done, their talking for hours about "leveraging" and name dropping about the top brass they are schmoozing with. I just ask if we are going to show our MVP to real users and she morphs to the bride of chuckie. I say we ought to pair program and she says it cost double to make a feature. Testing and code reviews are taking too much time but they hover over your shoulder while you try to fix a "mission critical bug" that occurs because they wanted us to skip practices that could have prevented the bug. Woo I feel better now!2
-
Manager gave me a project he wanted to be done fast. Spoke with the guy who wanted the feature asap . After 4 days of hard work and testing sent a email to the guy who wanted the feature asap, requesting access to ftp where to periodically upload the output data. Day 3 still no answer.1
-
I'm actually a Dev, mostly just a shell scripter who needs to support 500 servers which run our applications. I install the new versions and check whatever is wrong if there are customer issues.
One release weekend everything went wrong, Development had to make new builds on the fly with hardly any time for testing.
It took 18 hours with no break.
It was extremely hard to concentrate, but being in the Skype group with everyone and finally getting everything fixed was quite rewarding.
Everyone just opened a beer and we stayed on the call for about 30 more minutes just to relax.
I like our Dev team way better than I like my actual colleagues, who merely mess things up and call me for the smallest thing without even thinking.4 -
I have a situation that is so out there I almost wouldn’t believe it if it wasn’t happening to me. The company I work at has three branches and around 100 employees. The owner of the company has a brother who needs a liver transplant. Two weeks ago, a company-wide memo went out that all employees would be required to undergo testing to see if they were a suitable liver donor for the owners brother. No exceptions.
Last week at the branch the owner works out of most of the time, his assistant went around to schedule days off for everyone so they could go get tested. People who declined were let go. One of these people was born with liver disease and therefore ineligible to donate. She had a doctor’s note. Other people also had medical reasons as well and some were just uncomfortable with the request and didn’t want to do it. One was pregnant. They were still terminated. My employer’s assistant has said that because our employment is at will, he can legally fire us.
I’m in remission from cancer. I’m ineligible to donate and any kind of surgery would put a major strain on my system. Even if I was healthy, I would still object to possibly being forced into donating an organ just to keep my job. Soon they will be scheduling people’s days off for testing at my branch.
I know this situation is nuts, but I don’t know what to do. I know I could just go for the testing and then be declined, but I don’t think I should have to do that. I’ve had enough with hospitals. Other coworkers who don’t have medical conditions are afraid they won’t be declined because they will be a match. I’m looking for another job but in the meantime I don’t know what to do and I and many of my coworkers are really stressed out.25 -
I don't get it why there are so many people out, that think testing stupid model classes with getters and setter is needed.
Dude. There is no logic in this class ... it's pure data that gets not modified there (well except if you call the setter)
I've wasted way too much time writting useless unit test because some ppl want to masturbate on 100% code coverage 🤦🏻♂️12 -
Me: Im testing a new feature that is not on production yet for 30m and can not make it work. (I asked the developer for any idea why is not working)
Dev: i just tested, works fine.
Me: i just tested again with no luck. I’m i missing anything?
Dev: (Developer comes to my desk). Lets see what you doing wrong here. (After 5seconds). You're not on UAT. You have been redirected to the production and you've been testing there all this time.
Me: 😩 -
I have a lab at uni where my lab group have to refactor some code from an open source project. We got assigned some Apache project and jfc that code is a mess. Little to no documentation, hard to navigate, tests that you have no idea what it's testing, and so on. On top of that the teacher expects us to spend more time than we have on it. I'll be glad when this course is over :))5
-
I assigned a new task to an intern who has been with us for a month. He was supposed to prepare the testing environment and test the Geolocation API. When it works, then he can start integrating it with our platform and everything.
After a week, he emails me to say that he thinks the Geolocation API doesn't work. I was weirded out by that because a lot of people use it. We scheduled a meeting and asked him for a demo of his code to see what the error message is.
Him: *no Visual Studio, no code, nothing at all* So here it goes.
Me: ????
Him: *Goes to the API documentation, copies the base URL, pastes it to the browser and hits Enter* See? It says 404 not found.
Me: *literally facepalmed*
Now, he is working on sales management. We totally took him off every software developing projects.7 -
"Let the developers consider a conceptual design,” the King said, for about the twentieth time that day._
“No, no!” said the Queen. “Tests first—design afterwards.”
“Stuff and nonsense!” said Alice loudly. “The idea of writing the tests first!”
“Hold your tongue!” said the Queen, turning purple. “How much code have you written recently, anyway?” she sneered.
“I won’t,” said the plucky little Alice. “Tests shouldn’t drive design, design should drive testing. Tests should verify that your code works as it was designed, and that it meets the customer’s requirements, too,” she added, surprised by her own insight. “And when you drive your tests from a conceptual design, you can test smarter instead of harder.”4 -
Nobody Unit Tests.
So it's already 1:15am late night and I am all tucked up in bed watching Roy Oshrove talk on unit testing and ways to write correct unit test. My friend walk in and finds me in bed watching this. He seems surprised as what are you doing ??
I replied it is an interesting talk on unit testing.
He says are you mad? Who the hell does unit testing ?
People out there are spitting on unit test code base. And they don't write unit tests.
Nobody unit tests.!!
I stay calm. I know there is no point of arguing. I said I'll sleep in some time.
And he works as developer, a job that I applied an never got because of connections.
I am optimistic someday I'll find a job that I deserve. The developer world is in danger. !!!4 -
I just want to share this:
When I start working at my last job, I have little idea of what a unit test was.
My boss on one meeting said that unit testing will be mandatory (wich is ok and umderstandable).
Almost a *year* after that, no one still care about them. I see myself doing them the best I can, but I saw things like wrap the assertion line with "try / catch" to lie to the coverage and unit test percentage. Or in other cases directly uploading *manually* the code on the server without test at all.
And then, as the only developer who do the unit test ok I have to do the missing ones and repair the fake ones.
Then when something explodes the question all the managers love to ask "Did we had the testing?"
At least I quit... that job was some crazy shit, this is just one story of many.
Like that other time that my co-workers did not understand why I needed to do POJOs on an android app because the big bad JSON that the app used was working fine.... -
I hate hearing "this should be a quick one" from the client. Especially when your code base is a fucking legacy with no documentations, no testing, and a multisite that shares the same classes where functions has some crazy if conditions just to satisfy each site's requirements.2
-
I really like this book on the basis of the philosophy overall, no this doesn’t solve all problems but it’s a good baseline of “guidelines/rules” to program by. Good metrics or goals to architect and design software projects high and low level projects.
Fight Software Rot
Avoid duplicate code
Write Flexible, dynamic, adaptable code
Not cargo cult programming and programming by coincidence.
Make robust code, contracts/asserts/exceptions
Test, Test, and TEST again and Continue testing.. this is a big one.. not so much meaning TDD.. but just testing in general never stop trying to break your software.. FIND the bugs.. you should want to find your bugs. Even after releasing code the field continue testing. 24
24 -
PM: Did you start looking into that stress testing tool.
Me: Literally looking into it right now
PM: Ah cool. So you'd be ready tomorrow?
Me: No
PM: Why not?
Me: I literally started looking at the tool. I can't promise anything.4 -
So recently I needed to make a little Tic-tac-toe game with Node.JS for an university project. I previously learned Java and C# so Javascript as a non-compiled, script based language was something new for me.
Now during the programming process I reached the point where I needed to implement a function to change the player who's playing.
I was testing the game and... It seemed like the player was changed twice so it immediately switched back to the previous player.
Using a lot of console.log's I finally stumbled upon the error... (since Javascript or at least Visual Studio Code, I honestly don't know, doesn't have any kind of debugger or something).
Why the fuck does js allow to make allocations in if conditions?
I accidentally wrote one '=' instead of three '==='.
No error, no warning... Nothing.
Since then js and me are not friends anymore.8 -
F*CK...that feeling when you were working as a junior UI/UX designer for about 3 weeks in new company, you were on a project which is almost finished and delivered...
1 and half week Later (after technical issues - check my older rants)......
you have noticed one quite importat mistake in the designs, which were done by senior designers, which can lead in future to a huge Ux problems - so huge, that users will probably leave/close the app and will not purchase the product via that app... ( We can say than whole design solution was a waste of money for the client)... On that designes was working a team of 4 people, about 3 Months (and the app (prototype) had to be ready already 2 Months back)...
the deadline was pushed 2x already...
And your boss (senior designer) tell you that this is not such an issue.. But thx for your opinion.....
1 week Later by user testing 4 out of 4 people were asking about that stuff I told to my boss that is missing...
And I was ignored...
In less than 1 week Later after the testing I get fired from the company without no reason...
Or better - the reason was:
I have too little experiences for this job...
Dont know if I should laugh or cry🤦♀️🤣/😭6 -
Hi! I'm new in freelancing. I've created a program that scrapes data from a website, parses it, runs DB queries, and emails the prepared data to the customer for whom I've created this program. The whole program is written in PHP and uses a MySQL table. There's almost no front-end, it's just like an automated background process that runs with a cron job. I've bought and set up a domain and hosting for them (my cutomer paid it all). I got the core part of the program running after ~2 days, and it took me ~a week to complete the project including adding features and the testing phase. Now, I'd like to know, how much does this kind of project cost? The business operates in Silicon Valley.10
-
Me: Im testing a new feature that is not on production yet for 30m and can not make it work. (I asked the developer for any idea why is not working)
Dev: i just tested, works fine.
Me: i just tested again with no luck. I’m i missing anything?
Dev: (Developer comes to my desk). Lets see what you doing wrong here. (After 5seconds). You have been redirected to the production site and you've been testing there all this time.
Me: 😩1 -
03:00 am
Just coded for 12 hours.
One feature is blocked,
2 are ready for testing
And a third needs some development but actually has no task in the backlog,so that one is in limbo.
To bed
*drops mic
Tomorrow it will all be done. -
Our project at work goes live in 3 weeks.
The code base has no automated tests, breaks very often, has never had any level of manual testing
will not be releasing with any form of enforced roles or permissions in our first release now due to no time to enforce, however there is a whole admin api where you can literally change anything in our database including roles.
We also have teams in various countries all working separately on the same solution using microservices with shared nuget packages and they aren't using them properly.
Our pull requests are so big - as much as, 75 file changes - in our fe app that I can't keep up with it and I honestly have no idea if it even works or not due to no automated tests and no time to manually test.
We have no testing team, or qa team of any sort.
Every request into the system has to hit a minimum of 3 different databases via 3 different microservices so 1 request = 4 requests with the load on the servers.
We don't use any file streams so everything is just shoved in the buffer on the server.
Most of the people working on the angular apps cba to learn angular, no one across 2 teams cba to learn git. We use git so they constantly face problems. The guy in charge has 0 experience in angular but makes me do things how he wants architecturally so half the patterns make no sense.
No one looks at the pull requests, they just click approve so they may as well push directly to master.
Unfinished work gets put in for pull request so we don't know if the app is in a release state since aall teams are working independently, but on the same code base.
I sat down and tested the app myself for an hour and found 25 fe only issues, and 5 breaking cross browser issues.
Most of our databases are not normalised. Most of our databases make no sense. 99% of our tables have no indexing since there is no expertise with free time to do it.
No one there understands css properly. Or javascript.
Our. Net core microservices all directly use ef in the controller actions so there is no shared code there.
Our customer facing fe app is not dry because no tests so it was decided it was better this way.
Management has no idea on code state, it seems team lead is lieing to them about things like having any level of tests.
Management hire devs that claim to be experts but then it turns out they have basically no knowledge of what they were hired to do, even don't know what json is or the framework or language they are hired for, but we just leave them to get on with it and again make prs too big to review.
Honestly I have no hope that this will go well now but I am morbidly curious to watch. I've never seen anything like the train wreck that we are about to get experience.5 -
So, I work in a game development studio, right?
We're trying to launch the title on as many platforms as reasonable, because as a social VR app we're kinda rowing upstream.
So far, Steam and Oculus have been fairly reasonable, if oddly broken and inconsistent.
Enter store 3.
Basically no in-game transaction support (our asking prompted them to *start* developing it. No, it's not very complete). No patch-update system (You want an update? Gotta download the whole fsckin' thing!). No beta-testing functionality for most of their stuff ("Just write the code like the example, it will work, trust us!"). No tools besides the buggy SDK (Wanna upload that new build? Say hello to this page in your web browser!).
So, in other words: Fun.
We've been trying to get actively launched for two months now. Keep in mind that the build has been up on Steam and Oculus for over a year and half a year (respectively), so the actual binary functionality is, presumably fine.
