
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Long rant ahead, but it's worth it.
I used to work with a professor (let's call him Dr. X) and developed a backend + acted as sysadmin for our team's research project. Two semesters ago, they wanted to revamp the front end + do some data visualization, so a girl (let's call her W) joined the team and did all that. We wanted to merge the two sites and host on azure, but due to issues and impeding conferences that require our data to be online, we kept postponing. I graduate this semester and haven't worked with the team for a while, so they have a new guy in charge of the azure server (let's call him H), and yesterday my professor sends me (let's call me M), H and W an email telling us to coordinate to have the merge up on azure in 2-3 days, max. The following convo was what I had with H:
M: Hi, if you just give me access to azure I'll be able to set everything up myself, also I'll need a db set up, and just send me the connection string.
H: Hi, we won't have dbs because that is extra costs involved since we don't have dynamic content. Also I can't give you access, instead push everything on git and set up the site on a test azure server and I will take it from there.
M: There is proprietary data on the site...
H: Oh really? I don't know what's on it.
<and yet he knows we have no dynamic data>
M: Fine, I'll load the data some other way, but I have access to all the data anyway, just talk to Dr. X and you'll see you can give me access. Delete my access after if you want.
H: No, just do what I said: git then upload to test azure account.
Fine, he's a complete tool, but I like Dr. X, so I message W and tell her we have to merge, she tells me that it's not that easy to set it up on github as she's using wordpress. She sends me instructions on what to do, and, lo and behold, there's a db in her solution. Ok, I go back to talking to H:
M: W is using a db. Talk to her so we can figure out whether we need a database or not.
H: We can't use a database because we want to decrease costs.
M: Yes I know that, so talk to her because that probably means she has to re-do some stuff, which might take some time. Also there might be dynamic content in what she's doing.
H: This is your project, you talk to her.
<I'm starting to get mad right now>
M: I don't know what they had her do apart from how it interfaces with what I've done.
H: We still can't have databases.
M: Listen, I don't do wordpress, and I'm not gonna mess with it, you talk to her
H: I won't do any development
<So you won't do any dev, but you won't give me access to do it either?>
M: Man, the bottleneck isn't the merging right now, it's the fact that W needs a db
H: I know, so talk to her
M: THE RESTRICTION TO NOT HAVE DATABASES IS NOT MINE, IT'S YOURS, YOU TALK TO HER. I can't evaluate whether it's a reasonable enough reason or not since I don't know the requirements or what they're willing to spend.
H: It's your project.
M: Then give me fucking access to azure and I'll handle it, you know you'll have to set up wordpress again regardless whether we set it up the first time.
H: Man just do your job.
At this point I lost it. WHAT A FUCKING TOOL. He doesn't wanna do dev work, wants me to go through the trouble of setting up on a test subscription first, and doesn't want to give me access to azure. What's more, he did shit all and doesn't want to anything else. Well fuck you. I googled him, to see if he's anyone important, if he's done anything notable which is why he's being so God damn condescending. MY INTERNSHIP ALONE ECLIPSES HIS ENTIRE CV. Then what the fuck?
There's also this that happened sometime during our talk:
M: You'll have to take to Dr. Y so he'll change the DNS to point to the azure subscription instead of my server.
H: Yea don't worry, too early for that.
M: DNS propagation takes 24 hours...
H: Yea don't worry.
DNS propagation allows the entire web to know that your website is hosted on a different server so it can change where it's pointing to. We have to do this in 2-3 days. Why do work in parallel? Nah let's wait.
I went over his head and talked to the professor directly, and despite wanting to tell him that he was both drunk and high the day he hired that guy, I kept it professional. He hasn't replied yet, but this fucker's pompous attitude is just too much for me alone, so I had to share.
PS: I named his contact as Annoying Prick 4 minutes into our chat. Gonna rename him cz that seems tooooooo soft a name right now.46 -
Four months ago changed a laptop failing hdd and give it back to customer. Today I got a 30 minutes call because the computer "is not like before the repair, it doesn't work well".
*Thinks* Well, s#*@, before the repair the hdd had more than 2000 damaged clusters, which prevented even the os to start
*Says* "Could you describe me the issue?"
....
...
[ basically he was saying that since he started using IE as a browser, he didn't have Google.com set as the first page and that he had to bing it]
...
"When did the 'issue' start, If I may ask?"
>"Two weeks ago. "
Two weeks ago.
Two f*""#ng weeks ago.
Set aside for the nature of the issue, you blame my four months ago repair for a two weeks ago issue?
"The computer was better before"?
THAT F###ING MACHINE WAS LIKE A BURNING HOUSE - I RESCUED DATA FOR 2 DAYS JUST BEFORE THE HDD STARTED TO CRANK AT EVERY SPIN - I REBUILT IT TO GIVE IT YOU BACK FULLY WORKING AFTER YOU USED AS A FOOTBALL, AND NOW YOU BLAME ME BECAUSE THE
BROWSER ISN'T SETTED AS YOU LIKE
No,seriously, is like I rebuilt a burned house from scrap and now the owner blames me because in the kitchen sink the hot water tap is on the right side instead of the left side.
Seriusly, wtf.6 -
I think I've shown in my past rants and comments that I'm pretty experienced. Looking back though, I was really fucking stupid. Since I haven't posted a rant yet on the weekly topics, I figure I would share this humbling little gem.
Way back in the ancient era known as 2009, I was working my first desk job as a "web designer". Apparently the owner of this company didn't know the difference between "designer", which I'm not, and "developer", which I am, nor the responsibilities of each role.
It was a shitty job paying $12/hour. It was such a nightmare to work at. I guess the silver lining is that this company now no longer exists as it was because of my mistake, but it was definitely a learning experience I hold in high regard even today. Okay, enough filler...
I was told to wipe the Dev server in order to start fresh and set up an entirely new distro of Linux. I was to swap out the drives with whatever was available from the non-production machines, set up the RAID 5 array and route it through the router and firewall, as we needed to bring this Dev server online to allow clients to monitor the work. I had no idea what any of this meant, but I was expected to learn it that day because the next day I would be commencing with the task.
Astonishingly, I managed to set up the server and everything worked great! I got a pat on the back and the boss offered me a 4 day weekend with pay to get some R&R. I decided to take the time to go camping. I let him know I would be out of town and possibly unreachable because of cell service, to which he said no problem.
Tuesday afternoon I walked into work and noticed two of the field techs messing with the Dev server I built. One was holding a drive while the other was holding a clipboard. I was immediately called into the boss's office.
He told me the drives on the production server failed during the weekend, resulting in the loss of the data. He then asked me where I got the drives from for the Dev server upgrade. I told him that they came from one of the inactive systems on the shelf. What he told me next through the deafening screams rendered me speechless.
I had gutted the drives from our backup server that was just set up the week prior. Every Friday at midnight, it would turn on through a remote power switch on a schedule, then the system would boot and proceed to copy over the production server's files into an archive for that night and shutdown when it completed. Well, that last Friday night/Saturday morning, the machine kicked on, but guess what didn't happen? The files weren't copied. Not only were they not copied, but the existing files that got backed up previously we're gone. Why? Because I wiped those drives when I put them into the Dev server.
I would up quitting because the conversation was very hostile and I couldn't deal with it. The next week, I was served with a suit for damages to this company. Long story short, the employer was found in the wrong from emails I saved of him giving me the task and not once stating that machine was excluded in the inactive machines I could salvage drives from. The company sued me because they were being sued by a client, whose entire company presence was hosted by us and we lost the data. In total just shy of 1TB of data was lost, all because of my mistake. The company filed for bankruptcy as a result of the lawsuit against them and someone bought the company name and location, putting my boss and its employees out of a job.
If there's one lesson I have learned that I take with the utmost respect to even this day, it's this: Know your infrastructure front to back before you change it, especially when it comes to data.8 -
In a user-interface design meeting over a regulatory compliance implementation:
User: “We’ll need to input a city.”
Dev: “Should we validate that city against the state, zip code, and country?”
User: “You are going to make me enter all that data? Ugh…then make it a drop-down. I select the city and the state, zip code auto-fill. I don’t want to make a mistake typing any of that data in.”
Me: “I don’t think a drop-down of every city in the US is feasible.”
Manage: “Why? There cannot be that many. Drop-down is fine. What about the button? We have a few icons to choose from…”
Me: “Uh..yea…there are thousands of cities in the US. Way too much data to for anyone to realistically scroll through”
Dev: “They won’t have to scroll, I’ll filter the list when they start typing.”
Me: “That’s not really the issue and if they are typing the city anyway, just let them type it in.”
User: “What if I mistype Ch1cago? We could inadvertently be out of compliance. The system should never open the company up for federal lawsuits”
Me: “If we’re hiring individuals responsible for legal compliance who can’t spell Chicago, we should be sued by the federal government. We should validate the data the best we can, but it is ultimately your department’s responsibility for data accuracy.”
Manager: “Now now…it’s all our responsibility. What is wrong with a few thousand item drop-down?”
Me: “Um, memory, network bandwidth, database storage, who maintains this list of cities? A lot of time and resources could be saved by simply paying attention.”
Manager: “Memory? Well, memory is cheap. If the workstation needs more memory, we’ll add more”
Dev: “Creating a drop-down is easy and selecting thousands of rows from the database should be fast enough. If the selection is slow, I’ll put it in a thread.”
DBA: “Table won’t be that big and won’t take up much disk space. We’ll need to setup stored procedures, and data import jobs from somewhere to maintain the data. New cities, name changes, ect. ”
Manager: “And if the network starts becoming too slow, we’ll have the Networking dept. open up the valves.”
Me: “Am I the only one seeing all the moving parts we’re introducing just to keep someone from misspelling ‘Chicago’? I’ll admit I’m wrong or maybe I’m not looking at the problem correctly. The point of redesigning the compliance system is to make it simpler, not more complex.”
Manager: “I’m missing the point to why we’re still talking about this. Decision has been made. Drop-down of all cities in the US. Moving on to the button’s icon ..”
Me: “Where is the list of cities going to come from?”
<few seconds of silence>
Dev: “Post office I guess.”
Me: “You guess?…OK…Who is going to manage this list of cities? The manager responsible for regulations?”
User: “Thousands of cities? Oh no …no one is our area has time for that. The system should do it”
Me: “OK, the system. That falls on the DBA. Are you going to be responsible for keeping the data accurate? What is going to audit the cities to make sure the names are properly named and associated with the correct state?”
DBA: “Uh..I don’t know…um…I can set up a job to run every night”
Me: “A job to do what? Validate the data against what?”
Manager: “Do you have a point? No one said it would be easy and all of those details can be answered later.”
Me: “Almost done, and this should be easy. How many cities do we currently have to maintain compliance?”
User: “Maybe 4 or 5. Not many. Regulations are mostly on a state level.”
Me: “When was the last time we created a new city compliance?”
User: “Maybe, 8 years ago. It was before I started.”
Me: “So we’re creating all this complexity for data that, realistically, probably won’t ever change?”
User: “Oh crap, you’re right. What the hell was I thinking…Scratch the drop-down idea. I doubt we’re have a new city regulation anytime soon and how hard is it to type in a city?”
Manager: “OK, are we done wasting everyone’s time on this? No drop-down of cities...next …Let’s get back to the button’s icon …”
Simplicity 1, complexity 0.16 -
At my previous job we had the rule to lock your PC when you leave. Makes sense of course.
We were not programmers but application engineers, still, we worked with sensitive data.
One colleague always claimed to be the most intelligent and always demanded the "senior" - title. Which he obviously did not deserve.
multiple times a day forgot to lock his workstation and we had to do it for him.
My last week working there, I've had it. He forgot it again... So I made a screenshot of his current environment. Closed everything. Set his new background with the screen shot and killed explorer (windows). Then finally I locked his PC.
When he came back he panicked that his PC froze. He couldn't do shit anymore. Not knowing what to do... 😂
Which makes him a senior of course.
But seriously, first thing I would do is open the task manager and notice that explorer wasn't running... Thus my background with the taskbar isn't real.... My colleagues must be pranking me!
Nope... The "senior" knew little10 -
Biggest scaling challenge?
The imaginary scaling issues from clients.
Client : How do you cope with data that's a billion times bigger than our current data set? Can you handle that? How much longer will it take to access some data then?
I could then give a speech about optimizing internal data structures and access algorithms that work with O(log n) complexity, but that wouldn't help, non-tech people will not understand that.
And telling someone, the system will be outdated and hopefully been replaced when that amount of data is reached, would be misinterpreted as "Our system can not handle it".
So the usual answer is: "No problem, our algorithms are optimized so they can handle any amount of data"6 -
I’ve been thinking lately, what is it that devRant devs do?
So after a couple of days of pulling data from devRants API's, filtering through the inconsistent skill set data of about 500 users (seriously guys, the comma is your friend) i’ve found an interesting set of languages being used by everyone.
I've limited this to just languages, as dwelling into frameworks, libraries and everything else just grows exponentially, also ive only included languages with at least 5 users out of the pool.
sorry you brainfuck guys. 28
28 -
--- GitHub 24-hour outage post mortem ---
As many of you will remember; Github fell over earlier this month and cracked its head on the counter top on the way down. For more or less a full 24 hours the repo-wrangling behemoth had inconsistent data being presented to users, slow response times and failing requests during common user actions such as reporting issues and questioning your career choice in code reviews.
It's been revealed in a post-mortem of the incident (link at the end of the article) that DB replication was the root cause of the chaos after a failing 100G network link was being replaced during routine maintenance. I don't pretend to be a rockstar-ninja-wizard DBA but after speaking with colleagues who went a shade whiter when the term "replication" was used - It's hard to predict where a design decision will bite back and leave you untanging the web of lies and misinformation reported by the databases for weeks if not months after everything's gone a tad sideways.
When the link was yanked out of the east coast DC undergoing maintenance - Github's "Orchestrator" software did exactly what it was meant to do; It hit the "ohshi" button and failed over to another DC that wasn't reporting any issues. The hitch in the master plan was that when connectivity came back up at the east coast DC, Orchestrator was unable to (un)fail-over back to the east coast DC due to each cluster containing data the other didn't have.
At this point it's reasonable to assume that pants were turning funny colours - Monitoring systems across the board started squealing, firing off messages to engineers demanding they rouse from the land of nod and snap back to reality, that was a bit more "on-fire" than usual. A quick call to Orchestrator's API returned a result set that only contained database servers from the west coast - none of the east coast servers had responded.
Come 11pm UTC (about 10 minutes after the initial pant re-colouring) engineers realised they were well and truly backed into a corner, the site was flipped into "Yellow" status and internal mechanisms for deployments were locked out. 5 minutes later an Incident Co-ordinator was dragged from their lair by the status change and almost immediately flipped the site into "Red" status, a move i can only hope was accompanied by all the lights going red and klaxons sounding.
Even more engineers were roused from their slumber to help with the recovery effort, By this point hair was turning grey in real time - The fail-over DB cluster had been processing user data for nearly 40 minutes, every second that passed made the inevitable untangling process exponentially more difficult. Not long after this Github made the call to pause webhooks and Github Pages builds in an attempt to prevent further data loss, causing disruption to those of us using Github as a way of kicking off our deployment processes (myself included, I had to SSH in and run a git pull myself like some kind of savage).
Glossing over several more "And then things were still broken" sections of the post mortem; Clever engineers with their heads screwed on the right way successfully executed what i can only imagine was a large, complex and risky plan to untangle the mess and restore functionality. Github was picked up off the kitchen floor and promptly placed in a comfy chair with a sweet tea to recover. The enormous backlog of webhooks and Pages builds was caught up with and everything was more or less back to normal.
It goes to show that even the best laid plan rarely survives first contact with the enemy, In this case a failing 100G network link somewhere inside an east coast data center.
Link to the post mortem: https://blog.github.com/2018-10-30-...6 -
Devs: We need access to PROD DB in order to provide support you're asking us for.
Mgmt: No, we cannot trust you with PROD DB accesses. That DB contains live data and is too sensitive for you to fuck things up
Mgmt: We'll only grant PROD DB access to DBAs and app support guys
Mgmt: <hire newbies to app support>
App_supp: `update USER set invoice_directory = 54376; commit;`
----------------
I have nothing left to say....7 -
A few years ago:
In the process of transferring MySQL data to a new disk, I accidentally rm'ed the actual MySQL directory, instead of the symlink that I had previously set up for it.
My guts felt like dropping through to the floor.
In a panic, I asked my colleague: "What did those databases contain?"
C: "Raw data of load tests that were made last week."
Me: "Oh.. does that mean that they aren't needed anymore?"
C: "They already got the results, but might need to refer to the raw data later... why?"
Me: "Uh, I accidentally deleted all the MySQL files... I'm in Big Trouble, aren't I?"
C: "Hmm... with any luck, they might forget that the data even exists. I got your back on this one, just in case."
Luck was indeed on my side, as nobody ever asked about the data again.5 -
You know side projects? Well I took on one. An old customer asked to come and take over his latest startups companys tech. Why not, I tought. Idea is sound. Customer base is ripe and ready to pay.
I start digging and the Hardware part is awesome. The guys doing the soldering and imbedded are geniuses. I was impressed AF.
I commit and meet up with CEO. A guy with a vision and sales orientation/contacts. Nice! This shit is gonna sell. Production lines are also set.
Website? WTF is this shit. Owner made it. Gotta give him the credit. Dude doesn't do computers and still managed to online something. He is still better at sales so we agree that he's gonna stick with those and I'll handle the tech.
I bootstrap a new one in my own simplistic style and online it. I like it. The owner likes it. He made me to stick to a tacky logo. I love CSS and bootstrap. You can make shit look good quick.
But I still don't have access to the soul of the product. DBs millions rows of data and source for the app I still behind the guy that has been doing this for over a year.
He has been working on a new version for quite some time. He granted access to the new versions source, but back end and DB is still out of reach. Now for over month has passed and it's still no new version or access to data.
Source has no documentation and made in a flavor of JS frame I'm not familiar with. Weekend later of crazy cramming I get up to speed and it's clear I can't get further without the friggin data.
The V2 is a scramble of bleeding edge of Alpha tech that isn't ready for production and is clearly just a paid training period for the dev. And clearly it isn't going so well because release is a month late. I try to contact, but no reaction. The owner is clueless.
Disheartening. A good idea is going to waste because of some "dev" dropping a ball and stonewalling the backup.
I fucking give him till the end of the next week until I make the hardware team a new api to push the data and refactor the whole thing in proper technologies and cut him off.
Please. If you are a dev and don't have the time to concentrate on the solution don't take it on and kill off the idea. You guys are the key to making things happening and working. Demand your cut but also deserve it by delivering or at least have the balls to tell you are not up for it. -
I'm convinced code addiction is a real problem and can lead to mental illness.
Dev: "Thanks for helping me with the splunk API. Already spent two weeks and was spinning my wheels."
Me: "I sent you the example over a month ago, I guess you could have used it to save time."
Dev: "I didn't understand it. I tried getting help from NetworkAdmin-Dan, SystemAdmin-Jake, they didn't understand what you sent me either."
Me: "I thought it was pretty simple. Pass it a query, get results back. That's it"
Dev: "The results were not in a standard JSON format. I was so confused."
Me: "Yea, it's sort-of JSON. Splunk streams the result as individual JSON records. You only have to deserialize each record into your object. I sent you the code sample."
Dev: "Your code didn't work. Dan and Jake were confused too. The data I have to process uses a very different result set. I guess I could have used it if you wrote the class more generically and had unit tests."
<oh frack...he's been going behind my back and telling people smack about my code again>
Me: "My code wouldn't have worked for you, because I'm serializing the objects I need and I do have unit tests, but they are only for the internal logic."
Dev:"I don't know, it confused me. Once I figured out the JSON problem and wrote unit tests, I really started to make progress. I used a tuple for this ... functional parameters for that...added a custom event for ... Took me a few weeks, but it's all covered by unit tests."
Me: "Wow. The way you explained the project was; get data from splunk and populate data in SQLServer. With the code I sent you, sounded like a 15 minute project."
Dev: "Oooh nooo...its waaay more complicated than that. I have this very complex splunk query, which I don't understand, and then I have to perform all this parsing, update a database...which I have no idea how it works. Its really...really complicated."
Me: "The splunk query returns what..4 fields...and DBA-Joe provided the upsert stored procedure..sounds like a 15 minute project."
Dev: "Maybe for you...we're all not super geniuses that crank out code. I hope to be at your level some day."
<frack you ... condescending a-hole ...you've got the same seniority here as I do>
Me: "No seriously, the code I sent would have got you 90% done. Write your deserializer for those 4 fields, execute the stored procedure, and call it a day. I don't think the effort justifies the outcome. Isn't the data for a report they'll only run every few months?"
Dev: "Yea, but Mgr-Nick wanted unit tests and I have to follow orders. I tried to explain the situation, but you know how he is."
<fracking liar..Nick doesn't know the difference between a unit test and breathalyzer test. I know exactly what you told Nick>
Dev: "Thanks again for your help. Gotta get back to it. I put a due date of April for this project and time's running out."
APRIL?!! Good Lord he's going to drag this intern-level project for another month!
After he left, I dug around and found the splunk query, the upsert stored proc, and yep, in about 15 minutes I was done.1 -
Me: So what if this field has no info?
NonDev Manager: There should always be data in that field.
Me: *Shows the field has default set as null*
NonDev Manager: *thinks thinks thinks*, but they are always added...how...if...
Me: I'll default to X behavior.
NonDev Manager: ...Yeah...do that.
I know what should happen but it's so fun to see non-dev's scratch their heads with business logic edge cases that seem nonsensical to them. Yeah I'm a bit of a dick.3 -
After work I wanted to come home and work on a project. I have a few ideas for a few things I want to do, so I started a Trello board with the ideas to start mapping things out. But there were guys redoing the kitchen tile and it was noisy as fuck. So I packed up and headed to the library.
So I get all set up, and start plugging away. Currently working on a database design for a project that is a form for some user data collection for my dad, for an internal company thing. I am not contracted for this - I just know the details so I am using it as a learning exercise. Anyway...
I'm fucking about in a VM in MySQL and I feel someone behind me. So I turn and it's this girl looking over my shoulder. She asks what I am doing, and it turned into a 2 hour conversation. She is only a few years older than me (21) but she was brilliant. She (unintentionally) made me feel SO stupid with her scope of knowledge and giant brain. I learned quite a bit from talking to her and she offered to help me further, if I liked.
And she was really cute. We exchanged phone numbers...16 -
*creates table in database*
*writes query to retrieve data*
*gets error and Google's problem for 2 hours but no luck*
*in frustration, takes a half hour break*
*checks database for set up issues*
*realizes that the database is the wrong fucking database*
*face palm & quits fucking life*
I make dumb fucking mistakes like this way too much5 -
I’m so mad I’m fighting back anger tears. This is a long rant and I apologize but I’m so freaking mad.
So a few weeks ago I was asked by my lead staff person to do a data analysis project for the director of our dept. It was a pretty big project, spanning thousands of users. I was excited because I love this sort of thing and I really don’t have anything else to do. Well I don’t have access to the dataset, so I had to get it from my lead and he said he’d do it when he had a chance. Three days later he hadn’t given it to me yet. I approach him and he follows me to my desk, gives me his login and password to login to the secure freaking database, then has me clone it and put it on my computer.
So, I start working on it. It took me about six hours to clean the database, 2 to set up the parameters and plan of attack, and two or three to visualize the data. I realized about halfway through that my lead wasn’t sure about the parameters of the analysis, and I mentioned to him that the director had asked for more information than what he was having me do. He tells me he will speak with director.
So, our director is never there, so I give my lead about a week to speak with her, in the mean time I finish the project to the specifications that the director gave. I even included notes about information that I would need to make more accurate predictions, to draw conclusions, etc. It was really well documented.
Finally, exasperated, and with the project finished but just sitting on my computer for a week, I approached my director on a Saturday when I was working overtime. She confirmed that I needed to what she said in the project specs (duh), and also mentioned she needed a bigger data set than what I was working with if we had one. She told me to speak to my lead on Monday about this, but said that my work looked great.
Monday came and my lead wasn’t there so I spoke with my supervisor and she said that what I was using was the entire dataset, and that my work looked great and I could just send it off. So, at this point 2/3 of my bosses have seen the project, reviewed it, told me it was great, and confirmed that I was doing the right thing.
I sent it off to the director to disseminate to the appropriate people. Again, she looked at it and said it was great.
A week later (today) one of the people that the project was sent to approaches me and tells me that i did a great job and thank you so much for blah blah blah. She then asks me if the dataset I used included blahblah, and I said no, that I used what was given to me but that I’d be happy to go in and fix it if given the necessary data.
She tells me, “yeah the director was under the impression that these numbers were all about blahblah, so I think there was some kind of misunderstanding.” And then implied that I would not be the one fixing the mistake.
I’m being taken off of the project for two reasons: 1. it took to long to get the project out in the first place,
2. It didn’t even answer the questions that they needed answered.
I fucking told them in the notes and ALL THROUGH THE VISUALIZATIONS that I needed additional data to compare these things I’m so fucking mad. I’m so mad.15 -
Q: Your data migration service from old site to new site cost money.
A: Yes, I have to copy data from old database and import to the new one.
Q: Can I just provide you content separately so you don’t need to do that?
A: Yes, but I will have to charge you for copying and pasting your 100 pages of content manually.
Q: Can it come with part of the web development service and not as an additional service?
A: Yes, but the price for web development service will have to be increased to combine the two. If you don’t want to pay for it, I can just set up a few sample pages with the layout and you can handle your own content entry. Does that work for you?
Q: Well, but then I will have to spend extra time to work on it.
A: Yes you will. (At this point I think she starts to understand the concept of Time = Money...)3 -
Every step of this project has added another six hurdles. I thought it would be easy, and estimated it at two days to give myself a day off. But instead it's ridiculous. I'm also feeling burned out, depressed (work stress, etc.), and exhausted since I'm taking care of a 3 week old. It has not been fun. :<
I've been trying to get the Google Sheets API working (in Ruby). It's for a shared sales/tracking spreadsheet between two companies.
The documentation for it is almost entirely for Python and Java. The Ruby "quickstart" sample code works, but it's only for 3-legged auth (meaning user auth), but I need it for 2-legged auth (server auth with non-expiring credentials). Took awhile to figure out that variant even existed.
After a bit of digging, I discovered I needed to create a service account. This isn't the most straightforward thing, and setting it up honestly reminds me of setting up AWS, just with less risk of suddenly and surprisingly becoming a broke hobo by selecting confusing option #27 instead of #88.
I set up a new google project, tied it to my company's account (I think?), and then set up a service account for it, with probably the right permissions.
After downloading its creds, figuring out how to actually use them took another few hours. Did I mention there's no Ruby documentation for this? There's plenty of Python and Java example code, but since they use very different implementations, it's almost pointless to read them. At best they give me a vague idea of what my next step might be.
I ended up reading through the code of google's auth gem instead because I couldn't find anything useful online. Maybe it's actually there and the past several days have been one of those weeks where nothing ever works? idk :/
But anyway. I read through their code, and while it's actually not awful, it has some odd organization and a few very peculiar param names. Figuring out what data to pass, and how said data gets used requires some file-hopping. e.g. `json_data_io` wants a file handle, not the data itself. This is going to cause me headaches later since the data will be in the database, not the filesystem. I guess I can write a monkeypatch? or fork their gem? :/
But I digress. I finally manged to set everything up, fix the bugs with my code, and I'm ready to see what `service.create_spreadsheet()` returns. (now that it has positively valid and correctly-implemented authentication! Finally! Woo!)
I open the console... set up the auth... and give it a try.
... six seconds pass ...
... another two seconds pass ...
... annnd I get a lovely "unauthorized" response.
asjdlkagjdsk.
> Pic related. 19
19 -
Me:, I built you this beautiful site it's super modular, it's really straight forward
Client: urm we aren't tech people if you could..... Set up all the pages for us using the modules so we can just input the data
Me: 😡 yes I could do that or you could take 5, minutes to learn this system. It's simple 😡 see that title there "left image right title module" . I've done the sample for the templates. So if you need to you can duplicate it! There's even a duplicate button!
Client: can you do it I don't want to waste time learning it right now since we are on a tight deadline
Me in head: fuck off you supreme bitch you try to get my mates dad fired! Now I've done you this huge favour getting you out of the shit 😡 and you won't take 5 minutes to just look at the admin section your old site was wix ffs.
My next move(not yet done): here is a word document it outlines what you need to do 😐
If after this see asks again I'm asking to work with someone else or quitting the project2 -
Writing more infrastructure than product.
Look, my application requests and transforms data from a single external API endpoint, it's just one GET request...
But I made an intelligent response caching middleware to prevent downtime when the parent API goes down, I made mocks and tests for everything, the documentation is directly generated from the code and automatically hosted for every git branch using hooks, responses are translated into JSONschema notation which automatically generate integration tests on commit, and the transformations are set up as a modular collection of composable higher order lenses!
Boss: Please use less amphetamine.5 -
Dev: We need a better name than “Data” for this class. It’s used for displaying a set of tiles with certain coordinates so maybe TileMap would be a bit more declarative?
Manager: No I don’t like that. Data is perfectly fine, this class is for managing data so it’s perfectly declarative you just need to get better at reading code. If you have to change it then DataObject or DataObjectClass might be a bit more specific.
Dev: …14 -
My first real "rant", okay...
So I decided today to hop back on the horse and open Android Studio for the first time in a couple months.
I decided I was going to make a random color generator. One of my favorite projects. Very excited.
Got all the layouts set up, and got a new color every tap with RGB and hex codes, too. Took more time to open Android Studio, really.
Excited with my speedy progress, I think "This'll be done in no time!". Text a friend and tell them what I'm up to. Shes very nice, wants the app. "As soon as I'm done". I expected that to be within the hour.
I want to be able to save the colors for future reference. Got the longClickListener set up just fine. Cute little toast pops up every time. Now I just need to save the color to a file.
Easy, just a semicolon-deliminated text file in my app's cache folder.
Three hours later, and my file still won't write any data. Friend has gone to sleep. Homework has gone undone. My hatred for Android is reborn.
Stay tuned, the adventure continues tomorrow...11 -
I think I will ship a free open-source messenger with end-to-end encryption soon.
With zero maintenance cost, it’ll be awesome to watch it grow and become popular or remain unknown and become an everlasting portfolio project.
So I created Heroku account with free NodeJS dyno ($0/mo), set up UptimeRobot for it to not fall asleep ($0/mo), plugged in MongoDB (around 700mb for free) and Redis for api rate limiting (30 mb of ram for free, enough if I’m going to purge the whole database each three seconds, and there’ll be only api hit counters), set up GitHub auto deployment.
So, backend will be in nodejs, cryptico will manage private/public keys stuff, express will be responsible for api, I also decided to plug in Helmet and Sqreen, just to be sure.
Actual data will be stored in mongo, rate limit counters – in redis.
Frontend will probably be implemented in React, hosted for free at GitHub pages. I also can attach a custom domain there, let’s see if I can attach it to Freenom garbage.
So, here we go, starting up modern nosql-nodejs-react application completely for free.
If it blasts off, I’m moving to Clojure + Cassandra for backend.
And the last thing. It’ll be end-to-end encrypted. That means if it blasts off, it will probably attract evil russian government. They’ll want me to give him keys. It’ll be impossible, you know. But they doesn’t accept that answer. So if I accidentally stop posting there, please tell my girl that I love her and I’m probably dead or captured28 -
Dear Managers,
This is not efficient:
Boss: * calls *
Me: * answers *
B: there's a bug in feature ABC! The form doesn't work!
M: ABC uses a lot of forms. Is it Form A, B, or C?
B: Umm... let's just go on a Zoom call!
* 5 minutes trying to set up a Zoom call *
* 3 more minutes trying to find the form *
B: This form in here.
M: It works fine for me. What data are you inputting?
B: * takes 5 minutes trying to reproduce the bug * (in the meantime, the call is basically an awkward silence)
You spent 5 minutes wasting both of our times trying to set up a Zoom meeting, and another 8 wasting MY tine trying to find the bug.
This is efficient:
B: There is a bug in form C. If I try to upload this data, it malfunctions.
M: Thank you. I'll look into it.
You saved me 8 minutes of staring at a screen and saved us both another 5 minutes of setting up a meeting.6 -
I tried to convince my boss that using 3d rendering to display information on webpage is unnecessary luxury.
The web browser would hang if the user is using an average pc and there is too much data to render.
This product is aimed for average joe, but he argues that computers in foreign countries are high end devices ONLY.
Such a bullshit.
I asked what if someone with low spec laptop tries to view the webpage.
He said, we will set a min spec requirements for using the website.
Are you fucking kidding me?! RAM and Graphics requirements for a webpage?!
My instinct says that the thing I'm working on would probably end up as waste of time.
But I'd probably learn cool tricks of threejs.5 -
!rant
We just did a massive update to our prod db environment that would implicate damn near all system in our servers....on a friday.
Luckily for us, our DB is a badass rockstar mfking hero that was planning this shit for a little over a year with the assistance of yours truly as backup following the man's lead...and even then I didn't do SHIT
My boy did great, tested everything and the switch was effortless, fast (considering that it went on during working hours) and painless.
I salute my mfking dude, if i make my own company I am stealing this mfker. Homie speaks in SQL, homie was prolly there when SQL was invented and was already speaking in sql before shit was even set in spec, homie can take a glance at a huge db and already cast his opinion before looking at the design and architecture, homie was Data Science before data science was a thing.
Homie is my man crush on the number one spot putting mfking henry cavill on second place.
Homie wakes up and pisses greatness.
Homie is the man. Hope yall have the same mfking homie as I do5 -
EXCEL YOU FUCKING PIECE OF SHIT! don't get me wrong, it's usefull and kt works, usually... Buckle up, your i for a ride. SO HERE WE FUCKING GO: TRANSLATED FORMULA NAMES? SUCKS BUT MANAGABLE. WHATS REALLY FUCKED UP IS HTHE GERMAN VERSION!
DID YOU HEAR ABOUT .csv? It stands for MOTHERFUCKING COMMA SEPERATED VALUES! GUESS WHAT SOME GENIUS AT MICROSOFT FIGURED? Hey guys let's use a FUCKING SEMICOLON INSTEAD OF A COMMA IN THE GERMAN VERSION! LET'S JUST FUCK EVERY ONE EXPORTING ANY DATA FROM ANY WEBSITE!
The workaround is to go to your computer settings, YOU CAN'T FUCKING ADJUST THIS IN EXCEL!, change the language of the OS to English, open the file and change it back to German. I mean, come on guys, what is this shit?
AND DON'T GET ME STARTED ON ENCODING! äöü and that stuff usually works, but in Switzerland we also use French stuff, that then usually breaks the encoding for Excel if the OS language is set to German (both on Windows and Mac, at least they are consistent...)
To whoever approved, implemented or tested it: FUCK YOU, YOU STUPID SHITFUCK, with love: me7 -
So my in-laws got a new computer 😑
Yup you know where this is going. Ok so after I transferred all of their data set them all up etc.
They wanted to use "word" and could I set it up for free for them. I said no Microsoft office is not free you lost your license and disk and your old computer is trashed so the better choice would be Google services . So I explained the value of using Google drive, docs,sheets etc.. today and told them how much better it is everything would be on their Google drive so if I got hit by a bus they could get a new computer again and still have access to their data etc... So they said great and so I did.
Two weeks later... Can you set up word for us on our computer. Me annoyed at this point " sure no problem"
I made a shortcut on their desktop to Google docs. Them: oh boy this is great see John all you have to do is click on google docs to go to word! Thanks so much!
🤫🤓5 -
Not only do I write software, but now I help the managers view and understand our analytics, just like in kindergarten.
Now I'm forced to help them essentially fake data so investors are satisfied 🤡🔫
"Delete metrics X, Y, and Z for now, we don't want anyone to see them!"
"Change the label of this metric to 'unique user' views! (not total!)"
"Set all charts to cumulative so it looks like they are all up and to the right!"
Sigh.
This isn't what I signed up for.17 -
Just thought I'd share my current project: Taking an old ISA sound card I got off eBay and wiring it up to an Arduino to control its OPL3 synth from a MIDI keyboard. I have it mostly working now.
No intention to play audio samples, so I've not bothered with any of the DMA stuff - just MIDI (MPU-401 UART) and OPL3.
It has involved learning the pinout of the ISA bus connectors, figuring out which ones are actually used for this card, ignoring the standards a little (hello, amplifier chip that is wired up to the +12V line but which still happily works at +5V...)
Most of the wires going to it are for each bit of the 16-bit address and 8-bit data. Using a couple of shift registers for the address, and a universal shift register for the data. Wrote some fairly primitive ISA bus read/write code, but it was really slow. Eventually found out about SPI and re-wrote the code to use that and it became very fast. Had trouble with some timings, fixed those.
The card is an ISA Plug and Play card, meaning before I could use it I had to tell it what resources to use. Linux driver code and some reverse-engineering of the official Windows/DOS drivers got me past this stage.
Wired up IRQ 5 to an Arduino interrupt to deal with incoming MIDI data, with a routine that buffers it. Ran into trouble with the interrupt happening during I/O and needing to do some I/O inside the handler and had to set a flag to decide whether to disable/re-enable interrupts during I/O.
It looks like total chaos, but the various wires going across the breadboard are mainly to make it easier to deal with the 16-bit address and 8-bit data lines. The LEDs were initially used to check what addresses/data were being sent, but now only one of them is connected and indicates when the interrupt handler is executing.
There's still a lot to do after that though - MIDI and OPL3 are two completely different things so I had to write some code to manage the different "channels" of the OPL3 chip. I have it playing multiple notes at the same time but need to make it able to control the various settings over MIDI. Eventually I might add some physical controls to it and get a PCB made.
The fun part is, I only vaguely know what I'm doing with the electronics side of this. I didn't know what a "shift register" was before this project, nor anything about the workings of the ISA bus. I knew a bit about MIDI (both the protocol and generally how the MPU-401 UART works) along with the operation of a sound card from a driver/software perspective, but everything else is pretty new to me.
As a useful little extra, I made some "fake" components that I can build the software against on a PC, to run some tests before uploading it to the Arduino (mostly just prints out the addresses it is going to try and write to). 46
46 -
Yep. So the dev teams boss says it's fine to run a production environment on a single Windows instance with the db on that same instance, which they already totally lost once from a reboot after an auto update before I came along tasked with fixing the cluster fuck they created.
This from a man who somehow runs a dev team while using gmail via the web because he can't use an email client, uses email to track tasks but can't because they get lost amongst his 3000+ unread emails, has a screen dirtier than a hookers vag on half priced Tuesday, and got a new laptop but had to get his daughter to set it up and transfer his data because he couldn't.
But ok... you have a degree, You must know what you're doing.
It's ok though, I'll keep covering your incompetent ass while you keep raping the company because no one listens.
Peoples ignorance and arrogance astounds me.4 -
Client called the office in an angry voice complaining about how he could nog see the data in the latest generated excel sheets. Calmy tryimg to figure out what could be the problem. Asked him to send over the file so I could check it. Works perfect on my end. Ask him to open the file again on his computer and tell me what he is seeing. Error message, empty excel file. He starts to me discribing a directory full of files and folders. 15 minutes later I finally figuren out what it is.
The guy had set winzip as default program for excel files. Hoe do these people work behind a PC Evert day. Are they like I hope this magic box with screen and buttond does everything right today.4 -
FUCK THE RECRUITERS WHO ASK US TO MAKE AN ENTIRE PROJECT AS A CODE TEST.
Oh you need to scrape this website and then store the data in some DB. Apply sentimental analysis on the data set. On the UI, the user should be able to search the fields that were scraped from the website. Upon clicking it should consume a REST API which you have to create as well. Oh and also deploy it somewhere... Oh I almost forgot, make the UI look good. If you could submit it in one week, we will move towards further rounds if we find you fit enough.
YOU KNOW WHAT, FUCK YOU!
I can apply to 10 others companies in one week and get hired in half the effort than making this whole project for you which you are going to use it on your website YOU SADIST MOTHERFUCK
I CURSE YOUR COMPANY WITH THE ETERNITY OF JS CALLBACK HELL 😡😤😣9 -
When migrating from MySQL server to MariaDB and having a query start returning a completely different result set then what was expected purely because MariaDB corrected a bug with sub selects being sorted.
It took several days to identify all that was needed on that sub select was “limit 1” to get that thing to return the correct data, felt like an idiot for only having to do 7 character commit 😆4 -
I'm moving some old data into a new database.
It contains some dates that *should* be in ISO 8601...
This is some of the trash that I found:
01/01/70
2010-11-05T08:06:48T08:06:03.7
2007-09-13T
Moreover, it has a column which *should* contains numbers, instead it has been defined using varchar, so it contains also some wonderful 'NaN' values.
I really would like to beat the person who set up all this stuff without some basic validation policies.9 -
I've optimised so many things in my time I can't remember most of them.
Most recently, something had to be the equivalent off `"literal" LIKE column` with a million rows to compare. It would take around a second average each literal to lookup for a service that needs to be high load and low latency. This isn't an easy case to optimise, many people would consider it impossible.
It took my a couple of hours to reverse engineer the data and implement a few hundred line implementation that would look it up in 1ms average with the worst possible case being very rare and not too distant from this.
In another case there was a lookup of arbitrary time spans that most people would not bother to cache because the input parameters are too short lived and variable to make a difference. I replaced the 50000+ line application acting as a middle man between the application and database with 500 lines of code that did the look up faster and was able to implement a reasonable caching strategy. This dropped resource consumption by a minimum of factor of ten at least. Misses were cheaper and it was able to cache most cases. It also involved modifying the client library in C to stop it unnecessarily wrapping primitives in objects to the high level language which was causing it to consume excessive amounts of memory when processing huge data streams.
Another system would download a huge data set for every point of sale constantly, then parse and apply it. It had to reflect changes quickly but would download the whole dataset each time containing hundreds of thousands of rows. I whipped up a system so that a single server (barring redundancy) would download it in a loop, parse it using C which was much faster than the traditional interpreted language, then use a custom data differential format, TCP data streaming protocol, binary serialisation and LZMA compression to pipe it down to points of sale. This protocol also used versioning for catchup and differential combination for additional reduction in size. It went from being 30 seconds to a few minutes behind to using able to keep up to with in a second of changes. It was also using so much bandwidth that it would reach the limit on ADSL connections then get throttled. I looked at the traffic stats after and it dropped from dozens of terabytes a month to around a gigabyte or so a month for several hundred machines. The drop in the graphs you'd think all the machines had been turned off as that's what it looked like. It could now happily run over GPRS or 56K.
I was working on a project with a lot of data and noticed these huge tables and horrible queries. The tables were all the results of queries. Someone wrote terrible SQL then to optimise it ran it in the background with all possible variable values then store the results of joins and aggregates into new tables. On top of those tables they wrote more SQL. I wrote some new queries and query generation that wiped out thousands of lines of code immediately and operated on the original tables taking things down from 30GB and rapidly climbing to a couple GB.
Another time a piece of mathematics had to generate all possible permutations and the existing solution was factorial. I worked out how to optimise it to run n*n which believe it or not made the world of difference. Went from hardly handling anything to handling anything thrown at it. It was nice trying to get people to "freeze the system now".
I build my own frontend systems (admittedly rushed) that do what angular/react/vue aim for but with higher (maximum) performance including an in memory data base to back the UI that had layered event driven indexes and could handle referential integrity (overlay on the database only revealing items with valid integrity) or reordering and reposition events very rapidly using a custom AVL tree. You could layer indexes over it (data inheritance) that could be partial and dynamic.
So many times have I optimised things on automatic just cleaning up code normally. Hundreds, thousands of optimisations. It's what makes my clock tick.4 -
Yesterday I got to the point where all changes that customer support and backend asked for were set, and i could start rebuilding the old models from their very base with the changes and the new, disjoint data the company expansion brought.
So making the start of our main script and the first commit, only having that, had high importance... At least to me. 3
3 -
Working on a project with 2 other students. One of them makes a C# "super class" with 50 fields, and manually creates getters and setters for each and every one. Then he proceeds to write a constructor that accepts 50 parameters, because why not.
I comment on the git commit, telling him that he can just write " get; set; " in C# and that he should model the problem in smaller, more manageable classes ( this class had 270 lines and did everything from displaying data to calculating stuff). Tried to explain to him that OOP works kind of differently from how he did it.
....
His answer: "Yeah, I don't really care. If it works once, it's okay for me".
This after the most beautiful code review I have ever done...
Fml8 -
Currently, a classmate and I are working on our technical thesis.
It is all about industry 4.0, IIoT, big data and stuff.
This week, we presented our interim results to our supervisor. He is very pleased with our work and made the following suggestion:
He thinks it would be awesome to publish our work on our own GitHub repository and make it open source because he is convinced that this thesis is able to kind of "set a new standard" in some specific fields of using big data analysis in production processes.
I guess I'm kind of proud :)4 -
I am interviewing people for a job position with python knowledge.
My first question is how to reverse string and second one what’s the difference between set and list.
So far no one knows.
Fairly speaking I am asking only basic questions about what is decorator, generator, lambda. Also some basic data structure questions.
Is it to hard ?
I lost my faith in humanity.15 -
"We use WSDL and SOAP to provide data APIs"
- Old-fashioned but ok, gimme the service def file
(The WSDL services definition file describes like 20 services)
- Cool, I see several services. In need those X data entities.
"Those will all be available through the Data service endpoint"
- What you mean "all entities in the same endpoint"? It is a WSDL, the whole point is having self-documented APIs for each entity format!
"No, you have a parameter to set the name of the data entity you want, and each entity will have its own format when the service return it"
- WTF you need the WSDL for if you will have a single service for everything?!?
"It is the way we have always done things"
Certain companies are some outdated-ass backwater tech wannabees.
Usually those that have dominated the market of an entire country since the fucking Perestroika.
The moment I turn on the data pipeline, those fuckers are gonna be overloaded into oblivion. I brought popcorn.6 -
Poorly written docs.
I've been fighting with the Epson T88VI printer webconfig api for five hours now.
The official TM-T88VI WebConfig API User's Manual tells me how to configure their printer via the API... but it does so without complete examples. Most of it is there, but the actual format of the API call is missing.
It's basically: call `API_URL` with GET to get the printer's config data (works). Call it with PUT to set the data! ... except no matter what I try, I get either a 401:Unauthorized (despite correct credentials), 403:Forbidden (again...), or an "Invalid Parameter" response.
I have no idea how to do this.
I've tried literally every combination of params, nesting, json formatting, etc. I can think of. Nothing bloody works!
All it would have taken to save me so many hours of trouble is a single complete example. Ten minutes' effort on their part. tops.
asjdf;ahgwjklfjasdg;kh.5 -
Sad story:
User : Hey , this interface seems quite nice
Me : Yeah, well I’m still working on it ; I still haven’t managed to workaround the data limit of the views so for the time limit I’ve set it to a couple of days
Few moments later
User : Why does it give me that it can’t connect to the data?
Me : what did you do ?
User : I tried viewing the last year of entries and compare it with this one
Few comas later
100476 errors generated
False cert authorization
Port closed
Server down
DDOS on its way1 -
AT&T: We've fixed your voicemail setup issue, use <APP> to set it up
Me: About fucking time
*uses app*
AT&T: Voicemail setup failed. Also, we've eaten 300MB of your 500MB of mobile data. 15
15 -
<just got out of this meeting>
Mgr: “Can we log the messages coming from the services?”
Me: “Absolutely, but it could be a lot of network traffic and create a lot of noise. I’m not sure if our current logging infrastructure is the right fit for this.”
Senior Dev: “We could use Log4Net. That will take care of the logging.”
Mgr: “Log4Net?…Yea…I’ve heard of it…Great, make it happen.”
Me: “Um…Log4Net is just the client library, I’m talking about the back-end, where the data is logged. For this issue, we want to make sure the data we’re logging is as concise as possible. We don’t want to cause a bottleneck inside the service logging informational messages.”
Mgr: “Oh, no, absolutely not, but I don’t know the right answer, which is why I’ll let you two figure it out.”
Senior Dev: “Log4Net will take care of any threading issues we have with logging. It’ll work.”
Me: “Um..I’m sure…but we need to figure out what we need to log before we decide how we’re logging it.”
Senior Dev: “Yea, but if we log to SQL database, it will scale just fine.”
Mgr: “A SQL database? For logging? That seems excessive.”
Senior Dev: “No, not really. Log4Net takes care of all the details.”
Me: “That’s not going to happen. We’re not going to set up an entire sql database infrastructure to log data.”
Senior Dev: “Yea…probably right. We could use ElasticSearch or even Redis. Those are lightweight.”
Mgr: “Oh..yea…I’ve heard good things about Redis.”
Senior Dev: “Yea, and it runs on Linux and Linux is free.”
Mgr: “I like free, but I’m late for another meeting…you guys figure it out and let me know.”
<mgr leaves>
Me: “So..Linux…um…know anything about administrating Redis on Linux?”
Senior Dev: ”Oh no…not a clue.”
It was all I could do from doing physical harm to another human being.
I really hate people playing buzzword bingo with projects I’m responsible for.
Only good piece is he’s not changing any of the code.3 -
I managed to accidentally clear everybody's usernames and email addresses from an SQL table once. I only recovered it because a few seconds before, I'd opened a tab with all the user data displayed as an HTML table. I quickly copied it into Excel, then a text editor (saving multiple times!), then managed to write a set of queries to paste it all back in place. If I'd refreshed the tab it would have all gone!2
-
Context: we analyzed data from the past 10 years.
So the fuckface who calls himself head of research tried to put blame on me again, what a surprise. He asked for a tool what basically adds a lot of numbers together with some tweakable stuff, doesnt really matter. Now of course all the datanwas available already so i just grabbed it off of our api, and did the math thing. Then this turdnugget spends 4 literal weeks, tryna feed a local csv file into the program, because he 'wanted to change some values'. One, this isnt what we agreed on, he wanted the data from the original. When i told him this, he denied it so i had to dig out a year old email. Two, he never explicitly specified anything so i didnt use a local file because why the fuck would i do that. Three, i clearly told him that it pulls data from the server. Four, what the fuck does he wanna change past values for, getting ready for time travel? Five, he ranted for like 3 pages, when a change can be done by currentVal - changedVal + newVal, even a fucking 10 year old could figure that out. Also, when i allowed changes in a temporary api, he bitched about how the additional info, what was calculated from yet another original dataset, doesnt get updated, when he fucking just randimly changes values in the end set. Pinnacle of professionalism.2 -
When working with hardware some mistakes can be literally painful. Thankfully this was all during undergrad and I'm only around computer hardware now lol.
>Misprogrammed a software kill switch so a sensor that should not have been sending data was actually sending data which caused the system to activate a piston that went WHAM! into the face of a teammate working on replacing some part of it...
>Misprogrammed a controller so it drew too much power from the supply and the puny supply wires literally burst into flame and fell across my arm.
>Spun a 9000rpm CNC spindle the wrong way and caused an attached screw to go rocketing upwards instead of downwards and almost break the (pretty expensive) thing (uh...we were trying to use it as a power screwdriver essentially but I set the rpm to about 100x what I wanted and the direction wrong so yeah).
>Switched a -1 with a +1 in a robot's control system sending it careening into a teammate's leg... let's just say mecanum wheels are paaaainful.6 -
The Hungarian public transport company launched an online shop (created by T-Systems), which was clearly rushed. Within the first days people found out that you could modify the headers and buy tickets for whatever price you set, and you could login as anyone else without knowing their password. And they sent out password reminders in plain text in non-encrypted emails. People reported these to the company which claims to have fixed the problems.
Instead of being ashamed of themselves now they're suing those who pointed out the flaws. Fucking dicks, if anyone they should be sued for treating confidential user data (such as national ID numbers) like idiots.3 -
Fuck Android Oreo and everyone who thought that the following ideas are useful:
- xy app is running in the background notification, which can't be disabled
- xy app is overlaying other apps, click here if you wish to disable it. But you can't disable the notification, you can only disable the app.