The best feedback we get back tends to be "Well, when we click the Launch button it crashes, so fail."
Meanwhile we're going back and forth, dealing with other-side-of-the-world timezone lag, trying to figure out what is so different from their machines as ours. Eventually we get them to start sending logs (and no, Windows Event logs are not sufficient for GAMES, where did you even get that idea????) except the logs indicate that the program is getting killed so terribly that the engine's built-in crash handler can't even kick in to generate memory dumps or even know it died.
All this boils down to today, where I get a screenshot of their latest attempt.
I just can't even right now.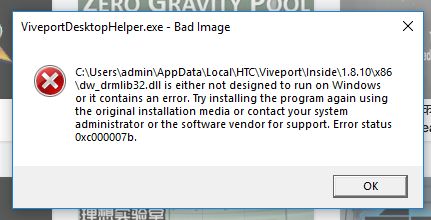 5
5 -
!Rant
Hello devRant!!
Just released a small little app to share links to your PC directly from your device (Linker).
It uses a Java server running on your PC so there are no middle-men. Everything is open source and on my GitHub.
It's currently in alpha. Basically:
1. Run server on your PC (no UI ATM so run in a console) - defaults: 0.0.0.0:8090
2. Add the server IP-Port in the Android app
3. Share a link from any app through linker
4. Magic 😎
Below are the links if anyone likes the idea and wants to try it out (UI is crap I know! - I had very little time to work on it)
Become tester:
https://play.google.com/apps/...
App:
https://play.google.com/store/apps/...15 -
Rant
I'm tired of this shit!!!
First I receive a task to create a new functionality for the app that I'm working on and some documentation (this is the only good part of all the rant) but no design.
It's been 2 weeks since I got assigned to this and still no design, no assets, no API calls that ACTUALLY WORK.
Today was testing a plist to get a banner link, and for 1 hour that little fucker didn't returned the image I was asking.
Better, I wasn't getting ANY IMAGE. Turns out that the link sends me to a HTML URL that doesn't have any image... go figure!
So I've been working on this from some images inside the PDF with the documentation given.
Oh! Wait! There's more!
The cherry on top is that I'm implementing a chat/voice call/video call into the app and the framework that I will be using is being created now, and it's not even finished!!!!!!4 -
Code is sat in UAT for a month and no one looks at it. Two days before the (completely arbitrary) go live date and testing commences, finding one bug which is immediately fixed. And now I'm the one allegedly delaying roll-out. Err OK...1
-
I might break my "no beta-testing unless paid" rule for this. I am beyond ready for quic-ness.👍🏻
https://twitter.com/JustinKotalik/... 7
7 -
So here I am testing some python code and writing to a file. No big deal. But damn is it taking a long time to get data back from this API. Ah it's fine I'll let it work in the background.
40 minutes later.
Oh! The requests timed out. No big deal. I'll just cut out the parts that are already done.
1st request in.
I wonder what the file is looking like.
Only showing 1 request.
waitaminute.jpeg
I should have more than that.
*Suddenly realizes that I was writing to the file and not appending.
Fuuuuuuuuuuuuuuuuuuck 2
2 -
Holy crap, I can't take it anymore.
I know that user acceptance testing is supposed to be done by the end user but it's as if they entirely skipped UNIT TESTING and QUALITY ENGINEERING.
Does their API work? Yes. It does.
Are their endpoints working? Sort of... why are query parameters required again?
Is it good overall? No, there are CORNER CASES ALL OVER THE PLACE (are they even still corner cases at this point?). It feels like it was made by amateurs!
Why am I doing quality testing on their services??? holy crap, they should pay ME for doing this1 -
Corporate pushed a change to our PC's which similataneously installed chrome and pushed their security policies on us. Extensions are no longer available. I can't sign in with my chrome account anymore. I can't automate ui testing with selenium. I can't control any chrome settings, they're controlled by group policies now.
I guess it's time to switch to Firefox. At least until they block that. At least the UI testing still is functional on that...7 -
Fuck. The entire day to do this shit.
The screen was my first experiment, but because of a bad module (i2c) it didn't worked.
Today I finnaly got it to work.
Starting making everything almost like in the picture, everything mounted (and lots of black hot glue, no wires showing...
Didn't work.
One hour breaking everything apart without damaging the screen... Was a loose wire.
Started again... Didn't work...
The pot is also damaged, sometimes it works, others need to turn it hard.
New pot.
New set of wires.
Soldering everything right, testing all wires so no mistakes this time... But it takes so longgggg... Making everything in modules this time (to reuse without having to sordering again. And finally... It works.
By this time I should have 3 or 4 learning projects finish (I really wanted the screen to adapt all output in text, no serial, no blinking less, everything in modules, code prepared so, when I get my 40+ packages from China I already have a prototype tester ready.
10 hours... Fuck I'm really addicted, or else I would just solder everything together :D 28
28 -
First software refactoring in the company I worked for. No test environnement because "who needs it?", no unit testing, no comments, had to make sql updates and shit, was scared all day long that something would fuck up.
"Fuck fuck fuck, forgot a part of the where !" Had to fix everything quickly so no one would notice, no coffee/smoke pauses. On top of that, got a ton of retarded requests from the PM and other technicians working with me like "hey boi, could you add an icon to every button we made? There's like a thousand, we need it for tonight, our client will come visit us and I want to show him a better interface blablabla"
And since I was an intern, I couldn't refuse, had to work like a prostitute in virgin-land, and for what?
"Oi, you did good, now do other stuff"1 -
Here's how it usually goes:
1) I estimate the different aspects of the assignment to the best of my abillities, based on customer criteria and information. I come up with an realistic estimate for development and testing.
2) My PM runs the numbers through an algorithm. It adds time for other stuff, but its all still very fair and in tune.
Now to the fucked up part.
3) My ceo and cto looks at the estimate, and he will just turn on every possible button and twist the estimate into what he thinks he can get the customer to pay🤢🤮
This ends in the customer saying - no thank you.
He comes back to us and does not understand why they declined.
Idiot! -
fuck this!
spent an hour trying get my website working (on a raspberry) ... no errors, dev tools gave nothing, php gives nothing mySQL related... weird.. debugged my code for an hour when it me... db on my pc for testing is not the same one as the "production" server. i am so fucking stupid... i need some sleep3 -
When you give your team and the client a month+ to test the app and get no feedback, then all of a sudden once it's live in the app store you get an email filled with bug reports....
Were you guys not testing it at all?!
😡🤦♂️1 -
Why won't you just approve my PR???
Whats wrong with you?!
I don't understand your cryptic one-sentence feedback. I'm not even sure you understand what you're asking yourself.
What the hell does "make it a transaction" mean? Don't give me pseudo-code examples that don't even work fucking asshole!
Its a small change that does NOT need a canary build dammit. Don't go testing the ORM, its a goddamn standard library. Why does working with you make everything so complicated?!?!
The code fucking works! There is no need to make it comply to your specific tastes goddamn it. Working with you is like pulling teeth!
/endrant9 -
Hired by large prestigious company to do web development. Understanding at the outset, I was not a web developer, just wanted my foot in the door with the company. 2 days after orientation, I am placed on a $20 million contract expansion with 3 other developers. All new to this contract. So: new language, new technologies, new team, no leadership, no mentorship. 2 months later after a month of asking for help, I'm asked why I'm not delivering solid code by the project exec and moved to the testing team. Testing team lead introduces me to people on the contract and answers questions or tells me vaguely where to loom. Spend last 4 months building a professional fuck you by making myself a yes man to everyone and their mother. Left the contract and have been getting regular hours with them since (including developing for them). New contract loves me and despite the project execs attempt to torpedo me, I have an excellent reputation and am positioned for career advancement already.
I couldn't give him the finger, but I made him regret lettimg me go. Original team lead has since been released for unrelated HR complaint. -
spent 3 weeks with not more than 20 hours sleep per week on programming a mobile Chat Application. after finally 1 more week of bug fixing and testing and redesigning UI, App works like a charm! Most beautiful thing I ever created, my close friends are all astonished.
Happily I uploaded it on Playstore, 2 weeks later -> no downloads :(12 -
I'm using my devrant avatar for some UI testing :P , thanks @trogus and @dfox
(no production and plagiarism intended) -
A "partner" company has created a "REST" API we use on an online shop we developed to send all shop-related requests to.
At least once a month, something fails on their end and the customer calls us every time, expecting that we did something wrong, but it has never been us.
These "partners" do exactly zero testing, are extremely slow in solving API bugs, have almost no logging and have no monitoring on the API at all.
Today at noon, suddenly no customers were able to order anything anymore for 4 hours.
How the fuck can you run a business so unbelievably brainless that this keeps repeating monthly?
Time they fire all their "devs" and everyone in charge of the company and operations. TERMINATE.9 -
I hate those morons who do QA by simply clicking around. You are a disgrace to people like me who like to code and still enjoy doing testing.
Get a life you fuckers. You are the sole reason why many people in industry thinks that QA is something anybody can do.
Yes, I agree you can test the application, but in no way you could ensure the quality of the product.4 -
Boss fast tracked a release for a customer. No testing. Not checking commits or the state. Undocumented requirement brings down everything and everyone is running around with their hair on fire. Sigh.2
-
My tech debt meltdown is happening right now. We are releasing our huge micro service based product next week with no automated testing of any sort. Our front end clients are relatively DRY. No tests and dry = can't change anything = hacks on top of hacks.
Why? Team lead won't listen to me and has beaten me down so I don't care anymore. If it's broken fuck it.2 -
Business Continuity / DR 101...
How could GitLab go down? A deleted directory? What!
A tired sysadmin should not be able to cause this much damage.
Did they have a TESTED dr plan? An untested plan is no plan. An untested plan does not count. An untested plan is an invitation to what occurred.
That the backups did not work does not cut it - sorry GitLab. Thorough testing is required before a disruptive event.
Did they do a thorough risk assessment?
We call this a 'lesson learned' in my BC/DR profession. Everyone please learn by it.
I hope GitLab is ok.2 -
my boss, recently: "Partner company is complaining about seg-faults in our software" [the system is still in testing, not deployment]
me: "tell me what steps to reproduce the error and I'll fix it"
boss: "I'd like to prevent seg faults from happening no matter what"
...I literally can't even at this point5 -
A meeting to redefine the definition of done. Which a "senior" programmer threw in.
3 hours after we are still there to "define"... All of this because this developer and a couple more want to keep a physical board which has no space for a "testing" section, so the tasks need either to be done-but-not-really and this is technically wrong (who cares?) or in-progress-but-not-really which is technically wrong (again, who cares?).
Just effin find a bigger board and don't waste 3 hours of my life and/or start thinking pragmatically and accept tasks can move backwards or have a ticket saying "testing" stuck to them, ffs!
The funny part? This dev is probably one of the grumpiest devs I met when you talk about meetings which are actually useful.4 -
So today when I was testing my new website I learned that IE/Edge does not support smooth scrolling with JavaScript.
I get why it doesn't work in IE but Edge... like what? Edge is supposed to be a modern browser... No?8 -
The worst type of debugging: Programming an MCU without a Serial Monitor.
Some Context: I've spendt today about 3h+ on getting an attiny 45 to read 3 digital values on 3 pins. So for every test I wanted to make, I needed to put the MCU inside a socket put this socket on a arduino and flash it. Then extract it from the socket and put it on a breadboard for testing.
After getting headaches for nothing making any goddamn sense, I ended up noticing that one input pin is a multiplexed reset pin with the reset having top priority and no way to change it. So whenever this pin should have read a low signal, it got held in reset! FML -
Overengineering. Finding the right point between overdesign and no design at all. That's where fancy languages and unusual patterns being hit by real world problems, and you need to deal with all that utter mess you created being architecture astronaut. Isn't that funny how you realize that another fancy tool is fundamentally incompatible with the task you need to solve, and you realize it after a month of writing workarounds and hacks.
But on the other hand, duct tape slacking becomes a mess even quicker.
Not being able to promote projects. You may code the shit out of side project and still get zero response, absolutely no impact. That's why your side projects often becomes abandoned.
Oversleeping. You thought tomorrow was productive day, but you wake up oversleeped, your head aches, your mind is not clear and you be like "fuck that, I'm staying in bed watching memes all day". But there's job that has to be done, and that bothers you.
Writing tests. Oh, words can't describe how much I hate writing tests, any kind of. I tried testing so many times in high school, at university, even at production, but it seems like my mind is just doesn't accept it. I know that testing is fundamentally important, but my mind collapses every time I try to write a single fucking test, resulting in terrible headache. I don't know why it's like that, but it is, and I better repl the shit out of pure function than write fucking tests. -
So I'm working our remote build/testing server, and all of a sudden my computer just turns off. No crash message, no error, just turned off. My co-worker tries to help troubleshoot the problem.
Nothing.
I take the computer downstairs to the hardware department. They plug it in and it starts no problems.
After it finishes updating, I take it back upstairs and plug it back in.
Nothing.
I suggest that it is the power cable, and my co-worker looks under his desk. Turns out he had kicked the switch on the surge protector. 😑1 -
Last day of agile project i get asked for confirmation that the alpha system can handle 100000 records. We have had no load testing requests only feature pushes every sprint.
I see the back-end guys have used EF in a search function that eager joins a bunch of tables. Then the results get sorted and filtered in application code. It works fine for a few hundred records but the customer will do about 100k new records a year.
Yeah this won’t meet requirements. I wish they asked for some load testing before the last day. They aren’t going to like that one person can do a search every 15 seconds by the end of the year when I tell them. FML12 -
I hate it that I'm still forced to use Ubuntu 16.04 and can't upgrade to bionic beaver.tried it on vm (for testing)loved new features and default gnome interface but even after switching to xorg most of my tool were still not running properly or crashing, most important factor is that there is still no official cuda support and installing gcc g++ 6 and symlinks are nerve racking. On top of that upgrading to 18.04 LTS on my main machine will leave me with broken packages and dependencies.
p.s. for people who are going to reply saying that these issue can be solved. Please try updating your work machine and spend hours fix these issues1 -
Boss: so we've got to call an app to verify data in this project. But I've got no more info and I'm on holiday next week. Please contact GuyA next week.
Me: ok I guess?
*writes email to GuyA*
GuyB: GuyA is on holiday please hold the line
*1 week later*
GuyA: we need more time it's not ready yet
*2 weeks later?
Me: so?
GuyA: yeah it's ready here's the wsdl etc your client already has the password
*1 week later*
Me: yeah so I got the data but the api says my auth isn't working
GuyB: yeah your user isn't activated on the test system. I'm gonna forward that and come back at you
*1 week later*
GuyA: so we're going live in about 2 weeks hows testing going?
Me: well I'm still waiting for the response and activation
*suddenly it works*
Me: yeah so auth is working but i can't find any data. Is there any special test data?
GuyA: oh no there is NO test data on the test system. You need to wait for GuyB but he us not here today...
Me: are you fking kidding Me?????
... no response since then and it's been days.... -
Tl;Dr Im the one of the few in my area that sees sftping as the prod service account shouldn't be a deployment process. And the ONLY ONE THAT CARES THAT THIS IS GONNA BREAK A BUNCH OF SHIT AT SOME POINT.
The non tl;dr:
For a whole year I've been trying to convince my area that sshing as the production service account is not the proper way to deploy and/or develop batch code. My area (my team and 3 sister teams) have no concept of using version control for our various Unix components (shell scripts and configuration files) that our CRITICAL for our teams ongoing success. Most develop in a "prodqa like" system and the remainder straight in production. Those that develop straight in prodqa have no "test" deployment so when they ssh files straight to actual production. Our area has no concept of continuous integration and automated build checking. There is no "test cases", no "systems testing" or "regression testing". No gate checks for changing production are enforced. There is a standing "approved" deployment process by the enterprise (my company is Whyyyyyyyyyy bigger than my area ) but no one uses it. In fact idk anyone in my area who knows HOW to deploy using the official deployment method. Yes, there is privileged access management on the service account. Yes the managers gets notified everytime someone accesses the privileged production account. The managers don't see fixing this as a priority. In fact I think I've only talk to ONE other person in my area who truly understands how terrible it is that we have full production change access on a daily basis. Ive brought this up so many times and so many times nothing has been done and I've tried to get it changed yet nothing has happened and I'm just SO FUCKING SICK that no one sees how big of a deal this. I mean, overall I live the area I work in, I love the people, yet this one glaring deficiency causes me so much fucking stress cause it's so fucking simple to fix.
We even have an newer enterprise deployment. Method leveraging a product called "urban code deploy" (ucd) to deploy a git repository. JUST FUCKING GIT WITH THE PROGRAM!!!!..... IT WAS RELEASED FUCKING 12 YEARS AGO......
Please..... Please..... I just want my otherwise normally awesome team to understand the importance and benefits of version control and approved/revertable deployments2 -
During one of our 'pop-up' meetings last week.
Ralph: "The test code the developers are checking in is a mess. They don't know what they are doing."
ex.
var foo = SomeLibrary.GetFoo();
Assert.IsNotNull(foo);
Fred: "Ha ha..someone should talk to HR about our hiring practices. These people are literally driving the company backwards."
Me: "I think unit testing is complete waste of time."
- You could almost see the truck hit the wall and splatter watermelon everwhere..took Ralph and Fred a couple of seconds to respond
Fred: "Uh..unit testing is industry best practice. There is scientific evidence that prove testing reduces bugs and increases code quality"
Ralph: "Over 90% of our deployments are rolled back because of bugs. Unit testing will eliminate that."
Me: "Sorry, I disagree."
- Stepping on kittens wouldn't have gotten a worse look from Fred and Ralph
Fred: 'Pretty sure if you ask any professional developer, they'll tell you unit testing and code coverage reduces bugs.'
Me: "I'm not asking anyone else, I'm asking you. Find one failed deployment, just one, over the past 6 months that unit testing or code coverage would have prevented."
- good 3 seconds of awkward silence.
Ralph: "Well, those rollbacks are all mostly due to server mis-configurations. That's not a fair comparison."
Me: "I'm using your words. Unit tests reduces bugs and lack of good tests is the direct reason why we have so many failed deployments"
Boss: "Yea, Ralph...you and Fred kinda said that."
Fred: "No...we need to write good tests. Not this mess."
Me: "Like I said, show me one test you've written that would have prevented a rollback. Just one."
Ralph: "So, what? We do nothing?"
Me: "No, we have to stop worshiping this made up 80% code coverage idol. If not, developers are going to keep writing useless test code just to meet some percent. If we wrote device drivers or frameworks for other developers maybe, but we write CRUD apps. We execute a stored procedure or call a service. This 80% rule doesn't fit for code we write."
Fred: "If the developers took their head out of their ass.."
Me: "Hey!..uh..no, they are doing exactly what they are being told. Meet the 80% requirement, even if doesn't make sense."
Ralph: "Nobody told them to write *that* code."
Boss: "My gosh, what have you and Fred been complaining about for the past hour?"
- Ralph looks at his monitor and brilliantly changes the subject
Ralph: "Oh my f-king god...Trump said something stupid again ..."
At that point I put my headphones on went back to what I was doing. I'm pretty sure Fred and Ralph spent the rest of the day messaging back-n-forth, making fun of me or some random code I wrote 3 years ago (lots of typing and giggling). How can highly educated grown men (one has a masters in CS) get so petty and insecure?7 -
I've never installed games on my phone (except one or two for testing, from the beginning of my use on phone)
But Google keeps fucking suggesting Games every single time I open Google Play.
And no, it's not just one or two suggestions, it's the all fuckening screen full of games..
I'm not fan of games.. good work google and AI and alll stuff7 -
Working on codebase of a 20+ year old system that the company I work for bought five years ago and in that time there’s been no refactoring, no security updates, no attempt to create automated testing (there is none), new features have just been built on the codebase with no regard for quality and it’s just spun into the horror cesspool that it is today.
I joined one year ago and I’m slowly refactoring the codebase and updating it to get it to a more modern codebase, cleaner code, faster load times and creating a ton of dev documentation so the devs in India can start getting into best practices and start producing quality code.4 -
Fuck testing react native apps with Detox ! I can’t select a value in a picker no matter what I do 😭2
-
PM: Page load times are up. It might be your API blocking requests.
Me: Possible, though most of my load testing was performed against a random sample of requests at nearly 5 times the expected average per minute rate. I can add some logs but I think this is a red herring theory.
PM: Yes add logs, and New Relic and get it released ASAP.
Me: To confirm, you want me to make a bunch of diagnostic changes to a mission-critical API the day before Holiday break...
I felt like that guy from the Apollo 13 team warning Gene Kranz that the LEM was not built for this and I can make no guarantees... Released an hour before we went home for the weekend. -
Last Thursday, project owner insisted that the module I was working on to be ready for testing this Monday(though the supposed deadline is next week).
Went to work on a day off to deliver it as requested. Monday came. Monday went. No testing started. Project owner was on leave.
Now he's asking if we can start with the testing.
Hope I have laser beam eyes so I can toast him. -_-2 -
Tl;dr was told I couldn't and found I like programming. :)
Went to some school for testing out different industries but didn't have any goal nor found anything I was really interested in..
So i was tested for qualifications and told I was too stupid to be in IT..
So I decided to prove them wrong, went for an it supporter ground course and aced it with top grades + extra courses..
But still had no goals or dreams.
On that education, I met a friend who wanted to be a web programmer, so I decided to walk that path and aced another education with top grades..
Then I found, that I actually sorta enjoy programming and doesn't get bored quickly so then, I decided to plant my flag and become a programmer :)1 -
Spent fucking 11 hrs on fixing a stupid bug in Laravel that caused all my unit tests to fail. Just because that unit testing method has no unit test...
-
FUCK YOU GOOGLE
I feel I have zero control as a developer.. You made the shittiest choice by bringing in intellij , you made an even worse choice by adding gradle.. You add thousands of configuration options to manifests, layouts but provide no common place to find documentation for them.. This is just nonsense.. I've wasted endless hours figuring out your dex limits, proguard rules.. It's just frustrating.. Could you be anymore counterintuitive with your unit testing framework! Honestly it's a steaming pile of shit..5 -
Long time no see devRant. This rant is dedicated to an MQTT implementation we use. Mosquitto, mqtt.js - FUCK YOU.
I spent the last fucking 30+ hours trying to find why the bloody fuck the stupid server / client won't connect to the shitty mqtt broker. From changing all possible config, enabling & disabling specific code nothing abso-fucking-lutely works.
But then it will randomly decide to connect to the fucking broker, not causing any issues at all. And each fucking day when I wake up again and think to myself: oh today I can actually leave when it is still somewhat bright outside - NOPE. Because guess what? The fucking shitty abomination doesn't work anymore.
I just love these types of problems that are almost impossible to debug because the only logs you get is: "SERVER disconnected". It's impossible to get a proper reason out of this shit show, it's just turned into randomly guessing what the error could be (and especially where it could be).
And each time I got it to work, tested it and let the testing team know that they can start testing it will just stab me in the back and be like "fuck you, I'm not working any more". Luckily it's not like the deadline is next week... otherwise work is great, trust me.13 -
My mate just pen-testing on running production server using admin credential.
Guess what happen!
And no backup!
What a day!2 -
I'm not sure if it's just here, but in my country dev teams are not very organized. Most teams i've seen have no sense of process and they overlook testing.1
-
Since I have seen a lot of people uploading this kind of stuff lately, here is Xiaomi's test in production, back in 2017 November...
 1
1 -
Many "purists" love to piss on JavaScript and web development. And to an extent I can understand ostream’s frustration with these people.
It’s easy to criticize because yes: many web projects are indeed shit.
But I’d like to argue that the reason why so many of these projects are crappy is because of bad management:
- unrealistic deadlines
- no clear testing strategy
- or no testing at all because of deadlines
- no time allotted to catch up on technical debt
- etc.
This type of management is far more commonplace in web projects because things need to get delivered quickly and if they’re delivered with bugs, it’s no big deal as lives aren’t at stake.
I doubt this type of management is tolerated in projects where you’re working on software for welding machines (for example), where the stakes are that "you’re expected not to kill anyone" (to quote demolishun)
So in these types of projects, management can’t tolerate anything much below perfection and thus has to adapt by setting realistic deadlines that take into account the need for quality processes and thorough testing.
If this type of management was more common in web development, I can guarantee that web applications would be much more reliable and of better quality.
I can also guarantee that poorly managed non-web projects as outlined above would be just shitty as many web products.
My point being that’s it’s really DUMB to criticize fellow devs that work with web technologies on the basis that the state of websites/web apps is a mess. It just so happens that JS is the language of the web and that the web is where things are expected to be delivered quickly (and dirty … but we can fix it later mentality)
Stop acting like you’re the elite. I have no doubt you’re super smart and great at what you do. So be smart all the way and stop criticizing us poor webdevs that have to live with the sad state of affairs. ❤️35 -
No. I’m not going to take a 20 minute user-testing job disguised as a “survey” for you - for free, LinkedIn - and all your other super rich companies. You gotta pay people to work for you.