- the un-zeroable data limit. It can't be disabled, you can only set it to a retarded high number to avoid annoying notifications
Go suck a veiny one Android devs. Fucking cunt faces.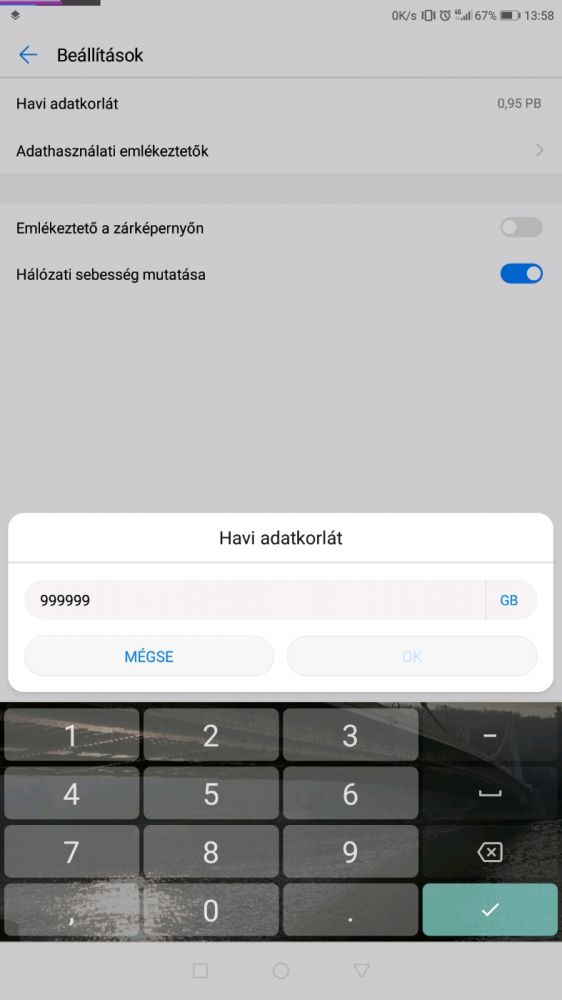 13
13 -
Fuck me in the ass, but do it harder then this api just so I can feel some love 😖
it's one of those days where you have to migrate from soap to rest, only the rest api doesn't have the same structure or search parameters as the soap api, so there's this entire fucking application sending requests at a brick wall, and expecting a purple throbbing 12 inch cock of xml to be pushed into an multi dimensional array and pushed through to the views to derange the mess, only you have to create that fucking 12 inch cock from several 2 inch dipsticks that have a different hierarchy, different field names, and merge the shit together with a glue gun...
good thing it's only an unexpected prod problem... right? 🤷♂️
Ah, the woes of a Monday on the legacy app adventures.1 -
Client: "Let's code a prototype to show our intents to the customer. We have 96 screens to implement as a native app in 6 weeks"
~Prototype delivered in 6 weeks, despite some changes in the design on-the-go. Few months later~
Client: "The customer likes the prototype a lot. They would like to see some changes (another set of > 40 screens). It's still a prototype and the changes should be implemented in a month, but this time it has to use real data from external apis. We don't know which APIs yet, but it should also go live on the app store"
Like, seriously?8 -
So these motherfuckers... they have stored the queries to generate the reports... fucking guess where. Just guess.
They stored the queries AS FUCKING STRING DATA IN THE TABLE. And you know how they get the parameters? A FUCKING JOIN WHERE THEY HAVE STORED THE PARAMS AS DATA IN ANOTHER TABLE.
So you query set the params to query to get the query to get that is joined with a query to get the reports.
If God is a programmer after all y’all are fuuuuuuuuuuuuuucked4 -
This is the craziest shit... MY FUCKING SERVER JUST SET ON FIRE!!!
Like seriously its hot news (can't resist the puns), it's actually really bad news and I'm just in shock (it's not everyday you find out your running the hottest stack in the country :-P)... I thought it slow as fuck this morning but the office internet was also on the fritz so I carried on with my life until EVERYTHING went down (completely down - poof gone) and within 2 minutes I had a technician from the data centre telling me that something to do with fans had failed and they caught fire, melted and have become one with the hardware. WTF? The last time I went to the data centre it was so cold I pissed sitting down for 2 days because my dick vanished.
I'm just so fucking torn right now because initially I was absolutely fucking ecstatic - 1 week ago after a year of doomsday bitching about having a single point of failure and me not being a sysadmin only to have them look at me like I'm some kind of techie flat earther I finally got approval to spend around 5x more per month and migrate all our software to containerized micro services.
I'll admit this is a bit worse than I expected but thanks to last week at least I have recent off site images of the drives - because big surprise I have to set this monolithic beast back up (No small feat - its gonna be a long night) on a fresh VPS, I also have to do it on premises or the data will only finish uploading sometime next week.
Pro Tip: If your also pleading for more resources/better production environment only to be stone walled the second you mention there's a cost attached be like me - I gave them an ultimatum, either I deploy the software on a stack that's manageable or they man the fuck up and pay a sys admin (This idea got them really amped up until they checked how much decent sys admins cost).
Now I have very flexible pockets because even if I go rambo the max server costs would only be 15-20% of a sys admins paycheck even though that is 13 x more than our current costs.
-
My apprentice is driving me nuts with his failed attempts on gold-plating.
The task "Get the data and export it to a file" becomes ""After many attempts to get the data via a different query than we worked out together I now finally got it and it makes sense if it was displayed but only one set of data at a time and it should also be selected what data should be exported and I have no idea how to do that so Cero, can you help me?".
Dang it dude, just show me for once that you can do 1 clearly decribed task, where you have many examples to work with, and NOT try to add any extras!
I am now working on how to tell him this in a nicer way...2 -
Always back up your data.
I came to my computer earlier today to find it on my Linux login screen. This could only mean one thing: something went horribly wrong.
Let me explain.
I have my BIOS set up to boot into Windows automatically. The exception is a reboot or something horrible happens and the computer crashes. Then, it boots me into Linux. Due to a hardware issue I never looked into, I have to be present to push F1 to allow the computer to start. The fact that it rebooted successfully, without me present, into *Linux*, could only mean one thing:
My primary hard drive died and was no longer bootable.
The warning was the BIOS telling me the drive was likely to fail ("Device Error" doesn't really tell me anything to be fair).
The massive wave of panic hit me.
I rebooted in hopes of reviving the drive. No dice.
I rebooted again. The drive appeared.
Let's see how much data I can recover from it before I can no longer mount it. Hopefully, I can come out of this relatively unscathed.
The drive in question is a 10 year old 1.5 TB Seagate drive that came with the computer. It served me well.
Press F to pay respects I guess.
On the bright side, I'll be getting an SSD as a replacement (probably a Samsung EVO).8 -
The guy who became my manager just pushes to the prod branch.
On a repo where another team clearly set up development and production branches.
This guy has been pushing code like crazy and I always wanted to take my time setting things up properly in our team: TDD, CI/CD, etc.
Because he pushed so much he became my manager and I was seen as unproductive.
Data Science and software development best practices just dont coexist it seems.
Yeah yeah, it's up to me to start introducing good practices, but atm "getting it done" takes priority over the real based shit.3 -
"I found this tool that we should use because I'm a manager and its simple enough that my tiny little manager brain could set it up!"
Oh wow good for you, Mr. Manager! And what, praytell, does the tool require?
"All proprietary and cost-ineffecient products: MSSQL Server and Windows IIS! What do you mean we have to get the data out in order for it to be scalable? Look at it! I set up a website by clicking on an EXE i downloaded from github!"
Amazing, Mr. Manager. So you violated our security practices AND want to pocket even MORE of our budget?
Kindly fuck right off and start suggesting things instead of making people embarrass you into stoping your fight for your tool (has happened on more than one occassion).3 -
I spent two weeks writing a WordPress plugin to take some form data, process it through another website, and take the result to Salesforce. the client had a "Salesforce specialist" doing everything on the Salesforce side and refused to give me access to see if the data was properly pushed through.
Finally I got it in working condition when suddenly it stopped working, I hadn't changed anything since it worked so I asked if he could have possibly changed something. We argued for over 4 hours about who changed something, the whole time I was looking for the error in my code. At 6pm I finally told him I would need to take a look at it tomorrow.
Overnight he sent me an email:
"Hey, sorry about the confusion yesterday, I set Salesforce to deny duplicate email entries, looks like once I removed that everything is working."6 -
Current task:
Somehow, one of my predecessors made some sort of custom hook tied to woocommerce check out that pipes some data into a nightmarish spaghetti fuck pile of undocumented wild west visual basic bullshit. It does this, presumably, via a set of parameters passed as plaintext in a url. I know this because I found the singleton that declares this. Helpfully, Mr. Fuckass named the class "Default", so I only have around 30k instances being kicked back by my IDE when I search for it. The only reason I "need" to find this, is so that I can just change the button to an href pointing at my own MS for shipping, and I need to change the fifteen params being passed to just one - a customer ID, which should be stored in the session, and referenced by a cookie. Once that is done, I should be able to freely delete a couple of gigs worth of bullshit. Been stuck on this for three days now. God forbid we have a test environment or something.
I'm tired. Can't even get angry anymore really. Can't even think of anything funny to say about it either, I just can't wait until this is done and I can go back to sleep.3 -
Because sharing is caring.
For anyone whom cares, I've extracted the CoronaVirus data for total infected / deaths from the world health organisation and shoved it into applicable csv files per day.
You can find the complete data set here:
https://github.com/C0D4-101/...5 -
Every language ever:
"You can't compare objects of type A and B"
Swift, on the other hand:
"main.swift:365:34: note: overloads for '==' exist with these partially matching parameter lists: (Any.Type?, Any.Type?), ((), ()), (Bool, B ool), (Character, Character), (Character.UnicodeScalarView.Index, Character.UnicodeScalarView.Index), (CodingUserInfoKey, CodingUserInfoKey ), (OpaquePointer, OpaquePointer), (AnyHashable, AnyHashable), (UInt8, UInt8), (Int8, Int8), (UInt16, UInt16), (Int16, Int16), (UInt32, UIn t32), (Int32, Int32), (UInt64, UInt64), (Int64, Int64), (UInt, UInt), (Int, Int), (AnyKeyPath, AnyKeyPath), (Unicode.Scalar, Unicode.Scalar ), (ObjectIdentifier, ObjectIdentifier), (String, String), (String.Index, String.Index), (UnsafeMutableRawPointer, UnsafeMutableRawPointer) , (UnsafeRawPointer, UnsafeRawPointer), (UnicodeDecodingResult, UnicodeDecodingResult), (_SwiftNSOperatingSystemVersion, _SwiftNSOperatingS ystemVersion), (AnyIndex, AnyIndex), (AffineTransform, AffineTransform), (Calendar, Calendar), (CharacterSet, CharacterSet), (Data, Data), (Date, Date), (DateComponents, DateComponents), (DateInterval, DateInterval), (Decimal, Decimal), (IndexPath, IndexPath), (IndexSet.Index, IndexSet.Index), (IndexSet.RangeView, IndexSet.RangeView), (IndexSet, IndexSet), (Locale, Locale), (Notification, Notification), (NSRange,
NSRange), (String.Encoding, String.Encoding), (PersonNameComponents, PersonNameComponents), (TimeZone, TimeZone), (URL, URL), (URLComponent s, URLComponents), (URLQueryItem, URLQueryItem), (URLRequest, URLRequest), (UUID, UUID), (DarwinBoolean, DarwinBoolean), (DispatchQoS, Disp atchQoS), (DispatchTime, DispatchTime), (DispatchWallTime, DispatchWallTime), (DispatchTimeInterval, DispatchTimeInterval), (Selector, Sele ctor), (NSObject, NSObject), (CGAffineTransform, CGAffineTransform), (CGPoint, CGPoint), (CGSize, CGSize), (CGVector, CGVector), (CGRect, C GRect), ((A, B), (A, B)), ((A, B, C), (A, B, C)), ((A, B, C, D), (A, B, C, D)), ((A, B, C, D, E), (A, B, C, D, E)), ((A, B, C, D, E, F), (A , B, C, D, E, F)), (ContiguousArray<Element>, ContiguousArray<Element>), (ArraySlice<Element>, ArraySlice<Element>), (Array<Element>, Array <Element>), (AutoreleasingUnsafeMutablePointer<Pointee>, AutoreleasingUnsafeMutablePointer<Pointee>), (ClosedRangeIndex<Bound>, ClosedRange Index<Bound>), (LazyDropWhileIndex<Base>, LazyDropWhileIndex<Base>), (EmptyCollection<Element>, EmptyCollection<Element>), (FlattenCollecti onIndex<BaseElements>, FlattenCollectionIndex<BaseElements>), (FlattenBidirectionalCollectionIndex<BaseElements>, FlattenBidirectionalColle ctionIndex<BaseElements>), (Set<Element>, Set<Element>), (Dictionary<Key, Value>.Keys, Dictionary<Key, Value>.Keys), ([Key : Value], [Key : Value]), (Set<Element>.Index, Set<Element>.Index), (Dictionary<Key, Value>.Index, Dictionary<Key, Value>.Index), (ManagedBufferPointer<Hea der, Element>, ManagedBufferPointer<Header, Element>), (Wrapped?, Wrapped?), (Wrapped?, _OptionalNilComparisonType), (_OptionalNilCompariso nType, Wrapped?), (LazyPrefixWhileIndex<Base>, LazyPrefixWhileIndex<Base>), (Range<Bound>, Range<Bound>), (CountableRange<Bound>, Countable Range<Bound>), (ClosedRange<Bound>, ClosedRange<Bound>), (CountableClosedRange<Bound>, CountableClosedRange<Bound>), (ReversedIndex<Base>, ReversedIndex<Base>), (_UIntBuffer<Storage, Element>.Index, _UIntBuffer<Storage, Element>.Index), (UnsafeMutablePointer<Pointee>, UnsafeMut ablePointer<Pointee>), (UnsafePointer<Pointee>, UnsafePointer<Pointee>), (_ValidUTF8Buffer<Storage>.Index, _ValidUTF8Buffer<Storage>.Index) , (Self, Other), (Self, R), (Measurement<LeftHandSideType>, Measurement<RightHandSideType>)"17 -
I have a few of these so I'll do a series.
(1 of 3) Public privates
We had a content manager that created a content type called "news item" on a Drupal site. There where two file fields on there. One called "attachments" and the other called "private attachments". The "private attachments" are only for members to see and may contain sensitive data. It was set to go trough Drupals security (instead of being directly hosted by the webserver) but because the permissions on the news items type where completely public everybody had access. So basically it was a slow public file field.
This might be attibuted to ow well Drupal is confusing. Howerver weeks earlier that same CM created a "private article". This actually had permissions on the content type correctly but had a file field that was set to public. So when a member posted the URL to a sensitive file trough unsafe means it got indexed by google and for all to read. When that happend I explained in detail how the system worked and documented it. It was even a website checklist item.
We had two very embarrassing data leaks :-(1 -
Had to consume a soap webservice which spits out a XML of 5000 lines with ambiguous node names and a shitload of data that needs to be parsed.
Built a ORM model to hold all the data and I already built a Xmlparser which works like a boss.. untill now..
I've been debugging for 3 hours, cursing every God man ever made up. Swearing at my screen like a madman... but this particular set of nodes just didn't got saved properly to the DB...
Alright, so my ORM definition is fucked... nope... Alright, so my XmlParser is fucked... nope...
Whaaaaat the fuuuuck...
Oh wait, I've been checking the wrong table for hours....
Hooray for ambiguous tables because I followed the ambiguous structure.
I am going to get drunk now.
X1 -
This was about 3 years ago. I’m on vacation and just getting off the plane, when my boss calls me on his cellphone. Apparently the crontab on our main file upload server had gotten nuked, and he was asking if there were any backups.
A word about this server. I work with video, so this thing is doing about a few gigabits of traffic incoming at any moment. The cron jobs are necessary to move and organize these massive files into a sane scheme for processing. Hundreds of drop folders receiving thousands of files resulting in terabytes of data every single day. Our storage vendor tells us we have the third largest deployment they know about.
No cron jobs mean all of this content is just sitting around piling up. I tell him sorry, try contacting $otherAdmin since he’s more familiar with that system.
A few days later, after the vacation, I come back in. $boss and $otherAdmin have reconstructed the crontab from scratch after an all nighter.
I ask how it got deleted.
$boss was training some people how to set up new customers on this file server, and he told the trainees to open the crontab in read-only mode. One of them ran:
crontab -r
Yes, we back up our crontabs now.3 -
Fuck Microsoft! 😡
I bought the new xBox One S....
Turns out it's not compatible with my home network and you can't set it up without an internet connection.
Ended up using my phone data (2GB used) just so I could do the updates required to watch a 4K movie.
Oh well, I guess I'll have to wait for the new internet connection arriving Monday 😔7 -
As you can see from the screenshot, its working.
The system is actually learning the associations between the digit sequence of semiprime hidden variables and known variables.
Training loss and value loss are super high at the moment and I'm using an absurdly small training set (10k sequence pairs). I'm running on the assumption that there is a very strong correlation between the structures (and that it isn't just all ephemeral).
This initial run is just to see if training an machine learning model is a viable approach.
Won't know for a while. Training loss could get very low (thats a good thing, indicating actual learning), only for it to spike later on, and if it does, I won't know if the sample size is too small, or if I need to do more training, or if the problem is actually intractable.
If or when that happens I'll experiment with different configurations like batch sizes, and more epochs, as well as upping the training set incrementally.
Either case, once the initial model is trained, I need to test it on samples never seen before (products I want to factor) and see if it generates some or all of the digits needed for rapid factorization.
Even partial digits would be a success here.
And I expect to create multiple training sets for each semiprime product and its unknown internal variables versus deriable known variables. The intersections of the sets, and what digits they have in common might be the best shot available for factorizing very large numbers in this approach.
Regardless, once I see that the model works at the small scale, the next step will be to increase the scope of the training data, and begin building out the distributed training platform so I can cut down the training time on a larger model.
I also want to train on random products of very large primes, just for variety and see what happens with that. But everything appears to be working. Working way better than I expected.
The model is running and learning to factorize primes from the set of identities I've been exploring for the last three fucking years.
Feels like things are paying off finally.
Will post updates specifically to this rant as they come. Probably once a day. 2
2 -
I got my new Oryx Pro today, from System76. It came with Ubuntu 18.04 LTS. I opted not to get Pop!_OS or Ubuntu 18.10, as I would prefer to leave the OS on it for the longterm.
Even at 15.6", it's a BIG laptop. It measures 18" from corner to corner, when it's closed. It comfortably fits in my backpack, which is a bit on the small side, but it's probably about 30-50% heavier than a MacBook Pro.
But that size and weight are vindicated by the most thuggish hardware I have ever seen in a laptop. As configured, this machine has a 4.1GHz 8th gen i7, 32GB of DDR4 at 2666MHz, an 8GB GTX 1070, a 250GB nvme system disk, and a 1TB SSD for data.
The display is set by default to 4K resolution, but I cranked that down to FHD for the sake of my eyes and the battery. I will try some games at higher resolution at some point, but for desktop navigation, I get more use out of multiple virtual desktops than in massive resolution.
I will comment tomorrow or the day after with the steps I've taken to bend this beast to my will, and it's also important to say that I have not finished yet. This is just a summary, but I should have been in bed an hour ago, so I'm gonna go do that.9 -
Still dealing with the web department and their finger pointing after several thousand errors logged.
SeniorWebDev: “Looks like there were 250 database timeout errors at 11:02AM. DBAs might want to take a look.”
I look at the actual exceptions being logged (bulk of the over 1,600 logged errors)..
“Object reference not set to an instance of an object.”
Then I looked the email timestamp…11:00AM. We received the email notification *before* the database timeout errors occurred.
I gather some facts…when the exceptions started, when they ended, and used the stack trace to find the code not checking for null (maybe 10 minutes of junior dev detective work). Send the data to the ‘powers that be’ and carried on with my daily tasks.
I attached what I found (not the actual code, it was changed to protect the innocent)
Couple of hours later another WebDev replied…
WebDev: “These errors look like a database connectivity issue between the web site and the saleitem data service. Appears the logging framework doesn’t allow us to log any information about the database connection.”
FRACK!!...that Fracking lying piece of frack! Our team is responsible for the logging framework. I was typing up my response (having to calm down) then about a minute later the head DBA replies …
DBA: “Do you have any evidence of this? Our logs show no connectivity issues. The logging framework does have the ability to log an extensive amount of data regarding the database transaction. Database name, server, login, command text, and parameter values. Everything we need to troubleshoot. This is the link to the documentation …. If you implement the one line of code to gather the data, it will go a long way in helping us debug performance and connectivity issue. Thank you.”
DBA sends me a skype message “You’re welcome :)”
Ahh..nice to see someone else fed up with their lying bull...stuff.
-
Want to make someone's life a misery? Here's how.
Don't base your tech stack on any prior knowledge or what's relevant to the problem.
Instead design it around all the latest trends and badges you want to put on your resume because they're frequent key words on job postings.
Once your data goes in, you'll never get it out again. At best you'll be teased with little crumbs of data but never the whole.
I know, here's a genius idea, instead of putting data into a normal data base then using a cache, lets put it all into the cache and by the way it's a volatile cache.
Here's an idea. For something as simple as a single log lets make it use a queue that goes into a queue that goes into another queue that goes into another queue all of which are black boxes. No rhyme of reason, queues are all the rage.
Have you tried: Lets use a new fangled tangle, trust me it's safe, INSERT BIG NAME HERE uses it.
Finally it all gets flushed down into this subterranean cunt of a sewerage system and good luck getting it all out again. It's like hell except it's all shitty instead of all fiery.
All I want is to export one table, a simple log table with a few GB to CSV or heck whatever generic format it supports, that's it.
So I run the export table to file command and off it goes only less than a minute later for timeout commands to start piling up until it aborts. WTF. So then I set the most obvious timeout setting in the client, no change, then another timeout setting on the client, no change, then i try to put it in the client configuration file, no change, then I set the timeout on the export query, no change, then finally I bump the timeouts in the server config, no change, then I find someone has downloaded it from both tucows and apt, but they're using the tucows version so its real config is in /dev/database.xml (don't even ask). I increase that from seconds to a minute, it's still timing out after a minute.
In the end I have to make my own and this involves working out how to parse non-standard binary formatted data structures. It's the umpteenth time I have had to do this.
These aren't some no name solutions and it really terrifies me. All this is doing is taking some access logs, store them in one place then index by timestamp. These things are all meant to be blazing fast but grep is often faster. How the hell is such a trivial thing turned into a series of one nightmare after another? Things that should take a few minutes take days of screwing around. I don't have access logs any more because I can't access them anymore.
The terror of this isn't that it's so awful, it's that all the little kiddies doing all this jazz for the first time and using all these shit wipe buzzword driven approaches have no fucking clue it's not meant to be this difficult. I'm replacing entire tens of thousands to million line enterprise systems with a few hundred lines of code that's faster, more reliable and better in virtually every measurable way time and time again.
This is constant. It's not one offender, it's not one project, it's not one company, it's not one developer, it's the industry standard. It's all over open source software and all over dev shops. Everything is exponentially becoming more bloated and difficult than it needs to be. I'm seeing people pull up a hundred cloud instances for things that'll be happy at home with a few minutes to a week's optimisation efforts. Queries that are N*N and only take a few minutes to turn to LOG(N) but instead people renting out a fucking off huge ass SQL cluster instead that not only costs gobs of money but takes a ton of time maintaining and configuring which isn't going to be done right either.
I think most people are bullshitting when they say they have impostor syndrome but when the trend in technology is to make every fucking little trivial thing a thousand times more complex than it has to be I can see how they'd feel that way. There's so bloody much you need to do that you don't need to do these days that you either can't get anything done right or the smallest thing takes an age.
I have no idea why some people put up with some of these appliances. If you bought a dish washer that made washing dishes even harder than it was before you'd return it to the store.
Every time I see the terms enterprise, fast, big data, scalable, cloud or anything of the like I bang my head on the table. One of these days I'm going to lose my fucking tits.10 -
Just learned that yesterday someone suggested putting the dev team on "workspace", when I was on leave.
My first question, "what the hell is workspace?"
"It's a remote environment..."
Okay I get it. Are you kidding me? Doing development on remote desktop?
My second question, "Why the hell did someone suggest that?"
"We have had issues with devs using MySQL but the target prod will be using PostgreSQL. That caused issues, inconsistencies... And we found some issues after deployment."
Okay so much for DB agnostic. I called it out that everyone now install PostgreSQL on local. Problem solved, hopefully.
Why we had MySQL in the first place? Yes DB agnostic is one of the reason. The other being I'm more familiar with MySQL so it's quicker to perform tasks (like "can you clone that environment for me" and "can you fix the data on XYZ"). But that's trivial.
Just some ridiculous suggestion that set me off.7 -
Fucking shit i just had a 3 days chat with google's cloud engineer about an issue i had in a project. eventually the issue occured due to an update they made on some projects involving IAM changes that required some changes from my part in my security toles. Like wtf haven't you heard of data fixes when you roll out such changes?! I just had my production env down for 72hours for their fuckup.
At least send an email regarding it so we could set it up in time1 -
Hi! I'm new in freelancing. I've created a program that scrapes data from a website, parses it, runs DB queries, and emails the prepared data to the customer for whom I've created this program. The whole program is written in PHP and uses a MySQL table. There's almost no front-end, it's just like an automated background process that runs with a cron job. I've bought and set up a domain and hosting for them (my cutomer paid it all). I got the core part of the program running after ~2 days, and it took me ~a week to complete the project including adding features and the testing phase. Now, I'd like to know, how much does this kind of project cost? The business operates in Silicon Valley.10
-
Idiots. Just... Fucking Idiots.
Junior Frontend dev got a feature to implement. Decided to add a field to a set of mongo collections. I'm the responsible adult for those collections. Talked to the junior - told it, "don't do that, you will lose the data you are adding later". Junior says "will not happen", and goes on to try and prove It is "Right". Problem? Junior is an Idiot. did not trigger the data loss scenario. So... Junior got his TL to talk to the RND manager. And those Idiots Decided that the implementation will go forward as is.
Data loss will happen. QA will not find it. Only the client will experience the data loss, and complain....3 -
#10 year challenge is basically data set father for new ai which will predict how X looks after 10 years
Data mining at its best2 -
when you start machine learning on you laptop, and want to it take to next level, then you realize that the data set is even bigger that your current hard-disk's size. fuuuuuucccckkk😲😲
P. S. even metadata csv file was 500 mb. Took at least 1 min to open it. 😭😧11 -
Ok, here goes...
I was once asked to evaluate upgrade options for an online shop platform.
The thing was built on Zend 1, but that's not the problem.
The geniuses that worked on it before didn't have any clue about best practices, framework convention, modular thinking, testing, security issues...nothing!
There were some instances when querying was done using a rudimentary excuse for a model layer. Other times, they would just use raw queries and just ignore the previous method. Sometimes the database calls were made in strange function calls inside randomly loaded PHP files from different folders from all over the place. Sometimes they used JOINs to get the data from multiple tables, sometimes they would do a bunch of single table queries and just loop every data set to format it using multiple for loops.
And, best of all, there were some parts of the app that would just ignore any ideea of frameworks, conventions and all that and would be just a huge PHP file full of spagetti code just spalshed around, sometimes with no apparent logic to it. Queries, processing, HTML...everything crammed in one file...
The most amazing thing was that this code base somehow managed to function in production for more than 5 years and people actualy used it...
Imagine the reaction I got from the client the moment I said we should burn it to the ground and rebuild the whole thing from scratch...
Good thing my boss trusted me and backed me up (he is a great guy by the way) and we never had to go along with that Frankenstein monster... -
Oh I have quite a few.
#1 a BASH script automating ~70% of all our team's work back in my sysadmin days. It was like a Swiss army knife. You could even do `ScriptName INC_number fix` to fix a handful of types of issues automagically! Or `ScriptName server_name healthcheck` to run HW and SW healthchecks. Or things like `ScriptName server_name hw fix` to run HW diags, discover faulty parts, schedule a maintenance timeframe, raise a change request to the appropriate DC and inform service owners by automatically chasing them for CHNG approvals. Not to mention you could `ScriptName -l "serv1 serv2 serv3 ..." doSomething` and similar shit. I am VERY proud of this util. Employee liked it as well and got me awarded. Bought a nice set of Swarowski earrings for my wife with that award :)
#2 a JAVA sort-of-lib - a ModelMapper - able to map two data structures with a single util method call. Defining datamodels like https://github.com/netikras/... (note the @ModelTransform anno) and mapping them to my DTOs like https://github.com/netikras/... .
#3 a @RestTemplate annptation processor / code generator. Basically this dummy class https://github.com/netikras/... will be a template for a REST endpoint. My anno processor will read that class at compile-time and build: a producer (a Controller with all the mappings, correct data types, etc.) and a consumer (a class with the same methods as the template, except when called these methods will actually make the required data transformations and make a REST call to the producer and return the API response object to the caller) as a .jar library. Sort of a custom swagger, just a lil different :)
I had #2 and #3 opensourced but accidentally pushed my nexus password to gitlab. Ever since my utils are a private repo :/3 -
I think I've been doing too much Android programming in the last three days.
Had a lucid dream last night where I couldn't wake up until I figured out how to set up an inter-thread latch that would allow me to process through a shit ton of data points in parallel without duplication or skipping errors in the most efficient manner (effectively no blocking). We're talking several hundred lines of code. Slept 14 hours last night, I heard my alarm but didn't wake up. When I finally got up, I did what I did in my dream and it worked better than the existing code.
Turns out my brain is great at Java evaluation now, I guess.4 -
Fuck everything about Microsoft Dynamics. I'm supposed to use the REST API to make a web front-end. I notice all of the data comes back codified.
null == 0.
boolean true == 100000000
boolean false == 100000001
except sometimes when
boolean false == 100000000
boolean true == 100000001
or other times
string "Yes" == 100000000
string "No" == 100000001
string "Maybe" == 100000003
Hang on. Is the system representing a 1 bit value with base 10 numbers? Did the client set this up like this? Holy crap every number corresponds to a unique record in a table somewhere. That means it only returns numeric values instead of strings and I have to figure out what the number means in the context of the table.
A "key" is user typed? So every time someone starts to make a new record it saves a new "key" without a record? So I can pull a bunch of "0" records if I pull sequentially? So basically I need to see all of the data in Dynamics to have any context at all for what is returned from the Dynamics API? Fuuuuuuuuuu10 -
One of our employees set up a RAID 0 (by accident) on the MySQL server years ago and a drive decided to fail....
Why did the system administrator not do their job :’(
24 hours of data lost, clients will be mad especially since its running a CRM.13 -
I dunno about coolest, but I did sort of cement my reputation as the "database guy" in my first job because of this.
My first job was with a group maintaining a series of websites. Because of the nature of the websites, every morning we had to pull the records from one database on one network, sneaker net the data to a database on another network, and import the data via custom data import function.
However, the live site would crash after 100 or so records were imported. The dba at the live site had to script out a custom data partitioning script to do his daily duties, but it definitely messed up his productivity.
Turns out, the custom mass import function had recycled the standard import function, which was only used to import 1 record at a time, and it never closed its database connections, because it never needed to. A one line fix to production code was delivered 6 months later (because that was our release cycle) and I came up with the temporary work around, which was basically removing the connection limit. It would still crash with the work around, but only with multiple days worth of data. So basically only on Monday. Also developed the test set for the import (15k+ records). -
Possibly the start of a very bad adventure: I'm helping my brother-in-law set up a website for a business he'd beginning with his wife. I'll be needing to provide him a simple cms & shopping cart that he can manage. No payments as we want to just use PayPal so as to avoid having to actually manage user data & credit card information.
Wish me well....
Also advices appreciated cause otherwise, I'm gonna use a simple Drupal or WordPress site with like 1 theme and 0 plug ins.4 -
This is some real shady shit...
I was trying to set my office 365 account we got from school to gmail in my phone and this is what it wants to be able to do. In summary (Dutch screenshots):
- It can disable important safety features,
- Lock me out of my phone at any moment,
- Encrypt all data,
- Or just erase all of it
- And watch me while they do it
Nice. 3
3 -
Why the hell must Microsoft always be dickhead about the telemetry.
Take one beautiful NET.CORE. I make an app for myself, deploy it only to find out that those data-hungry arses have built-in default enabled telemetry and the only way to disable it is to set one dick-long env. variable:
DOTNET_CLI_TELEMETRY_OPTOUT="1"
Seriously ??
No way to exclude it completely, you have to sweat blood everywhere it runs.
Consent ? Hardly, just small line during installation...
I swear everything MS touches turns into spyware...1 -
When I was really new to JavaScript, I wanted to create an image gallery with images which I stored in a MySQL database. Well, I did not really had a clue how to load all the image sources into my JavaScript to load the images. I also didn't know much about fetching an endpoint of my website to get the data asynchronously.
I also wasn't a good database architect at that time and my database had an image table wich was for the gallery. Within this table there were multiple columns for one image slider (there should be multiple sliders on one page in the gallery (I know... 🤢)).
So I ended up writing an PHP loop wich printed Javascript loops for each row in my images table. Within my JavaScript loop I created the sliders and set the images.
In my defense I can say: It worked. 😅
It hurts to remember this. And I hope you won't judge me.2 -
Was talking to a cousin of mine who's a priest and who spent 10 years in the Vatican, apparently they have 2-3 servers devoted specifically to acting as a firewall processing the data coming in and out of its network and it's a continuous stream of people trying to hack it, like think it would be pretty cool to see what way they have to whole thing set up, might see if he could take me on a tour (might even get a look at the private archives, though apparently it's mainly boring letters about popes meeting their mother and stuff4
-
!(!(!(!(!(!(!(!rant)))))))
My new HTC smartphone hates me.
First it started to shut down all of the sudden yesterday night, when I was solving quadratic equations on my laptop.
I thought that it might be due to low battery. So I have restarted it. After putting itself into a bootloop for 4 start sequences, it was able to fully start to the page where it told me to enter the security pin to decrypt my files. I also had 30 attempts left. Like a ransomware.
I was like "tf I didn't set anything up".
So I decided to use my first attempt as I had 30 attempts left.
I entered the pin (I can swear that it's correct) and it told me that it has to wipe the /data partition.
I did that. I pressed that button. After waiting for 30 minutes I gave up and rebooted into the bootloader.
Bootloader -> Download Mode -> wipe /data (stock rom + stock recovery btw.)
Some error with "e: mount /cache failed[...]e: mount /data failed"
So, I tried using the adb sideload - no success.
Fastbooted into RUU Mode - HTC keeps rebooting itself into the RUU Mode - no success
Tried to flash the firmware and twrp recovery from Download mode - no success
Then I tried to flash all these things from the sd card - no success
Searched for revolutionary (I know this from my old HTC sensation device).
It wasn't big of any help.
Then someone on xda recommended htcDev (htc's <b>developer-friendly</b> lol site)
I followed every step. Everything seemed to be okay.
I got to the last step.
I needed to get my encrypted token by entering "fastboot oem get_identifier_token" to be able to submit it to HTC, and after they would send me an e-Mail with an .bin file that would let me unlock the bootloader to be able to flash my way through all this headache giving fucking piece of dog shit!
But since I can't back to the phone settings to select the bootloader activation box that would let me get my token... but nah.
FML
------------
Sent by using the devRant web app (:\)8 -
Writing coroutines for io_uring. Submissions aren't working (they go through but the operation never seems to complete). Just fixed a few segfaults because of error cases not destroying coroutine handles correctly. Been on this for two days, finding more and more things I need to do that unrelated to the task at hand. Don't have issue tracking set up yet because haven't had time. Mountain of things that need to get working just for a demo is only growing. Layered maps of data structures and code flow are in my head as I'm trying to mentally debug some of this. I'm focused, completely dead to the outside world.
Then I feel a small scratch on my cheek. Three hours of mental mapping and a deep stack of thought, vanishes into thin air in a single moment.
The trade-off is worth it though. 10
10 -
Maybe if you started actually fucking backing up your bullshit MONTHS ago when I told you your system was dying, or replaced it when I told you it was failing, you wouldn't have lost 6 fucking months worth of fucking work when it finally died today.
I setup a file backup system since you never had one, I gave you detailed instructions a fucking 40 year adult she be able to follow, I even offered to walk you through the process the first time after I set it up.
It shouldn't be my fucking problem you're too fucking stupid to listen to the tech person YOU fucking hired and lost data.
I was hired as a damn programmer, setting up the server wasn't in my job description, backing up emails because you refuse to pay for more GMail storage isn't in my job description, fucking 70% of what I've done this past fucking year working for you isn't in my job description.
Fucking hell, I'm fucking glad I'm working on leaving. The fucking employee shouldn't fucking care more than the damn owner. This place is not going to grow, and most of your employees are working on applying elsewhere because of your short-sightedness and petty bullshit drama you bring everywhere, everyday.3 -
Two months ago I started working at a new company, who's system is a huge monolith. The company is a bit over one year old, and the code base is huge. The desire to move to more of a microservices architecture is on the radar, but one of the biggest issues in moving towards it is how we should keep our models. The stack is basically Node.js and Mongoose, where there's about a few dozen mongoose models that the whole system uses, and the issue is that, if we moved to a microservices architecture, how could we keep the models in sync. One idea I had was to keep the models in a separate (node) package that would be shared across all microservices, but then there's the issue that if one model needs changes, all microservices that use that model will need to be updated. Another idea we had was to not share models, but instead let every microservice be in charge of everything to do with a certain type of data (eg. Users are only directly accessed by one microservice, companies by another, and no two microservices share responsibility over data), but that might bring problems when one microservice depends on a certain set of data from another microservice. How do you guys manage all that? Any ideas or tips? Thanks ^^14
-
My God is map development insane. I had no idea.
For starters did you know there are a hundred different satellite map providers?
Just kidding, it's more than that.
Second there appears to be tens of thousands of people whos *entire* job is either analyzing map data, or making maps.
Hell this must be some people's whole *existence*. I am humbled.
I just got done grabbing basic land cover data for a neoscav style game spanning the u.s., when I came across the MRLC land cover data set.
One file was 17GB in size.
Worked out to 1px = 30 meters in their data set. I just need it at a one mile resolution, so I need it in 54px chunks, which I'll have to average, or find medians on, or do some sort of reduction.
Ecoregions.appspot.com actually has a pretty good data set but that's still manual. I ran it through gale and theres actually imperceptible thin line borders that share a separate *shade* of their region colors with the region itself, so I ran it through a mosaic effect, to remove the vast bulk of extraneous border colors, but I'll still have to hand remove the oceans if I go with image sources.
It's not that I havent done things involved like that before, naturally I'm insane. It's just involved.
The reason for editing out the oceans is because the oceans contain a metric boatload of shades of blue.
If I'm converting pixels to tiles, I have to break it down to one color per tile.
With the oceans, the boundary between the ocean and shore (not to mention depth information on the continental shelf) ends up sharing colors when I do a palette reduction, so that's a no-go. Of course I could build the palette bu hand, from sampling the map, and then just measure the distance of each sampled rgb color to that of every color in the palette, to see what color it primarily belongs to, but as it stands ecoregions coloring of the regions has some of them *really close* in rgb value as it is.
Now what I also could do is write a script to parse the shape files, construct polygons in sdl or love2d, and save it to a surface with simplified colors, and output that to bmp.
It's perfectly doable, but technically I'm on savings and supposed to be calling companies right now to see if I can get hired instead of being a bum :P14 -
If they followed my suggestion and went straight to debugging the server issues they would have been solved it from week 1 and everyone would have thought the migration had a minor performance hiccup. In fact, we have already done such at least twice before and nobody batted an eye.
Instead they self-labelled the migration a failure on first error, setting the stage for apologizing to the client, and put themselves on the spot for a whole staging / production signoff, replication / backup worfklow, almost a blue-green "seamless" deployment reminiscent of DigitalOcean.
Well they're not DigitalOcean, and anyone who has spent any time understanding users knows they will not participate in "new system" tests long enough to find or report issues.
So of course the migration stretched out to almost three months up until the whole reason for the migration - the rapidly escalating risk of the old provider disappearing - hit like a freight train and now they have to go through the problem of debugging the server like I told them to on week 1. Only this time they've set the client mindset against it, lost any chance of reverting, have had grave risk for data loss, and are under pressure to debug other people's code in real-time.
This is why I don't trust devs to do ops. A dev's first solution to any problem is to throw tech at it.
-
Hey, fellow dRs.
I may need some help regarding this circuit.
It is about an 8 Bit multifunctional shift register with a 2 Bit instruction set.
These work:
If "Sel" is 0x00, the circuit loads data into its 8 D flip flops.
If "Sel" is 0x03, the circuit replaces all data with 0s.
These don't work (they do, but they do it in a very strange way and end up filling 1s instead):
If "Sel" is 0x01, it is supposed to ringshift bitwise to the right.
If "Sel" is 0x02, it is supposed to ringshift to the left.
As mentioned above. They do it in a very strange way. If we have 10000000, it will shift to the left or right depending on the "Sel"'s binary value. Let us say we want to shift it right. The output will turn from 10000000 to 01000000 (which is what we want), BUT after that it adds another 1 to it: 01100000. It keeps doing it until every single Bit is a 1. Same thing happens with the left ringshift.
I will include the other circuits used in this circuit in the comment section. 23
23 -
On a more positive note, after reading that facebook set a ton posts and pictures to public "accidentally" - I finally deleted my near old age, never used facebook account, that I was tbh just too lazy to delete or thought I'd sometime have some value looking back to people I haven't talked to in multiple decades and couldn't give a flying fuck about
Before that I downloaded "all" (tbh what did I expect, there's not even a folder like "tagged in", which obv. is data they have too) the data they collected for the time, that I did use it and I am glad basically all creepy named folders had nothing in them, like e.g. phone call logs, since I never as far as I remember installed the app on my phones
btw: does somebody know what happened to @nanos? he seemed to have just disappeared3 -
Pulled into an 'emergency' meeting with a group of web designers deeply concerned a particular service wasn't going to meet all their requirements.
DevA: "For each page, Its going to be A LOT of work to retrieve all the data and store it's state. Every page load will require a round trip to the service."
DevB: "Yes, we aren't sure how the service should be changed to do what we need."
Mgr: "What is it not doing now? Doesn't the service already returns all the necessary data?"
DevA: "Well...um...its all the boolean fields. Some may be defaulted from the database or false because the user unchecked the box. We have to know which is which"
Me: "Why? Are you doing anything different in the UI? Checkbox will be true or false. What or who set that value is irrelevant"
DevC: "Well, it matters if the user didn't fill out all other other values."
Me: "How so?"
DevA: "Its matters because the values in the other fields. Its going to be A TON of work to figure out."
<mgr goes to the white board>
Mgr: "Lets map this out...what fields are you needing to trigger the state on?"
DevA: "Um...uh...the 'Approved' field...and um...'OK to Contact' field"
Mgr: "Just those two?"
DevA: "Yea..um...there are other fields, but whether or not to show the edit box depends on those two."
Me: "The service already returns data, you only have two fields to check? I don't see a need to change the service at all."
DevA: "Returning all that data, we are going have a serious scaling problem. We'll be hitting the service A LOT. All that javascript could cause performance problems too"
Me: "How much data are we talking about? Name, address, couple of booleans?"
DevA: "I have to serialize the data. All that logic is going to be reeeaaallly complicated. It might be better if the service returned only the data I need."
Me: "$64,000 question, how often is this feature going to be used on the web site? Maybe once? Few hundred a week?"
Mgr: "We have no idea. A lot of the data will be pre-populated and we're only sending out a few thousand invitations. More around the holidays...but honestly, not very many."
Me: "Changing that service only for this particular area of the web site isn't going to happen. Changing the UI is the only course of action."
DevA: "Oh frack I can't wait until this project is over."
DevA...how the funck do still have a job here? You wasted about half-hour of my time with your cry-baby crap. Where is my hammer...no...no..don't go there...ahhh...thanks devrant. Prison sentence diverted.2 -
Ecma International, the organization in charge of managing the ECMAScript standard, has published the most recent version of the JavaScript language. ECMAScript 2016 (ES7 or JavaScript 7th Edition in the old naming scheme) comes with very few new features. The most important is that JavaScript developers will finally get a "raise to the power" operator, which was mysteriously left out of the standard for 20 years. The operator is **... It will also become much easier to search for data in a JavaScript array with Array.prototype.includes(), but support for async functions (initially announced for ES2016), has been deferred until next year's release. "From now on, expect smaller changelogs from the ECMAScript team," reports Softpedia, "since this was the plan set out last year. Fewer breaking changes means more time to migrate code, instead of having to rewrite entire applications, as developers did when the mammoth ES6 release came out last year."1
-
Ladies and gents, it was a 🍺 day, today.
I spent more hours than I care to say today tracking down an issue in our web workflow, even looping in our only web dev to help me debug it from his side. There ended up being multiple bugs found, but the most annoying of them was that the json data being pulled back was truncated because a certain someone, in their migration script, set their varchar variable to a size of 1000 and then proceeded to store a json string that was 2800+ characters in length.
C'mon man!
I got nothing productive done today. Hate, hate, hate days like this!
Beer me.3 -
I recently tried to apply the same data analytics rationale that I use at work to my personal life. This is not a rant, it is more like an data storytelling of an actual use case I would like some input on.
I set a goal - gotta thin up a bit and calm down my ticker - and got a (almost unreasonably expensive) field expert consultant to yell at me about it for a couple hours.
I unravel the metrics - there is like a million weight-related KPIs and most say nothing at all. I have never seen an non-infrastructure measurable subject that could not be resumed to 2-5 performance metrics. I got overall weight, how well my nine-years-old business suit fits me, heart rate, and day-after relative muscle pain (it will make sense soon).
Then its data-pipeline time. I bought a cheap weight scale and smartwatch, and every morning I input the data in an app. Yes, I try to put on the suit every morning. It still does not fit.
After establishing a baseline, I tried to fit different approaches. Doing equipment-free exercises, going to the gym, dieting. None was actually feasible in the long run, but trying different approaches does highlight the impacts and the handling profile of each method.
Looking at the now-gathered data, one thing was obvious - can't do dieting because it is not doable to have a shopping list and meals for me and another for the family.
Gym is also off the table - too much overhead. I spend more time on the trip there and back than actually there.
And home exercise equipment is either super crappy or very expensive. But it is also the most reasonable approach.
So it is solutions time. I got a nice exercise bycicle (not a peloton), an yoga mat (the wife already had that one) and an exercise program that uses only those two resources. Not as efficient without dieting, not as measurable and broad as the gym, but it fits my workflow. Deploy to production!
A few months pass and the dataset grows. The signal is subtle but has support - it works! The handling, however, needs improvement, since I cannot often enough get with the exercise program. Some mornings are just after some hard days.
I start thinking about what else I can improve in the program, but it is already pretty lean and full of compromises.
So I pull an engineer and start thinking about the support systems and draft profile. What else could be draining my willpower and morning time?
Chores. Getting the kids ready for school, firing up the moka pot, setting the off-brand roomba, folding the overnight-dried clothes, cooking breakfast, doing the dishes, cleaning the toilets. All part of my morning routine. It might benefit from some automation.
Last month I got that machine our elders call "wasteful" and "useless crap lazy entitled Americans invented because they feel oh-so-insulted for simply doing something by hand like everyone always did" - a "dish-washer".
Heh, I remember how hard was to convince my mother-in-law that an remote-controled electric garage door would not make she look like an spoiled brat.
Still to early to call, but I think that the dishwasher just saved me about 25 mins every morning. It might be enough to save willpower for me to do more exercise.
This is all so reflective of all data analytics cases really are out in the wild - the analytics phase seems so small compared to the gathering and practical problem-solving all around. And yet d.a. is what tells you that you are doing the wrong thing all along. Or on what you should work next.7 -
Should I be excited or concerned?
Newbie dev(babydev) who just learned string vs int and the word "boolean", is SUPER into data parsing, extrapolation and recursion... without knowing what any of those terms.
2 ½ hrs later. still nothing... assuming he was confused, I set up a 'quick' call...near 3 hrs later I think he got that it was only meant so I could see if/where he didnt understand... not dive into building extensive data arch... hopefully.
So, we need some basic af PHP forms for some public-provided input into a mySQL db. I figured I'd have him look up mySQL variables/fields, teach him a bit about proper db/field setup and give him something to practice on his currently untouched linux container I just set up so he could have a static ipv4 and cli on our new block (yea... he's spoiled, but has no clue).
I asked him to list some traits of X that he thinks could be relevant. Then to essentially briefly explain the logic to deciding/returning the values/how to store in the db... essentially basic conditionals and for loops... which is also quite new to him.
I love databases; I know I'm not in the majority... I assumed he'd get a couple traits in his mind and exhaust himself breaking them down. I was wrong. He was/likely is in his sleep now, over complicating something that was just meant as a basic af.
Fyi, the company is currently weighted towards more autistics (him and myself included) than neurotypicals.
I know I was(still am) extremely abnormal, especially when it comes to things like data.
So, should I be concerned/have him focus elsewhere for a bit?... I dont want to have him burnout before he even gets to installing mySQL44 -
Years ago I was working in local cinema as a student job from time to time and used to sleep after shifts at my uncle's. Uncle did not had internet but there were so many wlans all around. Since I had nothing to do for hours after shift, I downloaded Backtrack linux at home, made live dvd of it and saved a two articles of "how to hack wifi" to text files.
It took me 4 hours to break WEP, since I was total lame, and it was the only one WEP around. They also had mac restrictions set to router, so I changed my mac address to one of their devices, logged in to router and added our mac address. For my uncle it was complete magic but since he is total geek to linux he liked it.
Fast forward weeks later. When I came to my uncle's house he was downloading like ton of linux distributions. Literally each one. Gigabytes of data. I told him not to do so because sooner or later neighbour will notice, but he did not care. Guess what, he notices, probably slow internet and (maybe) bigger bills, I do not know, but owner just changed protocol to WPA2, not changing password. So the story continued for almost 2 years. Felt a bit sorry for neighbour but did not expect such an outcome. I just wanted to watch youtube videos and scroll social networks, keeping low profile so no one notice.1 -
This utilization shit is stupid! Seriously man what the hell! Yes yes it's an important number yes yes I don't even care. You want me to increase my utilization and at the same time be wary of the budget, which are unrealistically tight to begin with. It's freaking impossible! Who comes up with this shit?
You know what? Half of this shit ain't even my fault! A project was set for 200 hours and a guy wasted half of that trying to figure out just HOW TO CONNECT TO THE API! Like the guy only wrote 30 lines in 100 HOURS! ARE YOU FREAKING KIDDING ME! THEN YOU PASS OVER THE PROJECT TO ME AND SAY YOU HAVE ONLY 100 HOURS LEFT TO CONNECT TO THE API, GET THE DATA (WHICH BTW DOESNT EVEN EXIST), PARSE IT, AND THEN CREATE GRAPHS AND A FULLY FUNCTIONAL SOFTWARE, WITH A USER INTERFACE THAT SHOULD RUN AS AN EXECUTABLE!!!! ME? ALONE?
MAN FUCK YOU!2 -
*leaning back in the story chair*
One night, a long time ago, I was playing computer games with my closest friends through the night. We would meet for a whole weekend extended through some holiday to excessively celebrate our collaborative and competitive gaming skills. In other words we would definitely kick our asses all the time. Laughing at each other for every kill we made and game we won. Crying for every kill received and game lost. A great fun that was.
Sleep level through the first 48 hours was around 0 hours. After some fresh air I thought it would be a very good idea to sit down, taking the time to eventually change all my accounts passwords including the password safe master password. Of course I also had to generate a new key file. You can't be too serious about security these days.
One additional 48 hours, including 13 hours of sleep, some good rounds Call of Duty, Counter Strike and Crashday plus an insane Star Wars Marathon in between later...
I woke up. A tiereing but fun weekend was over again. After I got the usual cereals for breakfast I set down to work on one of my theory magic decks. I opened the browser, navigated to the Web page and opened my password manager. I type in the password as usual.
Error: incorrect password.
I retry about 20 times. Each time getting more and more terrified.
WTF? Did I change my password or what?...
Fuck.
Ffuck fuck fuck FUCKK.
I've reset and now forgotten my master password. I completely lost memory of that moment. I'm screwed.
---
Disclaimer: sure it's in my brain, but it's still data right?
I remembered the situation but until today I can't remember which password I set.
Fun fact. I also could not remember the contents of episode 6 by the time we started the movie although I'd seen the movie about 10 - 15 times up to that point. Just brain afk. -
Today during a follow-up meeting of the grand project I'm workng on...
TL: ... and I want to start working on the production environment and have it ready by next month.
Me: (interrupts) hold up! We are not ready, we have a huge backlog of technical tasks that need to be addressed and we are still not in possession of the very crucial business and functional requirements that you are supposed to provide. The acceptation environment is just set up on infra perspective but does not have anything running yet! The API we depend on is still not ready because you keep adding change tasks to it. We have a mountain of work to do to even get to a first release to integration yet and there is still the estimations on data loads and systems... your dream will not be possible until at least Q2 of 2024.
TL: stop being so negative @neatnerdprime and try to be more customer friendly. I want it by the end of the next month.
Me: remember what I said to you about moving prematurely. Remember I don't take any responsibility if things break because you rush the project. Please, reconsider!
TL: I just want it, please do it
FUCK YOU YOU SORRY EXCUSE OF A PEOPLE PERSON KNOWING JACK SHIT AND JUST LICKING THE MIDDLE MANAGEMENT ASSHOLE TO RECEIVE ATTABOY PETS ON YOUR UGLY ASS BALD HEAD AND CROOKED TEETH. YOU SHOULD FUCKING DIE IN A FURNACE AND LEAVE NO TRACE BEHIND.4 -
Have you ever use the offline mode in chrome or set the data downloading and uploading speed.