-
Best client I have ever experienced. Kappa
So, I got job to recreate one old website, because the old one was incredibly fucked up. She told us, it was made by someone retarded.
The code was fucked up even more than UI. It was definitely written by some kind of idiot. Diacritics, mixed languages, no OOP, no FW, just copy&paste. Yeah copy and paste for every page.
The DB was another level of shit. Inifine is not enough to describe it. Column names with whitespace, diacritics, uppercase, lowercase...pure hell. Yeah and I had to import it.
Whenthe new website was ready for testing I got an email from her that it was her who made the website... HER!! Fucking hell, no more of this please!1 -
New normal. New app to build.
- Still have to maintain older systems in parallel
- That leaves 1 week for developing the new app
- Slept 2 hours a day, coding coding coding
- Tested the shit out of the app because.. hey, its to help the customers' safety and health... I don't mind staying up late
- Finished the app in 5 days, code is now on prod
- Could barely look myself at the mirror because I look like shit
- Btw the app requires an external device as an input, the existing device works flawlessly based on my testing
- We need more devices
- Clueless manager bought new model instead. He assumed everything is fine, no testing is required
- Tested the app with new device model, doesn't work
- Deadline closing in
- Thanks, there goes my sleep
- THANK YOU1 -
The company where i am working at currently is kinda weird. The company is run by a gujrati guy and he has placed almost all his cousins in high positions...and on top of that the CTO (whos the bro of the owner) micromanages people and also fires them on a whim...i am kinda worried that if i am not able to do a particular task, i would be fired too...He has asked me to do unit testing of some complicated functions on mocha/chai and i have never done all this before. I am not understanding what to do and there are no senior devs in the office who knows about these things...7
-
YES!
Finished a complete version upgrade with vastly improved scalability and maintenance in just 3 weeks!
NO!
I forgot to do the database migrations as I went along. Ok... no problem.. I'll just use some kind of database comparing software, I'm sure they exist...
<googles...>
...fuck... is there not any for free?
Ok fine whatever i'll manually compare the tables and columns, fuck it. Sure there's like 50 tables and like 20 columns per... whatever...
should take like a day or so, with testing...
YES!
Finished my new version upgrade after just 6 weeks of coding!
....fuck sakes... -
I think I'm reaching now 40 hours in 3 days coding a function for a nasty grouping report.
Now the report is ready.
Testing with real data I'm 3/4 units off.
Now start at least one full week of monster counting-debugging-fixing on hundred of data.
If somebody get close to me in these days, I'll cut their throat drink their blood and eat their heart still beating, like Aztecs.
I'll have no time to cook or buy anything else to eat anyway, so it will be for survival.1 -
TL;DR: working too fast is as worse as working too slow
3 months ago the team leader left.
Sincee then, me and another dev are sharing his responsibillities.
Me and him used to do a lot of testing.
(In our team, the devs test and CR each other)
Now that he left, I often find myself sitting without anything to do - because I did all the available tasks and no one tested them or gave feedback.
Sitting with nothing to do feels aweful.
My manager sits behind me, so i cant sit on devRant or Twitter without feeling bad about it.4 -
What a disastrous deployment: instead of deploying one thing, 50.000 unexpected other things had to be done before. When the "official" deployment was done inside our own network, nothing worked as expected, servers had to be reconfigured, errors everywhere. Mind you it was tested multiple times by multiple people in a testing env. Difference between test and prod, classic.
When it was finally deployed, other errors started emerging, things that weren't considered before came to surface.
On top only the main dev knows the ins-and-outs, no substitute in case anything happens.
Deployment was rolled back in the end.1 -
I am forced to work with a client's notoriously slow SOAP api. Slow in this case is 1.5-2s per request.
The api is structured rather... creatively... at the same time. So we have to bombard it with thousands of requests to build our data base with historical SOAP data. Also the data sometimes is a couple of hours late, giving a flat line (all values at 0) until retroactively fixing the output for the same requests.
So to fill one dev data base with a year's worth of historical data (nice to have when testing a dashboard application) we hammer the api with ~20k requests (~1 million if we want to be thorough).
Best thing about that: There is no staging/test api and the prod api seems not to handle lots of requests at the same time very well...
Latest thought: Maybe we could put a varnish cache in front of the SOAP for testing. Better have wrong data, than nothing at all and we don't kill the prod clients every time we ramp up a new instance.
Also that would dramatically decrease the 4.2 hours of data pumping to about 7 minutes after the first run. -
Sprint planning, we spot a risk for one of the stories: An old client wants a new feature that relies on a third-party component that has not been included in our integration tests for the last 2 years.
The risk: It's probably not compatible with the new version of our system, if that's true, we'll need to make changes to our system before starting to work on the new feature, and setup integration testing.
Management: - Are you sure it's not compatible anymore?
Me: - No, we would need to bring both systems up and test if they work, there's no automation for that right now.
Mangement: - If you have not checked it's not a risk.
Me: (o_O) ? Whatever, I've warned you.
2 Days later: Our system does not work with this third-party system anymore, we can't finish the feature this sprint.
Management: (☉_☉)3 -
Not a rant but sort of a rant.
Getting REAL fucking tired of the corporate rat race.
Thought Bubble ...
{If I quit this stupid job I could do freelance sites}
Then I realized that I have no idea what skill set it takes to be a freelance developer. I only know my one little corner. Once I commit my code it goes off down the assembly line for others to worry about testing, deployment, hosting, security and other things I have no idea about.
So tell me freelancers, is the grass greener? What additonal skills do you have to have the us enterprise folks would have no idea about?
Or are you making huge bucks where you overcharge for Wix sites that do not suck?9 -
I value our most senior developer. His code is certainly clean and structured. He is the ultimate at KISS. However he's not a fan of testing and instead just says, well, did it compile? No matter how much I show him how great testing is, he comes back with how it's pretty unnecessary. Somehow, in the deep dark parts of the web, he finds articles that comply with his standing. I'm okay with him not making tests, I do it myself. But then when working extending or implementing his code, many of my parts are untestable because the parents are. Oye.6
-
I just love code-golf, I only started recently, but sometimes it's nice to fuck all coding conventions, missuse lazy evaluation and abuse scope leaking.
I'm normally really tidy with formating and whitespace placement, but code-golf is also a testing field for uncommen constructs and I think it can give deeper insights into a language.
I don't like languages specifically for code-golf though, these are just stupid and no fun (at least for me).1 -
When you join a project that has no testing, no component policy, a lot of css mixins, that has to work simultaneously as a pwa, android and ios app.
Oh, yes, obviously no documentation at all *flips table*2 -
So... I take over this one ticket to test... the ticket mentions some visual component popping up when a button is clicked. It says there is a success and a failure message. The title of the story also mentions another functionality.
I start testing and some fellow QA asks me why I'm testing in this environment. Turns out, three people are sharing one environment and three different things are deployed...
I ask the dev whats going on because I heard there are multiple people deploying stuff...
He just tells me "oh, my changes are deployed I just checked".
I tell him that it's not about that but about communication and testing one thing at the time. Then I tell him, that I wouldn't test until his stuff is the only stuff there.
Some time later he hits me up again, now with the env to himself.
I test and quickly I see, that there is only the positive message even when I make sure that the backend is not reachable. I tell the dev what I found and he tells me "oh no, it's just the implementation of the popup thing, it's just frontend for now"...
I tell him, that the ticket should say so.
No answer for like 1-2 hours. Then I get an "ok".
End of the day.
Next day I come in and the fellow QA tells me, that the dev asked him to test the ticket.
I ask him if he changed anything about the scope of the ticket, he says no...
I'm like "ok... know what... begin testing and then tell him what I already told him".
So he's testing and then tells him again to update the scope.
Later in the daily the the dev's update is besically "they won't test my ticket..."
It would have taken him like 1 fucking minute to update the ticket...
The whole QA team was always trying to being helpful and even when the tickets where sometimes not 100% clear we always made it work... but now we are more and more going towards "MR does not meet ticketdescription, fix it" and "I don't care if its just a small thing... fix it and then come back to me"...
Seriously frustrating some times...2 -
When your boss says "no more testing cycles until July because we've ran out, just push the builds" 🙃🙃🙃 🔫🔫🔫
-
Wish me luck. Looks like the feature I am developing is going to be late because QA doesn't feel like following the estimates we agreed on. We already identified that development was going to be the longest part of this whole effort and that QA was going to be relatively easy, but but no. Because this is the day we have to be "code complete", they don't want to test a relatively simple feature. In fact we had to talk them into even starting testing on it today. Even though regression day is Monday and they are basically going to be done testing their last ticket this morning. Like what the fuck were they going to do for the next 7-8 hours? They don't write any documentation. There are no reports to do. There are no meetings. Did they just want a virtual day off?
Edit: they are literally playing with people's careers here. This is not the first time I have had something delayed by QA even though they agreed that it was simple to test and it was delivered with enough time to fucking test. Then I get in trouble because of late delivery.5 -
During an interview, how to detect if a company has a dysfunctional flow of development? What good questions to ask?
Like things are scattered all over and there's no standard being followed, no architecture, no code reviews, everything is a patchy magic, no testing, and everything is just on fire! How to avoid such companies?6 -
Just had a class where we had to write a heap adding algorithm in Java to reduce rounding error for x amount of floats being added together
After an hour of writing code with no testing anything I finished. Ran the JUnit tests provided by the teacher and it passed all the tests!
Who says it can't work the first time? 2
2 -
Found out today during testing that a page made it to the server when it wasn't supposed to exist... Angry soapbox dev sent out a blast email... No you cock, it's not supposed to look like that because it's not supposed to fucking exist. 😒
-
So working for a company and the dev team I’m apart of works on a legacy rails app. Technical debt is high, no automated tests, no proper routing and also running unsupported versions of the language.
I joined seven months ago and got the current team doing automated testing so that’s a plus, they bought this app four years ago and there’s been no language updates, testing, cleanup, security updates, nothing, just adding to bad code.
Now we’re looking to actually upgrade language versions, the language and the framework now this will cause a lot of stuff to break naturally due to how outdated it is.
So I started putting proper routes into place how things should of been when things were being built as we have some spare time I decided to go out of my way to clear up some of the technical debt to get ahead of the curb. Re-done an entire section of the app, massive speed improvements, better views, controller, model, comment clean up and everything exactly how it should be.
I push the PR,
*other dev* - “why are we doing all of these other changes”
*me* - “well to implement routes properly, we have to use the new routes I just did some extra cleanup along the way”
*today, me* - “can you lend me a hand with one of the routes the ID isn’t getting passed”
*today, other dev* - “this wouldn’t of happened if you didn’t redo all these files, let’s just scrap the changes”
…
Sooo, I’ve spend three weeks improving one section in the app, because I’m having issues with one route according to this dev I should scrap it? Wait come again, am I the only one in this team who cares about making this app better all round?
Frustrating…4 -
Upper mgmt paying an enterprise software vendor 40k US annually. Told vendor No more me QA'ing for them and 'discovering' obvious bugs. Told them to hire QA person and spring for some automated testing software. Yeah I know I am a nice guy but Enough is enough!1
-
I just reviewed a pull request with a test case like (pseudo code):
# Test MyService
const mock = createMock(myService.myMethod)
.whenCalledWith("foo")
.returns("bar");
assert(mock.myMethod("foo") === "bar"));
Why though? Why are we testing the mock? What is happening here? This test has no reason of being there instead of a fuzzy feeling that we now have unit test to lure us into a false sense of security.
I asked why we don't do an integration test. Response was: "They are slow."
Well, duh, but at least they would actually test something.
What do you gain by asserting that the mock is working the way you set it up?3 -
I have become the only thing I always hated in a developer. Building a project without a proper documentation.
As a solo developer in a company where I have to do database architecture, front-end, back-end, testing, NETWORKING (I am the most ignorant guy when it comes to networking), product design, there is no time for documentation.
But hey, I have structured the project, files and functions (with comment, parameters type and return type) properly and I understand what I've done even after 4-5 months without touching that specific project so I got that going for me which is nice... I guess.3 -
The scope for this project was absolute horse shit, and now they are mad because the end product is still horse shit...
I want to feel guilty for the outcome, but I just can't. This is something they should have had foresight for. Validation and testing is absolutely atrocious here. No official real scenario testing, and now the whole thing has been blown wide open for all the shit it can't do. -
I must admit sometimes agile methodology zealots annoy me but I just quit a shop with no process, no source code repository, and no testing. I worked there a month and had no idea such places still exist. I knew it was a bad idea but I needed remote work. I tried to evangelize to them but they blamed me for everything after they fired the project manager.6
-
Ranting...
So they called me for a phone interview, I made a good impression, the job desc. states that it's a full stack Java/J2EE Developer, after all they hired me.
Now I found myself doing validation (Implementing a VTP for functional testing) using UFT and VBS for an eclipse RCP application made in 2007, in my previous job I was a TL for a Spring/angular application with five other developers building a LIMS from scratch, I feel a bit disappointed, although the salary is pretty good and there is no stress at all.
Any comment is welcomed.10 -
Counted it out... 100k LoC frontend & backend... Not a single automated test. No unit testing, no integration testing, nothing. I've been asked to implement a CI server.
Halp5 -
Back on my university internship.
I knew nothing about web dev and it was a full stack role. I was taught nothing and just sat down and ran entire solo projects for websites and web apps. Everything was down to me including client contact.
Taught nothing and had to learn the entire stack on the fly whilst trying not to get fired or lose clients. Company had no version control for these projects, no quality assurance/testing, no frameworks or anything.
The first 3 months were not a good time. -
My company never used unit tests. And i would love to educate but i do not know how to unit test properly. I always en up with: if i want to properly test all ins and outs of this class's + operator. I need to add checks for positive number, negative numbers, nan, infinites, nulls etc. Etc. It needs so many tests for something so stupidly simple, that i don't see a way to motivate people to use it.
Am i missing something? Is there a guideline for "ok coverage"? Is testing just that much work and is that why nobody cares until it is too late?
I have been reading a book about working with legacy code. But still i got no answers. Halp!7 -
Got designs on Wednesday afternoon. Final changes on Thursday and they expected me to work all weekend because they were lats for designs I asked 1 month ago for QA and testing. Not my fucking problem.
And not working on a weekend.
And today got told that components were missing and they needed animations. No fucking duh7 -
Load tests:
I'm used to do load tests in Visual Studio where it gives which line is exactly your bottleneck. But now I'm using VS Code (visual studio requires enterprise license for load tests :\ no longer have one)
Anyways long story short, what are the best practices for load tests? For me what I'm testing is how much can a given hardware specs handle and when test fails I go back and check if code can be optimized, is this the correct way to do this?7 -
Out of curiosity for all the front-end web developers, do you normally test to make sure that your websites are accessible to the blind, color-blind etc.. ? (and i'm not just talking about "alt" attributes)
I've been working as a web developer for over 5 years now at several different companies with close to 100 websites and not a single one seemed to have even considered it. The first time it came up was because a client REQUIRED conformance level AA or higher (I had no idea this was even a thing). In my opinion, ensuring that your website is at least somewhat accessible should be an essential step in every project.
If anyone's looking for some tools to make testing easier you can check these out:
- axe - Web Accessibility Testing (chrome extension)
- Accessibility Insights for Web (chrome extension)12 -
Senior dev on our team is concerned that we are raising standards above and beyond what we need to deliver the project.
For 6m+ this project has delivered little, but what there is is full of bugs that got through testing, and no standards (coding or otherwise) in place at all.
I hate dealing with people who preach “good enough” is fine but won’t accept they aren’t even close to doing “good enough”7 -
ATTENTION PLEASE! Important announcement following:
Please check your interface implementations for correct byteorder according specification BEFORE YOU START COMPLAINING ABOUT DATA FAILURES ON EXCHANGING DATA.
Freakin hell, if I'd get some money for every byte order mismatch on testing interfaces, I'd be a be a billionaire.
And why are all those highlevel I-know-every-fucking-framework developer incapable of checking the real memory content of a datatype, and the real data content on the interface even if you tell them that their byte order is obviously wrong?
No, your system is not the centre of the universe and I don't care how you get your less-than-32bit-datatypes-are-for-assembler-usage-frameworks to change byteorder. It's not rocket science, if there's no ready-to-use-function then write those 4 lines yourself.
Next time I get to specify an interface I'll go for mixed-endian, just to make sure everybody involved knows the concepts of endianess afterwards.2 -
It realy just warms my heart when the customer provides us with software that I need to go through manually and test every method individual before we can start implement it. Then I have to spend hours testing every fucking bit of it to make sure the modules we control with said sw doesnt meet their untimely doom cause the sw is too broken to actually run.
Any.net developers on this plattform? If you doesnt use these xml comments for commenting methods, you're on my hit list.
I realy hate these back-alley developers. Sorry of I sound salty and whiny but seriously. These past 3 weeks, most of my time Ive just worked around issues instead of solving them, cause their sw just keeps chaining good coding down to the ground. And theres no documentation cause "we have higher priorities ", testing is done by us at release cause "its faster and we dont make mistakes" and worst of all, our contact quote on quote "senior experienced developer lead design im far up my own ass and way more experienced than you" guy is a consultant who is only reachable about 2h on a daily basis.
Tldr: we live in a society. -
I'm currently testing live and that includes trying sql injection, i have no backups. So if i forgot to escape string somewhere, I'm fucked. I like to live dangerous :D
Alos, i always test sql injection with "--; DROP ALL TABLES;" Casue... It's a bad idea..?1 -
VP last week: No you can't have that equipment that fakes out the gps. It's very expensive and not in the budget. Just run valgrind and push your code so we can deploy it.
VP in today's all hands: Guys, if you need test equipment, come ask for it and we'll get you what you need. Not having equipment is not a valid excuse for skipping integration testing.2 -
Not sure if junior dev is lying or just really bad at using the search function. He made sweeping changes in code he inherited from me and failed to find all the jQuery selectors that broke because of it. And he didn't think of clicking on all the other buttons on the page to check they are still doing their thing. Of course claiming that there is no time for testing when I pointed out his mistake. Wish he'd stop being such a bad, this is not the first time this has happened!
-
Has anyone else actually *used* mutation testing at all?
Heard a lot about it recently - it seems all the rage amongst the bloggers, but I'm generally always very sceptical of things touted as the "latest hotness" (my thoughts on blockchain for instance are well known.)
So I went ahead and whacked http://pitest.org/ into one of my more recent pet projects to see if it offered anything decent. Surprisingly, it did - in particular it caught a number of places where switching "<" for "<=" and similar had no affect on the pass / fail rate (indicating the tests should be better.) There were a *few* false positives, and some which were borderline useful, but as a whole I'd say it was a worthwhile addition.
Curious as to if anyone else has had the same experience?1 -
So with the current project that I am working on, I'm in charge with creating various base classes, libraries, and helpers. The problem is that the other developers on the team just want to dive straight into developing the API endpoints without designing what the request and response formats should be, let alone decide what the URL structure should be!
So in the middle of their development work, they keep telling me how this and that don't work, or they can't figure out why Laravel is throwing this particular error. It's starting to piss me off that I'm having to do an architect's job whilst also teaching these guys how to use Laravel because they don't bother reading the documentation.
The worst part is that once they've completed their implementation, I'll have to end up fixing it because it's either missing a bunch of business rules, or it doesn't account for any error handling. -
"Oh I knew they'd say that it's why I didn't get them to test it "
Did these words really just come out of your mouth? Who the fuck left you in charge of planning this shit?
Some team manager requested dev work it got approved and done standard. However they knew from the get go their team would rip it apart so when it came to the testing phase did he get his team to use it?
No he pulled fucking random people from other teams who don't use this feature at all in their day to day to test and sign it off.
Sod your vision mate. Our team just lost two months of work your team's productivity has dropped because you had a picture of how things should be but didn't want to be told no. And for a fucking valid reason your method is shit.
Don't think he'll be left in charge of a project anytime soon. -
In no particular order:
Educational website on comunicating with politicians
A mobile app game
IoTing my condo (lights, blinds, and thermometer)
My node bot
A website automated testing tool. -
That moment when: You're asked to quickly code a fake login screen and you have a deadline to add it to 10 devices before 2pm.
First build: Forgot to force it to be on top, forgot to add closing preventions
Second build: Due to it going on tablets, it needed an onscreen keyboard, but being on top all the time means the builtin onscreen keyboard doesn't work.
Third build: Forgot to add try and catch exceptions which caused crashes
Final build: Avast kept closing and opening it due to DeepScan
urgh... -
I just tested a VPS and it was kind of impressive: I just had shared hosting until now and it is a total difference when you're having full root access.
Kind of hating these greedy shared hosting fuckers now ;)
Because it was just for testing purposes, I wanted to try the mysterious command "rm -rf / --no-preserve-root".
It was working for around 5 minutes and after that literally no command worked anymore!
Not even reboot worked :P
Then I tried reboot it via the VPS panel :) End of the story: vps panel chrashed with error message: unable to start vps :P
I thought it was kind of funnny and nice to share & thanks for reading 'til here!5 -
I'm literally one junior developer building a front end stack for a company that uses the waterfall method of building shit...
My application has not been fully tested and none of the real user base has actually tested it. I have no clue what potential egde cases exist in my application. I did as much testing as possible but it's keeping me on edge that there is potentially something broken lurking underneath that I don't know about.
If it is broken it's all erupting into flames and there's nothing I can do about it because the application will have to go through a whole beuacratic process to allowed to be fixed.3 -
So... I might have to build a survey and analysis tool to be used online nation wide (the final client is the government).
The bad news, it's probably going live in a week.
Even though 90% I wrote and tested in the last 3 years (matrixes,formulas,dB, Interface elements ) from previous runs, I have to handle fronted, databases, math, testing and design.
Over a daily changing methodology and session workflow (by my direct client).
No sleep for the next few days 😭6 -
So I'm working on some communications app which bridges the main server/database with some equipment on the field. Now this equipment works in a redundancy pair: two cpus, A and B, both connected via ethernet, one active, the other standby/replicating and no comms on it. One obvious requirement is that when this equipment swaps the active cpus the comms app should switch as well. Fair enough, going with this into testing phase.
This guy, from qa, got some instructions from someone else:
1. Trigger the soft switch from equipment so that cpus got swapped.
2. Remove the ethernet cable from the standby unit.
3. Observe the communications.
And the test goes like: cpu A is active, B is standby. Switch is triggered, B becomes active, A goes into standby. The cable is pulled out from cpu B.
Test result: failed, no comms ever4 -
Report comes in that there is "no purchase confirmation screen" in the app.
Well, yes the hell there is, so I use the test credit card to make a purchase. Sure enough, it works fine on my testing account. Just to be sure, I try a couple other test accounts. Flawless.
"No, try it on *this* account"
I try again on their stupid account. Works fine.
"Well I just tried it in Chrome and it worked, it doesn't work in Firefox"
I was already testing in Firefox...
Wasting my time over a corrupted browser profile.. GTFO, why are you even a tester? -
> be me, working on small addition to enormous feature branch
> build system in flux due to reorganization started a month ago, not quite solid yet, but mostly works
> f_branch gets master merged into it sometime last week
> bossman makes "minor" change to build system and edits master to match
> doesn't merge changes into f_branch
> bossman goes on holiday for a week
> no permission to merge master changes into f_branch
> linter barfs
> npm barfs
> build server barfs
> mfw I can't even deploy to our testing environment 4
4 -
Spent most of this week busting my ass working on a hotfix that came out of nowhere with mega high priority. This annoys me greatly because the hotfix wasn't even fixing a bug, it was adding new functionality because certain customers were being blocked from testing without this specific feature. In my humble opinion, given that we release every weekend, hotfixes should be reserved for actual critical bugs. But anyway, as I probably could have predicted, the code got to QA and exploded. Literally nothing works.
This is what happens when you try to rush out features to satisfy customers. If you try to rush something that is late, you WILL make it later.
Meanwhile there's an issue I'm supposed to be fixing for our next release which goes out this weekend and I've had no time to even look because of this hotfix. And now it's the end of the day and I just feel worn out from stress, tomorrow will no doubt be similar.1 -
when you've been moved to quality assurance, and is forced to watch hours of videos and read hours of blogs, just to keep you busy because there is no testing work but plenty of developing work to be done...2
-
can't take this sh1t anymore, will start updating my CV today.
I have to steer wheels on this shitty php-related task with testing suites with latest guides written in 2014, code base of that suite got a shitton of changes.
When referring to original documentation and example that is not working and gives me loads of errors, community pricks just saying something like: don't use 6 year old tutorials!!! well, that is the latest I could find, so yeah -> basically go fuck yourself situation!
went alive from 1st part as I managed to make some hacky clusterfuck that works. now i had to switch library that has no documentation at all, has shitton of options and lattest update is like from 3 years ago, library that is connected had some breaking changes lately so to no surprise I can't get this shit to work!
Is whole php ecosystem just made of folks who simply doesn't give a fuck and latest knowledge update they had is like 4 years ago?
ofc I am excluding laravel community in this!2 -
Mid - senior dev (L from now on) comes in on a project to help out. Starts working on creating a dashboard for the application. Work is progressing, new ideas come in, team lead (TL) is ok with everything, business analyst (BA) is also ok. The dashboard even gets thru testing (T), everything is great. In comes (A), a (probably bored) junior backend dev.