It is the great feature in chrome. In that way you easily develop your offline site. Without disconnecting your LAN or Wifi connection.
Best way to develop offline site for developers.1 -
#whenProdBreaks
$data = ["some","predefined","data","set"];
// :/ this suddenly broke
//$response = $this->makeSoapRequest($data);
/**
Due to prod failure, Hot-swap soap for rest - don't ask how we took the same input, spun the shit out of the response and recreated the same data structure that the soap request made, but it works... and that's all you will ever have to know.
**/
$response = $this->makeRestRequest($data);
//process the response
$this->process($response); -
> be me
> studying 1.5 years liberal arts stuff and general education class at community college
> transfer to a 4 year university.
> realize I need a major
> Realize I also I wanted to 9ne day have a family.
> realize family would need money
> "struggling actor" not a great choice
> pray about what I should be doing
> get distinct impression that instead of attending the session on majors at the college of fine and performance arts to go to session with the college of Science and engineering.
> hear pitch for computer science.
> signup for introduction to programming taught with c++.
> A couple semesters down the line take 3 classes all at once Discrete Math 1, Linear Algebra, and database design and administration.
> around week 6 realize that all 3 classes revolved around sets and set logic and set math.
> realize rdbs's are "applied" set math and that Each class a little more "applied" than the former.
> Be genius at SQL and set math
> havereally smart database teacher mentored me
> get introduced to the recruiter at the career fair.
> get interviews
> get flown out for 2md interview
> get internship
> do work, and get project back under budget
> a job offer
> finish senior year
> start as a "real" developer supporting business data and analytics.
> ???
> profit.3 -
This is my understanding of "Machine Learning" in general
There are two sets of data:
1. In first data set, all the properties are known
2. In the second set, some properties are not known.
The goal of the machine learning is to find the value of the unknown properties of the second data set.
We do this by finding (or training) a suitable machine learning model (mathematical, logical or any combination of), that in the first data set, computes the value of the properties, which are unknown in second data set, with minimum error since we already know the real value of those properties.
Now, use this model to predict the unknown properties from the second data set. 3
3 -
story - u get a new job, u really like the boss and work env, have been assigned a v ambitious project.. which involves v critical deploy control, data backfills and multiple level of integrations, takes 2 quarters to complete, in the mean time ur fav boss left for a better job and new boss doesn’t seems to understand the gravity of the project and thinks u r just sitting there twinkling fingers...anyways fast forward to d-day : deploys go fine everything working great... time to run some post deploy scripts for some data consistency, a single change to another piece of code done by some one else 2 days back triggers an additional logic and damn suddenly the app users loose ownership to part of the data they owned... u run history reports, do data loads to assign them back, some data errors out, u r about to manually set that up - u drop ur laptop from ur table and it refuses to restart - and all the Prep data is gone and all the scripts are gone and it’s a weekend so no IT Sypport... u r without a laptop for next 24 hours... the struggle continues... next update on Monday1
-
Oh god where do I start!?
In my current role I've had horrific experiences with management and higher ups.
The first time I knew it would be a problem: I was on a Java project that was due to go live within the month. The devs and PM on the project were all due to move on at the end. I was sitting next to the PM, and overheard him saying "we'll implement [important key feature] in hypercare"... I blew my top at him, then had my managers come and see if I was OK.
That particular project overran with me and the permanent devs having to implement the core features of the app for 6mo after everyone else had left.
I've had to be the bearer of bad news a lot.
I work now and then with the CTO, my worst with her:
We had implemented a prototype for the CEO of a sister company, he was chuffed with it. She said something like "why is it not on brand" - there was no brand, so I winged it and used a common design pattern that the CEO had suggested he would like with the sister company's colours and logo. The CTO said something like "the problem is we have wilful amateurs designing..." wilful amateurs. Having worked in web design since I was 12 I'm better than a wilful amateur, that one cut deep.
I've had loads with PMs recently, they basically go:
PM: we need this obscure set up.
Me & team: why not use common sense set up.
PM: I don't care, just do obscure set up.
The most recent was they wanted £250k infrastructure for something that was being done on an AWS TC2.small.
Also recently, and in another direction:
PM: we want this mobile app deploying to our internal MDM.
Us: we don't know what the hell it is, what is it!?
PM: it's [megacorp]'s survey filler app that adds survey results into their core cloud platform
Us: fair enough, we don't like writing form fillers, let us have a look at it.
*queue MITM plain text login, private company data being stored in plain text at /sdcard/ on android.
Us: really sorry guys, this is in no way secure.
Pm: *in a huff now because I took a dump on his doorstep*
I'll think of more when I can. -
PouchDB.
It promised full-blown CRDT functionality. So I decided to adopt it.
Disappointment number one: you have to use CouchDB, so your data model is under strict regulations now. Okay.
Disappointment number two: absolutely messed up hack required to restrict users from accessing other users’ data, otherwise you have to store all the user data in single collection. Not the most performant solution.
Disappointment number three: pagination is utter mess. Server-side timestamps are utter mess. ANY server-side logic is utter mess.
Just to set it to work, you need PouchDB itself, websocket adapter (otherwise only three simultaneous syncs), auth adapter (doesn’t work via sockets), which came out fucking large pile of bullshit at the frontend.
Disappointment number four, the final one: auth somehow works but it doesn’t set cookie. I don’t know how to get access.
GitHub user named Wohali, number one CouchDB specialist over there, doesn’t know that either.
It also doesn’t work at Incognito mode, doesn’t work at Firefox at all.
So, if you want to use PouchDB, bear that in mind:
1. CouchDB only
2. No server-side logic
3. Authorization is a mess
4. Error logs are mess too: “ERROR 83929629 broken pipe” means “out of disk space” in Erlang, the CouchDB language.
5. No hosting solutions. No backup solutions, no infrastructure around that at all. You are tied to bare metal VPS and Ansible.
6. Huge pile of bullshit at frontend. Doesn’t work at Incognito mode, doesn’t work at Firefox.8 -
Everytime you tell yourself "This time I'm going to make them stop putting the cart before the horse again!!! No more forced shit implementations!!! NO MORE ! I'm strong!!"
The last hour in the next week:
- Selinux: off
- Firewall: Any-Any
- Application data: Everything installed on OS disc.
- Documentation: At best, someone remembers the server supposed-to-be dns record
- Service Accounts: Your domain admin account and sysadmin for databases.
- Patching: DON'T EVER THINK ABOUT IT..AND NO REBOOTING! I have set very important runtime variables.
- Backup: Maybe someone else will set this up.
- Monitoring: Not needed since clients will create tickets if system fails.
- Production Status: vague at best. Sort of silently transitioned to production.
- Handover status: Probably, but I quit before the project closed.
! -
Am I crazy ?
Right now we have an API which returns a full planning for a week for 300 employees with indicators (Like "late", "may be postponed" etc) in 4 seconds.
I have a pressure, people telling me it's not fast enough.
I honestly think it is fast.
In order of data it'a around 100 MB of JSON. AND you can do actions on the whole set if needed.
Long story short, I think 4 seconds to get all that data is pretty great. Customers think they should have it instantly.
(Never mind the whole filtering system at thier disposal, they literall only lod the full set and then MANUALLY scroll (Yes there is a quick search box)).
What can I do more ????? cache that ? I can. But they also expect that any changed value is reflected.
And we fucking do it. While you are on the page there is a SignalR conenxion created and notified when any of data is changed and updates it on front. Takes around 500 ms.
Apprently "too slow".
I honestly don't see what we can do more with our small 4 dev team.
Give me 56 developpers I can do something, but right now I'm proud of result.14 -
Can we all just agree to stop actively imagining progressively harder to parse CSV formatting options? For fucks sake I’ve had to build in tolerance for quoted and unquoted data, combined data and split data, ways to split the data and recombine it, compare every data point, filter some data, only add data, only remove data, base data updates on non Boolean fields in the file, set end point matching based on arbitrary fields, column number matching, header matching, manipulate malformed urls and reassemble the file with proper ones, it goes the fuck on. CSV’s should just be simple and not hard to format. Why does everyone want to try so fucking hard to do bizarro shit?!
-
I just finished designing an entire asset management pipeline and christ on a fucking pogo stick, if it isn't convoluted.
Theres a lot of game engines out there, but all of them do it a little different. They all tackle a slightly different problem, without even realizing it.
1. asset management
2. asset change management
3. behavior change management
4. data management
5. combinatorial design management.
6. Combinatorial Behavior management
7. Feature completion
ASSET MANAGEMENT is exactly what it says on the tin.
ASSET CHANGE management can be thought of handling the import, export, formatting, platform specific packing, and versioning (including forking) of an asset.
BEHAVIORAL CHANGE management is a subset of asset management, because code is a subset of assets (depending on how you define 'assets'). The oldest known example of this is commenting and uncommenting code.
Or worse, printf debugging.
This can be file versioning, basic undo services, graph management of forks and mergers, toggles for features or modules, etc.
DATA management is about anything that doesn't fall into the other categories, everything from mission text to npc dialogues, quests, location names, item stats, the works. Anything you'd be tempted to put in a database, falls under this category. Haven't yet seen many engines offer this as an explicit built in tool as of yet, because the other problems are non-trivial as is, so this is a bit of low hanging fruit that gets handled by external tools, or loaded from formats as simple as json.
COMBINATORIAL DESIGN management is the idea of prefabbing, blueprints of broader object design using nested prototypes of existing game objects, to create more complex, reusable set pieces. Unity did this well. GM does this in part.
COMBINATORIAL BEHAVIOR management is entity-component systems, plus tooling to make it easy to add, remove, and configure components and their values on entity blueprints, also not uncommon. Both stencyl and unity do this. GM has a precursor to this in the form of configurable fields, but these fields are not based on component scripts attached to objects.
FEATURE COMPLETION is that set of gameplay mechanics or styles of design that an engine naturally makes easier to include or build in a game.
I don't think I'm aiming for all that, but I think at minimum a good engine has to do asset management, behavioral change management, prefabs, and entity-component systems with management tools for that. And ideally, asset change management.8 -
Adobe's ExtendScript toolkit is abyssmal. I find posts from 2008 referring to issues that have not changed even in CC2017. Do you think they are small issues I'm bitching about? I'll list 2. First, the toolkit only colours "var, return, for, foreach" and a bit more keywords and the strings, of course you can set up color schemes but those are limited and not colouring stuff. The second issue is auto-complete, it rarely kicks in and suggestions have 0 connection to what are you doing and are always the same. It doesn't recognize anything of what are you doing.
Probably in 2008 you had to program with the manual near you like writing assembler, now there's an improvement in 2017, they got a window named object browser or something like that that actually is a summarised portable manual that could've been easily transformed in auto-complete suggestions.
Adobe writes about this and I quote: "a complete integrated development environment". Although I will not write much scripts in it, I need to write a big one and thought about extracting that object data and putting it in a more capable javascript editor. LO and Behold what I discovered, the ExtendScript Toolkit that's supposed to edit Extended javascript and save it as jsx or jsxbin is almost completely (it has some dlls too) built using around 100 jsx files. It's the equivalent of building a js IDE to edit js.
Sorry for formatting, I'm on mobile, I tried.
-
So we’ve taken over from a project team that disbanded... read: “cut their contracts because fuck this, I can earn more working for better people”.
Me and one other guy have been tasked with saving this heap of shit.
Obviously the project guys left saying “it’s nearly done, just this one feature”. Because cut contracts are easier to deal with if “everything is almost done”.
We jump on and find that’s not the case at all... this thing, is a beast, a big old stats analysis program... so we’re like “cool, let’s see what’s going o...OH MY GOD”.
The “recalculation” function was core to this POS. The contractors had done it in C# through entity framework... it took 24 hours to run, over a reasonably small data set that was due to double every 2-5 years.
So... here’s the deal, it ran over night.... then failed. And no cunt had noticed. Entity framework “can’t commit because I’m muddled up as fuck, did you really just put the whole db in EF in memory to work with it?” Exception.
Que 6 months of me and my lead doing the job properly.
Anyway, the failure: I ended up in Hospital again with a Crohn’s flare up... about 5 months in.
Fuckall to do with all this nonsense I just wanted to tell a story. it was an interesting/fun project to fix and my lead was a legend... so happy days.
Similar story, different set of contracted devs... they’d been defining requirements with the business users using the term “Risk” which the business users knew as a group of risks.
The domain model had been written RiskGroup<>— -
-----------Jr Dev Fucked by Sr Dev RANT------
Huge data set (300X) that looks like this :
( Primary_key, group_id,100more columns) .
Dataset to be split in records of X sized files such that all primary_key(s) of same group_id has to go in same file.
Sde2 with MS from Australia, 12 years of 'experience' generates an 'algo'. 70% Test case FAILED.
I write a bin packing algo with 100% test case pass, raises pull request to MASTER in < 1 day. Same sde2 does not approve, blocking same day release.
|-_-| What the fuck |-_-| Incompetent people getting 2x my salary with <.5x my work2 -
I would like to present new super API which I have "pleasure" to work with. Documentation (very poor written in *.docx without list of contents) says that communication is json <-> json which is not entirely true. I have to post request as x-www-form with one field which contains data encoded as json.
Response is json but they set Content-Type header as text/html and Postman didn't prettify body by default...
I'm attaching screenshot as a evidence.
I can't understand why people don't use frameworks and making other lives harder :-/ 3
3 -
How many of you use the right data structures for the right situations?
As seasoned programmer and mentor Simon Allardice said: "I've met all sorts of programmers, but where the self-taught programmers fell short was knowing when to use the right data structure for the right situation. There are Arrays, ArrayLists, Sets, HashSets, singly linked Lists, doubly linked Lists, Stacks, Queues, Red-Black trees, Binary trees,.. and what the novice programmer does wrong is only use ArrayList for everything".
Most uni students don't have this problem though, for Data Structures is freshman year material. It's dry, complicated and a difficult to pass course, but it's crucial as a toolset for the programmer.
What's important is knowing what data structures are good in what situations and knowing their strengths and weaknesses. If you use an ArrayList to traverse and work with millions of records, it will be ten-fold as inefficient as using a Set. And so on, and so on.31 -
My phone just randomly started installing "instant apps" by itself even though my settings are explicitly set to not auto download update anything. It's not even visible in my installed apps to remove. After a quick search it seems like Google is forcibly rolling out a new feature. If I wasn't looking at my phone I wouldn't have known. Thanks for eating my mobile data.10
-
I just set up SSHFS so I can play my media library on my TV without moving all my data!
Basically my setup is something like this:
*Gaming PC (with a total of 10TiB - 6TiB being used for my /home) located in my office
*Home Media PC (with total of 150GB) located in my living room
Everything I have is on my 6TB HDD, and just my Videos folder is larger than the hard drive in the Home Media PC, so I decided to set up SSHFS. After about 15 minutes of reading man pages and trying different configurations, I ended up just needing "sshfs -o nonempty -o allow_other [user]@[location]:/home/$USER/Videos /home/server/Videos/"
This is so great guys; I love Linux so much!3 -
What container data structures do all of you actually use?
For me, I'd say: dynamically sized array, hashtable, and hash set. (And string if you count that.)
In the past 8 months, I've used another container type maybe once?
Meanwhile, I remember in school, we had all these classes on all these fancy data structures, I havent seen most of them since.18 -
I wanted to rant like 10 times today but was on a tight schedule (yes its fucking sunday), so here is everything:
*********
Fuck you, i dont give a shit that you need to present data tomorrow, its weekend, you cant just fucking call me to get things done asap. Im working from the code of a dead guy do you know how fucking hard it is to ask a dead person whats their code do?
*********
I really wish devrant had some kinda longboard/skateboard in the profile pic
*********
Im still not a fucking designer i can make like does-not-make-you-barf tier designs, JUST TELL ME WHAT TO FUCKING CODE JESUS
*********
whys the new rick n morty episode not out yet wtf
*********
Yo i love linux but set the fucking privileges right you dipshit, i cant exrcute my damn code on your crappy ass 2008 xeon server fuck you3 -
The coolest project I ever worked on wasn't programming per second, though it involved a bit of scripting. The company I worked for had an FTP over TLS backup solution and it was put together with glue and paperclips by a guy that hadn't the slightest idea what he was doing. In order to conform with the insurance, data had to be encrypted. I setup a raid-ed server with full disk encryption on the raid volume that fetched the key over the network at boot from another secure server. I wrote a series of scripts for provisioning users and so on. The backup connections was sftp using a ssh tunnel, the users were chrooted to their own home directories, and were unable to open shells. The system was 100x more robust and secure than the original. I set it up on short notice and received absolutely no recognition for saving the company's ass, but it was definitely a fun project.1
-
So, we (I'm the backend guy and work with a UI dev) are building this product portfolio management tool for our client and they have a set of 250 users. The team has two point of contacts for the 250 users who maintain the master data, help users with data quality, tool guidance, reporting and other stuff. So one day one of these two support users come to me and say : Hey I'm not able to add new transactions coz a customer is missing.
We have the provision to create / maintain customers.
I check the production DB, application code, try creating the customer and then the transaction, everything works perfectly fine.
I ask the user for a screen sharing session, the user starts reproducing the error like this :
We have a 3 system landscape - Dev / Test and Prod
U : Logs into the test system url, creates the customer.
U : Points out the toast saying customer creation is successful.
U : opens a new tab, opens the production system, tries creating the transaction, searches for the customer and says " see !! cant find the customer here ! the master data management apps never work !! "
FML?. -
Windows 10 Action Center yesterday alerted me to set a PIN for my laptop.
Turned on PC this morning and typed in my regular password then realized it wanted the PIN.
Thinking how this feature came to be....
1. Windows wants you to link your login to your Microsoft/Hotmail Account and it makes it a pain in the ass to set a seperate one (Windows 8)
2. 2018 arrived an logins are a pain, everything is autologin or PIN/code based (aka short 'unsecure' passwords)
3. MS backtracks and realizes email logins are too long so they make a partial fix which basically reverts back to the pre-Win8 days of a seperate system login.. except now its called a new feature!
I realized now under enter a PIN the reason for the checkbox that says: Allow symbols and letters. It's a nice way of saying: please type in your old password again.
**Also rant #2: cuz i dont feel like waiting 1hr**
I felt great yesterday when my boss told me apparantly I have like an Expert designation at the company.
Feel like crap today cuz some user is complaining about some report:
- they asked us to create months ago
- now complaining its all wrong but never gave any formal requirements and actually did sign off on it during testing
- FIXED ASAP
HELLO!!!!!!!!!!! STOP MAKING IT SOUND LIKE IT'S MY FAULT U CAN'T BE BOTHERED TO PROVIDE CLEAR REQUIREMENTS AND THEN TAKING FOREVER TO COME BACK WITH UR PROBLEMS AND NOW NEED IT FIXED ASAP BY USING A NEW DATA SOURCE THAT I HAVE NO IDEA WHAT THE FUCK IS SINCE U USED A RANDOM ABBREVIATION LIKE I CAN MIND READ.
IF I COULD MINDREAD, ID BE WORKING ON A PLAN TO GET UR ASS FIRED.....
Happy friday and long weekend... Got 3 days to relax before i need to deal with this shit again...2 -
AI here, AI there, AI everywhere.
AI-based ads
AI-based anomaly detection
AI-based chatbots
AI-based database optimization (AlloyDB)
AI-based monitoring
AI-based blowjobs
AI-based malware
AI-based antimalware
AI-based <anything>
...
But why?
It's a genuine question. Do we really need AI in all those areas? And is AI better than a static ruleset?
I'm not much into AI/ML (I'm a paranoic sceptic) but the way I understand it, the quality of AI operation correctness relies solely on the data it's
datamodel has been trained on. And if it's a rolling datamodel, i.e. if it's training (getting feedback) while it's LIVE, its correctness depends on how good the feedback is.
The way I see it, AI/ML are very good and useful in processing enormous amounts of data to establish its own "understanding" of the matter. But if the data is incorrect or the feedback is incorrect, the AI will learn it wrong and make false assumptions/claims.
So here I am, asking you, the wiser people, AI-savvy lads, to enlighten me with your wisdom and explain to me, is AI/ML really that much needed in all those areas, or is it simpler, cheaper and perhaps more reliable to do it the old-fashioned way, i.e. preprogramming a set of static rules (perhaps with dynamic thresholds) to process the data with?23 -
We take over development of a live customer facing system and PM agrees date for our first code deployment with client CIO
Me: The dev and staging environments don't have any test data currently as the old agency screwed it up
PM: Well you better load some
Me: There isn't any... It'll take 10 days to copy prod db due to hosting provider SLAs, leaving 1 week for SIT, UAT and performance testing (assuming they don't screw up)
PM: Well the date is set, 1 week will be enough for testing2 -
Why does Google FRP even exist?!
For everyone who doesn't know what FRP is: FRP (Factory Reset Protection) is a partition on an Android device that stores data about the last used Google account on the device. It "protects" the device to be used by a second person (or a thief) even AFTER a factory reset when executed via bootloader.
Last week I bought a HTC One A9 second-hand w/o any documents. I ensured it has been reset, so I took it home... I then wanted to set it up, as following message appeared on the screen: "This device has been reset. Please login using a Google account that has been synced with this device before."
I checked the IMEI for being blacklisted, but it wasn't. Unlocking the bootloader and erasing the frp partition is not an option, because on HTC devices you have to enable OEM unlocking in the settings first. Someone stated on a forum, that you can bypass the bootloader lock with a "RUU Image" (I'm not familiar with this so pls don't blame me for that statement). But since the phone has a branding from Vodafone Germany, I can't find a RUU Image that would flash the device without a CID mismatch...
Why the f*** does Google have to implement a feature that prevents to use the phone when bought from another person that you don't know?12 -
Hello.
I am a student of Computer Science Engineering (Bachelor of Technology). I am 3 years into this 4-year course. I am strong in Data structures and Algorithms, and passionate to add more stuff to this list.
I am really done with this University coursework, and want to explore more (specifically, want to do something that is practical, and matters). I, obviously cannot leave the Uni, but I want to make my time at home more productive. Not just to me, but everyone.
But:
1. I don't know where to start.
2. I teach myself everything, and hence, there is much difference between what I know and what people need, and I'm kind of scared of ruining/wasting other's time.
If there is someone out here who has the time out of his/her busy schedule to guide and set me on a path, please do help me. It's getting weird in my head.
Languages I know: C(took a 1-year course), Python, JavaScript [learning JAVA], Oracle, Visual Basic
Things I have done before:
* Developed a fullstack website for Indian Railways (going live in May 2019) [used Python for back end]
I have a sincere need from within to do this, and I am going to learn whatever more I need to, in order to fulfill your requirements. Please just show me WHAT and from WHERE.
Kindly do get back.3 -
This was more than 15 years ago. We migrated a bunch if data (home to a new server and repurposed the old one, the same night. This was not the first task on that allweekender, so it was around 3am on Sunday, with very little sleep, when I had to copy the data. I did that by logging in as admin and copying with Total Commander. Obviously, even admin did not have the permissions to some folders, so a lot of financial data were lost, as the users found out on Monday morning. We had no backup. Old server was not only reformatted, but the disks were used to build a different raid set. Luckily, one of the users who had access to this data kept a backup on a flash drive. (If you're wondering, I should've used robocopy with backup mode)
-
Open for all.
Below are 4 sets of numeric data. Each set carries two numeric strings. Each occur in a pattern and each set below are n'th terms of the pattern. Each set equals to the value 50. The value of 50 can be obtained from either the first or the second string or even both.
Find a next term or even a n'th term of the pattern.
sets -
{ 738548109958, 633449000001000435 } , { 667833743011, 65173000001000838 } , { 314763556877, 652173000001000685 } , { 332455491545 , 65216100000100411 }
You will be rewarded
You will not fail 5
5 -
The project that we spent one freaking year on, researching, developing our own hardware and software just got cancelled and I ain't getting paid shit...
https://youtu.be/Dv3eduzcZxc
This is a fucking nightmare! All this motherfucking work for nothing! I think I am going to cry... I mean we still have all the hardware and stuff but we can't do anything with it because is was build for one fucking task and noone would probably buy it because how specific the task that it's made for is. I mean I technically only own the software... anyone interested in buying an Android app that connects to a sensor (that counts stuff) via BLE, processes data from the sensor and uploads it to a database? It can also upload new firmware to the sensor, set basically any parameter and get all kinds of telemetry from it... can't really say what does this sensor count or anything about the hardware (I am not sure if I am allowed to brcause I don't own it - I only got to work on the firmware and the app)3 -
Working on an app to sync data between our ticketing system and an API a vendor made for us to interact with their ticketing system. I put off working on it for months, mostly because I had mountains of other "urgent" things that jumped in my face, but also because I needed to design the whole thing, and I really have to get into the right frame of mind for that kind of creative organization.
Today I dove into it. I built the JSON to submit, given whatever variables are necessary, and figured out after a while that the smartest way to handle this is not to search for an existing internal ticket, but to have the creation of the internal ticket set a flag for an automated sync process to check when it runs.
It's going to be much easier when I get that built, but now, knowing that, I'm daunted enough that I'm procrastinating. Think of something, chart it out with notes in a text editor, procrastinate.That is probably like 95% of the time I spend in "development." -
There's very little good use cases for mongo, change my mind.
Prototyping maybe? Rails can prototype, create/update/destroy db schemas really quickly anyways.
If you're doing a web app, there's tons of libs that let you have a store in your app, even a fake mongo on the browser.
Are the reads fast? When I need that, use with redis.
Can it be an actual replacement for an app's db? No. Safety mechanisms that relational dbs have are pretty much must haves for a production level app.
Data type checks, null checks, foreign key checks, query checks.
All this robustness, this safety is something critical to maintain the data of an app sane.
Screw ups in the app layer affecting the data are a lot less visible and don't get noticed immediately (things like this can happen with relational dbs but are a lot less likely)
Let's not even get into mutating structures. Once you pick a structure with mongo, you're pretty much set.
Redoing a structure is manual, and you better have checks afterwards.
But at the same time, this is kind of a pro for mongo, since if there's variable data, as in some fields that are not always present, you don't need to create column for them, they just go into the data.
But you can have json columns in postgres too!
Is it easier to migrate than relational dbs? yes, but docker makes everything easy also.11 -
For what fucking reason the ability to set the date and time programatically has been blocked on Android?!
Why you can create fucking invisible apps that work in the background, mine cryptos, steal your data but they decided that something like that is considered dangerous?
Can anyone give me a logical explanation?
P.S.
There are cases (big pharma companies) where the users don't have access to internet nor a ntp server is available on the local network, so the ability for an app to get the time of a sql server and set it in runtime is crucial, expecially when the user, for security reasons, can't have access to the device settings and change it by himself.