A little backstory about (A):
- seated right next to (TL)
- most discussion about every developed feature take place at (TL)-s desk, right next to (A)
- (A) was also present when discussions took place between (TL) and (BA) about dashboard
- (A) could have easily heard any number of the other team members (over 15) talk about the dashboard
Well, (A) comes into the picture ... and the dashboard (first page after login, big shiny new thing, working just fine ...) breaks. Well, breaks is a little understated. Disappears would be more exact. Cause (A) commented it out. NOT deleted from code. JUST commented out the code.
But why you ask? Because he didn't know what it did and why it was there.
No asking around, no looking up history in repository, no looking up tasks that might be related to that ... no nothing.
He's a backend dev, there's something new and unknown in the backend, the new thing has to go.
(L) didn't scream, (TL) didn't scream, (BA) didn't scream, (T) didn't scream ...
I almost screamed. This didn't happen to me, or (A) would have screamed!3 -
A shitty platform that, although open source, there is no clearly documented way of setting a development environment for it. This pile of crap states clearly that it does NOT support RTL languages. One of the core business requirements is Arabic support. What to do? Look for other platforms? WRONG!
Base the fucking business on it and ask ME to see why the SQL database is not encoding the Arabic characters correctly and to look into the logs that back-end puked. My expertise is mobile development anyways damnit. Sure the backend code is Java code (Java jokers and haters, not the appropriate place) and I know it but there is no fucking way to test that motherfucker or to build it! No fucking testing server can be made! Only instructions to get a Docker image pulled and set up.
FML.
"This company is a fucking م."
I cannot believe I am so frustrated that I am ending this rant with a fun puzzle.
Hints to help you decipher the quoted sentence:
Hint 1: That Arabic letter is the perfect letter.
Hint 2: You don't need to be an Arab to understand what it means.6 -
In my first few months of my first dev job, I written this fragile piece of code in, trigger warning, PHP that sent out email reports to my clients. It was a two men team, and we have no clue about TDD or how to do unit testing for such code. We would just run that piece of code manually do send out dummy emails to ensure things were working.
One day the code broke. I was told by my boss to fix it. Spent the entire day trying to fix but couldn't get anything done. Finally at around 7pm my boss came by and asked why is it I couldn't get it fixed. He helped me troubleshoot and fixed it. And subsequently told me "c'mon man you're better than this."
It turns out that he changed a part of a code that was supposed return an array of strings to an array of objects, adding a second attribute that wasn't even in use.
So what that meant is that he changed a piece of working code, to include a property he didn't need, committed and push to production without even manually testing it. AND TALKED SHIT TO ME.
That was the day I learned git blame and began my journey on TDD. -
(I am not a native english speaker so please excuse any mistakes I make while writing this)
I know, during an internship, its good to see all different sides of the job and of course QA is one of them. Its definately good to know as a dev later how QA works, I can see that. But why the F U C K do I have to test the same 3 pages (not websites, PAGES) since 5 days for 8 hours a day even though NOTHING CHANGES?! The page doesn't get updated, I am just sitting there clicking around and wasting my time I could use to learn more PHP or jQuery or WTFEver. But no! I have to sit there for hours and hours, doing nothing but staring at a page where I already tested literally anything that can be tested 4 days ago. If you don't have a good task for me over there in QA, then STOP WASTING MY FUCKING TIME instead of forcing me to continue testing this stupid website even though testing already completed a few days ago!!! I don't even have Test Cases to follow, its just “yea look at this page and click around is something is broken“ for 5 days. There is nothing broken, your fucking website works fine. And now STOP WASTING MY TIME!!!!6 -
Should I be even be testing if no one cares.
I keep asking Devs regarding the functionalities of their system for testing and then, realize it's already on Prod even before I test in beta or enable to test in beta.
Do I exist!!!
Now, for the nth time, I have started to test when things are almost there or already there in Prod.
I should keep myself in adrenaline mode always on from now on.
Need to do something worthy.
The worst way to start a new job.2 -
GraphQL or REST?
I'm not really worried about boilerplate (my research reveals it's roughly the same), I currently have a (very incomplete) REST interface, but that was just for testing.
Also, the API has no real usage yet (I only use it for submissions) and it literally exists for the sake of having an API (so I don't need to write it later).10 -
When your job description says you are a mobile developer, but when you started working, you have started handling teams and doing web penetration testing. Then after 2 yrs of that still no salary raise. =.=2
-
Got my QBASIC demopart ready for testing, completely optimized and ready to roll. Found 486 owner (33MHz, 8MB of RAM) who tested it for me.
Takes 13 seconds for the scroller to draw each frame at 300x200.
No possible optimizations are present, everything's crushed as far as it'll go, meaning a completely different method of scrolling is needed.
(Still faster than the array method by 37 seconds per frame, but y'know...)
fuck me... -
!rant
Coworker: *Watching a DefCon talk*
Me: *walks over and notices an image on the slide of a woman sticking a cotton swab in her mouth with text saying "get paternity testing"*
Me: Paternity testing? But that's a woman!
Coworker: *silent for a second* What? Oh! *gets closer to screen, chuckles*
Coworker: It actually took me a second to catch that because I wasn't looking at the video, I was looking at the side "related videos" or the ad and I was like "no... did you mean Penetration Testing?" But even then, this is DefCon, so there aren't any women--or at least less than 3. And then I saw it in the corner and was like "Oh, I see it. But yeah, Paternity.... Oh wait..."
Me: Jeez, it really did take you a while...
Coworker: Yeah. All the while I was thinking "What the heck are you on," and then there was the "Oh, I get it" moment
Me: At least you got there -
* Gets handed additions to current software platform (web)
* Gives back estimte of time after meeting with everyone and making them understand that once the testing phase of the project is reached there will be no changes, tests should be exhaustive and focus on SAID FUNCTIONALITY of the new additions. NO CHANGES OR ADDITIONS AT THIS POINT IN TIME
* All directives, stakeholders, users etc agreed on my request and spend an additional hour thinking of different corner and edge cases as provided by me in case they can't think of them (they can't, because they are fucking stupid, but I provided everything)
* Boss looks irritated at their lack of understanding of the scope and the time needed, nods in approval after he sees my entire specification, testing cases, possible additions to the system etc
* All members of the committee decide on the requirements being correct, concrete and proper.
* Finish the additions in a couple of weeks due to the increased demand for other projects, this directly affects the user base, so my VP and Director make it a top priority, I agree with their sentiment, since my Director knows what he is doing (real OG)
* I make the changes, test inside of my department and then stage for the testing environment. Everything is ready, all migrations are in order, the functionality is working as proper and the pipeline for the project, albeit somewhat lacking in elegance is good to go.
* Testing days arrive
* First couple of hours of test: Oh, you know what, we should add these two additional fields, and it would be good if the reporting generated by the system would contain this OTHER FORMAT rather than this one.
* ME: We stated that no additions would be done during the testing environment, testing is for functionality, not to see if you can all think of something else, even then, on June 10 I provided a initial demo and no one bothered to check on it on say something.
Them: Well, we are doing it now, this is what testing is for.
Me: Out of this room, the software engineer is me, and I can assure you, testing is not for that. I repeatedly stated that previously, I set the requirements, added corner cases, tables charts everything and not one single one of you decided to pay attention or add something, actually, said functionality you are requesting was part of one of my detailed list of corner cases, why did you not add it there and then before everything went up?
Them: Well I didn't read it at the time (think of the I in plural form since all of these dumb fucks stated the same)
Then my boss went on a rampage on their dumbasses.
I fucking hate software development sometimes.
Oh well. Bunch of fucking retards.2 -
FMF! .NET Core's F# REPL depends on a bug. For two years the testing and building issue referenced as a reason for depending on the bug has not been resolved. Since 2016, no one has been assigned to fix the bug though the producer of the bug hates himself. Only the self-hating deserve love2
-
Started new internship last week, hired as dev but working qa till their next release goes up. See last 3 posts for some horror lmao. They... don't know how to use git but insist they do. 275MB single repo for entire angular frontend (no dependencies are pushed, few images) and "angular backend" (according to PM). Commits to master, bad commit messages, no testing except me on qa..... death
-
A peace of work to be done within 2 weeks for 3 devs
1 dev gets pulled off the team, the other decides now is a good time to take a 2 week holiday
So am the only one left and because the designs weren't even ready for the first week i only had a week to do it, i managed to finish it with some defect obviously, and testing oh yes the testing non, non whatsoever. Only test i had were snapshots. Other than that, nothing. So the demo seemed to please everyone and the whole team got praised for some gr8 work, work that was estimated for 3 but done by one and hah no testing...yet1 -
1) receive functional requirements
2) create functional specification, post it on forum (no jira)
3) create memo document, post it on forum (no jira)
4) create analysis document with actual code changes without seeing the code (wait for step 8), post it on forum (no jira)
5) receive review on analysis document, fix it and post (no jira, redmine etc from now till the end of rant)
6) after analysis is approved make a checkout request
7) source code manager checkouts files from svn and posts them on forum along with the files list
8) you make actual changes to the code, post changed sources on forum
9) source code manager makes a review to check that amendment commet is present in source code and is properly tagged, and every line of code chnged is properly tagged (you are not allowed to delete anything, not even one space, you need to comment it (and put an appropriate tag))
10) after you passed review you fill in standard compilation request form
11) you code is compiled and elf is put on testing stand
12) you fill in "actual behaviour" and "expected behaviour" columns near description of changed function in template of unit test plan document (yeah we have unit testing) and post it on forum
13) if testing ok changed sources and compiled elfs along with its versions (cksum) commited to svn (not by you, there is a source code manager for that)
14) if someone developed function in same source file as you "commited" he is warned by source code manager and fills checkout request form again
15) ...2 -
Imagine a workplace. A workplace that is planning a local event for tomorrow with deals and a free discount code for those who arrive.
Only thing is: everything is chaos, no one is taking responsibility for the event, no one communicates about changes or how the event is going to be.
Now you get a call off duty. You have to check a discount code that wasn't working. You were to set it up for the event. But apparently they decided to open the doors for the event TODAY. You get a call 5 minutes after the first. "Is it done yet?" NO. Because you have to FIX CODE and deploy changes because they don't have any staging environment, no proper testing environment and (best of all) development mostly connected directly to the production database.
This! This is my job.
I am so fucking mad.
I need courses on how to grow my spine even more and demand what should be fucking law at this point.
Or maybe just leave. I'm the only dev.. 😎4 -
If you wirte Code for hours without testing or either compiling it and in the end you get no error and you know this is not possible and began to search the error where no is...
-
My experience with a recruiter is for the internship I'm currently half way though the manager that interviewed me said I would be constantly developing tests for code...jumped at this opportunity as I have no prior testing experience 3 months into internship and I haven't seen a single line of code I am studying software development and my skills as a developer are not increasing what so ever I feel but since I'm an intern I'm not sure should I ask to move team or stay put for the rest of my internship and put it down as an experience2
-
When someone does a not-very-thorough mass rename but doesn't check if it causes problems in already tested sections.1
-
My current task is the one I abhor most - manual testing. Lots and lots of manual testing to find a performance bug, which may or may not exist. Am I able to take a couple of days to write a tool to automate this task? No, no I'm not. I must report my findings daily.
-
I like the people I work with although they are very shit, I get paid a lot and I mostly enjoy the company but..
Our scrum implementation is incredibly fucked so much so that it is not even close to scrum but our scrum master doesn't know scrum and no one else cares so we do everything fucked.
Our prs are roughly 60 file hangers at a time, we only complete 50% of our work each sprint because the stories are so fucked up, we have no testers at all, team lead insists on creating sql table designs but doesn't understand normalisation so our tables often hold 3 or 4 sets of data types just jammed in.
Our software sits broken for months on end until someone notices (pre release), our architecture is garbage or practically non existent. Our front end apps that only I know the technology have approaches dictated by team lead that has no clue of the language or framework.
Our front end app is now about 50% tech debt because project management is so ineffectual and approaches are constantly changing. For instance we used to use view models for domain transfer objects... Now we use database entities, so there is no commonality between models but the system used to have shared features relying on that..sour roles and permissions are fucked since a role is a page regardless of the pages functionality so there is no ability to toggle features, but even though I know the design is fucked I still had to implement after hours of trying to convince team lead of it. Fast forward a few months and it's a huge cluster fuck to enforce.
We have no automated testing of any sort or manual testing in place.
I know of a few security vulnerabilities I can nuke our databases with but it got ignored.