"System apps" can do it, but you would have to change the firmware of a device to sideload an external "System app" and in that case it would lose the warranty.
So, yeah, fucking Google assholes, there are cases where your dumb decisions make the others struggle every other day.
Give more power to third party developers, dumb motherfuckers.
It's not that difficult to ask the user, once, to give the SET_TIME permission.
It was possible in the past...
P.S.2
Windows Mobile 6.5 was a masterpiece for business.
It still could be, just mount better CPUs on PDAs and extend the support. But no, "Android is the future". What a fucking bad future. 10
10 -
The Zen Of Ripping Off Airtable:
(patterned after The Zen Of Python. For all those shamelessly copying airtables basic functionality)
*Columns can be *reordered* for visual priority and ease of use.
* Rows are purely presentational, and mostly for grouping and formatting.
* Data cells are objects in their own right, so they can control their own rendering, and formatting.
* Columns (as objects) are where linkages and other column specific data are stored.
* Rows (as objects) are where row specific data (full-row formatting) are stored.
* Rows are views or references *into* columns which hold references to the actual data cells
* Tables are meant for managing and structuring *small* amounts of data (less than 10k rows) per table.
* Just as you might do "=A1:A5" to reference a cell range in google or excel, you might do "opt(table1:columnN)" in a column header to create a 'type' for the cells in that column.
* An enumeration is a table with a single column, useful for doing the equivalent of airtables options and tags. You will never be able to decide if it should be stored on a specific column, on a specific table for ease of reuse, or separately where it and its brothers will visually clutter your list of tables. Take a shot if you are here.
* Typing or linking a column should be accomplishable first through a command-driven type language, held in column headers and cells as text.
* Take a shot if you somehow ended up creating any of the following: an FSM, a custom regex parser, a new programming language.
* A good structuring system gives us options or tags (multiple select), selections (single select), and many other datatypes and should be first, programmatically available through a simple command-driven language like how commands are done in datacells in excel or google sheets.
* Columns are a means to organize data cells, and set constraints and formatting on an entire range.
* Row height, can be overridden by the settings of a cell. If a cell overrides the row and column render/graphics settings, then it must be drawn last--drawing over the default grid.
* The header of a column is itself a datacell.
* Columns have no order among themselves. Order is purely presentational, and stored on the table itself.
* The last statement is because this allows us to pluck individual columns out of tables for specialized views.
*Very* fast scrolling on large datasets, with row and cell height variability is complicated. Thinking about it makes me want to drink. You should drink too before you embark on implementing it.
* Wherever possible, don't use a database.
If you're thinking about using a database, see the previous koan.
* If you use a database, expect to pick and choose among column-oriented stores, and json, while factoring for platform support, api support, whether you want your front-end users to be forced to install and setup a full database,
and if not, what file-based .so or .dll database engine is out there that also supports video, audio, images, and custom types.
* For each time you ignore one of these nuggets of wisdom, take a shot, question your sanity, quit halfway, and then write another koan about what you learned.
* If you do not have liquor on hand, for each time you would take a shot, spank yourself on the ass. For those who think this is a reward, for each time you would spank yourself on the ass, instead *don't* spank yourself on the ass.
* Take a sip if you *definitely* wildly misused terms from OOP, MVP, and spreadsheets.5 -
Wow fuck today. I took the day off to watch the eclipse yesterday so coming in today was like Monday squared. Right off the bat I have somebody from last week that I had spend around 8 hours working to get their system right call in and tell me they were cancelling even though everything just got working right.
Also got tasked with documenting the servers which wouldn’t be rant worthy if the dev that set them up didn’t get cranky whenever I ask for credentials or even a rough overview of how the server stack is configured. Then I get a ticket about how a customer is going to get his data from his ‘web guy’ but this customer has been keeping his data in our system for the better part of a decade. Wtf you getting bro? And who is this web guy? What data does he have? Nobody seems to know. And just to smear shit on top it turns out I swapped the addresses on the car parts I sold on eBay and now I have to do 2 returns and cross ship and almost definitely get negative feed back. Fuck everything.
All this before lunch. After lunch I still have the same problems but at least I got chicken!1 -
The day has come where I was asked to fix some windows issue of a coworker (not an IT guy) at home. Some data sharing issue in the homenetwork.
Ok, told him I've never set up anything like this but could take a look at it.
Got it fixed after 1-2hours and he was nice enough to pay me for my time.
I'm not even mad, that is nice :)
While I fixed stuff for a friend multiple times who is richer then me who can't take me to the next tram stop by car after a meeting since it's not on her way. Damn.3 -
*One Month Ago*
Project Manager: we have allocated these two workstations for you to extract data (set) from malicious files, they are off the network. I though would also prefer a seperate laptop for this project you can take this one (pointing towards the newish laptop on the table)
Me: (i declined his offer because i didn't wanted to carry two laptops everywhere) I'm going to use my own laptop, but I'll be using a sand box or virtual machine.
*Fast Forward to Today*
Accidentally ran a script outside the sandbox, which due to some unknown reasons ended up executing a bunch of malicious files I only realised my mistake when my antivirus started to go bonkers FML.
P.S. both of those PCs are now connected network because of me.
Fingers crossed2 -
I usually start with a MindMap where I try to write down every bit of the idea.
I then try to set requirements and set the tools/frameworks I want to use.
Next step would be data model and then git started ;)2 -
The networking group at my day job, hooooooolly crap I have some unprintable words. But keeping it professional:
* Days to turn around simple firewall whitelisting requests
* Expecting other teams to know the network layout despite not sharing that information anywhere and going out of their way to not share it
* Adding bureaucracy in the form of separate Word doc forms despite having a ticketing system - for no justifiable reason
* Breaking production systems multiple times per month
* Calling in with problems that are clearly network related, being told it’s our systems, and then the problems magically go away even though they swear they didn’t touch anything
* Outright verifiable lies or vague non-answers when they’re not talking to someone at the director level or a vendor from an outside company on conference calls
* Worse packet loss and throughput on our LAN than my home ISP
Doing anything with these clowns is my single biggest source of stress right now. I can’t wait until we get a full SDN stack set up and then we won’t have to deal with them for day-to-day needs any longer.
My boss swears it’s better that we’re not managing the network directly, but I’m pretty sure my friend’s dog could be loosed into the data center to chew on fiber, and eventually the pairs would be connected in such a way as to improve performance.1 -
promises in JavaScript have really spoiled me
it's the most optimal way to do async without leaving much on the table
there's a promises library in rust and the guy who wrote it says it sucks because it spawns new thread every time you execute a bunch of promises
and I finally, through my fogged brain, managed to get the bright idea to write what I want to make in rust in JavaScript and holy hell it's sexy to work with promises. there's no performance left on the table. you do things as fast as possible
but if I take this JavaScript usability code I made and make it possible syntax-wise in rust I don't see how I would be able to do it without starting new operating system threads every time I execute any promises (or set)
I can take the overhead hit but this sounds retarded
and this isn't even touching upon how in rust everything needs to have a predetermined data type. so you can do lambdas and capture variables and send in variables into a thread that way, but to return the return object must be a consistent type (synchronizing the order data was sent in to the data sent out aside, haven't written that yet should be fine though)
which is fine if you are making a threadpool and it'll all be returning one data type
but this means you can't reuse a threadpool you made elsewhere in the program
the only thing that could fix async is to literally be compiler-enabled. it would have to work like generics and automatically make an enum of every type that can return, and only then could you re-use the threadpool13 -
So I got the LSTM working in keras.
Working from a glorified tutorial.
Why the fuck do people let their github pages go down with no other backup?
Especially if its a link in your blog?
Why would you do that and not post the full script (instead of bits and pieces interspersed with *partial* explanations)?
In any case, its working and training on a test set and examples just to debug my own understanding of the process.
Once thats done I can generate some training data and try training on a small set. If that goes smoothly and the loss looks like it is heading in the right direction, then I'll setup the hardware for the private cloud and start writing the parallel computing component.2 -
I knew I wasn't very good at SQL, but here is a proof.
Need to make a bulk recalculation action. Basiclly precalculate some values in a separate table to speed up acess.
1 day of work : Fully SQL solution with triggers.
Execute for test : 35 minuts !! for
Me : fuck that
Today : 7 lines c# solution (Took me less than 2 hours) . Same database, saame data set : 10 seconds execution.
Well, I guewss I'll never try again fully SQL solutions lol6 -
How can Javascript, one of the MOST WIDELY used and MATURE languages with A MILLION CANCEROUS FRAMEWORKS, NOT have a basic collections class? Are data structures not important in Javascript?
I've been struggling all night trying to get Sets working - surprise, they're utterly useless in Javascript cause you can't define the set comparator.
I just lost it when I found out THERE ISN'T EVEN A QUEUE. WT-ACTUAL-F15 -
Fuck Google! I'm trying to write a fucking parential app that I can install on my little sisters phone, because I won't download something that is meant to monitor activity on a child's phone when I am capable of writing one. Problem is, I test it on my phone which has Android 10, because I am not keen on testing with a slowpoke out of wood brick that the target phone is. Android 10 does not let you do a single shit that is needed for a parential software. You try to turn on airplane mode to prevent messages from arriving and such? Well.... nope, you can't. Okay... airplane mode is too drastic. Let's try turning off WiFi and Data. Fuck me, you can't do that either. I gave the app fucking system permissions and It laughs in my face when I try to access some simple shit like... WiFi state. Miserable. I wonder if it will let me mute the fucking volume on the phone. I guess It won't, because "You shouldn't set these things on a user's phone.". Well, fuck that. That's exactly what I need. That old brick does not have built in parental settings. Jesus.13
-
Android Interview question: "what would you use to display a large set of similar data?"
1) a linearlayout
2) a spinner
3) a recyclerview
4) a listview
The "senior" applicant picked 1)
He was not even considered.10 -
I currently work in data analysis.
Yesterday one of the colleagues working in a different department came to me asking if I could fix his malfunctioning headphone set :/3 -
Fucking hashtables...I forgot that removals can screw with the probing sequence, causing later lookups to "randomly" fail after hundreds of operations and elements.
Spent 4 hours staring at 3 while loops and data sets of hundreds of key value pairs trying to figure out why one giant data set worked fine but the other failed on some lookups.2 -
Looking for ideas here...
OK, customer runs a manufacturing business. A local web developer solicits them, convinces them to let him move their website onto his system.
He then promptly disappears. No phone calls, no e-mail, no anything for 3 months by the time they called me looking to fix things.
Since we have no access to FTP or anything except the OpenCart admin, we agree to a basic rebuild of the website and a redeployment onto a SiteGround account that they control. Dev process goes smoothly, customer is happy.
Come time to launch and...naturally, the previous dev pointed the nameservers to his account, which will not allow the business to make changes because they aren't the account owner.
"We can work around this," I figure, since all we *really* need to do is change the A records, and we can leave the e-mail set up as it is (hopefully).
Well, that hopefully is kind of true—turns out instead of being set up in GoDaddy (where the domain is registered) it's set up in Gmail—and the customer doesn't know which account is the Google admin account associated with the domain. For all we know it could be the previous developer—again.
I've been able to dig up the A, MX, and TXT records, and I'm seeing references to dreamhost.com (where the nameservers are at) in the SPF data in the TXT records. Am I going to have to update these records, or will it be safe to just leave them as they are and simply update the A record as originally planned?6 -
Fuck this shit! We had bug on website when tinymce was showing broken tables and could not save them correctly. So, the first thing you think about is tinymce is fucked up and you have to either upgrade, downgrade or fix it fucking yourself. Well, I spend more than hour tryingto figure this out. Then I found out that some fucker set column length in DB where data are stored to varchar 800!!! WTF, are you fucking serious?
-
Hand over from another developer who handled our internal data pipeline. I tried to set meetings for the handover he kept canceling them. When I asked him why? He replied I'm writing a documentation so that you won't the meeting. After 3 weeks, he emailed me with an overview diagram for the data pipeline.
My reaction: Woooooooooot? You built this in 3 weeks. WTF 3
3 -
I just spent about 30h desperately trying to figure out why my Qradar API queries were not working while running in docker, but somehow worked when running locally. I was just minimally stressed because it's my bachelor thesis, which I need to turn in in 3 weeks and this basically nuked my whole planning.
So apparently docker requires you to set your own timezone, so my API queries were always querying data from an hour early, when the requested data did not exist yet....
It's 3PM and I need a drink, or maybe 101 -
when you think you're done coding and can finally start writing...
So you guys have seen my Unreal Engine adventures. I have to use a plugin for it, on top of everything, to extract some data. I've been using this plugin since ages on another pc, but now I had to set it up from scratch since this is a new project, new models, etc.
There is a new version. If I use the new one, it will break the chain which is to follow.
The old version is so legacy that the guy who wrote it does not remember how to set it up.
After hours, and tons of hacks and outcommenting stuff (there is physics involved with which I do nothing), it finally starts doing something. Finally!
Although I'm slowly loosing my sanity in the process....
Even if it now records the data, I cannot say if this is good enough or if the poses are all wonky now.
And that is my masters thesis. Submission deadline is on monday. Ha.
Ironically, since the start of this thesis, I felt like this will either make me or break me. ;D So much fun... FK2 -
>Working on code
>Shit works as intended first try, nice
>Goes to play strange bootleg Gameboy Color ROM sent by a friend
>ROM immediately fucking dies
wtf.svg
>Pop emulator's debugger
we're executing from VRAM, stack's firmly embedded in ROM
>why
>Add execution breakpoint to entrypoint of game, restart emulated system (because i'm actually using the legit bios i hacked so it allows null/corrupted games to run)
>Step through everything, everything goes well until all of a sudden we call a function and shit hits the goddamn fan
well we have the culprit
>step through subroutine
if <unused_byte_in_HRAM> != 0 then stackPointer+=32;tryAgain();else return
>***y***
>Realize this is using a bootleg Memory Bank Controller with hard-backed encryption so none of the bytes executed or read as data are the right byte
>Find emulator that'll handle the jank MBC
>read code to try and figure out how it works
if checksumExtendedLogoBlob == some_number then set MBC_Bootleg1 else if checksumExtendedLogoBlob == some_other_number then set MBC_Bootleg2 else if...
>of course
>Spend 10 minutes finding the right bootleg MBC
>code shows 8 possible tables for real bit order based on some value in the cart header
>look for code that gets this value
>not in the header
>not in ANY header in this 1000+ file emulator
>not in any related cpp files???
>get desperate
>email author
>"Delivery failed: email doesn't exist"
fuck me i guess2 -
When every related field has a god damn different way of working with the data on hand..
For example:
`tht_date` ("Y-m-d", Date) - expiration date on the product, hence, there can be multiple of the same products with a different THT
`tht_alert` ("-2 months", varchar, DateTime modify mutation string) - sending an alert when this interval is hit, and being the activator of the tht_date field (unless value is "none")
`tht_minimum` ("28", integer, quantity of days before tht_date) - to lock them from being sent out/collected.
...
How would you expect this ×not× to become a friggin' spaghetti when trying to resolve the best row ID?
These values are in the wrong spot in the first place, then they also act entirely different in relation to eachother..
I hate the person that set this up, for doing this. When is the madness going to stop...
FFS!! -
There is no system but GNU, and Linux is one of its kernels.
Sainthood in the Church of Emacs requires living a life of purity—but in the Church of Emacs, this does not require celibacy (a sigh of relief is heard). Being holy in our church means exorcizing whatever evil, proprietary operating systems have possessed computers that are under your control, or set up for your regular use; installing a holy (i.e., wholly) free operating system (GNU/Linux is a good choice); and using and installing only free software with and on the system. Note that tablets and mobile phones are computers and this vow includes them.
Join the Church of Emacs, and you too can be a saint!
People sometimes ask if St IGNUcius is wearing an old computer disk platter. That is no computer disk, that is my halo — but it was a disk platter in a former life. No information is available about what kind of computer it came from or what data was stored on it. However, you can rest assured that no non-free software is readable from it today.14 -
And here I am again, reading test cases that basically boil down to:
$testCase->foo = "bar";
$this->assertEquals($testCase, "bar");
$testCase2->foo = null;
$this->assertNull($testCase2->foo);
Why would anyone feel the need to write these kind of tests? They don't do anything. If I set up my mock a certain way, of course I will have that data, esp. if the unit under test only applies the data AS IS. (Funily enough through another component that already has the relevant dummy tests in place making these tests extra redundant and obsolete.)
You would think that one test case with dummy data suffices, yet no, there are like 30 examples that lie to you about apparent business logic cases, yet in the end the way you set up the mock decides what you will or won't get.
What's the point?6 -
Helping out a team, I was documenting some code/processes when I came across several classes that was logging a lot of, IMO, 'junk' that was unnecessary (and I knew wasn't being used in any Splunk alerts/reports)
I offer a refactoring suggestion, simplifying the data being logged, moving the duplicate code to a central location, maybe saving 10~20 lines of code. Didn't think it was a big deal because they were already actively working on the code and it was all new code (nothing deployed to production yet). Sent the suggestion to the lead developer and he responds:
Dev: "Yes, the changes looks fine, but not in scope of the project. Any out of scope work will need to be suggested at the end of the project, reviewed by the team, the project manager and approved by the vice president."
"Out of scope"? Logging data to Splunk needs a vice president's approval? WTF?
YOU PROBABLY HAVE THE PROJECT OPEN IN VISUAL STUDIO RIGHT NOW!!!
Along with the documentation the lead dev said they didn't have time to do, I send his boss and the dev team my suggested changes (before-after screen shots of the code) and offered to do the 2 minutes worth of work (again, this was new code, nothing in production and zero side affects to anything).
I even offered to create the splunk reporting/alerting against the data being logged (another item they said they would not have time to do)
About a minute later the lead dev responds..
Dev: "Those changes look good. I'll have Jake make those changes and we can test the logging when we deploy to dev on Monday. Thanks!"
Of course you will...fracking ass hat.
I'll bet my Battlestar Galactica DVD box set he was going to make the changes himself, brag to his boss how he refactored the code, saving X lines of code..blah blah blah to help *me* with documenting the logging portion. -
Disclaimer: I should know what I'm doing but I don't. 😢
I'm a very experienced full stack dev (15+ years), but I don't know the more modern JS frameworks. I'm trying to learn React and I have a little project I'd like to do.
I have database (in both SQLite form and JSON form). I'd like to read from it, parse it and run various displays in a shared hosting environment (that doesn't have node). So webpack. And either an API to get the data or a React compatible SQL component.
But dagnamit, I cannot find a tutorial or example with this kind of set up and I can't figure it out. What packages do I need and what kind of config?
I genuinely thought this would be a traditional and simple architecture but I'm obviously mistaken. And I'm about to turn in my developer card because I'm clearly a stupid twonk.
Has anyone done this? Do you know of any tutorials or examples of this kind of thing? Is there somewhere else I should ask this question? Thanks anyway...5 -
i fucking hate react and don't understand react
Is it cleaner to have useContext to pipe in override test data for storybook and write an outer context for that code only? Real production code can ignore and not set this.
Can child component onHover update parent's stateful variable to unpause the urql/graphql datafetch in parent data wrapper component. Parent pipes queried data to child component to properly display on hover that kicked process off.10 -
It's too early to be asking these questions today:
Are your DB schema changes checked into source control?
What branch are they checked into?
Why are the schema changes checked into one branch, but deployed to a completely different database?
Is my CI pipeline deploying incorrectly? Oh, you manually deployed changes.
Are your DB changes in source control an accurate reflection of what you actually put in the staging database?
Why not?
Can I just cherry-pick update my schema with your changes from the staging database?
Why is there a typo in your field name?
Oh. Why is there a typo in the customer data set? Don't they know how to spell that word?
Why is the fucking staging database schema missing three critical tables?
Is the coffee ready? I need coffee.
Why is the coffee not ready yet?
What's going on in DevRant this morning?
What project am I working on now anyway?
Did my schema update finish yet?
Yup, it finished. Crap. Where the hell do I keep those backup files?
What's the command line to restore the file again?
Why doesn't our CLI tool support automated database restores?
I can fix that. What branch name should I check the CLI tool into?
What project was I working on this morning again?1 -
The hype of Artificial Intelligence and Neutral Net gets me sick by the day.
We all know that the potential power of AI’s give stock prices a bump and bolster investor confidence. But too many companies are reluctant to address its very real limits. It has evidently become a taboo to discuss AI’s shortcomings and the limitations of machine learning, neural nets, and deep learning. However, if we want to strategically deploy these technologies in enterprises, we really need to talk about its weaknesses.
AI lacks common sense. AI may be able to recognize that within a photo, there’s a man on a horse. But it probably won’t appreciate that the figures are actually a bronze sculpture of a man on a horse, not an actual man on an actual horse.
Let's consider the lesson offered by Margaret Mitchell, a research scientist at Google. Mitchell helps develop computers that can communicate about what they see and understand. As she feeds images and data to AIs, she asks them questions about what they “see.” In one case, Mitchell fed an AI lots of input about fun things and activities. When Mitchell showed the AI an image of a koala bear, it said, “Cute creature!” But when she showed the AI a picture of a house violently burning down, the AI exclaimed, “That’s awesome!”
The AI selected this response due to the orange and red colors it scanned in the photo; these fiery tones were frequently associated with positive responses in the AI’s input data set. It’s stories like these that demonstrate AI’s inevitable gaps, blind spots, and complete lack of common sense.
AI is data-hungry and brittle. Neural nets require far too much data to match human intellects. In most cases, they require thousands or millions of examples to learn from. Worse still, each time you need to recognize a new type of item, you have to start from scratch.
Algorithmic problem-solving is also severely hampered by the quality of data it’s fed. If an AI hasn’t been explicitly told how to answer a question, it can’t reason it out. It cannot respond to an unexpected change if it hasn’t been programmed to anticipate it.
Today’s business world is filled with disruptions and events—from physical to economic to political—and these disruptions require interpretation and flexibility. Algorithms alone cannot handle that.
"AI lacks intuition". Humans use intuition to navigate the physical world. When you pivot and swing to hit a tennis ball or step off a sidewalk to cross the street, you do so without a thought—things that would require a robot so much processing power that it’s almost inconceivable that we would engineer them.
Algorithms get trapped in local optima. When assigned a task, a computer program may find solutions that are close by in the search process—known as the local optimum—but fail to find the best of all possible solutions. Finding the best global solution would require understanding context and changing context, or thinking creatively about the problem and potential solutions. Humans can do that. They can connect seemingly disparate concepts and come up with out-of-the-box thinking that solves problems in novel ways. AI cannot.
"AI can’t explain itself". AI may come up with the right answers, but even researchers who train AI systems often do not understand how an algorithm reached a specific conclusion. This is very problematic when AI is used in the context of medical diagnoses, for example, or in any environment where decisions have non-trivial consequences. What the algorithm has “learned” remains a mystery to everyone. Even if the AI is right, people will not trust its analytical output.
Artificial Intelligence offers tremendous opportunities and capabilities but it can’t see the world as we humans do. All we need do is work on its weaknesses and have them sorted out rather than have it overly hyped with make-believes and ignore its limitations in plain sight.
Ref: https://thriveglobal.com/stories/...6 -
Can we just for a moment recognize how absolutely fucked Windows update is?
I have done everything, EVERYTHING, outside of booting from a live Linux OS and permanently deleting the windows update executables. All this to stop windows from force updating and rebooting my system while it's locked.
I've killed services, schedules, edited the registry, changed group policy. I even set my wireless connection as metered. Fun fact about that, if MS deems the update to be "priority" they'll download it anyway and reboot, so fuck your data-cap.
I wouldn't have a problem with it IF they would put everything back the way it was before, but those fucking cucks can't even be bothered with doing that. But you bet your fucking sassy ass they start up all the bullshit services I disabled last update are all running.
I don't even know WHY I even try.
Doesn't matter anyway, in a few months I won't even be able to use half the tools I use on Windows for work due to licensing issues 🤷♂️
At that point I will give a big fucking finger to Windows 🖕 and use a VM for all the fucking work related bullshit.
Fuck you Microsoft, I would say it's been fun but you're a god damned disaster. I wish that I could send a message to the entire MS board on how much they have failed, but unfortunately I rather like my freedom and it's frowned upon sending rotting roadkill in the mail.15 -
I guess you could say that my speciality is cloud at scale. I’d say it chose me more than I chose it.
Looking back on it though, I think what I like about my speciality is the unique challenges it brings.
Every speciality has its own set of challenges, like tight resource limits in embedded, or client-server synchronisation in native/mobile.
The challenge of cloud at scale is throughput. Designing systems that can support 100K users making a bazillion requests a second, or a data pipeline firing events that you need to process in near real time without dropping a single one.
The real challenge of course is doing all this within a sensible budget. We have virtually infinite compute but we dont have infinite dollars to spend on it.
Its a fun problem to solve.3 -
This fucking Integration test with h2 is driving me insane as it just doesn't work for what I need it to! 😤
The setup seems correct, the sql files are "processed" according to logs. Everything seems to be set up as supposed, as AI, colleagues or internet recommend ... yet no insert statements are shown and no data is found on retrieve. No schemas or tables exist in h2 console although log says all these millions of tables are apparently created.
WTF am I doing?8 -
"Ughh, you're such a lazy person. Why don't you finish it instead of making me do everything afger I asked YOU to do it"
I am so fucking done playing family technicman for you. I copied all of your data from your old phone to yojr new one. I set up everything except personal accounts because I respect privacy. You only need to insert your damm sim card.
And don't you even try giving me that "I tried but could not do it, it's just to complicated"
I could buy the same phone, throw it at you and pay the lawyer if I would get one cent for each time you said that.1 -
I started running a Database benchmark yesterday morning, with my system configuration, expected time to complete was 36hrs(arround), so I left it and made sure no one disturbs (I stuck a note in the monitor) because it was on common system in the lab.
Then I went to my other work.
Evening ,I came to check the progress, my monitor was switched off, I thought its in power saving mode!
Fuck, I bend down and see the CPU is off!
Wtf!! Who shut it down ,even after the note.
Then I saw the electric outlet was off!
Then after wards asking ppl in the lab, they told ,the cleaning person was cleaning the switches, so yeah she could have by mistake!
* I facepalmed *
So again, I set it up with frustration!
Today morning ,I came to see the progress
FML, from no where ,
" It's in Windows automatic repair loop! "
It's been 3hrs, trying to get out of that loop without loosing the data.
1TB of data is there, took 1month to setup all the things
Fuck Microsoft for adding these kind idiotic stuff in windows.
Is there a spirit in the lab not allowing me to do benchmark? -
I once had to write a feature, which should allow the user to login and edit an appointment, which was automatically set. All the data we got, came from an incredibly unreliable API. And with incredible unreliable I mean like heisenbug-level unreliable.
The API spoke perfectly unreadable xml and was a horror to work with.
After a few weeks of me being messed with by this shit piece of an API, I finally got something which did kind of work sometimes.
Proper error handling has been added later and just before I was done, fixing all the flaws of their data management and nonsense status codes (not http status codes) which rarely correlated in at least some way with their data, our client said "scrap this, we don't want it anymore"
Many hours and effort gone, this thing worked almost perfectly. -
I am studying an online data science course in python offered by Microsoft.
The instructor uses Surface book and also has a Mac book on his desk for backup because windows.
He uses chrome all the time for his explanation to run jupyter.
The point is even they know their tech is shit but still "Windows has set your default browser to edge" - this happens
¯\_(ツ)_/⁻1 -
People are like a stable set of database artifacts blah blah
Repeat this repost that
Did anyone ever figure out why it is that trained human detection models don’t work better ?
All you’d think they’d have to do is run an animation renderer to create data representing a human figure in every conceivable position imaginable with limbs moving into positions that were within certain tolerances in different positions with different textures
I don’t personally think the full capability is being represented2 -
Few days ago PM said that all of our grids should load all the data at once and just display it, and now today he says he likes paging more. So many files to refactor :////
BTW: every grid has to be set up individually :(((1 -
Aka... How NOT to design a build system.
I must say that the winning award in that category goes without any question to SBT.
SBT is like trying to use a claymore mine to put some nails in a wall. It most likely will work somehow, but the collateral damage is extensive.
If you ask what build tool would possibly do this... It was probably SBT. Rant applies in general, but my arch nemesis is definitely SBT.
Let's start with the simplest thing: The data format you use to store.
Well. Data format. So use sth that can represent data or settings. Do *not* use a programming language, as this can neither be parsed / modified without an foreign interface or using the programming language itself...
Which is painful as fuck for automatisation, scripting and thus CI/CD.
Most important regarding the data format - keep it simple and stupid, yet precise and clean. Do not try to e.g. implement complex types - pain without gain. Plain old objects / structs, arrays, primitive types, simple as that.
No (severely) nested types, no lazy evaluation, just keep it as simple as possible. Build tools are complex enough, no need to feed the nightmare.
Data formats *must* have btw a proper encoding, looking at you Mr. XML. It should be standardized, so no crazy mfucking shit eating dev gets the idea to use whatever encoding they like.
Workflows. You know, things like
- update dependency
- compile stuff
- test run
- ...
Keep. Them. Simple.
Especially regarding settings and multiprojects.
http://lihaoyi.com/post/...
If you want to know how to absolutely never ever do it.
Again - keep. it. simple.
Make stuff configurable, allow the CLI tool used for building to pass this configuration in / allow setting of env variables. As simple as that.
Allow project settings - e.g. like repositories - to be set globally vs project wide.
Not simple are those tools who have...
- more knobs than documentation
- more layers than a wedding cake
- inheritance / merging of settings :(
- CLI and ENV have different names.
- CLI and ENV use different quoting
...
Which brings me to the CLI.
If your build tool has no CLI, it sucks. It just sucks. No discussion. It sucks, hmkay?
If your build tool has a CLI, but...
- it uses undocumented exit codes
- requires absurd or non-quoting (e.g. cannot parse quoted string)
- has unconfigurable logging
- output doesn't allow parsing
- CLI cannot be used for automatisation
It sucks, too... Again, no discussion.
Last point: Plugins and versioning.
I love plugins. And versioning.
Plugins can be a good choice to extend stuff, to scratch some specific itches.
Plugins are NOT an excuse to say: hey, we don't integrate any features or offer plugins by ourselves, go implement your own plugins for that.
That's just absurd.
(precondition: feature makes sense, like e.g. listing dependencies, checking for updates, etc - stuff that most likely anyone wants)
Versioning. Well. Here goes number one award to Node with it's broken concept of just installing multiple versions for the fuck of it.
Another award goes to tools without a locking file.
Another award goes to tools who do not support version ranges.
Yet another award goes to tools who do not support private repositories / mirrors via global configuration - makes fun bombing public mirrors to check for new versions available and getting rate limited to death.
In case someone has read so far and wonders why this rant came to be...
I've implemented a sort of on premise bot for updating dependencies for multiple build tools.
Won't be open sourced, as it is company property - but let me tell ya... Pain and pain are two different things. That was beyond pain.
That was getting your skin peeled off while being set on fire pain.
-.-5 -
Here's one for the data scientists and ML Engineers.
Someone set a literal date feature (not month, not season, but date) as a categorical feature... as a string type 🥺
I don't trust this model will perform for long2 -
So for a few months now, I've been battling w/ failed updates of Windows 11 from version 23H2 to 24H2.
Initially, the update became available around Christmas.
During the update process, the PC BSOD'ed, then failed, && ultimately reverted to its original 23H2.
Couple of months later - same thing.
A few weeks ago, the update was once again offered to me...
...same _fucking_ thing.
...OK. This time around I actually saw something that resembled a meaningful error code.
...googled it.
...stumbled upon this post:
https://learn.microsoft.com/en-us/... .
Well, I wasn't thrilled about it, but decided to try the solution, as that environment mentioned actually mirrored my own.
Yup. That was it.
It's fucking retarded how an OS can't even successfully undergo an update because of a security solution.
I'd say they should work together to solve that idiotic inconvenience.
Oh, yeah - once fully updated I have reinstalled the security solution. It's good, so apart from the OS's update failure thingy, can't really complain.
Thanks for reading.12 -
The concept of designing and building a testable application is apparently a very alien one to my colleagues.
1. The application cannot be used without gigabytes of data.
2. The application must be fully connected to all external systems at all times.
3. Convention over configuration is unheard of, so if you manage to achieve the above, it still takes hours to set up the damn thing.
Apes. -
Trying to add money to a prepaid SIM card today. Their website is a mess. Plus and minus buttons were not functioning, so my only option was to add 15 euro. Checked the console, no errors. Tried triggering the buttons jQuery, no luck. Found a data value attached to the submit button set to 15. Changed to 10, clicked submit, and BOOM, it worked! You just got engineered!
After I paid, I was curious, went back and set it to -15, and tried it again. Unfortunately, they know about backend validation. -
Ended up dong an internship for my school (not really internship, more along the lines of formal volunteering, but whatever) helping set up laptops for a statewide standardized assessment.
I made a program to log the machine's identifying info (Serial, MAC addresses, etc), renames it, joins it to the school's Active Directory, and takes notes on machines, which gets dumped into a csv file.
Made the classic rookie mistake of backing things up occasionally, but not often enough. Accidentally nuked the flash drive with the data on it, and spent a good while learning data recovery and how grep works.
Lesson Learned? Back up frequently and back up everything -
I think one of the hardest experiences as a junior is the oscillation from perceived competency to perceived incompetency.
I just spent the last 4 weeks putting together my first major UI set of components for a financial calculator. Uses Vue, Quasar, a lot of data transformation and reactive UI programming. I felt quite chuffed. Its pending merge.
Then my lead asked me to help him debug something on the flagship and legacy project; for educational purposes, not that he actually needs my help. The application is 100x the size of the one I have been working on, and monolithic. Orders of magnitude more complex.
The jump from a sense of “I might be able to do this” to “I could never do that” was almost soul destroying. Like looking back over the last ten meters you ran, realising that running is hard and you did it. Only to look ahead and realise there are easily 100 miles ahead of you.
How the fuck do you cope with that.2 -
Wonderful experience today
I'm scraping data from an old system, saving that data as json and my next step is transforming the data and pushing it to an api (thank god the new system has an api)
Now I stumbled upon an issue, I found it a bit hard to retrieve a file with the scraper library I'm using, it was also quite difficult to set specific headers to download the file I was looking for instead of navigating to the index of the website. Then I tried a built-in language function to retrieve the files that I needed during the scrape, no luck 'cause I had to login to the website first.
I didn't want to use a different library since I worked so hard and got so far.
My quick solution: Perform a get request to the website, borrow the session ID cookie and then use the built-in function's http headers functionality to retrieve the file.
Luckily this is a throwaway script so being dirty for this once is OK, it works now :) -
How do you diagnose speed issues?
I've been lumped with looking after a legacy app.
It connects to our ERP system to handle raising invoices etc. And in June is developed slowness, which we sort of fixed by making one section load later (the SQL was a horrible view in a view in a view).
We then upgraded our ERP software, and the SQL issues are resolved (had to upgrade SQL server etc at the same time) and now the legacy app is running really slowly.
I know that it is when it loops through a data set to set column values etc.
A particular project has 1900 time transactions and takes upto 2 minutes to load.
This part of the program hasn't been changed in over a year, and has only started running slowly since the upgrade.
Are there any good way I can investigate and diagnose exactly why it has suddenly started running slowly?8 -
When you're using openapi generators and stuff for generating SDK code and let "the architect" handle the data structure and nomenclature, don't you hate having to add 33 (I counted) models, most of which are just the same class with different name or one property apart from each other, serialization of which gives request body overhead 56-132x (actual calculated results depending on the model complexity) the size of actual data you want to send, just to add support for one endpoint that needs just one model that started this whole madness?
I just had to add this one top level model reference and this happened to me. Those 33 models are not including the ones I already had included in my project so they didn't have to import them again.
For the love of <your_belief_here /> and all that's holy, never ever agree on generating code based on openapi if the person responsible for that is unexperienced. It will do more harm than good, trust me.
Before we decided to go with generated SDK my compiled product was a bit over 30KB, and worked just fine, but required a bit of work on each breaking API change. Every change in the API requires now 75% of that work and the compiled package is now over 8MB (750KB of which is probably my code and actually needed dependencies).
Adding an endpoint handler before? Add url, set method and construct the body with the bare minimum accepted by the server
Now? Add 33 models (or more), run full-project find&replace and hope it will work with the method supplied by the generated code, because it's not a mature tech and it's not always guaranteed it will work. -
So, we're preforming a re-write an application. It's on an application (actual mortgage application, not 'app') that has 4 different entry points. We have the most common entry point converted to our re-written application with plans to have the next couple done over the next several weeks. Yesterday, the old version broke. It was under the impression that it could grab any row that matched the borrower and then check against a hash of that data to see if it could proceed. It can't. You can't hash data set 1 and expect it to be the same as the hash for data set 2. Not a thing. When asked, the only answer we could give right away was "We'll fix it, give us a couple of minutes" and "Sorry, bad {{appName}} is bad. We don't know root cause yet. We'll let you know when we do." Was pulled aside by my manager and told my answer was unsatisfactory and I shouldn't give answers like that. I get it, "Bad {{appName}} is bad" isn't great, but it's not like we were going to give that and leave it! We needed some time!2
-
Worst experience: Learning how data is stored in segments in a middleware application called PMS on mainframe and how to manipulate that data.
Best Experience: Building a app that lets you pull down any set of segment data from mainframe and figuring out a way to automatically annotate the data so you could just hover over it and you know what the data is exactly. This way I didn't have to constantly refer back to a reference manual to see what a field name is in a segment, or having to go talk to a mainframe developer to go look at their code. Btw, did I mention I made it searchable by field name?? -
I was wondering if anybody working for a larger Company in 3rd-Level faces the same personal problems as me?
We got alot of our own developed software and process. Regulary some Keyuser fucks something up by importing something wrong, which skews the master data. Its intended to be managed by the Keyuser.
Fast Forward, my Keyusers are so dumb, that they fuck up the master data import wrongfully. The process behind that then have wrong Data to operate (a numeric value neeeds to be set).
The Enduser then opens a Ticket for problem XYZ. Then the Keyuser forwards us the issue.
We already had that same issue X amount of times and its always the same reply. I made a FAQ, Knowledgebase entry, etc.
Nothing works, 2 weeks pass and a similiar tickets comes in...
Memory Capacity of the User exceeded after 1 Day. FML
Anybody facing the same shit?6 -
OK I need some help. I need to make sure I’m not losing my mind.
We are using an ERP which is hosted by another company. We are supposed to be able to access the data via a REST API. This works fine using Insomnia or Postman, but when I attempt to hit the API from my web application, CORS blocks the localhost origin.
I contacted the company’s technical team to request that they change the CORS configuration to allow localhost. They keep running me around in circles telling me that I don’t know what I’m talking about because localhost isn’t a DNS resolvable name and I’m doing something wrong and they don’t need to change any configuration.
They insist that if anything would need white listed, it would be my IP, not localhost.
I sent them screenshots and stack overflow posts and documentation links, showing them exactly what headers need to be set and where the configuration needs to be set in the ERP. They tell me I don’t know what I’m talking about.
They tell me that if I can hit the API from Postman, I can hit it from my browser.
Am I losing my mind? Have I fundamentally misunderstood CORS all these years? I’m sure I’m right. But I’m starting to feel like I’m crazy.19 -
I swear excel is fucking with me.
Use a formula to generate an array, all good.
Use same formula but passed into vba function, different set of data.
All of the ranges are hard set with $, if I use the formula in another cell the results are correct.
I hate Microsoft and my workplace for making me use this shit. -
Microsoft Windows can burn.
I have this feature where I configure a remote API via some endpoints and the API pushes data back to some webhooks in my API.
Yesterday I set everything up for the final test; fired up my own API with some test data, added some configuration and started trace logging to ensure that everything works as expected when the remote site tries to send me data.
I was ready to collect ! Enter this morning: Windows have forcibly rebooted to install an update and shut everything down.
inb4 install Linux; No, I can not. Windows is company policy and I am required to use shit that is only designed for Windows.6 -
Thoughts after a security conference.
The private sector, no matter the size, often plays a role (e.g. entry vector, DDoS load generating botnet, etc.) in massive, sometimes country-wide attacks. Shouldn't that make private businesses' CyberSec a matter of national security? Shouldn't the government create and enforce a security framework for private businesses to implement in their IT systems? IMO that'd also enforce standardised data security and force all the companies treat ITSec with at least minimal care (where "minimal" is set by the gov)
What are your thoughts?9 -
Executed chown -R www-data:www-data /var/www on my server without even thinking.
Not long after I panicked for a few seconds while checking if everything was still working. I didn't know if this command would break stuff or not.
So glad all websites are still working.
Now I'm sitting here thinking: was I braindead while executing the command??
All I wanted to do was set the right permissions for certain folders because images couldn't be uploaded with PHP.6 -
Just learned something about the ever infamous Tipper's self referential formula. Apparently, it isn't a self referential formula, it's a formula for turning a set of data into a grid. It simply tells a computer whether or not to draw a pixel based on a set of data. That's it. Not really anything special :/1
-
Going to set up my own mozilla auth + data + sync server for Firefox... Amount of dependencies is fucking huge...3
-
I'm so damn tired of being asked to set up "QC's" to check for data our client is supposed to be sending and alert them when it's considered "past due". Our customers pay us to manage and analyze the data they send us. If they don't send us data, that's their problem. Why all of a sudden is it my job to micromanage these people and remind them how/when to do their job?? I'm having enough trouble juggling all of the shit on our side of customer requests, but now I have to worry about making sure they handle the shit they are responsible for on their side?
Otherwise, if we don't remind them, then they yell at us like we dropped the ball. "Why didn't you tell us we didn't send you that data that we told you we were going to send!?"
But seriously. I get it. It's good customer service. And I'd rather someone alert me if I had a process break that was supposed to be sending data on a regular basis and I didn't realize it wasn't working how I intended. I get it. I'm just venting. I'm honestly more worked up about my ever growing backlog that I am never going to get caught up with at this rate. -
Docuware, oh Docuware.
Meant to be an archiving system, but the moment work flows were seen by our director the ball just went out of the court in terms of implementation.
We've gotten to a point where we don't want to use Asana for ticket tracking and task assignment, we don't want to use a tool that acts as a man in the middle to push information to dbs, we want to use workflows with set conditions to automate every single process in the company. Why? It's cheaper.
The syntax is alrightish for arithmetic expressions, but there are so many limitations that we've gotten to the point where we're absolutely circumventing the entire point of the software.
Initialise variables, Condition, condition, condition, draw data from external sheet, process based thereof.
"oh, why doesn't it display images on the populated forms? I don't want it just as an attachment I need to click next to see".
Frustration is paramount, but the light is at the end of the tunnel.
"Oh, did I mention that we need digital signitures?" you need an additional module Mr boss. "no, I bought the cloud bundle. Make it work".
Powerful tool, I'll give it that, but it's downfall is its lack of being comprehensive.
Month 3, here we go. 4
4 -
jinja templates make me look towards html in a whole new light. are we 'inserting' data to an already rendered page? am i really mixing server code with ui ? It doesn't feel so. there are if else and loops being executed for html code, like wtf?
I don't know but everything feels so good. like i was literally hating every piece of website i was writing in php. everytime i wrote <div>....</div> followed by <?php ... ?> followed by another html tag /php tag in a fuckin php file, i wanted to kill someone from w3c.
WHY THE FUCK ARE WE ALLOWING THE MIXUP ?WHY IS PHP FILE HOLDING HTM TAGS? WHY?WHY?WHY?
But this... this is beauty. their is separation of concerns. jinja has some big powers, we can loop, repeat, make clauses, inherit other html classes, load html content into blocks, set variables,
but main concepts like file handling, response/request handling,calculations,etc are all being done in separate python files. I know that these jinja templates also might be running python in background, but atleast a developer cannot fuck up that code.
we can be sure that if correct jinja codes are written in html, then it would load correctly. And wherever devs doesn't fuck up, the output is better to understand and more maintainable/scaleable3 -
Just spent 3 hours on a bs problem
I just start acceptance testing a node.js api.
I'm using frisby
I have logged the export method return data and it is correct
I am loading it into the set header function as the accept-type
On frisby side I run the test and it spits out that there is no accept-type
I really don't get why anymore. Came so close to a blind fury. -
Attempting to find usable data.
PM: but we have data.
Me: we have data bags. But data in there is not uniform, the time series have different lengths, and some fields are missing cuz ROS does magic. Plus, that new data type you've introduced, doesn't actually have a set in stone schema so it's free for all. You literally do not have enough data for one decent quick study.
PM: but we have vision data.
Me: ... But we're not a vision department. where's the robot data.
PM: idk. Go ask others.
Me: *drags own hair out* 💀6 -
Anyone tried converting speech waveforms to some type of image and then using those as training data for a stable diffusion model?
Hypothetically it should generate "ultrarealistic" waveforms for phonemes, for any given style of voice. The training labels are naturally the words or phonemes themselves, in text format (well, embedding vectors fwiw)
After that it's a matter of testing text-to-image, which should generate the relevant phonemes as images of waveforms (or your given visual representation, however you choose to pack it)
I would have tried this myself but I only have 3gb vram.
Even rudimentary voice generation that produces recognizable words from text input, would be interesting to see implemented and maybe a first for SD.
In other news:
Implementing SQL for an identity explorer. Basically the system generates sets of values for given known identities, and stores the formulas as strings, along with the values.
For any given value test set we can then cross reference to look up equivalent identities. And then we can test if these same identities hold for other test sets of actual variable values. If not, the identity string cam be removed, or gophered elsewhere in the database for further exploration and experimentation.
I'm hoping by doing this, I can somewhat automate the process of finding identities, instead of relying on logs and using the OS built-in text search for test value (which I can then look up in the files that show up, and cross reference the logged equations that produced those values), which I use to find new identities.
I was even considering processing the logs of equations and identities as some form of training data perhaps for a ML system that generates plausible new identities but that's a little outside my reach I think.
Finally, now that I know the new modular function converts semiprimes into numbers with larger factor trees, I'm thinking of writing a visual browser that maps the connections from factor tree to factor tree, making them expandable and collapsible, andallowong adjusting the formula and regenerating trees on the fly.6 -
We had an issue where a query to a db replica set was returning duplicates randomly when paging. Aka each HTTP call for next N results was hitting different dbs with same/copy data.
No one could figure out why... I look at the query and ask where's the ORDER BY ID?
These guys were interviewing ppl last week and saying how even they could solve algo questions they were asking candidates.
And so to explain the problem, I'm like "tell me what's the difference between a list and a sorted list?"
#why algo questions suck at predicting job performance3 -
So I'm in a situation where I have to send a big set of data (from a numerous set of profile), but I can't because the framework used has been thought for sending few data (from an only profile) and then get a timeout.
I should take it as a challenge, a hard one but a challenge. Gonna be funny (and tiring too I guess)1 -
Just got my first technical interview for a summer internship! Now it's time to brush up on data structures and I'll be set :D1
-
Fuuuuuuuck!!
CR estimates:
Part 1: 2h including testing
Part 2: 2h-2days-maybe never (small changes on horrifically fucked up project noone understands with tons of tech debt)
Managed to pull off the part two in one day.. //yay me?!
Additional day to unfuckup git fuckups (including but not limited to master head not compiling because a smartass included *.cs in .gitignore file which he also pushed..don't ask, I have no clue why..) which was a huuuge deal for me as I usually use only local repo and had no idea how to tackle this.. coworker helped out.. seems I was on the right way, but git push branchy was acting up & said I had to login & ofc I had no clue what the pass was set to (first setup was more than 2yrs ago)..so new key, new pass.. all good.. yay!
Back to the original story/rant: Now I'm stuck with writing jira explanation why it was done this way & not the way customer suggested. They offered only vague description anyways which would require me to do a hacky messy thing, ew.. + it most probably would require major data modifications after deployment to even make it work..
Anyhow, this expanation is also easy peasy in english..
BUT...
I must write it in my native tongue.. o.O FML! Spent almost 40mins on one paragraph..
Sooo.. if anyone will petition to ban non english in IT, I'm all for it!!2 -
WHY DOES EVERYTHING BREAK WHEN I WANT TO DEPLOY?
Finally fixed the last few bugs on my project and the thing is pretty much set to go. Then both the production and my local copy (identical in every way except for connecting to different MySQL servers) have the EXACT same query issues. The cursor fetch methods ALL get nothing EVEN WHEN I CAN SEE THE CURSOR HAS THE DATA I REQUESTED in the debugger.
I'm already in hot water for taking longer than expected with this project and this is going to push it back even further. -
Fuck this shit. Any socket connection on JIO's fucking network gets dropped after 5 seconds if no data is sent. It's working on any other network. Wtf is going on???
Does anyone have any idea on this?
If someone has jio network please go to https://www.websocket.org/echo.html
And connect and check how long until it gets disconnected. Would be greatful if someone can validate this.
The project I am working on uses websockets extensively and this thing is screwing it up. I have temporarily set websocket ping interval to 3 seconds but what if the f**ckers over at JIO decide to start dropping connections every 1 second?7 -
So i was trying to learn php from a udemy course. The guy there mixes a hell lot of php with html, like all the pages are .php with html content and mini <?php ... ?> Scripts in between everywhere: titles, swl queries running and displaying outputs as html with echo php variables, etc..
Now am not much versed with client server data model, but isn't there supposed to be clear distinction between the server side and the client side? He puts a form there using echo "html string" , rrcieves the form input in the string's action , runs an sql query and generates another set of html strings. All in one file.
Is it how major php websites work? On the other hand My web dev friend om who works a lot with js usually runs 2 seperate aws instances for frontend and backend and makes them communicate via apis9 -
In legacyCode, somebody mixed jQuery data-toggle with custom JS triggers that toggle the target's DOM node, and to "fix" the mess, set display: block !important.
Took me too long to remember that Firefox dev tools show JS events (while my Chrome dev tools don't - why?) now I'm on the right track towards a solution...4 -
So I have some OPC server to pass a lot of data to another app. And this developer is telling me that a "delete" event for a tag is not arriving into that app. So few emails flow back and forth between us, me trying to explain where that bastard event goes, he insisting nothing sort of arrives on his side and it's my server's fault. Until a meeting is set with my manager and his.
Dev: so I have no actual data from your server.
Me: can you seek, please, within your code if struct X is passed on from the server?
Dev: yeah, it appears a lot of times but I haven't seen any instance with your delete event.
Me: ok then, is it any place where you implement the main interface of the OPC client? There is a method in it where all the events are sent. You can put a breakpoint and I cand send you only this event.
Dev: hmmm, I'm looking for it.
[after couple of minutes]
His manager: Dev, did you find that class?
Dev: hmmm, I'm don't know...
His manager: can you add that breakpoint?
Dev: it's not necessary, I can fix it the "delete". -
Daughters fancy new insulin pump:
Rant 1 - works with Safari and IE, no Chrome support - that takes some skills
Rant 2 - Wife's laptop is Windows 10 - sync website identifies the operating system as "Windows NT" (unless a typo and they meant Windows TeN)
Rant 3 - syncing data - "next" button wants you to re-set up the device (from scratch) - "finish" button (on the same screen) actually syncs the data - did they do an UX training?1 -
It really annoys me that many tech recruiters do not have a basic knowledge of the roles they are trying to recruit for and what skill set to look for when they cold message/call potential candidates on LinkedIn.
I make it very clear on my profile that I am a Full Stack Engineer. Still, every other day I get messages about Data Engineering, Frontend Dev or SRE roles. Sometimes a recruiter would insist that I schedule a call with them before they tell me the details, and then I would realize after the call what an absolute waste of time it was.
I have a lot of respect for recruiters. It's not an easy job. But I'm starting to strongly believe that tech recruiters should be made to go through a specialized training to make life easy for themselves and to stop wasting time of people who are not even remotely suitable for their requirements. -
No one's made a MIDI player that pages out the MIDI into individual data chunks (which are how the file format is set up) and the Black MIDI community will never be the same once I drop my WIP paging player3
-
I just look at a layout like this and see a relational database. Because minus random markers, there is a defined set of relationships some of which can be inferred or taken from OTHER data like.
"Joe travels at 8 am +/- 1 hr 99% of the time, every day of the work week for the last 52 weeks, likely joe is commuting to this location"
or you could just add a schedule table and one item could be marked commute vs a log table of data that is actually happening.
With everything else I see the same things.
I also see a possibility for graph edges and the likej to get out of control really quickly when you start adding event data into it.
so what is the use of graph and whats its really offering ?
any data worthwhile is likely going to have some kind of structure, even if you add ad hoc fields that don't exist, after enough additions those fields should be standardized ! 28
28 -
What the hell am I!? I wonder if you guys can help me...
I've been programming most of my life but I've never actually been a developer by title or job role. I thought maybe if I list what I do and have done someone here could help? I'm sure there are more of you in a similar boat.
- C# and VB dev for some quick DBMS projects to help me understand and mine databases and create a nice simple view for project teams to show findings from the data to help make certain decisions.