Pr reviews are obviously a nightmare since they're so big.
I just tried to talk to scrum master again about story creation since any story involving front end ui as an aspect of it is crammed in under one pointed story as sub tasks, essentially throwing away any ability to calculate velocity. Been here a year now and the scrum master doesn't know what I mean by velocity... Her entire job is scrum master.
So anyway I am thinking about leaving because I like being a developer and it is slowly making me give up on doing things to a high standard and I have no chance of improving things, but at the same time the pay is great and I like the people. -
I would enjoy a position where I would have to write tons of tiny scripts for solving different logic problems. Tweak data, visualise it, pass it through different mediums. I would feel the best in research, implementing and testing different ideas, and build solutions for later use. Right now I'm on the first line at the customer site where the upcoming problems have to be solved instantly, I have the constant feeling that the thing could be much more efficient but there is no time for change, test and implement differently, so I'm not really using my full capacity on anything. I'm kind of a user of the built stuff but I feel more a developer. At the other end I'm satisfied and this is the best job I ever had :)1
-
When your boss says this is the cause, it must the cause. No, you don't need logs, you don't need any investigation, you don't need any proof to support why this is the cause. You don't have to provide alternative suggestions or any testing... Because he must be right! Just fix it the way he told you!
-
On a website, which is evolving, QA guy wants specification for website testing. Da, click anything you find, see if some thing changes. There is no specification which can compensate for incompetence. Aaaaaaaaaaaargh........1
-
Deploying a full test strategy across the company's range of php products because you haven't been scheduled to do anything else and the company has no automated testing after 10 years of functioning.
-
- "Two months" training upon hire, with all the other hires too.
- Entire thing takes place in a hotel's larger room meant for small conventions or whatever.
- Brought on as Java developers, told there was Java work for all of us
- By the end of it, there wasn't
- Sit at our company's office for a month doing nothing, waiting for work
- It's summer time, 90F+ heat, and the A/C not only wasn't on most of the time, when it was on it was actually heating the building instead of cooling
- Get on a project, join the client site, takes at least a week to get a laptop, takes a month to get most of the needed accesses
- Was brought on because they needed a SQL Developer, I do not know more than basic syntax which I told them
- Project is 3 months behind already
- Really no development since Offshore handles it (poorly)
- For the first year+ of my time here I am doing nothing but manual quality assurance testing, and no development
It's hard to leave when you aren't learning -
Did this interview with a tester for internship. Started to get the feeling that this person maybe should have chosen another education.
On the question: "What do you like with testing?", the answer was "Designing templates for bug reports".
Guess it's gonna be a quite boring career.
And no, we didn't hire. -
I'm currently working as a technical product manager. We lost a QE a while ago and I stepped into the ticket testing, happy path, and some exploratory testing for our tickets.
I had a friend from another company tell me to apply for a QE position. It's a combo product and QE position and I'm about 80% qualified.
Can anyone give me any places I can quickly and efficiently learn about setting up automated testing? I have some background in css, js, and html but basically no c# or other languages. -
Read this and tell me OOP (or at least C#) isn't broken:
https://levelup.gitconnected.com/5-...
All I want to do is mock System.DateTime is for a few of my tests, and I ended up going down this rabbit hole of absolute horseshit: build a custom class that you can mock in tests, blah blah blah blah, uhhhh... YEAH NO
Such a simple functionality / need, and yet there is no easy way to test for it. Sigh.15 -
Today is commit right to fucking master because I'm tired of how long this is taking me ...
(also nobody is actually using the service yet so no production is pretty much testing right now)5 -
Just checked the testing project that came from a group of contractors
Seeing Tests that have no details that have been there for months,
Fuckers have these in here to show test count as high!!!!!!!!!! 1
1 -
How do you think about unit testing/TDD when writing apps? (I'm working this at 3am so might be a bit messy... Just a thought I woke up to).
Whenever I write an app, I don't write unit tests but as I'm developing I may create test functions for specific parts that I run to validate a specific component is working before moving onto the next.
So first, when I get a problem, break it up into components based on the requirements. It's usually sort of input, processor, output sequence.
Where the processor is essentially the core app. And so I start coding it, referring to the input thru an interface, model objects, adding fields as I go along (assume no matter what the input, I will get these before the logic is called). I may add some more interfaces as well for other data I may need but I know won't be going in the first input.
So I write all the logic, functions needed to get a basic app to run that does what I am writing the app for.
Only then do I write a test functions passing in different parameters to make sure the logic and response is what I want and making fixes as necessary. At that point I basically have the simplest version of the app.
(I guess this is sort of like mocking?)
Then build outwards implementing and testing components as I go along and may do some simple refactoring/redesign. (I guess all these tests are functional then, have to start the whole app).
And finally when I have the basic requirements fully complete I will add the "nice to haves" on top via refactoring of specific logic in specific components. Again testing by running the app maybe with simple inputs.
I guess now I'm thinking how do you write unit tests/TDD if the app keeps changing (via adhoc refactorings) as you are creating it? -
I'm tired. I don't want to do these tests anymore. These vague test scenarios I have to decrypt on my own lest asking business shows signs of weakness. I'm slow to test and going way beyond the hours the client estimated and you folks just accepted. How can I finish this when I get pulled to meetings which I am not the decision maker but I'm supposed to be the technical one to help them decide. In between this testing I get emails to help check on issues I'm not even a part of. Production issues I can understand because those have a feel of critical and priority but if you pull me to that I lose time testing. I'm trying. But I'm truly very slow at this. I'm a slow tester for this set of test cases. I'm hating myself every minute as the hours inch to the deadline which is today. I want to sleep but I want to finish as well. Shitty days of drone work that could have been given to somebody else but I can't say no to because you guys accepted. Someone from management just see please, don't give this to me. But you can't see. You probably don't even understand. They asked, you caved because you can't see the list of tasks and level of detail that comes with each thing they ask. This testing is a ridiculous use of my time but I can't say that to the client. You could have. I want to. I truly want to say "Fuck these tests". I tried to push back. But the client of course reasoned back and it was understandable to ask. To do what's good and what's best. How can I say no to that?! I'm almost depleted. I'll just finish this somehow.
-
The job description of my internship:
You must be able to understand the complexities of receiving a unit test that you are told needs only mock data in the test database, but has never worked since it was written by a contractor a year ago. No one knows how the unit test works and requires testing a complex algorithm involving graph theory that you have not learned about yet. The task starts at 1 complexity and turns into a 13. -
We need to test the last step in our proof-of-concept chain before putting our project proposal... but just before testing what we believe will be (finally) a functioning scenario, the key service we need and have no influence over stopped working. I am pretty sure, it will start working like 5 minutes before I usually leave.. one has to love this waitNRush development.
-
This is really a rant:
The company i work for uses the wso2 enterprise integrator for message transformation and so on.
I am in charge to get this thing to work.
And i am so annyoid about this fuc**** crap software, there price it as lightweight, fast and easy to use?
EASY TO USE?????
Who the fuck there had the IDEA to use XML as configuration files.
They have kinda no documentation, even searching the web makes no sense because you only can find there crap documentation, once i searched after another problem and found my own Stackowerflow question, which had a totally different term!!
And i guess they are making no testing, i mean if i want to edit a api and i set one bracket false or so, than if i click on save, i am doomed, BECAUSE IT DELETES THE CHANGES WITHOUT WARNING ME, i mean srsly are you kidding me wso2???1 -
Just spent 3 hours on a bs problem
I just start acceptance testing a node.js api.
I'm using frisby
I have logged the export method return data and it is correct
I am loading it into the set header function as the accept-type
On frisby side I run the test and it spits out that there is no accept-type
I really don't get why anymore. Came so close to a blind fury. -
I've joined a team recently. its been about 4 months now. the damn testing framework changed more than 4 times now. and the environments to test, the necessary config changed a lot of number of times that is so fucking hard to keep up. If I ask a question, manager keeps saying that I should be knowing things by now (which I've never worked on). god damn, then atleast keep somethings fixed, or atleast write it up what got changed, and why it got changed. no one discusses shit, and assumes everyone should be knowing stuff without any communication.1
-
I really hate how steep the learning curve is for testing. I've been writing the same test for a week for a 150 line directive, and it's driving me fucking nuts. Nothing makes sense. No one in the office to help me. Only 10% of engineers here write any tests. I don't know what to do. Overnight they made it a rule that if you want to move up to the next level for software engineers, 80% of your code needs to have unit test coverage. It's just bullshit.3
-
Struggling to write my Engineering Thesis code. Not because I'm afraid of tech, but because I have no idea what it should do.
I'm testing mobile apps performance, but getting the right idea is pain in the ass. :(
Never been too creative, but always have been over ambitious and lazy.
So the deadline is coming slowly, I have specified my 'tests' (authorization, API connection, heavy calculations, graphics, database handling) and still don't know what my app should do.
And ideas or suggestions what else is to test? -
I am starting a testing project at work and we have nothing in place.
Should I use a tool like browserstack and try to hold my selenium tests there or bite the bullet and use something like spec flow to write the selenium tests by hand? The advantage being full control, easy way to integrate with CI and easier to integrate to existing workflows (no need for visual studio and a browser open to work on in parallel).
If I do that I will also need some way to do cross browser testing which I guess will require me to export the tests somehow to a cross browser treating service like browserstack. -
1. Music, something fast paced with minimal to zero lyrics (usually a GOA radio station in my case)
2. No distractions around (use a "do-not-disturb" flag or something to hang on your monitor or show on your desk)
3. No chats or other communication/social media visible, best case those apps / tabs are completely closed or muted
4. Having a clear goal to achieve, might even be only a sub-goal for the current coding session.
5. Structure your code before your actually write it, I usually create step-by-step comments in each file, documenting my thought process and what steps the current file/class/whatever should do.
6. Try to code your stuff in the same order as the aforementioned comment step-by-step list dictates (unless there is a reason to change the coding order)
7. Only windows open: IDE/Editor, Browser
8. Also keep only the browser tabs needed for your work open (testing clients, documentation, music if using a browser client, etc.)
At least that's what works for me2 -
Those who know x86 assembly and real mode, what'd I do wrong here?
mov cx,0000
.loop
mov ax,e823
mov bx,1
add cx,1
int 15 ; supposed to be undocumented CMOS raw write on my mobo if bx!=0,ax=e823
test cx,00ff
jne .loop
ret
The JNE doesn't ever trigger, so I end up always returning no matter what cx is. I'm testing if the undocumented writes actually work, and cl is supposed to be 00-FF as it's the address to write bx to in CMOS. I'm running in real mode, if it matters.8 -
semiRant
The debugging options in VSCodium for when working with golang have certain limitations on them that have made me start writing more tests inside of my codebase (s).
I find this both beautiful and frustrating at the same time since for 1 it has made me(no, forced me) to learn testing on the language as a primary thing rather than an afterthought (judge me all you want) and if this was added by design to force people into properly writing tests then BRAVO.
Well played Mr. Pike and Mr. Thompson, well fucking played you outstanding beautiful bastards. -
I once wrote a whole lot of classes with lots of functions and pushed them to the live server without testing... There were no errors 😎1
-
I start my new internship in a week. Its Java (springboot), angular, and the most popular testing tech for each. I know some of each, and no testing. PLS HALP. Want to impress.11
-
Scenario: Enabling yet another python test suite on vscode. No big deal.
I start the test init and discovery. Says it cant find the test files. Okay; usually the issue is there's no __init__.py in the test directory. It's okay we can fix that.
Oh wait it's still not working. Okay well this isnt good... After about an hour of searching, i finally find out that the file that vscode is discovering tests with doesnt exist... In fact the whole testing directory doesnt exist!
Okay so now what do i do... Reinstall? Doesnt work. Reinstall and delete the extension directory? Yes! Victory!
Dont know how i got a half-baked extension download but hey... Could've beem worse. -
New Project
M: Hey, check these two processes. Both took different paths for the same input. Here are the logs. Both are the same though.
Me: Ok... do we have a debugger?
M: No this product doesn't have a debugger
Me: Any unit tests i should know of?
M: We don't do unit testing. Everything is done in Integration Testing.
Me: Ok. So how can i check the db for this?
M: You can't, the access is restricted. You'll have to raise a ticket to other team with the sql output you need.
Me: Ok. So I hope you have the schema at least.
M: Yes we have the schema. But there was some issue last week so the values might not be there in the correct column. They may or may not be present where they are supposed to be.
Wtf am i supposed to do... fucking play football on ticketing system with the other team 😐 -
What is software development like where you live? Would you say it's good/modern or bad/outdated?