- Automating a lot of my colleagues work with Python and if very restricted then just VBA macros in Excel and MSP. This did also include creating tools to gather data during workshops and converting the data for input into other systems.
- Brought Linux to the office with most team members now moving over to Linux with the peace of mind to know that though they do need to try solve their own problems, I can help if need be.
- Had to learn AWS and then implement an autoscaling and load balanced data center installation of a few Atlassian toolsets.
- Creating the architecture diagrams documentation needed for things like the above point.
- Having said that, also have ended up setting up all the Jira/Confluence etc. servers we use and have implemented so far whether cloud (Azure/AWS) or on prem and set up scripts to automate where possible.
- Implemented an automated workflow view in SharePoint based on SP list data and though in an ASPX page, primarily built in JS.
- Building test systems in PHP/JS with Laravel and Angular to help manage integration between systems. Having quite a time right looking into how to build middleware to connect between SOAP and REST API's, the trouble caused more by the systems and their reliance on frameworks we're trying to cut out of the picture.
- Working on BI and MI and training a team to help on the report creation so that I can do the fun creative stuff and then set them to work on the detail :)
Actually it seems safe to say that it seems that though I've finally moved into a dev office (beforehand being the only developer around) I seem to be the one they go to when a strategic solution is needed ASAP and the normal processes can't be followed (fun for someone with a CompSci degree and a number of project management courses under the belt... though I honestly do enjoy the challenges)
But I always end up Jack of all but master of, well hopefully some at least. let's not even get started on the tech related hobbies from circuit design and IoT to Andoid / iOS and game dev and enjoying a bit of pen testing to make sure we're all safe at work and at home.
As much as I don't like boxes, I'm interested to know if there is in fact a box for me? By the way, the above is just a snapshot of my last two years minus the project management work...2 -
I starting developing my skills to a pro level from 1 year and half from now. My skillset is focused on Backend Development + Data Science(Specially Deep Learning), some sort of Machine Learning Engineer. I fill my github with personal projects the last 5 months, and im currently working on a very exciting project that involves all of my skills, its about Developing and deploy a Deep Learning Model for Image Deblurring.
I started to look for work two months to now. I applied to dozens of jobs at startups, no response. I changed my strategy a bit, focusing on early stage startups that dont have infinite money for pay all that senior devs, nothing, not even that startups wish to have me in their teams. I even applied to 2 or 3 and claim to do the job for little payment, arguing im not going for money but experience, nothing. I never got a reply back, not an interview, the few that reach back(like 3, from 3 or 4 dozen of startups), was just for say their are not interested on me.
This is frustrating, what i do on my days is just push forward my personal projects without rest. I will be broke in a few months from now if i dont get a job, im still young, i have 21 years, but i dont have economic support from parents anymore(they are already broke). Truly dont know what to do. Currently my brother is helping me with the money, but he will broke in few months as i say.
The worst of all this case is that i feel capable of get things done, i have skills and i trust in myself. This is not about me having doubts about my skills, but about startups that dont care, they are not interested in me, and the other worst thing is that my profile is in high demand, at least on startups, they always seek for backend devs with Machine Learning knowledge. Im nothing for them, i only want to land that first job, but seems to be impossible.
For add to this situation, im from south america, Venezuela, and im only able to get a remote job, because in my country basically has no Tech Industry, just Agencies everywhere underpaying devs, that as extent, dont care about my profile too!!! this is ridiculous, not even that almost dead Agencies that contract devs for very little payment in my country are interested in me! As extra, my economic situation dont allows me to reallocate, i simple cant afford that. planning to do it, but after land some job for a few months. Anyways coronavirus seems to finally set remote work as the default, maybe this is not a huge factor right now.
I try to find job as freelancer, i check the freelancer sites(Freelancer, Guru and so on) every week more or less, but at least from what i see, there is no Backend-Only gigs for Python Devs, They always ask for Fullstack developers, and Machine Learning gigs i dont even mention them.
Maybe im missing something obvious, but feel incredible that someone that has skills is not capable of land even a freelancer job. Maybe im blind, or maybe im asking too much(I feel the latter is not the case). Or maybe im overestimating my self? i think around that time to time, but is not possible, i have knowledge of Rest/GraphQL APIs Development using frameworks like Flask or DJango(But i like Flask more than DJango, i feel awesome with its microframework approach). Familiarized with containerization and Docker. I can mention knowledge about SQL and DBs(PostgreSQL), ORMs(SQLAlchemy), Open Auth, CI/CD, Unit Testing, Git, Soft DevOps Skills, Design Patterns like MVC or MTV, Serverless Environments, Deep Learning Solutions, end to end: Data Gathering, Preprocessing, Data Analysis, Model Architecture Design, Training and Finetunning. Im familiarized with SotA techniques widely used now days, GANs, Transformers, Residual Networks, U-Nets, Sequence Data, Image Data or high Dimensional Data, Data Augmentation, Regularization, Dropout, All kind of loss functions and Non Linear functions. My toolset is based around Python, with Tensorflow as the main framework, supported by other libraries like pandas, numpy and other Data Science oriented utils.
I know lot of stuff, is not that enough for get a Junior Level underpaid job? truly dont get it, what is required for get a job? not even enough for get an interview?
I have some dev friends and everyone seems to be able to land jobs, why im not landing even an interview?
I will keep pushing my Dev career, is that or starve to death. But i will love to read your suggestions! how i can approach this?
i will leave here my relevant social presence:
https://linkedin.com/in/...
https://github.com/ElPapi42
Thanks in advance!9 -
I got one problem I have some data in local storage. Now i have set iframe with another website. I need to pass local data into form inside iframe. but it gives me Cross Site permission issue. Any suggestions.?5
-
I guess I'll just die.
Using unity for a commission project:
Have a CCG-like setup, the cards inherit from Scriptable object, need to serialize a card inventory for the sake of persistence.
Attempt 1: XML serialization: get fucked, can't serialize dictionaries (what the hell)
Attempt 2: using data representation of the dictionary contents: get fucked, can't serialize Scriptable objects because they have to be handled by the engine...
Well okay, what if I use a Scriptable object to keep a persistent dictionary?
Attempt 3: Scriptable object with dictionary: get fucked, the dictionary didn't persist
Well now I'm starting to lose it, I've tried so many things, XML, Binary and JSon serialization, Scriptable objects, data representations, I'm really running out of ideas. I can only think of one more option: throw the Card objects into a Resources folder, an build a set of comma delimited strings to serialize. This is stupid.
Fuck Unity. Shit like this is why I'm making my own engine. Every week I find some new peeve, some new way that unity is full of redundancy and poor design, architectural flaws and workflow deficiencies. I don't know how much more of this I can take.2 -
The bug: Some string values for an identifier property in the data objects are being sent from our frontend prefixed with a '0'. Sometimes. When it happens, it usually gets stripped away again by the time it's passed to our backend. But not always.
This 0 is never explicitly set anywhere. I even searched for a few variants of " = 0" in both the frontend and backend projects without receiving any results. You might already be suspecting where this is going.
So it turns out.
The data object which holds this value is being initialized in the aspnet (don't ask) backend and passed to the frontend, which then hydrates it. This value is always an integer number, albeit incidentally so which is why string is used as the actual type. When this object is initialized, it's hardcoded with an anonymous type where this property is set as int because I guess someone figured "it's always an int though". Being a typed language, primitive scalars can't be null objects which means the property's value becomes the concrete int 0.
Okay weird. I can think of better ways of doing this but let's just set it to string as I can't start overhauling things right now. Let's just go find where this value is somehow concatenated into the incoming parameter.
You see, this happens because at the point where the frontend sets this value, it may be an int or string depending on where it came from, and I guess someone figured that in order to cast it to string you just go prop += arg seeing as the prop is empty string and all. Because explicitly casting it or - as much as I get a rash whenever I see it - going prop = "" + arg would be too verbose and unoriginal.
Bonus round: How come the 0 only sometimes made it all the way to our backend? The thing is that this bug has been fixed before. The fix is that because this string is "always" an int, you can parse it to int before passing it to the backend in case it has leading zeroes. This path is only taken in certain views because someone forgot to copypaste their fix into all the places this is repeated.
Sometimes you find a bug and you are just somehow more grumpy after fixing it.1 -
One of those debugging days where minutes feel like hours, and hours like days.
I had the bad luck of being asked to dive into a legacy project which was unmaintained for months, but of course it's still on prod. And very suddenly the urgent need arrises to change stuff.
Yet: the docker stack won't work. It builds fine but the stack crashes.
Long story short: some internal api URI were renamed and at some point one internal api started to always require an access token. Which we set for the stage, prod env yet somebody forgot to mention that to the devs of legacy-project.
That ain't too bad.
WHAT IS FUCKING BAD IS THAT YOUR SHITTY APP SWALLOWS THE ERROR MESSAGE!
I mean it's bad enough I have to `var_dump && die` your app since you never bothered to setup a xdebug that I could use out of the box, yet egregious fact that your app would catch a valid exception but transforms it into an "internal warning" is borderline insane!
It's ok to throw exceptions. It's ok to let your service die. That's how other will know what and where to fix it. (You may want to restrict the data visible to the outside, but that's a whole different conversation.) -
Ok just wanna share things that got me stuck for hours on my recent project and their solution. I hope it’s gonna help someone.
To start with, when I was implementing svg to png, i set an image object’s source with a data url. Normally this is going to trigger the onload hook. However for some fucked up reason it never triggered. The solution is to use setAttribute function and then the hook will be triggered.
Second, you can get rounded triangle by setting stroke width and set stroke linejoin and line cap as round. But remember, if stroke width is 6, then it’s 3 inside and 3 outside.
Third, if you have a rotation of svg element, and later on you want to manually compute the rotated point’s position, it’s most likely some vanilla code is not going to work. You see, when you rotate for x degree, it is actually rotating -x degree. I’m not sure if it’s a bug of my code, but it’s there.
And now the worst thing: if you look up how transform on svg is performed, stackoverflow is going to tell you it’s by order. But that’s somehow not true for my project. If I do set transform to do translation then rotation, the order it was applied is actually reversed. It’s rotation first then translation, like ffs why? Who the fuck said it was in order? It’s clearly in reverse fucking order.
Ok last thing, you can scale svg around it’s center, but absolutely don’t do that because it’s gonna fuck up tanslation and rotation applied to this svg. If you need to scale, translate it first then scale it will be better.
Anyway just some things i encountered. I’m gonna stay away from svg for at least two months now1 -
Date pickers!
After several decades of web development and even longer time to experiment with electronic UI on other devices, why is there no consistent best practice and everyone tries reinventing the weel to choose their own set of problems and annoyances?
The root cause, obviously, is using Gregorian calendar and localized display and input format in the first place, so there is no way to make a data unambiguous without a graphical calendar. Who even came up with any of those 9/10/11 formats and why?
So we need to use date pickers and make the users spend several minutes clicking, swiping or scrolling to enter their birthday - past at least one decade - and a booking date - in the near future - using the same interface with the same presets.
But users compare different offers, so they will use different sites, so they will have to handle different date pickers on different sites in a short period of time and carry unnecessary mental load.10 -
What is your method of dealing with states in state machines? In programming, we often come across situations where we have to model states in our head as to not get the programming wrong, e.g. in my case right now:
You have a tabular webform that gets filled in.
Requirements:
- When the user is able to search the data for a specific value, it should be a cumulative search (e.g.: search for books with "eng" in the language and then with with "19" in the publishing date)
And so the current pseudocode is:
search(e) {
if(!word) {
set(previousState);
}
const searchdata = previousState.filter((row) => row.indexOf(word) != -1);
// but wait, what if I say: searchdata = searchdata.filter() for cumulative search? Oops, I can't, because it doesn't exist at that moment yet. What if I create another variable?
setState(data: searchdata);
}
Current bug:
- when deleting characters from the search field, it doesn't filter cumulatively; it just filters the data according to the current filter.
It's things like these that get me stuck sometimes.12 -
What are exemples of underused data types that you wish we used more often?
Using Set or Map or WeakMap instead of the normal Object+handmade dirty functions (JavaScript), for exemples?1 -
OK, so I've been working on processing a Japanese dictionary file and things are going smoothly for the most part. Out of ~185,000 entries, I've got 35 that are still causing problems.
The error I'm getting is "Incorrect string value '\xF0\xA4\xAD\xAF' for column...". I've checked all of my encoding and collation settings, and I'm pretty sure I've got it set to properly implement all of Unicode (as well as it does, anyway), as shown in the image attached. My suspicion is the problem characters are likely among the JIS X 0213 character set; in either case we're clearly dealing with a 4-byte character encoding issue here.
If needed I can attach a flag in the database and base64 encode these particular entries so the data isn't lost, but I'd like to just get it to handle the data properly in the first place if possible.
Anyone have any ideas on other items I can check to resolve the error? 10
10 -
Another part of messy network gone.
Caching fucked me hard....
Isn't it just lovely that nowadays you need to nearly wipe a machine to get it from claiming stale data....
And thanks to DNS, HAProxy -/ service names / ... I think I know now why the curse of babel is so powerful.
When you have to think for 2 mins to make sure you've set the zone's right, cause otherwise you need to ProxyJump with SSH through more tunnels than imaginable (VPN/HO) to fix possible caching on several DNS servers.... You'll realize that it's russian roulette with too much bullets. :(
And If a monitoring service asks another monitoring service for status information which asks the first monitoring service which then asks the second monitoring cause you were too late...
You'll get very funky monitoring statistics.
Too slow, had to nuke it (mismatched a DNS name, the second monitoring service should have been a service node).
I think I've had more near death scenarios in the last 2 weeks than I like.
Hopefully I'll never have to do that again.
(Splitting and reordering a few dozen VLANs, assigning proper DNS names, loadbalancer migration....) -
How does Spring Boot/Data create a MongoClient/Template Bean to a **remote** database that requires password, certs, other configs?
These would be set in application properties but how does it get translated to the Beans?
I went through a lot of examples is like @Autowired MongoClient client
And then they just use it.
And I'm like wtf?7 -
What do you do if you are untrained in thinking logically and you currently are naturally bad at thinking logically?
Lacking this skill brings many problems: bad at understanding logical models, data structures, databases, collections of data, solving bugs, etc. Pretty much all the real work in Software Development. I heard the solution is mathematics, e.g. approximation theory, graph theory, set theory, etc, that would help you get a better vision and grasp on these things.
Has anyone been in this situation? Everyone around you knows by nature how to 'see' solutions to problems in their head, but you on the other hand, don't.10 -
So, the PowerQuery type system appears to be a Joke.
For those you that aren't familiar with PowerQuery, it's the ETL language that is used in PowerBI, and some other parts of the MS PowerPlatform. It was formerly known as the M Language.
The language has a type system, that includes records (think hashes) and tables, which are, for practical purposes, a list of records.
The wonderful M language specification document states that:
"Any value that is a record conforms to the intrinsic type record, which does not place any restrictions on the field names or values within a record value. A record-type value is used to restrict the set of valid names as well as the types of values that are permitted to be associated with those names."
Except that the restriction is only to the set of valid names, and the language interpreter doesn't throw an error when I place a number into a text field, but also doesn't do any sort of implicit conversion. This is all hunky-dory, until you then try to load the data into the Tabular Model that underlies the query engine, which does expect the values to be of the type that is specified, and it throws an error.
But PowerBI, in its infinite wisdom, doesn't actually *record* the error, it merely tells you the error exists, and tells you to go back to the query editor to list the errors thrown up by the powerquery engine. Which, as previously stated, doesn't throw up an error for this instance.
So I've spent all afternoon trying to work out why my queries aren't loading, because I have an error that doesn't exist. fml.
[You can follow this issue on the communtiy feedback site here: https://community.powerbi.com/t5/... ] -
I’m fucked off tonight.
I’m having to pull a very complex data set out of dB and loop through results in a table.
Easy, done, but one of the Columns I’m pulling out needs further broken down. It’s a comma delimited string.
I can’t get the data, and inside the same loop explode that string so that the contents can be handled independently.
Raging! I have foreach loops inside foreach loops and arrays inside objects that are inside arrays.
I’m going to bed furious.2 -
I think it would be nice to have an option to automatically set the setting "auto load feed images" based on the type of connection (mobile data connection or WiFi).
I think that would be great ;)2 -
I have a doubt regarding blockchain. I understand how it works, but couldnot make use of it.
I am currently working on a platform which let client to assign task to their employee
Now I am planning to make use of blockchain on existing platform, to somehow set up a mechanism to authenticate that employee had completed the task, as a certification to the employee. I just cannot figure out how
I thought of an implementation, ( if its possible ) where client will trigger the smart contract with some employee-specific data, and the smart contract will generate a custom token, which will then be sent to the employee's account. This token will be non transferable1 -
I love and hate javascript. I set out to do a fully ajax/state driven form interface that operates with multiple interdependent data objects which all extend a base class.
React/Angular may have been a better call but I just didn't have time so I needed to rapid prototype in jquery /vanilla JS.
I'm in the midst of learning and refactoring all the ajax calls to promises and then to async/await, so it's a huge learning experience...
Meanwhile I've got to build objects to represent the data on the backend which is all legacy OScommerce/PHP
Hell of a ride. -
I am feeling a lot doubtful right now.
I am an average undergrad student who has been dedicating efforts in java/Android for most of my college life.
As of now i have decent command over java , launched 2 simple apps on playstore, worked as an android dev intern in 3 companies and make decent medium complexity apps. I will say i am 40-60% down the path of an expert native Android dev.
However apart from Android, am dumb as a stick. I know shit about ai,ml, web dev, js , react, hybrid stuff, and am not very good with competitive programming and system topics ( os, Algorithms, networking, etc)
So this closes a lot of doors for me. I can't apply to some top tier companies as they would either want expert competitive skills or expert Android dev skills.
I had bad experiences with startups which are usually willing take rejected students like me for the post of a droid dev... there is usually low packages , high pressure, and treatment like a slave
So i am very unsure what to do next. I have tried to learn web dev/ ai-ml-data sciences. They are not very interesting to me, but again, what is interest really :/
What should be my focus now?
A) I could be learning competitive and other interview related topics so that i could crack interviews of top companies , and later try to get a position of android developer there.
B) i could focus on become better in Android and start learning things that i don't know like rx, kotlin, etc. I could then hope to crack interview of medium sized app dev companies which would mainly focus on my android knowledge in their interviews
C) i could increase my skill set and learn web dev or ai/ml topics to increase my recruiter pool. It would be like option B, but i will have more medium sized companies willing to take me.
Currently i am in a shit storm. I am about to go into a mass recruiter company in which i have heard would be doing more or less data entry work2 -
I set the voice password for my Android phone, it asked me to say ok Google three times.
Why can't it allowed me to name my phone ? Like Cindy Cindy Cindy ????? Don't you think that will be much safer and easier? No need to have data connection to unlock. -
I have set up a VM on Azure as a small build server - nothing fancy yet, just being able to manually build LineageOS. I only spin it up when I need it, so when I do, I can assign quite a beefy machine and that's all fine. But: It needs a lot of hard drive space and the additional data disk needs to be paid 24/7, whether the VM is up or not. As such, it is eating up my (free MSDN) credits. I am not too well versed with Azure yet, so maybe there is a better way.
Does anybody know a cheap way to get a large-ish SSD on Azure? Maybe with ephemeral OS disks, potentially running on another (small) VM in the same network and sharing it? -
Vivaldi browser is shit.
Simple isntructions on how to make most shitty browser ever:
1. Force users to use "really-fucking-long" password that will not match to any of their existing ones.
2. Invent some useless stupid "encryption password" (why does any normal browser work fine without that shit) and most ridiculous - automatically set it to be the same as the main password.
3. Of course you forget the pass you set because you dont remember what symbol you added 5 times in the end of your normal pass to fit their stupid rules.
4. You have to reset it
5. "Encryption password" does not reset with it, so you still dont remember it
6. Sync is not working!
7. If you think this is shitty enought, you are not right - they went futher. To reset that fucking "encryption password" you have to... ERASE ALL YOUR CLOUD DATA.
Fucking retarded piece of shit - never, never trust those morons who made this shit browser to sync any of your sensitive information.17 -
Serious question - how does one learn basics of higher level networking, beyond stuff I can mess with on my local machine?
Today, I was completely caught off guard when I had to set up BGP-based loadbalancing on a machine and I just... Didn't know how the whole topology looks or behaves...
Once I go beyond the server in the network, I tend to get lost. Especially around how routing works and stuff like that... All I know is my machine has one or more gateways to which it sends data going to specific network segments...6 -
today i`m after 3 year fucking android developing
try to show user name on text view but it`s not working, after 3 hours i just site up and site down (i`m boy, fuckers) and suddenly see i stopped boy set data on wrong text view :cry:8 -
I recently joined the team that is responsible for the maintenance and development of the ibis adapter framework (http://github.com/ibissource/iaf)
The IAF is an integration framework, with a set of pipes written in java one can compose a service written in xml by building a pipeline with the premade pipes. For data mapping and validation we use xsl and xsd files. The framework can communicate over different protocols such as HTTP(S), JMS, EMS, SMTP, FTP and more.
I will be responsible for the web interface where you can manage/debug/test your application.1 -
Okay soo I’m not a database guy.. I’m an embedded engineer but I’m helping one of my interns make a hardware tracking database... so we are tracking assembled products (dev samples).. but also tracking the pcbs within the product.. depending on the product it might have more than one pcb or contain other components to track.
The question is how would I set up the relationship in the tables, so depending on the say “type id” of the product it would link to a table full of feilds specfic to that “type”.. say the product is of type phone and has a pcb of this and a camera of that.. blah blah blah.... but say another product is of type “washing machine”.. which has no screen, it has a different pcb, but also has other things..
There would be a type table .. washing machine, phone, tv, camera, pcb, ecu.. etc.. but those type would need their own tables...
I guess the question is how to relate a field to different tables depending on the value of the field... is this portion all done thru query results and logic rather than pure data base schemas?
What would be the question in terms of database lingo to google search the answer lol2 -
I personally hate that ad blockers block analytics software, specially since (as by the law) users must give consent before it collects data, several options exist to opt-out, and they are not f'ing ads.
I've been thinking to set a cron job to fetch analytics.js regularly and serve it locally as, let's say jquery-4.0.js, and screw it. What's your insight about it, fellow frontend devs?8 -
I've been working here for a little under a month keep hearing about them not remembering passwords, or not being able to access something due to a rarely used forgotten password, so I decided to Set up a shared password manager for the team using keepass and a generic intranet setup, pulled a password csv from one random on the floor person's chrome to start with. Turns out they ALL sync data from the owners account, and the owners saved passwords include HER payroll login info, and the accounts for ebay, amazon, etsy, basically anywhere you can buy anything....
yeah I think this is gonna need to be a conversation with her soon.8 -
!Rant
New to the whole front end world so pardon me for such a question.
I have a huge set of data about 5-10k records flowing in which needs to be displayed in a tabular form with sorting, filtering, selection addition and deletion.
Is it wise to sort and filter in the front end? Or make multiple calls to backend and perform the operations there?
If in front end what is the best way to perform these operations?
The application is going to be loaded on a screen and left there for users to view. So even local storage could be am option.
Using polymer for frontend so any special tool for this in polymer?3 -
please whats the easiest way i could train a neural network without writing a code,i have data set of about 700 images9
-
For any hack-related jobs, crypto recovery or data recovery reach out to TRUST GEEKS HACK EXPERT they also help trace accounts that are hacked and track down scammers as well.
As one of the leading crypto recovery company services, TRUST GEEKS HACK EXPERT specializes in the recovery of lost Bitcoin, Ethereum and any other cryptocurrencies including lost or hacked crypto wallets. TRUST GEEKS HACK EXPERT utilizes some of the latest technology and recovery techniques. If you have lost crypto to a fraudulent investment company, TRUST GEEKS HACK EXPERT has the right personnel with the required skill set, and all the tools to recover scammed bitcoin and cryptocurrency. 3
3 -
I need to add 44,000 image to git repo. I try to use git-lfs but it's too slow when I run "git add ." command. Is there any faster solution?
Extra Information : The image are the data set for my AI model. The reason I use git is because I wanted to manage my data set easier since I am going to add/remove images to that data set.16 -
Hello, I am stuck working on a project built on top of CakePHP 1.3 and I have some custom helpers, one of them named Order; for my views, I need to set a variable $order to contain the order data.
My problem is that if I set the variable in the controller ( $this->set(compact('order)); ) it overwrites the helper instance ( $this->Order ), and if I set it with a different name in the controller (say $_order) and reassign it in the view file ( $order = $_order ), the helprr instance ( $this->Order ) is also overwritten...
I really need to have the namings as described in order for my code to be clean and logical.
FML... -
First contact with XEN.
Xen Orchestrator UI / Web, logged in first time...
Wow. The UI is a big giant mess...
I don't care for this fucking bling bling shit... Need to have an overview of all VMs.
Oh Lord... Wtf... Icon hell...
Hm, I need more detailed information... Ah. Found the button.
Pressed button.
Wtf... What's taking so long...
Bloody shit.... Why does it include real data diagrams of usage statistic per row????!!! (had pagination set to 100 rows, one row is one VM)...
Bloody christ, ain't no option to configure that monstrosity... Export function?... Nope... Great. This will be a giant fuckfest...
Rest API? Nope.... Non existent as it seems. Thought that would be common in the 21st century... Guess what, nope.
Further googling...
Oh interesting. An cli client in NPM?
Hm, pretty scarce documentation...
Poked it a bit... Got first results...
xo-cli --list-objects type=VM
...
Let's take a look...
Oh JSON. Gooooooo(d)....
Wow. The document structure looks like someone puked out alphabet soup...
Or maybe the dev had hemorrhagic fever and was suffering from delusion and blood loss.
After this... More than devastating experience...
I took a look at Proxmox REST API.
Sweet jesus. That's like... Stone Age to 23rd century. Oo
https://pve.proxmox.com/pve-docs/...
Seriously... It seems not so hard to define an API to get the data of all VMs... Without suffering a traumatic brain injury.1








































































































































































































Top Tags
Weekly Rant
View