For example, in Peru (this has a degree of truth of up to 95%):
- React isn't even a thing (nevermind RN)
- Everything uses Angular
- No Django, no Rails, no Express. Everything Laravel, CodeIgniter and .NET
- No NoSQL
- Objective-C >> Swift
- AWS? cPanel!
- No testing
Of course I focused on the "bad" part, but maybe this is what rants are for :) And I haven't said anything about salaries 😪
What about you? And please don't forget to mention your country.2 -
I was having a weird time playing manager because we had none. And the new one kind of sucks and it is too junior for the role. Acting as TL too and had almost no time to code or do PRs. And. Gee. Yesterday I went back to coding after a few months. And I found out that We have a team member that just shits all over the code. Tests that are invalid, basically testing nothing. Methods done apparently for no reason. It took me a good deal of time to sort things thru. And now I'm at a point where I can finally do some reviews. Long day today.1
-
Why... why they have to be like that?
https://github.com/micro/micro/... was reported 11 days ago, I have this issue with the dashboard inside docker than registers no services nor clients, a shame because this enables testing and that comes handy specially if you have never ever done micro-services.
Despite linking to a minimal example that reproduces the issue I have in my project I'm not getting any support from the developers of Go Micro other than "use the latest Docker image, it shouldn't panic", sadly others give it a try too but their directions won't fix the problem.
So this makes me wonder, after 11 days and a minimal reproducible example provided from day one, why no developer have offered any hint of what I'm doing wrong? they know their software, it should be easier for them to spot why the bloody dashboard is not working as it should.7 -
Thought I would be clever to batch insert a bunch of data into the db with sql, with the catch that the data of a specific column should have a zero-padded number as prefix, counting up from 0. Ask AI for suggestion. Generates some SQL beyond my basic understanding. No way I'm gonna run that! Can't be bothered for an explanation, don't have the time. I realize my assumption to SQL my way through failed right from the start. Instead I let AI generate a python script to create a CSV with the desired data. A few iterations of testing, I take the result file and import it into the db. Done.3
-
F***ing GitHub Actions.
I just wanted to make Snapcraft builds of my game with CI and instead I'm fiddling around with YAML syntax because for some reason everything got formatted incorrectly.
Also I have no way of testing the workflow locally to save me commits. So I have to wait five minutes each time to find out that I yet again somehow mucked up the script and it couldn't snap the executable.7 -
Power BI: wonderful tool, pretty graphics, and can do a lot of powerful stuff.
But it’s also quite frustrating when you want to do advanced things, as it’s such a closed platform.
* No way to run powerquery scripts in a command line
* Unit testing is a major pain, and doesn’t really test all the data munging capabilities
* The various layers (offline/online, visualisation, DAX, Powerquery, Dataset, Dataflow) are a bit too seamless: locating where an issue is happening when debugging can be pain, especially as filtering works differently in Query Editing mode than Query Visualisation mode.
And my number 1 pet peeve:
* No version control
It’s seriously disconcerting to go back to a no version control system, especially as you need to modify “live code” sometimes in order to debug a visual.
At best, I’ve been looking into extracting the code from the file, and then checking that into git, but it’s still a one-way street that means a lot of copying and pasting back into the program in order to roll back, and makes forking quite difficult.
It’s rewarding to work with the system, but these frustrations can really get to me sometimes2 -
To those who have worked in mad RAD solo environments, with next to no testing...
...and those who have worked full Agile, with high code coverage, code review amongst hoards of T-shaped developers...
...how much difference does it make to wellbeing and upskilling in the two?
Bonus points if you have done both and can compare in an n=1 way.2 -
Today I've been summoned to work for the first time in weeks to help with the startup of a machine, and testing the HMI software that goes with it.
Me and a junior colleague go to the machine. We try to get everything ready for testing. Machine was left stuck in some intermediate state by someone else. I have no idea on how to control the machine's individual components. My colleague received a crash course a while ago, but was unable to reinitialize the damn thing, and the senior machine builder was too busy on another project.
In other words, me coming over had no purpose at all, and we accomplished nothing.
I really don't understand companies. On one end there's an endless bitching about how everything is too expensive, and on the flip-side you see 'em toss buckets of money through the window.
Oh well, as long as it goes from the window to my bank account, there's no problem for me I guess.2 -
For a little background on the sort of stuff I'm dealing with, check out my last rant.
Anyways, I'm testing this pipeline at work and was just reminded of the fucktarded way a "software engineer", who had a bachelor's biology degree, decided to handle a json file.
The script is question is loading a json file containing an array of objects. The script is written in perl. There's a JSON module. Use that? Fuck no! Let's rather perform an in-place sed command on the file substituting the commas separating objects in the array with newlines, then proceed to read the file line-by-line and parse out the tokens manually. Mind you, in the process of adding the newlines he didn't keep the commas, so now all of these json files his bullshit handled are invalid json that cannot be parsed.
The dumb ass was lucky the data in the file is always output upstream as a single line and the tokens for each object are always in the same order, so that never led to problems. But now, months later after I fixed his stupidity I am being reminded of it again as I'm testing and debugging some old projects as part of regression testing new changes I'm making.
TL;DR Fuck dumbwit motherfuckers who can't even google search "parsing a json file" and doing literally anything that is less fucktarded than manually parsing a json file2 -
well... I really dont know how to explain this error
in the directory where I have my testing.cpp file, I type "clang testing.cpp -o testing"
my result is just supposed to be hello world and I am getting this.
note: clang is my c++ compiler since for some divine reason I can't install GCC on termux.
I checked the github and no one gives this complaint. I honestly can't read that error code, I just want it to go away
I hate coding on android, it's always a sorry case
I could have been a farmer or a teacher or a bus driver or an alien but I chose coding. I am really tired
I took a very long screenshot 6
6 -
Why is it acceptable for dev think it's ok to skip testing? WHY?
Today i was told that a co-worker had good enough judgment when it comes to CSS if it will break in other browsers other than chrome. I'd accept that if they knew the browsers inside out and read all the release docs but no, not them. Even more so when it's not their field of expertise.
After working for 2+ years at the some company, with a QA team, it's become evident no one does any proper testing, even the friking QA team!
I'm close to define the supported browsers as "What ever the developer used at the time of build".
Am I really the only Dev to test in at least 2 other browsers? -
Okay..
So, what do I have here?
A cross platform mobile app with NO unit tests.
😕
I have to write a big new feature from scratch. (Things can't go wrong, right?)
Started working on it, pointed out problems with the UI/UX designs. The design changed multiple times, still I thought I could finish it by the expected date. And, so I did.
The feature went through testing, and they found bugs. (Surprise...?)
It's already kinda scary to touch someone's code that has no unit tests and no comments. And I think, it's all the more difficult to not introduce bugs.
Also, had to work on the weekend to fix the bugs.
I had some good learnings here, but I'm not sure how I can prevent bugs without unit tests and proper feedback cycle. :/4 -
I've been working on an issue on and off for the past few weeks. The QA tests failed, so the ball is back in my court again. The data our analysts are testing from comes from a mysterious spreadsheet that no one knows where it came from, while my data is coming from some obscure database table. After asking around it turns out that the table hasn't been maintained for who knows how long, and nobody really knows what the data is used for... I feel like a freaking archaeologist.2
-
Working on a security testing tool that's purpose and use has been overstated by the staff engineer and product owner but no team wants to use it and everyone else in security second guesses if it should exist. Oh, also no documentation on how to use it, and you have to figure out how to use it. The tool has been developed and passed down from multiple people who each developed it differently and have all left the company now. No code reviews exactly exist so every functionality has been assumed to work my PO, SM and Staff Engineer, thus questioned when you bring up something that you're not sure works. Constantly redeploying to production at a timezone that's too early for your country but done to proviide minimal damage to the application for customers in case something goes wrong.
Upside is, you're leaving the team in a week and feel sorry for whoever is going to handle this next. -
What should I do, I have a central function that is not documentated and no test-cases are written for it. I have no clue what the method should really do, I know that it works in 99.9% of all cases otherwise we had much more bugs. Now there is one Unit-Test that reports an issue. I tracked it down to this method, no one touched the method nor the unit-test.
My logical thinking says that there is one statement missing, but it could also fuck up another part of the code... (This project has a bad testing coverage :'( )
What would you do?
- copy paste the method for this special case (I would hate me so much for breaking DRY)
- inheritance?! (Would make it more complex and then it would be still untested / undocumented)
- YOLO changing oO?! (hope for luck, just joking)
P.s it's an edge case unit test, the client / customer probably wouldn't realised it if it happens -
What's the worst part about testing React components? Using the equivalent of fucking stone tools to do your component integration tests! We got errors with no context and errors with no stack trace, just spewing out bullshit! A sample:
The classic "Can't access .root on unmounted test renderer"
The unforgettable and ALWAYS visible "Warning: An update to YourShittyComponent inside a test was not wrapped in act(...)."
We do love it! -
What is the best way to install iOS app for employees in a company?
Disclaimer, I'm no iOS developer.
In 2019 my boss asked if I could make a small iOS app. 3 forms which will have CRUD operations. I did it because I wanted to learn iOS development. The company got an Apple Developer Account and it finished the project within the week. The app can be used only from work's wifi, so if you try to use it outside that network will not work.
The issue is license. When I install the app from my XCode to one of the employees' iPhone, the app will work for 1 year (if I have paid for Developer Account). Also every time I make an update, the employee have to come to me with the iPhone and I have to install it directly.
Yesterday I submitted the app for Testing using TestFlight. The app updates automatically, but today I got notification that the "Submission for testing is rejected", because the tester could not connect with the server.
My question is, How do you install iOS apps for your work employees? I do not want to get Enterprise account because that will cost.5 -
Okay devs, this one caught me off guard.
I was testing out Google's NotebookLM, expecting it to be another AI summarizer. Cool, but whatever.
Instead, I found this "Studio panel" with something called Video Overview — and in less than 3 minutes, it literally turned a block of copied text and a YouTube transcript into a fully narrated explainer video with slide transitions, quotes, and everything.
No Adobe Premiere. No voiceover. Not even a script.
Check out the full video on my Youtube Channel
How it works:
You can paste copied text, link a YouTube video, or add docs
Then you hit “Generate Video Overview”
It gives you a narrated breakdown of the content
Bonus: you can customize tone, style, and export it right away
I tested it with AI tools and quantum networking stuff, and the result was clean enough to use in an actual client pitch or course video.
Maybe not perfect yet, but honestly? As someone who’s spent hours editing screencasts — I’m not complaining.
Anyone else tried this? 59
59 -
Thanks sefuckalize-mock for not letting me insert 2 row,
Now Im replicating the whole sequelize module itself to stub shit for no reason idk fuck this why am I doing this for stupid unit testing -
Just built out my first app using Cloudflare Workers, Typescript, and DurableObjects. Holy shit, this is nice stuff.
It's taken little to no time to build out:
* JSON API written in Typescript
* JWT verification against my OAuth backend (SAML support too)
* CI Automated Deployments including unit tests
* DurableObject support
* 3rd party HTTP calls + caching (built in to the framework!) to reduce network latency and hiccups.
* Cron-like tasks on each stored object so they can awaken the app on a schedule and update themselves as necessary
* Rapid deployment to new environments
The local testing with coordinated "miniflare" is dreamy too. -
Has anyone noticed that lately Safari renders websites faster?
I have been testing the cache on one of our sites. Been testing with Safari, Chrome, Firefox(Clean no addons) and FirefoxDeveloperEdition. The response time from the server is pretty much identical on all the browsers. But Safari is definitely quicker at rendering it out.
Anyone got a clue why? The only thing i suspect is that safari doesnt have dev tools enabled, so that might be the culprit? -
Arrgh...
I need to do a lot of refactoring and testing (%80 percent of which is integration) and ITS SO TEDIOUS!!!
Now, for anyone who says "oh, you write spaghetti code, your code shouldn't be so tedious to refactor". No. It's only tedious because it's a few thousand lines that I've been too lazy to refactor till now, and I need to go through it all.
Anybody have any advice for refactoring or testing in Go?17






































































































































































































































Top Tags
Weekly Rant
View